
低信噪比环境下语音端点检测技术
2020-09-29 08:08韦莎丽曾庆宁郑展恒
计算机工程与设计 2020年9期
韦莎丽,王 健,曾庆宁,郑展恒
(桂林电子科技大学 信息与通信学院,广西 桂林 541004)
0 引 言
常用的端点检测技术[1,2]有能零法、谱距离法[3]、经验模式分解(empirical mode decomposition, EMD)法[4,5]、相关函数法、方差法、谱熵法[6]等。这些端点检测方法在信噪比较高时检测性能较好,但却不大适用于低信噪比环境[7]。采用简单的去噪方法来增强语音是噪声环境下提高端点检测性能的一种解决方法。常用的减噪方法有维纳滤波法、自适应滤波器和谱减法[1]。近年来,研究学者针对低信噪比下语音端点检测正确率不高的问题开展了大量研究,由EMD分解和多窗谱估计对语音去噪,结合Teager能量算子和过零率进行端点检测[8]。结合谱减法的自适应子带选择的频带方差进行端点检测[9]。把对数能量与自相关函数结合[10],将多窗谱估计和能熵比相结合的检测算法[11],取得较好效果,但复杂度较高。
为解决现有端点检测算法在低信噪比环境下检测正确率不高及稳定性较差的问题,本文先增强语音后结合EMD分解和改进的自相关函数进行双参数双门限端点检测。仿真结果表明,在-10 dB-5 dB的不同噪声环境下能较准确地区分出语音信号的有话段和无话段。
1 语音去噪增强
1.1 调制域
生活中接收到的语音信号几乎都带有噪声。想要获得清晰的语音信号,就得对带噪信号减噪。常用的谱减法、多窗谱估计法、对数最小均方误差法、维纳滤波法等在信噪比较高时去噪效果较好,但在低信噪比时去噪效果往往不太理想[12]。因此,需要找到一种适用于低信噪比环境下的去噪方法。常见的信号处理方法通常是在时域和频域中进行,而随着频率源的广泛应用和调频技术的快速发展,调制域逐渐被应用到语音信号处理中[13]。时域以时间和幅度轴为坐标,频域以频率和幅度为坐标,调制域则以频率和时间轴为坐标,表示频率随时间的变化规律。三者的空间坐标关系如图1所示。

图1 空间坐标
设生活中接收到的信号由纯净语音和加性噪声组成,则带噪语音信号可以表示为
x(n)=s(n)+d(n)
(1)
式中:x(n) 为带噪语音信号,s(n) 为纯净语音信号,d(n) 为噪声信号。带噪信号分帧后,经过短时傅里叶变换(short-time Fourier transform,STFT)得到以极坐标表示的频谱[14]
X(k,ω)=|X(k,ω)|ej∠X(k,ω)
(2)
式中:k为帧数,ω为离散频率, |X(k,ω)|、 ∠X(k,ω) 分别表示信号的幅度谱和相位谱。对幅度谱 |X(k,ω)| 做STFT后得到调制域频谱
X(λ,ω,η)=|X(λ,ω,η)|ej∠X(λ,ω,η)
(3)
式中:λ为调制域的帧数,ω为离散频率,η为调制域的频率, |X(λ,ω,η)| 表示调制域的幅度谱, ∠X(λ,ω,η) 为调制域的相位谱。对调制域幅度谱使用谱减法得到改进的调制幅度谱,如下
(4)
式中:α代表的是过减因子(α≥1),β表示的是增益补偿因子(0<β≤1), |Δ(λ,ω,η)| 表示的是调制域的噪声幅度谱估计,由式(5)更新噪声
|Δ(λ,ω,η)|2=ρ|Δ(λ-1,ω,η)|2+
(1-ρ)|X(λ,ω,η)|2
(5)
式中:ρ表示遗忘因子,由噪声的平稳程度决定,当信号处于噪声段时根据式(5)更新噪声谱。
1.2 调制域相位补偿
目前很多改进的谱减法大都忽略了含噪信号中相位的重要性,只对幅度做出相应的调整。而相关研究表明,调制域相位能从语音信号中获得更多有用信息,处理调制域相位可以进一步抑制音乐噪声,提高语音的质量[14]。
首先,通过噪声的幅度谱估计 |Δ(λ,ω,η)| 计算出相位补偿度数
Λ(λ,ω,η)=μφ(η)|Δ(λ,ω,η)|
(6)
式中:μ为常数,φ(η) 为反对称函数,φ(η) 可表示如下
(7)

(8)
进而得到调制域的相位补偿公式如下
(9)
式中:ARG表示复数的幅角。
(10)
综上可知调制域谱减法的原理如图2所示。

图2 调制域谱减法原理
1.3 去噪仿真实验
为检验调制域谱减法的去噪效果,将其与常见的基本谱减法和多带谱减法进行对比。仿真实验选用noisex-92噪声库中的高斯白噪声、高速行驶的车内噪声(volvo)和战斗机驾驶舱噪声(f16)。噪声采样率为8 KHz,纯净语音的采样率为16 KHz。实验所用信号的信噪比为-8 dB,分帧的帧长设为32 ms,帧移设为8 ms。去噪效果如图3~图5 所示。

图3 高斯白噪声下去噪效果

图4 volvo噪声下去噪效果

图5 f16噪声下去噪效果
由图3~图5显示的对比结果可知,多带谱减法在3种噪声条件下的去噪效果是三者中最差的,尤其是在高斯白噪声条件下,减噪后语音信号依然被噪声淹没,在volvo噪声及f16噪声下去噪后虽然语音没完全被噪声覆盖,但信号中依旧存在大量噪声。3种噪声环境下多带谱减法去噪后仅将信噪比提高了8 dB左右。基本谱减法在高斯白噪声及volvo噪声环境下去噪效果较为理想,比较适用于volvo噪声,但去噪后的信号出现很多毛刺现象,在f16噪声下效果较差,毛刺现象极为严重,语音严重失真。本文采用的调制域谱减法在3种噪声环境下的去噪效果均优于对比的基本谱减法和多带谱减法,尤其适用于volvo噪声环境,可将信噪比提高21 dB。去噪后的信号几乎不存在毛刺现象,并且语音失真情况远远优于基本谱减法和多带谱减法,语音的保持度较好。由此可知,借助调制域谱减法在端点检测的前端对带噪语音信号进行消噪增强,在语音失真度较小的前提下提高信噪比,从而可为后期的端点检测提供良好的语音数据,以望能提高检测性能。
2 语音端点检测
2.1 经验模式分解端点检测
2.1.1 经验模式分解
本征模态函数(intrinsic mode function, imf)由Huang等于1998年提出,同时还提出经验模式分解(empirical mode decom-position, EMD)。EMD的核心是把信号分解成不同的imf分量与一个余项的和,如式(11)所示
(11)
式中:i表示阶数,ci(t) 表示第i阶模式分量,rn(t) 表示原始信号的余项。每个imf代表一个频率成分,表示信号的主要特征,而剩余分量表示信号的缓慢变化[15,16]。我们可以通过分析imf掌握信号的动态信息。部分imf的主要能量成分为噪声分量,研究表明EMD分解的前两阶imf中含有白噪声的75%分量,所以将含较多噪声分量的前两阶imf去除,用余下的分量重新合成语音信号,即可实现对含噪语音信号的初步去噪。EMD分解的主要目的是将复杂信号分解为简单的imf分量集,使得上下包络线更加对称。imf分量要满足的两个条件如下:
(1)在整个序列中,极值点与过零点的数量最多只能相差一个;
(2)在所有时间点上,信号局部极大值和局部极小值所确定的上下包络线的均值必须处处为零[4]。
EMD方法是依据原信号局域时间的某些特性,将信号分解为imf的集合,这些模态函数涵盖了原信号所有不同的频率成分,并随着信号的变化而改变。因此,可从不同的imf分量中获得语音特征信息。在EMD分解后进行端点检测的方法有很多,如EMD分解后计算各阶imf的短时过零率法,EMD后计算imf分量的短时能量法,EMD分解后分别计算每个不同频带的高阶统计量,然后根据系数的峭度变化进行端点检测的方法等。本文主要研究EMD分解后根据Teager能量算子(Teager energy operator, TEO)计算信号能量的端点检测法。
2.1.2 Teager能量算子
Teager能量算子(Teager energy operator, TEO)是由Kaiser提出的一种可获取信号“能量”的算子,具有非线性,可在增强稳定及半稳定信号的同时减弱不稳定信号[16]。而语音信号中的有话部分是稳定或半稳定信号,无话部分是不稳定信号。Teager能量算子能在表征信号幅度变化的同时表征信号的频率变化,对语音具有很好的适用性。
离散时间序列的TEO定义如下
T[xi(m)]=[xi(m)]2-xi(m+1)xi(m-1)
(12)
式中:xi(m) 为语音信号x(n) 加窗分帧后的第i帧信号,N为帧长,m=1,2,…,N。
2.2 自相关函数主副峰比值的端点检测
语音和噪声的一个重大区别在于语音的浊音段呈周期性而大部分噪声没有周期性。信号的自相关函数的周期性通常与原信号相同,且周期也相同。根据这一性质,求取一段含噪语音信号的自相关函数可判别出语音信号和噪声[10]。
语音信号具有短时平稳的特性,对语音信号x(n) 分帧后的第i帧信号设为xi(m), 其帧长设为N, 延时量为k, 则第i帧信号的短时自相关函数为
(13)
定义主峰与最大副峰比值为
(14)
式中:R(0) 为主峰幅值,Rm为最大副峰幅值。
含噪语音信号的有话帧和噪声帧归一化后的自相关函数曲线如图6所示。

图6 有话帧和噪声帧短时自相关函数曲线
由图6可知有话帧和噪声帧的最大幅度值为1,有话帧的最大副峰约为0.3,噪声帧的最大副峰约为0.1,故有话帧的主副峰比值约为3.3,噪声帧的主副峰比值约为10,两者相差很大,可依此判别语音和噪音。
然而,在现实环境中噪声随机性会比较大,含有的高频成分可能比较多,尤其是在低信噪比环境下,自相关函数主副峰比值波形在噪声段易出现起伏不定的情况,从而影响检测结果。因此,仅依靠自相关函数主副峰值比进行端点检测并不可靠,需要做出改进。
2.3 改进的自相关函数端点检测
汉语中含元音的韵母能量较大,而噪声段的能量则很低,故可根据短时能量判别语音和噪音。短时能量由下式计算可得
(15)
则每帧信号的对数能量为
LEi=lg(1+Ei/c)
(16)
式中:c为大于1的常数,此处取c=2。 含噪语音的短时能量和对数能量的曲线如图7所示。

图7 含噪语音的短时能量和对数能量曲线
由图7可知含噪信号的对数能量幅值没有剧烈跳变,对短时能量曲线起一定的平滑作用,并在一定程度上提高及稳定有话段能量的幅度。因此考虑将信号的对数能量运用于端点检测。
一段语音的自相关函数主副峰比值和短时过零率如图8所示。

图8 自相关函数主副峰值比和过零率曲线
根据图8可知自相关函数主副峰比值和短时过零率在噪声段有较大的值,语音段有较小的值,且自相关函数主副峰比值曲线比过零率曲线更加平滑且稳定。端点检测常用的短时能量除以过零率法是根据语音段能量较大,而过零率较小,噪声段则相反的原理用能量值除以过零率可拉大语音和噪声的差距依次判断语音和噪声段。根据这一原理把对数能量除以自相关函数主副峰值比亦可判断出语音和噪声段。二者的曲线如图9所示。
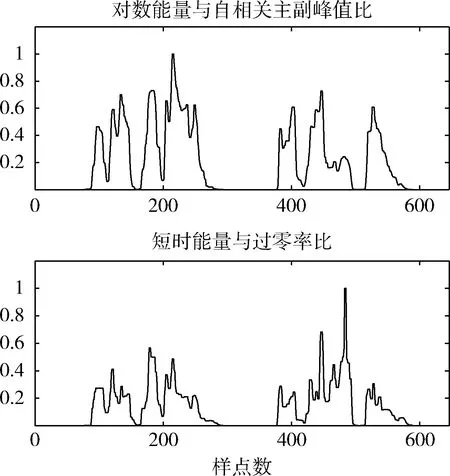
图9 含噪语音的短时能量和对数能量曲线
根据图9可知对数能量除以自相关函数主副峰比值在语音和噪声交界处的曲线更加陡峭,并且幅值更高更稳定,更易区分出语音和噪声。
2.4 TEO结合改进自相关函数端点检测
对于低信噪比环境下检测正确率不高及稳定性较差的问题,需要研究一种新的端点检测方法,能在强噪声的恶劣环境下改善端点检测的性能,提高正确率。对此,本文提出了结合调制域谱减法的基于Teager能量算子和改进自相关函数的端点检测法,具体步骤如下:
(1)对带噪的语音信号通过调制域谱减法去除噪声,提高含噪语音的信噪比。
(2)对去噪后的语音信号进行EMD分解,得到一系列imf分量,用除前2阶外的其它阶imf分量重构语音信号。
(3)对重构后的语音信号进行加窗分帧处理,并对每帧信号进行二次EMD分解,得到一组新的imf分量,由式(14)计算imf分量Teager能量值的均值,根据每帧信号的Teager能量平均值设置端点检测的相应门限阈值。
(4)对步骤(1)中调制域谱减去噪后的语音信号进行加窗分帧处理。
(5)求步骤(4)中每帧信号的对数能量、自相关函数及其主副峰比值,归一化后用对数能量除以相关函数主副峰比值,并依此设置端点检测的另一门限阈值。
(6)依据双参数双门限法进行端点检测。
3 实验结果及分析
在仿真实验中,用M-AUDIO公司的M-TRACK EGIHT音频采集器进行数据采集,录制背景为相对安静的大小为8*5*3立方米的室内环境。实验所用的语音内容为“小白小白,打开音箱”,采样频率为16 kHz。实验所用的噪声采样频率都是8 kHz,采样精度均为16 bit。对语音信号分帧,帧长wlen=512个采样点数,帧移inc=128个采样点数。实验平台选择MATLAB仿真工具。
本文研究低信噪比环境下的语音端点检测算法,针对实际环境中常见的高斯白噪声、volvo车内噪声和f16噪声3种噪声环境进行仿真。分别在5 dB、0 dB、-5 dB、-10 dB 信噪比环境下进行实验。为验证本文算法的可行性,采用两种经典的算法以及两个近两年提出的改进算法与本文的算法进行对比,分别是:①多带谱减法与短时能量-过零率结合法;②基本谱减法结合子带分离频带方差法;③吴进等提出的文献[8]中的EMD和改进谱减法结合的端点检测算法;④陈泽伟等提出的文献[10]的改进自相关函数的端点检测方法。以下所有图中的竖实线的位置表示语音开始点,竖虚线代表结束点。
为了研究不同噪声环境下端点检测的正确率,需要对纯净语音进行检测作为参考。图10表示纯净语音的端点检测结果。

图10 纯净语音端点检测结果
图11是高斯白噪声环境下信噪比为-10 dB的5种算法检测结果。
由以上5幅图可知在高斯白噪声-10 dB信噪比条件下,5种算法的检测效果分析如下:
对比算法1:结合多带谱减的能量-过零率法在低信噪比下出现错检和漏检情况,去噪后的语音信号依然被噪声淹没,“白”、“打”和“音”字被误判为噪声。由于语音信号被噪声覆盖,故短时平均能量和过零率曲线波动平缓,参数的阈值门限不好设置,易出现误判情况。
对比算法2:结合基本谱减法的子带分离频带方差法,端点检测的结果也较好,但是“音”字被误判为噪声,段末的尾音均未被检出。语音强度较弱的部分方差幅值较低且平缓,阈值门限设置困难。
对比算法3:文献[8]的多窗谱估计结合EMD和过零率法,语音基本上能被检测出来,但能量较小的“音”字没完全检出,依然存在语音漏检情况。
对比算法4:文献[10]的改进相关函数检测法把“打”字判成了两个音,而“音”字却并未检测出来,连音部分被分开,且尾音部分被截掉。

图11 高斯白噪声下-10 dB检测结果
本文算法在高斯白噪声-10 dB信噪比条件下由于经过调制域谱减法及EMD分解去噪,提高了信噪比,故端点检测效果较好,只出现轻微的截断尾音现象,这是因为在 -10 dB 信噪比下语音被噪声淹没,尤其是轻音和尾音部分,在使用调制域谱减法对含噪语音进行去噪时把尾音当作噪声也给去掉了。并且在连音部分并未出现间断情况,有话帧在可接受的范围内算是完全被正确检测出来,而对比的4种算法都出现发音较轻的“音”字未被检出。由此可见本文算法在高斯白噪声-10 dB信噪比条件下抗噪性能好,检测正确率高,鲁棒性较好。
本文共对3种噪声环境下的4种信噪比情况进行研究,作为参考对比的算法共有4个,而由于空间版面有限,除高斯白噪声环境下信噪比为-10 dB的5种算法检测结果外,其它情况下检测结果的正确率以折线图的形式给出。图12(a)~图12(c)分别是在高斯白噪声、volvo和f16噪声环境下5种检测算法的正确率折线图。横坐标表示信噪比,纵坐标表示端点检测的正确率,其中正确率计算方式如下

式中:误判帧数包括噪声帧检测为语音帧和语音帧检测为噪声帧。

图12 不同噪声环境下的检测正确率
从图12可以看出,5种算法在不同噪声环境下随着信噪比的不断提高,检测正确率都呈现上升趋势。结合多带谱减的能量-过零率法及结合基本谱减法的子带分离频带方差法在3种噪声低信噪比环境下的端点检测正确率均不理想,特别是结合多带谱减的能-零法在高斯白噪声和f16噪声信噪比低于-5 dB区域的正确率严重下降。这是因为在低信噪比下,语音中含有很多反复穿过坐标轴的噪声,产生了大量的虚假过零率,造成严重的端点误判,导致检测正确率极低。文献[8]方法在volvo噪声和高斯白噪声条件下检测正确率较高,尤其适用于volvo噪声环境。但在f16噪声下正确率较低,这说明该方法的适用性不够强。文献[10]方法在高斯白噪声和f16噪声环境下检测性能较好,在信噪比高于-5 dB区域检测正确率较高,但在volvo噪声环境下检测性能呈直线下降趋势。可见该方法不适用于volvo噪声环境。本文提出的端点检测算法在高斯白噪声、volvo、f16这3种噪声环境下,检测的正确率明显高于4种对比的算法。本文算法结合了文献[8]和文献[10]算法的优点,在高斯白噪声和volvo噪声环境下检测的正确率都很高,在f16噪声环境下虽然整体正确率低于另外两种噪声环境,但其依然明显高于对比的4种算法,本文算法的检测正确率随着信噪比的减少稍有降低,而对比的4种算法的正确率却大幅度下降。本文算法除了在f16噪声信噪比低于-5 dB区域检测正确率低于90%,其它情况下正确率均高于90%。这说明本文算法在低信噪比环境下检测效果优于对比的两种传统方法和近两年提出的两种新端点检测法,对噪声环境的适应性较强,抗噪性能较好,并具有良好的鲁棒性。
4 结束语
本文通过对Teager能量算子、对数能量和自相关函数的研究,提出了一种借助调制域谱减法去噪后进行EMD分解并计算其TEO能量,再结合改进自相关函数的端点检测方法。该方法在端点检测前端对带噪信号进行减噪,为后续的检测创造良好的数据条件,以便能更加准确地提取信号特征。最后结合TEO能量算子和改进相关函数利用双门限法对信号进行端点检测。实验结果证明,本文算法在不同类型的低信噪比环境下能有效提高含噪语音端点检测的质量,降低误识和漏识率,具有一定的抗噪性和稳定性,适用范围更广。但是,由于本文算法加入调制域谱减算法,并进行EMD分解重构再结合改进的相关函数法,增加了算法的计算复杂度,相较于单个算法运行时间较久,并且在实际环境中背景噪声的随机性大,如何在保持算法的准确度的前提下缩短运行时间并使其能适应混合复杂噪声环境将是以后研究的重点。
猜你喜欢
数学物理学报(2022年2期)2022-04-26
现代仪器与医疗(2022年1期)2022-04-19
中华养生保健(2020年7期)2020-11-16
北京航空航天大学学报(2019年9期)2019-10-26
中学生数理化·教与学(2019年8期)2019-09-18
雷达学报(2017年3期)2018-01-19
家教世界·创新阅读(2016年11期)2016-12-27
天津护理(2016年3期)2016-12-01
故事会(2016年15期)2016-08-23
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
