
主机和设备协作方式提升固态硬盘随机读取性能
2020-10-15 11:01李明江
计算机应用与软件 2020年10期
李明江 陈 仁
1(黔南民族师范学院计算机与信息学院人工智能与大数据应用技术研究所 贵州 都匀 558000) 2(中科院上海技术物理研究所中国科学院红外探测与成像技术重点实验室 上海 200083)
0 引 言
近年来,由于基于闪存(主要是NAND Flash)的固态存储设备具有速度快、延时低、功耗低、抗震、体积小[1]等优点,无论是在消费领域,企业数据中心,或是在移动领域(如eMMC、UFS等)都得到了广泛的使用。在存储设备内部,需要维护一张逻辑地址到闪存物理地址的映射表,该表大小约为存储容量的千分之一。过去,固态存储设备都配备相应大小的DRAM来存放该映射表,设备在处理主机读取命令时,通过访问DRAM快速获取该数据块在闪存的物理位置,从而能够快速获取用户数据。但在一些固态存储设备(如消费级固态硬盘、移动存储设备)中,出于成本和功耗考虑,没有配备DRAM存储映射表,有限的SRAM限制了无DRAM设备的随机读取性能,因为设备首先需要访问闪存以获取映射关系,然后再根据该映射关系从闪存中读取用户数据。本文注意到现在的主机端DRAM资源充足,因此提出把设备端的映射表存放到主机端,采用主机和设备协作的方式,实现一种快速随机读取算法,来提升主机随机读取设备的性能。
1 FTL
SSD的存储介质一般是闪存,闪存有其自身的一些特点,如写前擦除、擦除/写入次数有限、读取次数有限等。写前擦除特性不允许数据覆盖更新,当一个逻辑页面被重写时,设备会分配一个新的可用闪存页,将新的数据写入其中,并通过FTL(Flash Translation Layer)软件层来维护逻辑页到闪存页的映射关系。管理逻辑地址到物理地址(Logical address To Physical address, L2P)的映射是FTL最基本的功能。除此之外,FTL还针对闪存特性,实现了其他算法,如垃圾回收(Garbage Collection)、磨损均衡(Wear Leveling)等算法。
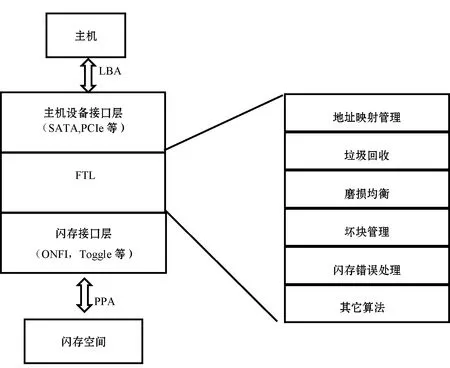
图1 FTL在固态存储设备中的位置和作用
在存储设备内部,FTL起着承上启下的作用,其处理来自主机的读写请求,然后把这些读写请求转换成对闪存的访问请求。另外FTL实现了一些和闪存特性相关的算法,诸如垃圾回收、磨损均衡、读干扰处理、数据保持处理等算法,来克服闪存的一些特性或者说是缺点。FTL算法的好坏直接影响着固态存储设备的性能、可靠性等关键指标。
FTL最原始和最基本的作用是管理逻辑地址(Logical Block Address,LBA)到物理地址(Physical Page Address,PPA)的映射,映射方案有块映射(Block Mapping)、页映射(Page Mapping)和混合映射(Hybrid Mapping)。块映射的优点是映射表小,占用存储设备存储资源(RAM)少,但其最大缺点是随机写入性能差;页映射的优点是性能好,缺点是映射表庞大,需占用很多RAM(一般为存储容量的千分之一,即1 TB的存储设备需要1 GB的内存来存放映射表)。混合映射则是介于两者之间的一种映射算法,典型的混合映射算法有BAST[2]、FAST[3]、LAST[4]、SuperBlock FTL[5]等。由于页映射性能好的优点,现在业界主流固态硬盘的映射算法采用页映射方案。
2 DFTL
基于页映射的FTL具有好的读写性能,但是其映射表庞大,对性能要求高的固态硬盘,一般都配有大容量的DRAM来存放映射表。对读写I/O来说,由于整个映射表都存储在DRAM中,固件可以快速地获取读写所需的映射关系,读取或者更新映射关系都很迅速(只需访问DRAM),因此其读写性能很好。
然而在一些对成本或功耗很敏感的固态硬盘中,存储设备没有DRAM,只配有少量的SRAM。如何在无DRAM的固态硬盘中实现页映射的FTL,国内外有很多研究。
Gupta等[6]注意到主机访问设备的时间局部性(temporal locality),提出了DFTL。其基本思想是把整个映射表按页管理,全局翻译目录(Global Translation Directory, GTD)用以存储这些映射页在闪存中的物理地址,而映射页按需加载到缓存中(Cached Mapping Table, CMT)。对读写I/O来说,它首先在CMT中查找映射关系,如果命中缓存,则直接根据该映射关系读取闪存获得用户数据;如果没有命中缓存,则查找GTD,找到所需映射页的物理地址,然后从闪存中读取映射页到缓存中,最后固件根据该映射关系获得用户数据。
DFTL的顺序读取性能很好,因为一个映射页加载到缓存中后,对接下来的很多笔读取,都能发生缓存命中,无须访问闪存便能获得该逻辑地址对应的物理地址。但对随机读取来说,因为页缓存大小有限,对每笔读取来说,发生映射页缓存的概率很小,因此很多时候它都需要访问两次闪存才能最终获得用户数据。举例来说,一个128 GB的固态硬盘,整个映射表大小为128 MB,由于SRAM大小受限,映射页缓存大小可能只有512 KB,因此发生页映射缓存命中的概率不到1%,意味着99%的读命令需要访问两次闪存才能获得数据。
为在有限的页缓存条件下提高缓存的命中率,在DFTL的基础上,Wei等[7]提出WAFTL,其思想是根据主机的读写负荷,对顺序写入的数据,采用块映射,而对随机写入的数据,采用页映射。这种方式能减小整个映射表大小,对同样大小的映射页缓存,缓存命中率会有一定的提升。
DFTL利用了主机访问设备的时间局部性,Xu等[8]同时注意到主机访问设备的空间局部性,提出了CAST FTL,其基本思想是压缩顺序写入的数据的映射表,达到减小映射表大小的目的,从而提升页映射缓存命中率。
WAFTL和CAST对顺序写入的数据,能提升读取速度,但是如果数据本来就是随机写入的,则随机性能并不能得到提升。
无论是DFTL还是CAST和WAFTL,其读取性能,尤其是随机读取性能,都不如带DRAM 的固态硬盘,因为带DRAM的固态硬盘只需访问一次闪存便能获得用户数据,而不带DRAM的固态硬盘在大多数时候都是需要访问两次闪存的(第一次访问闪存获得映射关系,第二次读取闪存获得用户数据)。
3 新的固态存储架构
自带DRAM的存储设备的性能好,但是成本和功耗高;不带DRAM的存储设备的成本和功耗低,但是性能不足。无论DFTL、WAFTL或CAST FTL,都没有从根本上解决无DRAM固态硬盘随机读取性能差的问题。
本文注意到当前主流的主机设备DRAM丰富,无论是台式机,还是移动设备,内存资源充足,因此提出了一种新的映射表存储架构,如图2所示。利用主机端的内存资源,把映射关系存放到主机端,通过主机和设备协作的方式来提升不带DRAM的存储设备的随机读取性能,解决了存储设备性能和成本、功耗之间的矛盾。

图2 映射表存储在主机端的存储架构
在这个架构的基础上,本文设计实现了一种改善随机存储性能的算法,称为快速随机读取算法(Fast Random Read Algorithm,FRRA)。该算法只需更改主机端驱动和设备端固件算法,无须修改硬件,只需牺牲主机端部分内存来换取快速的随机读取性能。
4 快速随机读取算法(FRRA)设计
4.1 相关定义
映射条目(Mapping Entry,ME):每个LBA在闪存中的物理地址,一般为4字节大小。
映射页(Mapping Page,MP):若干个连续LBA在闪存中的物理地址集合,如连续1 024个LBA的映射关系集合,则映射页大小为4 KB。它是设备管理映射数据的基本单位。本文假设映射页大小为4 KB。
全局映射表(Global Mapping Table,GMT):整个存储设备逻辑空间的映射集合。如一个存储设备容量为128 GB,一共128 GB/4 KB=32 M个LBA,每个LBA的物理地址为4字节,则全局映射表大小为32 M×4 B=128 MB。
主机端映射缓存空间(Host Mapping Cache,H_MC):主机端分配的内存空间,专门用以缓存映射页。其大小取决于存储设备大小和主机端可用的内存空间。它可以存储整个全局映射表,也可以缓存部分映射表。
主机端缓存映射页(Host Caching Mapping Page,H_CMP):缓存在主机端的映射页。
主机端缓存映射位图(Host Caching Mapping Bitmap,H_CMB):主机端的一个位图,每个LBA对应一个比特,0表示该LBA的映射关系不在主机端映射缓存空间,或者在映射缓存空间的物理地址不是最新的;1表示该LBA的映射关系在主机端映射缓存空间并是最新的。比如存储设备容量为128 GB,一共128 GB/4 KB=32 M个LBA,每个LBA占用1个比特,主机端总共需要32 MB/8=4 MB空间存储该位图。
主机端缓存映射页有效数据表(Host Caching Mapping Page Valid Count,H_PVC):主机端对每个缓存映射页,都记录了该映射页的有效映射条目的个数。当某个映射页加载到主机端映射缓存空间时,有效映射条目为1 024个,如果其中某个LBA之后被写过,则有效条目减1。当某个缓存映射页的有效条目数减少到一定阈值的时候,主机应该从设备重新加载该缓存映射页。
设备端缓存映射位图(Device Caching Mapping Bitmap,D_CMB):设备端的一个位图,每个映射页对应一个比特,0表示该映射页中至少有一个LBA对应的物理地址是过时的,或者是无效的;1表示该映射页中所有的LBA对应的物理地址都是最新的。
2个定制的主机命令如下:
1)读映射表命令(Read Mapping Table Command,RMTC)。主机通过RMTC加载映射表到主机映射缓存。RMTC中有两个参数:起始LBA和结束LBA,LBA为1 024的整数倍。
2)快速随机读命令(Fast Random Read Command,FRRC)。主机通过FRRC命令读取映射关系在主机映射缓存中的4 KB数据。FRRC命令中不仅带有LBA的信息,同时还带有该LBA对应的物理地址信息。
4.2 初始化
设备上电时,主机通过RMTC命令加载全部或者部分映射页到主机缓存空间。图3为以128 GB存储设备为例,主机加载全部128 MB映射关系到主机缓存空间。

图3 用RMTC命令加载128 MB映射表的例子
主机端:当128 MB映射数据加载到映射缓存空间后,初始化H_CMB为全1,即所有LBA的映射关系都是有效的,同时还需初始化所有H_PVC为1 024。
设备端:设备端接收到RMTC命令后,把所需的映射关系从闪存中读出,然后返回给主机,并初始化D_CMB为全1,即所有的映射页都是有效的。
4.3 主机读取操作
当主机需要读取一个LBA(4 KB)数据时,主机查询H_CMB,如果对应的比特为1,则向设备发送FRRC,即快速随机读命令;否则只发送普通的4 KB读命令,如图4所示。
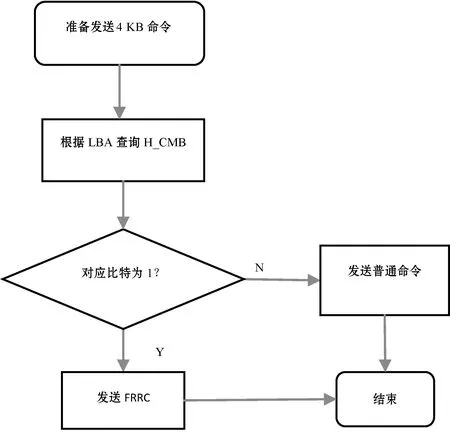
图4 主机根据H_CMB发送不同的读取命令
设备接收到的如果是普通的4 KB读命令,则先做地址翻译,即查询该LBA对应的物理地址,根据该物理地址从闪存中读取数据,然后返回给主机。由于设备内部缓存空间有限,所以该LBA对应的映射页很大概率不在缓存中,所以对每次读,大概率需要先从闪存中加载映射页,然后再根据映射页得到的物理地址,从闪存中获得主机所需的用户数据,即一次普通的4 KB随机读,需要访问两次闪存。
如果设备接收到的是FRRC,即快速随机读命令,其不仅带有LBA信息,还带有该LBA对应的物理地址,相当于主机已经帮设备做好LBA的翻译工作,则设备可以根据该物理地址直接从闪存中读取数据,大大改善了随机读的速度。
但由于设备内部存在垃圾回收算法,用户数据会从一个物理闪存块搬到另外一个物理闪存块,因此设备接收到FRRC之前,还需要检验该物理地址是否有效。设备通过查询D_CMB,如果该LBA所在的映射页对应的比特为0,表明该映射页中至少有一个LBA被内部垃圾回收搬走,由于不确定是否为该LBA,因此设备简单地认为FRRC中的物理地址是无效的,所以设备需要自己重新做LBA地址翻译,行为和处理普通读命令一样;如果查询该LBA所在的映射页对应的比特为1,则表明FRRC的物理地址是有效的,设备可以直接拿它来获取用户数据。图5为设备端处理命令的流程图。
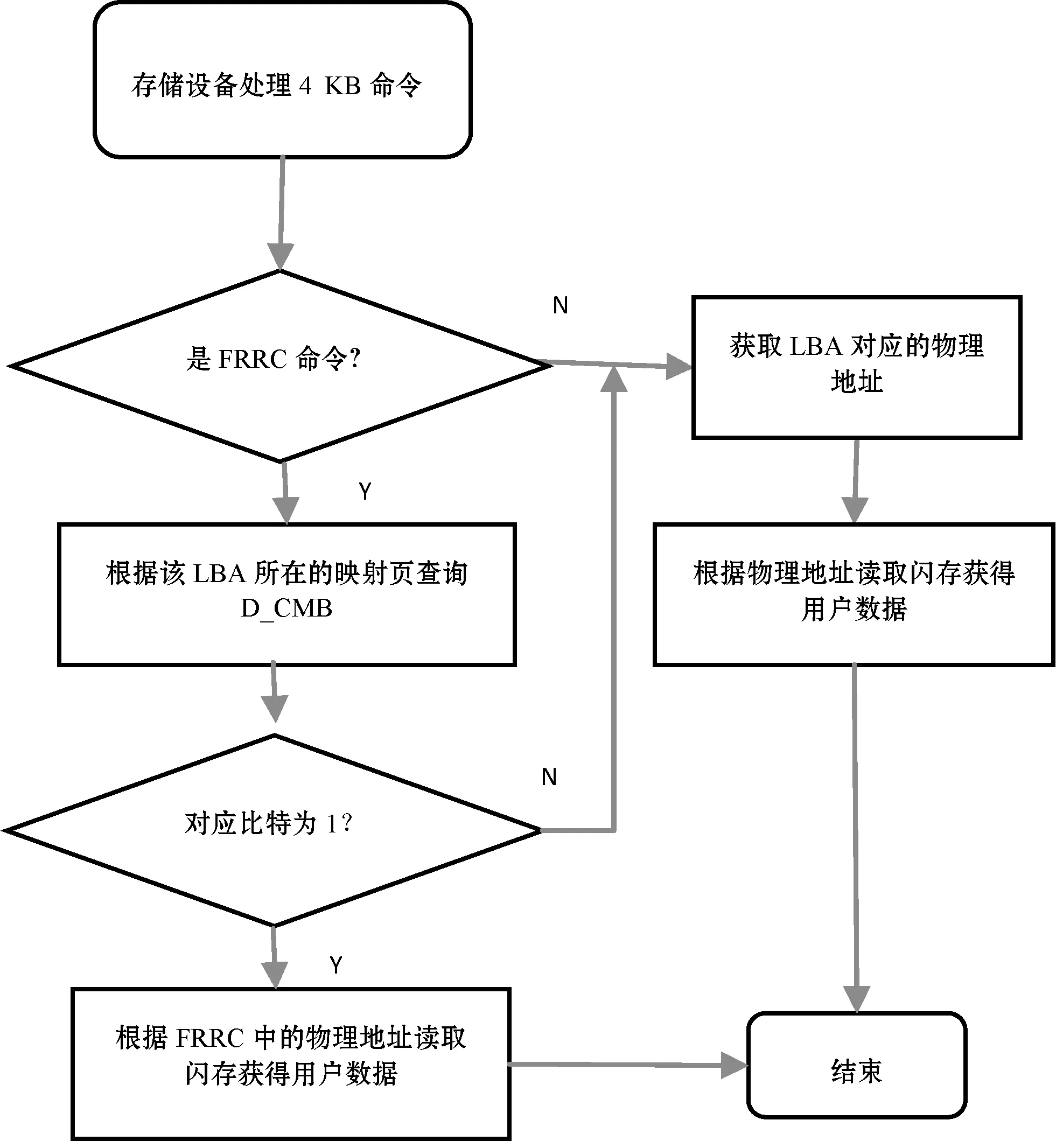
图5 设备端处理读命令
4.4 主机写入操作
主机写入数据时,设备会把这些数据写到空闲的闪存空间。如果这些数据的映射关系缓存在主机内存,由于设备把这些数据写到新的地方,主机缓存的映射关系变成无效的(或者过时的),主机清除H_CMB相应的比特。主机在读取的时候,不再使用该映射关系来发送FRRC。同时,如果某个LBA被主机写入,该LBA对应的映射页有效数据H_PVC应该减1。当某个映射页的H_PVC减到一定阈值,即该缓存映射页绝大多数映射关系都是无效时,主机在空闲的时候,应该再次从设备加载最新的映射关系。主机端处理写操作如图6所示。
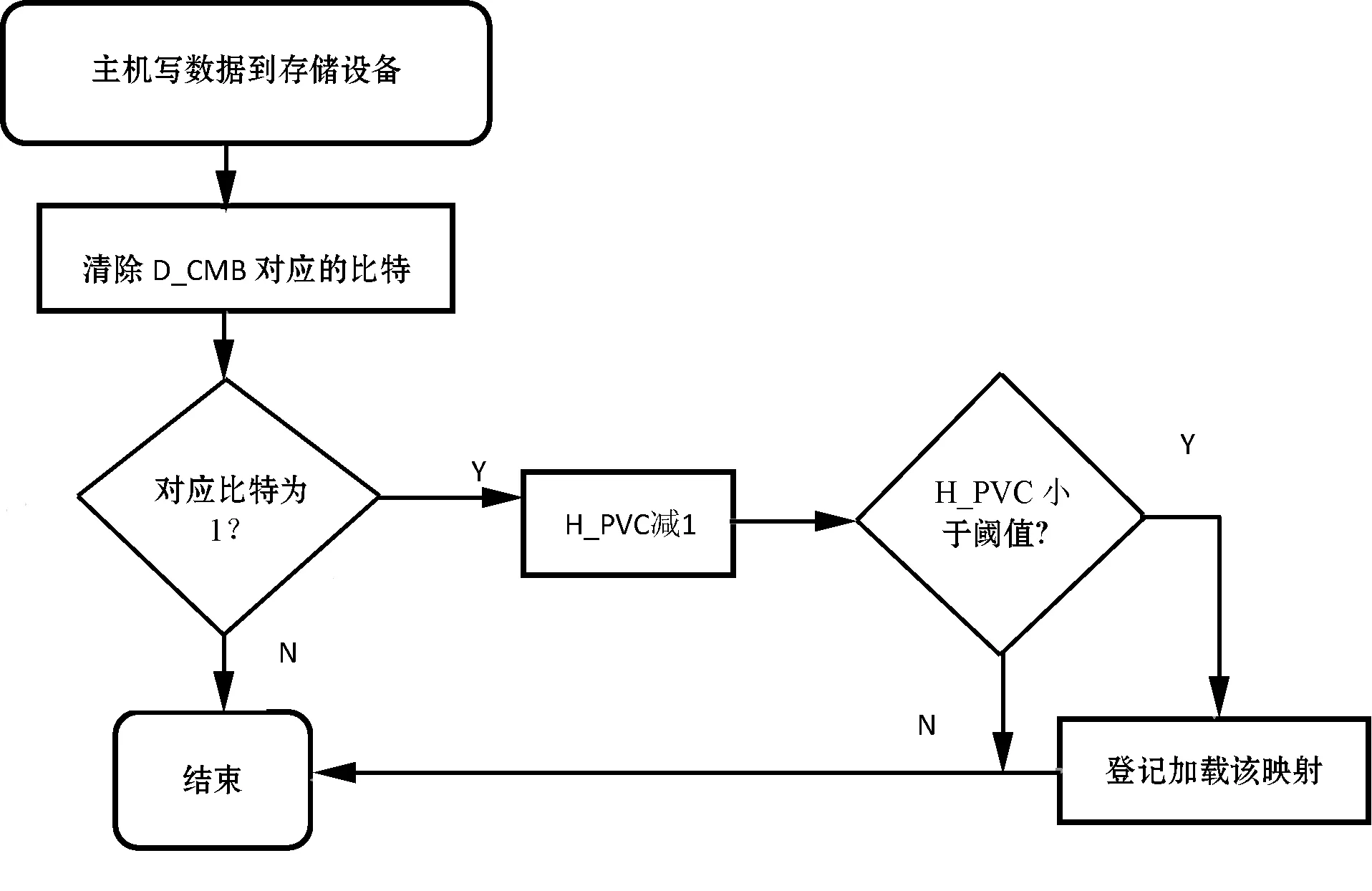
图6 主机端处理写操作
4.5 垃圾回收写入操作
基于闪存的存储设备,内部需要垃圾回收来释放闪存空间。垃圾回收会把用户有效数据从一个物理块重写到另外一个物理块,用户数据映射关系会在主机没有感知下发生变化,即缓存在主机端的映射页除了因为主机写之外,垃圾回收也会导致主机端缓存的映射关系无效。
垃圾回收重写应该更新设备端的D_CMB,具体来说,某个LBA被垃圾回收重写,如果其对应的映射页缓存在主机端,则把该映射页对应的D_CMB比特清零,该过程如图7所示。设备在接收到FRRC命令时,根据LBA对应的映射页查询D_CMB。如果对应的比特为0,则FRRC中的物理地址不可信,需要重写做LBA地址翻译;如果对应的比特为1,则FRRC中的物理地址是有效的,设备无需LBA地址翻译。
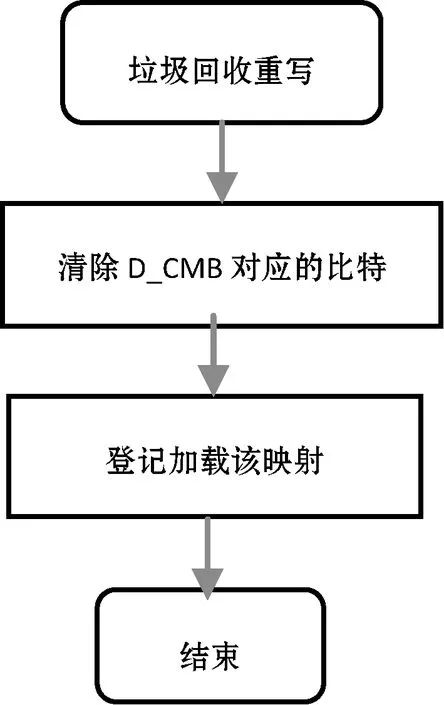
图7 垃圾回收操作需清除D_CMB相应比特
4.6 重新加载映射页到主机缓存
随着主机端数据的写入,缓存的映射页很多映射关系会无效,主机在写入时会登记哪些映射页需要重写加载以提升FRRC命令占的比例。当主机空闲时,主机可以发送RMTC命令给设备,让设备重新上传最新的映射页。
另外,垃圾回收也会导致缓冲页无效,它也会在做垃圾回收的时候登记哪些映射页需要重新加载。主机在空闲的时候,可以查询设备状态,获取这些登记信息,然后发送相应的RMTC命令重新加载映射页到主机缓存。加载新的映射页到主机缓存,需要更新相应的H_CMB、D_CMB和H_PVC。
5 实验结果
本文使用FlashSIM[9]仿真软件来测试FRRA算法性能。FlashSIM是一款开源的SSD模拟器,也是一款事件驱动的、模块化的基于C++的模拟器,内置了多种FTL策略,能够提供响应时间、能耗的模拟和许多额外的统计信息。本文在模拟器上实现了FRRA算法,同时通过修改主机端驱动程序来支持FRRA。
设备端:本文使用FlashSIM模拟128 GB存储设备,该存储设备由4个32 GB的Flash组成,每个通道上挂一个Die。表1为存储设备的配置信息。

表1 存储设备配置
本文使用DFTL算法,在此基础上增加了对RMTC和FRRC两个定制命令的处理,以及相应的FRRA算法实现。
主机端:分配128 MB内存,可以容纳全部的128 GB容量对应的映射页数据。增加了两个RMTC和FRRC命令,分别用以加载映射页到缓存和发送快速随机读取命令。
测试步骤:1)顺序写满盘,测试带DRAM SSD的4 KB随机读取性能,以及不带DRAM SSD不同算法下的4 KB随机读取性能;2)随机写满盘,测试带DRAM SSD的4 KB随机读取性能,以及不带DRAM SSD不同算法下的4 KB随机读取性能。
实验结果对比:
1)顺序填满盘后的4 KB随机读取性能对比如图8所示。
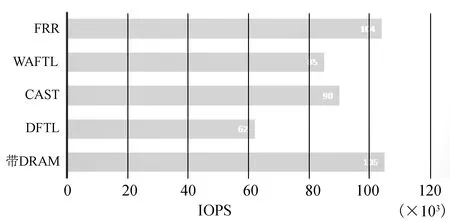
图8 顺序填盘后4 KB随机读取性能对比
2)随机填满盘后的4 KB随机读取性能对比如图9所示。

图9 随机填盘后4 KB随机读取性能对比
顺序填盘后,由于CAST和WAFTL能针对顺序写做优化(减小映射表大小),因此它比DFTL的4 KB随机读取性能好,但是如果是随机数据填盘,WAFTL和CAST并没有体现出性能优势。可以看出,利用主机端DRAM存储映射表的FRR算法,与带DRAM的SSD具有差不多的性能,其性能几乎为DFTL性能的两倍,因为它们访问一次闪存便能获得用户数据。
6 结 语
无论是DFTL、CAST FTL和WAFTL等基于页映射的FTL算法,都不能从根本上解决不带DRAM的固态硬盘随机读取性能差的问题。FRRA通过利用主机端充足的DRAM资源来存储设备的映射表,使用主机和存储设备协同合作的方式,主机读取命令中不仅携带了逻辑块地址,还包括该数据块在闪存中的物理地址,因此设备端省去了逻辑地址到物理地址的翻译工作。故FRRA能显著改善不带DRAM的存储设备的随机读取性能,并且其实现简单,只需软件层面的修改,无须改动硬件和修改接口协议。同时,它也不受当前协议限制,可以在当前几乎所有的接口协议上实现,比如PCIe、SATA、UFS和eMMC等。
猜你喜欢
消费电子(2022年6期)2022-08-25
核安全(2022年2期)2022-05-05
中国饲料(2022年5期)2022-04-26
电脑爱好者(2021年18期)2021-09-23
红领巾·探索(2020年8期)2020-10-26
人大建设(2020年2期)2020-07-27
电脑爱好者(2016年22期)2016-12-16
电脑知识与技术(2016年13期)2016-06-29
科技与创新(2016年9期)2016-05-28
小雪花·成长指南(2014年12期)2014-12-26
