
融合语义与事件特征的重大事件趋势预测
2020-09-04 03:16彭博远彭冬亮彭俊利
计算机工程与应用 2020年17期
彭博远,彭冬亮,谷 雨,彭俊利
杭州电子科技大学 自动化学院,杭州 310018
1 引言
事件,一般来说是指促使事物状态和关系改变的条件[1]。重大事件,在国际政治关系研究领域通常指对国家(地区)间政治关系产生巨大影响的事件,它能改善两国(地区)间的关系或直接导致两国(地区)关系的恶化[2],具体表现如中东地区恐怖袭击事件,由朝核问题引发的军事事件等。由于重大事件的产生及发展对国家(地区)间的稳定有着不容忽视的影响,因此,如何有效地针对重大事件发展趋势进行预测正成为当下众多学者研究的热点问题。
事件数据分析法,作为国际政治关系研究领域的经典研究方法,被广泛用于重大事件趋势预测问题的定量研究[3]。该方法主要包含四个步骤:确定事件消息来源、建立或选择一个编码系统、基于编码系统对事件信息进行量化赋值、计算赋值结果并进行分析[4]。张萌等[5]采用事件数据分析法对2003年至2008年的石油价格与美国-伊朗间的冲突合作水平进行了初步检验,有效实现对美伊关系的定量预测。阎学通[6]构建了1950 年至2005年间中国与各个主要大国关系的事件数据库,并基于事件数据分析法对中美、中俄等国的双边关系的变化趋势展开预测研究。
近年来,随着信息技术的普及以及传播媒介的多样化发展,新闻报道数量呈现指数级增长态势,这为重大事件趋势预测研究提供了充足的数据基础。然而,由于蕴含于海量新闻报道中的重大事件在时间分布上表现出相关噪声大、频次稀疏、影响周期长等特点,利用传统事件数据分析法人为进行海量数据的筛选与分析显然无法适应当前的时代需求。针对这一问题,有学者开始以跨学科视角对大数据背景下的重大事件趋势预测问题展开研究,提出结合当下人工智能相关技术进行数据的辅助分析[7]。Hartman 等[8]利用2008 年新闻数据与神经网络对2010年利比里亚冲突进行了高效预测。曹玮等[9]以韩统一社网站整理的2006 年至2017 年间的新闻报道为语料,基于现有对朝研究的成果构建了23 类朝核行为特征指标,在此基础上建立关于朝鲜核行为的朴素贝叶斯预测模型。董青岭[10]对印度恐袭事件相关报道中的因自变量进行建模,利用反向传播神经网络(Back Propagation Neural Network,BPNN)有效地实现了对于这一问题的趋势预测。
然而,现有跨学科视角下的重大事件趋势预测相关研究依旧未能摆脱传统研究领域的思维束缚。在特征构建上,普遍依赖领域专家知识人为构建特征指标。因此,这类方法在预测时效性与普适性上还存在相当大的制约。
与重大事件的特性不同,社交媒体事件,具体表现如微博、推特等社交平台所爆发的舆论热点事件,往往具有受众面广、突发性强、持续周期短等特点[11]。因此,研究者针对这类事件进行特征构建与分析的过程中更注重方法的普适性与时效性。曾子明等[12]利用LDA(Latent Dirichlet Allocation)主题模型提取微博文本主题分布特征,融合情感特征和句式特征。结果表明,结合主题分布特征的AdaBoost模型能够有效地实现对微博用户情感倾向的分析。Pu 等[13]将LDA 与文本挖掘API 以及维基百科分类相结合,构造出Wiki-LDA 以实现从推特数据中挖掘用户兴趣特征的目的。
为克服大数据背景下重大事件趋势预测研究在特征选择上的局限性,本文提出一种融合语义与事件特征的重大事件趋势预测方法。首先,在特征构建上,提出利用主题模型构建语义特征指标,利用模式指导下的事件抽取技术构建事件特征指标,并将两类指标进行特征融合;其次,对于主题模型LDA提取语义特征指标存在的全局偏向性问题,提出了一种改进主题模型IDFLDA(Inverse Document Frequency Latent Dirichlet Allocation);最后,以朝鲜核行为趋势预测为研究对象进行方法验证,通过与基于专家知识构建特征指标的传统方法进行结果对比,验证了提出方法的可行性与有效性。
2 融合语义与事件特征的重大事件趋势预测方法
面向海量新闻数据的重大事件趋势预测,在具体实施过程中需要重点解决两类问题:首先是数据特征构建与量化表示问题,传统做法采用领域专家知识人为选定特征指标,结合构造特征将非结构化的新闻数据进行结构化向量表示;其次是事件趋势的量化问题,即如何将具有笼统意义的重大事件趋势进行定量描述,当前普遍做法是结合领域专家知识制定事件影响力量化公式,结合相关新闻报道与量化公式对各时间段上的趋势分值进行计算。
为解决传统方法在特征选择上的局限性问题,本文受文献[9]针对朝核行为预测研究的启发,结合当下主流信息处理技术,提出一种融合语义与事件特征的重大事件趋势预测方法,方法流程如图1所示。
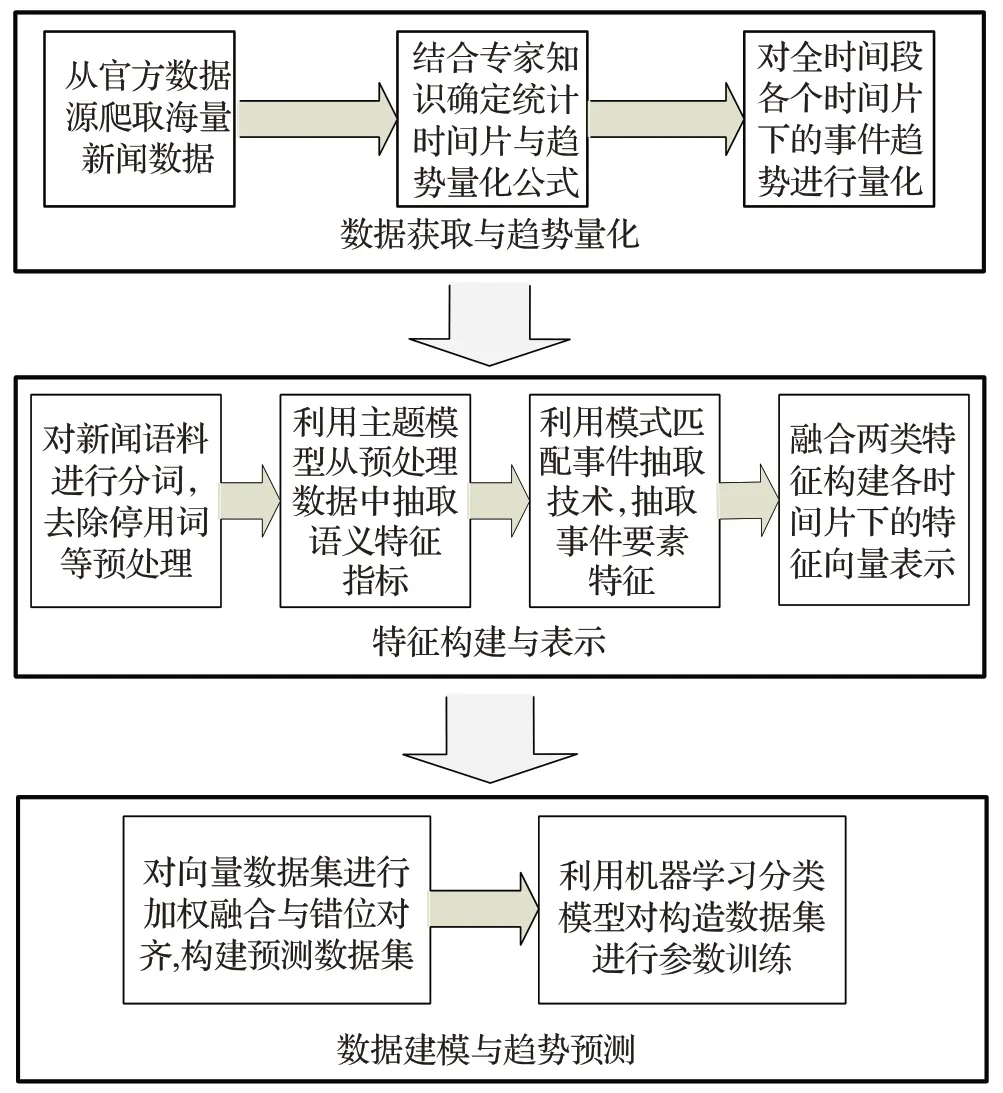
图1 融合语义与事件特征的重大事件趋势预测模型
如图1所示,该方法主要包括以下三个步骤:
步骤1数据获取与趋势量化。首先,结合网络爬虫技术从官方新闻网站爬取事件相关报道,构建专题新闻数据库;其次,借鉴该领域的传统做法,结合专家知识确定统计时间片(日、周、月、年等)及事件影响力量化公式;最后,结合量化公式与采集的新闻数据,对数据覆盖各时间片下的重大事件趋势值进行计算以及趋势等级标注。
步骤2特征构建与表示。首先,利用分词、停用词过滤等自然语言处理(Natural Language Processing,NLP)技术对爬取新闻报道进行文本预处理;其次,利用主题模型对预处理数据进行词汇级特征抽取,构建多组语义特征指标;再次,利用模式指导下的事件抽取技术,从预处理数据中抽取事件要素特征(事件句、发起者、承受者、事件类型等)并基于抽取结果构建事件特征指标;最后,将两类特征指标进行特征级融合,基于融合特征,对各时间片内的文本数据进行向量化表示。
步骤3数据建模与趋势预测。选定一个预测偏移量N,目标时间片T,将第T-N至T-1 个时间片内融合特征向量进行决策级融合,将融合结果对齐至第T个时间片的标注趋势等级。最后,将经过数据对齐操作后的数据集送入机器学习分类模型进行参数训练。
模型测试时,假定待预测的时间片为Tp,此时只需输入Tp前N个时间片内的原始新闻报道,经过步骤2至3构建相应的预测特征向量。预测模型将输出Tp下各重大事件趋势等级的发生概率,其中最大概率对应的趋势等级为模型预测结果。
2.1 语义特征指标构建
2.1.1 LDA主题模型
潜在狄利克雷分布(Latent Dirichlet Allocation,LDA)模型是由Blei等[14]于2003年提出的一种概率语言模型。模型通过引入了文本主题分布思想,有效实现了对文本的降维表示,并在文本信息处理领域得到了广泛的应用[15]。
LDA 在结构上可以描述为一个三层贝叶斯网络,分别为词层、主题层、文档层。基于这样假设:每篇文档可看作由一些隐含主题构成,而每个主题又可看作由相关特征词构成[16],其拓扑结构如图2所示。

图2 LDA模型拓扑结构
LDA模型生成过程如下:
(1)对于所有的主题Z,根据参数设定为β的狄利克雷分布φ~Dir(β)得到各个主题上单词的概率分布φ;
(2)根据参数设定为α的狄利克雷分布φ~Dir(α)得到文本的主题概率分布θ;
(3)基于主题集合Z服从的参数为θ的多项分布随机选择一个主题Zi;
(4)从主题Zi服从的词项分布中选择一个单词wi作为生成文本中的一个词。
由LDA模型生成过程可知,在模型众多参数中,主题-词概率分布φ和文本-主题概率分布θ是两组十分重要的参数,而针对这两类参数的估计,可以看作是LDA模型生成过程的逆过程。
相比于生成过程,LDA 参数估计是指在仅给定文本数据集的情况下,对模型未知参数进行估计。目前较为流行的LDA模型参数估计方法为Gibbs采样[17],首先对语料词典中的每个特征词的主题进行初步采样,接着基于各个特征词的出现频次进行迭代计算,最终计算出相关参数的估计结果。Gibbs 采样下LDA 模型参数φ和θ的计算公式如下所示:
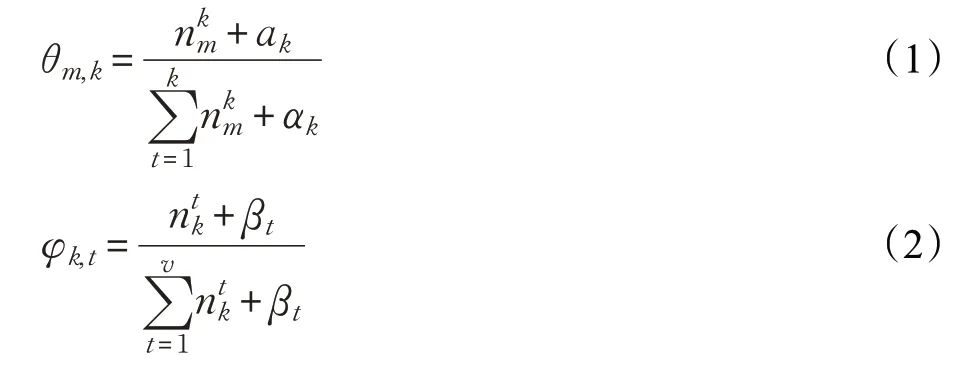
其中,θm,k指在文档m中第k个主题的分布概率,φk,t指词项t在主题k中的分布概率,表示在文档m中出现主题k的频数,表示在主题k下词项t出现的频数,αk对应于主题k下的狄利克雷先验,βt对应于词项t下的狄利克雷先验。
结合LDA 模型参数估计思想,LDA 模型具备以无监督的方式从文档中提取主题与特征词的能力。因此,在重大事件趋势预测过程中,能够很好地替代专家知识,以海量新闻数据为驱动,进行语义特征指标的构建。
2.1.2 基于IDFLDA的语义特征指标构建
当LDA 应用于文本建模或者文本特征抽取时,实际上就是对文本数据的“隐性语义”进行分析,即以无监督学习的方式从文本中发现隐含于其中的“主题”[16]。然而,由于真实文本中的词频分布大都符合幂率分布,基于Gibbs采样的LDA在进行主题词抽取时,容易向高频噪声词倾斜,这使得最终获取主题与对应特征词的相关性降低[18]。以朝鲜相关报道为例,诸如“北韩”“朝鲜”这类特征词,由于在事件相关报道中以很高的频率出现,在LDA参数估计的过程中,会因此被赋予很高的主题权重,但对于朝核问题研究而言,这类词并不具备很强的主题区分度,与其对应的分配权重相矛盾。
针对LDA 在主题词提取上存在偏向性的问题,有很多学者进行了相关改进研究。彭云等[18]提出在LDA模型中嵌入词语关联、全局特征词及主题情感隶属语义先验知识来提升LDA 对特征词、情感词及其关系的识别能力。张小平等[17]利用高斯函数对特征词加权,以此优化LDA 生成主题分布,使得改进后的模型在主题表达和预测性能方面都有所提高。万红新等[19]结合语义约束和时间关联,设计了一种主题词链提取算法,有效提升了LDA模型的语义理解功能和主题捕捉能力。郝洁等[20]提出了一种词加权LDA 算法WLDA,通过计算语料中词汇与情感种子词的距离,并结合吉布斯采样对不同词汇赋予不同权重,增强了具有情感倾向的词汇在采样过程中的影响,改善了主题间的区分性。
为了增强LDA 模型在局部主题词上的捕获能力,增加模型生成主题的判别力。本文提出一种加权单词逆文档频率[21]的改进主题模型IDFLDA,用于辅助当前重大事件趋势预测研究。首先,通过Gibbs 采样生成词-主题概率分布φ;接着,将词项t在主题k上分布概率φk,t乘上词项t在文档数据集中的逆文档频率IDFt,计算结果φk,t*表示词项t与主题k的相关性权重。以此弱化高频噪声词在LDA 语义特征抽取过程中的干扰,增强抽取各个主题间的区分度,相关改进公式如下所示:

其中,D表示文档总数,表示包含词项t的文档个数。
结合上述改进,本文针对重大事件相关新闻报道构建语义特征指标的具体实施步骤如下:
(1)对新闻语料进行分词与停用词过滤等预处理,构建词序列数据集。
(2)结合改进模型IDFLDA 对词序列数据集下文档-主题、主题-词分布进行参数估计。
(3)根据参数估计结果φk,t*获取多个主题,每个主题可看作由多个特征词组成的词团,并将生成主题(词团)集合作为影响重大事件发展趋势的语义特征指标集合。
2.2 事件特征指标构建
事件抽取技术作为信息抽取(Information Extraction,IE)领域的三大关键技术之一,能够从非结构化的信息中抽取出用户感兴趣的事件[22]。其中,基于模式匹配规则的事件抽取技术,通过结合领域先验知识定义的匹配规则以及NLP上游相关技术如分词、词性标注,依存句法分析,命名实体识别等,能有效实现对文本数据的事件级特征抽取。
因此,本文利用基于模式匹配规则的事件抽取技术来辅助重大事件趋势预测问题的研究,通过结合事件要素抽取结果构建相关特征指标,进一步丰富文本特征表示。相关流程如图3所示。

图3 基于模式匹配的事件抽取流程
由图3可知,基于重大事件相关报道构建事件特征的实施步骤如下:
(1)按照一定规则构建包括事件类型、事件触发词,实体间搭配关系的模式匹配规则库。
(2)结合爬取新闻数据,利用分词、停用词过滤,词性标注,命名实体识别等操作对读入数据进行预处理,将预处理结果与定义规则库进行模式匹配。
(3)若匹配成功,将匹配对应的几类事件要素(事件句、发生时间、事件所在地、发起者、承受者、匹配规则、事件类型)进行存储,构建事件抽取数据表。
(4)结合事件抽取数据表,对全时间段上各事件类型的发生频次进行统计。为增强构建特征的泛化能力,设定一个频次阈值,仅保留发生频次大于设定阈值的高频事件类型,所得高频事件类型集合即为对应重大事件相关报道的事件特征指标集合。
2.3 量化表示与特征融合
结合获取的语义特征指标与事件特征指标,对各个时间片内的新闻报道进行向量化表示。
步骤1语义特征向量构建。假设改进模型IDFLDA主题数设为K,首先,对各时间片下的新闻数据进行分词与停用词过滤,得到单个时间片下的词序列文本数据,并对捕获主题(词团)下所有特征词在当前词序列文本数据下的词频(Term Frequency,TF)进行计算;其次,遍历所有主题(词团),将单个主题(词团)下主题词的TF 值进行累加,累加和作为构造的语义特征向量单个维度下的数值信息,由此获取一个维度为K的特征向量;最后,对构造向量进行归一化操作,归一化结果即为对应时间片下的最终语义特征向量。
步骤2事件特征向量构建。首先,结合事件抽取数据表与高频事件类型集合,统计各时间片下各高频事件类型的出现频次;其次,将单个高频事件的频次信息描述为构造的事件特征向量单个维度下的数值信息,由此获取一个向量维度等于高频事件类型集合大小的特征向量;最后,对构造向量进行归一化操作,归一化结果即为对应时间片下的事件特征向量。
步骤3特征融合。由于基于文档词汇级信息构建的语义特征向量只能对各时间片下新闻报道的浅层语义分布特征进行表示,缺乏对事件信息的具象描述。而基于高频事件类型频次特征构造的事件特征向量恰好能对语义特征向量在特征表示上的不足进行补充。因此,将单个时间片下构造的两类向量进行首位拼接,在向量表示上进行维度扩充,实现特征级融合,以拼接向量作为单个时间片下的最终特征向量。
3 朝鲜核行为趋势预测研究
朝鲜核行为,具体表现为朝鲜射导、核试验等。作为一类地区重大事件,其产生与发展深刻影响着东北亚地区的安全局势。因此,针对朝鲜核行为的未来趋势进行预测对国家战略决策有着重大意义。
为验证本文提出方法的可行性,同时为了与基于专家知识构造特征指标的传统做法[9]形成对比。本文以朝鲜核行为趋势预测为研究对象,对提出的融合语义与事件特征的重大事件趋势预测方法进行验证分析。
3.1 数据获取与趋势量化
鉴于朝核问题的敏感性,国内能够获取到的相关公开新闻报道十分有限,主流的报道大多集中在韩国新闻网站且以韩文为主。为确保新闻数据来源的客观性与时效性,同时为了更好地应用中文NLP技术对新闻数据进行分析,选择韩国国际广播电台(KBS World Radio)北韩专题网页(http://world.kbs.co.kr/service/contentslist.htm?lang=c&menu_cate=northkorea)新闻报道作为数据来源,利用网络爬虫技术抓取2006年1月至2017年9月间的朝鲜相关中文报道共计4 255条。
借鉴相关领域对朝研究成果[9],以“月”作为统计时间片,确定如下所示事件影响力量化公式:
15枚中短程弹道导弹或潜射导弹=1枚远程或洲际导弹=1枚火箭=1次核试验=15分
结合量化公式与爬取新闻数据,对各月的朝核行为趋势值进行计算。以2006年7月抓取报道为例,朝鲜于7 月5 日发射了 6 枚短程导弹,参照公式,标记 2006 年 7月的朝核行为趋势值为6。基于各月趋势量化结果,绘制2006年1月至2017年9月朝核行为趋势统计图,结果如图4所示。
根据图4所示趋势值的分布情况,对各月的重大事件趋势进行离散化表示。为与文献[9]保持一致,本文将朝核行为划分成三类趋势等级:无核行为(C1)、轻度核行为(C2)、重度核行为(C3),三类核行为对应的分值区间分别为0、1~14、≥ 15。

图4 2006年1月至2017年9月朝核行为趋势统计图
3.2 特征构建与表示
利用主题模型与事件抽取技术为新闻文本数据构建特征指标并进行向量表示,具体实施包括三个部分:事件特征抽取与表示、语义特征抽取与表示、特征融合。第一部分,事件特征抽取与表示。基于事件句主客体及触发词在句法结构上搭配关系的不同,本文针对朝核问题共定义了603个事件抽取匹配规则,对于给定任意规则,均有唯一的事件类型与之对应;同时,对事件类型进行编码,共定义20大类,511个小类,结合匹配规则对新闻数据进行事件句匹配,部分结果如表1所示。
由表1可以看出,定义规则能有效地对事件句所属事件类型及主客体关系进行识别。其中,SOURCE表示事件句发起者,TARGET 表示事件句承受者,SRCTGT表示事件句发起者、承受者为并列关系,EVTLOC 表示事件发生地点。
根据匹配规则,对抓取报道进行事件要素的抽取。对于朝核问题,本文定义了8 类抽取要素,分别为事件句所在新闻报道的全局ID(GLOBAL_ID)、事件句(EVENTSENTENCE)、事件类型编码(EVENTCODE)、事件发生时间(PUBLISHTIME)、事件发起者(ACTOR1)、事件承受者(ACTOR2)、事件发起者所在国(ACTOR1-COUNTRY)、事件承受者所在国(ACTOR2COUNTRY),抽取结果共计14 247条,部分抽取结果如表2所示。

表1 部分事件句匹配结果
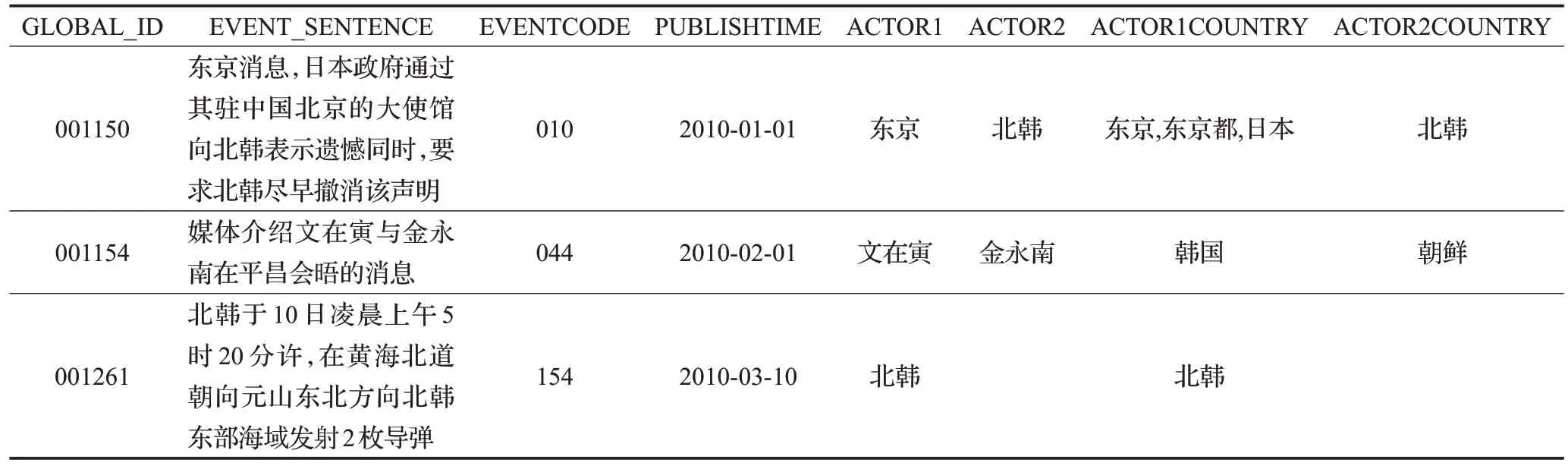
表2 部分基于模式模式匹配规则的事件要素抽取结果
结合表2所示的事件要素抽取结果,以事件发起国是否为朝鲜(北韩)作为判别条件,统计在全时间段上的高频事件类型,保留事件类型的频次阈值设为100,统计结果如表3所示。

表3 全时间段高频事件类型统计
由表3可以看出,以朝鲜作为发起国的高频事件类型集中描述了朝鲜单方面军事行为与政治动作,而以其他国家作为发起国的高频事件类型则反映出相关国家对朝鲜军事行为的反制措施与缓和手段,这与基于专家知识的对朝分析结果[9]相吻合。
基于各月新闻数据的事件抽取结果,对表3所示事件类型进行频次统计,构造出两类事件特征向量:EventVec_Y(维数11)、EventVec_N(维数25),将两类向量进行加权拼接,得到各月新闻数据的事件特征向量EventVec(维数36)。
第二部分,进行语义特征抽取与表示。结合获取的新闻数据与事件要素抽取结果,以报道中是否包含以朝鲜为发起国的事件句作为约束条件,生成2类词序列数据集,分别为WordsSeq1DataSe(t包含朝鲜作为发起国的事件句的所有新闻报道经预处理得到的词序列数据集)、WordsSeq2DataSe(t不包含朝鲜作为事件发起国的事件句的所有新闻报道经预处理得到的词序列数据集)。
分别以词序列数据集WordsSeq1DataSet及Words-Seq2DataSet作为训练语料,利用改进主题模型IDFLDA进行语义特征指标抽取。设置模型主题数K∈{10,15,20,25,30,35},模型系数a=50/K、β=0.01,对于单个特征指标(主题)k,保留φk,t*最高的50个特征词,模型迭代次数设为1 000,分别生成两组大小为K的语义特征指标集合。以K=15 的训练结果为例,部分特征指标如表4、表5所示。

表4 基于WordsSeq1DataSet训练的部分特征指标(K=15)

表5 基于WordsSeq2DataSet训练的部分特征指标(K=15)
由特征抽取结果可以看出,表4中抽取特征指标更多反映出朝鲜对外界刺激的一些反应,包括发射导弹、举行会谈等。其中,主题1、2、3 与文献[9]中指标10(核导力量)、指标9(朝韩间的经济与人道主义互动)、指标12(国际社会对朝鲜的刺激)相呼应;表5中抽取特征指标则更多反映出外界对朝鲜的一些动作,包括对朝援助、开放工业园区等,其中主题1、2、3 分别与文献[9]中指标7(朝鲜半岛统一和民族和解目标)、指标15(朝鲜对国际社会的外交应对)、指标21(朝鲜与外界的互动交流)相呼应,对比结果进一步验证了利用主题模型辅助提取重大事件特征指标的可行性。
结合2.3节向量构造方法及上述语义特征指标集合,为各月的新闻数据构建两类语义特征向量(TopicVec1与TopicVec2),最后,将两类向量进行拼接,得到融合语义特征向量TopicVec(维数2K)。
第三部分,特征向量融合。将各月的语义特征向量TopicVec与事件特征向量EventVec进行首尾拼接,得到相应月份下融合向量表示。部分月份下的融合向量如表6所示。

表6 部分月份下融合向量
3.3 建模与预测结果分析
为便于与基于专家知识[9]构建特征指标的传统做法形成对比,选择预测偏移量为3 个月,并对获取的向量数据集进行错位对齐,构建预测数据集时间跨度为2006 年 4 月至 2017 年 9 月。选择 2006 年 4 月至 2017 年2 月的向量数据作为训练数据,2017 年3 月至9 月的数据作为测试数据,最后利用朴素贝叶斯分类模型进行参数训练。
当主题模型参数K设置为15 时,提出方法的整体表现最佳。以2017 年3 月朝鲜核行为趋势预测结果为例,模型输出朝鲜无核行为发生的概率为7.471 25E-7,发生轻度核行为的概率为0.999 9,发生重度核行为的概率为1.371 87E-8,由此判断2017 年3 月朝鲜发生轻度核行为的可能性最大,这一预测结果与实际标记结果相吻合。在全部用于预测的7个月中,有5个月预测正确,这一结果与基于专家知识构建特征集的预测结果相当。对比结果如表7所示。
最后,为进一步验证本文方法的可行性与有效性,将 2006 年 4 月至 2017 年 9 月共计 138 个月的数据输入训练好的朴素贝叶斯分类模型进行检验,并与基于专家知识构建特征指标的全时间段趋势预测结果进行对比。
在测试时对比了6类不同的组合特征。其中,LDA-S与IDFLDA-S 表示仅利用LDA 或IDFLDA 训练抽取语义特征,LDA-C与IDFLDA-C表示以发起国作为约束条件,利用LDA 或IDFLDA 训练抽取的融合语义特征,EVENT-C 表示仅基于高频事件类型构建事件特征,IDFLDA-EVENT-C 表示利用IDFLDA 抽取的融合语义特征与事件特征构建融合特征。在设定的不同主题数K∈{10,15,20,25,30,35}下,各组合特征在全时间段上的重大事件趋势预测对比情况如图5所示。
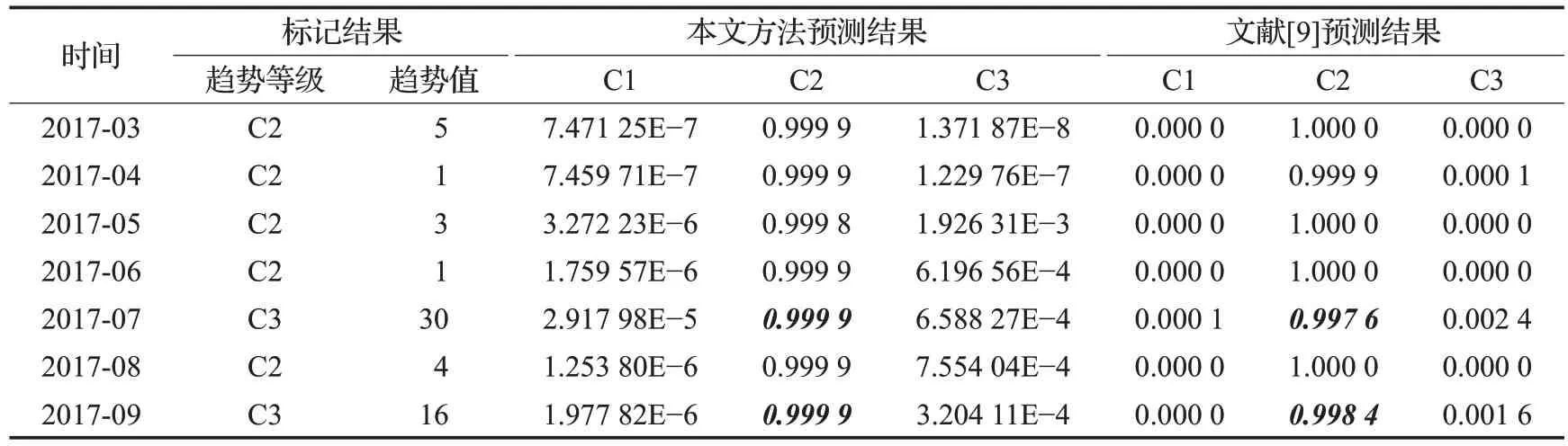
表7 测试月份上的预测结果对比(K=15)

图5 各特征组合形式下全时间段朝核行为预测结果对比
对图5对比结果进行分析,得出以下几点结论:
首先,无论是基于主题模型抽取的语义特征还是基于事件抽取技术抽取的事件特征,在单特征建模上的预测表现已经能在很大程度上接近基于专家知识构建特征的预测结果,验证了利用两类特征构建重大事件特征指标的有效性。
其次,由基于主题模型进行特征建模的预测结果可以看出,在其他参数保持一致的前提下,改进模型IDFLDA 特征建模的预测结果相较于传统LDA 表现更佳,验证了模型改进的有效性。
最后,当融合事件特征与基于IDFLDA抽取的语义特征时,各主题数K下的全时间段的预测表现均优于基于专家知识构建特征的预测结果。当K设为15 时,预测结果最佳,在全部的138 个月中,本文方法能成功预测119个月的朝鲜核行为趋势等级,整体准确率达到86.2%,结果充分论证了该方法的可行性与有效性。
4 结束语
本文针对基于海量新闻数据的重大事件趋势预测研究在特征构建上存在的局限性问题,提出一种融合语义与事件特征的重大事件趋势预测方法。在朝鲜核行为趋势预测表现上,该方法在全时间段的整体预测准确率达到86.2%,预测性能优于依赖专家知识进行特征集构建的传统预测方法,能有效进行重大事件的趋势预测。
该方法的局限性在于,首先,在利用主题模型进行语义特征抽取时,在参数K的选择上,该方法存在一定的随机性;其次,在对事件趋势进行量化时,仍需借鉴专家知识确定事件影响力量化公式。如何在趋势量化上实现自动化以及通过何种手段自适应确定主题模型参数K,实现真正意义上由数据驱动的重大事件趋势预测将是本文下阶段工作的重点研究方向。
猜你喜欢
第一财经(2021年6期)2021-06-10
开放教育研究(2020年2期)2020-03-31
智富时代(2019年3期)2019-04-30
智富时代(2019年3期)2019-04-30
Coco薇(2017年9期)2017-09-07
中国修辞(2017年0期)2017-01-31
股市动态分析(2016年22期)2016-12-27
中国社会历史评论(2016年2期)2016-06-27
纺织服装流行趋势展望(2016年2期)2016-05-04
长江学术(2016年4期)2016-03-11
