
基于图模型的多文档摘要生成算法
2020-08-19 10:42张云纯徐济铭袁卫平
计算机工程与应用 2020年16期
张云纯,张 琨,徐济铭,袁卫平,蔡 颖,高 雅
1.南京理工大学 计算机科学与工程学院,南京 210094
2.国家计算机网络与信息安全管理中心江苏分中心 互联网信息处,南京 210019
1 引言
人工文本摘要的形成过程十分复杂,且十分费时费力。它需要由具有一定专业知识并经过相关培训的特定人员,在研习了相关资料文献后,概括成可读性强、质量高的摘要。在这个信息超负荷的时代,对于文本摘要的处理,需要满足时效性强、范围广、速度快等特征,这显然是传统的人工提取文本摘要所不能满足的。
自动文本摘要生成技术是利用计算机技术从文章中提取内容生成摘要,并以语意连贯的段落乃至篇章的形式展现,该技术能够帮助人们快速获取情报信息,辅助国家舆情监测部门采取应急响应措施。它采用机器学习与自然语言处理技术进行内容抽取、分类,并精简概括全文。出于对信息过载问题的考虑,该技术在国内外正日益受到密切关注。本文以国外新闻网站的大量新闻文档为研究对象,利用自然语言处理、机器学习等技术,对新闻文档进行多文档摘要的生成。
2 相关研究
自动文本摘要生成技术是自然语言处理领域中较难的技术,亦是当下的研究热点。国内外学者在自动文本摘要领域做了大量的研究。统计学模型在自然语言处理领域应用广泛,统计技术也是自动文本摘要最早应用的技术。统计技术相较于其他技术而言,数学模型简单,实现方便,出现时间也最早。文献[1]最早提出了自动文本摘要的概念,运用词频来衡量句子在一篇文档中的重要性,即出现越多的单词越能够代表文章的主题思想。仅考虑词频不够全面,在实际提取摘要时,统计特征往往会与句子本身的特征结合使用,来提高权重的精确度[2-3]。例如在新闻报道中,针对首段内容往往凝炼了事件的主体信息,段落中的首句和末句能够概括段落内容等特性,设计特定的权重公式来提取摘要句更为恰当。Edmundson[4]设计了一个经典的抽取式摘要系统。他不仅利用词频和段落位置等基本特性,还将提示词、文档框架特征纳入考虑范围,对语句的重要程度进行评判。
图模型算法在自动文本摘要生成领域亦有着广泛应用,最早的工作可见文献[5]。文献[6]提出了一种基于亲和图的自动文本摘要生成技术,该方法考虑句子间的相似性,结合主题信息抽取出高信息性和高独特性的句子,经过冗余削减后生成摘要。文献[7]利用N-Gram图抽取文档中的重要成分。文献[8]使用WordNet 识别文档中的概念来构建文本图。基于图排序算法的自动文本摘要生成技术是图模型在该领域应用的一类特例,其因为良好的效果以及可扩展性成为本领域的研究热点。在图的构建方面,除了应用最广泛的余弦相似度度量外,基于关联规则挖掘[9]、信息论[10]等衡量文本单元相关性的方法也有所应用,以及基于超图[11]、聚类[12]、WordNet以及维基百科的方法[13-15]也有所应用;在图排序方面,现有的系统大多是对PageRank或HITS(Hyperlink-Induced Topic Search)算法基于所构建的文本图进行相应的改进,例如TextRank和GraphSum算法将PageRank算法的权重传播做了加权改进,Biased-LexRank[16]将马尔科夫链转移到自身的概率进行了加权,文献[15]从加权HITS算法中获得启发;也有方法进一步扩展了现有的图排序方法,例如文献[14]用全局排序的结果对聚类簇做动态更新,然后利用更新过后的聚类簇对句子进行重新排序。
多文档自动文本摘要生成技术以不同主题的文本集合为研究对象,其目的是生成同一主题下多个文档的摘要信息,通常在图模型的基础上展开研究。目前,研究人员在这一领域也展开了一系列的研究,并取得了阶段性成果。文献[17]提出了一种识别关键主题的方法,以在多个文档中提取摘要。文献[18]通过结合LDA(Latent Dirichlet Allocation)主题模型,提出了一种新的挖掘主题的方法。文献[19]主要针对多文档句子重要度排序的问题,设计了一种通用的解决方案。
新闻文档存在时效性强、主题明确的特征,传统的基于统计学模型和图模型的自动文本摘要生成方法很难充分考虑这两个特征,因而生成的摘要存在冗余度高、新颖性不强等缺点。基于此,本文对上述图模型算法进行改进,实现对英文文本的多文档摘要生成。算法采用两步文本聚类的方法,在提升效率的同时,更好地发现文档主题。此外,在摘要的抽取阶段,采用了基于特征融合的算法,充分考虑了位置因素和时间因素对文档、句子的影响,提高了文本摘要的新颖性、时效性和准确性。
3 基于图模型的自动文本摘要生成算法
为提高摘要句抽取的准确度,本文首先对传统的词频-逆向文件频率(Term Frequency-Inverse Document Frequency,TF-IDF)算法进行改进,以对文本中的单词进行向量表示。在此基础上,建立图模型,对多文档进行基于文档、句子两阶段的文本聚类算法。最后,基于多特征融合的方式,选取句子重要度高的句子作为摘要句,并按照一定的顺序生成最终的摘要。算法流程图详见图1。
3.1 基于改进的TF-IDF的文本特征向量化算法
文本特征向量化是文本预处理中最关键的一步,文本特征向量化的效果将直接影响生成的摘要的质量。常见的文本特征向量化有三种,即one-hot、TF-IDF、word2vec。one-hot编码是将标记转换为向量的最常用、最基本的方法。one-hot 编码在文本中的应用是,将每个词与一个唯一的整数索引关联,然后将这个整数索引i转换成长度为N(N是词典大小)的二进制向量,这个向量的特点是只有第i个元素是1,其余元素为0,但它得到的特征往往是离散稀疏的。word2vec不稳定,且无法区分文本中词汇的重要程度[20]。TF-IDF主要思想是:一个词的重要度不仅取决于其出现的频率,还取决于该词所具有的代表性。TF-IDF 也存在缺点,因为其提取关键字的能力严重依赖语料库,所以对语料库范围和质量要求较高。逆文本频率(Inverse Document Frequency,IDF)算法本身是一种抑制噪声的加权,对文本中频次较小的词存在着倾向性,这也影响了TF-IDF 算法的精度。该算法考虑对传统的TF-IDF 算法进行改进,实现文本特征向量化。具体地,该算法将引入一个热度系数Hot,充分考虑到随着时间的变化,新闻的热点话题会随之转移的问题,通过该算法得到的词权,更能突出实时热点。文本向量空间模型的表示如式(1)所示:

图1 算法流程图

式(1)中,tk(k=1,2,…,n)为特征词,wik为特征词tk在文本di中的权重,其具体定义如式(2)所示:

式(2)中,词频tfk为特征词tk在文档di中出现的频率次数,为逆文本词频,N为文本集中的文本总数,nk为包含特征词tk的文本数量,Hoti(x)表示文档di的热度系数,x表示文档di的报道时间距离当前时间相隔的天数。
新闻热度值的大小取决于两方面的因素:媒体因素和用户因素。对于某一新闻,在单位时间内与之相关的报道数量越多,则表明该新闻受到的媒体关注越多;同样地,若参与该新闻评论的人数越多,则表明该新闻受到的用户关注越多。因此,根据媒体关注度和用户关注度,设计式(3),计算新闻的热度。

其中,sR表示第x天的所有报道数量,sr表示第x天与新闻di相关的报道数量,pr为参与讨论新闻di的人数,υ和ν表示权重调节因子,υ=0.9,ν=0.1 。本文针对某一新闻,进行了热度计算,其热度系数Hoti(x)随天数变化的示意图如图2所示。

图2 热度系数变化图
由图可知,新闻的热度将逐渐消退,其变化趋势与指数函数的递减趋势类似,前期波动比较大,下降快,后期变化趋于平缓,并大约在30天内降为0。这个权重被称为基于热度的词频-逆向文件频率(Heat factor based Term Frequency-Inverse Document Frequency,TF-IDFH)权重。本算法将选取TF-IDFH 值最大的前γ个词作为特征词。文档集合总体的向量空间模型如表1所示。
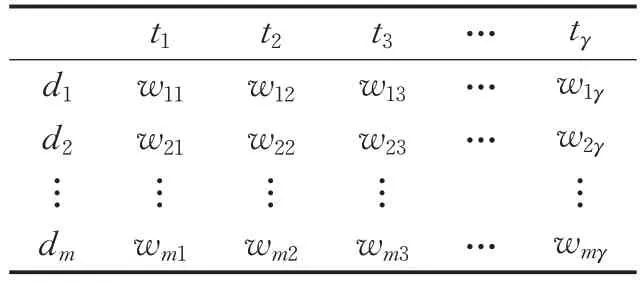
表1 向量空间模型
3.2 基于文档、句子两阶段的文本聚类算法
通过文本聚类,能够使同一簇内的节点与节点之间的连接紧密,而簇与簇之间的连接比较稀疏,从而找到相似度较高的集合,降低最后提取的文本摘要的冗余性。文本聚类应充分体现高内聚、低耦合的特性。通过文本聚类算法,可以将同一主题的句子归为一个簇。然而,由于多文档中句子数量庞大,若直接构建句子级的图模型,势必会导致运行效率下降。因此,本文采用文档、句子两阶段的文本聚类算法:首先,构建文档级的图模型,并进行文本聚类;其次,对得到的簇中文档的句子,仿照文档级图模型的构建方法,构建出句子级的图模型,再次进行文本聚类。如图3所示,C1、C2、C3为文档级文本聚类算法得到的簇,对C3中文档的句子构建句子级图模型,并进行文本聚类,得到S1和S2两个簇。
3.2.1 文档级图模型的构建方法
对于已有的文本集D={d1,d2,…,dm} ,根据文档的相似度阈值T1构造文档级的图模型。在文本向量空间模型的基础上,利用余弦相似度来表示两文档之间的相似度,文档之间的相似度如式(4)所示:
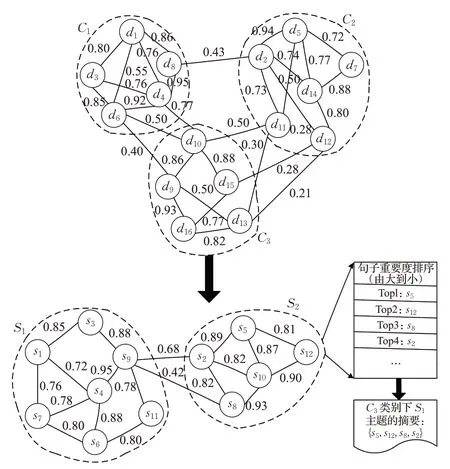
图3 两阶段文本聚类示意图

式(4)中,wik为特征词tk在文本di中的权重,wjk为特征词tk在文本dj中的权重,为两个向量的长度。如果两节点之间的相似度大于文档的相似度阈值T1,则认为这两个文档相似度较高,并将这两个节点连接。两点之间边的权重即用相似度Sim(di,dj)来表示,依此构建一个文档级的无向加权图。
3.2.2 句子级图模型的构建方法
在构建了文档级图模型后,将通过文档级文本聚类算法,得到相似度比较高的文档簇,即子主题的发现过程。为了对某一主题进行更为细节性的划分,考虑仿照3.2.1小节文档级图模型的构建方法,构建句子级的图模型。与文档级不同的是,句子通常比较简短,因此考虑多个因素来计算句子间的相似度,能够在不降低算法执行效率的基础上,提升最终抽取的摘要句的准确度。本文考虑将句子长度以及Jaccard相似度结合的方式来确定句子之间相似度,进而构建句子级图模型。
(1)句长相似度的计算
句子的长度往往能够反映句子之间的相似度,句长的差值与句子相似度成反比,长度相差越小,句子相似的可能性越高。假设len(si)表示句子si的长度,len(sj)表示句子sj的长度,则si和sj的句长相似度如式(5)所示:

(2)Jaccard相似度的计算
句子的相似度往往和句子中相同的词汇个数成正比,Jaccard 相似度就是衡量重叠性的一个标准。假设表示句子si和sj中重叠的词汇个数,则si和sj的Jaccard相似度如式(6)所示:

得到的句子相似度如式(7)所示:

式(6)中,cr为权重系数,,若两节点之间的相似度大于句子的相似度阈值T2,则认为这两个句子较为相似,并将这两个节点连接。两点之间边的权重即用相似度sim(si,sj)来表示,依此构建一个句子级的无向加权图。
3.2.3 文本聚类算法
在聚类方法中,基于距离的K-Means 聚类方法时间开销很大,对于簇的个数需要经过多次实验并根据轮廓系数来确定,受人工影响较大,且K-Means对于异常点也比较敏感。此外,在数据集方面,K-Means方法多适用于凸数据集,而文本数据一般不具有凸数据集的特性。因此,将该方法运用于文本聚类时效果不佳。相比之下,密度聚类不需要规定簇的个数,对异常点亦不敏感,适用于解决文本这类稠密数据集的聚类问题。本文采取基于密度的文本聚类算法,通过该方法可以更好体现数据分布,得到非圆形的聚类结果。通过该方法得到的簇的中心密度很大,围绕着这个中心的点较多,簇与簇之间的距离较大。基本步骤如下:
步骤1 根据相似度值的倒数,确定文档或句子之间的距离,构建文档级距离矩阵M和句子级距离矩阵N。其中,文档之间的距离用1/Sim(di,dj)表示;句子之间的距离用1/sim(si,sj)表示。矩阵中第i行、第j列表示di与dj(或si与sj)之间的距离disij。
步骤2 根据距离矩阵,计算每个点的密度。点i的密度,参数disc为边界阈值,disc的值越小,则会在尽可能小的范围内得到簇。
步骤3 根据距离矩阵,计算点i到比其密度更高的其他所有点的最小距离。
步骤4 选取ρ和δ都较大的点作为簇的中心点。此处,算法通过乘积因子ψ,综合衡量两个因素对簇中心的影响。对点i的乘积因子ψi的定义如式(8)所示。

其中,normρi和normδi都是归一化后的值。此处归一化的方法采用离差归一化,将值映射在[0,1]的区间范围内。具体地,以normρi为例:

normδi的计算方法与此类似,不再赘述。ψ越大,表示簇的中心密度越大,且不同簇的中心相互之间的距离越远。将ψ值从大到小进行排序,选取ψ值较大的点作为簇中心点。由于从非簇中心点过渡到簇中心点,ψ值会大幅度地提升,此处将根据幂次法则,确定簇的个数。
步骤5 对于其余非簇中心的数据点,将其分配给离它最近且密度比它高的邻点所在的簇。
3.3 基于特征融合的文本摘要单元提取
基于特征融合的文本摘要单元提取方法基本思想如下:选取句子的若干特征,对其进行加权求和,得到句子重要度。其关键点在于句子特征的选择上,本文所采用的算法中,抽取的特征信息主要包括段落及句子的位置信息、句子与标题之间的相似度等。特别地,考虑到报道型文档时效性强的特征,新闻报道的时间也将作为一个重要因素,融入到权重的计算中,并赋予较大的权重。最终句子的得分,将是多种权重的线性加权和。
(1)基于位置信息的句子权重计算
句子的重要度受到句子在段落中的位置因素的影响。例如,主旨性的语句放在第一段,且段落首句往往是中心句。根据人工摘要总结出的规律可知,段首句作为摘要句的概率高达85%。此外,新闻领域的文档多具有段落首尾句重要度更高的特征。因此,结合新闻领域及余弦函数的特征,设计了基于位置的句子权重的计算方法。其核心思想是突出段落首尾句的重要度。
定义countPi为第i篇文档的段落总数,则第i篇文档中第m个段落的重要度PEim如式(9)所示:

式中,α和β均为常量,在本文中,α=1,β=2 ,这两个参数的意义在于能够确保PEim的归一化。
(2)基于标题相似度的句子权重计算
新闻报道中的标题句往往能够反映文章的主旨,与标题的相似程度也能够反映句子的重要度。本算法采用余弦相似度,计算句子与标题的相似度。基于标题相似度的句子权重e2如式(10):

其中,sn为句子向量,ti表示第i篇文章的标题向量。
(3)基于报道时间的句子权重计算
新闻报道最大的特征是时效性强。例如,最新发布的文章,其重要度一定远远大于10 年前发布的文章。此外,新闻文档还满足越接近当下发表的文章,其重要度波动越大的规律。10年前的文章和11年前的文章相比,其价值近乎一样。因此,根据指数函数的特点,设计了符合新闻时效性特征的句子权重计算方法。
假设currentTime表示当前时间,oldestTime表示某主题内最早的一篇报道的发表时间。TimeLenth表示时间区间,即TimeLenth=currentTime-oldestTime。定义Timei为第i篇文章的发表时间。则基于报道时间的句子权重e3如式(11):

对上述三种句子权重的结果进行加权求和,得到句子的融合权重W,即句子重要度,如式(12)所示:

其中,quo表示权重系数,。
4 实验过程
4.1 数据收集
本文算法的数据集主要由纽约时报、福克斯新闻、华尔街日报、美国之音等国外著名新闻网站的报道组成,内容涉及网络、科技、军事、政治、经济、安全等领域。实验采用Python及Java语言,利用主题爬虫对新闻网站进行数据的采集,通过对网页源码进行正则匹配,得到所需格式的数据,共计抓取656 篇报道,去除篇幅过长和过短的报道,得到400篇符合要求的文档。
4.2 数据预处理
(1)去除噪声。该步骤去除对文本分析贡献度不大的特殊符号、表格等。
(2)词干化。此处采用经典的波特词干算法对单词进行词干化,该方法速度快,准确度高,目的是删除单词的后缀,保留词根。
(3)文档分割。首先,利用正则表达式匹配标点符号,将文档分割为句子集合。然后,通过去除停用词和标点符号,将句子表示为词项集合。
4.3 过滤句子
过长或过短的句子不适宜作为摘要的候选句,本实验考虑将长度系数CL >0.8 以及CL <0.2 的句子去掉。句子长度系数的定义如式(13)所示:

其中,L为句子的长度,LM为最长句子的长度。
4.4 文本向量化
通过改进的TF-IDF算法,对单词进行词权的计算,选取词权最高的50 个单词作为特征词,将文档转化为50维的向量,用于文档聚类前的相似度计算。
4.5 文本聚类
利用上文提到的基于文档、句子两阶段的文本聚类算法对多文档进行二次聚类,先得到文档中主要的分类方向,继而得到每个类别下的子主题。
4.6 摘要句抽取
利用基于特征融合的方法对摘要进行提取。传统方法没有考虑文档的时效性和新颖性,此处利用余弦函数及指数函数的特性,为句子位置与报道时间这两个衡量句子重要度的关键因素设计了特殊的权重衡量公式。
4.7 摘要输出
将每个子主题中得分高的K个句子按原文顺序及报道发表时间顺序输出,保证生成的摘要的连贯性。K的计算公式如式(14)所示:

其中,size(topic)表示topic主题下的句子个数,根据经验,此处的perc取为20%。
5 结果分析
实验中的主要参数如表2所示。

表2 实验中的主要参数
实验对一阶段文本聚类和两阶段文本聚类进行了性能的对比,具体运行时间如图4所示。由图4可知,一阶段聚类和两阶段聚类的消耗时间均随着文档数量的增加呈现上升的趋势,其中一阶段聚类所消耗的时间增加得更快。随着数据规模的增大,一阶段聚类的时间消耗将会大幅度提升,两阶段文本聚类的优势将逐步显现。产生这样的实验结果,是因为两阶段文本聚类中的第一阶段,已经对文本进行了初步的分类,为第二阶段的句子级聚类缩小了聚类的范围,从而减少了不必要的时间开销。从复杂度的角度来分析,本文基于密度的聚类方法本身的时间复杂度为O(n2),若对所有文档中的n个句子直接进行聚类,则时间复杂度为O(n2)。本文采用的是两阶段的聚类方法,假设一阶段的聚类将文档分为m个主题,则两阶段聚类的平均时间复杂度为,由于m的数量小于n,因此要小于n2,在主题个数合理的情况下,两阶段聚类的方法可较大幅度节省时间开销。相较于一阶段聚类进行主题划分的算法,本文所采用的两阶段文本聚类进行主题划分的算法运行效率更高。

图4 一阶段聚类与两阶段聚类运行效率对比图
图5 展示了在进行文档级聚类时,ψ值的变化趋势。由图可知,由簇中心点到非簇中心点过渡时,ψ值存在较大的变化,本实验选取ψ≥0.2 的16 个节点作为簇中心点,共选取了16个主题。

图5 ψ 值变化图
在本实验中,对自动摘要效果的评价主要是通过与人工撰写的摘要进行对比。实验采用的数据均经过国家应急响应中心专业人员的交叉审核,标准摘要亦由相关专业人士标注,准确性和可靠性高。国际上通用的评价指标为查准率P(Precision)、F1 分数(F1 Score)、查全率R(Recall)。查准率P是指正确摘要的句子占全部摘要句子的百分比,主要衡量摘要表现原文主题信息的准确度。查全率R是指被正确分类的文档样本数量占总文档样本数量的百分比。由于查准率和查准率是两个不同的指标,它们的关系是二律背反的。F1 分数是二者的调和平均值,一般来说,F1 分数越高,说明聚类效果越佳。计算公式详见式(15)~(17):

本实验通过对比三种算法,分别为本文所提的算法、TextRank算法以及TextTeaser,计算各算法在每种主题下的准确率P、召回率R及F1 值。由于句子级聚类得到的子主题较多,此处的主题是指文档级聚类得到的16个分类,其中的值为各分类中子主题的平均值,算法对比结果详见表3。

表3 算法对比结果
通过求取平均值对三种算法的三个指标进行对比,算法效率如图6所示。
实验结果表明,本文算法的平均查准率能达到83%,分别比TextRank 算法和TextTeaser 算法高出24%和18%。与此同时,本文算法的平均查全率为63%,比TextRank 算法高出19%,比TextTeaser 算法高出11%。此外,本文算法的F1 分数也较高,平均F1 分数为71%。综上,本文算法在自动文本摘要生成方面的效果比传统算法更加优化。因为利用改进的TF-IDF文本特征向量化方法,能够更加突出新闻热点;基于密度的聚类算法能够提高运行效率,本文所提密度聚类算法可以自动确定簇中心个数,两阶段的文本聚类,亦使得摘要富有层次性;此外,考虑到新闻时效性强,报道时间及句子位置对句子重要度起关键作用,本文算法利用余弦函数及指数函数的特性,对句子重要度进行运算,使得得到的摘要句更符合新闻文本的特点。
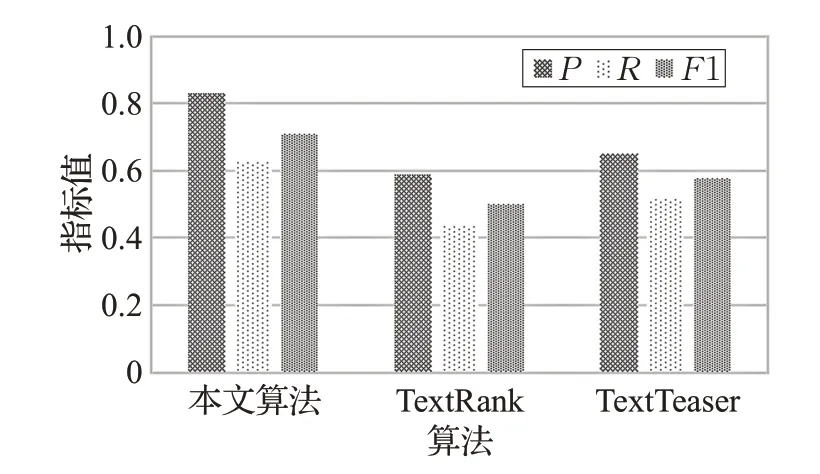
图6 算法效率
6 结束语
自动文本摘要技术应需而生,主要运用于新闻领域,旨在帮助群众快速获取信息,帮助情报部门快速了解国内外动态。本文算法基于新闻领域时效性强、主题明确的特征,对先前学者的研究进行改进,算法多次将时间因素纳入考虑的范围。实验表明,本文算法可提升摘要的时效性。此外,两阶段的聚类也在提升效率的同时,使最终生成的摘要更具层次性。然而,本文算法还存在许多局限性,有待深入研究,例如生成摘要时,如何使摘要更加通顺、连贯。本文研究的两阶段聚类虽然能够提升效率,但在多个子主题中抽取摘要容易产生句子不连贯的问题。因此,如何利用语义分析增强摘要的连贯性是未来的研究方向。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
当代陕西(2020年17期)2020-10-28
铁道通信信号(2019年6期)2019-10-08
人大建设(2018年5期)2018-08-16
雷达学报(2017年6期)2017-03-26
信息安全研究(2016年4期)2016-12-01
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
