
面向电力业务对话系统的意图识别数据集
2020-09-29 06:56廖胜兰陈小平欧阳昱
计算机应用 2020年9期
廖胜兰,殷 实,陈小平,张 波,欧阳昱,张 衡
(1.中国科学技术大学计算机科学与技术学院,合肥 230026;2.国网安徽省电力有限公司,合肥 230022;3.国网阜阳市城郊供电公司,安徽阜阳 236000)
0 引言
自从1950 年图灵测试被提出后,人工智能的目标就是构建能够自然地与人类沟通的交互系统。人机交互是指人类可以通过自然语言来控制机器人,或者与机器人进行交流沟通,以实现自己的目的。因此,从功能上来说,现有的对话系统主要分为任务导向型对话系统[1]和非任务导向型聊天对话系统[2]。顾名思义,任务导向型系统主要是针对特定领域或业务背景下的对话,目的是为了帮助人们完成特定的任务,例如订票系统、智能客服等。因此任务导向型的对话系统的评估指标为尽量少的对话轮数以及尽量高的任务完成率。本文中意图识别的研究背景是基于电力系统业务的任务导向型对话系统,用户描述自己要办理的业务后,机器人给予业务引导的回答。目前传统的电力营业厅存在服务资源不足、业务办理流程繁琐等问题,而智能机器人可以为客户提供业务办理指南、业务导引等服务,可以显著地提升营业厅的运行效率和服务质量[3]。
对话系统的研究是自然语言处理(Natural Language Processing,NLP)领域的一个重要课题,对话系统主要由语音识别(Automatic Speech Recognition,ASR)、口语理解(Spoken Language Understanding,SLU)、对 话 管 理(Dialog Management,DM)、对话生成(Dialog Generation,DG)和语音生成(Text to Speech,TTS)这5 个部分组成[4]。意图识别是口语理解模块中的一个子模块,也是整个人机交互系统中极其重要的模块。通过准确的意图识别,对话系统才能够理解用户的意图,从而进行下一步的对话决策。
意图识别又称为意图分类,可以看作是一种特殊的文本分类,有着文本较短、命令祈使句较多等特点。早期的意图分类主要是使用基于规则和模板的方法,然而规则和模板的设计需要耗费大量的人力,并且很难应用到其他场景中。随着深度学习的发展,越来越多的研究团队用深度神经网络来进行文本分类的研究。例如卷积神经网络(Convolution Neural Network,CNN)[5]、循环神经网络(Recurrent Neural Network,RNN)[6]等常用的神经网络模型都已经应用到文本分类任务中。深度学习方法不依赖于规则与先验知识,可以完全从数据中学习规律来进行分类,因此在很大程度上能够节省人力和资源。
深度学习的模型训练依赖于大量的有标注的数据集,许多特定领域的意图分类任务还没有相关的数据集,电力业务领域也是如此。为了完善电力业务领域的对话系统研究,并且为学界提供有效的公开标注数据,本文通过对供电营业厅采集的语音数据进行清洗、整理、扩充,构建了一个电力业务相关的意图分类数据集。数据集包含将近一万条用户业务咨询语句及其所属的业务类别。数据集目前公开发布地址为https://pan.baidu.com/s/1ysJrAlCI6TljOFh72Hehew。后 续 将把数据集及其相关信息发布在团队主页http://ai.ustc.edu.cn/上进行开源。
据了解,本文所述的工作是电力业务领域内首个与对话相关的数据集。数据集包含9 577 条问询语句与35 个业务类别。业务类别中包括许多常见的居民用电服务业务。为了在对话系统中实际应用,本文采用了意图识别领域和文本分类中的几个常用经典模型,包括统计学习方法与深度学习方法,在数据集基础上进行实验后得到了不同的性能与准确率。统计学习模型包括Logistic回归(Logistic Regression,LR)模型和支持向量机(Support Vector Machine,SVM)模型,深度学习模型包括FastText模型[7]、Text-CNN模型[5]和Text-RCNN模型[8]。本文将得到准确率最高的Text-RCNN 模型应用到了电力营业厅业务引导机器人的对话系统的研究中。实验结果表明,本文提出的人工标注数据集可以有效提升意图分类器的准确性,从而提升整个对话系统的业务引导性能,提高用户满意度。
因此,本文发布的数据集可以有效地驱动电力业务领域内的智能服务机器人、语音机器人等研究,从而实现线上语音、线下营业厅的智能化服务。
1 意图识别现状
意图识别通常被看作是人机交互对话的第一步。因为首先需要确定用户的意图,才能精准地给予相应的回答。如今随着机器人技术与人机对话的发展,意图分类任务也引起了许多研究团队的关注。
在过去的意图分类工作中,传统的方法主要是基于模板和规则的方法,模型构建简单,在小数据集上能较快地实现。但是传统模型难以维护、可移植性差,并且一般需要专家构建规则模板以及类别信息。例如Ramanand 等[9]在消费意图识别的任务中,提出了基于规则和图的方法来获取意图模板,并且在此单一领域能够取得较好的分类效果。但是Li 等[10]研究发现,即使在同一领域内,不同的表达方式也会导致规则模板数量的增加,因此会耗费大量的资源。所以,传统的方法虽然在小数据集上就可以实现意图分类功能,但是由于不同的任务需要专门构建不同的模板规则,依赖于专家系统,成本较高。
20世纪90年代兴起了统计学习方法,文本分类也由此发展出基于统计特征的方法。统计分类方法的过程分为人工特征工程与浅层分类建模两个步骤。通过对语料文本进行特征提取,如字、词特征、N-Gram、TF-IDF(Term Frequency-Inverse Document Frequency)特征权重等,然后再基于提取的特征训练分类器。常用的分类器有Logistic 回归[11]、支持向量机[12]、朴 素 贝 叶 斯(Naïve Bayes,NB)[13]和AdaBoost(Adaptive Boosting)[14]等。但是这些统计分类方法都需要人工进行特征工程,成本依然很高,且特征表达的能力有限。因此后来的研究者在特征的降维和分类器的设计方面做了大量的工作,Yang 等[15]对各种特征选择方法,包括信息增益(Information Gain)、互信息(Mutual Information)、卡方统计量等,在实验上进行了系统的分析和比较。Joachims[16]第一次将线性核函数的支持向量机用于文本分类,与传统的算法相比,支持向量机在分类性能上有了非常大的提高,并且在不同的数据集上显示了算法的鲁棒性。
传统的统计学习方法面临的主要问题是文本表示是高维度高稀疏的,特征的表达能力很弱。随着在图像和语音领域取得的巨大成功,深度学习也相应地推动了NLP领域的发展。而深度学习最初之所以能够在图像和语音上取得巨大成功,一个很重要的原因是图像和语音原始数据是连续和稠密的,有局部相关性。因此,将深度学习应用于NLP 领域最重要的就是解决文本表示。从词向量(Word Embedding)的分布式表示[17]提出后,深度学习模型就可以提取到文本更深层的特征,从而进行高准确率的分类。如今深度学习的模型在文本分类上已经取得了不错的效果,越来越多的学者们将卷积神经网络(CNN)[5]、循环神经网络(RNN)[6]和其变体长短时记忆(Long Short-Term Memory,LSTM)网络[18]、门控循环单元(Gated Recurrent Unit,GRU)[19]和注意力机制(Attention Mechanism)[20]等应用于意图识别任务中。深度学习模型可以免去复杂的人工特征工程,直接端到端地实现一个分类系统,并且提高分类的准确率。
中文领域的意图分类任务由于分词等影响,也面临着挑战。文献[21]介绍了中文领域内从基于规则的方法、基于机器学习的方法到混合模型的方法的意图分类方法研究,并在iDeepWise 公司第三代机器人积累的日志数据集上进行层次网络的实验。该数据集包含了68 850 条自然语言问句,涉及到订票类、天气类、音乐类等13 个通用领域。同样针对这个数据集,文献[22]提出了一种双通道卷积神经网络模型,通过两个通道可以同时接收字级别的词向量和词级别的词向量进行卷积运算。在CCL2018-Task1(中国计算语言学大会)的中国移动客服领域用户意图分类数据集上,文献[23]提出了一种混合神经网络层的模型。对于常常联系在一起的意图识别和槽位填充(Slot filling)任务,文献[24]提出了结合条件随机场(Conditional Random Field,CRF)和注意力机制的LSTM 联合模型。
除了在模型方法上的研究创新,构建一个意图分类器最重要的便是数据的驱动。如今的深度学习方法,需要大量的包含相应意图的文本作为训练数据。根据调研发现,现有开源的意图分类数据集几乎都是面向语音助手任务的数据,例如第6届全国社会媒体处理大会SMP2017中发布的中文人机对话技术评测数据集,其内容包括订票、打电话、播放音乐等任务。调研过程中还发现了一个包含买手机、买电脑、买电影票等意图的消费意图数据集[25]。总之,目前在特定的领域内,很难获得大量的标注训练语料。调研发现,目前在电力公司业务领域,还没有相关的开源数据集可以用来构建对话系统,因此本文构建了一个较大规模的电力业务意图识别数据集,有助于驱动电力业务相关的对话系统的研究。
2 电力业务用户意图识别数据集构建
为了在交互机器人对话系统中实现高准确率的意图识别功能,意图识别模块拟采用深度学习模型来实现。深度学习模型的优点是无需大量的特征工程,通过端到端的训练方式就可得到较高的准确率;但是缺点是需要大量的数据来训练模型。由于目前暂无公开的电力业务相关数据集,并且电力公司的业务具有领域性,不能用其他公开的文本分类数据集。因此,本文与电力公司营业厅合作进行数据采集,对得到的语音数据进行清洗、整理和扩充,构建了一个面向电力公司业务的用户意图数据集。该数据集可以为其他电力公司的智能客服、交互机器人等研究提供相应的帮助。
2.1 数据来源
本文提出的数据集所包含的内容来自供电营业厅真实的用户询问语句,涵盖了在营业厅真实场景中发生的大部分常见业务。语音数据通过线下录音笔收集得到。由于是真实的业务场景,所以数据具有真实性和多样性等特点,但因此数据也同时含有一些无意义的停顿、语气词等。为了使数据集更有利于意图分类模型的使用,本文通过项目小组内10 名成员对数据进行处理与标注。
2.2 数据处理
2.2.1 语音转文字
原始语音数据收集完毕之后,需要对数据进行处理和标注。由于收集到的是语音数据,因此需要将其转化为文本格式,才能进行下一步的意图分类工作。语音转文字的过程采用了科大讯飞的语音识别接口(https://www.xfyun.cn/services/lfasr)来实现。
2.2.2 人工校验
目前的语音识别工具无法达到百分百的准确率,并且真实场景中的语音数据中会含有噪声、停顿过长、语气词过多等问题对语音识别过程进行干扰,因此本文对转换后的文字数据进行人工校验,去除掉无效数据,并对有效数据进行修改。
例如,语音转文字后得到的语句“你好,那个,我们家里的电表最近,额,感觉走的不正常,很快,嗯。”经过人工校验后,去掉其中的无意义词,得到:“我们家里的电表最近感觉走的不正常,很快。”
2.2.3 敏感信息过滤
由于数据是在真实场景中得到的,因此需要对数据中涉及的敏感信息进行过滤,例如人名、身份证号、电力账户号等。过滤的目的是为了保护用户的隐私,并且能够用过滤后的数据集训练出通用、普适的意图分类模块。同时,敏感信息过滤也可以避免任何使用本文提供的数据集进行训练的对话系统公开用户的隐私或生成使用户感到不适的回复。
本文背景所研究的智能客服机器人主要是起到业务引导作用,并不涉及后续的复杂业务办理阶段。因此,收集到的数据中主要是用户对业务需求的描述,例如“我家电表好像坏了”“办理过户应该带什么证件”等。因此,大部分数据中不包含实际的人名、电力账户号等敏感信息。
2.3 数据标注
对数据预处理过后可以得到有效的文本数据。本项目小组的10 名成员根据电力公司提供的常见业务类别以及每个类别的示例对话来对数据进行标注。每一条问询语句对应一个电力业务类别。标注的类别一共有35 个,包括了缴费、供电报修等十分常见的业务,也包括了商业用电增容等较罕见的业务。
在标注过程中还遇到了语义模糊无法标注的数据。因为有小部分数据采集时可能来自老年人或使用方言的用户,因此语音转文字后得到的文字数据语义模糊。针对这样的数据,小组成员重新听语音,如果能听懂语句意图则人工转写为文字数据并标注业务类别,听不懂则作为无效数据删去。
2.4 数据扩充
在采集到的数据中,常见业务的数据量较多,而罕见业务的数据量较少。例如,分布式光伏发电、高低压界定、高压增容等面向企业用户的业务在日常的营业厅咨询语句中占比例较小,采集到的数据较少,而居民电费缴纳、在线办理业务、居民分时电价等面向居民的常见业务采集到的数据较多。因此,为了保证业务类别的平衡性,避免在训练过程中造成数据倾斜的情况,本项目小组的成员根据采集到的真实数据进行转写扩充。
根据电力公司提供的业务类别及其示例语句,以及采集到的数据,本项目小组成员对数据较少的业务进行补充。例如,对业务“商业更换分时”补充示例如表1 所示,根据原语句采用不同的叙述方式进行扩充。

表1 数据扩充示例Tab.1 Example of data augmentation
2.5 数据统计分析
最后本文构建的数据集一共有9 577条数据,平均的数据长度为18.41字。其中业务的类别分布如表2所示,数据中用户语句的平均长度特征如表3所示。
可以看出,电力业务一共标注了35 个类别,涵盖了大部分电力营业厅的常见业务,可以满足业务引导机器人的日常需求。
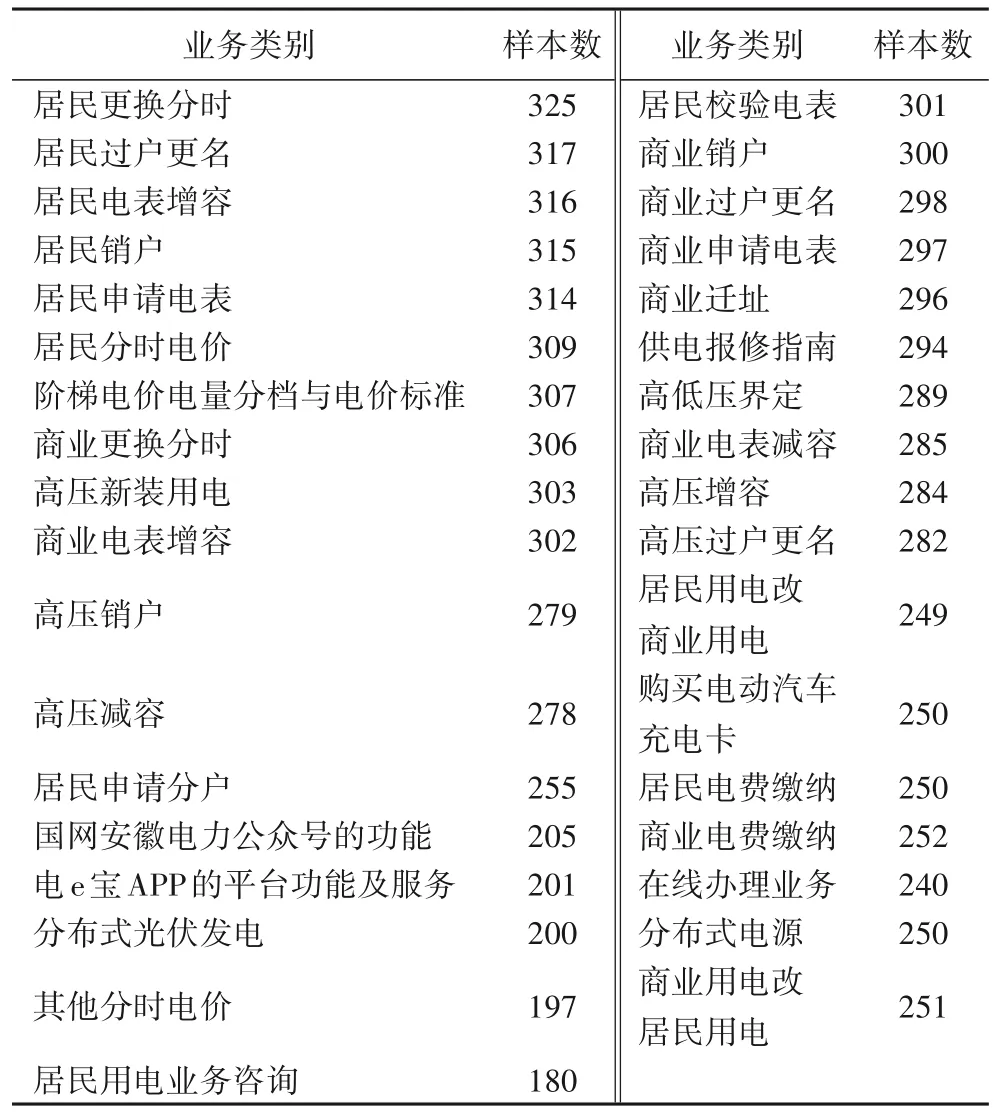
表2 数据集类别分布Tab.2 Category distribution of dataset

表3 数据集中语句平均长度Tab.3 Average length of sentences in dataset
3 基准实验
为了测试本文提出数据集的有效性,本文基于最终标注的数据集上采用几个常见的文本分类模型进行基准实验,包括统计学习方法和深度学习方法。在实验过程中,采用结巴分词工具(https://github.com/fxsjy/jieba)中的默认分词模式对数据集进行分词,在深度学习模型中,采用word2vec工具[26]进行词向量的预训练。
本文采用多个经典的统计学习方法和深度学习方法模型来进行实验,既可以验证数据集的有效性,又可以直观地得到各个文本分类模型在短文本对话数据集上的实验效果。
3.1 Logistic回归
Logistic 回归(Logistic Regression,LR)是统计学习中的经典分类方法,属于一种对数线性模型。LR 模型的优点是它直接对分类的可能性进行建模,无需事先假设数据分布,这样就避免了假设分布不准确所带来的问题。又因为它是针对分类的可能性进行建模的,所以它不仅能预测出类别,还可以得到属于该类别的概率。
在本文的基准实验中,用多分类的LR模型对数据集进行基准实验。特征提取方法采用词袋模型特征和词频-逆文档频率(Term Frequency-Inverse Document Frequency,TF-IDF)特征。
3.2 支持向量机
SVM的应用是统计学习模型在文本分类上最重要的进展之一。虽然SVM 在大数据集上的训练收敛速度较慢,需要大量的存储资源和很高的计算能力,但它的分隔面模式有效地克服了样本分布、冗余特征以及过拟合等因素的影响,具有很好的泛能力。
本文选用SVM 的线性核函数,分别用两种特征提取方法和不同的惩罚因子参数C进行实验。
3.3 FastText
FastText[7]是Facebook 公司在2016 年开源的一个词向量与文本分类工具,典型应用场景是“带监督的文本分类问题”。它提供简单而高效的文本分类和表征学习的方法,性能比肩深度学习而且速度更快。
因此,现在许多大规模的文本分类都会采用FastText 作为实验基准。由于其简单、便捷的特点,本文也选用FastText模型来进行意图分类。
首先需要对数据进行分词处理、去除停用词,以及添加Label。之后将分词过后的数据转换成FastText 的标准输入格式,即用“__label__”来分割文本和标签。最后将数据分割成训练集和验证集,用验证集来评估学习到的分类器对新数据的性能好坏。
3.4 Text-CNN
卷积神经网络(CNN)最开始是应用在图像处理领域的,最近几年随着词向量的发展,自然语言处理领域的数据稀疏问题得到解决。Kim 等[5]在EMNLP2014 提出的Text-CNN 方法,尝试将CNN 应用在文本分类领域中,并且在多个数据集上取得了很好的效果。
Text-CNN 模型首先将文本映射成向量,然后利用多个滤波器来捕捉文本的局部语义信息,接着使用最大池化,捕捉最重要的特征。最后将这些特征输入到全连接层,得到标签的概率分布。
本文用Text-CNN 模型在提出的电力公司业务用户意图数据集上进行意图分类,学习率设为0.01,训练的迭代轮数为50,词向量维度设为300,批处理大小设为32。
3.5 Text-RCNN
Text-RCNN[8]是一个结合了RNN 和CNN 各自优点的模型。首先利用双向循环神经网络(Bidirectional Recurrent Neural Network,Bi-RNN)来捕捉前后的上下文表征,将上文的所有信息和下文的所有信息进行编码,与词向量拼接起来,得到一个包含上下文信息和本身词向量表示的“词向量”。接着使用CNN 中滤波器filter_size=1的卷积层,并使用最大池化操作得到与文档最相关的向量表征,即获取潜在的最相关语义表示。最后将这些向量输入到Softmax 层,得到标签的概率表征,从而进行文本的分类。
本文用Text-RCNN 模型在提出的电力公司业务用户意图数据集上进行意图分类,参数设置如下,学习率设为0.01,训练的迭代轮数为50,词向量维度设为300,批处理大小设为32。
4 实验结果
本文用第3 章介绍的几个经典模型在数据集上进行实验后,得到的意图分类准确率如表4、5所示。表4显示了统计学习方法的结果,表5显示了深度学习方法的结果。
本文采用测试集上的准确率Accuracy作为评估指标,并且保证测试集的数据在训练集中不曾出现。准确率Accuracy表示预测出的类别和数据集中标注的类别相同的数据占所有测试数据的比例。表4分别列出了LR模型和SVM模型在数据集上训练后的训练集准确率train-acc和测试集准确率test-acc。

表4 统计学习模型实验结果 单位:%Tab.4 Experimental results of statistical learning methods unit:%
实验过程中,对于LR模型,使用词袋特征提取方法时,在惩罚因子C=2 时取得最佳测试准确率,为80.27%,训练时间为3.02 s。使用词频-逆文档频率特征时,在C=5 时取得最佳测试准确率80.43%,训练时间为1.39 s。对于SVM 模型,两种特征提取方法都是在C=1 时取得最佳准确率,且训练时间也都为约17.56 s。
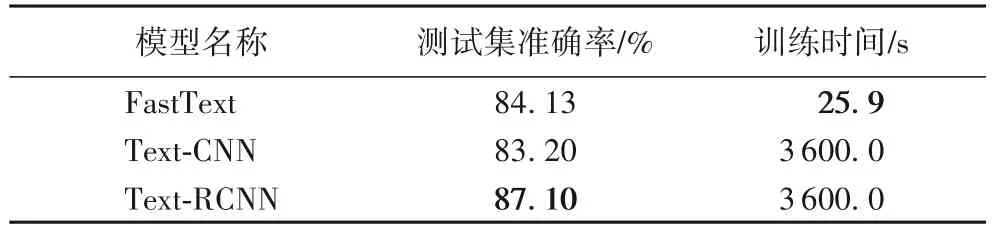
表5 深度学习模型实验结果Tab.5 Experimental results of deep learning methods
在深度学习模型的实验结果中,3 个模型得到的准确率都要高于统计学习模型。尤其是FastText 模型,训练时间短,准确率较高,很适合作为基准模型用于数据集的验证。实验结果得到的测试集最高准确率来自Text-RCNN 模型,它融合了循环神经网络(RNN)和卷积神经网络(CNN)的优点,模型并不复杂但是能够得到更好的结果。
从实验结果可以看出,虽然统计学习模型训练速度快,但是准确率较低。而深度学习的模型在免去提取特征步骤,并且端到端地进行训练后,能够达到更高的准确率。
在电力业务对话系统研究中,本项目小组采用了准确率最高的Text-RCNN 模型作为意图识别模块。结合对话系统中关键词实体抽取、对话管理、回答生成等模块,可以得到一个有效的针对电力领域的业务导向机器人。与使用通用闲聊数据集的对话系统相比,本意图识别数据集可以提升意图识别的准确率,从而使机器人给出更精准的回答。使用本数据集与使用通用闲聊数据集的对话系统回复对比如表6 所示。对于相同的用户问询语句,以本数据集构建的意图分类模型可以有效识别出用户语句中的潜在意图,而使用通用闲聊数据集的对话系统则无法精准识别出用户意图。

表6 使用不同数据集的对话系统回复对比示例Tab.6 Example of dialogue system response comparison with the use of different datasets
5 结语
基于对电力业务对话系统的研究工作,本文构建了一个大规模的人工标注电力业务意图识别数据集,其中包含了35个业务类别以及9 577 条业务意图数据。该数据集是电力领域对话系统相关的第一个开源的数据集。在此数据集中,每条数据是根据电力公司给出的业务类别进行分类标注,较全面地涵盖了供电营业厅中的常见业务。几个基准实验表明,基于本文发布的电力公司业务用户意图数据集进行训练后,意图分类的准确率最高可以达到87.1%。结合后续对话系统中对话管理模块、关键字抽取模块等,可以得到一个精准识别用户意图并给予可靠回复的电力业务引导对话系统,得到较好的用户体验。因此,本文所述数据集在实验的验证下证明了具有客观性和有效性,可以助益于供电营业厅场景中的聊天机器人的训练与评估。
但是本文所构建的数据集目前的规模还不足够大,数据中业务类别的分布也没有足够均衡。后续本小组将在研究进行的过程中得到更多数据,并进行更准确的标注。目前本文的基准实验主要是采用一些文本分类领域中经典的模型,但是现在已经有了许多更新、准确率更高的模型。因此,未来工作中也将采用更先进的模型对数据集进行实验。
由于目前特殊时期的原因,本文发布的数据集暂时公布在https://pan.baidu.com/s/1ysJrAlCI6TljOFh72Hehew。后 续会将数据集正式发布在团队主页http://ai.ustc.edu.cn,并补充相关授权信息。
猜你喜欢
法律方法(2022年2期)2022-10-20
汽车实用技术(2022年14期)2022-07-30
福建基础教育研究(2022年4期)2022-05-16
新高考·高一数学(2022年3期)2022-04-28
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
健康体检与管理(2021年10期)2021-01-03
高中生学习·高三版(2016年9期)2016-05-14
