
融合多头自注意力机制的金融新闻极性分析
2020-08-19 07:00:56赵亚南
计算机工程 2020年8期
赵亚南,刘 渊,宋 设
(1.江南大学 数字媒体学院,江苏 无锡 214122; 2.江苏省媒体设计与软件技术重点实验室,江苏 无锡 214122;
0 概述
情绪是对某种情况或事件的看法或态度,也可称为意见。文本情感分析是自然语言处理(NLP)领域的重要研究方向,旨在挖掘人们对产品、服务、个人和组织等实体的意见和情感以及文本中的事件、主题和属性[1]。情感分析的任务是识别语言文本极性,如积极、消极或中立,其被广泛应用于电影评论、信息预测和金融决策等领域[2]。相关研究表明,金融领域文本数据的情绪和意见可以影响市场动态、相关个股或者公司价值走势[3]。因此,分析金融新闻的倾向性可以帮助个人、公司即时获取新闻的重点内容,有助于投资者进行投资决策。
为解决文本情感分类问题,文献[4]在电影评论数据集上比较了朴素贝叶斯(Naive Bayesian,NB)与支持向量机(Support Vector Machine,SVM)的性能,实验结果表明,SVM的准确率高于NB。文献[5]根据分布式同义词,提出一种基于支持向量回归(Support Vector Regression,SVR)和逻辑回归集合的模型,以预测金融文本的倾向。文献[6]在亚马逊书评上评估了各种预处理技术与不同分类器相结合的有效性,其中,随机森林(Random Forest,RF)取得了90.15%的平均准确率,但其时间开销较大。多数机器学习方法都是逐字考虑文本,分析句子中的单词并根据单词的属性将句子分为正面或负面2个极性,有时为了提取句子的关键词而丢失了其他单词信息。
运用深度学习技术研究自然语言处理问题是当前的研究热点。在利用神经网络挖掘文本中的情绪时,可以考虑一段句子而不仅是逐个单词。文献[7]利用经典的CNN进行文本分类。文献[8]用双层CNN对中文微博从字到句抽取特征,其完善了短文本信息。文献[9]通过对情感词典的词性进行向量化操作,在网络架构中添加文本情感特征信息,然后组合不同的文本特征形成不同的通道并输入CNN网络,该模型提高了情感分类的准确率。文献[10]采用双层双向长短期记忆(BLSTM)网络模型对金融标题进行情感极性分析,但其模型的训练时间较长。文献[11]基于文本细粒度意见分析问题,建立了双向RNN的序列标注模型。文献[12]在RNN中引入注意力(Attention),将其应用于图片分类任务。文献[13]首次在机器翻译中使用Attention,其提高了翻译效果。文献[14]构建分层注意力网络,逐步建立单语言文档并进行文档分类。文献[15]利用BLSTM对句子进行建模,然后运用Attention计算BLSTM隐藏单元的权重信息。文献[16]采用混合注意力网络进行情感分析,其使用全局和局部Attention分别捕获文本整体上下文的粗略情感信息和接近目标的句法信息。
在自然语言处理领域,Google于2017年提出Transformer机器翻译模型[17],其仅利用纯Attention结构就取得了非常好的性能,具有良好的特征抽取效果。受此启发,本文将多头自注意力机制应用于文本情感分析任务。相较于经典机器学习算法,深度学习中的CNN与RNN算法在一定程度上可以自动捕捉文本的语义特征,且与RNN相比,CNN算法具有可以并行运算的优势。因此,本文将多头自注意力机制与CNN网络相结合,建立一种新的混合回归模型,用以预测金融新闻的情感极性值。由于神经网络抽取特征不够充分,因此在模型中考虑重利用浅层特征,结合文本的浅层特征与多头自注意力特征来提升模型训练效果。
1 相关工作
1.1 多头自注意力机制
神经网络中的注意力机制起源于人类视觉注意力,其模拟人类在观察信息时会重点关注信息的某些特定部分。目前,基于Attention的方法已成功应用于各种任务,如图片分类[12]、神经机器翻译[13,17]和文本分类[14]等。在机器翻译领域,为了更准确地提取文本特征,文献[17]提出了多头自注意力方法并构建了Transformer模型。文献[18]提出一种用于远程监督关系提取的神经网络MSNet,其利用MA学习句子的结构表示信息。文献[19]建立一种SAAN情感分析模型,该模型通过CNN学习单词表示,然后利用多头注意力结构进一步学习句子表示。文献[20]运用BLSTM捕捉词语间的语义依赖关系,再利用自注意力进一步学习重点词的特征信息,结果表明,该方法提升了情感分类的效果。上述方法验证了MA在文本特征提取方面的有效性,因此,本文采用MA对金融新闻数据集进行处理,学习其句子表示。MA的原理为:缩放点积注意力(Scaled Dot-product Attention,SDA)[17]通过向量点积进行相似度运算,得到Attention值。SDA结构如图1所示,本文SDA结构去掉了原结构中的mask操作,其计算如式(1)所示。

图1 SDA结构示意图Fig.1 Schematic diagram of SDA structure
(1)

多头注意力机制的目的是从多方面捕获序列的关键信息。Q、K、V分别通过参数不共享的线性转换送入SDA。将SDA运算重复h次,最后拼接所有的Attention值并进行线性变换,如式(2)、式(3)所示。其中,由于每个head的尺寸减少,因此算法的计算成本与具有全维度的单头注意力相似。
(2)
Head=MultiHead(Q,K,V)=
Concat(head1,head2,…,headh)WO
(3)

多头注意力机制结构如图2所示。
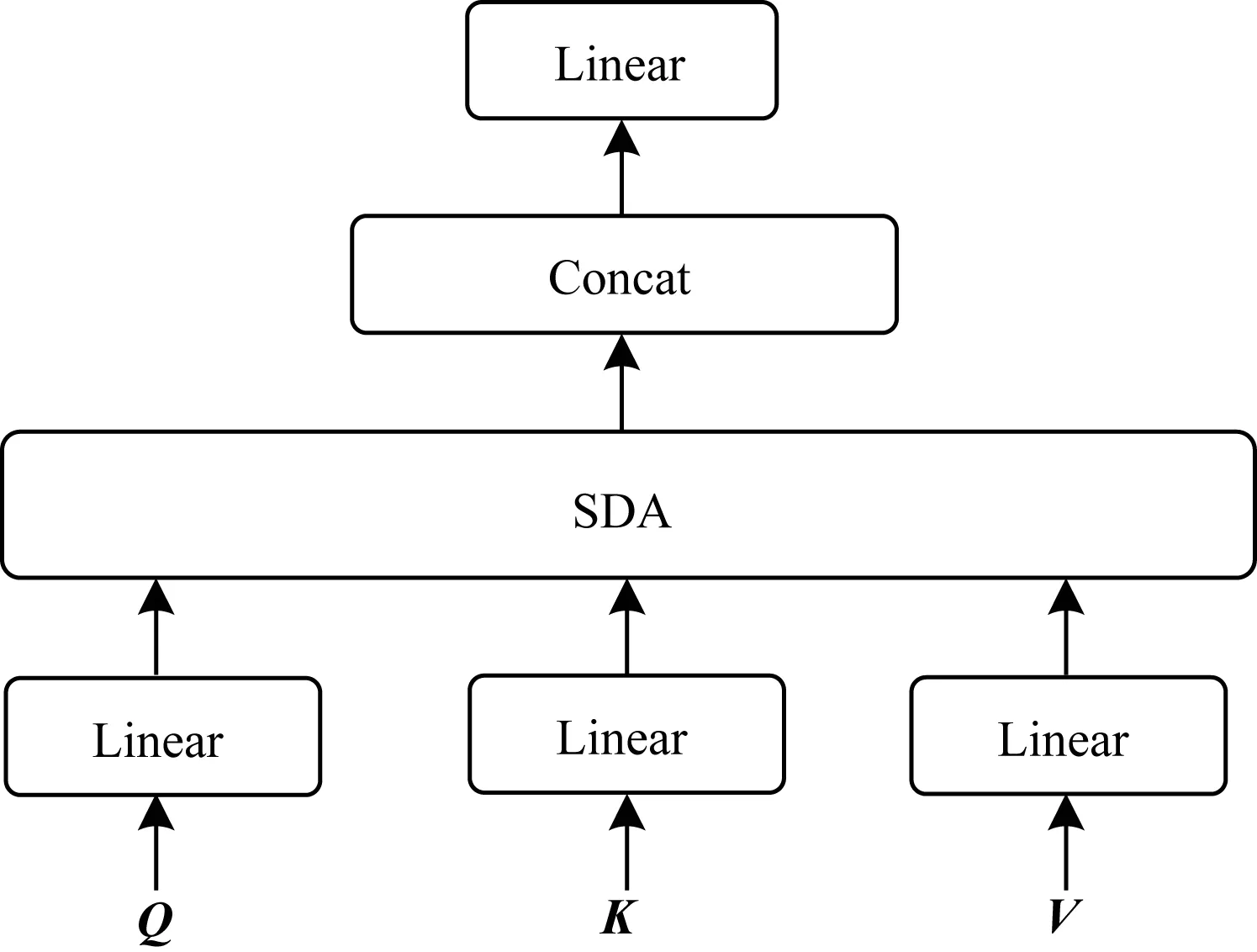
图2 多头注意力机制结构Fig.2 Structure of multi-head attention mechanism
当Q=K=V=X时,多头注意力为多头自注意力,X={x1,x2,…,xl,…,xL}是文本输入序列,其本质是将xl与X序列中的各个词进行对比,最后计算出每个词的权重信息,即在序列内部做注意力计算,进而获取序列的内部结构,也称为内部注意力。
1.2 卷积神经网络
CNN最初应用于计算机视觉领域[7]。运用CNN挖掘文本情绪时,首先将输入文本(长度为L)转换为矩阵X,每个句子矩阵的行是单词矢量(维度为k),将矩阵输入到CNN架构中,CNN输出每个句子的特定特征矩阵C,步骤如下:
X=[x2,x2,…,xL]T
cl=f(ω·xl:l+t-1+b)
C=[c1,c2,…,cL-t+1]
(4)
得到特征图后通过池化策略对输入特征矩阵进行二次采样,最后输出层应用Linear激活函数计算句子的情感值。
2 双层多头自注意力与卷积神经网络融合模型
MA的一个优点是可以获取到文本的全局联系,但其没有捕获局部特征的能力,而CNN的最大特点在于局部感知。因此,本文建立一种融合双层多头自注意力与CNN的DLMA-CNN模型,其结构如图3所示。将MA作为一个单独的层,区别于传统的CNN结合Attention的方法[19],DLMA-CNN模型直接将MA层置于词向量层之后。模型采用多头自注意力表示句子,学习序列内部的词依赖关系[17],然后融合CNN网络以预测金融文本的情感极性。

图3 DLMA-CNN模型架构Fig.3 DLMA-CNN model architecture
考虑到在深度学习模型训练过程中,神经网络存在特征抽取不充分或无法学习到更深层语义信息的问题,导致模型无法准确地捕捉文本情绪的关键信息。为解决以上问题,本文借鉴CNN网络中应用的Inception方法[21],该方法用于改善传统的卷积层结构,其级联同一层级多个尺寸卷积核的结果,提高了深度神经网络的性能。本文将Inception方法运用于文本情感分析模型中,提出一种重利用浅层特征改善模型,即在模型中连接文本的浅层、深层特征,丰富每一层输入序列的特征信息,使得模型可以更充分、更全面地学习文本序列的特征信息,从而提高网络文本情感分析的性能。
DLMA-CNN模型由输入层、隐含层和输出层组成,其中,隐含层包含双层多头自注意力层、卷积操作层与全局平均池化层。
1)输入层,该层预处理SemEval-2017 Task 5金融文本数据集,将训练文本输送到文本词嵌入层,将句子变换成多头自注意力层可以直接处理的文本词向量矩阵。设置模型输入大小L为训练文本中句子的最大长度,使用零填充长度小于L的输入文本。将每个句子表示成大小为L×dk的文本词向量矩阵E:
(5)
其中,E中的每一行el为句子中第l(1≤l≤L)词对应的词向量,词向量的维度为dk。
2)隐含层,该层利用MA与CNN算法融合文本序列的全局与局部特征。
(1)第一层多头自注意力层。MA旨在输入特征矩阵E内部多次计算注意力,用以捕获句子的长距离依赖性并学习不同位置不同语义空间的序列信息。
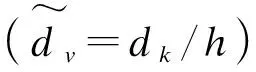
(6)

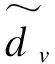
(7)
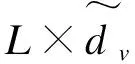
(8)
其中,αis是第i(1≤i≤h)次自注意力运算得到的词vs的权重系数。
Att1=MultiHead(E,E,E)=
Concat(head1,head2,…,headh)WO
(9)
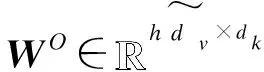
(2)第二层多头自注意力层。为了提取更丰富的特征信息,将浅层特征文本词向量E与第一层MA的特征序列Att1拼接融合,并作为新的特征F1送入第二层Transformer(MA2),用以提高输入文本中每个词的重要程度,提取出文本更高层次的特征表示。F1计算如下:
F1=Concat(E,Att1)
Att2=MultiHead(F1,F1,F1)
(10)

F2=Concat(E,Att2)
(11)
本文采用文献[7]的卷积层结构,使用多个不同尺寸大小的卷积核充分提取词语特征。使用滑动窗口大小为t的卷积核对输入特征进行卷积操作,如式(12)所示:
(12)
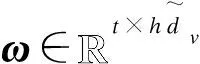
(13)
(4)全局平均池化层。将卷积层后的特征矩阵送入池化层再次进行特征采样,采用GAP(Global Average Pooling)[22]取代全连接层。GAP的使用降低了参数的规模,对整个网络进行正则化从而缓解了过拟合现象。通过GAP计算不同尺寸的卷积结果得到的特征信息表示为:
(14)
(15)

(16)
优化算法采用均方根反向传播算法(RMSProp)最小化损失函数,模型的目标函数应用均方误差(MSE),损失函数如式(17)所示:
(17)
3 实验结果与分析
3.1 实验数据
本文基准数据集采用SemEval-2017 Task 5的金融新闻标题(Finance News Headlines)数据集,数据集的样本情绪分数标记为-1和1之间的真实值,越靠近-1则越消极(负面、看跌),越靠近+1则越积极(正面、看涨)。为了评估DLMA-CNN模型的泛化能力,同时在SemEval-2017 Task 5的金融微博(Microblog Message)数据集上进行实验。数据集详情如表1所示。
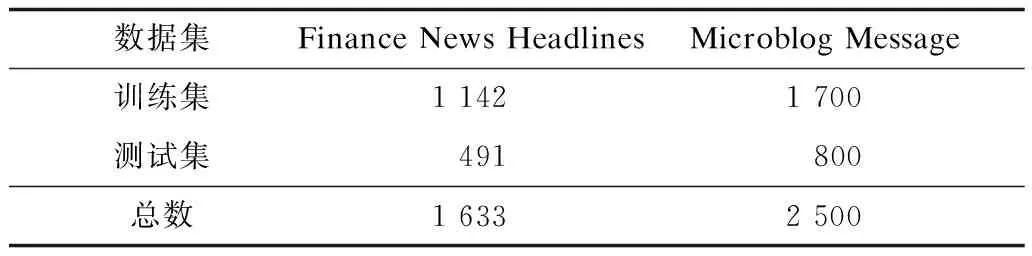
表1 实验数据集Table 1 Experimental dataset
3.2 实验衡量指标
评估指标1余弦相似性(Cosine Similarity,CS)[17],其比较样本情绪值与系统预测结果之间的一致程度,CS计算如下:
(18)
其中,G为文本标记情感值向量,P为系统预测文本情感值向量。
评估指标2该指标为CS与回答问题的比率加权:
(19)
评估指标3该指标为余弦和权重的乘积:
(20)
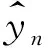
3.3 实验参数设置
在金融新闻标题文本上,采用Word2vec词嵌入方法预训练词向量数据,将文本输入单词输出为300维向量。DLMA-CNN模型参数设置:CNN的滤波器数量为100,窗口大小分别为3、4、5,步长为1,CNN单元的非线性函数均使用不易饱和的softsign,学习率设置为0.001,mini batch为16,引入梯度裁剪缓解梯度爆炸,clipvalue大小为5。为减少模型过拟合现象并避免手动设置epoch次数,DLMA-CNN模型采用回调函数Early Stopping(),patience=10。在训练过程中,对比当前的Loss与上一个epoch的结果,当损失函数不再减少时,通过10个epoch后停止训练。经过测试,在多头自注意力层与输出层分别将Dropout比率设置为0.1、0.5时,模型具有最优性能。实验采用10折交叉验证方法,实验的硬件环境:GPU为NVIDIA GTX1080Ti,CPU为i7-8700K;软件环境:Keras2.2.1(底层Tensorflow)。
3.4 实验对比
为了验证本文DLMA-CNN模型的优越性,将如下模型进行对比,分别在SemEval-2017 Task 5 Finance News Headlines数据集和Microblog Message数据集上进行文本情感极性分析。
1)机器学习算法:包括SVR与RF。SVR[10]最终找到一个回归平面,使一个集合的所有数据到该平面的距离更近,设置SVR的惩罚参数C为0.1,epsilon为0.01。RF算法[6]使用多个决策树训练和预测样本,设置决策树个数estimators为20。
2)ELSTM与EGRU。EGRU与ELSTM结构[10]相同,EGRU使用GRU单元取代LSTM,其他参数设置两者相同。
3)Att-BLSTM,使用Attention机制学习BLSTM输出层的特征信息[15]。
4)BiLSTM+EMB_ATT,采用BLSTM学习输入句子的语义信息,其与词向量自注意力为并行结构[20]。
5)MA,纯Attention,本文模型DLMA-CNN只保留单层MA网络结构,去掉CNN网络层,其他参数设置相同。
6)N-DLMA与DLMA:纯Attention,本文模型DLMA-CNN保留双层MA结构,去掉CNN网络层。其中,N-DLMA模型不考虑重利用浅层特征,即不将浅层特征与多头自注意力特征进行融合,其他参数设置相同。
7)CNN:本文模型DLMA-CNN去掉MA层,其他参数设置相同,不同于文献[7]中CNN结构使用的最大池化层,本文使用GAP。
8)DLMA-CNN:本文提出的一种融合多头自注意力机制与CNN的混合模型。
在上述模型中,深度学习模型MA、N-DLMA、DLMA、CNN和DLMA-CNN,除了模型的功能层外其他条件均一致。
3.5 结果分析
3.5.1 多头自注意力超参数取值对结果的影响
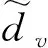

表2 h取值对结果的影响Table 2 Effect of h value on results
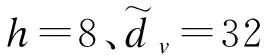
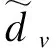

表3 注意力大小对结果的影响Table 3 Effect of attention size on results

3.5.2 Attention、CNN与DLMA-CNN模型对比
在测试集上进行对比实验,验证各模型的3个指标,结果如表4、表5所示。从表4、表5可以看出,DLMA-CNN模型相对于纯Attention模型、CNN模型,在3个衡量指标上都取得了最优结果。DLMA模型的性能优于MA模型、N-DLMA模型,这说明了重利用浅层特征的有效性,浅层特征与多头自注意力特征融合能够丰富特征信息,提高模型训练的结果。在评估指标Metric1上,DLMA-CNN模型比MA模型提高了3.1%~3.8%,比CNN模型提高了6.7%~7.8%,即本文提出的混合模型优于单一注意力模型,这是因为纯Attention模型更适合解决长程、全局的依赖问题,在DLMA-CNN模型中引入CNN,CNN的卷积计算使得模型更加关注局部结构,从而弥补了纯Attention的不足,因此,融合Attention和CNN的模型效果更优。

表4 Finance News Headlines数据集上的实验结果1Table 4 Experimental results 1 on the Finance News Headlines dataset %
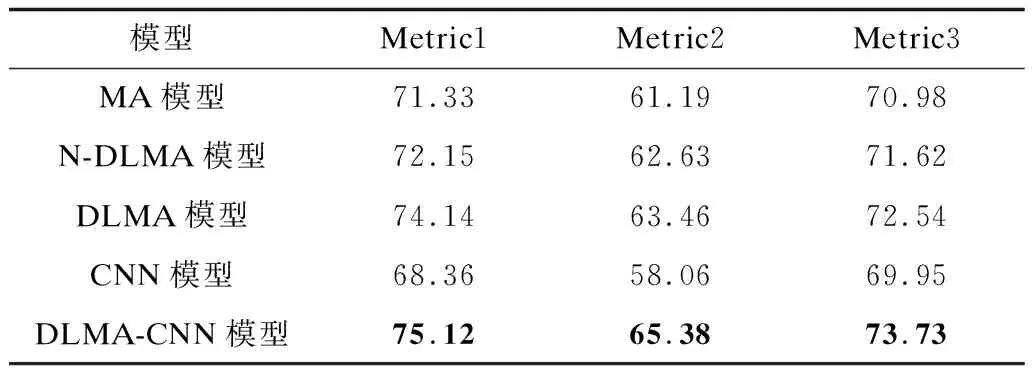
表5 Microblog Message数据集上的实验结果1Table 5 Experimental results 1 on the Microblog Message dataset %
3.5.3 与其他深度学习算法的对比
为了进一步验证本文模型的性能,在Finance News Headlines和Microblog Message数据集上,将该模型与其他文本情感分析算法进行对比,实验结果及各模型每个epoch所耗费的时间如表6、表7所示。
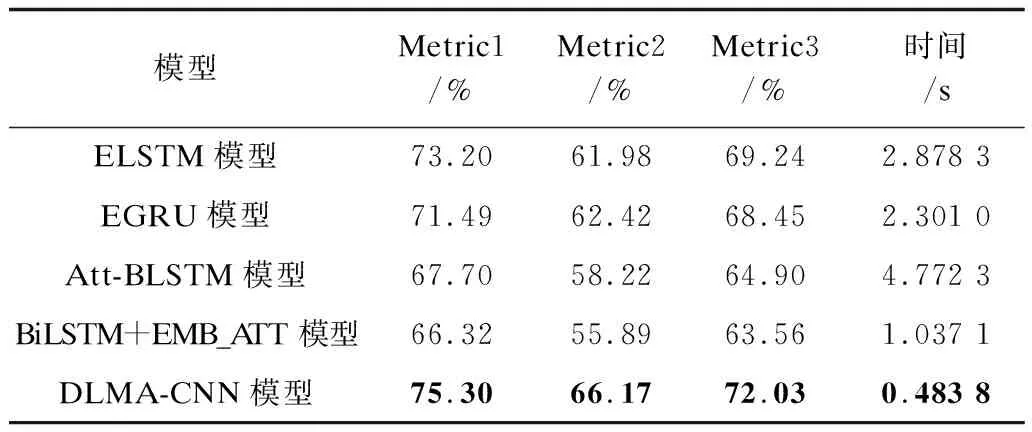
表6 Finance News Headlines数据集上的实验结果2Table 6 Experimental results 2 on the Finance News Headlines dataset

表7 Microblog Message数据集上的实验结果2Table 7 Experimental results 2 on the Microblog Message dataset
从表6、表7可以看出,DLMA-CNN模型的性能优于其他模型。对比Metric1指标上各模型的结果,DLMA-CNN模型比ELSTM模型提高了2.1%~3.6%,比EGRU模型提高了3.8%~5.3%,分别高于Att-BLSTM、BiLSTM + EMB_ATT模型4.9%~7.6%与8.9%~9.2%。从算法运行时间来看,RNN模型的效率较差,而DLMA-CNN混合模型的运行时间最短,这是由于RNN存在序列依赖关系,下一时间步(t)的隐藏计算依赖上一时间步(t-1)的计算,LSTM不能很好地并行运行,造成训练时间较长。而MA、CNN不依赖前一时刻(t-1)的计算,具有较高的并行计算能力,因此,DLMA-CNN模型的时间复杂度远低于RNN模型。
3.5.4 与经典机器学习算法的对比
如表8、表9所示,DLMA-CNN模型在2个数据集上的实验结果均优于经典的机器学习模型SVR与RF,验证了本文模型的有效性和泛化能力。DLMA-CNN模型展现了其良好的性能,在文本情感极性分析任务中具有较大优势。

表8 Finance News Headlines数据集上的实验结果3Table 8 Experimental results 3 on the Finance News Headlines dataset %
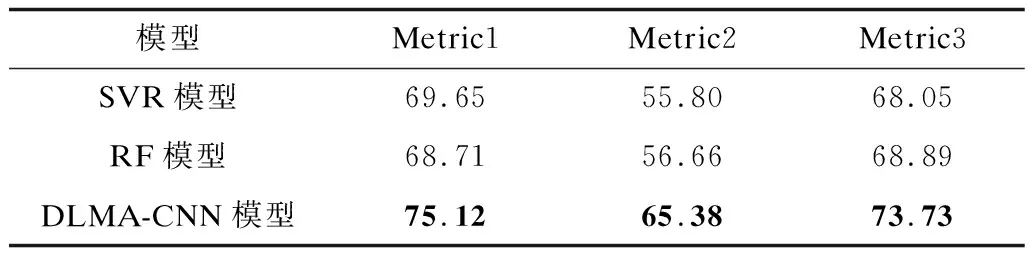
表9 Microblog Message数据集上的实验结果3Table 9 Experimental results 3 on the Microblog Message dataset %
4 结束语
为对金融领域的新闻进行情感极性分析,本文提出一种融合双层多头自注意力机制与CNN的混合模型DLMA-CNN。通过采用Transformer机器翻译模型中的多头自注意力机制获取文本的全局信息,结合CNN算法使得模型可以捕获文本局部结构。在SemEval-2017 Task 5的任务数据集上进行对比实验,结果表明,该模型的文本情感分析性能优于MA、DLMA等模型,运行效率相对ELSTM、EGRU等模型也具有较大优势。本文模型仅针对文本句子级别进行情感分析,下一步将结合文本Aspect特征实现更细粒度的情感分析。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
数学物理学报(2017年5期)2017-11-23 07:51:31
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
电视技术(2014年19期)2014-03-11 15:38:20
