
结合Bi-LSTM和注意力模型的问答系统研究
2020-10-15 11:00邵曦陈明
计算机应用与软件 2020年10期
邵 曦 陈 明
(南京邮电大学通信与信息工程学院 江苏 南京 210003)
0 引 言
随着人工智能技术的快速发展,其实际应用场景也变得越来越广泛,在人们生活中的各个方面都有所体现。信息爆炸的今天,人们对于搜索引擎简单地返回一个相关网页感到不满,而问答系统能够与用户一对一进行交互,精确理解用户意图,从而能够高效快速地完成用户的需求[1-2]。最初对于问答系统的研究受限于语料数据的限制,并没有取得很好的效果。但随着互联网的发展,微博、Twitter等聊天工具的兴起,为问答系统模型训练提供了大量的文本数据。1966年,Weizenbaum[3]开发了最早的智能问答机器人ELIZA;2004年,Knill等[4]研发了问答机器人Sofia。这些早期的智能问答大都是基于检索技术和机器学习算法来实现的。常用的机器学习算法包括潜在狄利克雷分配模型(Latent Dirichlet Allocation,LDA)、支持向量机(Support Vector Machine,SVM)等,并利用贝叶斯法和K近邻等方法进行分类,以此构建问答之间的对应关系[5]。此类算法对于数据提出了很高的要求,必须有充足的数据才能保证匹配的准确性,且对于不同场景算法的泛化性较低,使用性能较差。
随着深度学习技术的快速发展,其在图像处理、语音交互等领域取得了优异的成绩[6]。近年来,深度学习在自然语言处理领域也大放异彩[7]。2012年,Mikolov等[8]发现了一种基于循环神经网络(Recurrent Neural Network,RNN)包含上下文信息的语言模型,将RNN应用到上下文信息的获取中去。Schuster等[9]提出了Bi-RNN模型,可以利用句子的未来信息进行预测。因此,深度学习模型对于问答系统的研究具有十分重要的作用。鉴于深度学习技术在自然语言处理方向上具有不错的效果,本文提出了一种基于Bi-LSTM和注意力模型的问答系统。通过生成句向量以获取句子上下文之间的语义信息和匹配关系,结合注意力模型,找到主题信息,从而生成最佳的回答。
目前,对于问答系统的研究主要分为两个方向:基于统计特征的机器学习方法和基于深度学习的方法。随着深度学习技术的发展和各种深度神经网络模型的提出,基于深度学习的方法成为了当前的研究热点。Kim[10]提出一种基于卷积神经网络(Convolution Neural Network,CNN)的分类模型,利用训练好的词向量模型进行文本分类。Shi等[11]提出了基于长短时记忆网络(Long Short-Term Memory,LSTM)的映射分类模型。为了提高回答的准确率以及效率,Sutskever等[12]提出了序列到序列(Sequence to Sequence,Seq2Seq)框架,通过输入端编码形成中间语义,再解码出相应的回答。Feng等[13]提出了基于共享卷积神经网络用于进行训练问答模型,通过该模型进行语义相似度计算,并且在英文数据集上取得了优异的成绩。注意力模型的提出使得自然语言处理领域又有了一个新的研究方向,该模型通过模拟人脑的机制,对语句中的信息进行加权处理,从而对语句主题信息进行重点关注。Yin等[14]提出了一种基于注意力模型的多层卷积神经网络模型,实现了对文本语义的建模,并且在问答匹配和语义识别上都取得了很好的效果。目前,关于注意力模型大致可以分为两类:Soft Attention和Hard Attention。Soft Attention是在求注意力概率分布的时候,对输入句子中每个单词都给出权重,其为概率分布;而Hard Attention在进行权重分配时,只会对句中某个或某几个单词进行分配,把目标句子单词和这个单词进行对齐,句中其他单词硬性地认为对齐概率为0。本文提出的注意力模型是基于Soft Attention机制实现的。
1 系统设计
图1为本文提出的结合Bi-LSTM和注意力模型的问答系统框图。在本系统中,输入问句会首先经过句向量(doc2vec)层生成相应的句向量,然后将生成的向量作为Bi-LSTM的网络输入,最后将网络模型的输出通过Attention机制形成最后的输出结果。
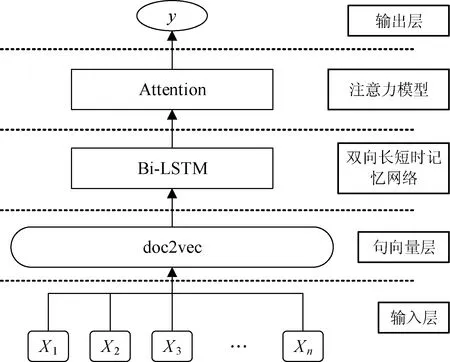
图1 基于Bi-LSTM和注意力模型问答系统
1.1 句向量层
在词向量(word2vec)技术占据主流时,Le等[15]在word2vec的基础上进行拓展,提出了句向量(doc2vec)技术。在word2vec技术中,主要分为Continuous Bag Of-Words(CBOW)模型和Skip-gram模型。本文主要讨论CBOW模型,其模型结构如图2所示。该模型分为输出层和输入层,相比传统的语言模型,由于其去掉了隐藏层,所以运算速度得到大幅提升。CBOW模型使用一段文本的中间词作为目标词,即利用该中间词的上下词来预测该词,通过利用上下文各词的词向量的平均值来替代之前模型各个拼接的词向量,可以提高模型预测的准确性。
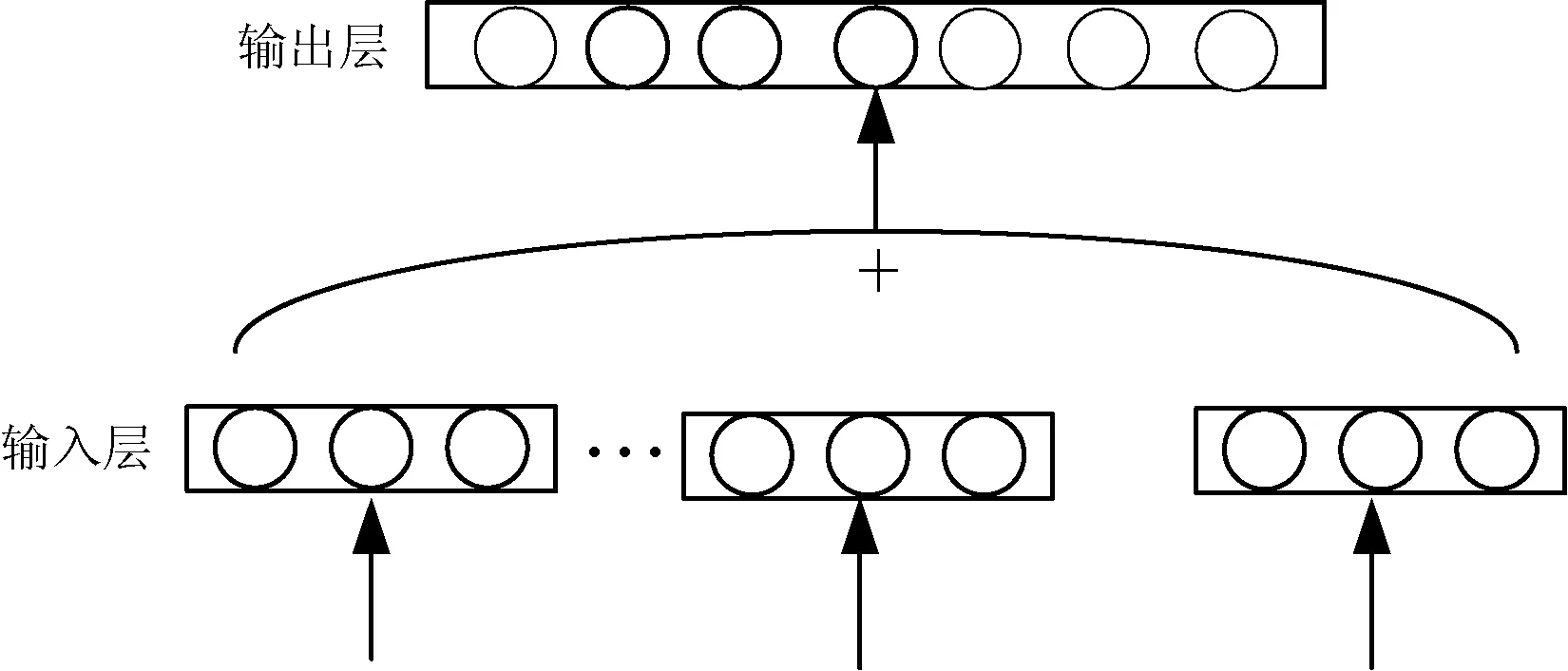
图2 CBOW模型结构图
与word2vec相对应,doc2vec也存在两种模型:DM(Distributed Memory)模型和DBOW(Distributed Bag of Words)模型,本文采用的是DM模型。DM模型框架如图3所示。
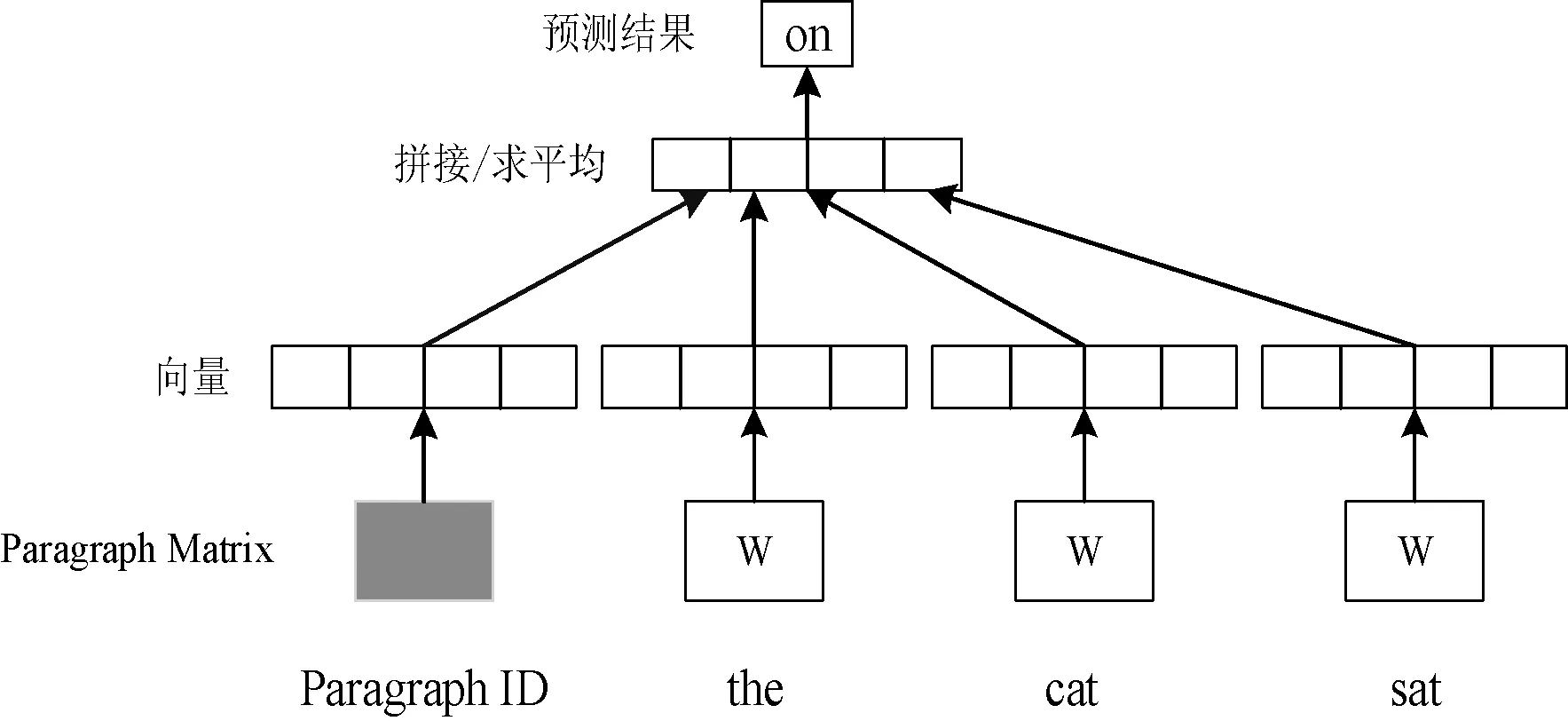
图3 DM模型
DM模型增加了一个Paragraph ID,在训练过程中,Paragraph ID会先映射成一个向量,且与词向量的维数相同,但二者属于不同的向量空间。在之后的计算中,paragraph vector和word vector累加起来,输入softmax层,从而输出预测结果。以“the cat sat”为例,通过DM模型可以预测出下一个词为“on”。在一个句子的训练过程中,paragraph ID始终保持不变,共享同一个paragraph vector,相当于每次在预测单词概率时,都利用了整个句子的语义。在进行预测时,给每一个句子分配一个paragraph ID,词向量和输出层softmax参数保持训练得到的不变,通过随机梯度下降法训练预测语句。本文利用句向量代替词向量进行预测,从而可以充分利用语句的语序信息,准确理解语句意图,并将其输入下一层的网络。
1.2 双向长短时记忆网络
Bi-LSTM是由LSTM演化而来,LSTM的提出是为了解决循环神经网络在面对长序列时产生的梯度消失问题[16]。LSTM网络模型由各个记忆单元组成,通过输入门、遗忘门和输出门来控制记忆单元的存储内容,通过门的控制可以在新的状态下不断叠加输入序列,从而对前面的信息具有记忆功能。LSTM的网络结构如图4所示。
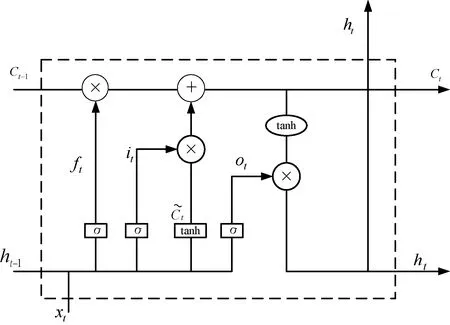
图4 LSTM网络结构
x={x1,x2,…,xt}表示输入序列,h={h1,h2,…,ht}表示记忆单元的输出,Ct表示记忆单元的记忆内容。网络具体计算方式如下:
ft=σ(wf·[ht-1,xt]+bf)
(1)
it=σ(wi·[ht-1,xt]+bi)
(2)
(3)
(4)
ot=σ(wo·[ht-1,xt]+bo)
(5)
ht=ot*tanh(Ct)
(6)
式中:w表示权重矩阵;b表示偏置向量;σ表示sigmoid函数。上一单元的输出和当前输入信息经过遗忘门后,网络决定需要抛弃哪种信息,然后通过输入门进行信息更新,将Ct-1更新为Ct,最后通过输出门确定需要输出的值ot。
由于单向LSTM网络在进行训练时只考虑到句子的时序信息而忽略了上下文之间的关系,因此在进行多句对话时,往往不能取得很好的效果。Bi-LSTM网络是由前向LSTM和后向LSTM组成,可以充分利用序列的上下文信息。本文提出用Bi-LSTM对问句进行训练,融合前向LSTM和后向LSTM的结果进行输出,从而可以提高模型回答的准确率。
1.3 注意力模型
注意力模型是由Bahdanau等[17]提出,该模型借鉴了人脑的思维模式,即人的注意力一定是集中在目光看到的事物上,随着目光的转移,注意力也在转移。在自然语言处理领域中,注意力模型往往是附着在Encoder-Decoder(即Seq2Seq)框架下使用。该框架是处理由一个句子生成另一个句子的通用处理模型,对于输入问句X经过Encoder模块编码形成中间内容向量C,Decoder模块根据中间内容向量C和之前已经生成的历史信息解码出该时刻的单词。在该框架中,解码生成目标单词时,采用的都是同一个内容向量C,因此无法获取关键信息,例如以下对话:
Q:南京有什么好玩的地方?
A:南京是江苏省会,著名的六朝古都,是一座文化名城,有新街口、总统府和夫子庙等旅游景点。
当根据这个问题去生成答案时,“新街口”“总统府”“夫子庙”等回答与问题语义更加贴切,所以在模型中应当突出这些关键词语的作用。采用将注意力模型应用到Encoder-Decoder框架中,可以有效地为不同词语分配不同的权重,达到获取对话主题信息的目的。融合注意力模型的Encoder-Decoder框架如图5所示。
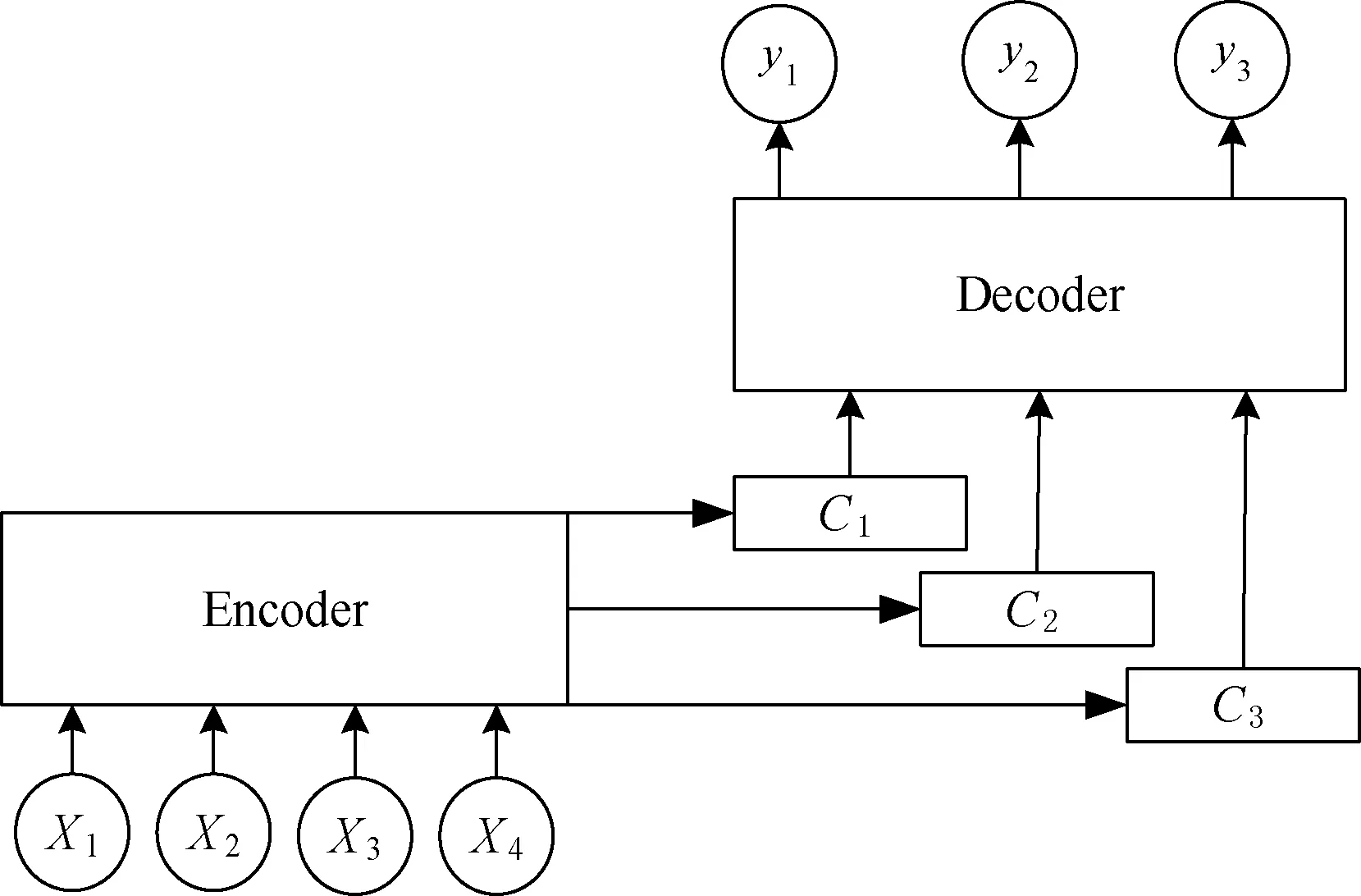
图5 融合注意力模型的Encoder-Decoder框架
图5中的Encoder-Decoder框架融合了注意力模型,在解码时条件概率可以写为:
p(y1,y2,…,yi-1,X)=g(yi-1,si,ci)
(7)
式中:si可以是一个非线性的多层神经网络,表示解码器在i时刻的隐藏状态,其计算公式如下:
si=f(si-1,yi-1,ci)
(8)
式中:f(·)表示某种非线性函数。可以看出,目标输出与相对应的内容向量ci有关,相比于传统的Encoder-Decoder框架只有一个内容向量C,图5模型具有更好的获取主题信息的能力。ci由编码时的隐藏向量序列加权得到:
(9)
(10)
式中:eij=a(si-1,hj);L表示输入源语句单词的个数;αij表示在输入第i个单词时源输入语句第j个单词的注意力分配系数,αij的值越高,表明在生成第i个输出时受第j个输入的影响越大;hj表示源输入语句第j个单词的语义编码。将第i-1时刻的隐藏状态si-1和hj通过前馈神经网络a计算得到一个数值,然后使用softmax得到i时刻输出在L个输入隐藏状态中的分配系数。
本文研究的问答系统就是采用融合了注意力模型的Encoder-Decoder框架,对问句进行编码并解码生成出相应的回答,具有回答准确、多样等特点。
2 实 验
2.1 实验环境
本文的实验都是在TensorFlow框架下进行的。TensorFlow是一个经典的深度学习框架,具有一个很强大的库以支持大规模的数值计算,并在后端使用C++加快其计算速度,拥有丰富的高级机器学习应用程序接口(API)可以使其更容易地配置、训练模型。
2.2 实验数据收集及处理
本文实验数据来源于百度客服推广的对话录音,利用科大讯飞的语音转文字工具,将对话录音转换成文本形式。将对话文本整理成两个txt文档,分别是问句文档question.txt和答句文档answer.txt。整个问答文档包括大约80 000条对话数据,其中60 000条作为训练数据集,20 000条作为测试数据集。采用jieba分词器进行文档的中文分词,然后进行去标点处理等操作,为句向量的生成做准备。
2.3 结果与分析
利用TensorFlow框架对该神经网络模型迭代训练,直至网络收敛并保存模型,模型参数如表1所示。

表1 模型的相关参数
在对话问答系统领域,主要采用计算系统生成的回答与参考回答之间的余弦相似度,以此来对问答系统的性能进行评价。
本文的问答系统采用上述方法进行性能评价。通过使用句向量模型分别计算生成回答与参考回答的句向量,然后计算二者之间的余弦相似度确定生成回答的准确性。为了更好地验证本文所提出的方法,另外设置了两组对照实验,分别是:未融合注意力模型的Seq2Seq问答模型和基于检索技术的问答模型。不同模型的回答准确率如表2所示。

表2 各个模型实验结果对比
可以看出,本文提出的基于Bi-LSTM和注意力模型的问答系统在回答的准确率上较传统的两种模型都有较大的提升,其准确率可达到80.76%。对于检索模型,其只能依靠训练过的语料库来进行回答,不能对训练语料库中未出现的问句做出有效的回答,但对于训练语料库中出现过的问题,可以给出准确的回答;而Seq2Seq模型虽然能够解决检索模型的一些缺陷,但是在解决长对话问题和理解用户语义方面仍然存在不足,往往不能做出准确的回答。本文提出的模型充分利用了Bi-LSTM对上下文信息的获取能力以及注意力模型对主题信息的获取能力,从而提高了问答系统的准确率。图6为本文提出的模型的问答效果。

图6 对话效果演示
可以看出,本文设计的问答系统在面对提问时,能够理解问题的语义并结合上下文对话信息,做出较为准确的回答。例如:在面对“太高了”这个简短的问句时,系统能够联系到上文的价格信息,最后生成相应的回答。
3 结 语
本文提出一种结合Bi-LSTM和注意力模型的问答系统,采用了Encoder-Decoder框架实现系统的问答,并进行了模型训练和测试。设置对照实验,通过回答的准确率对系统的性能进行评估。实验表明,本文系统在问答结果上能够达到较高的准确率,可以较为流畅地回答问题,解决了传统问答系统回答僵硬、理解能力不足等缺陷。在今后的研究工作中,将着重研究句法分析、数据预处理等,以降低中文问答语料库不足对模型训练带来的影响。同时,尝试利用不同的神经网络模型构建系统,观察是否能够更好地提高系统回答准确率,以及如何将注意力模型应用到整个问句上也是未来研究的方向。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
新高考·高一数学(2022年3期)2022-04-28
黑龙江大学自然科学学报(2022年1期)2022-03-29
煤气与热力(2022年2期)2022-03-09
小资CHIC!ELEGANCE(2022年1期)2022-01-11
北京航空航天大学学报(2021年4期)2021-11-24
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年24期)2019-02-23
现代职业教育·职业培训(2019年12期)2019-02-03
高中生学习·高三版(2016年9期)2016-05-14
