
基于Scrapy的物流资讯网站群爬虫系统设计与实现
2020-08-28 10:14:24邓子云
物流技术与应用 2020年8期
文/ 邓子云
全国有不少物流行业协会、学会网站,会经常发出各种行业资讯,能否有一种数据收集软件能自动收集这些资讯供公共使用呢?这样,物流行业人士不必为查找每一个网站而费时费力,而只需要在一处查阅收集后的所有资讯。有了这种自动收集工具,还可以在收集到数据后作大数据分析,进而形成更多的行业应用,如可作物流行业的舆情分析、热点分析、网站活跃度分析等。这些应用的前提就是要研发出具有自动收集物流资讯网站内容功能的爬虫系统。
现已有不少相对成熟的爬虫系统框架,如Crawler4j、Scrapy等。Crawler4j和Scrapy分别支持用Java语言、Python语言开发爬虫系统,均支持多线程爬取数据,且均为开源系统。已有许多应用系统基于这些框架编写,如物流车货源信息的抽取系统、农业网络空间信息系统等。为确保爬虫系统的成熟和稳定,这里不打算研发新的爬虫系统框架,而是使用现有成熟、开源的Scrapy框架技术来研发出物流资讯网站群的爬虫系统。
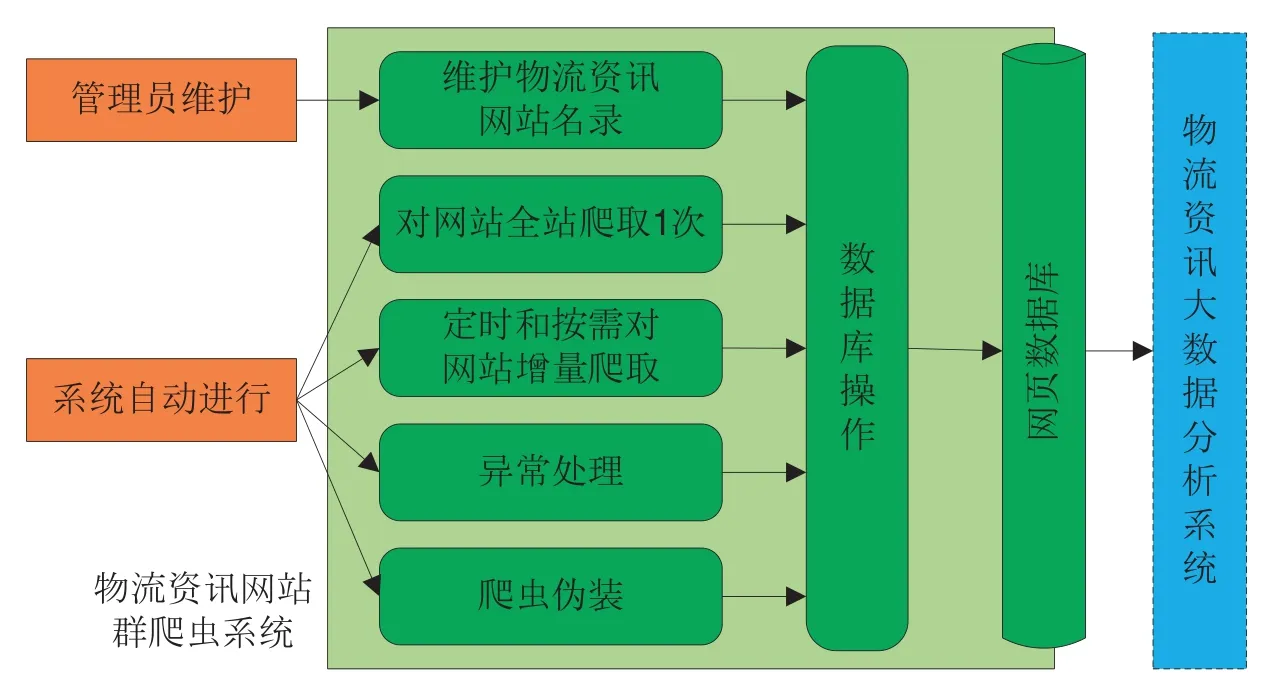
图1 物流资讯网站群爬虫系统的功能设计
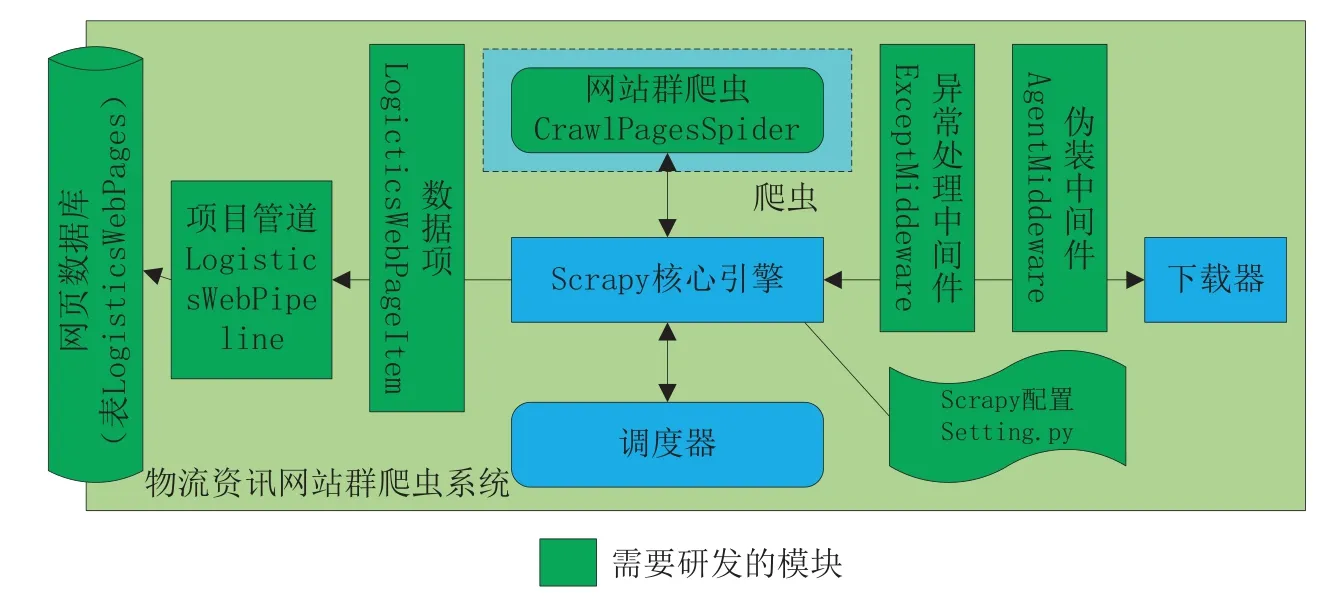
图2 物流资讯网站群爬虫系统的技术架构
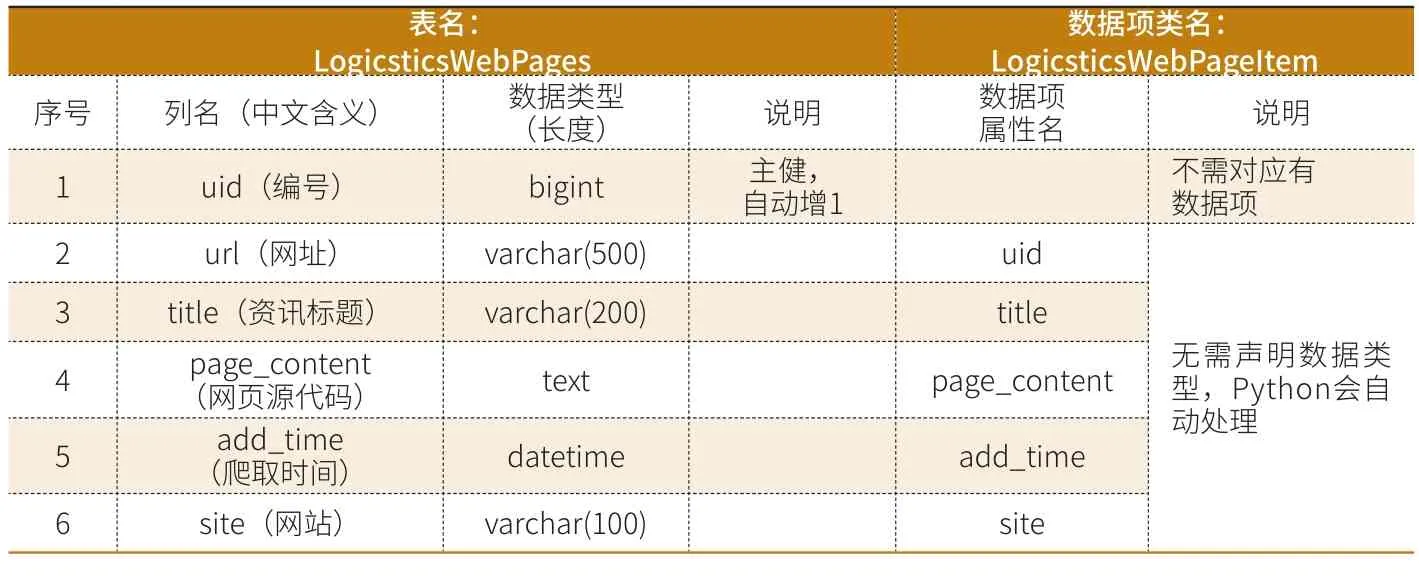
表1 设计的MySQL的数据库表及对应的数据项
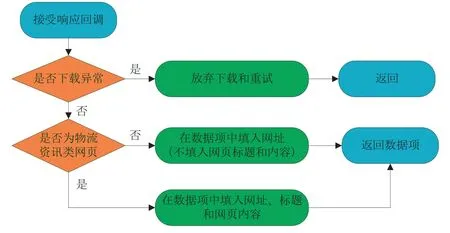
图3 爬虫类CrawlPagesSpider的回调函数解析response的过程
一、爬虫系统的设计
采用Scrapy框架来研发物流资讯网站群爬虫系统与不采用框架技术研发该系统有很大区别。首先应从业务需求和设计的角度分析设计上考虑的偏重之处,其次应分析清楚系统的技术架构,然后再予以实现。
1.业务需求和设计上的偏重
从业务需求的角度来看,爬虫系统需要将网页内容、网址等信息先爬取下来保存到数据库里。爬取网页时需要注意限定爬取的网页范围为物流资讯类网站中的网页,且不爬取网页以外的其它文件(如图片、PDF、Word文档等)。由于在收集物流资讯的时效上不要求实时更新,因此在功能实现上应先做全站爬取,再定时和在需要的时候做增量爬取,增量爬取的定时间隔可控制在1天。
从设计的角度来看,Scrapy框架已将待爬取队列、已爬取队列、网页查重、多线程爬取等爬虫需要实现的通用功能实现,在物流资讯网站群爬虫系统中重点要实现异常处理、爬虫伪装、数据库操作等功能。
因此,根据物流资讯网站群爬虫系统的业务需求和设计上的偏重,可作如图1所示的功能设计。
2.爬虫系统的技术架构
物流资讯网站群爬虫系统的技术架构如图2。图中绿色部分是需要开研发的模块,其它部分是Scrapy已有的模块,这些不需再行研发。
从技术架构来看,下载器、调度器、核心引擎、队列这些Scrapy都已经实现,但应研发以下模块:
(1)网页数据库。这里用MySQL实现,用表存储数据。存储网页数据用一个表LogisticsWebPage就可实现。使用MySQL的原因是因为这种数据库开源,可支持大容量数据的存取和并发访问,并且具有良好的操作系统可移植性,Windows平台、Linux和Unix平台都可适配。
(2)数据项。需要定义一个数据项类,这个类对应于MySQL中存储数据的表。为简单起见,这里用一个数据项类LogisticsWebPageItem对应数据库中的表LogisticsWebPages,数据项类的一个属性对应表中的一列,这样一个LogisticsWebPageItem对象就对应着表LogisticsWebPages中的一条记录。
(3)网站群爬虫。对于网站群的全站爬取和增量爬取,只需要研发一个爬虫类CrawlPagesSpider。增量爬取功能的实现不需要再行编制程序,在运行爬虫的命令中加入网页查重配置参数即可。这是因为Scrapy已经实现了网页查重功能,应用哈希技术记录了已经访问过的网页,在再次启动爬虫时Scrapy会自动判断网页是否已经下载过,如没有下载过则爬取,如已下载过则略过。Scrapy按URL(Uniform Resource Locator,统一资源定位器)、POST数据、Method这3项来判断网页是否已下载过,如果这3项合起来做哈希运算可找到记录的相同项则表示已下载过。这种网页查重办法已可适用于物流资讯网站群爬虫系统的需求。
(4)项目管道。需要在项目管道中编制程序,将数据项用insert SQL语句把网页数据存储到MySQL数据库中。
(5)2个中间件。需要研发异常处理中间件ExceptMiddleware和伪装中间件AgentMiddleware。异常处理中间件ExceptMiddleware用于处理下载过程中产生的所有异常,包括超时异常、域名解析异常等,以增强爬虫系统的健壮性、稳定性和保持一定的爬取速度,不至于在下载引发异常时,部分线程中断、无限等待和向Scrapy容器抛出未处理的异常。伪装中间件AgentMiddleware用于防止物流资讯网站拒绝爬取,可以采用伪装浏览器和使用代理服务器2种方法,经过考察发现物流资讯网站绝大多数没有反爬虫系统,因此这里采用简单的随机伪装各种浏览器的办法。
(6)Scrapy配置。需要修订Scrapy的配置参数文件setting.py,用于将研发的中间件、数据项类配置进Scrapy容器,并设置下载超时时间、数据库连接、日志水平等参数。
二、爬虫系统的实现
根据物流资讯网站群爬虫系统的技术架构设计,下面详细讨论研发的网页数据库、数据项、网站群爬虫、项目管道、2个中间件、Scrapy配置的实现。
1.数据库和数据项
设计的MySQL的数据库表及对应的数据项如表1。为防止乱码数据的产生,在创建表时,应将字符集设置为“utf8”,即在“create table”语句的最后加上参数“DEFAULT CHARSET=utf8”。
为兼容网址为文件(如图片、PDF、Word文档等)的情况,当爬虫遇到这样的文件时,只记录网址、网站、爬取时间,但不记录文件内容,这样仍可通过Scrapy的查重功能防止重复访问这些网址。此外,由于默认情况下,MySQL支持的SQL语句最长为1M,考虑到网页源代码的长度可能超过1M而会引发异常,可使用MySQL的“set global”语句修改“max_allowed_packet”值为更大的值,这里将其设置为“1024*1024*32”(即32MB)。
在设计完数据项类LogisticsWebPageItem后,应修改Scrapy的配置参数文件setting.py,加入以下配置以将数据项类配置进Scrapy容器:

2.网站群爬虫
爬虫类CrawlPagesSpider继承自Scrapy的CrawlSpider类,有两个固定的属性需要设置。一个属性是allowed_domains,是指允许爬虫访问的域名,为一维数组,这里应设置为管理员维护的物流资讯网站的域名集。另一个属性是start_urls,表示要爬取的网站首页,为一维数组,这里应设置为管理员维护的物流资讯网站的首页网址。
在爬虫类CrawlPagesSpider的回调函数中应根据response对象解析出要存储的数据到数据项Item中,再返回这个Item,这个过程如图3。
首先应判断response对象看是否有下载异常,判断的根据是异常处理中间件设置的url值,如果为空则表示有异常,继而放弃下载和重试。如果没有异常,继续判断response对象的内容是否为物流资讯类网页,判断的根据是response.encoding值,如果存在则为物流资讯类网页,继而设置数据项中的网址、标题和网页内容。其中,标题可以用Xpath从response.text中获取。如果获得response.encoding值引发了异常(图片、PDF、Word文档等非网页类文件的response对象没有encoding值),则判断为非物流资讯类网页,在数据项中只填入网址,而不设置网页标题和网页内容。
在爬虫类CrawlPagesSpider的回调函数中不应操作数据库,操作数据的工作应放在项目管道中完成。
3.项目管道
项目管道类LogisticsWebPipeline的工作内容是:从Scrapy配置文件setting.py中获得数据库连接参数并设置数据库连接池的连接参数;从数据库连接池中获得一个连接;根据数据项生成一个insert SQL语句;执行insert SQL语句;及时捕获以上工作中的异常,并作出日志记录。
4.两个中间件
根据图2所示的技术架构,设计了2个中间件,一个为异常处理中间件,另一个为伪装中间件,其实现原理均比较简单,不作赘述,但应在Scrapy中作出配置:

5.Scrapy配置
在setting.py配置文件需要配置的参数中,前述已经给出了项目管道和中间件的配置,不再赘述,但还应给出如表2所示的配置参数,以优化爬虫的性能。
在以上参数的设置上,爬取的并发数应视爬虫系统所在的计算机性能而定,默认值为32,这里因采用了较高性能的服务器而设置为100;将COOKIES_ENABLED和RETRY_ENABLED参数设置为False,可提升爬虫的性能,以免反复去尝试下载某个网页;将DOWNLOAD_TIMEOUT设置为80是考虑到在可接受的80秒以内下载完一个网页,以免下载网页的线程进入太长时间的等待而降低整个爬虫系统的性能。
三、实现环境与性能分析
物流资讯网站群爬虫系统使用了2台服务器,已经对10个物流资讯类网站作了全站爬取和增量爬取,具体情况分析如下。
1.软硬件及网络环境
物流资讯网站群爬虫系统使用了1台爬虫服务器和1台数据库服务器,这2台服务器的软硬件环境及网络环境如表3,2台服务器均放置于本文作者所在单位的中心机房。
2.爬取效果与性能分析
经过对中国物流与采购联合会(www.chinawuliu.com.cn)、江西省物流与采购联合会(www.jiangxiwuliu.com.cn)、北京物流协会(56beijing.org)等10个网站的爬取,实验中一共爬取了858,523个网页,花去了1791.25分钟(29.85小时),存储数据库共占用21,413MB空间,其分布情况如图4。

表2 setting.py配置文件中的其它配置参数
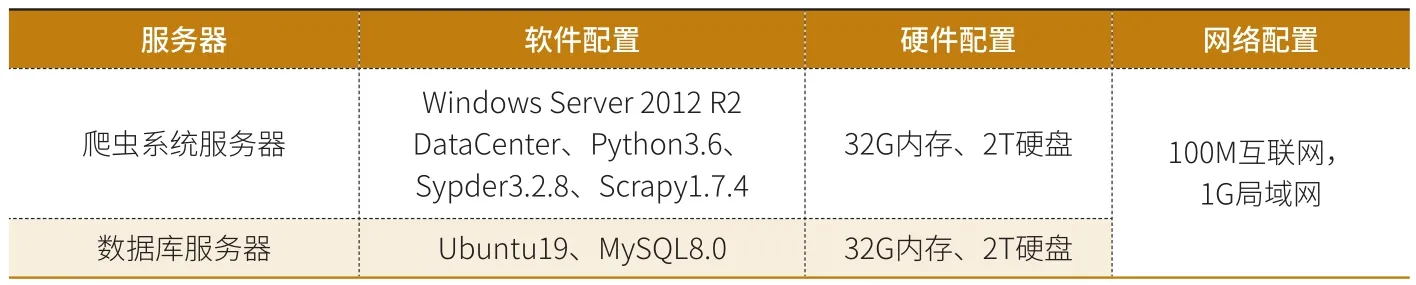
表3 软硬件环境及网络环境
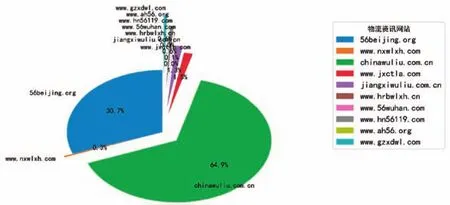
图4 从10个物流资讯网站爬取的网页数量图5 不同线程数爬虫的爬取速度
其中,从中国物流与采购联合会网站爬取了556,932个网页,从北京物流协会网站爬取了263,356个网页,从这两个网站爬取的网页数量占到总数的95.6%,可见资讯信息相对比较集中。
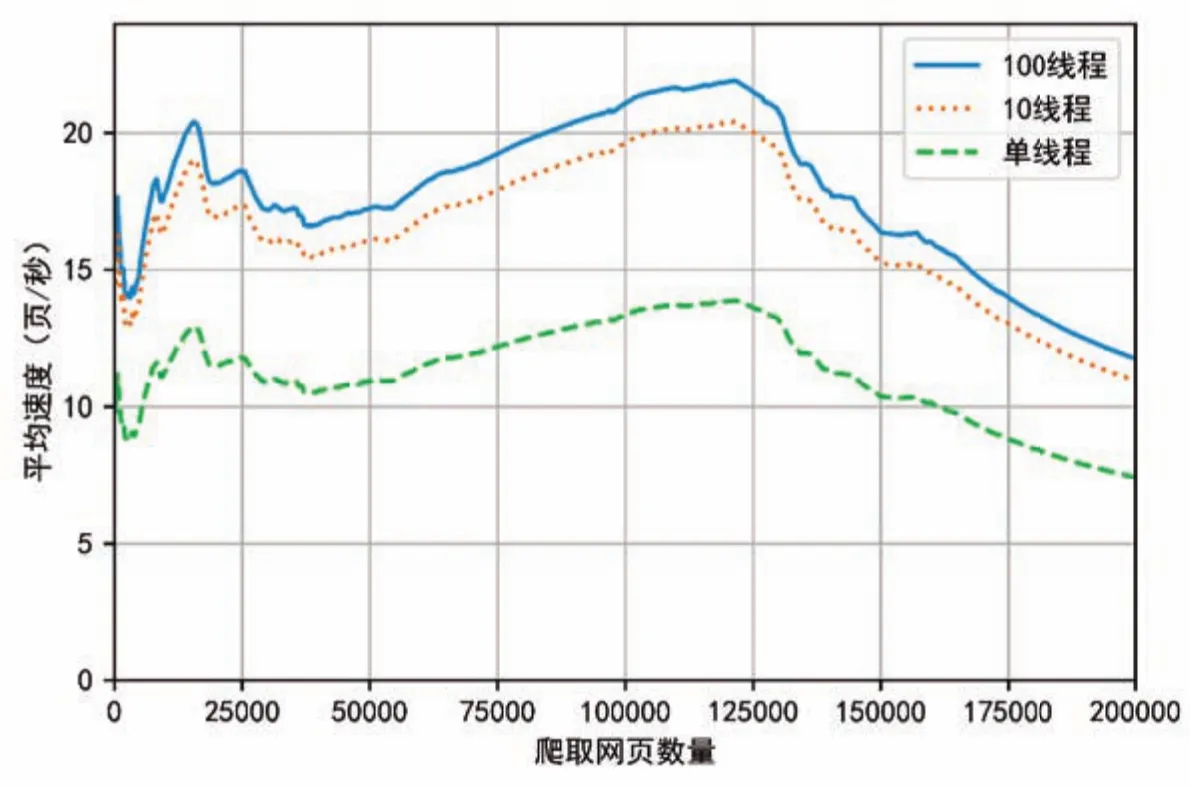
以爬取前20万个网页为例,计算爬取网页的平均速度,平均速度变化如图5所示。速度的计算公式如(公式1)所示。

式1中,s表示累积爬取的时间,n表示累积爬取的网页数量。
从图5来看,爬取速度峰值达到了22.3个/秒,还可以发现一些规律:线程数越多,爬取速度越快;线程数设置为10和100个速度差距并不明显;在爬取到12万个网页左右,爬虫爬取速度均呈下降趋势。可见,在采用10个以上的线程并行爬取后,增加线程数并不能显著提升爬虫的性能。
四、结束语
根据对基于Scrapy的物流资讯网站群爬虫系统的需求分析和技术架构设计,应重点研发该系统的网页数据库、数据项、网站群爬虫、项目管道、2个中间件、Scrapy配置等模块。应用该爬虫系统已经爬取了10个物流资讯类网站的85.85万个网页。从实验情况来看,中国物流与采购联合会、北京物流协会网站的信息量较大,两者占比合计达到95.6%;增加线程数并不能明显加快爬取的速度,并发线程数设置为10即可。从爬虫的爬取速度来看,还需要做出优化处理,应争取把爬虫性能提升到100万个/天以上;爬取的物流资讯类网站数量太少,应扩大到100个以上。后续还将继续展开以下研究:
1.优化爬虫,加大爬取的物流资讯类网站数量。从一次性提交多个SQL语句、调优爬虫性能参数等方面继续提升爬虫性能。
2.研发大数据分析与展示平台。继续开发程序清洗下载的海量网页数据,提取出网页结构和文字内容,采用TensorFlow对下载的海量的网页作分词、词频等技术处理,在Web系统中展示大数据与人工智能分析的结果,供物流行业广泛使用。
猜你喜欢
房地产导刊(2022年10期)2022-10-18 08:03:52
现代信息科技(2021年21期)2021-05-07 02:54:12
甘肃科技(2020年19期)2020-03-11 09:42:42
计算机与生活(2019年11期)2019-11-12 05:41:02
科技与创新(2019年14期)2019-08-12 12:55:20
电子制作(2018年14期)2018-08-21 01:38:10
电子测试(2018年10期)2018-06-26 05:54:02
电子测试(2018年1期)2018-04-18 11:53:04
电子制作(2017年9期)2017-04-17 03:00:46
中国交通信息化(2014年4期)2014-06-05 03:51:15
