
基于机器学习的疾病诊断模型研究∗
2020-10-09 02:47方丽华王庆玮张万义
计算机与数字工程 2020年7期
张 千 方丽华 王庆玮 孙 晓 梁 鸿 张万义
(1.中国石油大学(华东)计算机与通信工程学院 青岛 266580)
(2.中石化胜利石油管理局胜利医院老年病医院 东营 257091)
1 引言
医疗疾病诊断模型是一种应用相对普遍的监督分类方法。该模型依托于机器学习自身所拥有的能够自动学习这一能力,把相关技术应用到医疗疾病诊断模型之中,由此而形成的机器诊断方法不仅诊断效率高,并且具有良好的鲁棒性。医疗领域中对于疾病诊断的整个过程,实际上就是在高维变量中进行数据的筛选,选择出相对比较重要的相关特征,从而能够辅助医生进行某种疾病的诊断。在进行分析的时候还需要对该病给患者带来的危险进行预测,从本质上讲就是使用筛选出的高维的特征变量进行分类的过程。因此国内外很多研究学者在对医疗系统进行分析设计的时候已经将逻辑回归方法应用到其中。例如,田恒宇等[1]在对胆总管结石病因的相关类型进行研究的时候就使用该模型来进行分析。王春辉等[2]建立逻辑回归模型,探讨检测C 反应蛋白、血清淀粉样蛋白A 及降钙素原在感染性疾病鉴别中的诊断价值。陈建设等[3]在对艾滋病的相关情况进行分析的时候使用二分类逻辑回归分析的方法来实现对问题的分析。首先对OR 值的大小进行计算,然后将计算得到的值进行量化,从而依据该值的大小得到不同的症状在进行诊断时的权值大小。喻微等[4]建立一个预测孤立性肺结节恶性可能性的Logistic 回归模型,为临床诊断提供参考。Wang CH 等[5]采用单因素和多因素分析方法对实验室检测结果进行比较分析,建立传染病诊断方法的逻辑回归模型,有助于临床传染病的早期鉴别诊断。Ercan H 等[6]提出了一种基于逻辑回归的模糊推理方法用于对糖尿病的诊断,实验结果显示准确度为81.82%。Manogaran G等[7]基于逻辑回归建立预测模型以便有效地对心脏疾病进行分类,训练和验证样本的准确率分别为81.99%和81.52%。传统模型相较于深度学习训练快速,可以输出特征重要性,具有可解释性,目前相较于深度模型的应用相对广泛。
当前基于此类技术而构建的机器智能诊断模型已经获得了大力的推广与使用,本文结合具体的2 型糖尿病视网膜病变应用,建立了基于逻辑回归的疾病特征分析模型,实验结果获得了2 型糖尿病视网膜病变的重要性特征排序,而且取得了较高的训练准确率和测试准确率,为医务工作者在进行疾病诊断的过程中提供了比较可信的参考数据。
2 Logistic疾病特征分析模型
本文主要以患者信息及其体检信息为依据基于Logistic 回归方法构建疾病特征分析模型,该模型对2 型糖尿病视网膜病变进行了重要相关因素的排序,算法基于python 语言实现。Logistic 回归方法的实验流程如图1所示。

图1 Logistic回归算法实验流程图
实验共分为四大部分,分别为数据的采集、数据归一化(预处理)、分类器训练、测试集检测。
2.1 数据采集
实验从中国人民解放军总医院获取的电子医疗记录包括病人信息表、详细资料表、诊断表、生病体征记录表、生化指标表、糖化指标表、随访表等,大约含有600 万条记录。依据需要选取出2009~2013 年前来此院接受治疗的住院病人的糖尿病诊断、糖化以及生化检查信息,在各类信息中,有3 种数据隶属于独立表格,在对其进行有效整合后能够获得一个具有统计分析价值的数据集。数据整合主要包括下述三个流程:
1)通过第一次诊断信息筛选出2 型糖尿病视网膜病变的病人信息;
2)结合病人就诊ID 和诊断时间从相关检查表中筛选出最新一次病人检查信息;
3)根据现有的诊断信息筛选出具有参考价值的合并症信息。
有关提取的变量信息如表1 所示,获取到了糖尿病视网膜病变(Diabetic Retinopathy,DR)患者的相关资料。为了确保预测的合理性,还从数据集中筛选出不是DR 的患者作为对照样本,来保证DR和非DR 的数据保持1∶1 的比例。最终,创建了适用于此试验的数据集,由DR 患者的相关数据和非DR患者的相关数据所组成。由于获取到的数据存在部分缺失,在2009 年的病人电子病历中包含了尿常规相关体检数据,而其2010~2013 年并不包含尿常规相关体检数据,为了避免相关重要特征的遗漏,本文分别使用两个数据集进行实验,数据集1包括45 个特征向量,共计1000 条数据;数据集2 包括33个特征向量,共计2800条记录数据。

表1 变量信息表
2.2 数据预处理
在诊断系统中,首要步骤就是获取并处理数据,若在此过程中获得了医学领域权威专家的指导,那么所获得的医疗信息往往带有非常关键的特征。若未获得医学权威专家的指导,那么需要通过Brute-Force 方法逐个过滤信息特征,以此获得关联性最强的特征,基于此对问题展开客观详细地说明。但是由此而获取到的数据信息通常包含大量的无用信息或者是不规则的信息,尤其是医疗数据通常会包含高维度、不平衡性等特征,不利于提高系统的处理速度和预测准确率,所以在对数据进行分类之前一定要采取有效的方式对数据实行严格的去噪处理。针对2 型糖尿病视网膜病变数据集,实验前对数据进行了标准化、归一化、缺失值插补等处理。主要使用sklearn 中的preproccessing 库来进行数据的预处理。
2.3 分类器训练
通过相应的指标对分类器的性能进行客观合理的评价,基于训练集而构建的分类模型其性能或许并非最优,一般来讲,其性能和预测效果之间呈正相关联系,即某种模型性能愈佳,在测试集上所获得的预测效果愈理想。所以要选取合理的标准对分类器的性能进行客观合理地评价,其评价标准主要包括误分率、成本、速度以及混淆矩阵等。其中应用相对较为普遍的当属混淆矩阵。
在混淆矩阵中,C0指的是负例样本,C1指的是正例样本,行表示样本被预测的类别,列则表示样本的类别。真反例(TN)主要指的是将归C0所有的例子予以科学分类的数目,假正例(FP)则指的是将归C0所有的样本划分至C1的数目,假反例(FN)指的是将归C1所有的样本划分至C0的数目,真正率(TP)指的是将归C1所有的样本进行科学合理分类的数目。如表2 二分类的混淆矩阵所示。

表2 二分类的混淆矩阵
2.4 训练集及测试集检测
1)数据集1,包含45 个特征向量共计1000 条数据。
为了准确地评价该模型的实际效果,先将预处理后的数据进行随机划分为两部分,一部分为训练样本,其占比为70%,另一部分为测试样本占比30%。由此构建成训练集和测试集,使用训练集创建诊断模型,使用测试集评估模型效果。
特征工程中需要把年龄离散化成十的倍数,但是由于本实验所使用的数据集中年龄的取值较多,所以依旧当做数值型。性别取值为0或1,男或女,可以当做类别型变量。类别性变量还有尿胆原定性试验、尿胆红素定性试验、尿糖定性试验、尿液颜色尿液亚硝酸盐试验、尿浊度、尿酮体试验、尿蛋白定性试验等。
2)数据集2,包含33 个特征向量共计2800 条数据。
为了准确评价模型的实际效果,先将预处理后的数据进行随机划分为两部分,一部分为训练样本,占样本总数的3/4,另一部分为测试样本,占样本总数的1/4。由此构建成训练集和测试集,使用训练集创建诊断模型,最后用测试集来评估模型效果。
3 实验结果分析
由于所获取的数据集所带来的限制(除了2009 年以外,2010~2013 年数据都不包含尿常规相关体检数据),为了避免实验结果对2 型糖尿病视网膜病变相关重要特征的遗漏,同时医学领域中尿常规中的部分特征对该病变存在一定的影响,所以实验使用2 个数据集,其中数据集1 包含尿常规相关体检数据,而数据集2 中不包含尿常规相关体检数据。

图2 糖尿病视网膜病变重要特征权重—数据集1
数据集1 比数据集2 共有29 个特征重合,数据集1 与数据集2 不同的特征有16 个,分别为铁.7.32umol.L、不饱和铁结合力.20.62umol.L、尿白细胞.0.36.ul、尿比重测定、尿胆原定性试验.0.0mg.dl、尿胆红素定性试验.0.0mg.dl、尿红细胞.0.27.ul、尿酵母细胞.0.0.ul、尿糖定性试验.0.0mg.dl、尿液结晶、尿液酸碱度测定、尿液颜色、尿液亚硝酸盐试验、尿浊度、尿酮体试验.0.0mg.dl、尿蛋白定性试验.0.0mg.dl。数据集2 与数据集1 不同的特征有4个,分别为:总胆汁酸.0.10umol.L、低密度脂蛋白胆固醇.0.3.4mmol.L、游离钙.1.02.1.6mmol.L 和二氧化碳.20.2.30mmol.L。
针对数据集1,糖尿病视网膜病变主要特征权重如图2所示,权重值保留小数点后两位。
实验结果显示共发现14 项特征对糖尿病并发视网膜的患病产生影响,具体含义如表3所示。

表3 特征参照表
通过观察分析Logistic 回归模型输出的特征权重后,得知尿蛋白、糖化血红蛋白、肌酐、尿素等变量权重较高。因为数据集2 的特征并不包括尿蛋白、尿液颜色、尿浊度等特征,所以本实验中将2009 年的数据集进行了单独的训练,避免遗漏尿常规数据中能够对2 型糖尿病视网膜病变产生影响的重要特征。实验结果显示,尿蛋白作为权重最高的影响因素。
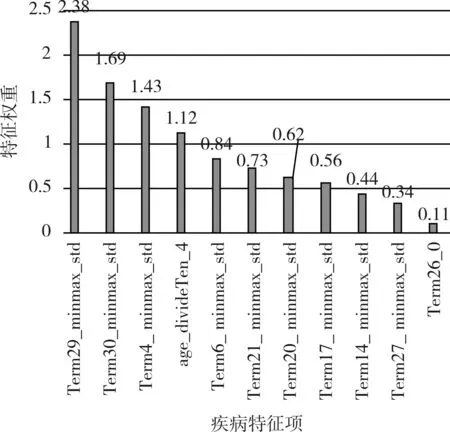
图3 糖尿病视网膜病变重要特征权重-数据集2
针对数据集2,糖尿病并发视网膜病变主要特征权重如图3所示,权重值保留小数点后两位。
实验结果显示共发现11 项特征对是否患有糖尿病并发视网膜病变产生影响,具体含义如表4 所示。

表4 特征参照表
相关研究已证实,2 型糖尿病视网膜病变是在多重因素的共同作用下形成的,比如高血压、性肾病及相关实验室检查指标等。尿蛋白作为慢性肾病的重要特征也在我们实验一中显示具有较高权重。综合两个数据集的实验结果显示,糖化血红蛋白、肌酐、尿素以及年龄等变量权重较高且有临床意义。
综上,本文采用的Logistic 模型结果表明,慢性肾病与糖化血红蛋白浓度是诱发此病发生的直接因素。慢性肾病与糖尿病并发视网膜病变的关联性很清晰,医学专家表示,糖尿病联合视网膜病的发病机理与慢性肾病存在一定相似之处,具体体现在两个方面,一是微血管发生病变,二是微循环出现异常。大量研究结果表明,尿白蛋白是与糖尿病联合视网膜病变高度关联的一个风险因素[9~10]。关于血型与此病变的关联性因素并未展开过多研究,还需后期进一步研究与分析。另外,与此病变具有直接关联的高血压和血脂异常也没有被纳入模型,导致这种情况发生的原因是本实验所使用的数据集中并没有相关数据。
在相同实验环境下进行特征工程与不进行特征工程的Logistic回归模型进行诊断的训练准确率和测试准确率如表5 所示。实验结果显示,进行特征工程后,训练准确率提高约1 个百分点,测试准确率提高3个多百分点。

表5 实验结果
4 结语
依据Logistic 回归的诊断流程,分别从数据的采集、数据的预处理、分类器训练、训练集和测试集的检测以及对实验结果进行分析这几大部分进行概述。由于实验结果显示训练集与测试集诊断准确率都比较高,并没有存在过拟合现象,因此实验所得结论是有效的。实验结果显示糖化血红蛋白、肌酐、尿素、尿酸年龄等变量权重较高且具有临床意义,慢性肾病与糖化血红蛋白浓度作为是否患有2型糖尿病视网膜病变的最主要的因素。
猜你喜欢
现代仪器与医疗(2022年2期)2022-08-11
老友(2022年4期)2022-05-18
人人健康(2021年17期)2021-11-30
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
保健与生活(2019年12期)2019-07-31
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
