
基于RNN的低压变压器区域日线损率基准测试
2020-09-26 00:58何伟民孙一迪金良勇毛和云
计算机测量与控制 2020年9期
何伟民,孙一迪,姜 捷,金良勇,毛和云
(国网浙江江山市供电有限公司,浙江 江山 324100)
0 引言
线损率是电网的一项重要评价指标,它能反映电网在经济和技术方面的运行和管理水平[1]。线损一般分为技术性线损和非技术性线损。日线损率值是否在合理的范围内(即日线损率的合格率)已成为电网运营商迫切关注的问题,这就需要从大量采集的样本中直接区分正常线损率值和异常值[2]。由于日线损率能够作为操作人员更好了解低压变压器区域工作状态的依据,因此,日线损率的基准值的准确测量对于提高线损管理水平尤为重要。
在数据挖掘分析领域,通常有4种方法来计算基准值和检测异常值,即经验法[3]、统计法[4]、无监督法[5]和监督法[6]。文献[3]利用经验法指出在日线损率的基准测试中,经验区间通常设置为-1%~5%。文献[7]揭示了由于不可避免的采集误差,不小于-1%的值均可以接受。文献[4]指出统计法中的区间界限能够适应不同的检测样本,但该方法很难利用线损率的影响因素。文献[5]利用无监督法中的聚类算法将异常值可以通过数据点与聚类中心的距离来进行识别。监督法利用机器学习模型求解分类问题[6]和回归问题[8],文献[9]和文献[10]分别设计用于异常值检测和基准计算任务,分类模型通过对标记样本的学习来区分正常和异常数据。然而,线损率样本通常没有标记,因此它无法识别收集到的线损率值是否正常。
本文提出了一种基于鲁棒神经网络(RNN)的回归计算方法,并由去噪自动编码器(DAE)、多径网络结构、丢包层、Huber损失函数、L2正则化和10个输出组成。基准是根据10个输出的平均值计算得出。经过误差分析,该方法可以得到合理的区间来检测原始线损率样本的异常值。
1 线损理论计算
本文提出了基于等效电阻法计算技术的理论线损公式,该方法假定线路的前端存在等效电阻,其中三相三线和三相四线系统的能量损失可表示为[11]:
(1)
其中:ΔAb为三相平衡负载时的理论线损,N为结构系数,在三相三线制下等于3,在三相四线制下等于3.5。K、Iav、Req和T分别为负荷曲线的形状系数、线首处平均电流(A)、导体等效电阻(W)和工作时间(h)。此外,Req的计算公式为:
(2)
其中:Ni、Ai和Ri分别为第i个线段的结构系数、计量功率和电阻。Aj为从第j个电表采集的电量。对于三相平衡负载系统,理论线损可修正为:
ΔAub=ΔAb×Kub
(3)
其中:Kub为修正系数,可定义为:
(4)
其中:当出现单相重负荷和两相轻负荷时,k=2。当出现两相重负荷时,k=8。δI为三相负载的不平衡度,可计算为:
(4)
其中:Imax为来自具有最大负载相的电流。因此,以上定义的理论线损是不可避免的能量损耗,即技术线损耗。然而,电网运营商也担心因窃电引起的非技术性线路损耗。由于非技术性线损情况会导致按日计量的线路损耗率出现异常值,因此有必要计算合理的时间间隔以进行区分识别。
2 数据集
在实际应用中,通常国家电网公司每月检查一次低压变压器区域日线损率的合格性。在这种情况下,本文研究中使用了2019年7月份的线损率数据集,该数据集以每日间隔进行采集,以此检查当月线损率的合格率。合格率指标在7月份尤为重要,这是由于7月份通常是夏季的用电高峰期。该数据集选自浙江省江山市共计19 884个低压变压器区域,共有616 404个样本,满足了大数据分析的需要。基于该数据集,选择约80%的样本(15 907个低压变压器区域)作为训练样本,其余的样本(3 977个区域)作为测试样本。
2.1 数据质量分析
本文的研究对象为日线损率,一些低压变压器区域日线损率示例,如图1所示。

图1 不同低压变压器区域日线损率示例
本文选取25%(q1),中位数(q2),75%(q3),最大值(max)、最小值(min)、均值、标准差(std),下限值(la)和上限值(ua)作为研究指标。基于总体线损率数据集的数据质量分析,如表1所示。

表1 基于总体线损率数据集的数据质量分析
原始数据集和插值后数据集的方框图,如图2所示。

图2 原始数据集和插值后数据集的方框图
下限值(la)和上限值(ua)是基于25%的(q1)和75%的(q3)计算得出,其中超出界限范围的值可以视为异常值:
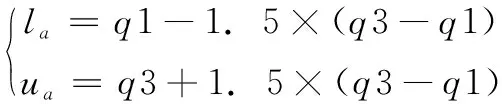
(6)
根据曲线和数据质量分析,日线损率的数据特征总结如下:
(1)线损率数据日变化规律性很小,但波动性很大。从图1可以看出,不同低压变压器区域的线损率曲线随着时间的推移变化很大,历史线损率很难用来估计进一步的数值。因此,选取线损率的影响因素是本文研究的重点。
(2)数据集中异常值的偏差有时偏离正常值较大,这表明计电装置和通信设备的可靠性较低。根据表1和图2,对比图中原始数据集的上下限值分别为-1.57%和5.22%,与项目标准(-1%和5%)相当接近。然而,所收集的线损率的最大值和最小值分别为100%和-1.69×106%,与界限有很大的不同。在这种情况下,基准线损率在实际应用中仍然重要。
(3)数据集的质量较差,无法直接使用。数据质量分析的组成结果,如图3所示。其中,正常值84.61%,异常值8.67%,缺失值6.72%,因此,存在大量的异常值和缺失值,并且分别占整个数据集的8.67%和6.72%。本研究利用样条插值法来填补缺失值。从表1和图2可以看出,插值后的数据集与原始数据集的分布相似。相反,虽然可以根据la和ua可以直接消除异常值,但分布会发生变化,并且很难计算出准确的合理区间。

图3 数据质量分析的组成结果
2.2 线损率的影响因素
考虑到可能的影响因素和记录的信息,本文共选择12个因素作为回归模型的输入,如表2所示。其中,第三因素和第4个因素是1 bit字符,其他都为数值。

表2 线损率的影响因素
3 基准值和合理区间的计算
根据数据质量分析,原始数据集中含有大量的异常值,这些异常值超出合理范围较远,很难得到准确的结果。因此,本文的任务是利用具有鲁棒的学习模型来获得异常值稳定的回归结果,如图4所示。

图4 传统的学习模型容易受到异常值的影响
通常,学习模型需要手动设置阈值,并根据这些阈值从数据集中删除异常值,数据集的其余部分可用于训练机器学习模型,然而确定准确的阈值成为研究的难点。此外,学习模型合理区间的计算范围可能接近人工阈值,从而影响原始数据集的分布,并使得训练概率学习模型实效。在这种情况下,本文提出了基于RNN的计算方法,如图5所示。
具体计算步骤如下。
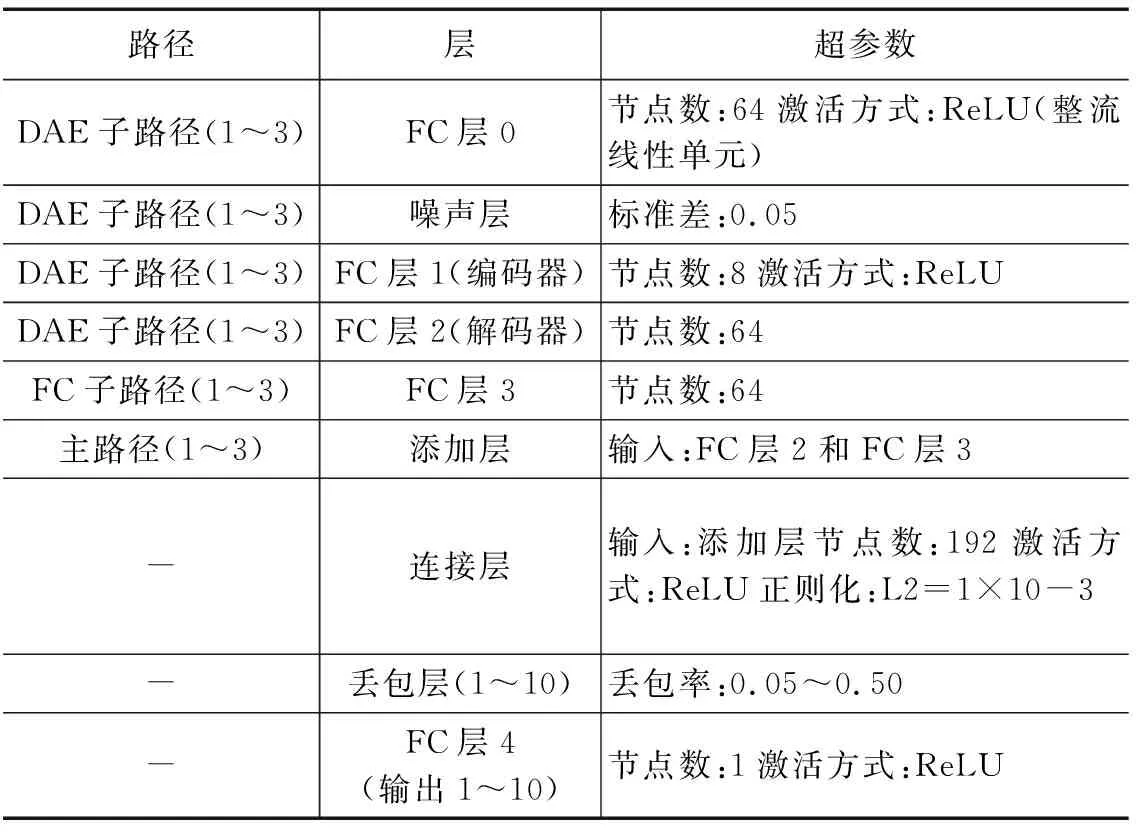
步骤1:建立RNN。为了充分扩展其鲁棒性,本文利用DAE、多径结构、L2正则化、丢包层和Huber损失函数等方式进行分析。由于RNN具有10个输出节点,其中每个节点以不同的丢包率(从0.05到0.50)连接到一个层。
步骤2:根据10种不同的输出计算平均值,即线损率的最终基准值:
(7)

步骤3:根据误差分析获得合理的区间。本文不仅计算了基准值与实际线损率的绝对误差,还计算了不同输出的方差。根据区间结果,不在区间范围内的数据点认为是异常值,具体的计算公式如下:
(8)
(9)

(10)


图6 消除可能异常线损率值的双尾检验
4 鲁棒神经网络(RNN)
本文使用RNN算法[12]进行鲁棒学习,其结构如图7所示。其由三条主要路径组成,这些路径通过串联组合在一起,并且每条主路径上都有一个DAE。为了进一步提高系统的鲁棒性,将串联后的输出节点放在同一层中,这些层表示从原始输入中提取的高阶特征,并在层中采用L2正则化来限制这些节点的输出值。然后,在高阶特征层之后叠加10个具有不同丢包率的丢包层,并得到10个输出。本文对10个输出进行分析,并计算基准值和合理区间。

图7 鲁棒神经网络(RNN)的结构
4.1 去噪自动编码器(DAE)
本文所提出的DAE的结构,如图8所示。它是自动编码器的鲁棒变体,在编码器之前具有一个噪声层[13],例如正常(高斯)噪声层:

图8 去噪自动编码器(DAE)的结构
xi,n=xi+N(0,σ2)
(11)
其中:xi和xi,n分别为噪声层的第i个输入和第i个输出。N(0,σ2)为正态分布,其平均值为0,方差值为σ2。在本文研究中,当输入标准化为[0,1]时,σ设置为0.05。
此外,DAE中的编码器层和解码器层均由传统的全连接(FC)层组成,其方程可以表示为:
(12)

4.2 通过加法和串联组合的多路径
在RNN中共有三条主要路径,它们具有相似的层,其输出在串联操作下可以组合起来:
(13)
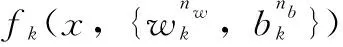
此外,主路径由两个子路径形成,即DAE子路径和FC层子路径。两个子路径的输出作为主路径的输出相加,如下所示:
(14)
4.3 丢包层
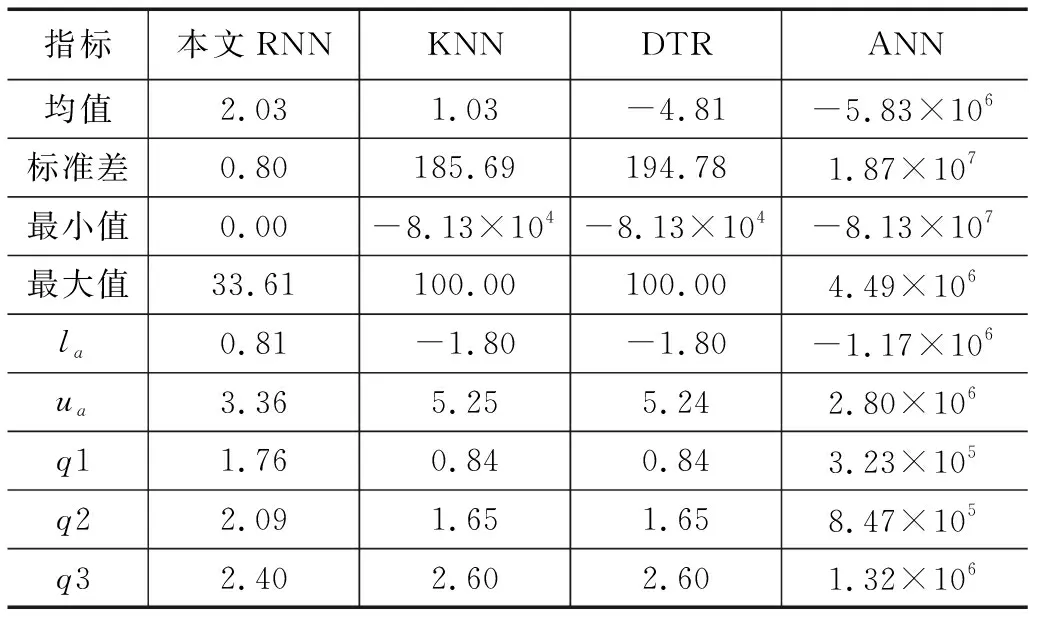
丢包层作为一种特殊的层,其可以有效地防止过度拟合[14]。丢包过程可概括为两个阶段,即训练阶段和应用阶段。对于公式(12)所示的传统FC层,存在j个输入节点。在训练阶段中,输入节点将以概率p(0 图9 在训练阶段的丢包原则 (15) 其中:p为丢包率,其设定在0.05到0.50之间(步长为0.05),以便在研究中获得10种不同的输出。 神经网络的训练过程是设置损失函数,利用BP梯度下降算法逐层更新参数。均方误差(MSE): (16) (17) 其中:MSE和MAE也可作为L1损失和L2损失,这是由于MSE和MAE分别使用了线性项和二次项。 MSE与MAE相比,MSE具有更光滑的导数函数,这有利于梯度下降算法的计算,而MAE的微小差异可能导致参数更新的巨大变化。相反,在对抗异常值时,MAE表现出比MSE更好的性能[16]。在这种情况下,Huber损失函数的原理,如图10所示。 本文采用Huber损失函数[17],该函数结合了MSE和MAE的优点: (18) 其中:δ为需要手动设置的超参数,在本文研究中设定为10%。 在本文研究中,L2正则化旨在为具有较大激活输出的节点设定惩罚项,以此防止过度拟合,并提高神经网络的鲁棒性。正则化在训练阶段起到作用,在训练损失函数中加入两个范数的惩罚项,其表达式为: (19) 其中:L为模型训练的最终损失函数,λ为惩罚项的超参数,在本文研究中设置为0.001。 本文所提出的RNN结构和超参数如表3所示。 表3 RNN的结构和超参数 考虑到训练样本数量较多的特点,本文建立了k近邻(KNN)、决策树回归(DTR)和单隐层人工神经网络(ANN)进行比较,在大数据集上具有较高的训练效率。在NVIDIA GTX 1080 GPU的计算机上,采用Python 3.5和Tensorflow 1.4对深度RNN模型进行训练。RNN的所有超参数和训练配置以及超参数(即σ、δ和λ)通过基于整体训练数据集的三重交叉验证的网络搜索进行选择。参数的搜索空间和最终结果,如表4所示。 表4 RNN中选定超参数的搜索空间 在本文中,从测试样本中随机选择6个低压变压器区域作为展示示例,如图11所示。 图11 6个实验区域的基准值和合理区间的结果 低压变压器区域的编号分别为1 100、1 302、7 015、8 125、12 610和14 072。结果表明,合理区间的界限可以根据多个输入因素进行自适应调整,例如,在区域1 100和区域8 125中。距离基准值较远的异常值可以有效地剔除,虽然这些异常值可以在-1%~5%之间,但是合理区间的结果要优于1%~-5%之间的固定区间。此外,基准值与实际线损率相比波动较小,表明日线损率的估计具有较高的可靠性。基准值能够根据相关因素的变化自适应地反映低压变压器区域的日常运行状况,而不是根据原始数据集计算出的平均值或中值。 基于本文所提出的RNN,可以分析线损率的通过百分比结果,如图12所示。 图12 基于鲁棒神经网络的线损率合格率分析 对于线损率的数据点分析,由于所提出的方法能够准确地识别出与基准值相差较大的异常值,因此异常值的数目比图3中的异常值要多。此外,虽然所有数据点的缺失值和异常值的百分比都不算大,分别为6.72%和13.06%,但一个月内没有缺失值和异常值的区域仅占整个数据集的19.84%,这说明当前计电设备的可靠性较低。 为了评估本文所提出方法的鲁棒性和准确性,首先建立KNN、DTR和ANN的超参数,如表5所示。 表5 KNN、DTR和ANN的超参数 (1)鲁棒性分析:为了评估所提方法的鲁棒性,本文分析了基于不同测试模型的计算基准值的分布,如图13所示。 图13 基于不同测试模型的计算基准值分布 分布指标的详细数值,如表6所示。 表6 不同测试模型的鲁棒性分析结果 结果表明,测试的ANN模型性能最差,完全无法计算出有效的基准值。ANN的最大值和最小值分别为4.49×10%和-8.26×10%,因此,其很难作为基准值。根据分布,KNN和DTR得到了相似的结果。它们都利用接近未知测试区域的大量训练样本来确定新的基准值。因此,在本文中,KNN和DTR比ANN具有更好的鲁棒性,并且在大多数低压变压器测试区域都具有可行性。然而,这两个模型的最小基准为-8.13×104%,仍然不是合理的基准值,而且RNN在4个测试模型中取得了最好的结果,其中计算的基准值在合理的范围内。利用RNN计算得出的基准值标准差仅为0.80%,这表明该方法得到的结果稳定且可靠。 (2)精度分析:本文利用MAE、MSE和Huber损耗3个损耗指标来比较4个测试模型。在使用双尾检验进行损失计算之前,测试样本中的异常值被消除,如图6所示。不同测试模型的精度分析结果,如表7所示。 表7 不同测试模型的精度分析结果 结果表明,由于ANN的3个损失指标远高于其他模型,因此其性能最差。当直接对具有极端异常值的样本进行训练时,ANN并不适用。虽然KNN和DTR具有相似的鲁棒性,但它们的精度指标却有很大的不同。由于KNN计算出的异常值较少,因此KNN得到的MAE指标最好,而KNN的MSE值大于所提出的RNN的MSE值。综合比较这些指标,本文提出的RNN具有最高的性能,在MAE值较小的情况下获得了最佳的MSE和Huber损耗指标。 日线损率作为考核低压变压器区域性能的重要指标,其对供电企业的利润有很大的影响。为了更好地管理线损水平,为低压变压器区域的建设和运行提供指导,本文研究开发的日线损率基准值计算方法,有助于发现异常线损率值,也有助于运行人员对异常运行情况进行检查和确认。从实例分析和比较结果来看,传统的ANN模型不能处理异常值,无法计算出基准的结果。在案例分析中证明了KNN、DTR和所提出的RNN的适用性,其中所提出的RNN优于其他两个模型。在所有的测试模型中,该方法具有较高的精度和鲁棒性。此外,根据所提出的RNN的最终结果,在整个数据点中约有13%的异常值。一个月内线损率无缺失值和异常值的区域仅占20%左右,说明了计电设备可靠性较低。因此,目前电网中仍需要一套可靠的线损数据监测与管理系统。
4.4 Huber损失函数

4.5 L2正则化
5 实验分析

5.1 计算结果


5.2 性能分析



6 结束语
猜你喜欢
计算机应用与软件(2022年6期)2022-07-12
商品与质量(2021年43期)2022-01-18
科技研究·理论版(2021年22期)2021-04-18
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
中国电气工程学报(2019年25期)2019-09-10
智富时代(2018年12期)2018-01-12
智富时代(2018年12期)2018-01-12
电脑知识与技术(2016年28期)2016-12-21
汽车科技(2016年5期)2016-11-14
科技视界(2016年16期)2016-06-29
