
基于MapReduce和Spark的大数据模糊K-means算法比较
2020-09-02 14:19翟俊海田石张素芳王谟瀚宋丹丹
河北大学学报(自然科学版) 2020年4期
翟俊海, 田石, 张素芳, 王谟瀚, 宋丹丹
(1. 河北大学 数学与信息科学学院 河北省机器学习与计算智能重点实验室, 河北 保定 071002;2. 中国气象局 气象干部培训学院河北分院,河北 保定 071000)
聚类分析是数据挖掘的基本任务之一,已成功应用于许多领域,聚类算法可大致分为2类:层次聚类算法和划分聚类算法[1].K-means算法是著名的划分聚类算法,在2006年举行的国际数据挖掘学术会议上评出的十大数据挖掘算法中[1],K-means名列第2位.K-means算法是一种硬聚类算法,具有非此即彼的性质,即一个样例只能属于一个簇.Bezdek[2]对K-means算法进行了改进,提出了模糊K-means算法.模糊聚类建立了样例对类别的不确定性描述,更能客观地反映现实世界,往往比清晰聚类能获得更好的聚类效果.不管是清晰聚类还是模糊聚类,都容易受聚类个数与初始聚类中心的影响,研究人员提出了许多自适应确定聚类个数的方法.针对K-均值聚类算法,Gupta等[3]提出了一种利用最小化聚类中心之间距离快速自动确定聚类个数的方法.受人类观察视野范围内山峰峰顶的启发,Masud等[4]提出了一种确定聚类个数的新方法,该方法用混合高斯模型对观测点和对象之间距离的分布进行建模.Lord等[5]提出了一种利用对象的稳定性确定聚类个数的方法,定义了一个聚类中对象的稳定性指标.Yu等[6]提出了一种利用决策理论粗糙集自动确定聚类个数的方法,文献[7]和[8]对确定聚类个数的方法进行了全面深入的综述.随着大数据时代的到来,聚类算法在大数据环境中的可扩展性研究引起了研究人员的极大关注,已有一些大数据聚类方面的研究成果.例如,Havens等[9]研究了FCM(Fuzzy C-Means)算法在大数据环境中的可扩展性问题,对3种FCM的扩展方法(抽样方法、增量方法和核化方法)进行了比较研究,得出了一些有价值的结论.Ludwig[10]研究了FCM算法并行化实现问题,提出了基于MapReduce的FCM算法,并讨论了其稳定性.Bharill等[11]提出了一种可扩展的迭代抽样FCM算法,可对大数据进行聚类,并用大数据开源平台Spark实现了该算法.Wu等[12]研究了模糊一致性聚类问题,定义了模糊一致性度量指标,提出了基于模糊一致性的大数据聚类算法,并在Spark平台上实现了该算法.王磊等[13]也研究了基于Spark的大数据聚类及系统实现.李应安[14]和阳美玲[15]分别研究了基于MapReduce的大数据聚类算法.基于动态信任评估.张彬等[16]讨论了针对政务大数据分析的云服务平台设计问题.高学伟等[17]讨论了基于Hadoop大数据建模问题.吴信东等[18]对MapReduce与Spark用于大数据分析进行了全面的比较.宋杰等[19]对MapReduce大数据处理平台与算法的研究进展进行了全面而深入的分析.翟俊海等[20]提出了基于Spark和SimHash的大数据K-近邻算法.张素芳等[21]对大数据与大数据机器学习研究进行了全面的综述,具有很高的参考价值.然而,目前还未见到基于Hadoop和Spark的大数据模糊K-means算法的比较研究,从算法执行时间、同步次数、文件数目、容错性能、资源消耗这5方面进行比较,得出的结论对从事大数据研究的人员具有较高的参考价值.
1 模糊K-均值算法
模糊K-均值算法[2]是K-均值算法的改进,它允许一个样例点以不同的隶属度属于不同的簇.模糊K-均值算法最小化下面的目标函数:
(1)
其中,N是样例数,m是大于1的参数,uij是样例xi属于第j个簇的隶属度,cj是第j个簇的中心.与K-均值算法一样,模糊K-均值算法也是一个迭代算法,在迭代过程中,模糊隶属度uij用公式(2)更新,簇中心cj用公式(3)更新.
(2)
(3)
算法的迭代停止条件为
(4)
在公式(4)中,ε∈(0,1),n表示迭代次数.
2 基于MapReduce的模糊K-均值算法
基于MapReduce的模糊K-均值算法包括下面2个MapReduce过程.
第1个MapReduce过程用于计算聚类中心.这一过程包括下面3步:
1) 首先,系统会从HDFS中读取数据并随机生成每个数据隶属于每一簇的隶属度.然后,对数据进行分片,每个分片传入一个Map节点进行处理.并且Map任务在计算完毕后会对中间数据进行排序,使其分区内有序.
2) combiner会将每个Map的计算结果进行合并以减少数据传输,提高运行效率.
3) Reduce会将combiner传来的数据进行合并,从而计算出聚类中心.
第2个MapReduce过程用于计算隶属度.这一过程系统依然会从HDFS中读取数据,进行分片,传递给Map节点并利用之前计算出的聚类中心重新计算隶属度,多个Map节点都会将计算结果传递给Reduce节点进行比较隶属度是否收敛,不收敛则继续迭代,收敛则终止运行.
不同的Map阶段、combiner阶段、Reduce阶段之间互不干扰,都是一个独立的任务,只有前面的任务全都完成之后才能进行后面的任务,并且每一个任务的计算结果都要写入磁盘.图1通过一个例子展示了MapReduce一次迭代的流程.

图1 MapReduce一次迭代的流程Fig.1 Schematic diagram of one iteration by MapReduce
基于MapReduce的模糊K-均值算法包括4个作业、16个任务和4次Shuffle.下面给出基于MapReduce的模糊K-均值算法的伪代码.
1) class Mapper
2) method Map(key ,value ,context)
3) for(i= 1 tok)
4) 隶属度的2次方
5) for(j= 1 ton)
6) 数据与隶属度的2次方相乘
7) end
8) end
9) class Combiner
10) method combiner(key ,value ,context)
11) 具有相同键的数据将其值进行相加
12) class Reducer
13) method Reduce(key ,value ,context)
14) 具有相同键的数据将其值进行相加
15) 计算聚类中心
16) class Mapper
17) method Map(key ,value ,context)
18) 根据聚类中心重新计算隶属度
19) class Reducer
20) method Reduce(key ,value ,context)
21) 计算前后2次隶属度之差的绝对值
22) 判断隶属度之差的绝对值的最大值是否小于阈值
3 基于Spark的模糊K-均值算法
Spark是一种基于内存计算的大数据处理平台,它用RDD(resident distributed dataset)将数据组织在内存中,并通过RDD算子对数据进行操作.基于Spark的模糊K-均值算法需要5次转换操作,共产生5个RDD.图2通过一个例子展示了5个RDD的转换过程.

图2 Spark一次迭代的流程Fig.2 Schematic diagram of one iteration by Spark
Spark在一次迭代过程中需要进行2次Shuffle操作,可以划分成3个阶段.基于Spark的模糊K-均值算法迭代2次被划分为4个阶段,包括8个任务和3次Shuffle.与MapReduce相比,减少了任务数和Shuffle次数,提高了运行效率.下面给出基于Spark的模糊K-均值算法的伪代码.
1) rdd = sc.textFile(Data) //读取名为Data的文件
2) memdeg[n][k] //初始化隶属度
3) memdegRDD = sc.parallelize(memdeg) //并行化
4) while (x是否大于阈值)
5) 计算隶属度的2次方
6) 将数据与隶属度的2次方进行相乘
7) 计算聚类中心
8) 更新隶属度
9) 计算前后2次隶属度之差的绝对值的最大值x
4 基于2种开源平台的大数据模糊K-means算法的理论比较
受文献[18]的启发,下面从算法执行时间、同步次数、文件数目这3方面,对2种大数据模糊K-means算法进行理论比较.
1)算法执行时间
基于MapReduce模糊K-means算法的执行时间主要用于中间数据排序和文件传输.中间数据排序只存在于MapReduce中,这是为了对数据进行初步的归并操作,避免因为传输文件数量过多给网络造成重大压力.在运算时,MapReduce需要执行2次MapReduce操作.在第1次操作中,每个Map需要比较的次数为3,每个Combiner需要比较的次数为1;在第2次操作中,每个Map需要比较的次数为1.因此在一次迭代任务中,MapReduce任务需要比较4次,而Spark在处理数据时不需要中间结果有序,所以不需要比较.
在MapReduce中,假设平均每个Map任务处理m条数据,平均每个Reduce处理r条数据,可以得出排序时间为O(mlogm),而在Spark中,排序时间为O(0).
关于中间数据的传输时间,在不考虑网络传输性能带来的差异的情况下,假设其传输速度为Cr,需要处理的数据大小为D,所以传输时间为D×Cr.在MapReduce任务中,数据是由执行Map任务的节点发送到Reduce节点的,需要执行2次Map-Reduce任务,2次发送的数据量D1=8,D2=8,所以1次迭代时间为16Cr,2次迭代时间为32Cr.Spark任务的执行过程与MapReduce相同,需要发送2次数据,第1次传送数据D1=4,D2=8,所以1次迭代时间为为12Cr,2次迭代时间为为24Cr.
2)文件数目
如果文件数目过多,在执行计算时就会有大量I/O操作,严重影响系统性能.所以应该尽量减少数据文件的数量.
在MapReduce处理数据的过程之中,每个Map节点都会产生一个文件,即使是不同的分区,数据也会存储在一个文件之中,这是由MapReduce的数据存储原理决定的,即每个数据都是由键值对的形式存储,面对不同的分区可以设置不同的键.而在Spark中,不需要对数据进行预排序,因此需要对数据进行分区存储.
因为MapReduce一次迭代共产生4个Map任务,所以产生2+2=4个文件;在Spark中,每个Map任务被划分为2个分区,从而共产生2*2+2*2=8个文件.
3)同步次数
因为在MapReduce计算模型中,只有所有的Map任务完成后才可以进行Reduce任务,所以MapReduce是同步模型.而Spark可以看作为异步模型,在需要网络传输时,它才需要同步.在算法执行的过程中,同步次数执行的越少,算法的执行速度就越快.
在执行模糊K-均值聚类时,MapReduce与Spark的1次迭代同步次数都为2次,2次迭代MapReduce的同步次数为4次,Spark为3次.随着算法迭代次数的增多,Spark比MapReduce的优势会越来越明显.
4)容错性能
在实际应用中,难免遇到用户代码错误、进程崩溃、机器宕机等情况,良好的容错性能能使系统快速地从故障中恢复过来,合理的容错机制是算法执行的保证[20].使用MapReduce的好处是它有很强的容错能力,使你的Job能够成功完成.MapReduce通过冗余备份实现容错,虽然会产生大量的I/O操作,但是在计算出现问题时容易恢复,安全性比较高.而Spark通过血缘关系实现容错,文献[19]系统分析了MapReduce和Spark的容错能力,证明了MapReduce的容错性能确实比Spark要好.
5)资源消耗
在处理大数据问题时,不同的算法对计算机性能的要求是不同的,如排序和查询算法需要有大量的I/O操作,对网络带宽要求比较高;而执行K-均值、PageRank等迭代算法时需要做大量的计算,对CPU要求比较高.当使用MapReduce与Spark运行模糊K-均值算法时,MapReduce在内存、网络以及磁盘的占用率上都要低于Spark.显然,MapReduce对硬件要求比Spark更低,成本更低.
5 基于MapReduce和Spark的大数据模糊K-means算法的实验比较
实验所用的数据集包括3个人工大数据集和4个UCI数据集,对基于2种开源平台的大数据模糊K-means算法从运行时间和迭代次数2方面进行了实验比较.为描述方便,基于MapReduce的模糊K-均值算法记为MK-Means,基于Spark的模糊K-均值算法记为SK-Means.4个UCI数据集分别是Covtype、HT_Sensor、Poker-hand-testing和SUSY;3个人工大数据集都是用高斯分布生成的.第1个人工数据集GAUSS1是一个2类包含100万个点的数据集,每类包含50万个样例.2类服从的高斯分布为p(x|ωi)~N(μi,∑i),i=1,2,参数列于表1中.

表1 GAUSS1的参数
第2个人工数据集GAUSS2是一个包含3类样例的数据集,每一类包含40万个样例,服从的概率分布分别为
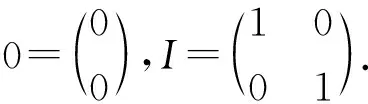
第3个人工数据集GAUSS3是一个4类包含100万个点的3维数据集,每类250 000个点,每类服从的高斯分布为p(x|ωi)~N(μi,∑i),i=1,2,3,4,参数如表2所示.
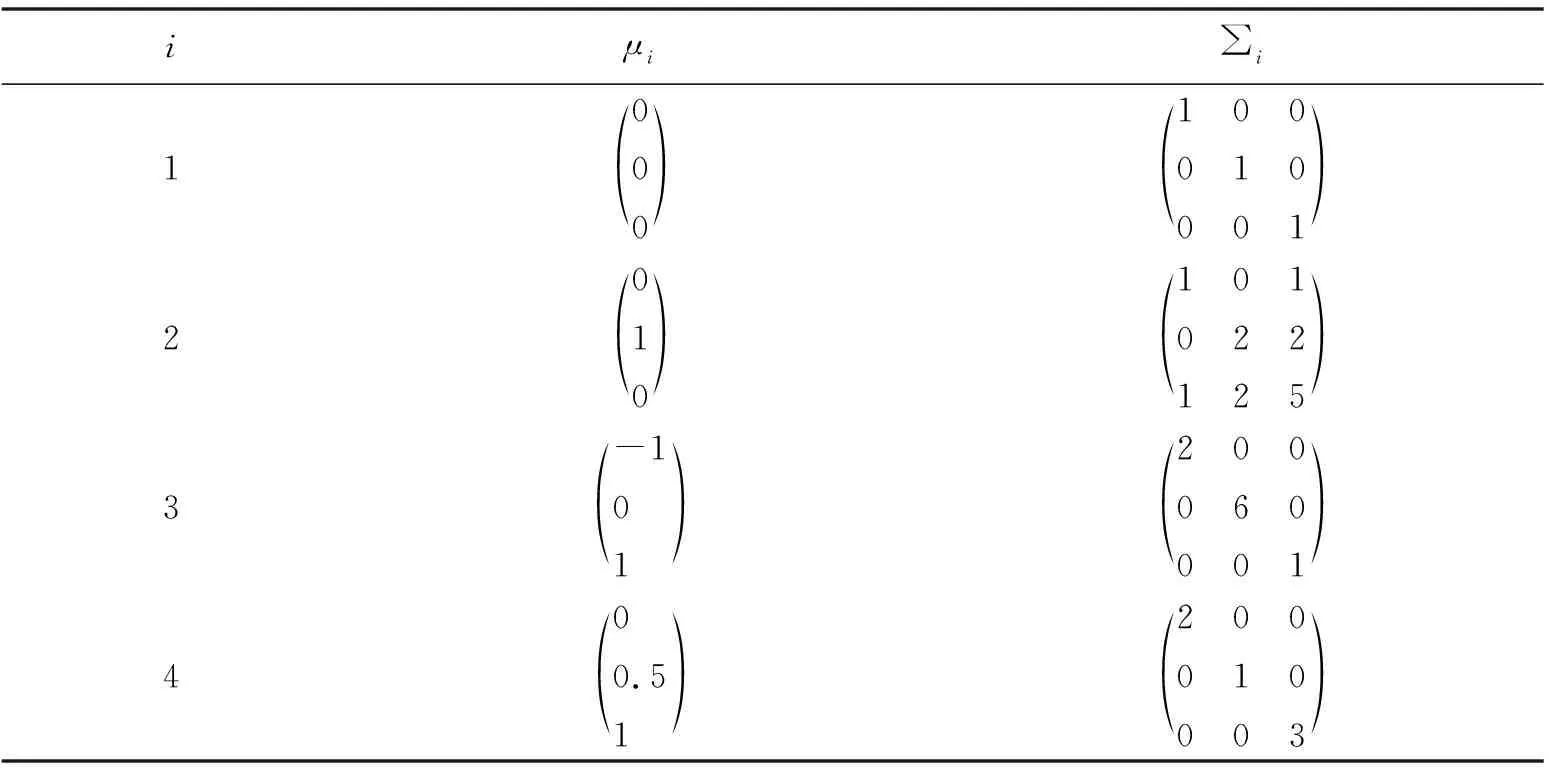
表2 GAUSS3的参数
实验客户端开发环境为Eclipse,JDK版本为jdk-7u80-windows-x64.实验所用集群开发环境主、从节点的基本信息如表3所示.

表3 实验环境的基本信息
在人工数据集的实验中,隐去数据集的类别标签,并设置聚类数据K为实际的类别数,实验结果列于表4中.

表4 2种算法实验比较的结果
从表4可以看出,相同的数据在不同平台迭代次数并不完全相同,是因为数据的初始隶属度的确定具有随机性,具有一定的差异.其中,GAUSS3,HT_Sensor与SUSY差异较大一些,是因为GAUSS3,HT_Sensor数据集的类别数较多,SUSY的数据量较大,随机性也相对大一些,迭代次数差异相较于其他数据自然也大一些.
5 结束语
本文对基于MapReduce和Spark的2种大数据模糊-K均值算法进行了比较研究,得出如下结论:1)从算法执行时间上看,基于MapReduce的模糊K-均值算法较慢,基于Spark的模糊K-均值算法较快;2)从需要缓存的文件数目方面来看,基于MapReduce的模糊K-均值算法需要缓存的较少,基于Spark的模糊K-均值算法需要缓存的较多;3)从同步次数方面来看,基于MapReduce的模糊K-均值算法需要的同步次数较多,基于Spark的模糊K-均值算法需要的同步次数较少;4)从容错性能方面来看,基于MapReduce的模糊K-均值算法较强,而基于Spark的模糊K-均值算法较弱,这种容错性能差异是由大数据开源平台决定的,而不是由模糊K-均值算法决定的;5)从资源消耗方面来看,基于MapReduce的模糊K-均值算法资源消耗较少,基于Spark的模糊K-均值算法资源消耗较多.
猜你喜欢
商用汽车(2021年4期)2021-10-13
阅读与作文(小学高年级版)(2020年8期)2020-09-12
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
现代计算机(2018年27期)2018-10-25
数学大世界(2018年35期)2018-02-22
发明与创新·中学生(2017年5期)2017-05-12
雷达学报(2017年6期)2017-03-26
军事运筹与系统工程(2016年3期)2016-09-26
互联网天地(2016年1期)2016-05-04
