
基于联合一致循环生成对抗网络的人像着色
2020-08-19 10:42刘昌通杜康宁
计算机工程与应用 2020年16期
刘昌通 ,曹 林 ,杜康宁
1.北京信息科技大学 光电测试技术及仪器教育部重点实验室,北京 100101
2.北京信息科技大学 信息与通信工程学院,北京 100101
1 引言
色彩是图像的重要属性,人眼对彩色图像的敏感程度高于灰度图像。因此,通过灰度图像着色,可以使观察者从着色图像中获得更多的信息,提高图像的使用价值。灰度图像着色在视频处理、影视制作、历史照片还原等方面起着至关重要的作用,具有重要的研究价值。其中,人像着色是图像着色的主要应用领域,本文针对人像着色展开了一系列的研究。
传统的图像着色方法主要有基于局部颜色扩展的方法[1-2]和基于颜色传递的方法[3-4]。基于局部颜色扩展的方法需要指定灰度图像某一区域的彩色像素,将颜色扩散至整幅待着色图像。这一类方法需要大量人为的工作,如颜色标注等,且图像着色的质量过度依赖于人工着色技巧。基于颜色传递的方法消除了人为因素在图像着色中的影响,通过一幅或者多幅颜色、场景相近的参考图像,使颜色转移至待着色图像。传统方法可以应用在人像着色中,但这类方法需要设定参考图像,且着色的计算复杂度高。
为了减小着色过程中人工因素的影响,传统的着色方法已逐渐被基于深度学习的方法所取代。其中,Iizuka等人[5]使用双通道网络,联合图像中的局部特征信息和全局先验信息,可以将任意尺寸的灰度图像自动着色。Larsson 等人[6]利用 VGG 神经网络[7],提取图像的特征,来预测每个像素的颜色分布。Zhang 等人[8-9]先后提出针对像素点进行分类和基于用户引导的灰度图像着色方法。这一类方法利用神经网络提取特征,但在训练过程中容易丢失局部信息,使特征表达不完整,限制了着色的效果。
近年来,生成对抗网络(Generative Adversarial Network,GAN)[10]在图像生成领域取得了巨大的成功,相比较传统的神经网络[11],GAN 生成的图像质量更高。但GAN的训练不稳定,容易出现模式崩溃。Zhu等[12]研究人员在文献[13]的基础上提出了循环生成对抗网络(Cycle Generative Adversarial Network,Cycle-GAN),通过循环生成对抗的方式,提高训练网络的稳定性。
综上所述,针对复杂背景下人像误着色的问题,本文提出了联合一致循环生成对抗网络(Jonit Consistent Cyclic Generative Adversarial Network,JCCGAN)。该网络在循环生成对抗网络基础上,联合了一致性损失实现网络整体的反向传递优化,其生成网络改用U型网络(UNet)[14],并加入最小二乘损失,作为着色的优化目标,提高图像的生成细节。在判别网络中,采用多层特征融合的方式提取图像特征,使提取的特征表示更多图像信息。最后在自建的CASIA-PlusColors 数据集上进行实验,结果验证了本文方法的有效性。
2 本文方法
2.1 色彩空间
在色彩空间中,基于颜色合色的RGB空间,不适应人眼调色,只能比较亮度和色温的视觉特性,不能直接反映图像中光照信息的强弱。因此,大多着色方法中采用Lab色彩空间。
其中,着色的过程是通过网络模型,输入给定宽高W×H的亮度L通道图像XL,映射至色度通道a和b,预测值分别为,将网络模型的输出和L通道灰度重新合成一个新的三通道图像,即得到的着色图像为因而,训练着色模型最终的目标是获得的一种最优映射关系。因此,本文将图像从RGB 色彩空间转换至基于人眼对颜色感觉的Lab色彩空间。
2.2 网络结构
传统的GAN 是单向生成,采用单一的损失函数作为全局优化目标,可能会将多个样本映射为同一个分布,从而导致模式崩溃。CycleGAN 采用循环生成对抗的方式,有效地避免了传统GAN 的这一不足。本文提出了联合一致循环生成对抗网络的人像着色方法。该方法在CycleGAN的基础上,将两个循环生成网络重构的数据组合,计算其与真实彩色图像的距离,实现一致性损失对整个网络的反向传递,加强了原有网络的稳定性。同时,为了提高生成图像信息的完整性,本文采用了UNet 网络来改进原有的生成网络,并将多特征融合的方法引入到判别网络中,使提取的特征更多表示图像的细节。
2.2.1 着色网络模型
本文的着色网络模型包含四个子网络,分别是:生成网络G,负责将L通道灰度图像映射至ab通道彩色分量XL→;生成网络F,负责将ab通道彩色分量映射至L通道灰度图像Xab→;判别网络DX,用于判别区分L通道灰度图像XL和生成网络F生成的灰度图像;判别网络DY,用于区分真实的彩色图像和生成的分量与L通道组合的彩色图像 。该网络的目标是通过训练L通道分量{XL}i=1∈XL和ab通道彩色分量{Xab}i=1∈Xab,获得最优对应关系G:XL→,即将L通道灰度图像映射至ab通道彩色分量的最优关系。网络结构如图1所示。
以上的子网络构成了一对循环生成网络,其分别将输入的样本映射到中间域,然后将中间域的数据重构回原有的域中。例如,输入L通道灰度图像XL,最终会被映射回灰度图像F[G(xL)],中间域数据是生成的ab通道彩色分量。同样,输入为ab通道彩色分量Xab时,最终也会被重构回原有的域中G(F(Xab)),其中间域是F网络生成的灰度图像。
在原始CycleGAN中,两个循环生成网络是相互独立的,反向传递优化网络时,循环生成网络的一致性损失是分开计算的。如图1所示,本文的着色模型将两个循环生成网络重构的数据结合,即将重构的ab通道彩色分量G(F(Xab))与灰度分量F[G(xL)]重新组合,得到重构的彩色图像。然后计算其与输入彩色图像的L1距离作为网络的联合一致性损失,共同实现整个网络的反向传递优化。

图1 联合一致循环生成对抗网络结构图
2.2.2 生成网络
传统GAN 中,生成网络仅由简单的卷积层和反卷积层构成,提取特征时容易丢失图像的局部信息,限制网络的着色效果。如图2 所示,为了避免上述问题,本文的生成网络采用U 型网络(UNet),通过跳跃连接,将下采样中每一层输出的特征连接至对应的上采样层。其目的是将浅层信息直接传递到相同高度的反卷积层,形成更厚的特征,提升图像的生成细节。

图2 生成网络结构图
生成网络整体由上采样和下采样两部分组成。其中下采样部分共有5 层,滤波器的数量分别为[32,64,128,256,512]。如图2所示,下采样过程中,图像特征每层经过两次卷积,滤波器大小为3×3,其目的是提取图像纹理结构等基本信息。卷积后连接批标准化(Batch Normalization,BN)层[15],目的是调整卷积后的数据分布,使卷积的输出分布在激活函数近原点邻域内,降低梯度弥散率,避免梯度消失的问题。激活层本文采用带泄露的线性整流函数(Leaky Rectified Linear Unit,LReLU),代替原本的线性激活函数(Rectified Linear Unit,ReLU)[16],其目的是减少计算的复杂度,且不会导致负值区域的神经元全为0。在上采样过程中,采用了与下采样相对称的5层反卷积,将深层特征恢复至一定尺寸的大小。生成网络的目的是将输入映射至目标域空间的分布,例如根据嘴唇形状特征对应至着红色的过程。
2.2.3 判别网络
传统判别网络采用单层特征表达整个图像,容易丢失图像的细节信息。因此本文在判别网络中引入多特征融合的方式,如图3所示。采用融合后的特征可以增强对图像的细节信息,提高图像分类的准确率。同时,为了避免维度灾难,本文在特征融合层后添加编码网络对特征进行降维。
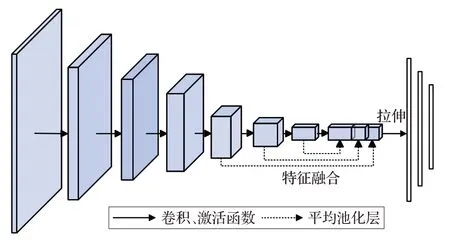
图3 判别网络模型
生成的分量同L通道组合后构成一幅着色图像,判别网络DY对其与真实的彩色图像之间进行判别区分。由于二者之间存在相关性,判别器可以通过卷积神经网络进行学习,获取更加有效的图像特征,对两类图像进行正确分类。对于判别网络DY,首先输入三通道256×256 大小的彩色图像,然后经过带有步伐(Stride)的6次卷积后,输出256个4×4的特征图。特征提取的卷积核尺寸为5×5,卷积步长2,每一个卷积层的特征图个数分别是8、16、32、64、128、256。卷积后融合特征,分别对第四层和第五层进行4×4、2×2的平均值池化,生成448 个4×4 大小的特征图。然后将融合后的特征图拉伸至11 264维长度的向量,使用多层全连接将特征的维度降低至1 024维。为了进一步防止特征降维过程中,出现过拟合的现象,在全连接层后面加上Dropout层,概率值设置为0.7。最后,将压缩过的特征向量输入至Sigmoid 函数,判别生成图像是否符合真实图像的分布。对于判别网络DX,输入图像为单通道的灰度图像,模型结构与判别网络DY相同。
2.3 损失函数
传统GAN 只采用生成对抗损失函数,存在多余的映射空间。本文方法结合生成对抗损失和联合一致性损失共同监督训练网络,有效避免了这一问题。同时,为了减小生成图像与决策边界的距离,本文采用最小二乘损失LLSGAN改进原有的生成对抗损失函数,提高图像生成的质量。
2.3.1 生成对抗损失
生成对抗性损失应用在输入图像映射为中间域图像的过程。原始的交叉熵损失如式(1)所示,使得生成器无法进一步优化被判别器识别为真的生成图像,可能导致网络生成图像的质量不高。受Mao等人[17]的启发,本文采用最小二乘损失作为生成对抗损失。相比较原始损失函数,最小二乘损失会对远离决策边界并且判决为真的生成样本进行处理,将远离决策边界的生成样本重新放置在决策边界附近。即通过使距决策边界不同的距离度量构建出一个收敛快、稳定,并且生成图像质量高的对抗网络。

其中,x~Pdata(x)、y~Pdata(y)分别为样本X、Y服从的概率分布。Ex~Pdata(x)和Ey~Pdata(y)是各自样本分布的期望值。
因此,对于生成网络G:X→Y及其判别网络DY,生成网络G将X域数据生成符合Y域分布的目标,判别网络DY用于区分真实的Y域数据{y}和生成样本{G(x)}。本文最小二乘生成对抗损失的函数定义如式(2)所示。

最小二乘生成对抗损失的目标如式(3)所示。训练判别器时,损失函数目标是使判别器区分真实的样本和生成的样本,即最大化DY(y),同时使DY(G(x))最小;训练生成器时,损失函数的目标是使生成数据接近真实数据,即使DY(G(x))最大化。

对于生成网络F:Y→X及相应的判别网络,同样引入相同的生成对抗损失,损失函数目标如式(4)所示。

2.3.2 联合一致性损失
传统GAN 只使用了对抗性损失训练网络,学习输入图像和目标图像的映射关系,但无法解决生成网络中存在的多余映射问题。而循环生成网络采用了循环一致性损失,来更好确保生成数据的稳定性,减少其他多余映射关系。本文在此思想的基础上,提出了联合一致性损失,将重构的数据重新组合,再计算其与输入彩色图像的L1损失。
式(5)和式(6)分别是网络中两个循环生成过程:

其中,xL和为真实的L通道分量和其重构的数据;xab和为真实的ab通道彩色分量和其重构的数据。

其中,x为输入的样本,F(G(xab))+G(F(xL))表示重构的彩色图像。
完整的目标函数包括生成对抗损失和联合一致性损失,如式(6)所示:

其中,λ参数用于调整最小二乘损失和联合一致性损失的权重。网络总训练目标为:

3 实验数据
目前公开的人像数据集有很多,如PubFig、CelebA等,主要应用在人脸识别等领域,人物图像大多集中在人的面部区域,并且图像质量不一致,直接用于着色模型的训练,效果不好。为了解决数据库的问题,本文在CASIA-FaceV5数据库的基础上,通过爬虫技术,对数据集进行扩充,最终数据库总共包含了9 500张多种姿态、各种背景下的人物彩色图像,简称为CASIA-PC(CASIAPlusColor)。
CASIA-FaceV5 是中国科学院公布的数据库,该数据库是开放的亚洲人物数据集,其中包含了来自500人2 500 张高质量的彩色图像。通过观察发现,该数据库的人物图像大部分为单色背景下的正面照,缺少实际环境下的人像场景。
为了解决CASIA-FaceV5 数据库缺乏真实场景人像的问题,本文在该数据库的基础上,使用爬虫技术,完成了在互联网中自动化、模块化爬取图片的任务,收集图片,最后得到了7 000 张复杂背景下的不同姿态的彩色人像。
本文实验采用了CASIA-PC数据集,所有图片的大小调整为225×225像素,并将数据库划分为训练集和测试集,训练集由随机选取的8 600张图片组成;剩下的图片作为测试集。数据集实例如图4所示,其中图4(a)选自CASIA 数据库,图4(b)选自互联网中爬取的人像。由图4可知,本文自建的数据集场景丰富,色彩鲜艳,增加了着色的难度。

图4 数据集实例
为了客观地评价生成图像的质量,本文采用图像质量评价标准结构相似性(Structural Similarity Index,SSIM)[18]和峰值信噪比(Peak Signal to Noise Ratio,PSNR)对着色图像整体进行质量评估。PSNR用于评价生成图像着色的真实程度,其值越大,表示失真越少;SSIM用于衡量目标间结构的相似程度,SSIM测量值越大,表示两张图像相似度越高。
4 实验与分析
4.1 实验步骤
(1)预处理。实验的预处理阶段,将每张图像的颜色模型从RGB 转为Lab 模型,并将彩色人像的L通道和ab通道彩色分量分离,将分离后的L通道和ab通道彩色分量作为网络的输入。
(2)参数设置。数据训练过程中,生成网络G和F,判别网络DX和DY均采用初始学习率为0.000 2,动量为0.5 的Adam 优化器更新网络的参数,同时采用线性衰减的方法逐渐降低学习率。经过不断的迭代训练使模型收敛,存储整个网络的参数。
(3)实验过程。实验流程如图5 所示,可以分为两个阶段:第一阶段使用8 600 个训练样本对整个网络进行训练,得到着色模型。为了避免网络有过拟合的现象,本文在使用规模较大的数据集训练网络时,会出现数据质量不同,部分图像存在颜色暗淡和图像模糊等问题,会影响模型着色的效果。因此,第二阶段本实验在规模较大的原数据集中筛选出了质量相对较高的2 160个训练样本,微调网络的参数。

图5 模型训练示意图
本文将图像的标准差和平均梯度值作为数据筛选的评价指标,具体如下:
标准差(Standard Deviation,SD)是指图像灰度值相对于均值的离散程度,标准差越大说明图像中灰度级分布越分散,图像的颜色也更加鲜明。设待评估图像为F,大小为M×N,则标准差的计算公式如下所示:

平均梯度(Mean Gradient,MG)反映了图像细节和纹理的变化,在一定程度上可以表示图像的清晰度,其值越大说明图像整体的清晰度越高。图像平均梯度的计算公式如下所示:

其中,ΔxF(i,j)、ΔyF(i,j)分别表示像素点(i,j)在x、y方向上的一阶差分。
本文将标准差和平均梯度的阈值设置为54 和25时,筛选出的图像质量较高。如图6 所示,前两列是筛选出的人像图片,图像颜色明亮,且清晰程度较高。后两列是未选出的人像图片,其中第三列人像的标准差低于阈值54,图像亮度低,色彩偏暗,第四列人像的平均梯度值低于阈值25,图像较为模糊。

图6 人像筛选实例
实验第一阶段是模型预训练的过程,为了使生成网络G学习灰度图像映射至ab通道彩色分量的对应关系;第二阶段则是模型微调的过程,为了提高模型着色的效果。
4.2 实验结果与分析
4.2.1 着色效果提高
为了测试数据筛选对不同模型着色效果的影响,本文对三种不同的着色方法进行实验,结果如图7 所示。其中,第一列是灰度图像;第二列是直接采用CASIA-PC训练模型的结果;第三列是在第二列基础上加入筛选人像微调模型的结果。对比后发现,采用筛选人像微调的方法均比直接训练的着色效果好,主要表现在部分背景的色彩变得更加明亮。

图7 人像筛选着色对比
本文在循环生成对抗网络的基础上,提出了基于联合一致循环生成对抗网络的人像着色方法。该方法改进了基础网络的模型结构、损失函数,并在训练中采用了模型微调的方法。为了验证上述方法对提高模型着色能力的影响,本文比较了不同改进方法的着色效果,如图8 所示。其中,第一列是待着色灰度图;第二列是基础网络模型的着色结果;第三列是训练中采用模型微调后的着色结果;第四列是采用最小二乘损失训练网络的着色结果;第五列是模型采用联合一致循环网络的着色结果。
通过对比不同改进方法的着色结果,发现仅改进训练方法对改善人像误着色问题的效果不明显,但部分区域颜色效果有所提升。如图8(c)第二行中树叶的颜色相比图8(b)更明亮。而损失函数和着色模型的改进都可以改善人像误着色的问题。其中,采用最小二乘损失训练模型的着色准确率虽有提高,但部分区域仍有较明显的误着色,如图8(d)中第一行所示,草色被误着为红色。而相比较下,改进网络模型后的着色效果提升更为明显,如图8(e)中第一行所示,仅有少部分不明显的误着色。
4.2.2 着色人像对比实验
不同方法的着色结果如图9所示,第一列为L通道的灰度人像;第二列为真实的彩色人像;第三列为原始CycleGAN 的着色结果;第四列在第三列方法的基础上仅将生成网络结构改为UNet 网络;最后一列是本文方法的着色结果。前两行为相应模型在单色背景下的着色结果,其余为复杂背景下的着色结果。
根据图9中不同模型着色的结果可以看出,使用原始CycleGAN 模型进行着色时,效果较为粗糙,颜色饱和度和着色准确率偏低,会出现误着色和颜色溢出等问题。例如,图9(c)的第三行中误将原图中绿色的树叶生成为其他颜色,而图9(c)的第五行中原本属于人脸区域的颜色超出了自身的范围,扩散至树木、天空等四周。生成网络采用UNet网络的方法,该模型着色结果如图9(d)的第二行所示,对于背景单一的图像着色准确率有很大的提升。在复杂背景人像下的着色效果虽有一定提高,但依旧存在着误着色的问题,其中图9(d)第三行中较为明显。相比之下,本文着色模型采用联合一致循环网络,着色结果更加准确、自然,即使在复杂背景的人像中,也能够较为准确地赋予人像和背景真实的颜色,人像误着色的问题有明显的改善。并且本文方法可以正确区分出图像中的不同目标,减少颜色溢出的现象,如图9(e)所示。另外,第一行的着色结果值得注意,着色后服饰的颜色发生了改变,这是由于数据库中缺乏相同服饰的样本,或是相近的服饰多以灰黑色为主。这说明了训练集对着色结果具有很大的影响。图9(d)中第一行的着色结果相比采用本文方法的着色结果,其拉链部位的颜色更接近于原始的彩色图像。这是由于该方法注重学习待着色目标的结构,着色时选择模型学习到的特征中和它结构相近的颜色。而本文模型采用了联合一致循环网络,在学习图像结构的同时,更注重人像着色的整体一致性。因此,拉链部位着色时会对应服装的色彩,选择与之相适应的颜色。

图8 改进方法着色对比
本实验在单色和复杂背景下,分别比较了三种模型的PSNR 和SSIM 平均指标,如表1、表2 所示。在客观指标评定下,随着三种模型网络结构的丰富,着色效果在单色背景和复杂背景下依次有着提升。另外,由于单色背景图像的结构和纹理相对比较简单,着色相对更为容易,其表现在同一种模型中单色背景下图像的平均指标,明显高于在复杂背景下图像的指标。

表1 复杂背景下不同方法平均SSIM、PSNR对比

表2 单色背景下不同方法平均SSIM、PSNR对比
另外,本文又与其他着色模型进行了比较,结果如图10 所示。其中Iizuka 等[5]采用双通道卷积网络,着色结果颜色较为鲜艳,但着色准确率低。Larsson等[6]采用VGG网络提取图像特征,误着色问题有所改善,但人像部分区域变得模糊。Zhang等[8]针对图像中每个像素点进行分类,着色准确率较高且人像清晰,但颜色饱和度低。而本文方法的着色准确率高,不同目标的区分度较高,颜色也更加自然。但部分区域存在颜色分布不均匀的问题,仍未能达到理想的饱和度,如图10第一行的着色结果。本文进一步比较了与其他着色模型不同场景中SSIM和PSNR指标均值,分别如表3和表4所示。在不同场景下,本文方法着色的图像与原图相比具有更高的SSIM、PSNR值,说明本实验的结果与原图相比较,结构更加相似,而且失真较小。

图9 不同方法着色对比

图10 不同模型着色对比

表3 单色背景下不同模型平均SSIM、PSNR对比

表4 复杂背景下不同模型平均SSIM、PSNR对比
5 结束语
针对复杂背景的灰度人像误着色问题,本文提出了联合一致循环生成对抗网络的人像着色方法。该方法采用联合的一致性损失,联合重构的数据计算其与输入彩色图像的L1损失,实现整个网络的反向传递优化。实验证明了本文方法适用于单色和复杂背景的人像着色,着色精度有很大提高,并且对比同类的方法,本文方法在图像颜色连续性和合理性等方面都有着出色的表现。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
今日农业(2021年9期)2021-11-26
数学小灵通·3-4年级(2021年5期)2021-07-16
天津医科大学学报(2021年1期)2021-01-26
今日农业(2020年16期)2020-12-14
数学杂志(2019年1期)2019-02-18
今日农业(2019年15期)2019-01-03
电影(2018年10期)2018-10-26
自动化学报(2017年5期)2017-05-14
共产党员(辽宁)(2015年2期)2015-12-06
