
基于邻域代价敏感三支决策的痛风诊断模型
2020-08-19 10:42孙秉珍楚晓丽
计算机工程与应用 2020年16期
张 萌,孙秉珍,楚晓丽
西安电子科技大学 经济管理学院,西安 710071
1 引言
分类决策问题是机器学习和数据挖掘领域的研究热点。传统的分类决策模型多为“非此即彼”的二支决策,通过从训练数据和历史经验中提取出决策模型,将样本分为正样和负样,继而做出接受或者拒绝决策。在现实生活中决策信息往往不完备,传统的二支决策会导致信息不充分的样本难以被正确划分,造成较大的误分类率和误分类代价。针对这个问题,三支决策通过引入延迟决策,将决策信息不充分的样本划分到边界域中,降低决策代价,提高了决策的准确性。
三支决策是Yao等[1]在概率粗糙集和决策粗糙集的基础上根据实际决策情况提出的决策理论。三支决策通过引入分类损失函数,基于贝叶斯最优损失代价计算阈值(α,β)。假设给定对象x属于某个类X的条件概率为P(X|x),将P(X|x)大于或等于α的对象划分为X的正域,做出接受决策;将P(X|x)小于或等于β的对象划分为X的负域,做出拒绝决策;当P(X|x)介于α和β之间时,对象被划分到X的边界域,做出延迟决策。在决策过程中,将有把握的且信息全面的对象直接给予拒绝或者接受的判断,而对信息不充分且无法做出立刻判断的对象延迟其决策,待信息充分时再对其做出决策,从而避免了错误拒绝和错误接受决策带来的损失。三支决策在实际生活中应用广泛,例如在医疗诊断过程中,当患者的临床病症信息表现充分或者完全没有病症信息时,医生可以立马对患者做出接受治疗或不需治疗的决策;而当患者临床病症信息表现不充分,不能完全确诊患病,医生对其进一步观察待有更明显的症状时再做出判断。三支决策自提出以来,由于其语义符合实际和决策过程的优越性,成为国内外学者研究热点。目前,关于三支决策的理论研究获得了一定的进展。刘久兵等[2]提出确定直觉模糊三支群决策模型概率阈值的方法,解决了阈值难以确定的问题;胡峰等[3]提出基于三支决策的主动学习方法,通过对正域、负域和边界域中的无标签样本进行分别打标处理,解决样本无标签的问题;方宇等[4]提出了代价敏感学习的序贯三支决策模型,并对决策结果代价和决策过程代价的平衡问题给出了两个优化方向;Qian等[5]提出了基于多个不同阈值的广义多粒度序贯三支决策模型,解决了传统序贯三支决策无法适应多视图多阈值粒度结构的情况,从定量角度构建了五种多粒度序列三向决策模型,讨论了这些多粒序贯三向决策的对应关系和不确定性测度。这些三支决策理论研究广泛应用于图像处理[6-8]、医疗诊断[9-10]、评估管理[11-13]、物流动态调控[14]、文本分类和文本情感分析[15-16]中。其中,Savchenko[8]将基于序贯三支决策和粒计算的算法运用到图像识别,提高了图像识别的速度。Maldonado等[13]将三支决策模型运用到信用评分管理,对于无法立刻进行评估的客户进入第二阶段进行再决策,并对智利7 000多个小型企业的信用申请进行分析研究。董新雁等[14]将物流任务转化成决策信息表,基于三支决策理论,建立虚拟物流任务动态调控模型,并验证其有效性和合理性。张刚强等[15]运用序贯三支决策对中文评论进行情感分析,通过将粒度细化提高分类效果。
三支决策建立在决策粗糙集模型上,且传统的粗糙集模型[17]只能处理离散型数据,很难对具有符号型、连续型数值的混合信息系统进行处理。对于连续型数据则需离散化,而将连续值转换为离散值会造成大量信息的丢失,导致分类精度不高。在现实应用中,信息系统中存在多种类型的数据是很普遍的,例如在医疗检查结果中,性别和血型为符号型数据,而血压和血糖等指标为连续型数据。因此本文在混合信息系统的基础上引入邻域关系,建立了基于邻域关系的决策粗糙集模型,同时处理具有连续值和离散值的混合信息系统,降低了数据处理过程中信息的丢失,保留数据的真实性。然而现有的基于决策粗糙集模型三支决策分类方法,由于边界域的存在,使得在算法在分类过程中将一些模糊的、根据现有信息不能立即做出决策的对象划分到边界域中,造成边界域中大量数据的冗余。当对边界域中的数据进一步分类时,由于数据信息不完备,无法进行准确划分,会造成很大的代价损失,降低分类的准确性[18]。例如在医疗诊断中,边界域中存在大量冗余数据会延迟患者的治疗时间,给患者带来巨大的代价和成本损失。已有三支决策模型对边界域数据处理的研究还较少。其中对边界域数据处理多是基于对象之间距离和相似度来确定数据的最终分类[19]。这种方式没有考虑到分类问题的代价敏感性,分类效果与采用的距离公式和特征点的选取有关,在分类数据特征不明显的情况下,分类效果欠佳,且不利于实际应用中的规则获取。针对上述问题,本文提出了基于邻域决策粗糙集的二阶段多次迭代分类方法,在基于邻域决策粗糙集三支分类的结果上,多次迭代将测试集中的正域数据加入到训练集中形成新的训练集,测试集中的负域和边界域形成新的测试集[20]。在多次迭代过程中,训练集中的数据特征更加明显,分类效果更加明显,分类精度有所提高。
痛风是由于人体内嘌呤的物质代谢发生紊乱,尿酸盐结晶沉积在关节腔引起炎性反应,出现关节红肿热痛。痛风性关节炎只是痛风危害的一种症状表现,更重要的是对肾脏的危害,由此诱发冠心病、动脉硬化、高脂血症、高血压病和糖尿病等[21]。目前,我国高尿酸血症患者人数已经达到1.7 亿,其中痛风患者超过8 000 万人。痛风患病率在1%~3%之间,且呈持续上升的趋势。国内外调查结果显示,目前医生对痛风病的认识不足,诊断不规范。随着互联网快速普及和数据的海量增长,在医疗方面通过运用数据挖掘等技术,可以提高医疗行业生产力,提高医疗资源利用率。比如通过数据分析对医疗救治流程优化,提高诊断效率和救治质量,降低病人的诊断成本和身体损害;在公共卫生方面,通过大数据分析对流感、病毒等疾病进行预测,为预防和决策提供支持,降低人民的损失,节约医疗资源。传统的痛风诊断是由专家进行诊断,对于痛风的成因研究和相关指标分析多用数理统计方式,将其与数据挖掘技术和理论结合的研究甚少。本文把三支决策思想和数据挖掘技术引入痛风诊断决策问题,尝试给痛风临床诊断决策提供较为客观的诊疗方法和参考。
本文根据现有问题特点,提出基于邻域的决策粗糙集模型,将邻域关系引入到决策粗糙集模型中处理混合信息系统,并提出了基于邻域决策粗糙集多迭代的分类方法处理边界域中的冗余数据,最终得到基于代价敏感三支分类结果。该模型一方面解决了传统粗糙集模型无法处理连续值属性,对噪音数据敏感的不足;另一方面,通过引入代价矩阵建立邻域决策粗糙集模型并对数据多次迭代处理,得到较高的分类准确率和较低的分类代价。最后将该模型应用到痛风诊断中,验证了其有效性和合理性。这对诊断痛风患者和分析指标之间潜在关系有着极高的优越性。
2 准备知识
给定一个决策信息表S=<U,A=C∪D,V,f> ,其中U是非空样本集,称为论域,A是有限非空属性集,C是条件属性集,D是决策属性集。Va表示属性a的值域,f表示一个信息函数,f:U×A→V。
2.1 邻域粗糙集
定义1 对于B⊆A,xi∈U,xi在子空间B上的邻域定义为:
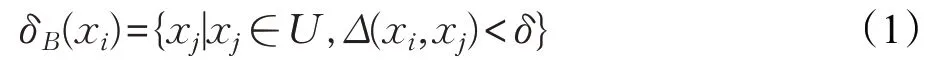
其中,Δ表示距离,f(xi,ak)表示样本xi在属性ak上的取值[22-24]。

当p=1 时,Δ表示曼哈顿距离;当p=2 时,Δ表示欧式距离;p=∞时,Δ表示切比雪夫距离。
对于离散型数据,当xi、xj在属性ak上取值相同时:
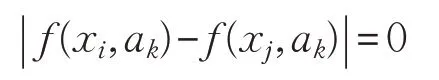
当xi、xj在属性ak上取值不同时:

定义2 给定(U,N),N是U上的一个邻域关系,对于任意X⊆U,定义X关于N的上近似和下近似如下:

其中正域,负域和边界域分别如下:

2.2 决策粗糙集
在DTRS(Decision Theoretic Rough Set)模型中,给定数据对象x,状态集表示x可能的状态集,对象x属于等价类X的可能性描述为P(X|[x]),R={aP,aB,aN}表示对象x可能的三种决策行为:接受、延迟、拒绝。aP、aB、aN分别表将一个对象划分到正区域POS(X) ,负区域NEG(X) ,边界区域BND(X)中。P(x|[X])表示当对象x属于等价关系[X]的概率,λPP、λBP、λNP分别表示当x属于等价关系[X]时,采取aP、aB、aN的代价。同理λPN、λBN、λNN分别表示当x不属于等价关系[X]时,采取aP、aB、aN的代价。
根据对象x的条件概率和代价,可以计算出当对象x做出不同的决策付出的代价如下:

根据贝叶斯最小风险原则,可以得到如下规则:
(1)如果C(aN|[x])<C(aB|[x]),C(aN|[x])<C(aP|[x]),则x∈NEG(X)。
(2)如果C(aB|[x])<C(aN|[x]),C(aB|[x])<C(aP|[x]),则x∈BND(X)。
(3)如果C(aP|[x])<C(aB|[x]),C(aP|[x])<C(aN|[x]),则x∈POS(X)。
在日常生活中,往往做出错误决策的代价要大于做出正确决策的代价,由语义信-息可得λPP≤λBP≤λNP,λNN≤λBN≤λPN,P(X|[x])+P(X|[x])=1 ,决策规则可以简化为:
(1)如果P(X|[x])≥γ,P(X|[x])≥α,则x∈POS(X)。
(2)如果P(X|[x])≥γ,P(X|[x])≤β,则x∈NEG(X)。
(3)如果P(X|[x])≥β,P(X|[x])≤α,则x∈BND(X)。其中α、β、γ根据已知的代价函数计算如下:

由上述决策规则(1)易得α >β,考虑代价满足以下条件:
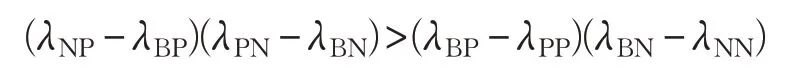
可以得到 0 ≤β <γ <α≤1,决策规则可简化为:
(1)如果P(X|[x])≥α,则x∈POS(X)。
(2)如果P(X|[x])≤β,则x∈NEG(X)。
(3)如果β <P(X|[x])< α,则x∈BND(X)。
由于λPP、λNN表示分类正确的代价,故一般设λPP=λNN=0。

令P(X|[x])= p,可以计算出在整个决策信息表中,决策代价如下:

2.3 邻域决策粗糙集
定义3 给定 (U,N),X⊆U,定义x关于子空间B⊆A在N上的上近似和下近似如下:
传统成本管理过程中,成本信息量较大、部门沟通不及时、项目费用控制不到位等都是其主要的管理问题所在。在BIM项目成本信息管理中,工程管理人员借助基础平台层、数据资源层、业务支撑层、成本应用层和用户管理层五个层面的应用,有效的确保了成本管理的规范化:

对于子集X⊆U,X相对于B⊆C的正域、负域、边界域定义如下:

则决策D关于B⊆C的正域、负域、边界域定义如下:

同理也可以得到如下规则:
(1)如果p(X|δB(xi))≥α那么xi∈POS(D)。
(2)如果p(X|δB(xi))≤β那么xi∈NEG(D)。
(3)如果β≤p(X|δB(xi))≤α那么xi∈BND(D)。
为了定量的计算分类能力,定义D关于B⊆C的分类质量如下:

3 算法设计
3.1 基于邻域决策粗糙集属性约简算法
定义4 给定有限集合B⊆C,若满足则称B是一个独立属性子集,如果对则称B为C的一个属性约简。
在邻域决策粗糙集系统中,∀B⊆C,∀a∈C,定义属性a相对于子集B的属性重要程度为:
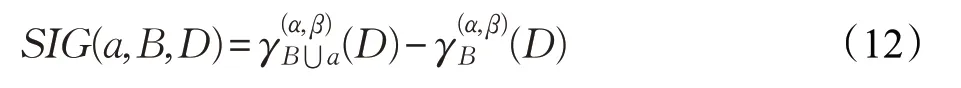
上式也等价于:
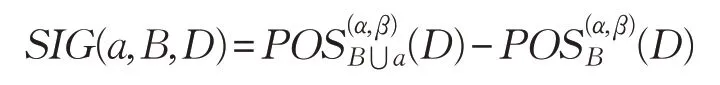
基于上述内容,本文给出了基于邻域决策粗糙集属性重要度的启发式属性约简算法Algorithm1[25]。

在 Algorithm1 中,设循环次数为m,计算的时间复杂度为O(|U|),计算两个属性重要性的时间为O(1),查找属性重要性最大的对象这个步骤中,集合中最多有个对象,故时间复杂度为O(|C|),因此该算法的时间复杂度为在该算法中没有额外的空间开销,故空间复杂度为O(|U|)。
3.2 基于邻域决策粗糙集多迭代分类算法
在该三支分类方法(Multi-iterative Neighborhood Decision Theoretic Rough Set,MNDTRS)中,采用二阶段多循环的方式对边界域的数据进行处理,既充分考虑了分类问题的代价敏感性,又使分类结果更具特征。本文将数据集分为训练集和测试集两部分:第一阶段在测试集上运用训练集上训练好的基于邻域决策粗糙集的三支分类器(NDTRS)将测试集中的数据分为正域、负域和边界域三类。在第二阶段运用Algorithm2,将测试集中标记为正域的数据加入到训练集中形成新的训练集,测试集中标记为负域和边界域的数据形成新的测试集。接着多次迭代运用基于邻域决策粗糙集的三支分类方法。在每次迭代中,将测试集中的正域数据加入到训练集中,扩展了原始训练集,重构了训练集中的数据,使得测试集中负域和边界域的对象不断减少,多次迭代直到测试集的负域和边界域不再改变(或者测试集的正域为空)[26]。具体算法内容见Algorithm2。

现在简要讨论该算法的时间复杂度,用N1代表训练集中数据的数目,N2代表测试集中数据的数目,假定在Algorithm2上运行了k次,其中k为常数。在训练集上邻域三支分类器的时间复杂度为O(N1),则该算法的时间复杂度为O(k×(N1+N2));该算法空间没有额外开销故其空间复杂度为O(N1+N2)。显然该算法的时间复杂度和空间复杂度开销较小,符合算法设计的原则。
4 实验
4.1 实验准备
本文建模所采用的痛风数据共5 616 条数据,其中女性数据3 137条,男性数据2 479条,每条数据对应28个属性,其中血脂指标TC、TG、HDL-C、LDL-C;血糖指标GLU;肾功指标Urea、Cr;肝功指标ALT、AST、AST/ALT、GGT、ALP、TBIL、DBIL、IBIL、TP、ALB、GLB、PA、ALB/GLB、TBA、LDH、LAP、eGFR、non-HDL-C、ADA;尿酸UA 和性别SEX。当血脂中的某项指标异常时表现为该功能异常,其他功能亦是如此。这些属性值中性别指标是逻辑值(离散值),其余指标都为连续值。其中各指标的正常范围如表1所示,单位为μmol/L。

表1 痛风数据各指标标准范围
在医学上,痛风是单钠尿酸盐(MSU)沉积所致的高尿酸血症关节炎,痛风发作的比率与尿酸水平有关。在临床上,女性尿酸在360 μmol/L 以下为正常值,360~480 μmol/L则需要临床干预,在540 μmol/L以上发展成为痛风的几率很高;男性尿酸在420 μmol/L以下为正常值,420~480 μmol/L 则需要临床干预,在540 μmol/L 以上发展成为痛风的几率很高。由于男性和女性尿酸值标准范围不同,在日常对痛风分析中把男性和女性进行分别处理,而在该模型中根据高尿酸与痛风发作的高相关性,将尿酸作为决策属性D,其他指标值作为条件属性C,将痛风诊断信息转化为决策信息表。一方面可以直接探讨尿酸与其他指标的相关性而避免对性别进行分类讨论;另一方面根据决策属性D可以将其转化为监督学习,巧妙地运用邻域三支决策模型对其进行分类和获取相关规则,既能够考虑痛风诊断基于代价敏感的特征,又避免数据特征不明显时聚类分析效果不佳。
在实验前进行数据预处理,将一些属性缺失值较多的样本剔除,将少量缺失值用平均值替换,将尿酸值根据性别范围转化为{0,1,2},其中0 代表正常,1 代表需临床再诊断(即为痛风低风险),2代表高概率发展为痛风(即为痛风高风险),符合三支决策的语义。其中标记为0的数据有4 072条,标记为1的数据有1 039条,标记为2的数据有235条,删除未标记数据,共5 616条数据。
根据实际意义,在该模型中,对于求诊者来说,将痛风患者诊断为正常的代价很大,会延误患者进行及时治疗,造成更严重的后果。对分类代价赋值,令λBP=5,λBN=10,λNP=10,λPN=20。其中取邻域阈值δ=0.1,距离函数采用欧式距离。在上述实验准备的基础上,运用Algorithm1对数据进行属性约简,得到属性约简集合R。接着运用Algorithm2,得到最终分类结果。
4.2 实验结果
通过运用Algorithm1,计算属性重要性,得到属性重要性排序(Cr,HDL-C,GLU,TG,TF,TC,AST,non-HDL-C,TBA,ALT,eGFR,ALP,AST/ALT,IBIL,GGT,ALB,ALB/GLB,LDL-C,LAP,PA,Urea,TBIL,TP,GLB,DBIL,ADA,LDH),如图1 所示,并得到约简集R={Cr,HDL-C,GLU,TG,TC,TF,AST,non-HDL-C,TBA,ALT,eGFR,ALP,AST/ALT,IBIL,GGT},共15 个属性。图1显示Cr的属性重要度为0.405 2,远高于其他指标,故可以推断Cr 可能是影响痛风发作的重要指标。在属性约简集中,肾功的指标有Cr,血脂的指标有HDL-C 和TG,血糖的指标有GLU,肝功的指标有TF、AST、non-HDL-C、TBA、ALT、eGFR、ALP、AST/ALT、IBIL和GGT。通过该属性约简算法,分别得到了肾功、肝功、血脂和血糖的代表性指标,符合属性约简的本质。

图1 各指标属性重要度柱形图
在Algorithm2中运用多次迭代的方法进行分类,为了说明在迭代过程中,正域、负域、边界域中样本数量的变化,图2记录了在多次迭代过程中正域、负域、边界域中样本数量占所有样本数量的百分比。通过观察图2可知,随着迭代次数的增加,边界域中的样本所占比例不断减小,正域和负域中的样本所占比例不断增大,并最终达到一个稳定值。每次迭代过程形成新的训练集和测试集,使得训练集中的数据特征更加明显,训练得到的模型更加准确,提高了分类器的分类能力。

图2 随迭代次数增加各区域数据所占比例

图3 不同分类算法的误分类代价
本文分别采用LR、RF、SVM与MNDTRS对痛风数据进行分类,得到四种分类算法的误分类代价(图3)和混淆矩阵(图4)。通过观察图表,MNDTRS算法在5 616条数据中误分类的数据只有49 条,分类准确率达到99%;SVM、RF 和LR 算法中误分类的数据数目分别为91、189、928 条,分类准确率分别为99%、98%、93%,且MNDTRS的误分类代价低于其他算法。通过痛风数据分类实验验证了MNDTRS 算法的有效性和优越性,且算法能够得到较高的准确率和较低的分类代价。SVM和RF算法在分类过程中也有较好的性能,而LR算法在分类过程中相较于本文涉及的算法,分类能力较差。
4.3 实验结果分析
本文在数据标准化的基础上,根据分类结果得到不同属性在痛风高风险、低风险、正常时的平均值,如图5所示。根据该图显示可知,AST/ALT、eGFR、HDL-C 这三个属性随着痛风疾病的严重性均值下降;IBIL、TBA属性对痛风疾病的敏感性不高;Cr、GLU、TG、TF、TC、AST、non-HDL-C、ALT、UA、ALP、GGT这些属性的值随患痛风疾病风险的严重性均值上升。图6 为各属性之间的相关矩阵图,从图中可以看出尿酸(UA)与AST/ALT、eGFR、HDL-C 相关系数为负值,尿酸(UA)与IBIL、TBA 的相关系数接近0,尿酸(UA)与Cr、GLU、TG、TF、TC、AST、ALT、ALP、GGT、non-HDL-C 相关系数为正值,这与上述结论相吻合。在图6中发现Cr属性的均值随患痛风疾病风险的严重性增幅较大,并且在相关矩阵图中尿酸(UA)与Cr的相关性比较高,达到0.54,而Cr 是肾功能的重要指标,故痛风疾病的发作与肾功指标有着极大的相关性。
通过分类结果,获取到分类规则,并做出规则树图,如图7 所示。从图中观察到肾功指标(Cr)在规则树的多个规则中出现,且规则树中Cr 指标作为判断是否患痛风的首要因素。例如规则R8 和R10 中,当Cr 指标值高时,有患痛风的风险,这也验证了上述Cr高属性重要度和Cr 与尿酸(UA)高相关性。另外肾功、肝功、血脂的指标呈相互制约相互影响的关系。例如当肾功指标(Cr)较高时,而血脂指标(TG、TC)和肝功指标(ALT、GGT 等)较低或在正常范围内,则痛风发作几率较小,反之亦然。如规则R6中,当Cr>73.5而TG ≤1.125时表现为正常;在规则R5中,当Cr ≤ 73.5,TG>1.385,eGRF>120 时表现为痛风高风险。而当肾功指标(Cr)、血脂指标(TG、TC)和肝功指标(ALT、GGT 等)都较高时,痛风发作的概率很大。例如在规则R11 中,Cr>73.5,TG>1.825,TC>6.475 时有患痛风的风险。血糖指标(GLU)没有在规则树中出现,故推断痛风发作与血糖指标相关性不高。实际中表明痛风发作常常伴随着肾功能指标异常,肾功能异常时会导致尿酸清除率降低而沉积在血液中,从而使尿酸水平升高。这也验证了该算法的有效性,通过大数据分析建立痛风诊断模型颠覆了以往根据数理统计的建模的思维,更能精准有效地进行知识挖掘和知识发现。

图4 不同分类算法的混淆矩阵

图5 各指标在不同分类下的均值

图6 相关矩阵图

图7 规则树
5 结束语
本文将基于邻域决策粗糙集代价敏感三支分类方法运用到痛风诊断模型的建立中,得到有效的分类结果,并通过分类结果提取分类规则,挖掘痛风发作潜在的影响因素,对痛风疾病的研究提供知识支持。通过与其他分类算法相比,证明了该算法具有较高的准确性和较低的分类代价。在该模型建立过程中将尿酸指标作为决策属性,而在临床过程中,确诊是否患有痛风,还看关节是否发生变形以及关节损坏程度。在之后的研究过程中,可以对关节损坏程度加以考虑,根据专家经验对致病程度给予权重,进行痛风诊断模型的建立。
猜你喜欢
农业工程学报(2022年7期)2022-07-09
科教导刊·电子版(2021年6期)2021-05-06
吉林大学学报(理学版)(2020年3期)2020-05-29
成都信息工程大学学报(2019年2期)2019-08-28
自动化学报(2018年7期)2018-08-20
系统管理学报(2018年3期)2018-08-13
海峡姐妹(2017年12期)2018-01-31
作文与考试·初中版(2017年12期)2017-04-19
厦门大学学报(自然科学版)(2016年6期)2016-12-07
周口师范学院学报(2016年5期)2016-10-17
