
基于图嵌入的用户加权Slope One算法
2020-08-17 13:59:52钟志松彭清桦吴广潮
计算机与现代化 2020年8期
钟志松,彭清桦,吴广潮
(华南理工大学数学学院,广东 广州 510640)
0 引 言
在当前信息量激增的大数据环境下,如何快速准确地从繁杂的海量商品列表数据中定位到每个用户的兴趣,对其进行推荐已经成为推荐系统面临的主要挑战。早在1992年Goldberg等[1]提出了协同过滤推荐的思想,该思想在电商平台的实践中成功解决了用户的兴趣预测问题。后来众多基于该算法思想进行改进协同过滤的推荐算法[2-3]都获得了良好的效果,例如Lemire等[4]提出的Slope One算法,该算法得到了广泛应用。
Slope One算法在用户没有表现出明确需求的情况下,能根据用户已有评分,预测该用户对项目集的缺失评分,得出用户对项目的偏好从而进行个性化推荐,在实际的推荐应用场景中表现出了操作简单和可解释性强的优点。然而由于传统的Slope One算法仅是利用评分记录通过简单的线性函数来获取项目间的相似度[5],若评分矩阵稀疏则会导致计算的预测评分偏差大,推荐精度降低,而伴随着数据规模的增长,数据稀疏性、算法的可扩展性问题逐渐凸显出来。
对于传统Slope One算法推荐精度低的问题,众多学者进行了探索研究。吴逸明[6]针对Slope One算法没有充分考虑用户相似度和项目相似度的缺点,提出了一种新的算法对其进行改善,该算法将用户相似度和项目相似度作为加权因子对预测结果进行处理,结果表明推荐准度更高,收敛速度也更快。同样地,田松瑞[7]基于项目的Slope One算法基础上结合基于用户的协同过滤算法,提出了混合推荐算法US-Slope One,该算法通过用户相似度对评分偏差计算公式进行了修正,提高了推荐准确率和推荐质量。文献[8-12]提出基于项目(或用户)聚类的算法,通过对项目(或用户)按照评分或特征向量进行聚类以优化目标项目的近邻选择,解决了数据稀疏带来的近邻选择随机问题,一定程度上提高了预测的准确性。王吉源等[13]和张飞等[14]结合KNN近邻过滤技术,引入用户特征属性并以最小权重相似度生成用户近邻集合产生预测评分,但是无法反映用户兴趣的时间变换特性。
另外,针对传统Slope One算法在大数据场景下算法面临的可扩展性问题,文献[15-17]在Hadoop或Saprk平台上结合聚类和Slope One算法进行混合推荐,结果表明相对传统单机算法,分布式混合推荐算法在保证推荐准度的前提下,运行性能得到了极大的提升,缓解了算法扩展性问题。
在上述现有对Slope One推荐算法研究成果的基础上,针对现有算法在计算用户相似度过程中出现的没有考虑用户不同时间点兴趣转移和用户二度近邻用户兴趣影响带来的相似度计算不准确的问题,本文提出一种基于图嵌入的用户加权Slope One算法,结合图嵌入算法、Slope One算法和Canopy聚类这3个算法模块,通过用户加权图网络生成用户的近邻序列,计算得到用户特征向量,在此向量空间对用户利用Canopy聚类后进行类内加权Slope One推荐,并在Spark平台上部署以提高算法执行效率。
1 相关研究
1.1 图嵌入(Graph Embedding)算法
图是一种高度抽象但灵活的拓扑结构,图的节点可以用于表示大部分现实世界中可理解的实体,实体之间的关系则通过节点之间的边来体现[18],如社交关系、搜索行为和购买行为等。一般而言,基于用户协同过滤推荐就是在用户购买行为的基础上,通过将购买过相同项目的用户视为“近邻用户”进行偏好项目推荐。事实上,评分矩阵表现在图结构上能够反映更多的潜在信息,如图1所示。

图1 由用户行为序列生成的近邻用户关系图
用户与项目的评分记录在用户-项目集上建立了一个二分图,不同用户与同一项目评分的记录刻画了用户间相似度。借助二分图的传播性,可以发掘一个用户直接和间接的兴趣相似用户,从而更准确地得出用户特征,这就是图嵌入的思想。基于这种思想,2014年Perozzi等[19]提出了DeepWalk算法。
该算法的思想是在由项目作为节点组成的图网络结构上进行随机游走产生足够的样本序列,最后利用Skip-gram算法对这些序列样本进行训练,得到项目embedding后的特征向量,过程可视化为图2所示。
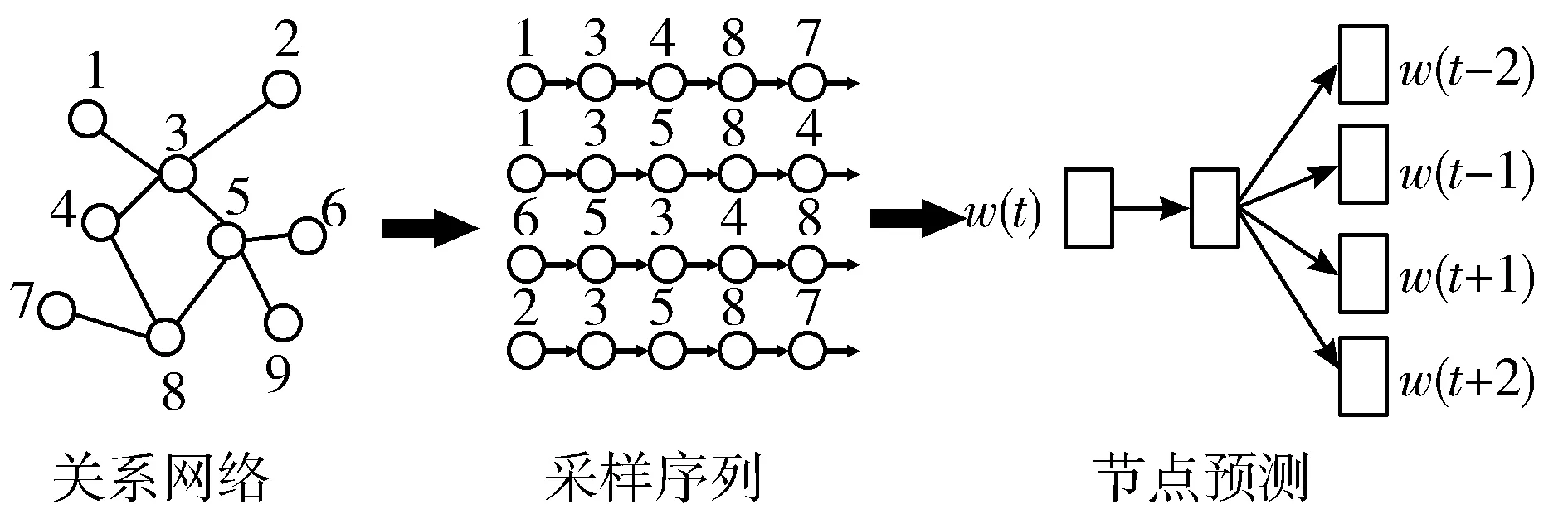
图2 图嵌入算法过程
图嵌入过程中最重要的步骤就是节点间的游走采样规则,不同的采样规则会产生不同的特征空间。被广泛采用的是随机游走采样,然而该方式不适用于大规模的商品网络结构,节点之间的弱关联性使得随机游走的采样方法会生成冷门节点序列,因此文献[18]提出了基于节点间边权比例的采样方法Weight Walk,通过边权控制图游走的方向,使采样往热门节点进行游走的概率尽可能大,生成高置信度的序列样本。节点间游走公式为:
(1)
其中,vi和vj为节点,Mij为节点vi和节点vj之间边的权重,N(vi)为节点vi的近邻节点集合。
1.2 Canopy聚类算法
Canopy算法[20]是为了改进K-means算法在确定聚类中心时不确定性过大的缺陷而提出来的。该算法不需要事先设定聚类数,它能以交叉检验的方式设置阈值T1和T2,通过迭代计算启发式地确定初始较优聚类数目,具有抗噪能力强、收敛速度快的优点,适用于高维、海量数据规模的计算场景。算法流程如下:
输入:用户特征向量集S1、S2(S1=S2),阈值T1,阈值T2
输出:聚类结果集Q
1 while(S1不为空):
2S1中随机选取一个用户u初始化新聚类c
3 求S1中其他用户v到u的距离dist
4 若dist 5 若dist 6 end 7 得到初始化聚类Q 8 while(2次迭代前后Q改变): 9 求S2中用户u到Q中各中心距离dist 10 将u归入dist最小所对应的聚类中心 11 重新计算聚类Qn(求均值) 12Q=Qn 13 End 由上可知,通过Canopy算法“粗”聚类获取的K个聚类中心,可以作为K-means算法的参数输入,能降低聚类中心值选取的盲目性。 Slope One算法的本质思想是一个一元函数w=f(v)+b。假设需要在已知用户u对项目i评分ui的基础上去预测该用户对j的评分uj,则可以通过其他同时对项目i和j有评分的用户评分集进行线性拟合,获取项目i和j之间的偏差devji,进而预测用户对j的评分。算法利用偏差公式(2)计算得到两两项目对的平均评分差: (2) 其中,Sji(χ)为同时对项目j和i有评分行为的用户集,card(Sji(χ))表示用户集中元素的个数。利用公式(3)预测用户u对项目j的评分: (3) 其中,S(u)表示用户u已评分项目集。 但基础Slope One在计算评分差时没有考虑项目间共现次数对结果置信度的影响,因此引入了加权Slope One。该算法认为一个项目与目标项目共现的次数越多,其与目标项目差值对预测的影响因子越大,具体预测公式如下: (4) 其中,cji=card(Sji(χ))。 加权Slope One算法考虑了项目共现次数对评分估计的影响,对评分的预测更加准确。 本文将结合图嵌入算法、Slope One算法和Canopy聚类这3个算法模块来构建用户加权Slope One推荐算法,但是在计算用户相似度的过程中,传统的计算方式往往没有考虑到用户的兴趣会随着时间而发生改变,因此忽略了用户兴趣的时序性特征,会导致推荐结果不够准确。 另外,在对用户进行近邻用户序列采样的时候,如果仅仅是使用随机游走或者按照边的权重游走采样,会导致样本中出现很多不活跃用户或者全是活跃用户的情况,不符合推荐系统多样性、合理性的标准,因此针对上述问题,本文提出以下改进以提升算法效果。 对于用户兴趣时序变化问题,本文算法在计算近邻用户相似度时加入兴趣衰减因子,通过一个函数刻画用户对项目兴趣的衰减。考虑到用户对项目兴趣更像用户的阶段性特征,有别于人对事物的记忆,本文采用相对指数衰减更加平缓且相对Sigmoid函数“厚尾”的反三角衰减函数: (5) 其中,t为时间跨度。同时考虑到不同用户的评分偏好差异,如积极的用户给予的项目评分偏高,因此在作用衰减因子后将对用户评分进行归一化。 另一方面,不同用户对同一项目的评分时间间隔也刻画了用户间相似度,间隔越短代表他们对该项目的兴趣度越相似,因此在计算“共现项目评分”时也使用时间衰减因子,具体定义如下: (6) 其中,tui和tvi分别为用户u和用户v与项目i发生评分的时间点。 本文将根据用户评分构建图:以用户为图节点,用户综合相似度为边权,将对同一项目评分的用户定义为近邻用户。在计算近邻用户间相似度的时候,为确保最后的相似度得分在[0,1]范围,在余弦相似度计算公式的基础上对分母进行变形,最终用户相似度公式如下: (7) 其中,R(u)和R(v)分别表示用户u和用户v的评分项目集,R(u,v)表示用户u和用户v的都有评分的项目集。 为了解决在近邻用户序列采样过程结果随机性大的问题,本文对节点间跳转的规则公式进行重新定义。 首先对每个用户在基于用户评分矩阵建立的用户加权图上进行概率游走,再利用生成的相似度序列训练出用户特征向量,以此刻画用户特征。 以用户u为起点的游走过程为马氏链上k步转移的过程,具体定义如下: (8) (9) 其中Nei(v)为加权图上用户v节点的邻接用户集,u与v不相邻时sim(u,v)定义为0。 由此可知,从用户u转移n步形成的用户节点序列挖掘了用户u在用户加权图上的潜在相似用户。通过将这些序列传入Word2Vec模型中训练,获取隐含层用户特征矩阵,便可实现用户加权图的嵌入。 其具体实现的伪代码描述如下: 输入:用户评分矩阵R;每个用户游走次数num,每次游走步数len。 输出:用户特征向量矩阵Φ。 1)基于R,按照公式(5)~公式(7)、公式(9)生成用户加权图; 2)初始化序列集合L; 3)对用户集中每一个用户u: 4)进行num次游走: 5)从节点u出发; 6)按公式(9)随机选取下一个邻接节点; 7)生成长度为len的节点序列,并加入L; 8)将L传入Word2Vec模型训练,获得隐含层矩阵Φ。 在计算过程中涉及大量的数据迭代,算法面临着磁盘的IO和内存的不足甚至溢出的风险,对推荐模型的执行效率造成了极大影响[21]。因此,为了解决算法的可扩展问题,本文在Spark平台上面部署算法,对数据进行并行化计算,提高算法性能。 综上,本文实验大致流程如下: 1)对原始数据的评分加入兴趣衰减因子进行处理,计算近邻用户相似度作为边的权重; 2)将用户近邻关系以图的方式表达,通过概率随机游走方式对路径进行采样,得到的序列样本输入Word2Vec模型,预测用户隐特征向量; 3)根据用户隐特征向量进行Canopy聚类,在类内结合用户相似度使用加权Slope One算法预测推荐,获取最终的推荐结果。 以上推荐模型的综合框架可视化流程如图3所示。 图3 推荐流程图 本文的实验平台所需的Spark集群环境在3台相同型号的服务器上面搭建,每台服务器操作系统为Linux,分别有10核CPU和256 GB内存,集群使用框架版本分别Spark 2.4.3,Scala 2.11.12,Java _1.8.0_221。 实验采用公开数据集MovieLens中的ml-100k和2016年在Kaggle竞赛平台上公开的Retailrocket电子商务网站行为数据集[22]的部分数据,2个数据集的具体统计概况见表1。 表1 实验数据概况 在实验过程中,对数据的预处理操作为:仅保留每个用户对同一项目评分最高的评分记录,将数据集划分为训练集和测试集;引入变量r,表示数据集上训练集占全数据集的百分比,例如r=0.8表示选取全数据集中80%的数据作为训练集,其余作为测试集。 为了同时考量算法对用户兴趣偏好的预测准确率及在预测准确的项目列表中对评分的预测偏差,本文使用平均绝对误差(Mean Absolute Error, MAE)作为指标,在特定长度的推荐结果列表中考量算法的效果,MAE越小,代表算法的推荐质量越高。 MAE具体定义如下: (10) 其中,χ′为测试集数据,rui和pui分别表示χ′中用户u对项目i的评分。 采用ml-100k的数据集,假定数据预处理时不融入兴趣衰减因子,设推荐列表长度为30,将阈值T1分别设为15、20和25,T2从2开始以1为步长依次递增到11,得到的MAE结果如图4所示。 图4 阈值组合对应的MAE变化图 由图4可以看出,在设定阈值T1的前提下,结果的MAE会随着阈值T2的增加先降低后升高,这与用户间距离有关,T2在一定范围内的增加首先会使得更多相似的用户归并到同一类里面,从而使得类内推荐结果更加准确,但是后来过大的T2让更多原本不相邻的用户聚到了同一类,直接影响了推荐准度,因而当T2>9后MAE提高了。因此根据图4的结果,考虑到聚类数对算法执行性能和推荐准确度的影响,最终采用的阈值组合为T1=20,T2=10。 为了检验本文算法EWSO的有效性,本文将EWSO与传统的加权Slope One算法WSO、基于项目相似度的加权Slope One算法IWSO[22]、基于聚类的Slope One算法CWSO[23]在ml-100k数据集上进行实验,取r=0.8,随机划分并进行10次实验,利用MAE进行评估,具体实验结果如表2所示。 表2 不同算法在ml-100k数据集上的MAE效果 从表2中可以看出,几种不同算法的MAE都是随着k值的增大而减小,其中IWSO与CWSO的算法效果相似,后者因为多了项目聚类的步骤,因此表现更好;当k≤30时IWSO与CWSO的效果要好于本文算法EWSO的效果;当k>30时,EWSO效果要优于其他算法。 为了进一步挖掘本文算法的有效性,将上述4种算法在不同k值下面的MAE值进行可视化,如图5所示。 图5 4种算法不同k值的MAE效果图 由图5可知,相比于简单的结合项目相似度的IWSO和在此基础上用聚类思想提升推荐准确度的CWSO,本文算法EWSO通过图游走融入了用户相似度的聚类推荐方式,在k值增大的时候更加有效。从图中还可以看出,当k>70后上述算法的MAE趋向稳定,EWSO效果相对更优。 首先,为了说明时间衰减因子对降低MAE的作用,在Retail数据集上进行了4组实验,对比了算法在加入衰减因子前后的效果。因为该数据集中没有物品特征向量,无法进行CWSO的项目相似度聚类,故仅对IWSO和EWSO进行了试验。 实验分4组进行,每组实验随机抽取N个用户10次,r=0.8,N∈{500,600,700,800}。 具体结果如图6所示。 图6 IWSO和EWSO对WSO的MAE提升百分比(有无时间衰减情况下的对比) 可以看出,在各实验组上,对于IWSO和EWSO,加入时间衰减因子后相对WSO的提升MAE百分比都要高于未考虑衰减因子时的提升百分比。同时随着数据量的增加,衰减因子的作用都稍有提升。另外,IWSO在该稀疏数据集上对MAE的提升效果并不理想,这是由于IWSO中根据Pearson相似度大于0的条件过滤掉了一些信息,使得数据更加稀疏,从而导致计算结果变差,但是作用时间衰减因子后,IWSO也能对提升MAE起到一定的效果(见700、800用户组结果)。由此可知衰减因子对降低MAE有积极作用。 所以,本文对EWSO融合时间衰减因子在稀疏数据集上进行实验,从而说明EWSO的鲁棒性。 具体实验结果如图7所示。 图7 考虑时间衰减时EWSO与WSO在Retailrocket部分数据集各用户组中实验结果 从图7中看出,EWSO在4组实验上都对MAE有10%以上的提升,而且随着数据量增加(用户数增多),EWSO的优势愈发明显,提升MAE百分比也随之增加,该结果与有效性对比中的结论——随k值增加,EWSO效果越来越好进而稳定地优于其他算法——也是吻合的。可见,EWSO算法对稀疏数据有一定的适应能力,能在一定程度上缓解数据稀疏的问题;同时,EWSO能在隐式评分数据集上对提升评分预测准确率有较WSO更好的效果。 为优化算法性能,基于Spark框架实现了本文算法,并在Retailrocket的4组用户数据上对比了不同处理线程数下EWSO的运行时间。具体结果如图8所示。 图8 不同用户组上运行时间随处理线程数变化趋势图 由图8可知,随着处理线程数的增加,算法运行时间逐步降低至平稳,20个线程资源的运行效率远比4个线程资源运行效率高。而在本文实验环境中,每个节点的executor包含了4个线程,这直接说明了Spark集群节点数的增加可以有效提升算法运行速度,这也体现了Spark平台实现推荐算法快速、可拓展的优势。 本文主要提出了图嵌入的用户相似度加权图的聚类Slope One推荐算法,在融合了时间衰减因子的加权图中游走生成用户近邻序列,并借鉴Word2Vec思想训练出用户特征向量,对向量进行Canopy聚类,最后在类内进行加权Slope One推荐,有效地提升了Slope One在显式、隐式评分数据集上预测准确率,也提高了算法对稀疏评分矩阵的适应能力。另一方面,本文算法基于Spark分布式框架实现,提高了Slope One算法的拓展性和运行速度。下一步工作将优化算法运行时耗费内存方面展开,进一步提升算法鲁棒性。1.3 加权Slope One算法
2 基于图嵌入的加权Slope One算法
2.1 兴趣衰减因子
2.2 近邻节点边的权重
2.3 概率图游走模型
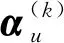
2.4 基于图嵌入的并行化用户加权Slope One推荐模型

3 实验与分析
3.1 实验环境与数据

3.2 评价指标选取
3.3 聚类阈值探究

3.4 算法有效性对比


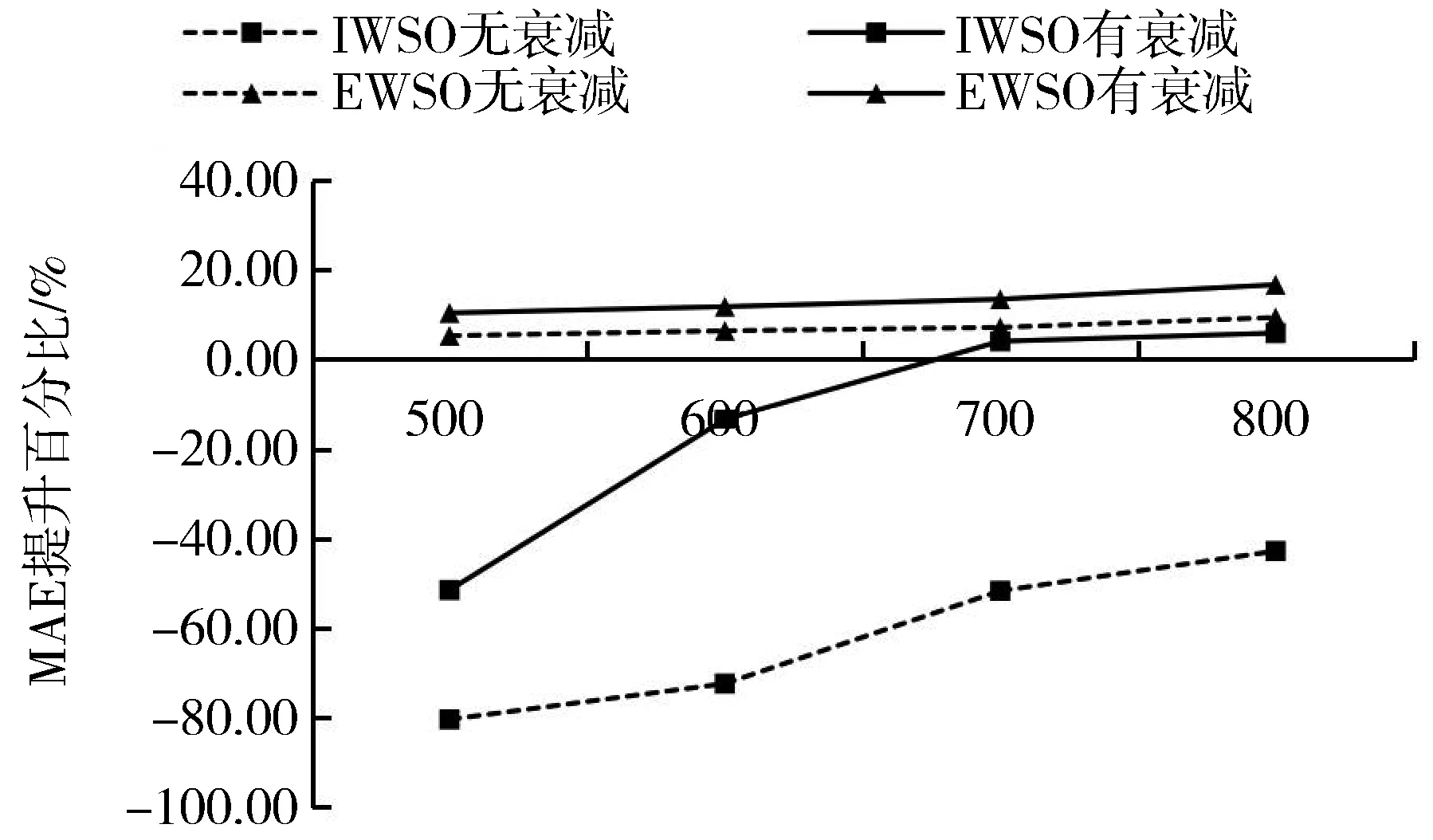
3.5 算法鲁棒性对比

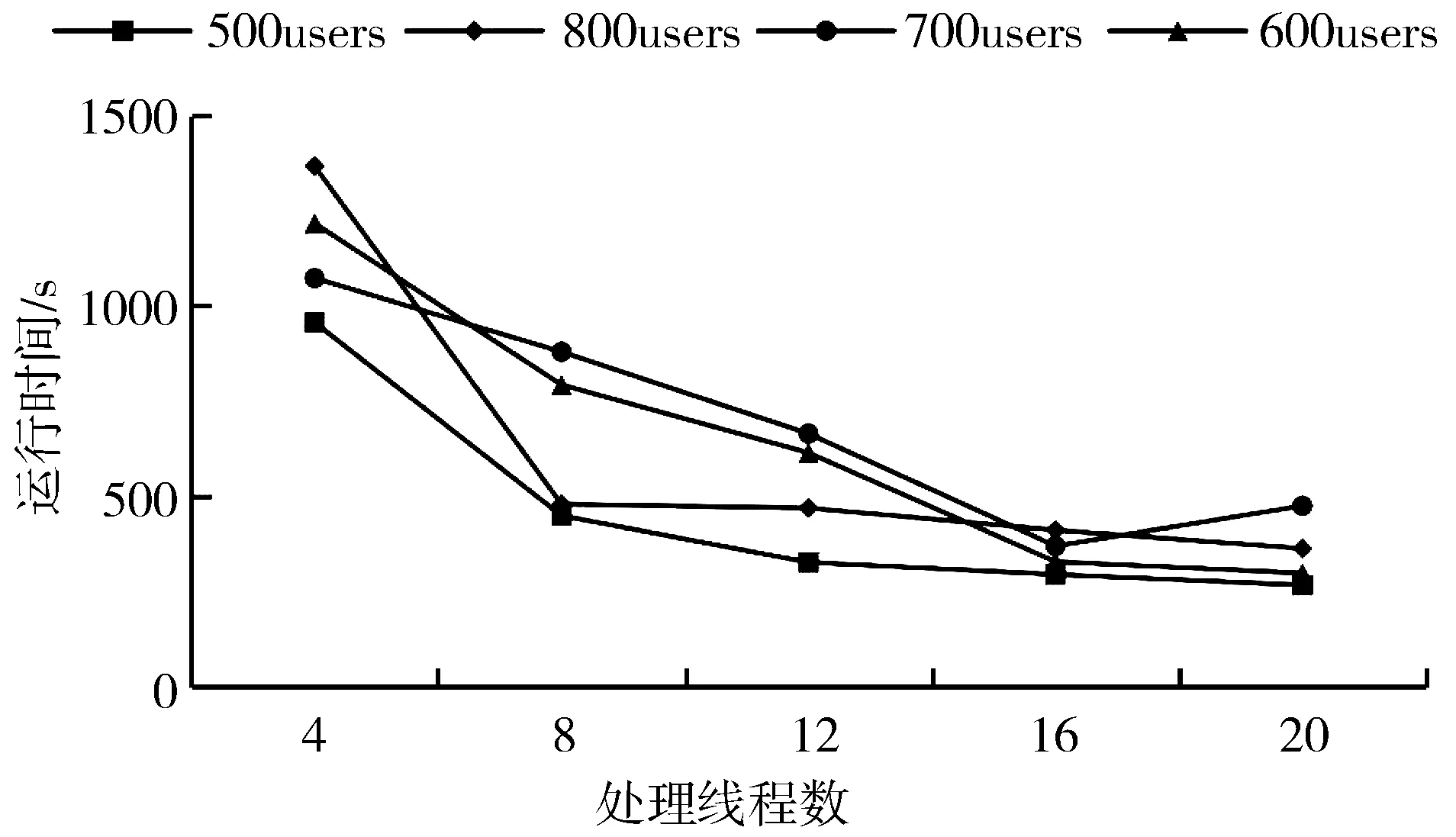
3.6 本文算法在Spark框架下的运行效率
4 结束语
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54机械工业标准化与质量(2022年6期)2022-08-12 02:07:42保定学院学报(2022年2期)2022-04-07 02:26:50国际眼科杂志(2021年9期)2021-09-15 03:24:42装备制造技术(2020年2期)2020-12-14 03:09:16许昌学院学报(2018年4期)2018-05-02 12:27:37电子测试(2017年15期)2017-12-18 07:19:27中华建设(2017年1期)2017-06-07 02:56:14智能系统学报(2015年4期)2015-12-27 09:38:39中国卫生(2015年12期)2015-11-10 05:13:34
