
基于嵌入式GPU的红外弱小目标检测算法
2020-09-29 03:09
应用光学 2020年5期
(西安应用光学研究所,陕西 西安 710065)
引言
红外弱小目标检测技术作为红外搜跟系统、红外预警系统、精确制导系统中的关键技术,一直是国内外红外图像处理领域的研究热点[1]。尽可能提高目标的检测距离,可以为打击对抗等措施赢得时间。但红外目标的成像面积小,对比度低,背景复杂,难以准确检测;红外成像帧频高、数据量大,难以实时处理[2]。
近年来,随着GPU(graphics processing unit,图像处理器)应用技术的不断发展,具有强大并行能力的GPU 越来越多地被应用于高性能计算需求领域[3]。针对红外弱小目标检测算法对每个像素点独立处理,适合于GPU 并行计算的特点,本文提出了基于嵌入式GPU的红外弱小目标检测算法。由于应用系统对处理器功耗体积要求较高,因此选择采用英伟达Jetson TX2 嵌入式GPU 作为边缘计算平台进行并行优化。实验结果表明,对640×480像素分辨率的红外视频,并行优化后的目标检测算法能够在10 ms 内完成计算,满足实时处理需求。
1 红外弱小目标检测算法
在红外成像过程中,由于受到大气散射、光学散焦等因素的影响,红外弱小目标在图像中一般表现为斑点状,其面积一般不大于9×9像素[4-5],空间灰度分布表现为中心最亮,且向四周辐射,与二维高斯函数非常相似[6]。
红外弱小目标检测算法可以分为单帧检测和多帧检测两类[7]。由于许多应用场景中存在目标与成像传感器之间的相对运动,不利于多帧检测轨迹关联,因此单帧检测已成为红外弱小目标检测算法的主要研究方向之一[8-9]。
1.1 LCM算法
基于单帧图像的红外目标检测算法,主要利用目标与背景之间的灰度、结构等特征差异进行检测。根据弱小目标的灰度强于邻域灰度的特征,Chen 等[10]基于视觉对比机制提出了一种局部对比测量方法(local contrast measure,LCM)。此后,许多学者对该方法进行了研究和改进[11],其中基于高斯尺度空间的增强型LCM算法[12]目检效果显著。LCM算法在计算局部对比度时,多使用的是比率形式定义。具体方法为通过计算图像中某局部中心与邻域之间的比率,得出目标响应值。LCM算法示意如图1所示。
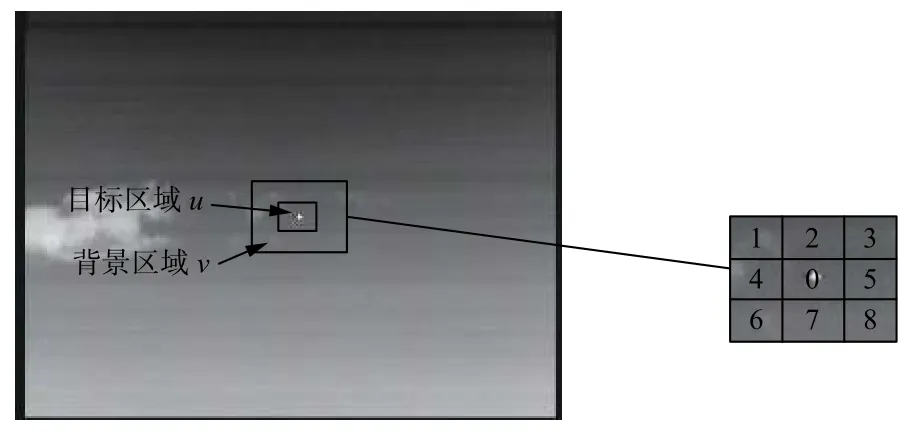
图1 LCM算法示意图Fig.1 Schematic of LCM algorithm
图1中,u对应于目标区域,v对应于目标邻域的局部背景。将窗口在图像上依次从左向右、从上到下滑动,截取图像块。对图像块进行九等分,中心图像块即为目标区域,记为“0”,邻域图像块分别记为“1”~“8”,代表中心块的八邻域。
首先计算出邻域每个子图像块的均值mi,可以由(1)式表示:

式中:i取值为1,2,…,8;N表示一个图像块中的像素个数;表示第i个邻域块内第j个像素的灰度值。
中心块与八个邻域块的响应值C可以表示为

其中L为中心块像素的最大值,即

C 即为目标响应值,当 C大于阈值时,中心区域即为目标。
1.2 零均值高斯核简介
LCM算法在信噪比较高的红外图像中取得了较好效果,但是当红外图像中存在高亮点噪声时,容易引起虚警。借鉴于LCM算子,本文在算子设计时考虑尽可能采用卷积核实现,不仅便于快速运算,而且可以消除随机噪声影响,还能与弱小目标形成最大响应。为此,设计了零均值高斯核(zero-mean Gaussian kernel)算子来替代LCM算子,通过一次高斯核卷积来求解目标响应值。零均值高斯核算子示意如图2所示。

图2 零均值高斯核卷积滤波示意图Fig.2 Schematic of zero-mean Gaussian kernel convolution filtering
零均值高斯核是在标准高斯核的基础上,减去其平均值,得到一个积分为零的高斯核。这种高斯核不仅保留了原有高斯函数特性,还具备了与高斯差分算子(DoG)相似的差分特性。所不同的是,零均值高斯核减小了过渡区域的权重,在中心位置和最远端具有最大权重,更容易使目标与背景形成最大响应。零均值高斯核卷积滤波的具体计算流程为:设定图像块区域包含9×9个像素,对图像块区域计算零均值高斯滤波,得到目标响应值C。由(4)式表示:
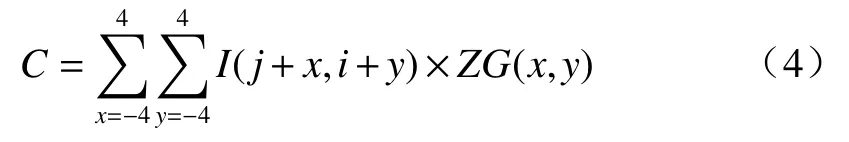
式中:I(j,i)表示像素坐标点(j,i)的灰度值;零均值高斯核ZG(x,y)由(5)式表示:

其中σL为高斯核的标准差。遍历整幅图像中所有像素,即可得到与原图相对应的局部对比度图像C。
1.3 零均值高斯核分析
与LCM算法相比,零均值高斯核的改进主要体现在以下几个方面:
1) 将图像去噪、目标信号增强和目标背景差分,在一次卷积运算中完成;
2) 去掉了对区域的强制九等分,邻域块之间过渡更加平滑,降低了高斯核标准差对目标尺度变化的敏感性;
3) 去掉了求局部极值,采用高斯核滤波,便于GPU 快速运算,有利于简化计算和工程应用;
4) 零均值高斯核更加符合目标灰度分布特征,目标响应值更显著,能够抑制云层干扰。
很多LCM改进算法,均采用高斯差分算子(DoG)算子或拉普拉斯算子(LoG)来计算目标响应,其滤波核剖面曲线与零均值高斯核对比如图3所示。

图3 DoG/LoG 算子与零均值高斯核剖面图Fig.3 DoG/LoG operator and zero-mean Gaussian kernel profile
这两类算子的均值都为零,属于差分算子。所不同的是零均值高斯核中,背景像素与中心位置距离越远,其权重越大,这一点和DoG/LoG 算子正好相反。带来的好处是对目标尺寸大小不敏感,真实目标比滤波核稍大或稍小,不会引起目标滤波后响应值的剧烈变化。而DoG/LoG 算子由于将背景主要取在目标边缘处,对目标尺寸较为敏感,目标稍大时会引起响应值急剧下降,因此常需采用多尺度空间的方式来解决,但随之也增大了计算量。零均值高斯核也存在不足之处,主要是会保留屋脊状强边缘。后续还需要进行非极大值抑制和目标判断,才能检测出真实目标。
2 基于嵌入式GPU的目标检测算法实现
从零均值高斯卷积计算过程可以看出,该方法是一种像素级操作,通过每个像素点的卷积运算,来凸显弱小目标并抑制背景。为满足算力需求,本文采用NVIDIA的Jetson TX2平台实现。
2.1 平台架构
Jetson TX2平台体积小巧,集成度高,性能强大。TX2平台核心是Tergra Parker SOC 芯片,芯片架构如图4所示。该芯片为ARM+GPU 架构,CPU部分由双核Denver2 64位CPU和四核ARM A57共同组成,GPU 则采用Pascal 架构,由两个SM(stream mulitprocessor,流多处理器)组成,每个SM有128个CUDA(compute unified device architecture,统一计算机设备架构)核心,浮点计算能力为1.5TeraFLOPS[13]。除此之外,还有8 GB DDR4 内存和丰富的外围接口,非常适合低能耗和高计算性能的应用场景,因此选择该平台来设计实现实时目标检测系统,并基于该平台GPU 结构及特性设计优化目标检测算法。

图4 Tergra Parker 芯片架构Fig.4 Tergra Parker chip architecture
2.2 目标检测算法程序设计
为充分利用TX2平台的ARM+GPU,本文将算法拆分为ARM端和GPU端并行处理,程序流程图如图5所示。
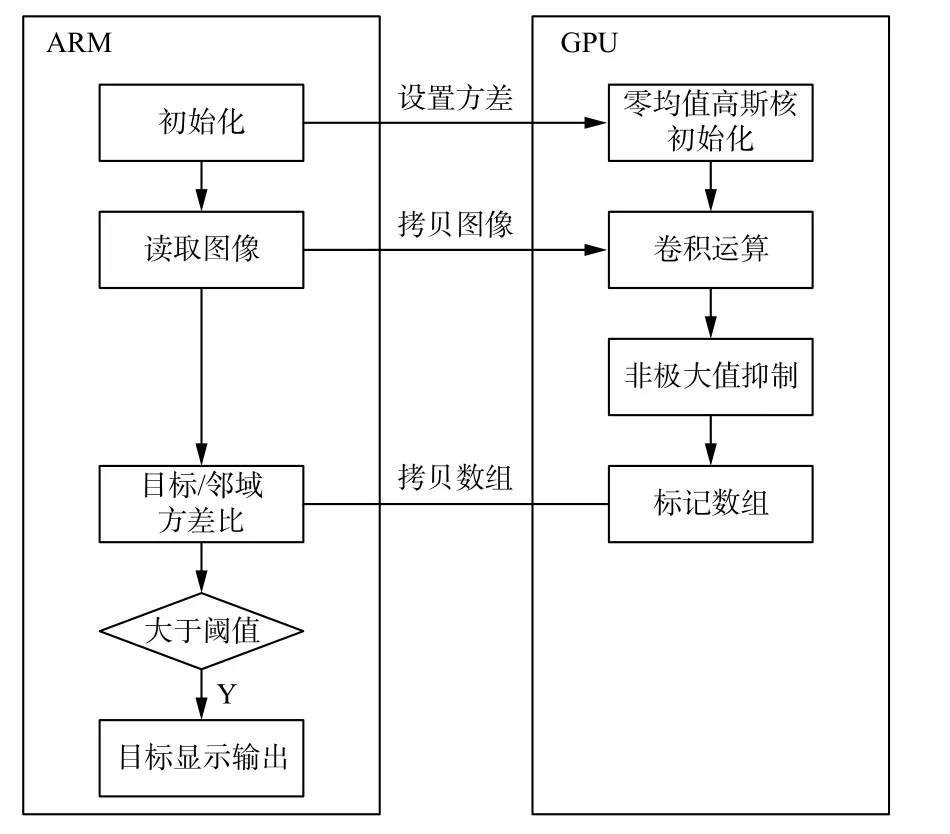
图5 红外弱小目标检测算法流程图Fig.5 Flow chart of infrared weak small target detection algorithm
GPU端主要实现卷积滤波和非极大值抑制,这两者都是通过计算每个像素与其9×9 邻域来完成,每个像素可独立计算,相互之间没有依赖关系,因此可以通过 CUDA 程序对其进行并行设计实现。零均值高斯核滤波和非极大值抑制的CUDA伪代码如表1所示。

表1 零均值高斯核滤波和非极大值抑制的CUDA 伪代码表Table1 CUDA pseudo code table for zero-mean Gaussian kernel filtering and non-maximum suppression
ARM端主要根据标记数组找到目标位置,并在输入图像中完成目标方差及其邻域方差的计算和比较。针对弱小目标,将目标方差统计范围设定为7×7像素。邻域方差统计范围为去掉目标区域后的9×9像素环状区域。若目标方差与邻域方差的比值大于阈值,则认为该点为目标点。方差比阈值设为1.6。
GPU端与ARM端程序采用多线程流水线处理,通过信号量来实现任务同步。
2.3 运行优化
在GPU 代码实现过程中,主要从以下几个方面对程序进行优化:
a)数据零拷贝
JetsonTX2的硬件架构与通用计算机不同,并不存在单独的显存或者内存,只有实质一体的存储器,所以并不需要使用cudaMemcpy函数将内存数据拷贝到显存,只需要采用cudaMallocManaged函数来开辟内存,同时将flags 参数配置为cudaMem AttachGlobal,即可将内存同时映射到GPU和CPU。当GPU 访问该内存时,应确保CPU 不会同时访问。GPU 计算完毕后,可调用cudaEventSynchronize函数来确保GPU 已完成计算,释放该内存的使用权,使CPU可以正常访问。上述方法可实现GPU与CPU的统一内存寻址,避免了计算数据在内存与显存之间的互相复制。
b) 纹理内存的应用
为提高内存访问效率,本文采用cudaBindTexture 2D函数,将一维图像内存绑定为二维纹理内存,再由GPU 读写。通过纹理内存读取数据,可以避免硬件合并访问机制引起的多次内存读取,多数访问将在纹理缓存中多次命中,这样会使性能得到明显提升。另外,纹理内存可以自动处理边界条件,无需由代码来判断是否发生越界读取,减少了越界判断引起的线程分支。
c) 代码调试优化
NVIDIA为GPU开发提供了一款功能强大的性能分析工具nvprof。通过输入不同的指令,即可查看分析各项数据。通过nvprof 对代码进行分析优化,总结出以下几点工程经验:
1) 程序应减少读写内存次数,以便有效降低时间,特别是对外部内存操作。读写共享内存也会耗费时间。GPU 更擅长于计算,不擅长读写内存。因此固定参数尽可写在代码里,而不是从内存中读取。
2) CUDA程序预编译时,对于整数和浮点数的处理不同。如果需使用浮点数,必需将数值写成浮点数。例如(1/16)在CUDA 中的预编译结果为0,(1.0f/16.0f)的预编译结果为0.0625。所以对于能够预先计算出的数值,最好直接写成计算结果。
3) nvprof统计出的计算时间,波动较大。将算法计算过程拆分为多个步骤,可以降低计算时间的波动,但也会增加部分计算时间。
4) 写入共享内存后,需在每个线程内加入同步函数__syncthreads(),完成计算后写入全局内存时,可以不加入同步函数。读取共享内存和数值计算可以交叉进行,有助于提高读取共享内存效率。
5) CUDA函数代码内可以使用printf()函数打印变量,便于分析错误。
6) 尽量不要使用除法和求模运算,不仅计算耗时,而且还会占用很多寄存器,代价昂贵。对于复杂运算如开方等,应使用CUDA 库所提供的__fsqrt_rn()等专用数值计算函数。
3 实验结果与分析
本文所采用的实验平台为NVIDIA的嵌入式开发板Jetson TX2,处理器为64 bit Denver2 and A57 CPUs,内存8 G,GPU为NVIDIA Tegra X2,频率为130 MHz,操作系统为Ubuntu16.04,CUDA版本为9.0,其硬件配置如表2所示。

表2 实验平台硬件配置Table2 Hardware configuration of experimental platform
零均值高斯核检测算法设置滑动窗口大小为9×9,高斯核标准差σ=1.2。对真实图像红外弱小目标检测结果如图6所示。
图6中图像从上至下依次为:云层背景、弱小目标、杂波背景、山地背景。由图6可以看出:在高信噪比云层背景下,LCM算法与本文算法效果相近;在弱小目标、杂波较大、目标较大时,零均值高斯核滤波后背景噪声更小,信噪比更高。
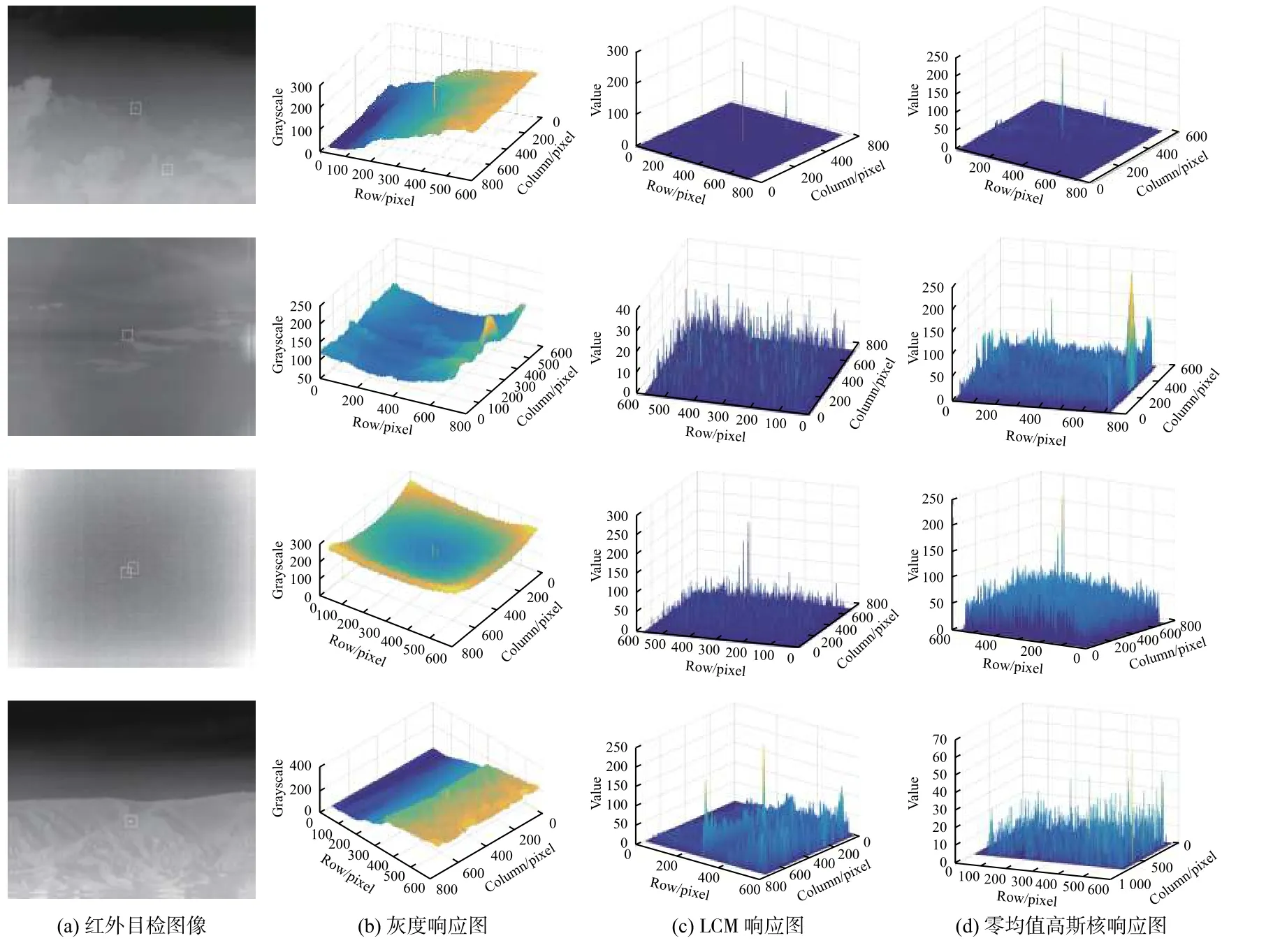
图6 响应图实验结果Fig.6 Experimental results of response maps
为了进一步客观分析零均值高斯核,本文采用信杂比(SCR)指标对滤波效果进行评估[14],指标的定义如(6)式所示:

式中:It为目标峰值;µb和σb分别为目标邻域内背景的均值和标准差。SCR 越大,说明目标信杂比越高,目标越易检测。为了确定出零均值高斯核标准差的最佳参数,本文测试了不同标准差参数条件下的SCR,测试结果如表3所示。

表3 不同场景的SCRTable3 SCR of different scenes
4个场景中的目标大小依次为:5×4像素、3×2像素、3×3像素、12×8像素。从。从表3可以看出:标准差参数设置对于小目标影响较大,对大目标影响很小(山地背景),这与1.3节中的分析结果一致。为兼顾各类场景及不同大小的目标,本文将零均值高斯核标准差设定为1.2。
零均值高斯核不属于分离滤波器,不能直接调用CUDA算法库实现,因此本文采用直观实现方法,通过合理使用共享内存和纹理内存来达到实时处理[15]。对分辨率640×480像素的红外图像序列,采用9×9 零均值高斯核滤波的处理时间对比如表4所示。
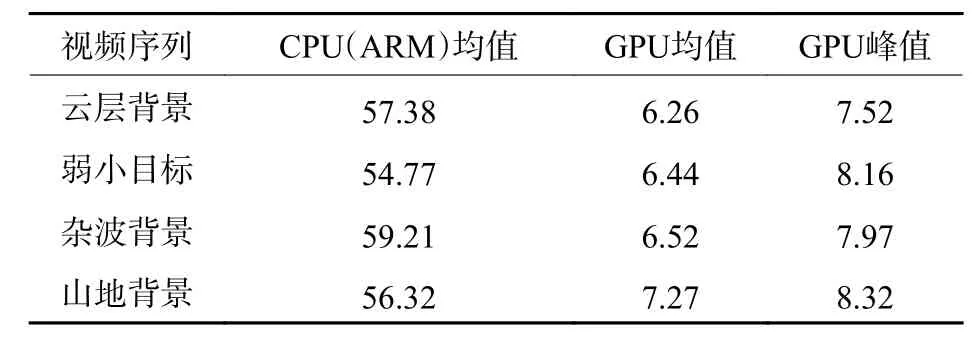
表4 CPU和GPU 耗时比较Table4 CPU and GPU time comparison ms
在实验过程中发现,GPU 计算时间存在较大的波动性,这与共享内存频繁读取偶尔会引发bank 冲突有关。统计结果表明,算法峰值计算时间小于10 ms,已能够满足系统实时处理需求。
4 结论
由于红外弱小目标的可用特征较少,且需进行像素级处理,对弱小目标的实时检测非常具有挑战性。本文利用弱小目标灰度的高斯分布特性,设计了基于零均值高斯核滤波的目标检测算法。在NVIDIA的Jetson TX2 嵌入式平台实现了算法移植,运用GPU 加速计算技术,实现了算法的实时处理,计算时间小于10 ms。下一步拟换用Jetson Xavier平台,利用其512个Volta 架构CUDA核,有望将计算时间控制在5 ms 以内。
猜你喜欢
雪豆月读·高年级(2020年2期)2020-09-10
小天使·二年级语数英综合(2019年4期)2019-10-06
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
小学生学习指导(低年级)(2019年6期)2019-07-22
飞天(2018年8期)2018-10-29
电脑爱好者(2015年21期)2015-09-10
电影故事(2015年16期)2015-07-14
红领巾·萌芽(2015年1期)2015-04-10
电脑爱好者(2009年13期)2009-07-07
