
噪声下自闭症儿童视听双通道言语知觉特征*
2020-08-18 02:22杜晓新刘巧云
应用心理学 2020年3期
刘 敏 杜晓新 刘巧云
(华东师范大学教育康复学系,上海 200062)
1 引 言
Massaro(1986)提出言语知觉的过程需要视听双通道的资源。视听双通道言语知觉(audiovisual speech perception)是指在与他人面对面交流时,个体会整合听觉与视觉信息进行言语理解,这是一种多感官整合过程,即视听整合(audiovisual integration)。其中听觉信息(auditory speech)指说话者的声音,而视觉信息(visual speech)主要包含说话者的面部表情、颈部和构音器官(下颌、唇、舌)的运动部位和方式。虽然听觉信息是我们日常言语知觉的主要信息来源,但是视觉信息对日常社交沟通的影响也是不可忽视的。视觉言语信息可以帮助减少听觉单通道信息可能引起的歧义,同时在日常存在噪音的沟通环境中可以降低遇到的困难,使言语知觉更加清晰可靠。然而自闭症儿童在社交沟通方面存在持续性缺陷,同时研究也发现他们在感知觉加工上存在多通道信息整合困难的问题,那么在涉及视听整合的视听双通道言语知觉能力上自闭症儿童的表现如何,是否会影响他们的沟通能力呢?
McGurk效应是目前视听言语知觉的主要研究范式,McGurk效应是一种典型的视听整合现象,指当同时向被试呈现特定的视觉刺激和听觉刺激时,被试会感知到完全不同于任何一个感知通道的言语信息(如视觉刺激为口型ga,听觉刺激为声音ba,被试会感知到da)。它反映了视觉言语信息对言语知觉的影响,目前认为可以将McGurk效应的强度作为双通道整合的强度指标。
无论是在安静环境(Williams,2004;Mongillo,2008;Iarocci,2010;Bebko,2014)还是在噪声环境下,大部分的研究结果都支持自闭症儿童的视听言语知觉要弱于普通儿童。Stevenson(2013)发现6~12岁的自闭症儿童和普通儿童的视听言语加工没有差异,但是在13岁以后两组之间差异显著,普通儿童表现出随年龄增长的趋势;Ross(2015)发现不同信噪比下,自闭症儿童在纯听、纯视和视听一致下的言语知觉表现要低于普通儿童,视听一致时的视觉增益也要低于普通儿童;Irwin(2009,2011)发现即使两组儿童注视面孔的时间没有差异,自闭症组的视觉增益仍然要显著地落后于普通儿童。Foss-Feig(2009)和Woynaroski(2013)则发现自闭症儿童的McGurk效应强度与普通儿童没有显著差异,而Taylor,Isaac和Milne(2010)以及Foxe(2015)分别在安静和噪声环境下发现他们的发展速度比较快,在高年龄段时已经追赶上普通儿童。王玉珏(2017)发现汉语为母语的自闭症谱系障碍儿童在纯听和视听一致刺激模式下的言语辨识成绩显著低于普通儿童,但是两类儿童的视听整合能力差异不显著。
研究发现McGurk效应存在刺激材料的差异性,Strophal(2016)发现12个视听不一致音节引起的McGurk效应强度不同,这与Jiang & Bernstein(2011)、Mallick(2015)的研究结果一致;Green(1988)发现元音材料引起的McGurk效应大小存在差异,从强到弱分别是i、a、u。这使得我们在进行相关研究时需对实验材料进行筛选。虽然王玉珏(2017)的研究中根据汉语的语音结构特征和最小音位对比编制了材料,但是没有考虑到刺激材料的差异性。其次我们日常所处的沟通环境存在许多的噪声,无论是在社区情景还是集体授课情景,而国内尚未有探索噪声环境下自闭症儿童视听双通道言语知觉特征的相关研究。所以,本研究拟在筛选汉语体系中有效的McGurk效应实验材料基础上,探索噪声下自闭症儿童视听双通道言语知觉的特征。
2 研究方法
2.1 研究对象
实验组为30名自闭症儿童,6~12岁的儿童18名,13~16岁的儿童12名,男25名,女5名,平均年龄为11.35±2.86岁,所有儿童均持有上海市相关医院诊断。研究人员采用DSM-V的诊断标准和儿童自闭症评定量表(Childhood Autism Rating Scale,CARS)对其进行汇聚式评估,均符合DSM-V的相关诊断标准,CARS平均得分为34.80±8.30。对照组为30名与实验组生理年龄和性别相匹配的普通儿童,平均年龄为11.38±2.80岁。两组被试的视力或矫正视力正常,听力正常。同时采用汉语构音语音能力评估表对所有被试的构音语音能力进行主观评估已排除言语构音障碍。
2.2 实验材料
2.2.1 实验材料的编制
McGurk效应的实验材料通常为一对辅音不同、元音相同的音节,且辅音的发音方式相同,只是发音部位不同。本研究辅音选择相同方式(塞音)不同发音部位的六个声母,其中b、p为唇音,d、t为舌尖音,g、k为舌根音;元音选择相同结构不同开口的单韵母,其中a为开口呼,i为齐齿呼,u为合口呼。视听不一致下一共包含72个实验材料,按照辅音的不同发音部位可以分为六个类别:听(唇音)+视(舌尖音),听(舌尖音)+视(唇音),听(唇音)+视(舌根音),听(舌根音)+视(唇音),听(舌尖音)+视(舌根音),听(舌根音)+视(舌尖音)。
使用SONY HDR-XR160数码摄录一体机和ZOOM H4NEXT录音设备进行录像和录音。一名基频正常(约260Hz)、普通话水平为二级甲等的22岁女性在标准隔音室录制音节。分别用Adobe Audition和Adobe Premiere对录音和录像材料进行剪辑和处理。每个言语刺激都是从静止的表情开始,然后发音,到恢复静止表情结束,时长约3秒,视觉言语和听觉言语的时间起始点相同,以保证口形与声音相对应。
2.2.2 实验材料的筛选
本研究选择6-12岁、12~18岁和20~30岁的普通儿童和成人各30名进行实验材料的筛选。视听不一致下72个实验材料每个重复2次,共计144个试次,使用Eprime 2.0呈现实验材料,要求被试报告听到的内容,考察不同材料引起McGurk效应强度差异。方差分析结果显示,六个类别的刺激材料主效应显著,F(5,74)=100.56,p<0.001,η2=0.872,BF10=6.155e+107(其为当前数据模式下,备择假设H1相比虚无假设H0成立的可能性,下同;吴凡,顾全,施壮华,高在峰,&沈模卫,2018),其中听(唇音)+视(舌尖音)、听(唇音)+视(舌根音)两组刺激材料所引起的McGurk效应比率要显著高于其他组。Stropahl(2016)的研究发现大部分刺激材料融合反应频率在40%~60%之间,Mallick(2015)发现引发McGurk效应的平均比率在50%。所以从以上两个类别的材料中,以引发McGurk效应比率大于或等于60%为原则进行筛选材料,筛选出六对符合要求的实验材料:ba-ga、ba-ka、ba-ta、pa-da、pa-ga、pa-ka(具体结果见图1)。
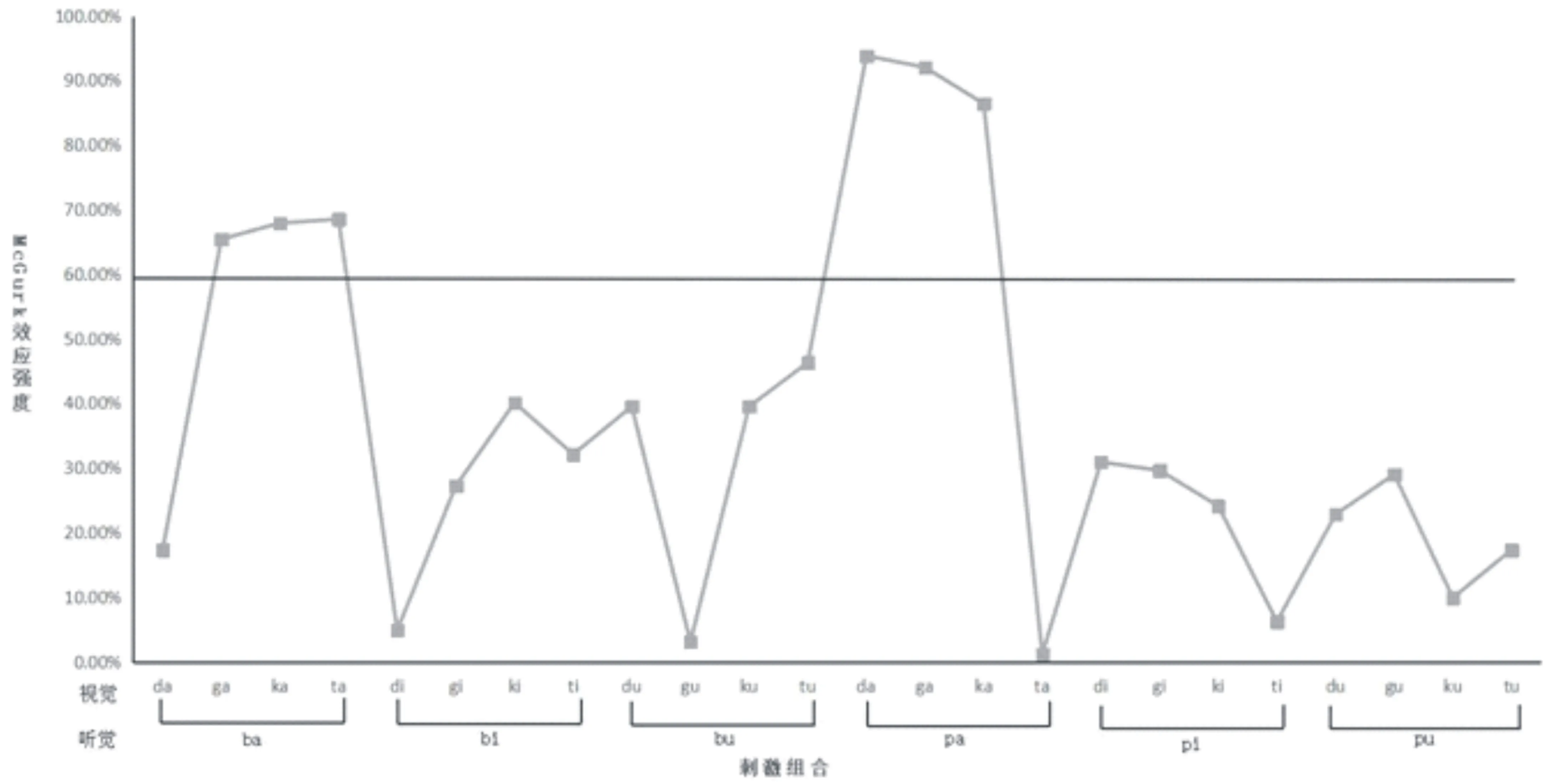
图1 不同刺激组合McGurk效应强度
结合以上筛选结果,本研究中纯听和视听一致刺激模式下包含ba、da、ga、pa、ta、ka六个实验材料,视听不一致刺激模式下包含ba-ga、ba-ka、ba-ta、pa-da、pa-ga、pa-ka六个实验材料。所有刺激材料输出强度为60dB SPL,除无噪声条件外,使用Adobe Audition添加5种不同水平的粉红噪声(57,60,63,66,69dB SPL),噪声与视频的起始时间相同。
2.3 实验过程
实验在隔声室中进行。被试坐在电脑正前方,双眼与屏幕齐平,距离约70cm。主试用Eprime 2.0呈现上述言语刺激材料,要求被试分别在三种言语刺激模式下说出自己听到的声音。正式实验之前,通过屏幕呈现和言语的方式告知被试指导语,然后依次呈现三个言语刺激材料,在被试理解实验要求后进入正式实验。正式实验时,先在屏幕正中心呈现注视点“+”,800ms后自动转到刺激界面。在纯听刺激模式下,刺激界面为白屏,只呈现一个音节的声音;在视听刺激模式下,刺激界面呈现说话者完整的面孔,同时播放声音(与发音口形一致或者不一致)。被试报告后随即进入下一个试次,若被试在5秒内无反应,主试播放下一个试次。
实验程序按照纯听、视听一致和视听不一致的固定顺序进行,每种刺激模式下刺激材料随机呈现。经过添加不同水平的噪声,三种刺激模式下各包含36个实验材料,每个材料重复2次,实验共有216个试次。
3 实验结果
3.1 两种言语刺激模式下的言语辨识率
两组被试在纯听、视听一致两种言语刺激模式下言语辨识率的描述性统计结果见表1。

表1 两组儿童听觉辨识率描述性分析
纯听刺激模式下进行2(组别:自闭症儿童vs普通儿童)×2(年龄:6~12岁vs13~16岁)×6(信噪比:NN,-3,0,+3,+6,+9)重复测量方差分析结果显示:组别主效应显著,F(1,56)=17.371,p<0.001,η2=0.698,BF10=192.801,普通儿童的言语辨识率显著高于自闭症儿童;信噪比主效应显著,F(5,52)=54.057,p<0.001,η2=0.844,BF10=2.349e+38,随着听觉噪声水平的增大,言语辨识率会越低,即信噪比越小,言语辨识率越低;年龄主效应显著,F(1,56)=4.819,p=0.032,η2=0.745,BF10=1.375,13~16岁儿童言语辨识率显著高于6~12岁儿童。组别和年龄交互效应不显著,F(1,56)=0.001,p=0.975,η2=0.001,BF10=0.263;组别和信噪比交互效应不显著,F(5,54)=0.169,p=0.973,η2=0.003,BF10=0.015;信噪比和年龄交互效应不显著,F(5,52)=0.496,p=0.778,η2=0.015,BF10=0.067;组别、年龄和信噪比交互效应不显著,F(5,52)=1.538,p=0.194,η2=0.024,BF10=0.301。
视听一致刺激模式下进行2(组别:自闭症儿童vs普通儿童)×2(年龄:6~12岁vs13~16岁)×6(信噪比:NN,-3,0,+3,+6,+9)重复测量方差分析结果显示:组别主效应显著,F(1,56)=45.900,p<0.001,η2=0.713,BF10=3.816e+6,普通儿童言语辨识率显著高于自闭症儿童;信噪比主效应显著,F(5,52)=36.457,p<0.001,η2=0.787,BF10=1.357e+29,随着听觉噪声水平的增大,言语辨识率会越低;年龄主效应边缘显著,F(1,56)=45.900,p=0.052,η2=0.367,BF10=1.151,13~16岁儿童的言语辨识率要高于6~12儿童。组别和年龄交互效应不显著,F(1,56)=3.721,p=0.059,η2=0.062,BF10=1.405;组别和信噪比交互效应不显著,F(5,52)=0.507,p=0.770,η2=0.046,BF10=0.024;年龄和信噪比交互效应不显著,F(5,52)=0.745,p=0.594,η2=0.067,BF10=0.044;组别、年龄和信噪比交互效应不显著,F(5,52)=0.892,p=0.493,η2=0.079,BF10=0.112。
为了进一步考察视听一致刺激模式下视觉言语的影响,我们运用[视听一致准确率-纯听准确率]的公式计算其视觉增益。2(组别:自闭症儿童vs普通儿童)×6(信噪比:NN,-3,0,+3,+6,+9)重复测量方差分析结果显示:组别主效应显著,F(1,58)=14.900,p<0.001,η2=0.655,BF10=26.588,普通儿童组的视觉增益显著高于自闭症儿童;信噪比主效应不显著,F(5,54)=1.831,p=1.222,η2=0.145,BF10=0.187;组别和信噪比交互效应不显著,F(5,54)=0.151,p=0.979,η2=0.014,BF10=0.016。
为了比较两组儿童在不同刺激模式下言语辨识的差异,我们以儿童类型和言语刺激模式为自变量,对纯听和视听一致下的言语辨识率进行2×2方差分析。儿童类型主效应显著,F(1,58)=40.438,p<0.001,η2=0.611,BF10=320237.756,自闭症儿童组言语辨识率显著低于普通儿童组;言语刺激模式主效应显著,F(1,58)=102.801,p<0.001,η2=0.639,BF10=1.559e+10,视听一致下的言语辨识率显著高于纯听刺激模式。
3.2 视听不一致下McGurk效应强度
对自闭症儿童和普通儿童在视听不一致刺激模式下的McGurk效应强度进行描述性分析和方差分析,从而判断各组儿童受视觉影响的大小。描述性统计结果见表2。

表2 两组儿童McGurk效应强度描述性分析
对两组儿童在视听不一致模式下的McGurk效应强度进行2×2×6的方差分析。方差分析结果显示:组别主效应显著,F(1,56)=5.366,p=0.024,η2=0.537,BF10=3.773,普通儿童的McGurk效应强度显著强于自闭症儿童;信噪比主效应显著,F(5,52)=6.721,p<0.001,η2=0.685,BF10=127.976,不同信噪比下McGurk效应强度大小顺序分别是:-6、-9、-3、NN、+3、0;年龄主效应不显著,F(1,56)=1.712,p=0.196,η2=0.030,BF10=0.767。组别和信噪比交互效应不显著,F(5,52)=0.328,p=0.894,η2=0.002,BF10=0.024;年龄和信噪比交互效应不显著,F(5,52)=1.378,p=0.248,η2=0.004,BF10=0.042;组别和年龄交互效应不显著,F(1,56)=0.187,p=0.667,η2=0.003,BF10=0.410;组别、年龄和信噪比交互效应不显著,F(5,52)=0.142,p=0.982,η2=0.003,BF10=0.027。
4 讨 论
本研究运用McGurk效应研究范式,在筛选McGurk效应实验材料的基础上,比较不同噪声水平下自闭症儿童与普通儿童在纯听、视听一致下的言语辨识能力,通过视听一致下的视觉增益与视听不一致下的McGurk效应强度来探究自闭症儿童视听双通道言语知觉特征。
噪声环境中,自闭症儿童在纯听和视听一致刺激模式下的言语辨识正确率都显著低于普通儿童,表明自闭症儿童单通道和双通道言语知觉能力存在一定缺陷。同时,自闭症儿童在视听一致下视觉增益以及视听不一致下McGurk效应强度都要显著低于普通儿童,这说明自闭症儿童在言语感知过程中视觉信息对听觉信息的影响比普通儿童小,即其视听整合能力要低于普通儿童。这与国外的大部分研究结果比较一致。Mongillo(2008)的实验中包含不同视听整合程度的任务,结果发现自闭症儿童只在包含人类刺激的视听整合任务(McGurk实验任务、性别声音一致性判断任务)上与普通儿童存在显著性差异,研究证实自闭症儿童在言语知觉过程中较少受视觉信息的影响,这可能是由于他们普遍很少对面孔产生注意。其他一些研究中发现即使对自闭症儿童注视面孔进行控制,但其受到的视觉影响仍然与普通儿童存在差异。这可能表明自闭症儿童对面孔采用的视觉加工方式与普通儿童有差异。Eskelund(2015)研究证实视听双通道言语知觉需要的不仅是面孔的局部信息,更需要整体的构型信息。然而大部分研究却发现自闭症儿童在面孔加工时表现出局部加工优势和整体局部加工转换障碍的特点。需要进一步的研究探索自闭症儿童的视听双通道言语知觉是否受到其视觉加工方式的影响。
两组儿童在纯听和视听一致条件下言语辨识率表现出明显的随年龄增长而发展的趋势,13~16岁组儿童的言语辨识率都显著高于6~12岁组儿童,但是年龄和组别的交互效应不显著,表明无论是6~12岁还是13~16岁,自闭症儿童言语识别率都要显著低于普通儿童。但是在视听不一致条件下,虽然两组被试中13~16岁儿童的McGurk效应强度都高于6~12岁,但是两个年龄段之间的差异不显著,同样无论是高年龄段还是低年龄段,自闭症儿童的McGurk效应强度都低于普通儿童。这与Foxe(2015)的研究结果并不一致,他们发现13岁以后两组儿童的差异已经不显著。但是由于本研究中两个年龄段被试数量较少,且两组被试人数不一致,后续需要进一步扩大被试数量探讨自闭症儿童视听双通道言语知觉的发展趋势。
本研究在无噪音以及五种不同水平的粉红噪音条件下进行,结果发现在纯听和视听一致刺激模式下,听觉噪声水平越大,言语辨识准确率越低,这与之前的研究结果一致。所以之前的理念认为听觉噪声越大,言语知觉对视觉的依赖就越大,Hirst(2018)对普通儿童和成人的研究中发现听觉噪声越大,视觉对言语知觉的影响就会增大,会使得McGurk效应的强度增加。但是本研究中不同信噪水平对视听不一致下McGurk效应强度影响却表现出不同趋势,当信噪比为-6时McGurk效应强度最大,此时视觉言语信息对听觉言语信息的影响最佳。这与Ross(2015)和Barutchu(2010)的研究结果一致,他们的研究也发现中等强度的听觉噪声会更好地促进多感官整合,会获得最佳的视觉增益,噪声水平对视听双通道言语知觉的影响呈现倒U型趋势。
虽然自闭症儿童的单通道和双通道言语知觉都显著低于普通儿童,但是可以发现他们在视听一致下的言语辨识正确率还是要显著高于纯听下的正确率,只是其利用视觉言语信息的能力较低。Irwin(2015)通过iPad软件对自闭症儿童在噪声背景下的视听言语知觉能力进行干预,发现自闭症儿童对名词、动词和形容词的识别都得到了有效提升。结合本研究结果,在对自闭症儿童社交沟通能力的康复训练中,特别是言语知觉的干预中可以利用视听一致的刺激模式,提高他们视听双通道言语知觉能力,发挥视听双通道感知、理解言语信息的优势,同时可以设置适当的背景噪声以帮助他们将习得能力顺利迁移至日常噪声环境中。
猜你喜欢
现代仪器与医疗(2022年1期)2022-04-19
北京理工大学学报(2021年12期)2022-01-13
文萃报·周五版(2021年14期)2021-06-08
科教新报(2021年14期)2021-05-11
就业与保障(2021年23期)2021-04-06
舰船电子对抗(2020年1期)2020-04-27
北京航空航天大学学报(2019年9期)2019-10-26
海峡姐妹(2018年5期)2018-05-14
海峡姐妹(2017年5期)2017-06-05
电脑爱好者(2015年22期)2015-09-10
