
基于CAE与LSTM的航空发动机剩余寿命预测
2020-09-08 08:17王旭,艾红
北京信息科技大学学报(自然科学版) 2020年4期
王 旭,艾 红
(北京信息科技大学 自动化学院,北京 100192)
0 引言
发动机作为航空飞机的动力源,对飞行安全性至关重要。早期,飞机在飞行之前,需要进行全面检修以保证飞行安全,而高频的维护工作,使得维护成本占据了总成本的70%。因此,在保证安全性前提下,为了降低维护成本,避免“维护过度”,1980年英国CAA提出了故障预测与健康管理技术(prognosis and health management,PHM)[1],在故障发生之前进行剩余寿命(remaining useful life,RUL)预测[2],以做到实时维护,防止故障的发生。
剩余寿命预测主要采用基于失效机理和基于数据驱动,以及两者相融合的方法[3]。近些年,机器学习[4]成为数据驱动的主流方法,其中又以深度学习的方法最受关注。它能有效提取海量数据特征,获得与剩余寿命的表征关系。研究表明深度学习方法比浅层机器学习预测精度更高。Babu等[5]提出基于卷积神经网络(convolutional neural network,CNN)的RUL预测模型;Yuan等[6]采用多种循坏神经网络(recurrent neural network,RNN)对航空发动机进行RUL预测,发现长短期记忆(long short-term memory,LSTM)网络模型预测性能较好;Zheng等[7]提出深层LSTM结构,通过多层LSTM堆叠提高RUL预测精度。航空发动机结构复杂,状态监测变量类型多,获得的监测数据维度高、数量大。为降低计算复杂度,常需要进行维度约减。传统的降维方法有主成分分析(principal components analysis,PCA)[8],此外也有自编码器(Autoencoder)等深度学习的方法。Hinton等[9]研究表明Autoencoder降维比PCA效果更优。Malhotra 等[10]结合PCA技术与LSTM自编码网络模型构造健康因子(health indicator,HI)[11],以HI曲线表征发动机退化程度。
本文提出的航空发动机间接预测方法,首先运用卷积自编码器(convolutional autoencoder,CAE)网络将多维状态监测变量编码为一维,以作为航空发动机的HI,其次将HI时间序列输入LSTM模型,实现HI与RUL的特征映射,提高了预测精度。
1 模型构建
1.1 卷积自编码器
自编码器是一种自监督的算法,其标签产生自输入数据。它通过优化参数,使其编码层输入与解码层输出之间的重构误差最小化,以取得低维数据表征高维数据特征。CNN网络是由多层卷积、池化操作构成,并通过局部连接、权值共享的方法实现特征提取,特别是在捕捉图像特征上表现非凡。因此,将CNN与Autoencoder相结合的CAE网络模型用于提取特征更加优异。
传统自编码器隐藏单元之间使用的是全连接方式。CAE模型在继承传统自编码自监督的基础上,将自编码器中的隐藏神经元之间的矩阵乘积运算替换为卷积、池化运算,以用来捕捉状态监测数据的内在特征。CAE模型编码和解码过程通常采用对称结构。编码包括多层卷积和池化操作,对应解码过程中上采样与卷积操作,如图1所示。本文采用滑动时间窗口构造CAE输入样本。
设每个发动机单元具有m个监测变量,则某个发动机单元在时刻t所采集的数据可表示为
(1)
设时间滑动窗口为T,构造卷积自编码输入为
X=[Xt,Xt+1,…,Xt+T-1]
(2)
则编码输出可表示为
hk=f(X·Wk+bk)
(3)
式中:Wk为第k个卷积核参数矩阵;“·”代表卷积运算;bk为卷积偏置项;f为非线性激活函数。将得到的编码hk进行特征重构,其解码输出为
(4)
损失函数定义为
(5)
式中:N为批量大小,每输入N个样本更新一次参数。
1.2 长短期记忆网络
LSTM是RNN的变体,RNN是一种特殊的神经网络,与深度神经网络(deep neural network,DNN)和CNN不同,它具有记忆功能,其当前时刻的输出不只是与当前时刻的输入有关,而且记忆了上一时刻输出的信息,因此RNN对时间序列问题处理效果较好。但它对于长时间序列存在长期依赖问题,在反向传播更新参数过程中,也会出现梯度消失和爆炸问题。
为解决此类问题,国外学者提出了RNN的变体结构LSTM。它是拥有3种“门”的特殊网络结构,解决了时间序列长期依赖问题,在自然语言处理、机器翻译等领域应用广泛。航空飞机在每次运行周期内所采集的状态监测数据可看作时间序列数据,可将LSTM应用于航空发动机的剩余寿命预测。门结构的实质是使用sigmoid作为激活函数,使得全连接网络层输出0到1之间的数值,描述信息量通过的比例,遗忘门表示上时刻输出信息量的遗忘比例,输入门表示当前时刻输入信息量的保留比例,两者共同更新状态值,输出门则表示新状态输出比例。
LSTM的内部结构如图2所示。图2中xt为当前输入,ht-1为上一时刻的输出。ct为新状态值,ct-1为上一时刻的状态值。
输入状态为
zt=tanh(Wzxt+Uzht-1+bz)
(6)
输入门为
it=σ(Wixt+Uiht-1+bi)
(7)
遗忘门为
ft=σ(Wfxt+Ufht-1+bf)
(8)
当前状态为
ct=ft*ct-1+it*zt
(9)
输出门为
ot=σ(Woxt+Uoht-1+bo)
(10)
当前输出为
ht=ot*tanh(ct)
(11)
式中:xt为当前时刻的输入,大小为m×1,m为监测变量数目;Wz、Wi、Wf、Wo为输入的权值矩阵,大小为1×m;Uz、Ui、Uf、Uo为循环权重;bz、bi、bf、bo为偏置值;σ为sigmoid函数;*代表数值乘积运算。
1.3 CAE-LSTM混合模型
本文提出的CAE-LSTM混合模型,包括两方面内容:针对复杂设备数学模型难建立问题,首先使用CAE进行无监督学习,不仅能达到降维的目的,而且能表征设备的退化趋势,可作为发动机的HI值;其次将发动机单元的HI序列值输入LSTM,建立RUL序列的特征关系。图3为CAE-LSTM混合模型结构,该模型对于评估复杂设备的健康状况以及预测剩余寿命具有通用性。
在CAE编码部分,卷积层用于特征提取,池化层用于降维。在解码部分,进行上采样,卷积操作,以恢复原始数据。编码输出为HI序列,作为LSTM的后续输入。
本文采用多层LSTM堆叠的结构,能更高层次地提取特征。首层LSTM在每个时间步输出结果,将返回的时间序列输入第二层LSTM,该层只返回最后时间步结果,在LSTM层后添加全连接,使输出的特征维度为一维。为防止模型过拟合,本文模型加入了随机丢弃层,丢弃概率设置为0.2,即在每次迭代中隐藏神经元以1/5概率随机抑制。
2 实验
2.1 数据集
本课题以涡扇发动机为研究对象,采用NASA卓越故障预测研究中心(Prognostics Center of Excellence,PCoE)提供的飞机发动机仿真状态监测公开数据[12]。它是通过CMAPSS软件模拟发动机不同的运行环境,输出各部件在退化过程中的状态监测数据,在设备剩余寿命预测的研究领域,被广泛作为基准数据。该数据集有3类子集,训练集和测试集中选取了21种传感器信号及3种运行参数,训练集包括了涡轮发动机从初始状态到首次故障的整个退化过程的监测数据,测试集记录了从初始状态到故障之前的某个周期之间的监测数据,剩余寿命集给出了测试集发动机运行到故障的剩余周期。
2.2 数据预处理
由于发动机性能变量选取的多样性,传感器采集的数据量纲不统一,数据在输入模型前需要归一化处理,且使处理后的数据不改变传感器数据的退化特征。本文采用最值归一化,将各传感器序列按照如下方式处理:
(12)

在21种性能变量中,采集的传感器数据并非都具有趋势性,整个退化过程中基本维持不变的变量,对模型的训练可能会产生负面影响,本文给予剔除。在数据集中,没有直接给出各个运行周期的RUL值,需要自行设置。本文的RUL值设置为分段线性函数,如图4所示。首先将运行周期的次大值设置为首次运行周期的RUL,然后在此基础上依次递减至0,分别作为各个周期的RUL值。由于发动机在退化初期,其各变量数据基本维持不变,为了提高模型预测的准确性,将RUL进行裁剪,由于发动机的平均寿命为125左右,故裁剪阈值设置为125。
本文选择滑窗输入卷积自编码器,窗口的宽度设置为变量数目相同,即采用14个时间步的传感器数据作为单个输入;同时,第14个时间步的RUL值作为LSTM的训练标签,依次滑窗输入。滑窗卷积不仅达到了性能变量融合的目的,还能提取时间域特征,而且这样设置标签可使预测结果超前,这对飞机的安全性非常重要。
2.3 网络设置与训练
本文将编码输出为一维,为使得HI值映射到0到1之间,在编码最后层,采用sigmoid激活函数。若在编码部分卷积层进行裁剪输出,则在解码部分采用转置卷积进行升维,以达到输入与输出维度相等。为使得模型快速收敛,解码最后卷积层亦采用sigmoid激活函数。在训练CAE中,采用adam优化算法,初始学习率为0.001,批量大小为64,训练20个世代,CAE的结构设置如表1所示。
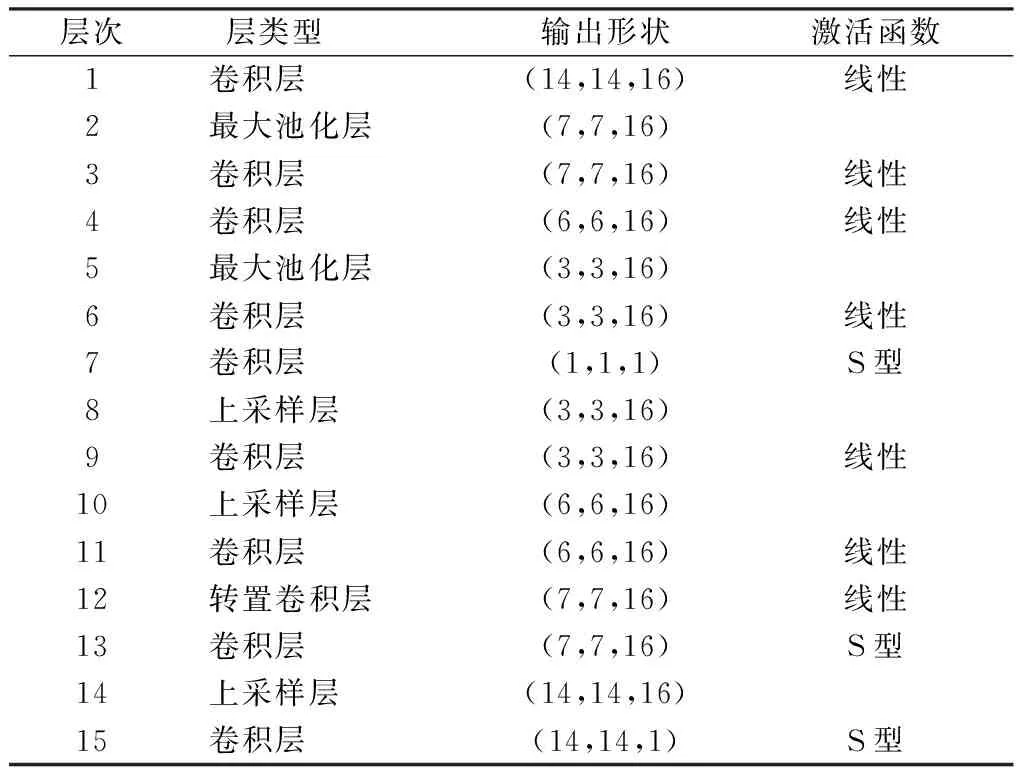
表1 卷积自编码器结构设置
为使HI曲线趋于平滑,本文采用指数加权移动模型进行滤波。平滑窗口设置为20。图5为FD001训练集中100个发动机单元所构造的HI曲线。从图中可以看出HI曲线退化趋势分为两阶段,发动机失效与退化后期直接相关。若将训练集全部周期的HI序列用于LSTM模型输入,不仅预测所得的前期RUL值参考意义不大,还会降低后期预测值的准确性,因此本文只将退化后期的HI序列用于预测输入,直接建立退化后期的LSTM预测模型。
从图5可以看出,在运行周期前100,HI值没有明显下降,HI值基本在0.8~1.0范围内;而在后期,HI值下降明显,且下降趋势具有一致性,在接近余寿终点时,HI值基本在0.2左右。该CAE模型构造的HI曲线符合发动机的退化趋势,可以将其作为发动机的退化模型。本文提出的间接预测方法是在构造HI值的基础上,对当前时刻HI值小于0.8的发动机进行LSTM预测,将HI值从0.8至最后值的HI序列作为预测模型的输入。
图6为FD001测试集中100个发动机所构造的HI曲线。在测试集中的100个发动机单元有部分是处于退化初期,即HI曲线最后值大于0.8,在本文将这些发动机健康状况视为良好,不予预测。
在训练LSTM中,采用adam优化算法[13],设置初始学习率为0.01,批量(取值10,20),丢弃率(取值0.2,0.5),LSTM数目(取值100,150,200),全连接神经元个数(取值20,50),训练世代(取值100,200)进行实验。
2.4 结果分析
均方根误差(root mean square error,RMSE)和评分函数(score)是评价预测模型常用的性能指标[7]。本文采用这两种度量标准来评估此模型的准确度。均方根误差为
(13)
(14)
从式(14)中可以看出,Score函数对于高估的预测值给予的惩罚大于低估的,这符合实际应用。使用这两种度量可以综合地评价模型的性能。
设置LSTM隐藏单元为200,全连接数目为50,丢弃率为0.2,训练批量大小为20,训练世代为200,将训练好的模型在训练集上测试,在训练集100个发动机单元中随机选取4个单元,绘制RUL真实值与预测值对比图,如图7所示。
从图7中可以看出,当发动机HI值在0.8时,RUL值在40左右;在预测初始阶段,预测值存在微小震荡,随着预测加深,预测值趋于真实值,拟合效果较好。
在测试集100个发动机单元所构造的HI曲中,49个发动机的HI序列最后值小于0.8,将训练好的模型在该49个单元上测试,随机选取4个,绘制RUL真实值与预测值对比图,如图8所示。
从图8中可以看出,在预测初始阶段,测试集的预测值震荡较训练集大,但在预测后期,预测值同样趋于真实值,且最后周期的预测误差在10左右。
为了证明模型的准确度,将实验结果与多层感知机(multi-layer perceptron,MLP),支持向量回归(support vector regression,SVR),CNN[5]以及多层LSTM[7]预测模型的最优结果进行比较,如表2所示。

表2 各模型结果对比
从表2中可以看出,本文提出的CAE-LSTM的间接预测模型,在RMSE指标上和Score评分下都取得了较好效果。相比多层LSTM模型预测结果,RMSE提高了19%,Score提高了46%。之所以本文模型取得优异表现,是因为本文首先运用卷积自编码器,将退化特征降至一维,为发动机的RUL预测提供先验信息,其次通过LSTM模型,仅建立后期HI与RUL的映射关系,提高了预测模型的精准度。
3 结束语
本文针对航空发动机系统复杂,状态监测数据维度高,退化模型建立困难的问题,提出了首先运用CAE模型进行HI建模,其构造的HI不仅能在故障前期进行预警,还能为RUL预测提供先验信息。其次,将退化后期的HI序列通过LSTM结构建立HI序列与RUL序列的特征关系,降低了预测模型的复杂度,提高了预测精度。本文提出的CAE-LSTM间接预测模型,相比于其他深度学习模型,能充分利用的设备健康状态或退化信息,实现精准预测,为航空发动机的健康管理提供有力支撑。该间接预测模型也可移植于其他复杂的设备系统。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
小学生学习指导(中年级)(2021年12期)2021-12-30
锻压装备与制造技术(2021年5期)2021-11-13
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
电子制作(2019年11期)2019-07-04
