
基于语言学特征与层次注意力机制的幽默识别
2020-08-19 07:00邹艳波樊小超
计算机工程 2020年8期
杨 勇,杨 亮,邹艳波,任 鸽,樊小超,
(1.新疆师范大学 a.计算机科学技术学院; b.物理与电子工程学院,乌鲁木齐 830054;2.大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
0 概述
幽默普遍存在于日常用语中,是人们沟通交流的重要组成部分。幽默一词来源于英文单词“Humor”,由林语堂先生于1924年引入中国,有可笑、有趣而意味深长之义[1]。近年来,随着人工智能的快速发展,幽默识别受到了国内外学者的广泛关注。幽默识别任务通常是识别某个语句或段落是否包含幽默的语义表达[2-3]。幽默数据集有多种类型[3],包括笑话、One-liner形式的幽默、对话幽默等,本文的研究重点为One-liner形式的幽默。
One-liner形式的幽默通常是一个简短的句子,使用少量词汇传达幽默的语义。与其他形式的幽默相比,One-liner形式的幽默缺乏上下文信息,多数采用语音、语言歧义或叠字等手段产生预期的幽默效果。针对One-liner形式的幽默,目前的幽默识别方法主要分为基于特征工程的机器学习方法[4-5]和基于神经网络的深度学习方法[6-7]。前者需要领域专家构建特征,且耗时耗力,泛化能力较差。后者网络结构的构建通常缺乏幽默理论的驱动,可解释性较差。为解决以上问题,本文提出基于语音、字形和语义的层次注意力神经网络模型(PFSHAN)进行幽默识别。
1 相关工作
随着幽默在互联网中的广泛应用以及文本情感分析问题的深入研究,越来越多的学者对幽默识别产生了很大兴趣,幽默识别成为自然语言处理领域的热点研究问题之一。对于幽默识别研究,根据使用方法的不同,本文从基于特征工程的机器学习方法和基于神经网络的深度学习方法两个方面对现有工作进行概述。
基于特征工程的机器学习方法被广泛应用于幽默识别领域。文献[8]构建大规模的笑话语料库,并利用n-gram特征对幽默段落进行识别。文献[5]定义3种类型的幽默特征,包括头韵、反义词和成人俚语,并通过实验证明了其在幽默识别中的有效性。文献[9]基于幽默的不一致性理论和语言学特点,设计5个类别多达50多种幽默特征。文献[4]对幽默的潜在语义特征进行系统阐述并构建包括语音特征、歧义特征、不一致性特征和情感特征在内的4种类型的幽默特征。在此基础上,文献[10]将语义分析和情感分析相结合,对情感关联模式进行建模并用于幽默识别。文献[11]通过成分分析和依赖关系分析得到幽默的句法特征来提升幽默识别的性能。文献[12]基于幽默的歧义性和语音特性提出一系列幽默特征。文献[13]由喜剧电视节目中的对话构造了幽默数据集,并采用多模态的分析方法,结合声音特征与语义特征进行幽默识别。
近年来,基于神经网络的深度学习方法在幽默识别领域取得了许多研究成果。文献[14]提取《生活大爆炸》中的对话文本,利用幽默情景剧中特有的背景笑声自动标注笑点,并采用长短期记忆(Long Short Term Memory,LSTM)网络提取语义特征和声音特征识别笑点。文献[15]采用卷积神经网络(Convolutional Neural Network,CNN)和LSTM提取幽默特征并识别对话中的笑点。文献[7]比较CNN与传统机器学习方法的性能。文献[16]采用LSTM和注意力机制在幽默评测中取得了较好的结果。文献[17]结合人工特征和神经网络自动提取的特征,对西班牙语的推特文本进行幽默识别。文献[18]构建了一个大型的俄语幽默数据集,并使用调优的预训练语言模型进行幽默识别。文献[19]提出基于张量的幽默识别方法,能够有效提取幽默语句的词汇特征。
对于现有工作的研究结果表明,语音特征和歧义性特征能够有效提高幽默识别的性能,然而人工构造的特征成本较高且泛化能力较差。相比于基于特征工程的机器学习方法,基于神经网络的深度学习方法能够自动提取幽默的高维语义特征且性能较好。然而,现有基于神经网络的深度学习方法缺乏幽默理论的驱动,实验结果难以给出令人信服的解释。本文提出PFSHAN模型识别幽默语句,PFSHAN模型基于幽默的语言学特征,分别从文本的语音、字形和语义3个维度提取幽默特征,并采用层次注意力机制,使得模型能够提取更有效的幽默特征。
2 基于音形义的幽默识别方法
如图1所示,本文提出基于音形义的层次注意力神经网络模型进行幽默识别的主要步骤为:1)将文本内容表示成对应的音素形式,采用卷积神经网络提取语句的语音特征;2)将文本表示成字符形式,采用双向门控循环单元(Bi-directional Gated Recurrent Unit,Bi-GRU)和注意力机制提取文本的字形特征;3)引入单词歧义性等级信息,更好地提取幽默语句的语义特征。为更好地区分不同幽默特征在幽默识别过程中的贡献程度,本文采用层级注意力机制来调节幽默语言学特征和幽默语句的关联程度。

图1 基于音形义的层次注意力神经网络模型Fig.1 Hierarchical attention neural network model based on pronunciation,font and semantics
2.1 基于语音的幽默特征提取
许多幽默由语音引起,文本内容中不协调的发音产生了幽默[20]。文献[5]指出幽默文本的语音特征与其语义内容一样重要。语音是引发幽默的重要手段,其通常通过押头韵或尾韵的形式进行表现[4]。
例1You can tune a piano,but you can’t tuna fish.
在例1中,句子的语义并不有趣,但是句子中单词“tune”和“tuna”有相似的发音,这使得句子的幽默效果得到了加强。在许多幽默文本中,即使文本内容不幽默,也经常使用头韵、尾韵等语音特点引发或增强幽默效果。
由于单词的发音和拼写并不完全一致,因此无法从字符来直接获取句子的语音表示。为获得单词的语音表示,本文使用卡内基梅隆大学(CMU)的发音词典将文本表示成其对应的语音形式。相比于含有重音标识的版本,包含39个音素的无重音标识的CMU发音词典更加准确。因此,本文采用无重音标识的CMU发音词典将幽默语句中的单词转换成对应的音素表示。例如,单词“word”的音素表示为[“W”,“ER”,“D”]。卷积神经网络能够更好地提取数据的局部特征且速度较快,因此本文采用卷积神经网络提取幽默语句中头韵、尾韵等语音特征。

2)变换层。本文的目标是发现单词间的头韵、尾韵等语音特征,因此采用变换层对输入张量进行变换,使得卷积神经网络的滑动窗口能够提取多个单词对应位置上的语音信息。
3)卷积层。卷积层利用一个窗口大小为h的卷积核提取局部的语音特征,其计算公式如下:
ci=f(wpi:i+h-1+b)
(1)
其中,ci为输出的特征向量,f为非线性激活函数ReLU,w为参数,pi:i+h-1代表p中的第i列到第i+h-1列,b为偏置项。在实验中使用二维卷积神经网络及多个卷积核。
4)池化层。该层主要用于文本语音特征的降维,压缩参数数量,缓解过拟合现象,提高模型的容错能力。常用的池化操作有平均池化和最大池化两种策略,本文采用最大池化策略获取固定长度的语音特征向量:
(2)
对池化后的特征向量进行拼接后,得到语句的语音特征表示为:
(3)
2.2 基于字形的幽默特征提取
幽默是一种文体,通常有其独特的表达方式,在很多情况下,正是字形的特征产生了幽默效果[21]。文献[22]指出反复出现的文本元素序列使得文本表现出相对稳定的特征。幽默语句常采用重复的字符或重复的标点符号等方法表达出幽默的效果。
例2I used to be a coyote,but I’m alright noooooooooooow!!!
例2是一个幽默的语句,该句采用字符重复的方式表现出幽默的效果。语句中的单词“now”是一个不规范的拼写形式,字符“o”被重复了多次,同时为了表达强调的效果,“!”也被重复了多次。这种刻意的字符重复是幽默语句的重要特征。
对于例2中“now”的不规范拼写形式,常规的词向量表示会将其作为未登录词处理,模型无法关注到该类单词对幽默识别性能的影响。为使模型能够捕获幽默语句的字形特征,本文对幽默语句的字符进行建模,将句子表示成字符的序列,句子的字符序列的向量表示作为模型输入。循环神经网络(Recurrent Neural Network,RNN)能够更好地处理序列信息,因此本文采用RNN提取语句中的重复字符、符号等字形特征。
在字形特征提取层中,为缓解RNN的梯度爆炸、梯度消失及长期依赖等问题,研究人员提出LSTM网络和门控循环单元(Gated Recurrent Unit,GRU)神经网络。GRU相比LSTM参数更少,训练速度更快,而两者性能相当。基于以上特性,本文采用GRU提取字形特征。GRU利用重置门和更新门控制序列的状态更新。在t时刻GRU的状态可以形式化表示为:
zt=σ(Wzxt+Uzht-1+bz)
(4)
rt=σ(Wrxt+Urht-1+br)
(5)
(6)
(7)

GRU能够提取每个时间步长t之前的信息,但是忽略了t之后的文本信息。Bi-GRU包含两个相互独立的隐藏状态,可以同时从前向和后向提取文本信息,然后对两部分信息进行整合,从而更好地利用文本的上下文信息。本文采用Bi-GRU提取文本的字形特征,其形式化表示如下:
(8)
(9)
(10)

在字符特征注意力层中,为能够对携带显著语义信息的字符给予更多的关注,在提取字形特征时,引入注意力机制,其形式化表示如下:
wij=tanh(WT[hj·Hc]+b)
(11)
(12)
(13)
其中,W为权重矩阵,b为偏置项,tanh为激活函数,aij为注意力权重,所有参数采用随机初始化并在训练中动态更新,qc为字符特征注意力层的输出向量。
2.3 基于语义的幽默特征提取
句子本身的语义特征将为幽默识别提供直接的线索。文献[23]指出语义的歧义性会引发幽默,歧义性是幽默产生的重要因素。幽默语句中的歧义性是指句子中的某些单词包含多个语义,使得句子存在多种不同的理解方式[24]。
例3Did you hear about the guy whose whole left side was cut off? He’s all right now.
例3是一个典型的由于歧义性引起幽默的语句。单词“right”包含多个语义,它既可以被理解为“右侧”,又可以被理解为“恢复”。由于单词的多个语义造成了句子理解的偏差,因此使该语句显得十分有趣。句子中单词包含的同义词的个数与语句是否幽默具有一定的相关性。
基于特征工程的机器学习方法将单词包含的同义词的个数作为特征来识别幽默[4]。为使神经网络模型能够学习到包含不同同义词数量的单词,本文根据同义词的个数对单词进行分类,将类别信息进行向量表示并和单词的向量表示进行融合,最后采用Bi-GRU和注意力机制提取携带歧义性信息的潜在语义特征。
在语义特征提取层中,Bi-GRU能够有效处理文本序列数据并能够更好地提取上下文信息。因此,本文采用Bi-GRU提取文本的语义特征,携带歧义性等级信息的语义特征可表示为Hu=Bi-GRU(x′i,ht-1)。
在语义特征注意力层中,为使模型能够关注携带显著语义信息的单词,在提取语义特征时,引入注意力机制,其中qu为语义特征注意力层的输出向量。
2.4 层次注意力机制
由于不同幽默语言学特征和幽默语句的关联程度不同,因此本文采用层次注意力机制调整不同语言学特征对于幽默识别性能的影响,其形式化表示如下:
wj=tanh(WTVj+b)
(14)
(15)
(16)
其中,W为权重矩阵,b为偏置项,Hp为语音特征表示,qc为字形特征表示,qu为语义特征表示,Vj为不同句子的表示,βj为注意力权重,所有参数采用随机初始化并在训练中动态更新,q为句子的最终特征表示。
2.5 幽默分类
本文提取文本的语音、字形和语义特征,采用softmax函数进行幽默识别,其形式化表示如下:
v=tanh(Wpq+bp)
(17)
(18)

本文模型基于反向传播算法与端到端的方式进行训练,并采用期望交叉熵作为损失函数。
(19)
其中,y为真实标签,i、j分别为句子的编号和类别编号,λ为正则化参数,θ为超参数。
3 实验结果与分析
3.1 实验数据与评价指标
Puns数据集[4]中的幽默语句来自同名网站,非幽默文本来自美联社新闻、纽约时报、雅虎新闻和谚语。Puns数据集包含幽默语句2 423条,非幽默语句2 403条,句子平均长度为13.5。Oliner数据集[5]中的幽默语句来自多个著名的幽默网站,非幽默语句来自路透社新闻标题。Oliner包含幽默、非幽默语句各16 000条,句子平均长度为12.6。为便于和基线方法进行比较,本文采用精确率、准确率、查全率和F1值作为评价指标。
3.2 实验设置
在训练过程中,词向量采用GloVe进行初始化,维度为300。语音向量采用高斯分布U(-0.1,0.1)进行随机初始化,维度为100。字符向量采用随机初始化,维度为100。单词被划分为4个歧义性类别,歧义性等级采用随机初始化,维度为10。卷积神经网络采用2D卷积和池化层,卷积核数量为128,卷积核大小为2、3、4。Bi-GRU的神经元个数为150,优化方法为Adadelta[26]。Batch大小为64,dropout为0.5。同时,在训练过程中使用学习率衰减和早停机制防止过度拟合,并使用五倍交叉验证法减少数据集划分的影响。
3.3 对比方法
实验对比方法具体如下:
1)支持向量机(Support Vector Machine,SVM)。该方法[4]使用人工构造的语音特征、歧义特征、不一致特征和情感特征,采用支持向量机模型。
2)HCFW2V。该方法[4]同时使用上述4类特征和词向量作为幽默特征,采用随机森林模型。
3)ST。该方法[10]同时使用上述4类特征以及人工构造的情感冲突和情感转换特征,采用随机森林模型。
4)Syn。该模型[11]同时使用上述4类特征以及人工构造的句法结构特征,采用随机森林模型。
5)CNN。该模型[7]采用卷积神经网络进行幽默识别。
6)Bi-GRU。该模型采用Bi-GRU提取幽默文本的潜在语义特征并进行幽默识别。
7)Bi-GRU+Att。该模型采用Bi-GRU和注意力机制提取语义特征并进行幽默识别。
8)CNN+HN。该模型[27]采用CNN和Highway网络架构。
9)PFSHAN。本文提出的一种基于语音、字形和语义的层次注意力神经网络模型。
表1和表2列出了不同幽默识别方法与模型的性能对比,其中最佳结果加粗显示,实验结果表明:
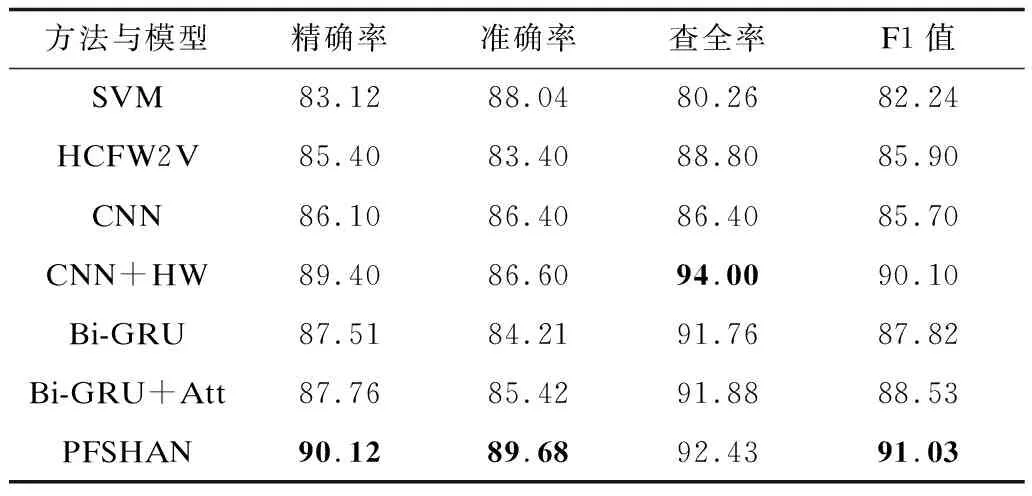
表1 Puns数据集上的实验结果Table 1 Experimental results on Puns dataset %

表2 Oliner数据集上的实验结果Table 2 Experimental results on Oliner datasets %
1)基于特征工程的机器学习方法的性能低于基于神经网络的深度学习方法。对于相同的人工特征集合,基于特征工程的机器学习方法在两个数据集上性能有所差别。HCFW2V在Puns数据集上性能较好,而SVM在Oliner数据集上性能较好。这也说明了基于特征工程的机器学习方法依赖于人工特征的构造,其泛化能力较差。此外,引入句法信息后,幽默识别的性能有了一定幅度的提升。
2)基于神经网络的深度学习方法能够自动学习幽默语句的潜在语义特征,在两个数据集上均表现出较好的性能。Bi-GRU能够更好地利用上下文信息与长距离的依赖关系,其性能优于CNN。引入Highway后,CNN的性能有了较大幅度的提升。
3)PFSHAN模型在两个数据集上均取得了最佳的性能。PFSHAN模型能够提取语句的语音、字形和语义信息,而且在提取语义特征时,其能够捕获单词的歧义性信息,从多个维度提取幽默特征。此外,PFSHAN模型采用层级注意力机制,不仅能够调节不同输入对提取特征的影响,而且能够调节不同语言学特征对幽默识别的影响。
3.4 歧义性等级信息对模型性能的影响
为验证歧义性等级信息对幽默识别的影响,本文对比仅使用语义信息的Bi-GRU和加入歧义性等级信息的Bi-GRU的PFSHAN模型幽默识别性能。如图2所示,加入了歧义性等级信息后,PFSHAN模型F1值均有所提高,在Puns数据集上F1值提高了0.8%,在Oliner数据集上提高了1.14%。实验结果表明,单词的歧义性等级信息能够有效提高PFSHAN模型的幽默识别性能。

图2 歧义性等级信息对幽默识别性能的影响Fig.2 Impact of ambiguous level information on performance of humor recognition
3.5 语音、字形和语义特征对模型性能的影响
本文对比语音、字形和语义特征对PFSHAN模型性能的影响,PFSHAN-pro、PFSHAN-font、PFSHAN-sem分别表示未使用语音、字形和语义信息的PFSHAN模型。如表3所示,当PFSHAN模型未使用语义信息时,模型性能受到的影响最大。这表明模型能够从文本的潜在语义信息中学习到与幽默关联较强的信息,如果仅从语音和字形特征对幽默进行识别,则模型性能较差。当PFSHAN模型未使用字形信息时,对模型性能影响较小。这可能是因为在构造数据时对数据进行了预处理,其不规范的拼写等字形特征较少。语音特征对模型有一定的影响,说明文本中一部分幽默是由语音特征引起。当同时引入音形义特征时,PFSHAN模型取得了最佳的性能,这表明语音、字形和语义特征能够更加有效地对幽默文本进行表征,从而提高幽默识别性能。

表3 语音、字形和语义特征对幽默识别性能的影响Table 3 Impact of pronunciation,font and semantics on performance of humor recognition %
3.6 层次注意力机制对模型性能的影响
本文对比了不同注意力机制对幽默识别性能的影响。PFSHAN-Hyp表示提取字形和语义特征后,采用注意力机制得到字形和语义信息的表示,然后直接和语音信息进行拼接并识别幽默。PFSHAN-Lin-Hyp表示只使用Bi-GRU提取字形和语义特征,并使用CNN提取语音特征,然后拼接3类特征进行幽默识别。
如表4所示,采用层次注意力机制能够有效提高幽默识别的性能,相比不使用注意力机制的模型,PFSHAN在两个数据集上的F1值分别提高了1.19%和0.97%。实验结果表明,层次注意力机制不但能够调整不同字符或单词对于不同幽默特征的权重,而且能够调节不同幽默语言学特征和幽默语句的关联程度,从而提高幽默识别性能。

表4 层次注意力机制对幽默识别性能的影响Table 4 Impact of hierarchical attention mechanism on performance of humor recognition %
3.7 错误样例分析
为更好地研究并提升PFSHAN模型在幽默识别任务中的性能,对其错误样例进行分析。以下是两个PFSHAN模型不能正确识别的样例:
例4The one who invented the door knocker got a no bell prize.
例5A clean house is a sure sign of a broken computer.
例4和例5均为幽默样例,但是PFSHAN模型却把它们视为非幽默的语句。在例4中,“no bell prize”的发音和“nobel prize”发音十分类似,所以引发了幽默的效果。显然,该句的幽默效果是语音所致,但是“nobel prize”没有出现在原文中,PFSHAN模型无法捕获相关的语音特征。此外,背景知识也是判断该语句是否是幽默的重要因素。在例5中,“clean house”和“broken computer”形成了语义上的对比,这种不协调、不一致使得句子产生了幽默的效果,因此如何捕获文本语义的不一致性将是未来幽默识别中的重要研究方向。
4 结束语
本文提出基于语音、字形和语义的层次注意力神经网络模型(PFSHAN)进行幽默识别。基于幽默文本的语言学特点,采用CNN和Bi-GRU捕获幽默语句的语音、字符和语义特征,同时利用层次注意力机制调节不同语言学特征对幽默识别的影响。实验结果表明,本文方法能够有效获取幽默语句的音形义特征,提高幽默识别性能。但由于PFSHAN模型仅适用于英文文本的幽默识别,而中英文表达在很多方面存在差异,因此下一步将构建中文幽默数据集及模型进行中文幽默文本识别。此外,如何利用自注意力机制与预训练模型捕获文本语义的不一致特征也将是今后研究的重点。
猜你喜欢
新世纪智能(语文备考)(2020年4期)2020-07-25
开放教育研究(2020年2期)2020-03-31
中国外汇(2019年12期)2019-10-10
语文教学与研究(综合天地)(2018年10期)2018-12-24
疯狂英语·新悦读(2017年2期)2017-04-08
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
校园英语·下旬(2016年3期)2016-04-18
长江学术(2016年4期)2016-03-11
小学生·多元智能大王(2014年6期)2014-07-09
