
基于可见-近红外光谱的茄子叶绿素荧光参数Fv/Fm预测方法
2020-09-05 03:45陈丹艳张海辉
光谱学与光谱分析 2020年9期
李 斌, 高 攀, 冯 盼, 陈丹艳, 张海辉, 胡 瑾*
1. 西北农林科技大学机械与电子工程学院, 陕西 杨凌 712100 2. 农业农村部农业物联网重点实验室, 陕西 杨凌 712100 3. 陕西省农业信息感知与智能服务重点实验室, 陕西 杨凌 712100
引 言
叶绿素荧光技术作为植物光合作用的探针, 能间接反映植物光合系统对光能的吸收、 传递、 耗散和分配。 叶绿素荧光参数(Fv/Fm)为光学系统Ⅱ(PSⅡ)反应中心最大光合效率, 是使用频率最高的参数之一, 被广泛应用于植物逆境胁迫研究中。 Zhou等[1]采用Fv/Fm进行番茄耐热性的早期检测; Hazrati等[2]研究表明水分胁迫和光照胁迫会造成芦荟的Fv/Fm降低; 秦红艳等[3]对葡萄幼苗进行不同浓度盐处理, 发现其叶片Fv/Fm随盐胁迫程度加剧而降低。 实现Fv/Fm的快速检测对于表征植物生理状态具有重要意义。 然而传统的Fv/Fm检测方式需对待测叶片进行暗适应, 无法实现实时测量, 另外由于叶绿素荧光仪价格昂贵,Fv/Fm检测成本高, 不能满足实际应用中大范围检测需求。
光谱检测技术具有快速、 无损、 成本相对较低的优势, 近年来在植物生理状态监测方面发展迅速。 国内外学者对植物叶绿素荧光参数与反射光谱的关系进行了深入研究, 朱艳等[4]对不同施氮水平下, 不同品种和生育时期的不同叶位小麦叶片的叶绿素荧光参数和高光谱反射率进行分析, 发现小麦顶部两叶片的荧光参数同其差值植被指数DVI(550和750 nm)相关性最高,Fv/Fm与该指数相关性达0.68; Ibarakip等[5]搭建了一套光学植被指数(PRI)成像系统, 采集马铃薯叶片的反射光强并计算出PRI指数(530和570 nm), 发现叶片暗适应后, 在弱光条件下该指数同Fv/Fm存在线性关系。 Zhang等[7]采用主成分分析的方法提取出水稻叶片叶绿素荧光参数的特征波段, 选出多个植被指数与荧光参数建模, 结果表明归一化植被指数NDSI(680和935 nm)的拟合效果最好, 其Fv/Fm的回归模型的相关系数R为-0.818, 均方根误差RMSE为0.03。 有报道分析了紧凑型玉米整个生长期Fv/Fm同高光谱植被指数的关系, 发现结构色敏指数SIPI(445, 680和800 nm)同Fv/Fm相关性最好, 并以SIPI构建了Fv/Fm监测模型, 决定系数可达0.813。 以上研究证明了反射光谱预测Fv/Fm的可行性, 然而多着重于分析植被指数同Fv/Fm的关系, 建立的预测模型以植被指数为输入, 其包含的波长信息量有限, 且多用固定公式拟合建模, 导致模型精度受限。 然而鲜见研究采用统计学方法分析反射光谱同Fv/Fm的关系, 并以提高精度为目的探寻预测模型建模方法。
本工作以茄子叶片作为研究对象, 测量其可见光-近红外光谱数据及叶绿素荧光参数Fv/Fm, 采用3种光谱数据预处理方法滤除光谱噪声; 使用5种变量筛选方法提取特征波长, 并建立偏最小二乘回归(partial least square regression, PLSR)模型, 根据模型精度确定不同预处理方法下的最优特征波长组合; 最后采用4种机器学习算法建立Fv/Fm预测模型, 并与传统线性回归算法进行对比, 选出最优建模方式, 实现基于可见-近红外光谱的茄子叶片Fv/Fm准确预测。
1 实验部分
1.1 样本处理
实验于西北农林科技大学农业农村部农业物联网重点实验室(北纬34°07′39″, 东经107°59′50″, 海拔648 m)进行, 实验材料为紫红长茄F1幼苗, 采用基质培养(Pindstrup Substrate, 丹麦)。 为获取荧光参数差异显著的茄子叶片, 于2018年11月将生长健康、 长势一致的茄子幼苗置于光照强度设置为6个梯度(光量子通量密度分别为50, 90, 140, 220, 280和340 μmol·m-2·s-1)的6个CO2人工气候箱(达斯卡特, RGL-P500D-CO2)内培养。 箱内光周期为昼/夜14h/10h, 环境温度为昼/夜25 ℃/16 ℃, 空气相对湿度为昼/夜60%/50%, CO2浓度为400 μmol·mol-1。 由于各箱内茄子植株接受光辐射不同, 培育15 d后, 产生了长势良好和受光抑制影响明显的植株样本, 其株高、 茎粗, 叶片形状、 颜色等形态特征产生明显区别, 且叶绿素荧光参数Fv/Fm差异较大, 分布于0.682~0.877的区间内。 对其进行可见-近红外光谱和叶绿素荧光参数测定, 共获取光谱及荧光数据302组。
1.2 可见-近红外反射光谱数据采集
可见-近红外反射光谱数据采集系统包括波长范围为350~1 100 nm, 像素为2068的光谱仪(OFS-1100, Ocean Optics, 美国), 卤钨灯(HL-2000, Ocean Optics, 美国), 积分球(SpectroClip-TR, Ocean Optics, 美国)及计算机。 其中测量前, 将卤钨灯预热30 min, 以保证光源强度均匀。 通过光谱校正去除设备暗电流影响, 获得样本光谱反射率, 其计算公式如式(1)所示
(1)
式(1)中,R为样本光谱反射率;I为样本反射光谱光强;Iw为参考白板的反射光谱光强;Ib为光源关闭时光谱仪采集的光谱光强。
使用SpectraSuite软件(Ocean Optics, 美国)设置光谱采集参数: 光谱积分时间为80 ms, 扫描次数为10, 平滑度为5。 对每个叶片取避开叶脉的三个点采集反射光谱数据, 取平均值作为单个叶片的原始光谱。
1.3 叶绿素荧光参数采集
使用便携式调制叶绿素荧光仪Mini-Pam-II(Walz, 德国)测定叶绿素荧光参数。 测定前使用暗适应叶片夹夹取待测叶片, 充分暗适应20 min后, 通过光纤探头在叶片相同位置采集叶绿素荧光参数Fv/Fm, 同样取三点均值作为单个叶片Fv/Fm。
1.4 数据处理方法
1.4.1 样本集划分
由于光谱首尾波段信噪比较低, 选取了400~1 000 nm波长范围内的1 358个波段进行光谱分析。 在302个样品中, 利用蒙特卡洛抽样方法(Monte-Carlo sampling method, MCS)对光谱数据进行分析, 去除9个明显异常值, 在剩余293个样本中, 按4∶1随机划分出训练集和测试集, 其样本数分别为234和59。
1.4.2 光谱数据预处理
为消除仪器产生的随机噪声、 叶片表面散射、 光程变化等对光谱产生的影响[7], 保留有效光谱信息, 提高模型精度及适用性, 本研究分别使用SG卷积平滑(savitzky-golay, SG)、 多元散射校正(multiplicative scatter correction, MSC)、 标准正态变量变换(standard normal variate transformation, SNV)三种方法对光谱进行预处理。
1.4.3 特征波长提取
叶片反射光谱波段线性重复性高、 冗余信息多, 会导致模型复杂且精确性下降[8]。 特征波长筛选可以减少波长变量的个数, 且有利于提高模型预测速度。 本研究采用连续投影法(successive projections algorithm, SPA)、 随机蛙跳算法(random frog, RF)、 竞争性自适应加权算法(competitive adaptive reweighted sampling, CARS)及其组合进行特征波长筛选。 其中, SPA是一种前向循环选择方法, 通过向量的投影分析, 将含有最少冗余度和最小共线性的波长组合提取出来; RF和CARS则是以优化校正模型的预测精度为目的, 通过循环迭代建立预测模型得到最适于提高模型精度的特征变量。 其不同之处在于RF算法通过计算循环过程中各波长的被选择概率作为特征波长选择的标准[9], 而CARS则在迭代过程中不断筛去贡献小的波长, 以精度最高的模型所采用的波长组合为特征波长组合, 其变量选择的具体步骤见文献[10]。 为实现在考虑模型精度的同时尽可能地减少特征波长的个数, 选择将CARS和RF分别与SPA连用, 即先采用CARS和RF提取出有利于预测模型精度的特征波长组合, 而后使用SPA筛去重复性高的冗余变量。
为衡量各方法提取的特征波长组合的性能, 以预处理后的样本光谱的特征波长反射率为输入, 叶绿素荧光参数Fv/Fm为输出, 采用PLSR算法建立预测模型。 以决定系数(R2)和均方根误差(RMSE)衡量模型精度, 确定最适数据处理方法下的最优波长组合。 为评价波长组合内各特征波长的重要性, 对建立的PLSR预测模型中各波长权值的比重进行计算, 如式(2)
(2)
式(2)中,bi为PLSR拟合公式中第i个特征波长的回归系数,wi是第i个特征波长的权值比重。
1.5 建模方法及模型评价
为了获取最优的建模方法, 分析4种常用的机器学习算法对Fv/Fm预测模型精度的影响, 并与PLSR模型进行对比, 从而建立预测模型。 机器学习算法分别为: BP神经网络(back propagation neural network, BP)、 RBF神经网络(radial basis function neural network, RBF)、 极限学习机(extreme learning machine, ELM)及回归型支持向量机(support vector regression, SVR)。 以测试集Fv/Fm的实测值与预测值的决定系数(R2)及均方根误差(RMSE)衡量模型预测效果。
研究中BP神经网络隐层数量设置为1, 各层之间的传递函数为tansig, 优化函数为trainlm, 目标误差为0.000 1, 最大迭代次数为1 000, 学习速率为0.1; RBF神经网络的目标误差设置为0.000 1, 径向基函数扩散速度为13.5。 ELM的隐层神经元个数设置为50, 传递函数为sigmod; SVR的核函数设置为径向基函数, 通过网格搜索法确定正则化参数c与核函数参数g。
2 结果与讨论
2.1 光谱分析
取叶片样本Fv/Fm值区间为[0.65, 0.90], 按步长为0.05将其划分为5个子区间, 将Fv/Fm值落于各子区间的茄子叶片反射光谱取均值, 其平均光谱如图1所示。 其光谱符合植物光谱普遍规律, 在550 nm左右出现反射率峰值“绿峰”, 在680 nm存在反射率低谷“红谷”[11]。 在可见光与近红外波段之间, 出现反射率急剧上升的“红边”现象。 另外, 随叶片Fv/Fm的增加, 其光谱反射率整体呈下降趋势。 其中, 500~700 nm区域内的光谱幅值降低对该趋势的反映极为明显。 分析认为Fv/Fm是植物PSⅡ反映中心的最大光能转化效率,Fv/Fm值大的叶片样本对光能的吸收、 利用能力强, 故其在叶绿素吸收光范围内的反射光强明显低于Fv/Fm值小的样本。 这种叶片光谱的统一变化趋势为建立Fv/Fm预测模型提供了理论依据。
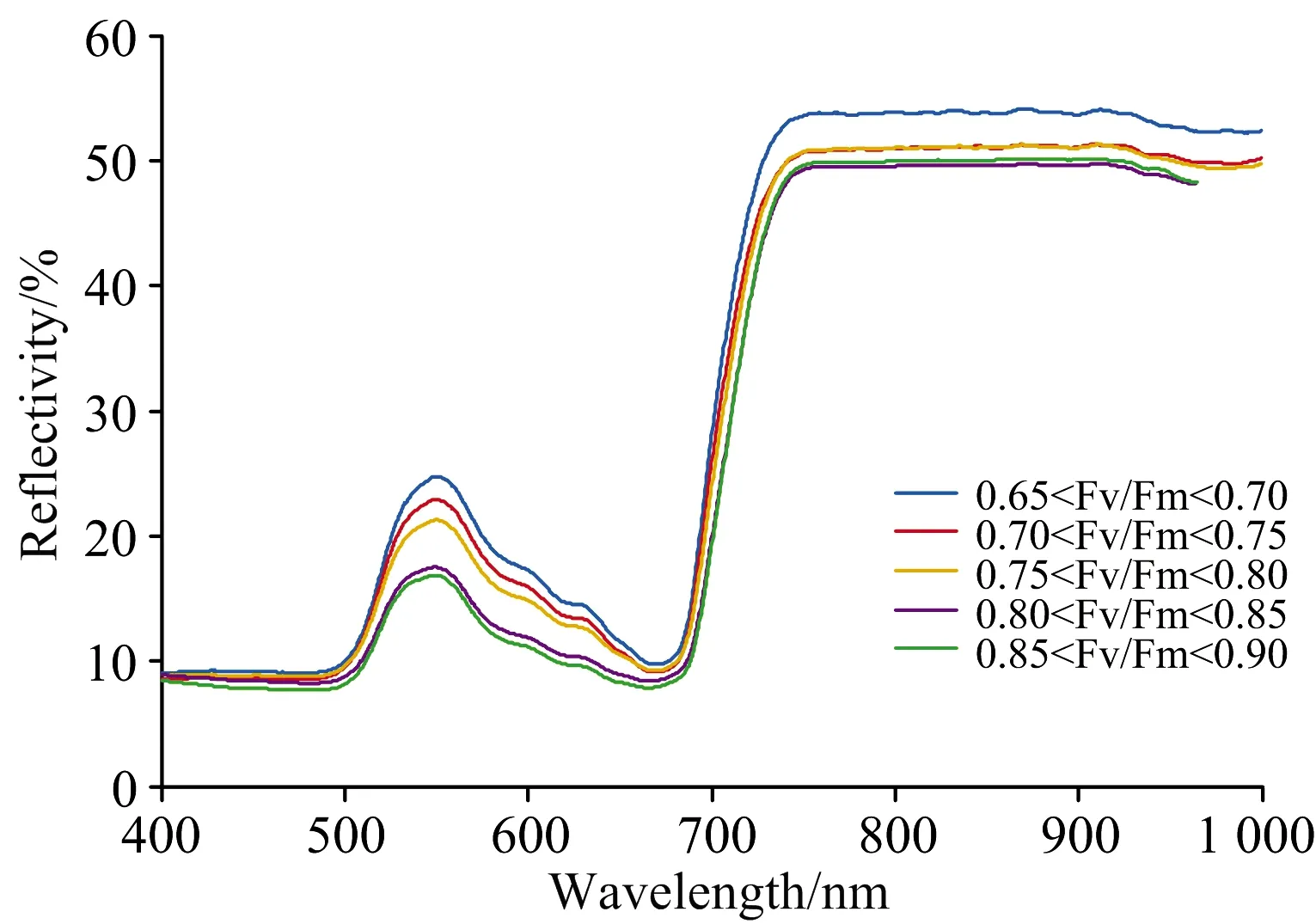
图1 样本平均光谱
2.2 光谱数据预处理及特征波长提取
为筛选建模效果最优的特征波长组合, 在光谱预处理及特征波长提取的基础上, 以PLSR建立的预测模型的精度以及采用的特征波长个数如表1所示。 在三种预处理方法中, MSC和SNV的表现较好, 训练集和测试集的R2均能达到0.8以上, RMSE均在0.015以下。 而SG平滑效果一般, 除了以RF-SPA方法提取特征波长的建模效果比原光谱有较小提升的效果, 其余的模型精度反而不如原始光谱数据建立的预测模型, 可能是由于SG平滑在过滤噪声的同时也消除了部分光谱中的有效信息。
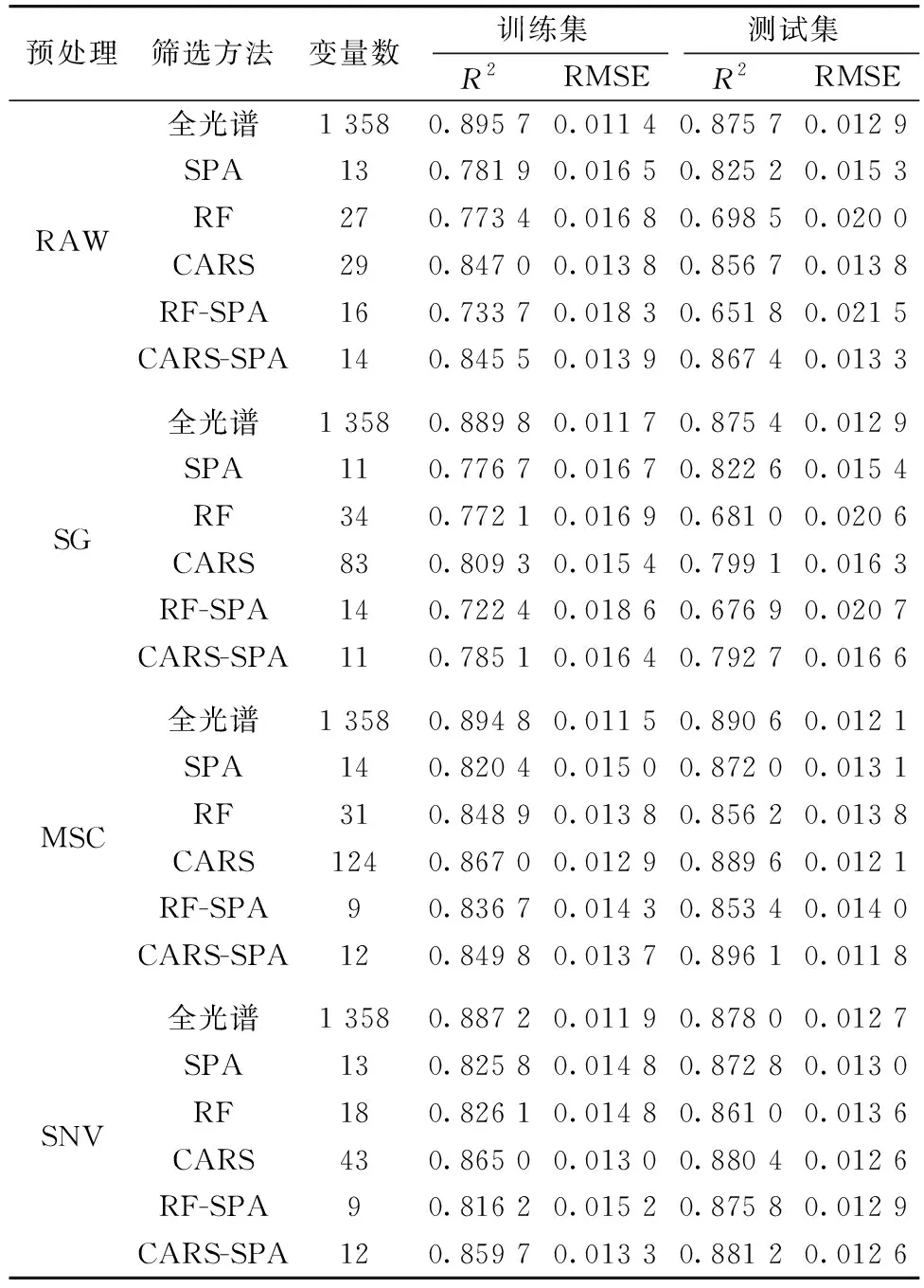
表1 不同预处理及变量筛选方法下的PLS模型精度
由表1中三种变量筛选算法单独使用的结果可知, CARS和SPA的效果较好。 CARS提取的波长建模精度最优, SPA次之, 但其提取出的特征波长数量最少。 这是由于CARS的选择策略是基于模型精度最优, 而SPA则是基于各变量之间的重复性最小。 RF算法表现不佳是因为其根据单个波长被选择的概率进行变量筛选, 没有考虑波长之间的组合效果。 而CARS和SPA筛选出的则是特征波长的集合。 两者的组合使用充分发挥了各自的优点。 各预处理下, CARS-SPA的模型精度与CARS相近, 但其特征波长数量远少于CARS。 在所有方法中, MSC-CARS-SPA及SNV-CARS-SPA的波长选择效果最优。 MSC-CARS-SPA-PLSR的测试集R2为0.896 1, RMSE为0.011 8, 而SNV-CARS-SPA-PLSR的测试集精度与前者相近而训练集精度更高, 两者的特征波长个数均为12个, 仅占全光谱建模中1 358个波长的0.88%。 两方法均在大幅度降低模型输入的同时, 提高了模型预测能力, 故将两者筛选出的波长变量作为最终的特征波长组合。
进一步对两种方法筛选出的特征波长分布情况及重要性进行分析。 各特征波长的分布及其权值比重如图2所示, 其中图2(a)和(b)分别为经MSC及SNV预处理后的光谱图, 图2(c)和(d)则是MSC-CARS-SPA和SNV-CARS-SPA两种方法筛选出的12个特征波长的权重分布, 采用点划线表示特征波长在预处理光谱中的位置。 由图2(a)和(b)可知, 两种方法提取出的特征波长在可见光(400~780 nm)与近红外区域(780~1 000 nm)的数量较为均匀, MSC-CARS-SPA的分布比例为1∶1, 而SNV-CARS-SPA的分布比例为5∶7。 但由图2(c)和(d)可发现: 在权重分布上, 可见光区域的权重明显高于近红外区域, MSC-CARS-SPA的可见光范围特征波长累积权重为71.54%, SNV-CARS-SPA为68.15%; 另外, 两种方法在400~730 nm范围提取出的特征波长具有高度相似性。 在该范围内MSC-CARS-SPA提取出的波长分别为405, 512, 644和729 nm, 而SNV-CARS-SPA的特征波长为402, 512, 648, 708和723 nm。 以上波长的权重也具有类似变化, 随波长增大, 呈先降后升趋势, 并在730 nm附近达到最大值, MSC-CARS-SPA筛选的729 nm处的波长权重为18.97%, 而SNV-CARS-SPA对应的723 nm的权重为24.64%, 表明该处波长信息对Fv/Fm的反映最为明显, 这可能是由于该波长位于植物反射率光谱变化最为明显的红边位置, 而红边信息可良好地反映植物的叶绿素含量、 含水率、 氮含量等影响植物生长发育的重要生理量, 故此处波长的权重最大。
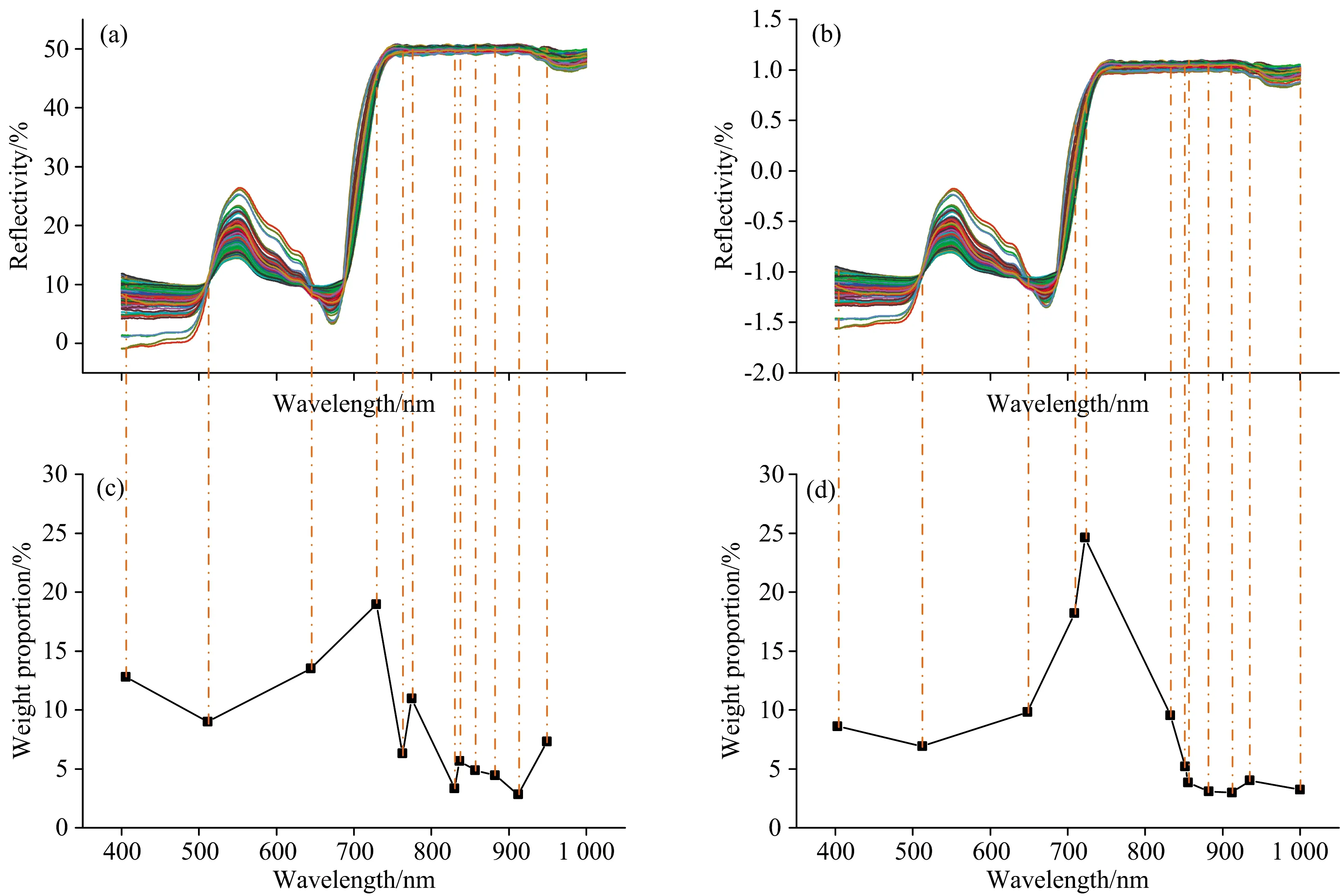
图2 特征波长分布及权值比重
2.3 预测模型的建立与对比
以样本光谱数据特征波长组合反射率数据为输入, 叶绿素荧光参数Fv/Fm为输出, 分别使用4种机器学习算法构建预测模型, 并与PLSR算法进行对比。 其中, 由于BP神经网络和ELM算法的随机性, 选择以运行十次的决定系数和均方根误差的平均值评价模型精度。 模型运行结果如表2所示。
由表2可知, 相比于PLSR模型, 四种机器学习模型的训练集的精度都得到了明显提升, 这是由于机器学习的非线性拟合能力更强。 另外, 除ELM模型, 其他三种机器学习模型的测试集精度都得到了提高。 但往往存在过拟合现象, 即训练集精度明显高于测试集。 在几种算法中, SVR的建模效果最优, 其在小样本训练的优势得到了体现, 表现为最高的决定系数、 最小的均方根误差及优秀的泛化能力。 在所有模型中, 以SNV-CARS-SPA方法获取特征波长, 并采用SVR建立的茄子叶片Fv/Fm模型的预测效果最好, 其训练集与测试集的拟合结果分别如图3(a,b)所示。 其训练集R2为0.912 7, RMSE为0.010 5; 测试集R2为0.911 7, RMSE为0.010 8, 且模型输入仅为12个波长。 而采用PLSR算法建立的全光谱模型的测试集R2为0.875 7, RMSE为0.012 9。 这表明本研究所采用的预处理和变量筛选方法有效地去除了光谱中的冗余信息, 保留了与Fv/Fm最相关的特征波长组合, 且SVR算法更适于构建光谱数据对Fv/Fm的预测关系。
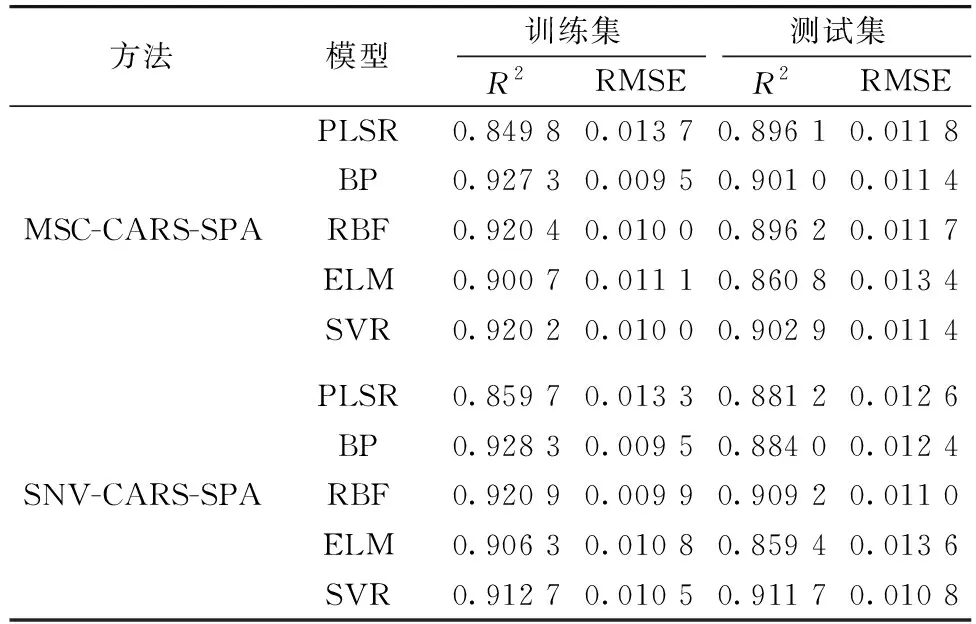
表2 不同建模方法下的模型精度
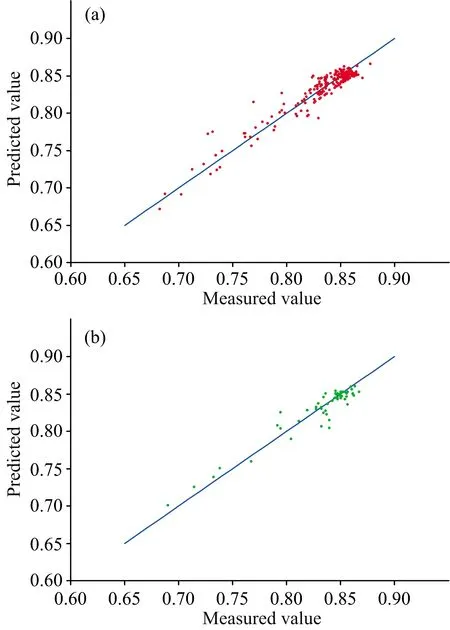
图3 基于SVR构建预测模型的拟合结果
3 结 论
以苗期茄子植株为研究对象, 采用可见-近红外光谱分析技术对其叶绿素荧光参数Fv/Fm进行定量预测, 使用多种预处理方法及变量选择算法完成特征波长的筛选, 基于多种机器学习算法构建预测模型, 通过模型精度对比确定了最优数据处理方法及建模算法。 主要结论有以下四点:
(1) 通过试验获取不同Fv/Fm的茄子叶片的反射光谱, 分析发现光谱反射率随Fv/Fm的增加呈下降趋势, 在500~700 nm波段处该现象最为明显。
(2) 采用SG, MSC和SNV进行光谱数据预处理, 通过SPA, RF, CARS, CARS-SPA和RF-SPA提取特征波长组合, 并使用PLSR建立建模。 发现MSC-CARS-SPA和SNV-CARS-SPA方法提取的波长组合建模效果最好, 且波长个数仅为12个。
(3) 由特征波长权重分布可知, 可见光区域的特征波长权重明显高于近红外区域, 表明该处特征波长对于Fv/Fm的预测贡献更大。 另外, 所有特征波长中红边位置的波长权重最大, 对Fv/Fm的反映最为明显。
(4) 基于两类特征波长信息, 分别使用BP, RBF, ELM和SVR算法建立预测模型, 发现SNV-CARS-SPA-SVR方式建立的模型精度最优, 其测试集R2为0.911 7, RMSE为0.010 8。 其精度高于全光谱PLSR模型, 表明本研究所采用的特征波长筛选方法结合机器学习算法有效地提高了模型预测能力。
本研究基于统计学方法, 探索了以可见-近红外光谱预测苗期茄子叶绿素荧光参数Fv/Fm的有效方式, 拟进一步推广至不同生长期的其他作物, 为植物生长逆境的快速、 无损检测提供技术支撑。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
空间科学学报(2021年1期)2021-05-22
阅读(科学探秘)(2020年8期)2020-11-06
中国果业信息(2019年1期)2019-01-05
生物学教学(2017年9期)2017-08-20
中南大学学报(自然科学版)(2016年2期)2017-01-19
中国照明(2016年4期)2016-05-17
中国光学(2015年5期)2015-12-09
中国当代医药(2015年26期)2015-03-01
云南中医学院学报(2014年5期)2014-07-31
