
基于场景识别的云制造服务推荐
2020-09-10 11:24:00郝予实范玉顺
计算机集成制造系统 2020年8期
郝予实,范玉顺
(清华大学 自动化系,北京 100084)
0 引言
近年来,随着互联网技术、云计算以及面向服务的体系架构(Service-Oriented Architecture, SOA)的迅猛发展,制造企业在经营模式和协作模式上正经历着深刻的变革,越来越多的制造企业由产品提供者的角色转化为服务提供者[1]。在这种背景下,云制造这一新型制造模式应运而生,并取得了长足的发展[2]。
在云制造模式下,越来越多的制造业企业将其制造资源(如制造设备、软件、知识、数据等)与制造能力(如生产能力、检测能力、设计能力等)以制造服务的形式发布到互联网上[3],第三方开发者借助云制造平台可以便捷地查找、使用和集成这些制造服务,以满足自身个性化的制造需求。因为单个制造服务往往仅能提供一种功能,而用户的制造需求一般具有较高的复杂性,所以在实际操作中,开发人员通常将多个制造服务组合使用,以满足用户复杂的个性化需求[4]。通过创建服务组合,制造服务的功能得以扩展和协作,从而提升了制造能力。大量的制造服务与服务组合、云制造体系下的各方参与者、服务与服务组合包含的大量信息及其之间复杂的关联关系共同构成了云制造服务系统[5]。
随着制造服务数量的不断增长,云制造服务系统出现了严重的信息过载问题,用户在从海量的制造服务中筛选合适的服务创建服务组合时遇到了较大的困难[6],在这种背景下,制造服务推荐算法获得了广泛的关注和研究。制造服务推荐算法旨在通过准确识别用户需求,自动地为用户推荐可能满足其需求的服务列表,从而帮助用户快速创建服务组合[7]。
现有的针对云制造服务系统和制造服务推荐算法的研究主要集中在以下方面:针对云制造服务系统,研究者主要关注云制造服务系统概念和架构、制造服务建模和分类、制造服务网络、制造服务评估和制造服务推荐等领域[8]。云制造服务系统概念和架构的研究旨在为云制造服务系统确立统一的概念和定义,并通过提出标准化的系统架构搭建云制造体系,为后续研究建立体系基础[9];制造服务建模和分类的研究主要聚焦于系统中的制造服务,研究者为制造服务建立统一的模型以对其进行规范化描述,然后基于服务的功能属性等进行服务分类,从而对系统中的制造服务进行管理[7, 10];制造服务网络的研究者将云制造服务系统中的服务关联关系抽象为网络化模型,利用网络分析的技术和手段对制造服务进行研究[11];制造服务评估旨在构建服务的信誉评价体系,其主要关注于识别和评价服务的各项服务质量(Quality of Service, QoS)指标[12-13];制造服务推荐算法是近年来研究的热门领域,也是本文的研究重点。早期的服务推荐算法主要利用语义匹配技术,通过匹配用户需求和服务描述文本的相似性进行推荐[14]。随着主题模型和协同过滤等算法的发展,研究者尝试利用各类主题模型对服务描述文本进行向量化,并且基于协同过滤的思想,利用服务历史组合记录的信息进行推荐[7, 15-16]。近期,各类复杂的推荐模型被相继提出,研究者从服务流行度分析、服务网络特性分析、服务演化特性分析等角度入手,构建了一系列复杂的制造服务推荐模型[17-18]。
虽然针对云制造服务系统和制造服务推荐算法的研究已经取得了一定进展,但是国内外研究者仍然忽视了两方面问题,从而限制了云制造服务系统的发展和制造服务推荐算法效果的提升。
(1)缺乏对已有服务组合应用场景信息的挖掘和组织 云制造服务系统现有的研究多聚焦于服务层面,对系统中服务组合蕴含的信息关注较少。现实中每一个服务组合都对应实际制造业务中的一个应用场景,该组合能够满足这一场景下的制造需求。通过挖掘和组织系统中已有服务组合的应用场景信息,云制造服务系统的运营者可以从场景的角度对系统内的服务与服务组合进行管理,进一步通过为各类应用场景建立特定的加权服务库来辅助服务推荐过程。
(2)缺乏对用户制造需求的应用场景信息的识别 当前的服务推荐算法均局限于从功能匹配的角度进行推荐,试图满足用户的各项功能需求,这些算法在提升推荐效果上遇到了瓶颈。实际上,用户的制造需求往往基于特定的应用场景,通过对需求的应用场景信息进行挖掘和识别,利用场景特性和场景加权服务库进行服务推荐可以大大提升制造服务推荐的效果。
针对以上问题,本文创新性地提出一种基于场景识别的云制造服务推荐(cloud manufacturing Service Recommendation Based on Scenario Recognition, SRSR)模型。SRSR模型首先对系统内原始服务组合描述进行重构,通过补充功能信息描述为每个服务组合建立场景综合描述文本;然后,利用主题模型和聚类分析等手段对服务组合的应用场景进行聚类,并为各类应用场景建立特定的加权服务库,从而实现了对服务组合场景信息的挖掘和组织;最后,通过对用户制造需求进行场景识别,利用各场景加权服务库为用户进行服务推荐。本文在实际数据集上对所提模型的推荐效果进行了验证,实验表明,SRSR模型用MAP(mean average precision)指标评估的综合推荐效果较当前最优模型提升了6.1%。
1 问题定义
本章将为云制造服务系统和制造服务推荐问题给出详细描述和数学定义,以利于后续讨论。
1.1 云制造服务系统
云制造服务系统内主要包括4类实体,分别为制造服务提供者、制造服务、开发者和服务组合。制造服务提供者将其拥有的制造资源与能力以制造服务的形式发布到云制造服务系统中。每个制造服务通常包括服务名称、服务标签、服务创建时间、服务描述等,其中服务描述是在服务发布时由服务提供者为其撰写的描述文本,通常包含对服务功能特性的介绍。开发者在系统内特指通过筛选制造服务创建服务组合,以满足复杂制造需求的人群。在实际系统中,开发者可以是服务系统的管理和运营者,可以是第三方的用户或客户,也可以同时是制造服务提供者,在本文讨论范围内不进行区分,均称为开发者或用户。服务组合指由开发者创建,集合多个制造服务以共同满足某一个性化制造需求的整体。每个服务组合通常包括服务组合名称、服务组合标签、服务组合创建时间、服务组合包含服务列表、服务组合描述等,其中服务组合描述是在服务组合创建时,由开发者为其撰写的描述文本,通常包含对服务组合应用背景与设计目标的介绍。
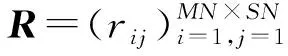
1.2 制造服务推荐
制造服务推荐问题指通过识别和分析用户的个性化制造需求,利用服务推荐算法在云制造服务系统中筛选可能满足需求的制造服务,以推荐服务列表的形式展现给用户,从而进行服务组合创建。因此,制造服务推荐算法的输入为用户的个性化制造需求,通常以一段文本描述的形式给出,算法的输出为一列带有顺序的服务列表,服务在列表中的排序越靠前,该服务越有可能满足用户的制造需求。
在云制造服务系统SS中,用集合Q表示不同用户的制造需求。对于每一个制造需求q∈Q,用一个含有nq个单词的集合QDq={wq1,wq2,…,wqnq}表示其需求描述,即用户输入的个性化制造需求。制造服务推荐算法针对需求q∈Q输出的带有顺序的服务列表用RLq表示。
2 模型架构与场景定义
为了更好地挖掘和组织服务组合应用场景信息,进而提升制造服务推荐的效果,本文提出一种SRSR模型。本章将从模型整体架构的层面入手,对SRSR模型的实现过程进行介绍,然后基于对模型的初步理解,明确场景的具体定义、表示和特征。
2.1 模型架构
SRSR模型的整体架构如图1所示。SRSR模型分为3个步骤:①利用云制造服务系统中的各描述信息与结构信息综合描述重构服务组合场景,得到各服务组合场景主题向量;②基于各服务组合场景主题向量进行场景聚类,聚类组织服务组合所代表的应用场景,为每类场景计算场景描述向量并建立加权服务库;③首先将用户制造需求向量化,然后识别用户需求的应用场景信息,最后利用各类场景加权服务库进行服务推荐,为用户推荐一列排序的服务列表。图1中不同线条的流程箭头表示模型不同的步骤。

步骤①的主要作用在于为系统内各服务组合建立场景主题向量,以供场景聚类使用。在云制造服务系统中,每一个服务组合对应一个实际的制造场景,通过识别和聚类各服务组合对应的场景,可以有效地组织和利用系统内的各类应用场景信息。为了实现这一目的,模型首先需要提取并整合各服务组合的场景信息,具体就是为各服务组合创建场景综合描述。实际上,各服务组合创立时,开发者已经为其撰写了一份描述文档,然而该原始描述通常着重于描述该服务组合的应用背景、设计目标和实现效果,对其所包含功能模块的介绍并不全面,为了构建场景综合描述,模型需要为原始服务组合描述补充功能信息描述。在各制造服务发布时,服务提供者会为其撰写一份功能描述文档,通过将服务组合所使用的各制造服务的描述引入原始服务组合描述,可为原始服务组合描述补充功能信息。采用这样的方式,步骤①通过对各服务组合原始描述进行重构获得各服务组合的场景综合描述(服务组合的场景综合描述在图中用RMDi表示,在后续章节中会给出RMDi的详细定义和计算过程)。然后,模型利用LDA(latent dirichlet allocation)主题模型[19]将各服务组合的场景综合描述向量化,得到各服务组合的场景主题向量。
步骤①为系统内各服务组合所对应的应用场景构建了主题向量。因为系统内服务组合之间可能存在相似的应用场景,其满足的制造需求类似,所以在步骤②中对各服务组合场景主题向量进行聚类,通过场景聚类来整合相似的应用场景、区分不同的应用场景。模型使用的聚类算法为改进的K-means聚类算法[20],通过调整迭代终止条件和类数设置,可以使聚类效果达到最佳。聚类后获得的每一类场景均包含一系列具有代表性的服务组合,通过计算这些服务组合场景主题向量的中心,可以得到该类场景的场景描述向量。另外,对场景中各服务组合所使用的制造服务进行统计,可以为各应用场景建立特定的加权服务库,服务的权重即为该场景下某一服务出现的总次数与该场景下所有服务出现的总次数的比值。综上所述,步骤②实现了对系统内各类应用场景的识别和组织,并为各场景建立了场景描述向量和加权服务库。
步骤③通过对用户制造需求进行场景识别,利用步骤②获得的各场景聚类结果和相应的加权服务库实现服务推荐。首先,模型对用户输入的制造需求进行向量化,利用LDA主题模型提取用户需求主题向量;然后,分别计算用户需求主题向量与各场景描述向量之间的JS(Jensen-Shannon divergence)散度[21],用以衡量用户需求场景与系统内各场景的相似度,从而识别用户需求场景;最后,利用用户需求场景与系统内各场景的相似度信息,结合各场景加权服务库计算各制造服务的推荐得分,为用户推荐一列带有顺序的制造服务列表,以满足用户的制造需求。
2.2 场景定义
本文提出“场景”这一抽象概念用以定义和描述服务组合的应用背景与环境属性。在服务系统中,每一个服务组合对应实际制造业务中的一个应用背景,服务组合在这一背景与环境下开展自身特定的功能,这一性质是服务组合的核心特性,本文使用场景的概念来表征服务组合的应用背景和环境属性。对于每一个服务组合个体,场景是其固有特性,然而该特性并不能从服务组合的显性信息中直接获取,需要算法的合理建模和挖掘。不同服务组合个体之间的应用场景既具有相关性又具有差异性,可以通过场景聚类分析对服务系统中的场景信息进行组织,从更高的维度理解服务系统中的场景信息。
用场景主题向量θi表示服务组合个体的场景,θi是一个多维向量,不同服务组合个体之间场景主题向量的相似性代表它们之间应用场景的相似性,其由服务组合的场景综合描述RMDi进行LDA主题建模得到。由于不同服务组合之间的场景可能具有相似性,算法基于各服务组合的场景主题向量θi对场景进行聚类(如图1),不同服务组合可能聚类为一个应用场景,通过计算每一类应用场景内的服务组合场景主题向量θi的中心,可以得出描述这一类场景的场景描述向量Centerk。另外,本文为每一类场景构建了加权服务库Libk,用以辅助服务推荐过程。
3 基于场景识别的云制造服务推荐
本章将对SRSR模型的实现过程进行分步骤详细介绍,并给出数学计算过程。
3.1 服务组合场景主题向量的构建
为了识别各服务组合对应的应用场景,利用云制造服务系统中的服务与服务组合的原始描述信息和历史组合记录信息对原始服务组合描述进行重构,从而为各服务组合建立场景综合描述。原始服务组合描述主要描述该服务组合的应用背景、设计目标和实现效果,而服务描述详细介绍了服务实现的功能。因此,引入服务描述信息可以补充原始服务组合描述中缺失的功能模块信息,进而构建服务组合场景综合描述。
根据前文定义,每一个服务组合mi∈M的历史组合记录可以用向量(ri1,ri2,…,riSN)表示,其中rij=1表示服务组合mi使用了服务sj。为了建立服务组合mi的场景综合描述,采用以下公式对其进行描述重构:
mi∈M。
(1)

LDA主题模型[19]认为一段文本的词汇生成过程由这段文本的潜在主题指导,文本的主题信息及各主题的权重则从抽象的层面代表文本更为本质的特征。因此,本文使用LDA主题模型对描述文本进行建模,提取各描述的潜在主题特征对描述文本进行向量化,以便后续分析使用。对于服务组合集合M={m1,m2,…,mMN},各服务组合的场景综合描述RMDi={wi1,wi2,…,win}的生成过程建模如下:模型中的每一个主题k=1,2,…,T均对应一个单词概率分布Φk~Dirichlet(β),即在该主题下单词的分布规律;而模型中的每一个服务组合mi∈M均对应一个主题概率分布θi~Dirichlet(α)。服务组合描述中的每一个单词w∈RMDi的产生过程首先是选取一个主题z~Multinomial(θi),然后在这一主题下产生这一单词w~Multinomial(Φz)。其中:T为主题数量;Φk为主题k下的单词多项式分布;θi为服务组合mi下的主题多项式分布;α和β分别是θi和Φk服从的狄利克雷分布的超参数。

(2)
至此实现了对各服务组合场景综合描述的向量化和主题特征提取,为各服务组合mi建立了场景主题向量θi。
3.2 云制造服务系统场景聚类
无论系统中已经创建的服务组合,还是用户新提出的制造需求,均对应于某一特定的应用场景。通过聚类组织云制造服务系统中的各类应用场景发现各类应用场景的特征,可以帮助系统运营者和开发者从场景的角度更好地理解制造需求。通过为每一场景建立场景描述向量和加权服务库,可以更好地刻画各场景的信息,从而提升制造服务推荐的效果。
下面采用改进的K-means聚类算法[20]对各服务组合mi的场景主题向量θi进行聚类,从而对服务系统进行场景聚类。传统的K-means算法进行聚类中心初始化时采用随机设置聚类中心的方式,然而随机设置的聚类中心往往质量较差,导致聚类结果较差或陷入局部最优解。本文认为场景主题向量之间越相似,越不可能同时成为聚类中心[23],基于此,本文的聚类中心初始化过程如下:
(1)随机选取一个样本点作为初始聚类中心Center1。
(2)计算每个样本点与最近的已有聚类中心的距离,该距离表示为D(θi)。
2016年7月4日傍晚,受强对流云团影响,出现一次明显雷雨大风过程。各站点强对流影响时段各风速值(表6)表明,国家站与浮标站风速情况较为接近,整体4个站点一致性较差,这也从一定层面反映出,当出现局地性突发性大风过程的时候,浮标站的阵风情况存在一定偶然性,视大风具体发展情况而定。而发生过程性大风过程,例如台风、冷空气影响时,浮标站往往与新沙岛站风速情况拟合程度较好,而国家站的风速则会大于其它3个站点。
(3)计算每个样本点被选为下一个聚类中心的概率P(θi),根据该概率选择出下一个聚类中心。
(4)重复(2)和(3),直到选择出K个聚类中心。
过程(2)采用欧氏距离计算两个样本点之间的距离,两个样本点的欧氏距离
(3)
过程(3)中的概率
(4)
过程(4)中,K为初始化设置的聚类中心个数,初始化完成后,得到的聚类中心集合记为Center={Center1,Center2,…,CenterK}。
完成聚类中心初始化后,算法通过反复迭代完成聚类,每次迭代过程如下:
(1)根据式(3)计算每一个样本点与各个聚类中心的距离dist(θi,Centerk)。
(2)将每一个样本点θi划分至距离其最近的聚类中心所对应的类中。
(3)根据划分结果更新各类聚类中心。
过程(3)更新各类聚类中心所采用的公式为
(5)
式中:Ck表示第k类;θi∈Ck为第k类中的所有样本;|Ck|为第k类中的样本个数。过程(4)中的迭代终止条件有两种:①达到预先设置的迭代次数的上限Nm;②两次迭代的误差平方和准则函数J的差值ΔJ小于预先设置的阈值δ,即ΔJ<δ。如果达到两种终止条件的一种,则聚类算法停止,得到的各聚类中心及各样本聚类结果即为最终结果;如果没有达到终止条件,则算法继续迭代,直至达到某一迭代终止条件为止。误差平方和准则函数模型为
(6)
完成场景聚类后,为每个场景建立加权服务库。对于任一场景k,服务系统中每个服务在该场景下的权重
(7)
式中:mi∈Ck表示聚类至场景k中的所有服务组合;sj_weightk表示服务sj在场景k下的权重,若sj_weightk>0,则将服务sj加入场景k的服务库,sj在场景k的服务库中的权重即为sj_weightk。完成所有场景和服务的计算,即可为每一场景建立加权服务库。
至此,完成了服务系统场景聚类和加权服务库的构建。通过聚类,共获得K类应用场景,Ck表示第k类场景,Centerk表示第k类场景的中心,即第k类场景的场景描述向量,Centerk根据最终的聚类结果,利用式(5)计算得到。对每一个应用场景k建立加权服务库,记为Libk={s1(s1_weightk),s2(s2_weightk),…,sSN_k(sSN_k_weightk)},其中:Libk表示场景k的加权服务库;si表示服务库中的各服务;si_weightk为服务si在场景k下对应的权重;SN_k为场景k的加权服务库中的服务数量。
3.3 制造服务推荐
本节基于前期挖掘得到的服务系统场景聚类信息、各场景描述向量和各场景加权服务库,通过识别用户制造需求的场景进行服务推荐。

θm=(Centerk+θq)/2;
JSD(Centerk||θq)=(KLD(Centerk||θm)+
KLD(θq||θm))/2。
(8)
JSD(Centerk||θq)的值越小,表示用户需求主题向量θq与场景描述向量Centerk的相似度越高,用户需求场景更可能接近场景k。
以上步骤实现了对用户需求的场景识别,下面利用用户需求场景与各场景的相似度和各场景的加权服务库,计算服务系统中各服务si∈S的推荐得分scorei,
(9)
式中:ILibk(si)为示性函数,当si∈Libk时,ILibk(si)=1;当si∉Libk时,ILibk(si)=0。因为JSD(Centerk||θq)的值越小表示相似度越高,所以在式中取倒数。scorei表示服务si的推荐得分,其值越高,表示服务si越可能满足用户的需求。
计算系统中所有服务si∈S的推荐得分,按照推荐得分scorei的大小由高到低对所有服务进行排序,生成一个推荐服务列表RLq输出给用户。至此,基于对服务系统和用户需求的场景识别完成了对用户个性化制造需求q的制造服务推荐。
4 实验设计与结果分析
4.1 实验数据集
ProgrammableWeb.com(1)http://www.programmableweb.com是迄今为止最大的服务和服务组合在线资源库,虽然ProgrammableWeb.com并非专门的制造服务数据集,但其包含的信息、服务组合关系和拓扑结构均与制造服务数据集一致。与制造服务数据集一样,ProgrammableWeb.com中的服务包括名称、提供者、类别、发布日期、标签和服务描述等信息,其中的服务组合包括名称、创建日期、开发者、调用服务列表和服务组合描述等信息。因此,本文采用ProgrammableWeb.com数据集验证制造服务推荐算法的效果。
爬取ProgrammableWeb.com资源库上自2005年9月~2016年6月的全部服务和服务组合数据,共计服务13 269个,服务组合5 840个,各类描述文本总词汇量为21 891个。其中,服务与服务组合的描述文本在实验前进行了必要的预处理和数据清洗[24],如分词、停止词去除、词干提取等,处理后的描述文本以词向量的形式作为算法的输入,称该词向量为原始描述。
4.2 评估指标
本文采用在推荐算法领域被广泛接受的评估指标MAP@N(Mean Average Precision @ top N)来评估制造服务推荐算法的推荐效果,该指标定义为
(10)
式中:|Q|表示参与评估的制造需求的数量;Sq为需求q∈Q实际使用的服务集合;Nq=min{N,|Sq|},N表示取推荐列表的前N项进行评估。对于每个服务s∈Sq,r(q,s)表示服务s在推荐列表中的排位,将Sq中的服务按照其在推荐列表中出现的顺序排列,n(q,s)为服务s在该列表中的排位。当r(q,s)≤N时,I(q,s)=1;当r(q,s)>N时,I(q,s)=0。当N值取整个推荐列表的长度时,MAP@N值通常用符号MAP@J表示。
MAP@N的取值范围为[0,1],其值越接近1,表示推荐算法的推荐效果越好。
4.3 对比方法
本文选取6种对比方法和所提推荐算法进行比较分析。
4.3.1 服务端主题匹配(SDCM)
服务端主题匹配(Service-Description-based Content Matching,SDCM)是文献[25]中提出的推荐算法,算法应用LDA概率模型对服务与用户需求进行建模,提取服务与用户需求的潜在主题特征,并基于主题特征的匹配展开推荐。通过对服务描述生成过程进行建模,算法推测出服务的主题概率分布p(t|s)与主题的单词概率分布p(w|t),依此计算服务针对用户需求q的推荐得分,计算公式如下:
(11)
SDCM仅依赖于服务端信息进行推荐,并未对服务组合的模式进行挖掘分析,本文利用该对比方法佐证挖掘服务组合模式的重要性与基于场景识别推荐的优势。
4.3.2 服务组合端协同过滤(MDCF)
服务组合端协同过滤(Mashup-Description-based Collaborative Filtering,MDCF)算法立足于传统的邻域协同过滤思想,认为相似的服务组合往往倾向于使用相似的服务。MDCF算法利用LDA主题模型对服务组合与用户需求进行建模,获取其主题特征向量,并根据服务组合与用户需求的主题向量相似度匹配计算各服务的推荐得分,计算公式如下:
(12)
式中:U(N,q)为与需求q相似度最高的N个服务组合的集合;sim(q,mj)计算用户需求q与服务组合mj之间主题特征向量的余弦相似度。
4.3.3 LDA+矩阵分解(MF)
LDA+矩阵分解(Matrix Factorization,MF)算法首先利用LDA主题模型计算服务组合与用户需求的主题特征向量,然后通过求解以下优化问题对矩阵R进行分解:
(13)
各服务推荐得分计算如下:
score(q,si)=ζTvi。
(14)
式中ηj和ζ为由LDA模型得出的主题特征向量。
MDCF和MF算法分别是传统协同过滤和矩阵分解算法的扩展方法,它们在实践中均被证明有较好的推荐效果并被广泛应用。
4.3.4 基于服务领域聚类的服务推荐(DTM)
基于服务领域聚类的服务推荐(Domain Topic Matching,DTM)是文献[26]中提出的推荐算法,该算法意识到服务可以划分至不同的功能领域,从服务领域聚类的角度出发进行服务推荐。算法首先根据服务描述信息对服务进行功能领域聚类,将服务系统中的服务划分至不同的功能域;然后,算法应用极限学习机(Extreme Learning Machine,ELM)工具分别训练需求—功能领域、功能领域—服务两个识别器,实现用户需求到所需服务的映射。DTM模型的详细介绍、计算过程和参数设置等可参阅文献[26]。
DTM模型在实际应用中取得了很好的推荐效果,被视为当前最先进的推荐算法之一。通过与DTM模型进行对比,本文试图评估所提SRSR模型相比当前最优模型在推荐效果上提升的幅度,并分析场景识别与聚类的模式相比服务功能领域聚类的模式是否具有更强的实际意义和更好的推荐效果。
4.3.5 基于服务组合描述重构的服务推荐
对比方法基于服务组合描述重构的服务推荐(SRSR_变体1)是本文提出的SRSR模型的变体,该方法省略了服务组合应用场景聚类的过程,仅利用服务组合描述的功能信息重构结果进行推荐。算法前期的服务组合描述重构过程、LDA主题特征提取过程均与SRSR模型一致,在获得服务组合主题向量θj和用户需求主题向量θq后,直接应用JS散度衡量二者相似度,并利用该相似度信息计算各服务的推荐得分,计算公式为
si∈S。
(15)
作为SRSR模型的简化版本,该方法除了不具备场景识别与聚类模块,其他部分与SRSR模型处理相同。本文采用该方法作为对比方法,证明所提场景识别思想的有效性,并证明通过对服务系统的应用场景进行识别和组织以及对用户需求场景进行识别和匹配可以大大提升推荐算法的效果。
4.3.6 基于服务组合聚类的服务推荐
对比方法基于服务组合聚类的服务推荐(SRSR_变体2)也是本文提出的SRSR模型的变体,该方法省略了服务组合描述功能信息重构的过程,以服务组合的原始描述信息作为其场景描述进行处理。算法后期的应用场景识别与聚类、用户需求场景识别与匹配等过程均与SRSR模型一致,不同之处在于该算法以服务组合的原始描述信息作为其场景描述,直接提取LDA主题,并将基于原始描述提取的主题向量作为后续聚类模块的输入。
作为SRSR模型的另一种简化版本,该方法除了不具备服务组合描述功能信息重构模块,其他部分与SRSR模型处理相同。本文采用该方法作为对比方法,证明通过补充功能信息描述对服务组合的原始描述进行重构可以提升服务组合描述的质量和信息含量,进而证明建立服务组合的场景综合描述可以提升算法的推荐效果。
4.4 实验结果分析
4.4.1 实验设置
数据集中的每一个服务组合均含有其创建时间,实验将测试时间窗口设置为一个月,并令其逐月向前移动,当时间窗口移动到某一个月时,将当月新创建的服务组合作为测试集,该月之前创建的服务组合作为训练集。训练集中的服务组合数据参与模型训练,测试集中的服务组合数据用以测试推荐效果,其中测试集服务组合描述文本被视为用户输入的制造需求,将这些服务组合实际所使用的服务列表作为推荐算法的理论真实值。在实验中,将测试时间窗口从2013年7月逐月移动至2016年6月,共获得36个MAP@N评估结果,将这36个MAP@N结果根据各自的测试集服务组合数量进行加权平均,最终的加权平均值为各推荐算法的MAP@N评估结果。实验通过对近三年的数据进行逐月测试,充分评估了各推荐算法的效果,最终获得的加权平均MAP@N结果可用于比较各算法的推荐效果。
实验参数设置如下:在SRSR模型中,根据经验,设置狄利克雷分布超参数α=50/T,β=0.01,聚类算法迭代次数的上限Nm=500,聚类算法迭代的终止阈值δ=0.000 01;经过参数寻优,设置LDA模型主题数T=50,吉布斯采样迭代次数Niter=1 000,聚类算法聚类中心的个数K=35。各对比方法的实验参数均设置为其最优参数。
4.4.2 实验示例
本节选取一个实例进一步说明数据集的特征以及SRSR模型的具体训练和预测步骤。以ProgrammableWeb.com上的服务组合MultCloud,Cloud Elements,Rainbow Data Sync为例,直观地展示模型的执行过程,这3个服务组合都属于“企业云端文档管理”应用场景。以MultCloud和Cloud Elements为训练集,以Rainbow Data Sync为测试集。所利用的从ProgrammableWeb.com上爬取的服务数据主要有服务名称、发布日期和服务描述,服务组合的数据主要有服务组合名称、创建日期、调用服务列表和服务组合描述,以上描述均为文本形式。
模型的训练步骤如下:
(1)MultCloud和Cloud Elements的原始数据包括一段文本形式的描述,经过数据集预处理和数据清洗后,获得两个21 891维的描述词向量,向量的每一项代表一个单词,每一项的值代表描述文本中对应单词的出现次数。
(2)算法进行服务组合描述重构,将MultCloud和Cloud Elements使用的服务的描述词向量重构入其原始描述词向量,特别地,MultCloud和Cloud Elements均使用了服务Box,因此Box的描述词向量会被同时引入MultCloud和Cloud Elements的词向量。经过重构后,每个服务组合获得了一个重构后的描述词向量,即场景综合描述。
(3)算法利用LDA模型提取词向量的主题特征,为各服务组合建立场景主题向量,根据参数设定,服务组合的场景主题向量为50维向量。
(4)算法对所有服务组合的场景主题向量进行场景聚类,根据参数设定,所有服务组合被聚类为35类。由于MultCloud和Cloud Elements的场景具有高度相似性,其中MultCloud帮助企业在云端移动、编辑、组合和存储文档,Cloud Elements帮助企业实现云存储、消息传递和文档共享,因此MultCloud和Cloud Elements被聚类到一个场景下。
(5)算法为每个场景计算场景描述向量和加权服务库。可以发现,MultCloud和Cloud Elements所在场景类别中的服务组合多是“企业云端文档管理”领域下的服务组合,因此将该场景命名为“文档管理”场景。因为该场景下的服务组合很多都使用了服务Box,Box是一个企业云端文档和内容管理平台,所以在“文档管理”场景下,Box服务在其加权服务库中拥有很高的权重,被认为很适合该场景。
在预测阶段,Rainbow Data Sync的描述文本被作为用户需求输入到模型。同样经过预处理和LDA主题特征提取后,可以获得Rainbow Data Sync的50维主题向量。算法将Rainbow Data Sync的主题向量与35类场景的场景描述向量进行相似性匹配。因为Rainbow Data Sync实现的是企业在云端的数据与文档共享、同步和传输,经过计算,Rainbow Data Sync与“文档管理”场景的相似性最高,而在“文档管理”场景加权服务库中,Box服务又具有最高权重,所以在计算各服务的推荐得分后,Box服务获得最高分数,在最终的推荐服务列表中排在第一位。实际上,服务组合Rainbow Data Sync的确使用了Box服务,从而证明本文的推荐结果是有意义的,也证明了所提出模型的有效性。
4.4.3 结果分析
图2所示为SRSR模型及对比方法1~4(SDCM,MDCF,MF,DTM)的MAP@N实验结果,横坐标取值对应取不同长度的推荐列表,纵坐标表示各算法的MAP@N结果。

SDCM算法仅依赖服务端的信息进行挖掘推荐,其通过挖掘服务描述的潜在主题特征与用户需求进行匹配。然而,该算法并没有考虑和利用服务的历史组合规律,由于服务的历史组合记录和服务组合的描述文本中均含有大量有价值的信息,SDCM算法的效果显著差于其他对比方法。由此可见,服务的历史组合记录中蕴含由丰富的价值信息,挖掘和利用服务系统中服务组合端的信息很有意义。本文从服务组合端入手,构建服务系统的场景识别体系正依赖于这些价值信息。
MDCF与MF算法均利用服务组合端和服务的历史组合记录展开推荐,因此其推荐效果均优于SDCM。然而,这两种算法将服务系统中的各服务组合视为独立的个体,在构建推荐模型时并未挖掘和利用服务组合之间的潜在逻辑关系,不能发现服务系统内部潜在的应用场景信息,其推荐模式仍停留在服务个体和服务组合个体层面,不能从场景的角度看待用户需求并进行推荐,因此其推荐效果仍差于其他算法。
DTM算法从服务系统中服务个体之间功能属性联系的角度出发,通过服务功能领域聚类对系统内的服务个体进行再组织,并通过对用户需求进行功能领域分解展开服务推荐。然而,DTM算法对服务系统的组织仍停留在服务功能层面,未能挖掘和管理服务系统中潜在的应用场景信息,也不能很好地识别用户需求的应用场景信息,因此其推荐效果仍落后于SRSR模型。DTM算法在实际应用中取得了很好的推荐效果[26],被视为当前最先进的推荐算法之一,而本文所提SRSR模型的推荐效果显著优于DTM算法,证明SRSR模型较当前最优模型在推荐效果上有显著提升,也证明了场景识别与聚类的模式相比服务功能领域聚类的模式具有更强的实际意义和更好的推荐效果。
图3所示为SRSR模型和SRSR模型的两个变体模型的MAP@N实验结果,其坐标含义与图2相同。

SRSR_变体1模型去除了SRSR模型中场景识别与聚类的模块,其他部分与SRSR模型相同。因此该模型既不能挖掘和组织服务系统中的应用场景信息,也不能识别用户需求的应用场景,从推荐效果上看,其MAP@N值显著低于SRSR模型。由此证明了本文所提场景识别思想的有效性,通过对服务系统的应用场景进行识别和组织并对用户需求场景进行识别和匹配可以大大提升推荐算法的效果。另外,虽然SRSR_变体1模型与MDCF算法、MF算法都是从服务组合个体层面出发展开推荐,但是因为SRSR_变体1模型增加了服务组合描述功能信息重构,通过重构为服务组合描述增添了功能信息,所以其推荐效果优于MDCF和MF算法。
SRSR_变体2模型去除了SRSR模型中的服务组合描述功能信息重构模块,其他部分与SRSR模型一致。因此该模型不能为原始服务组合描述补充功能信息,即不能为服务组合建立场景综合描述,从推荐效果上看,其MAP@N值低于SRSR模型。由此证明,对服务组合的原始描述信息进行重构,通过补充功能信息描述为每个服务组合建立场景综合描述文本,可以提升服务组合描述的质量和信息含量,进而证明建立服务组合的场景综合描述可以提升算法的推荐效果。
综上所述,SRSR模型的推荐效果显著优于所有对比实验,这得益于SRSR模型能够从应用场景的层面理解和组织服务系统与用户需求。SRSR模型首先对服务组合描述信息进行重构,通过补充功能描述为各服务组合建立场景综合描述文本,进而采用场景聚类挖掘和组织服务系统内的应用场景信息,最终从场景的角度理解和识别用户需求,并利用各场景加权服务库开展服务推荐。以上过程克服了传统推荐算法不能识别服务系统及用户需求场景信息的不足,取得了最优的推荐效果。
表1所示为SRSR模型及各对比方法的具体实验结果。比较SRSR模型与DTM模型结果可知,SRSR模型推荐效果较当前最优方法提升了6.1%,这得益于对服务系统场景信息的挖掘和利用;比较SRSR模型与SRSR_变体2模型结果可知,通过进行服务组合描述重构和构建服务组合场景综合描述,可以使推荐效果提升4.0%;比较SRSR模型与SRSR_变体1模型结果可知,通过对服务系统和用户需求场景信息进行识别,可以使推荐效果提升11.1%。
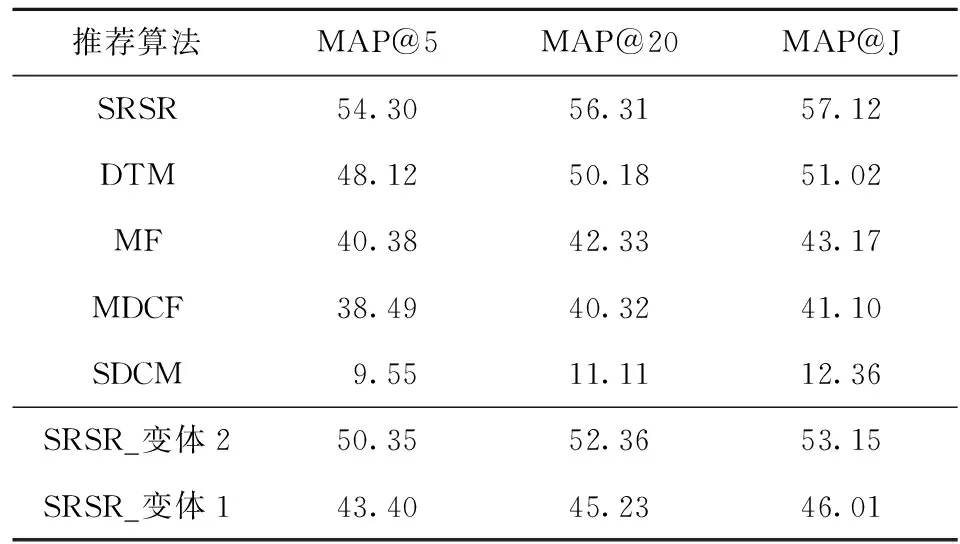
表1 SRSR模型及各对比方法MAP@N实验结果 %
4.4.4 参数讨论
K为场景聚类模块执行时预先设置的聚类中心个数,该值由算法执行者设定,因为事先并不知道该服务系统中应用场景的类别数,所以需要通过参数调整实验寻找其最优取值。如果K值设置过小,则可能将不同类的场景聚为一类;如果K值设置过大,则可能将同一个场景进行无谓的拆分,这些均会影响算法效果。图4所示为参数寻优的实验过程,横坐标表示K值的不同取值变化,纵坐标表示不同K值所对应的MAP@J指标结果,同时模型其他参数均设置为最优值。从图中可见,MAP@J的变化趋势为随着K的增大先增后减,当K=35时,MAP@J指标取得最大值,即推荐算法效果最好,因此认为该服务系统应用场景的类别数为35,后续实验均设置K=35。

5 结束语
近年来,随着云计算和SOA体系架构的迅猛发展,网络化制造与云制造的概念和技术均获得了广泛关注和应用,越来越多的制造业企业开始将其拥有的制造资源、制造能力以制造服务的形式进行封装,并发布到互联网上,构成了复杂的云制造服务系统。制造用户与开发者可以在云制造服务系统中便捷地查询、筛选和组合这些制造服务,构建个性化的制造服务组合以满足其复杂的制造需求。通过构建制造服务组合,系统中的服务实现了功能协作与扩展,可以快速满足更加个性化和复杂的制造需求,增强了云制造服务系统的生命力。然而,随着信息过载问题的日益严重,对精准的制造服务推荐算法的需求日益增加,现有的制造服务推荐算法研究主要聚焦于服务个体功能的层面,既不能挖掘和组织服务系统应用场景信息,也不能从场景识别的角度解构制造需求,限制了服务系统与制造服务推荐算法的发展。
本文从服务系统场景信息的挖掘与组织、用户需求场景信息的识别与匹配的角度出发,提出一种SRSR模型。首先对系统内原始服务组合描述进行功能信息重构,为每个服务组合建立场景综合描述文本;然后利用主题建模与场景聚类的方式对服务系统的应用场景信息进行挖掘和聚类,从场景的角度组织和管理服务系统的信息。在识别出服务系统场景类别后,模型为各类应用场景建立了特定的加权服务库,并通过对用户制造需求进行场景识别来开展服务推荐。最后通过在实际数据集上的综合实验表明,SRSR模型用MAP@N指标评估的综合推荐效果较当前最优模型提升了6.1%。
随着新的制造服务的不断增加,如何对没有历史使用记录的冷启动服务进行推荐是亟待解决的问题。笔者拟挖掘服务之间的协作属性关系,对冷启动服务的组合模式进行预测,以对没有历史使用记录的冷启动服务进行合理推荐。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
成都信息工程大学学报(2019年4期)2019-11-04 00:56:02
阅读与作文(英语初中版)(2019年8期)2019-08-27 03:59:25
小学生学习指导(低年级)(2018年11期)2018-12-03 05:05:00
电子测试(2017年15期)2017-12-18 07:19:27
现代防御技术(2016年1期)2016-06-01 12:13:27
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
智能系统学报(2015年4期)2015-12-27 09:38:39
新高考·高二数学(2015年11期)2015-12-23 18:17:44
