
基于Pytorch框架搭建U-Net网络模型的遥感影像建筑物提取研究
2020-09-21 09:51焦利伟麻连伟秦建辉
河南城建学院学报 2020年4期
焦利伟,张 敏,麻连伟,秦建辉
(1.河南省煤田地质局物探测量队,河南 郑州 450009;2.河南省地质物探工程技术研究中心,河南 郑州 450009;3.河南理工大学 工商管理学院,河南 焦作 454003)
随着计算机技术的快速发展,计算机的计算能力有了很大的提升。此外,借助于大数据的兴起、遥感影像分辨率的提升,多种大规模的数据集也相继出现,这些都为深度学习的成熟提供了土壤。传统的信息提取方法对影像信息的利用不足,多是基于影像的底层特征如光谱特征、纹理特征、几何特征等[1-2],特征选择相对单一,容易存在“同物异谱、异物同谱”现象。学者NEVATIA 等[3]利用建筑物的直线和角点等几何特征进行建筑物的提取;于书媛等[4]以高分一号影像为数据源,采用面向对象的 CART 决策树算法进行建筑物提取,相较于传统的决策树方法,精度有了一定提高;秦梦宇等[5]利用决策树的J48算法进行高分影像的建筑物提取,首先利用多尺度分割选取最优分割尺度,获得影像对象,然后利用特征空间优选工具得到最优特征子集,最后与传统的信息提取方法进行对比;林雨准等[6]提出了一种综合影像的光谱、形状、空间、纹理多特征融合的方法进行高分影像建筑物分级提取,首先利用建筑物指数和形状特征提取完整的矩形建筑物目标,在此基础上利用光照方向和阴影特征对已选建筑物进行筛选,然后建立概率模型进行建筑物提取。这些传统的方法虽然能够提取出建筑物信息,但提取的精度不高。为解决信息提取精度较低的问题,很多学者相继提出了基于深度学习的方法进行信息提取研究:宋廷强等[7]利用深度卷积神经网络 AA-SegNet 模型进行高分影像建筑物识别,有效解决了深度学习中过度分割问题,提取精度优于 SegNet 模型;沈旭东等[8]提出了一种基于 Resnet 的 U-Net 网络结构进行建筑物的变化监测。为进一步提高遥感影像信息提取精度,文章基于深度学习的方法,采用Pytorch框架搭建U-Net网络模型,进行遥感影像建筑物提取研究。
1 深度学习与U-Net语义分割网络
1.1 深度学习
深度学习方法最初由 Hinton 等人[9]在2006年提出,之后便迅速发展,并在语音识别、无人驾驶、计算机视觉等方面得到了广泛运用[10]。其通过模仿人脑神经元深层结构,利用大量的数据训练获得了图像的特征信息,最后建立起一个学习模型,并通过模型进行图像的分析和判断[11]。图 1为深度学习结构图。
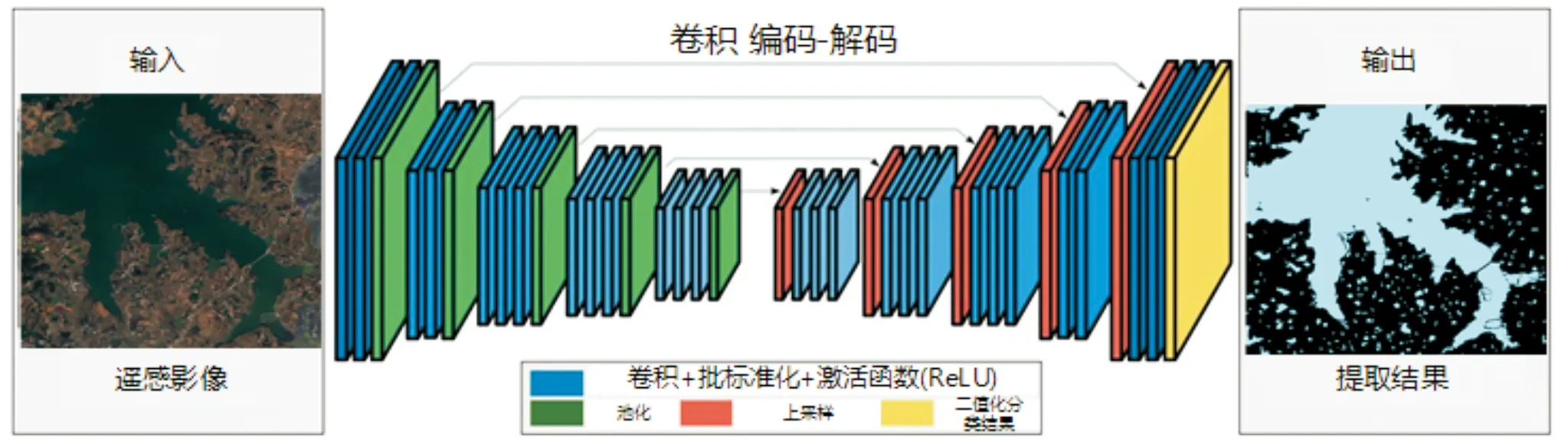
图1 深度学习结构图
1.2 U-Net语义分割网络结构
U-Net分割网络模型是深度学习方法中一个重要的分割方法,其产生于2015年,由 Ronneberger 等[12]人提出的一种类FCN新网络分割模型,最初主要用于医学影像的分割。随着算法的深入研究,也广泛应用于其他方面,如图像变换等。图2为U-Net网络结构图。U-Net网络的结构是对称的,形似英文字母U,所以被称为U-Net。其网络结构由两部分组成:搜索路径和扩展路径。搜索路径主要是用来捕捉图片中的上下文信息,对输入的影像进行卷积和池化操作,得到高维的特征金字塔。扩展路径则是为了对图片中所需要分割出来的部分进行精准定位。对影像进行反卷积和上采样操作,最后得到与输入影像尺寸相同的影像输出。
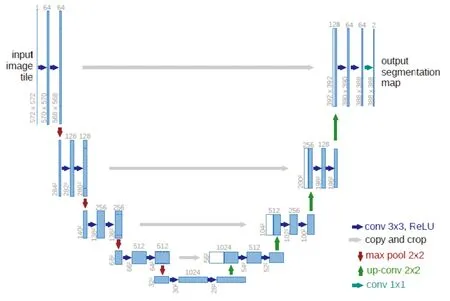
图2 U-Net网络结构图
从图2可以看出,整张图都是由蓝/白色框与各种颜色的箭头组成。其中,蓝/白色框表示特征图;蓝色箭头表示3×3卷积,用于特征提取;灰色箭头表示跳跃连接,用于特征融合;红色箭头表示池化,用于降低维度;绿色箭头表示上采样,用于恢复影像尺寸;青色箭头表示1×1卷积,用于输出结果。
2 数据与方法
2.1 试验区概况
选择两块典型区域作为试验区进行建筑物提取研究,分别位于河南省濮阳市台前县和信阳市罗山县,其中台前县位于河南东北部,豫鲁两省交界处,临河大堤把全县分为黄河滩区和北金堤滞洪区两部分,自然环境条件恶劣;罗山县位于河南省南部,大别山北麓,淮河南岸,水资源丰富,地势西南高、东北低,地形多样,从南至北分为山地、丘陵和平原。试验采用的数据是2017年多源遥感影像,其中台前县的投影坐标系为CGCS2000-3Degree-GK-Zone-38,罗山县的投影坐标系为CGCS2000-3Degree-GK-Zone-39。两幅影像质量较好,无条带影响,经匀光匀色、镶嵌拼接,重采样为分辨率1 m。其中,台前县和罗山县经裁剪后的试验区域大小均为2 000×2 000像素,如图3所示。

图3 裁剪试验图
2.2 总体技术路线
采用深度学习方法,基于Pytorch框架搭建U-Net网络模型,针对遥感影像进行建筑物的提取主要有5个步骤:影像预处理、样本库制作、网络训练与试验、样本更新、提取结果与精度验证。具体技术路线如图 4所示。

图4 技术路线图
2.3 样本库制作
以建筑物为目标,构建基于光学遥感影像的建筑物样本库。样本库包括样本影像与影像标签图(标签图中建筑物填充为白色,背景填充为黑色)。首先将已有建筑物数据与2017年遥感影像进行叠加分析,通过人工检查筛选出含有真实建筑的区域,经矢量栅格化,将建筑物内填充为白色,建筑物外填充为黑色,构建样本标签图,影像数据与标签图同步分块裁切为256×256大小。通过这样的操作,既可标准化样本,又可增大样本量,完成初步样本库的构建。
2.4 U-Net网络训练
本次试验基于 Ubuntu18.04 操作系统、两张NVIDIA显卡(24G 显存)的环境下运行,采用深度学习框架 Pytorch 实现 U-Net 网络模型。试验样本采用旋转、镜像和翻转等方式进行数据增强,样本量为16 000张256×256尺寸的图片,初始学习率为5e-4,批处理大小为64,训练迭代 100 次。
2.5 样本更新方法
样本对于试验结果至关重要。质量较好的样本库能够让模型快速收敛,获取较小的loss值和较高的整体精度。本试验的样本更新流程:首先,基于初步构建的样本库,进行网络初步训练,获得unet.pth;然后,用获得的初步模型,反过来对样本库进行分类,得到每个样本的提取精度,选取精度阈值,对低于阈值的样本,从样本库中剔除,逐样本遍历,更新样本库,总体循环三次,得到更为纯净的样本库,作为最终的网络模型训练输入。
2.6 精度验证指标
采用的分类精度评价指标为总体分类精度pOA和Kappa系数,搭配两者便于更加客观地对分类结果进行评价。总体分类精度是被正确分类的像元数和与总像元数的比值,是衡量分类结果正确程度的大小。其公式为:
(1)
其中:pii表示类别i正确分类的像元数;N为像元总数。
Kappa系数反映分类影像与参考影像之间的吻合程度,是检验二者一致性的客观评价标准。其公式为:
(2)
式中:ppi对应制图精度,为类别i真实参考的总像元数;pqi对应用户精度,为经分类器被分类为类别i的总像元数。
3 结果与讨论
3.1 不同方法结果对比
使用深度学习U-Net网络训练得到最优模型进行建筑物试验提取,其中深度学习U-Net网络的训练精度为98.7%,loss为0.011,模型在测试集上的精度为90%以上,说明此次模型对建筑物提取具有一定的可行性且精度很高。为验证建筑物提取的有效性,使用深度学习的方法对台前县和罗山县的试验区进行建筑物提取,并将提取的结果与最大似然分类方法和支持向量机(SVM)进行对比。其中,最大似然和SVM分类选用同样的样本,且样本选择要分布广泛,参数设置按照系统默认。三种建筑物提取方法如图5所示。

图5 三种不同建筑物提取方法成果图
采用目视解译的方法,对三种不同建筑物提取方法的结果进行分析。由分析结果可以看出,基于最大似然和SVM的方法,虽然能够提取出建筑物,但是存在误提和漏提的现象,容易将道路等与建筑物材质相近的区域误提为建筑物,且存在较多的“椒盐现象”。采用深度学习的方法能够有效避免道路和其他阴影造成的影响,建筑物提取精度更高,效果更好。
3.2 不同方法精度评定
使用ENVI软件采用地面真实分类图像进行混淆矩阵分析,不同建筑物提取方法精度评定结果如表1所示。对于台前县试验区,最大似然的方法总体精度为86.5%,Kappa系数为0.53;SVM的方法总体精度为87.5%,Kappa系数为0.59;本文深度学习的方法总体精度为94.3%,Kappa系数为0.83。对于罗山县试验区,最大似然的方法总体精度为80%,Kappa系数为0.48;SVM的方法总体精度为85%,Kappa系数为0.56;本文深度学习的方法总体精度为97.5%,Kappa系数为0.75。试验结果表明,在两个不同的试验区域,采用深度学习的方法总体精度和Kappa系数均高于其他两种方法。因此,采用本文方法进行建筑物的提取具有一定的可行性。

表1 三种建筑物提取方法的精度指标
4 结语
采用深度学习U-Net语义分割模型,选取台前和罗山县部分区域作为试验区,进行建筑物提取,并与最大似然和支持向量机(SVM)两种传统的方法进行对比。试验结果表明,采用U-Net进行建筑物提取,总体精度和Kappa系数均高于两种传统的方法,精度可达90%以上,这样的提取结果可应用于自然资源的动态监测、生态环境保护等领域。
当然,本文深度学习的方法也有一些不足之处:其一,本文方法主要适用于波段为RGB、分辨率为1 m的卫星遥感影像,对于其他影像数据的泛化能力不强;其二,本文方法依赖海量样本,但样本的制作耗费大量的人力和物力。另外,本文采用的深度学习方法仍然存在样本不足的情况,制约着模型的提取精度,这些问题都是以后研究的重点。
猜你喜欢
一重技术(2021年5期)2022-01-18
铁道建筑技术(2021年4期)2021-07-21
中学生数理化·高一版(2021年2期)2021-03-19
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
小学生学习指导(低年级)(2019年9期)2019-09-25
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
领导决策信息(2018年16期)2018-09-27
电子制作(2018年11期)2018-08-04
数学学习与研究(2017年3期)2017-03-09
