
基于Word模板的复杂文档快速生成方法
2020-10-15 11:00黎茂锋刘志勤
计算机应用与软件 2020年10期
骆 蓉 黄 俊 黎茂锋 刘志勤
(西南科技大学计算机科学与技术学院 四川 绵阳 621010)
0 引 言
Word作为一款功能强大的字处理软件,广泛应用于各个行业。在各类数据分析系统开发场景中,往往需要动态生成Word形式的数据分析报告。这些报告通常逻辑结构复杂,数据展现形式多样,包含了文本、表格、公式、图片等,有的甚至需要在已有的表格内再嵌入图片或者表格,并且报告的生成对内容格式与排版的要求非常严格。一些Word报告包含的数据量十分庞大,可达几百页之多。对于这样复杂的Word报告,直接使用COM组件技术[1]、ActiveX技术[2]和Jacob技术[3]等开发技术硬编码生成Word文档,不仅耗时费力,且代码量大,可读性差,不利于后期修改维护。
针对以上问题,目前有两种较好的解决方案。第一种为Word模板替换法[4-6],开发者预先制定带有动态内容的Word模板,再通过相应开发工具包解析替换模板中的占位内容,生成新的文档。该方法直接以Word文档为模板,内容的格式与排版可直接通过Office软件完成,减小了程序的复杂性,便于后期的修改维护,但文档生成效率不高,只适用于较小数据量的Word文档生成场景。第二种为模板引擎生成法[7-9],开发者仍然需要先制作Word文档,并另存为Word 2003 xml文档,再通过模板引擎的相关语法修改xml文档中的动态内容,形成新的模板。使用模板引擎解析该模板并填充数据,输出最终的.doc文档。该方法很大程度上提高了文档的生成效率,但生成的文档较大,开发者需要花费大量的时间制作模板,且当文档样式改变时,必须重新订制对应的模板,不利于修改维护。因此,如何平衡该类文档的生成效率、开发维护难度与工作量,是目前亟需解决的问题。
针对现有方法的不足,本文提出了一种基于Word模板的复杂文档快速生成方法,实现了文档的高生成效率和低开发成本。基于Office Open XML规范(OOXML)[10]实现了Word文档的自动生成,并通过Word文档自动生成主文档部件documen.xml的Enjoy模板,使得开发者既能使用Word模板加快开发速度,又能使用Enjoy模板引擎提高文档生成效率。对比实验表明,本文方法在文档生成效率以及文档生成大小上综合最优。
1 相关技术
1.1 OOXML
Office Open XML为Microsoft开发的一种以XML为基础并以ZIP格式压缩的电子文件规范,支持文件、表格、备忘录和幻灯片等文件格式[11]。在MS Word 2007及之后版本中,OOXML替代了传统的二进制格式,成为Word文档的默认存储格式,Word文档扩展名由.doc变为.docx。目前,有不少研究人员与开发者利用该规范构建Word文档生成与修改的解决方案[12-14]。
在OOXML格式下,Word文档由一个压缩的ZIP包组成,解压缩后可得到Word文档的内部组织结构,如图1所示。Word文档由文件夹和文件组成,这些文件被称为部件(part),每个部件定义了文档的特定信息。_rels文件夹用于定义ZIP包的部件关系;docProps文件夹用于定义应用程序的属性部件;word文件夹用于定义文档主体内容,包含存放关系部件的res文件夹、存放文档主题样式的theme文件夹、存放多媒体内容的media文件夹、存放正文的主文档部件document.xml,以及存放整体样式的样式部件style.xml等文档内容部件;[Content_Types].xml文件用于定义文档各个部件的属性信息以及内容类型。因此,修改模板中的相应部件后,与该模板中的其他部件一同压缩就能生成目标Word文档。本文根据上述原理制定了Word文档的生成策略。
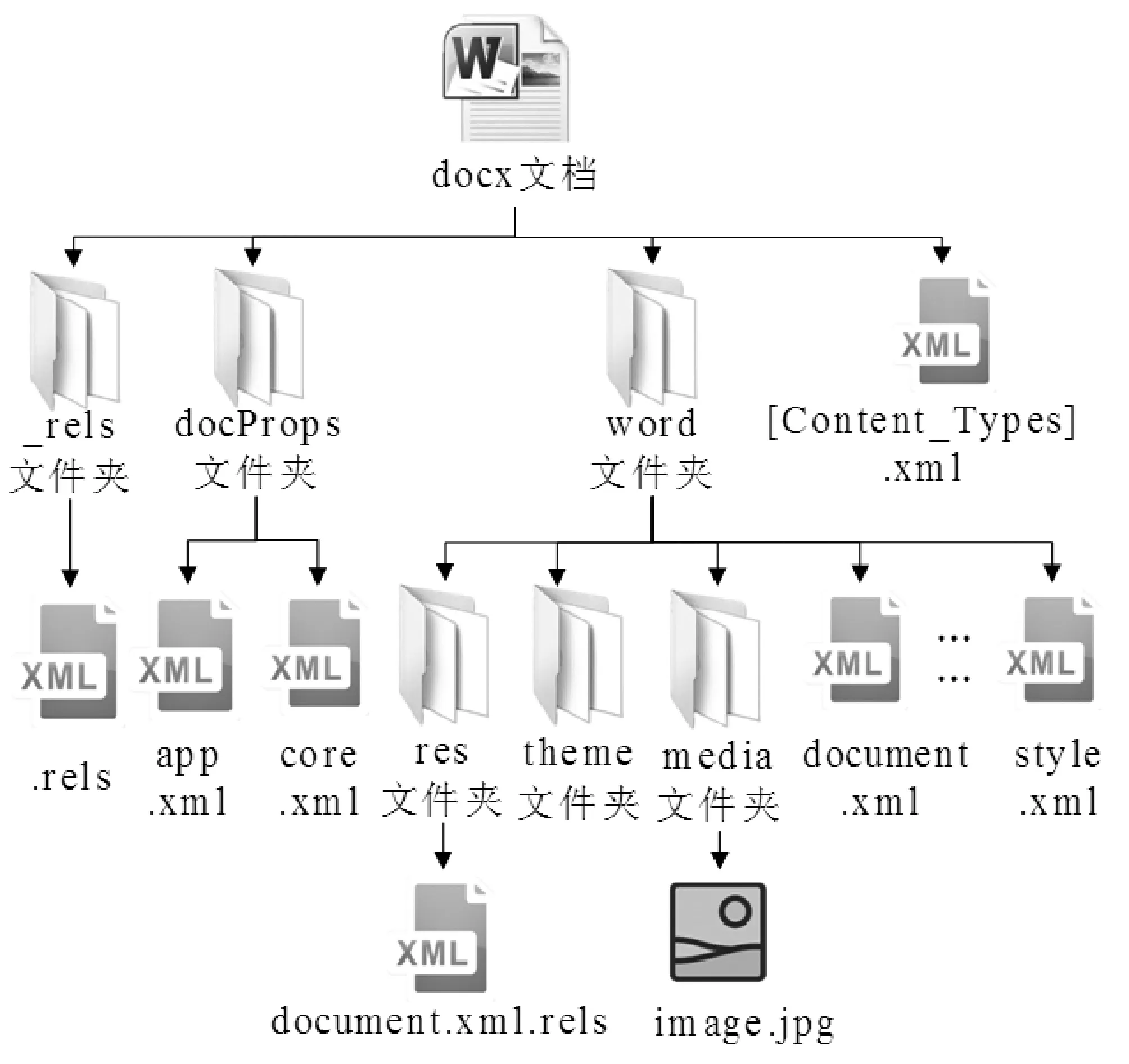
图1 Word文档内部组织结构
Word文档中的部件使用WordprocessingML语言[15]进行描述,其形式符合XML的基本规范。由于提出的复杂文档快速生成方法主要是对document.xml文件进行操作,特将该文件中的核心元素以及结构做一个简单说明。在document.xml文件中,元素w:body代表正文主体框架,由多个块级元素组成,如段落元素w:p和表格元素w:tbl。其中:w:p可包含多个连续文本范围元素w:r,而每一个w:r又可包含文本元素w:t或绘图元素w:drawing;w:tbl由多个行元素w:tr组成,在w:tr中可包含多个单元格元素w:tc,而每一个w:tc又可以包含多个w:p和w:tbl。本文根据document.xml的xml结构设计了Enjoy模板生成方法。
1.2 Enjoy模板引擎
Enjoy引擎模板是JFinal框架的组成部分,可单独使用。它是一个由Java编写的极轻量级的模板引擎,大小仅为227 KB[16]。相比于FreeMarker和Velocity等传统模板引擎,Enjoy不依赖第三方工具进行词法分析和语法分析,具有更优的性能。此外,Enjoy仅含7个核心指令,在表达式规则的设计上也尽可能沿用Java的语法规则,且基于空合操作符,实现了安全取值、安全调用,避免显式判断空值操作,使得模板制作更加容易。本文选择使用Enjoy模板引擎生成主文档部件document.xml。
1.3 DOM4J
DOM4J是一个开源的Java XML API,它提供了大量的操作XML文件的接口,其性能优异,功能强大,简单易用[17]。本文使用DOM4J技术读取并修改document.xml文件。
2 方法设计
2.1 总体设计
根据OOXML规范,本文方法直接以Word文档作为模板,通过复制模板中的所有部件并修改特定部件中的内容生成目标文档,总体设计如图2所示。本文生成的Word文档主要是对模板中正文内容的修改,涉及的部件有document.xml、document.xml.rels,以及[Content_types].xml文件,这三个xml类型文件可直接通过DOM4J技术进行修改。但当目标文档中填充的数据量较大时,就需在document.xml中频繁添加树节点,使得文档的生成效率变低。对此,引入Enjoy模板引擎技术生成document.xml。
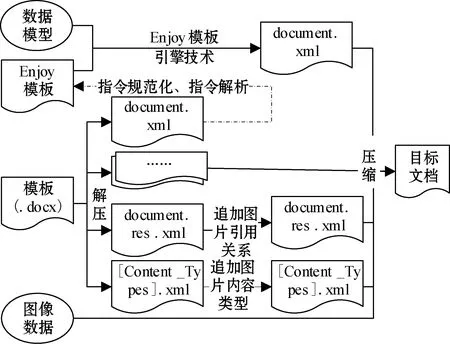
图2 复杂文档生成方法总体设计
引入Enjoy模板引擎后,开发者必需在document.xml文件中插入Enjoy指令生成新的Enjoy模板。为了简化开发,本文基于Enjoy指令,设计并实现了一套Word模板指令集,该指令集完成了指令规范化与指令解析,可自动生成document.xml的Enjoy模板。因此,开发者只需在Word模板中编写动态内容及其逻辑控制,而不用关心对应Enjoy模板的生成过程。
2.2 Enjoy模板的自动生成
开发者通过在Word模板中直接使用Enjoy指令编辑动态内容来生成document.xml文件的Enjoy模板是不可行的。主要原因有以下两点:(1)开发者在生成document.xml文件的Enjoy模板时,应该修改文本元素w:t或绘图元素w:drawing的属性实现动态文本、图片的标记,并在相关元素的前后位置插入#for、#if等指令控制内容逻辑。但在使用Word软件编辑模板时,所有的指令均被视为段落中的文本,存储于w:t中,而不能插到w:drawing及相应元素的前后位置上。(2)Word模板中的指令转换成xml形式时,通常会被拆分,存储在多个w:t中,Enjoy模板引擎无法解析。针对这两个问题,本文在Enjoy指令的基础上,设计了一组模板指令,用于标记Enjoy指令在document.xml中的位置,实现了指令规范化以及指令解析,使得开发者可直接通过Word文档生成Enjoy模板。
2.2.1模板指令设计
模板指令由两部分信息组成。一部分为实际操作动态内容与逻辑的Enjoy指令;另一部分为Enjoy指令在document.xml中的位置信息。
根据以往开发者手动生成Enjoy模板的经验可知:Enjoy插值指令#()出现的位置主要在文本元素w:t以及绘图元素w:drawing的特定属性中。#if、#for、#switch等逻辑控制指令出现的位置主要在块级元素w:p和w:tbl、运行元素w:r,以及行元素w:tr的前后位置之间。据此,设计了如下模板指令。
(1)文本输出指令。由于动态文本的位置就在元素w:t中,不需要改变位置,可直接使用Enjoy模板引擎的插值指令:#(para),para的取值为基本类型、对象的属性或者数组中的一个元素等。
(2)图片输出指令。图片信息存储于绘图元素w:drawing中,考虑到图片的循环输出,需要修改w:drawing中的wp:docPr、pic:cNvPr,以及a:blip元素中的属性值。由于要替换多个参数,为了降低模板制作的复杂度,将上述需要修改的属性封装到图片类中。定义图片输出指令为:@pic(picObj),picObj参数只能是图片类实例。为了方便解析,在图片输出指令后放置样例图片,并保证指令与样例图片放在一个段落中。解析过程中,需要将picObj的属性分别插入到w:drawing的相应位置;为防止picObj为空所导致的文档生成错误,需要在w:r之前判断该参数是否为空。
(3)块级逻辑指令。为了实现段落、表格间的逻辑控制,定义块级逻辑指令:@blk(stats),参数stats为一个或多个Enjoy模板引擎中的逻辑控制指令。解析时,会直接将该指令所在的w:p替换为stats指令。
(4)运行逻辑指令。为了实现段落内的逻辑控制,定义运行逻辑指令:@run(stats),参数stats为一个或多个Enjoy指令。解析时,stats会取代该指令所在的w:r。
(5)行逻辑指令。为了实现表格行的逻辑控制,定义行逻辑指令:@befTr(stats)和@aftTr(stats),分别代表在当前指令所在的w:tr之前插入stats指令和在当前指令所在的w:tr之后插入stats指令。
2.2.2指令规范化
指令规范化是指把分散到多个w:r中的模板指令合并到第一个w:r中。由于完整的指令存储在段落w:p中,所以只需要遍历所有w:p进行指令规范化即可,具体方法如下:获取所有的段落元素w:p;对于每一个w:p,依次获取含有文本元素w:t的运行元素w:r,并将w:t的内容追加至buf数组中;通过词法分析算法对buf数组进行模板指令识别,记录每一个模板指令开始的w:r和结束的w:r;合并开始w:r到结束w:r之间的文本内容,实现模板指令的规范化;直到所有的段落遍历结束,指令规范化完成。指令规范化流程如图3所示。
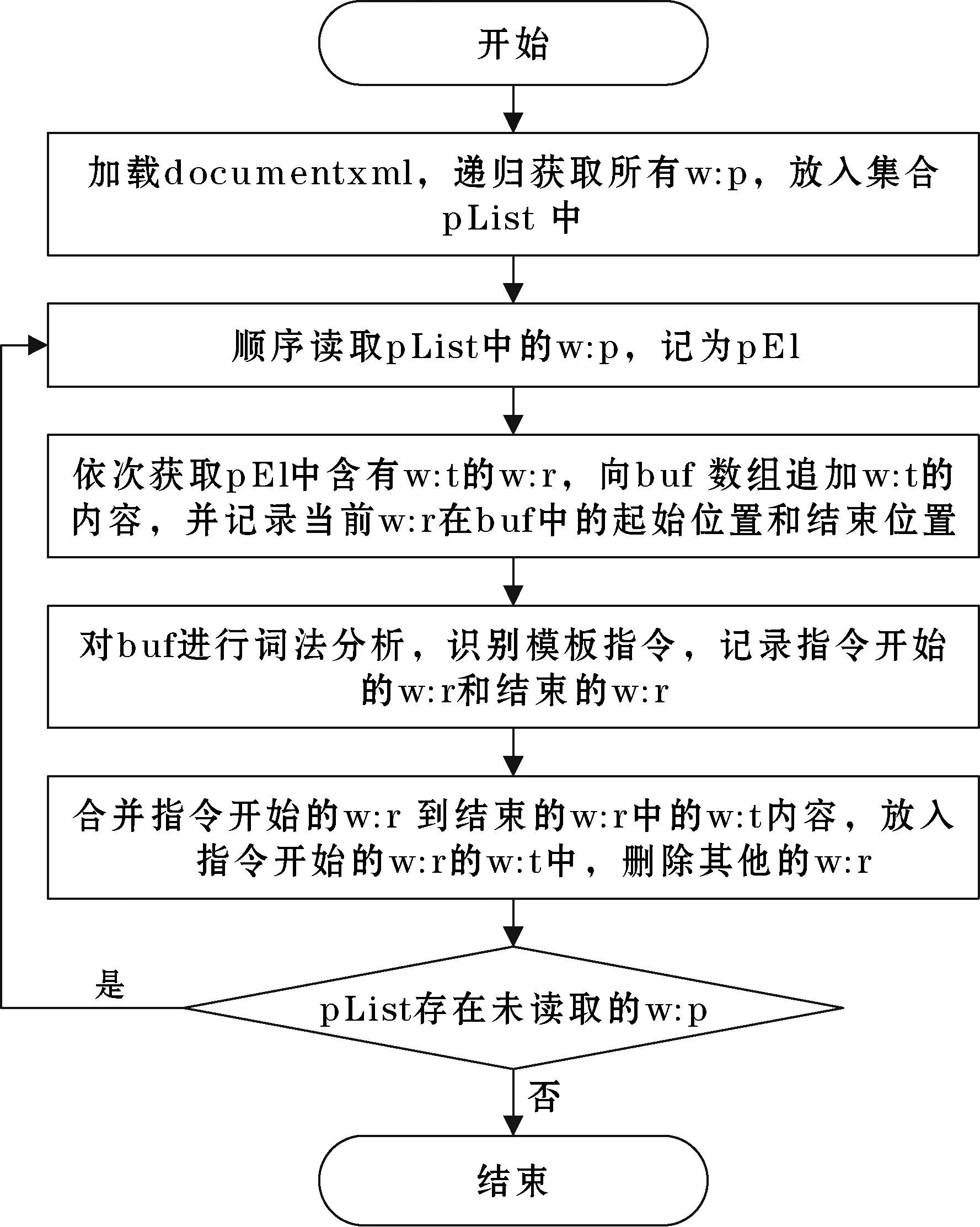
图3 指令规范化流程
指令规范化执行完成后,在一个w:t中,可能既包含静态文本,又包含模板指令。
2.2.3指令解析
指令解析主要是将模板指令中的Enjoy指令放到正确的位置,具体步骤如下:使用DOM4J技术加载document.xml文件,生成对应的dom树,获取所有的w:p;遍历w:p,获取当前w:p中所有含有w:t的w:r;对于每个w:r,获取w:t的文本内容并按照指令类型划分成多个模板指令(将静态文本处理视为文本输出指令);分别根据指令类型对每一个模板指令进行处理,由于使用DOM4J不能直接在元素的前后位置插入Enjoy指令,因此创建占位元素进行标记,使用Map集合记录占位元素的信息与对应的Enjoy指令;直到所有的模板指令都处理完成后,删除当前w:r;将dom树转化为字符串,并把所有的占位元素替换为对应Enjoy指令。指令解析流程如图4所示。
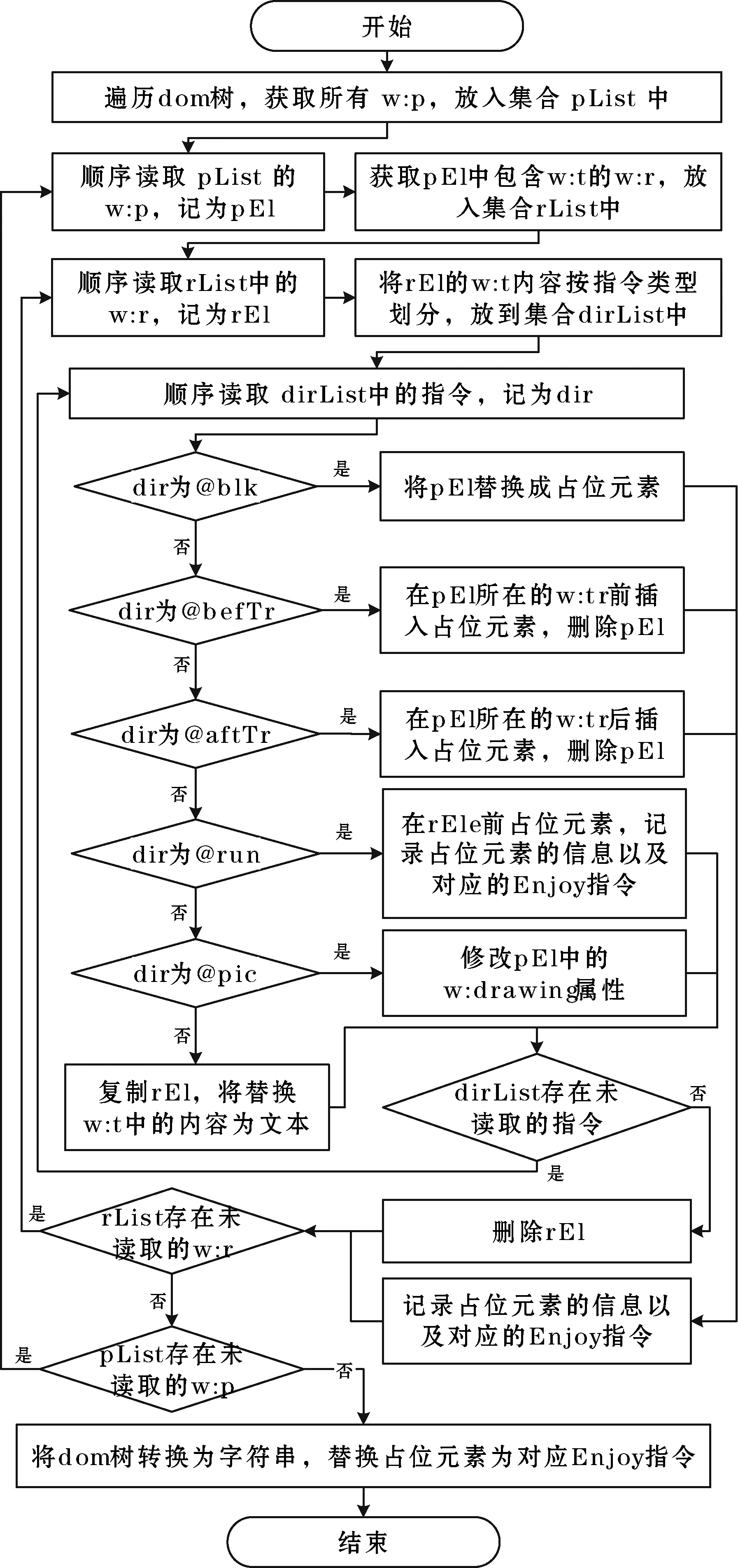
图4 指令解析流程
指令解析完成后,即完成了Enjoy模板的生成。
2.3 Word文档生成
Word文档生成之前需要准备数据,由于图片的生成涉及document.xml.rels与[Content_types].xml文件的修改,因此将文本数据与图片数据分离,分别以树状结构进行组织,便于后续对图片进行操作。
在准备好Word模板、Enjoy模板以及数据之后,基于OOXML生成Word文档的具体流程如下。首先判断是否涉及图片的生成:如果不涉及,则直接通过Enjoy模板引擎技术将文本数据填充到Enjoy模板中,生成新的document.xml文件,将其与Word模板的其他部件一同压缩输出,得到目标文档;如果涉及图片的生成,则需要获取所有的图片信息,将其转化为图片类,添加到文本中,并统计图片的内容类型以及记录引用关系。再通过Enjoy模板引擎生成document.xml文件,复制Word模板中的document.xml.rels与[ContentTypes].xml文件,并分别追加图片的引用关系与内容类型。最后将图片数据写入word/media/文件夹中,同时将新生成的部件与Word模板中的其他部件一起压缩输出,得到目标文档。文档生成的核心步骤如算法1所示。
算法1文档生成算法
输入:Word模板文件wFile,Enjoy模板文件eFile,文本数据模型dataMap,图片数据picMap。
输出:目标文档dirWord。
Procedure WordGeneration
1.if picMap=null then
%生成document.xml文件
2.docXML ← genDocumentXML(eFile,dataMap)
%将document.xml与Word模板的其他的部件一同压缩输出
3. dirWord ← replaceWordPart(wFile,docXML)
4. else
%将图片数据转换为图片类
5. picClassMap ← picMap2PicClassMap(picMap)
%将图片的信息添加到文本数据模型
6. dataMap.add(picClassMap)
7. docXML ← genDocumentXML(eFile,dataMap)
%获取模板中的[ContentTypes].xml文件
8. typesXML ← getContentTypesXML(wFile)
%追加图片的内容类型
9. typesXML ← addContentTypes(typesXML, picMap)
%获取模板中的document.xml.rels文件
10. docRelsXML ← getDocResXML(wFile)
%追加图片的引用信息
11.docRelsXML ← addPicRes(docResXML, picClassMap)
%将部件压缩输出到目标文档中
12.dirWord ← replaceWordPart(wFile, docXML, typesXML, docRelsXML)
%把图片数据写入word/media/文件夹
13. addPic(dirWord, picClassMap)
14. end if
15.return dirWord
3 应用实例
目前,本文方法已经成功应用于某气动数据库系统中,实现了气动设计数据手册、过程文档、分析报告等多种文档的快速、准确生成。这些文档为飞行器研究人员提供了气动数据分析、优化、决策依据。气动数据量大、维度高、结构复杂等特点[18]使得飞行器研制过程复杂,利用传统方法生成相应的文档难度很大;同时,文档的生成还需要根据不同的研究方向和行业需求进行定制,工作量巨大。而使用本文提出的方法极大地降低了开发难度,减少了工作量,提高了系统的研发效率。
以系统中数据分析报告的生成为例,该报告中包含了气动数据集来源、数据类型等统计信息,另外还包含了大量的表格、图像等数据分析内容。通过本文设计的指令集实现的该报告Word文档模板如图5所示。

图5 某气动数据库系统项目的分析报告模板
通过该模板可以对图片、表格、表格行等动态内容进行添加,并对这些内容进行结构上的逻辑控制。采用本文方法生成的数据分析报告实例如图6所示。
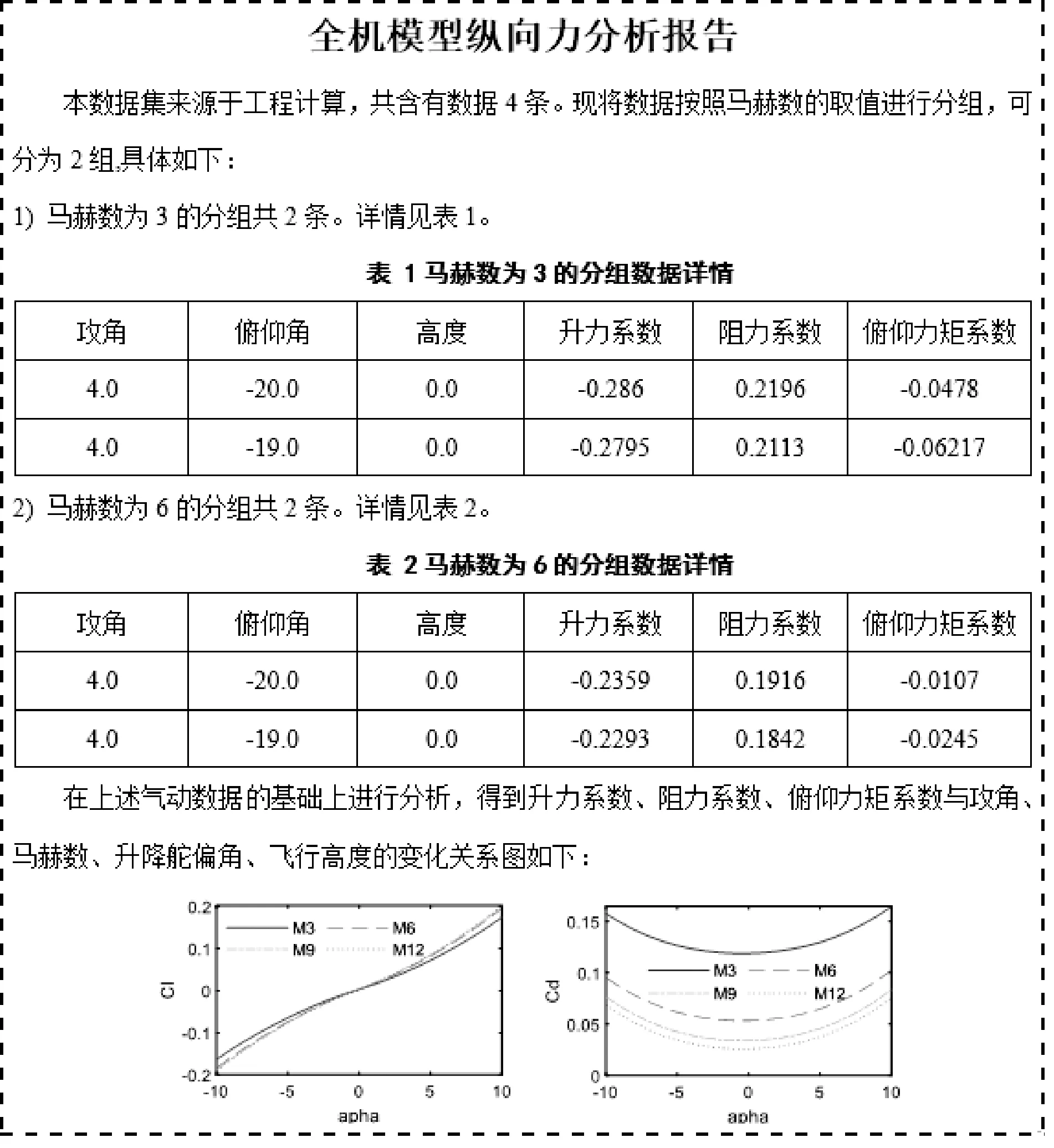
图6 某气动数据库系统项目的分析报告实例
可以看出,图6中固定文本、样式等静态内容与图5完全一致;表格、图像等动态数据也按照预期填充到了模板中的相应位置。
上述实例表明,本文方法操作简单,易于理解,降低了开发成本,便于后期维护,具有较好的实用性。
4 实 验
4.1 实验环境
所有实验均在普通PC上进行。硬件环境:处理器为Intel(R)Core(TM)i5-2520M @ 2.5 GHz,内存为4 GB。软件环境:Windows 10 专业版,MyEclipse 2017,JDK1.8。
4.2 性能对比与分析
将本文方法与文献所提两种复杂文档生成方法的生成效率以及文档大小进行对比,来分析本文方法的性能。方法1为Word模板替换法,选用POI解析Word文档替换动态内容,生成docx文档;方法2为模板引擎生成法,借助FreeMaker模板引擎生成doc文档。
4.2.1文档生成效率分析
以生成不同表格行数和不同图片数量的Word文档来对比这三种方法的文本生成效率。在实验中,不考虑数据准备所耗用的时间。
在表格实验中,循环行为7列,三种方法生成文档所用时间如图7所示。
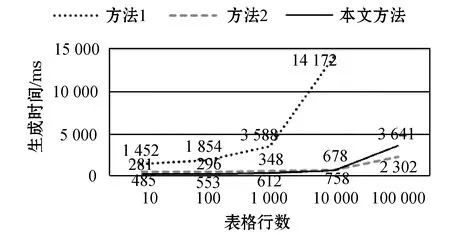
图7 三种方法生成表格文档所用时间
可以看出,方法1的文档生成时间随表格行数的增加而急剧上升,文本生成效率较低(由于该方法生成10 000行表格文档所用时间较长,因此未在图中给出其生成100 000行表格文档的时间);方法2与本文方法随着行数的增加,总时间增加,但是涨幅不大,文本生成效率更高。在10 000行以内,本文方法略优于方法2,但随着表格行数的继续增加,本文方法与方法2之间的时间差距变小;10 000行后,方法2略高于本文方法。出现该趋势的原因是:方法2的总耗时由模板解析时间及文档输出时间组成,而本文方法的总耗时还包含了文档压缩时间;当数据量较小时,本文方法压缩输出document.xml文件的时间占比小,而Enjoy模板引擎的解析性能优于FreeMaker模板引擎,本文方法比方法2更优;但随着数据量的增大,Enjoy模板的解析时间占总时间的比例越来越小,而压缩输出document.xml文件占总时间的比例越来越大,最终导致本文方法略低于方法2。
在图片实验中,所用图片大小在几十到几百KB之间,三种方法生成不同数量图片的Word文档所用时间如图8所示。
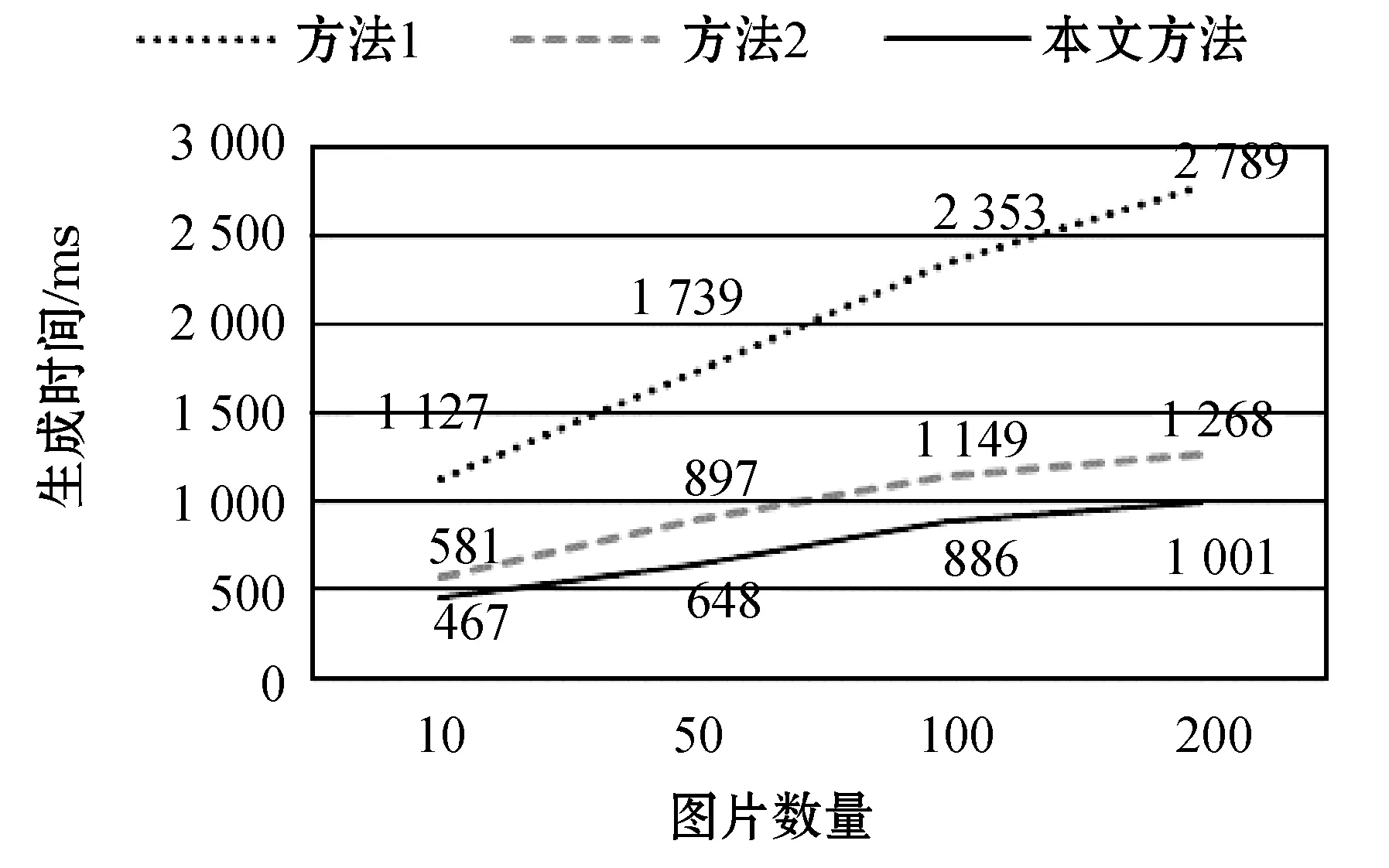
图8 三种方法生成图片文档所用时间
可以看出,方法1的文档生成时间随图片数量的增加而大幅度增加;方法2与本文方法的文档生成时间随图片数量的增加而小幅度增加,且本文方法优于方法2。
通过实验证明,方法2与本文方法的文档生成效率接近,均高于方法1。
4.2.2文档大小分析
Word文档的大小会影响文档下载的速度以及打开Word文档的速度。因此,本文将其作为一个评价指标,分别比较了三种方法生成的Word文档大小。
三种方法生成不同表格行数的Word文档大小如表1所示。
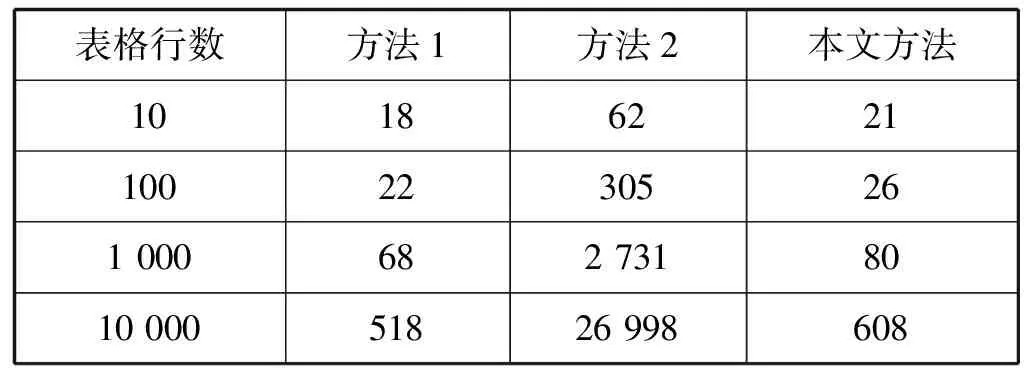
表1 三种方法生成表格文档大小 KB
方法1与本文方法的文档大小随着表格行数的增加少量增长,而方法2则急剧上升,在10 000行时,其大小约为本文方法的44倍。这是由于文档格式的差异造成的,方法1与本文方法生成的Word文档格式为OOXML,方法2生成的Word格式为二进制格式,OOXML存储文档采用了ZIP压缩技术,有效地减小了文档的大小。
三种方法生成多幅图片的Word文档大小如表2所示。
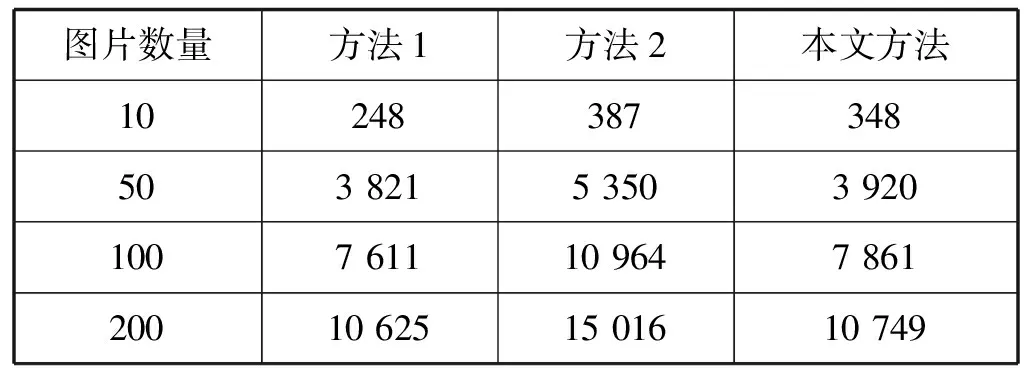
表2 三种方法生成图片文档大小 KB
在生成相同数量图片的文档时,方法1与本文方法生成的文档较小,方法2生成的文档较大。随着图片数量的增加,方法1与本文方法的优势更加明显。原因是方法1与本文方法对图片进行了压缩存储,减少了图片的大小,方法2将图片转换为Base64编码进行存储,没有进行压缩。
综上所述,在文档生成的时间上,本文方法与方法2效率相近,皆高于方法1。在文档生成的大小上,本文方法与方法1生成的文档大小接近,都小于方法2。因此,本文方法总体上优于其他两个方法。
5 结 语
本文针对现有的复杂Word文档生成方案存在的开发复杂与工作量大的问题,提出了一种基于Word模板的复杂文档快速生成方法。该方法基于OOXML规范制定了Word文档生成策略,可直接使用Word文档作为模板。同时设计了一组模板指令,实现了指令规范化与指令解析,能够自动将document.xml文件转换为Enjoy模板,在引入Enjoy模板引擎技术提高效率的同时,解决了Enjoy模板制作复杂和后期修改维护困难等问题。通过实例分析,并与已有的两种方法进行了性能对比,证明了本文方法的可行性、实用性、高效性。
猜你喜欢
江苏安全生产(2022年8期)2022-11-01
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2021年9期)2021-05-12
房地产导刊(2020年12期)2021-01-14
学校教育研究(2020年11期)2020-06-08
人民交通(2020年4期)2020-04-16
航空科学技术(2019年2期)2019-09-10
科技与创新(2019年2期)2019-02-14
电脑爱好者(2017年7期)2017-05-06
