
基于卷积神经网络的蜜蜂采集花粉行为的识别方法
2020-08-17 10:19王立扬
河南农业科学 2020年8期
薛 勇,王立扬,张 瑜,沈 群,4
(1.中国农业大学 食品科学与营养工程学院,北京 100083; 2.中国农业大学 国家果蔬加工工程技术研究中心,北京 100083; 3.中国农业大学 信息与电气工程学院,北京 100083; 4.中国农业大学 植物蛋白与谷类加工北京市重点实验室,北京 100083)
蜜蜂是自然生态系统中最重要的单一传粉媒介物种,人们利用蜜蜂为农作物等传授花粉,从而大幅提高粮食产量。近年来,由于生存环境遭破坏及病虫害威胁等原因导致蜜蜂数量不断减少,出现“蜜蜂危机”[1],继而可能影响农作物的产量和质量。花粉和花蜜是蜜蜂的主要食物来源,蜜蜂在采集花粉和花蜜时,携粉足会收集花粉并形成花粉团。其中,花粉的采集与蜜蜂的授粉效率密切相关,同时蜜蜂所携带的花粉团是一种高蛋白质和低脂肪的营养保健食品。因此,实时监测蜜蜂觅食行为,不仅有助于评估当地农作物授粉状况[2],也有助于及时采取措施提高蜜蜂产品的产量和品质,增加蜜蜂养殖产业的附加值。近年来,随着精准养蜂(Precise beekeeping,PB)概念提出,如何利用现代技术对蜜蜂行为(尤其觅食行为)进行监测与分析成为未来智能农业发展导向之一[3]。STREIT等[4]提出基于射频识别(Radio frequency identification,RFID)对昆虫单一个体跟踪,较早实现昆虫监测,但强电磁波具有侵入性,易对监测对象造成影响。最近,计算机视觉(Computer vision,CV)在监测动物行为方面研究较为深入,如肖德琴等[5]设计基于视频追踪的家猪运动监测方法,劳凤丹等[6]借助机器视觉对蛋鸡行为进行识别,取得良好效果。王俊等[7]构建最优二叉决策树分类模型对奶牛运动行为进行分类识别,陈彩文等[8]利用灰度差分统计法、灰度共生矩阵和高斯马尔科夫随机场模型提取鱼群纹理特征,最后利用支持向量机(Support vector machine,SVM)对鱼群图像进行分类识别,降维后达到0.935 0的识别准确率。但有关蜜蜂行为的图像识别却鲜有报道[9],国外也仅有少量研究[10-13]。
卷积神经网络(Convolution neural network,CNN)是一种深度前馈人工神经网络,其人工神经元可以响应一部分覆盖范围内的单元,对于大型图像处理有出色表现。自20世纪末LeNet-5的诞生[14],到2012年ALEX等凭借AlexNet获得当年ImageNet比赛(大规模视觉识别挑战赛)冠军,再到后来深层卷积神经网络(DCNN)的出现促进医疗诊断等领域的发展[15]。利用CNN模型识别蜜蜂觅食行为,监测蜜蜂个体情况对动物行为进行研究是一种新颖的思路,RODRIGUEZ等[16]借助基线分类算法、浅层CNN模型以及深层CNN模型对携带花粉蜜蜂的识别展开研究,结果表明,浅层CNN模型表现较好。
本研究设计5种CNN架构并采用GoogLeNet V1的深度迁移模型,用于监测视频图像中蜜蜂是否携带花粉。将计算机视觉技术引入蜜蜂觅食行为(是否携带花粉)的监测,设计5种浅层卷积神经网络模型进行对比分析,并与深层网络GoogLeNet V1的迁移学习进行对比,以寻找适合监测蜜蜂觅食行为的最优模型。
1 材料和方法
1.1 工作流程
准备工作包括图像采集、预处理;主线工作包括CNN架构的搭建、训练过程及调参、结果对比与分析;基线工作包括传统机器学习的特征工程、分类器的选择与训练、结果对比与分析(图1)。试验对比不同深度网络的特点,并对不同网络运用在不同实际情况进行讨论。
1.2 材料获取
本研究采用Kaggle公司的公开访问数据集,该数据集根据2017年6月在波多黎各大学Gurabo农业实验站拍摄的2段蜂群入口处的视频(10:00和13:00,时长各1 h)裁剪而来,包括369幅携带花粉和345幅不携带花粉的高分辨率蜜蜂照片。值得注意的是,为检测自然环境下模型的适应性,该视频分别在不同光照条件下录制,并将所获得的蜜蜂照片裁剪矩形的大小固定为180像素×300像素,这样带注释的胸腔位置就会以坐标(90,100)为中心出现,并且蜜蜂是完全可见的。
该视频采集系统(图2)由蜂箱、摄像头、入口处以及遮光板组成。其中,摄像装置使用4 Mpixels GESS IP摄像头连接到8 Mbps的网络录像机上进行连续录制,遮光板利用透明的丙烯酸塑料盖遮盖在装置顶部,同时为避免干扰蜜蜂生物周期只使用自然光。
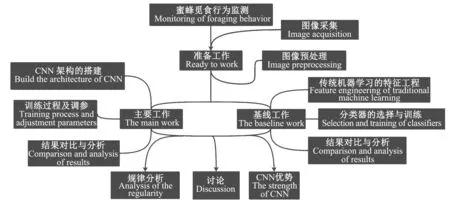
图1 研究流程Fig.1 Research process

①:蜂箱; ②:摄像头; ③:入口; ④:遮光板①:Beehive; ②:Camera; ③:Entrance; ④:Visor 图2 视频采集系统Fig.2 Video capture system
1.3 数据预处理
在图像分析中,预处理是对输入图像进行特征抽取、分割和匹配前所进行的处理。其主要目的是消除图像中无关的信息,恢复有用的真实信息,增强有关信息的可检测性和最大限度地简化数据。研究中首先对原始数据集(图3)进行数据增强。数据增强是深度学习中增加训练数据量、提升模型泛化能力和鲁棒性的有效技术手段[17],常见方法包括图像旋转180°(图4a)、图像水平翻转(图4b)、加入Gaussian噪声(图4c)等。本研究对数据集进行上述处理后获得1 476幅携带花粉蜜蜂图和1 380幅未携带花粉蜜蜂图,共计2 856个数据样本。

图3 部分原始蜜蜂数据集对比Fig.3 Comparison of some raw bee data sets

a:图像旋转180°;b:图像水平翻转;c:加入Gaussian噪声;d:直方图均衡化;e:对应直方图;f:Lab空间转换a:Image rotated by 180°;b:Image flipped horizontally;c:Added gaussian noise;d:Histogram equalization;e:Corresponding histogram;f:Lab space conversion图4 原始数据集的数据增强处理Fig.4 Data augmentation treatment of original data base
由于数据拍摄时间不统一导致图像亮度不一致,因此有必要对其进行图像增强。图像增强通过一定手段对原图像附加一些信息或变换数据,有选择地突出图像中感兴趣区域(Region of interest,ROI)或者抑制(掩盖)图像中某些不需要的特征,使图像与视觉响应特性相匹配。常见方法为对比度拉升、Gamma校正、同态滤波器以及直方图均衡化。本研究采用直方图均衡化以增强图像局部对比度,该方法增加灰度值的动态范围,使亮度更好地在直方图上均匀分布。研究中设置直方图离散水平为64,效果如图4d,对应直方图如图4e。
本研究还对数据集颜色空间进行转换,将原始RGB彩色空间转换为Lab颜色空间,Lab空间色域宽阔,不仅包含了RGB、CMYK的所有色域,还能表现其不能表现的色彩,弥补了RGB色彩模型和CMYK色彩模式色彩分布不均的不足。Lab颜色空间中亮度和颜色是分开的, L通道没有颜色,a通道和b通道只有颜色,因此调节操作简单,Lab空间转换后如图4f。
1.4 模型构建
目前,深度学习在各领域中获得极大成功,这与神经网络复杂性密切相关,而提升网络复杂性以增加网络深度和宽度为主。本研究对神经网络深度展开研究,分析不同深度的神经网络模型的效果从而寻找不同实际条件下的最适模型。研究设计7、9、11、13、15层共5种的CNN架构,其中,卷积层分别为2~6层,同时与目前数据挖掘挑战赛主流算法GoogLeNet V1(22层)的深度迁移学习进行对比,以构建最优化蜜蜂觅食自动监测模型。
1.4.1 浅层CNN结构设计 CNN主要结构包括卷积层、下采样层(池化层)和全连接层。卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法最佳化得到,目的是提取输入的不同特征,因此是CNN的核心。池化层分为最大池化(Max pooling)与平均池化(Average pooling),通常以最大池化为主。池化层可以非常有效地缩小参数矩阵尺寸,从而减少最后全连层中的参数量,既可以加快计算速度也可以防止过拟合。全连接层的每个结点都与上1层的所有结点相连,用以把前边提取到的特征综合起来,一般全连接层的参数也是最多的。其可以整合卷积层或者池化层中具有类别区分性的局部信息。本研究的浅层CNN采用输入层—卷积层—池化层—全连接层—输出层的基本架构,其中,卷积层与池化层交替连接,研究中依次增加卷积层与池化层的个数,以增加网络深度。各层设计具体如下:
1.4.1.1 输入层 研究采用预处理后的大小为32像素×32像素×3通道的蜜蜂图片作为输入。
1.4.1.2 卷积层 在卷积操作中卷积核是可学习的参数,常用的卷积核大小为3、5、7卷积,研究设置卷积核大小为5卷积。卷积核的步长(Stride)设置为1,扩充边缘(Padding)设置为0。为探究网络深度对模型效果的影响,依次增加卷积层层数(2~6层)。经多次调参发现,卷积层1~6层对应分别为6、16、120、250、300、380种时模型效果最好。
1.4.1.3 激励层 激励层中激励函数提供非线性变化,若无激励函数,每一层节点的输入都是上层输出的线性函数,输出均为输入的线性组合,即无法发挥隐藏层作用。传统的激励函数为sigmoid,该函数计算量较大且反向传播时易造成梯度消失。目前深度神经网络大多采用ReLU函数作为激励函数,此函数不仅能减轻梯度弥散的问题,而且计算量较小,但在学习速率较大时易造成神经元大批量“消亡”。为解决此弊病,本研究采用LeakyReLU作为激励函数。在该激励函数作用下,当神经元未激活时仍有一个小梯度的非零值输出,从而避免可能出现神经元 “消亡”现象[18]。
1.4.1.4 池化层 研究在每层卷积层后加入最大池化层,以减少上一级的参数矩阵尺寸。设置该层每个单元与上一层卷积层的特征图的2×2邻域相连接。
1.4.1.5 全连接层 在本 CNN 结构中,经多个卷积层和池化层后,连接着1个全连接层。经全连接层输出后,利用softmax分类器进行分类,输出最后预测结果。
1.4.1.6 Dropout层 研究在每个CNN架构的全连接层后添加Dropout层,随机让网络的某些节点输出设置为0,也不更新权重,随机删除网络中的一些隐藏神经元,但使得输入输出神经元数量相同,加入Dropout不仅能有效防止模型过拟合,而且取得较好的正则化效果,提升CNN的泛化能力。经交叉验证,选择Dropout为0.5。
将5种CNN架构按以上设置进行设计(图5),并进行输出结果对比分析。
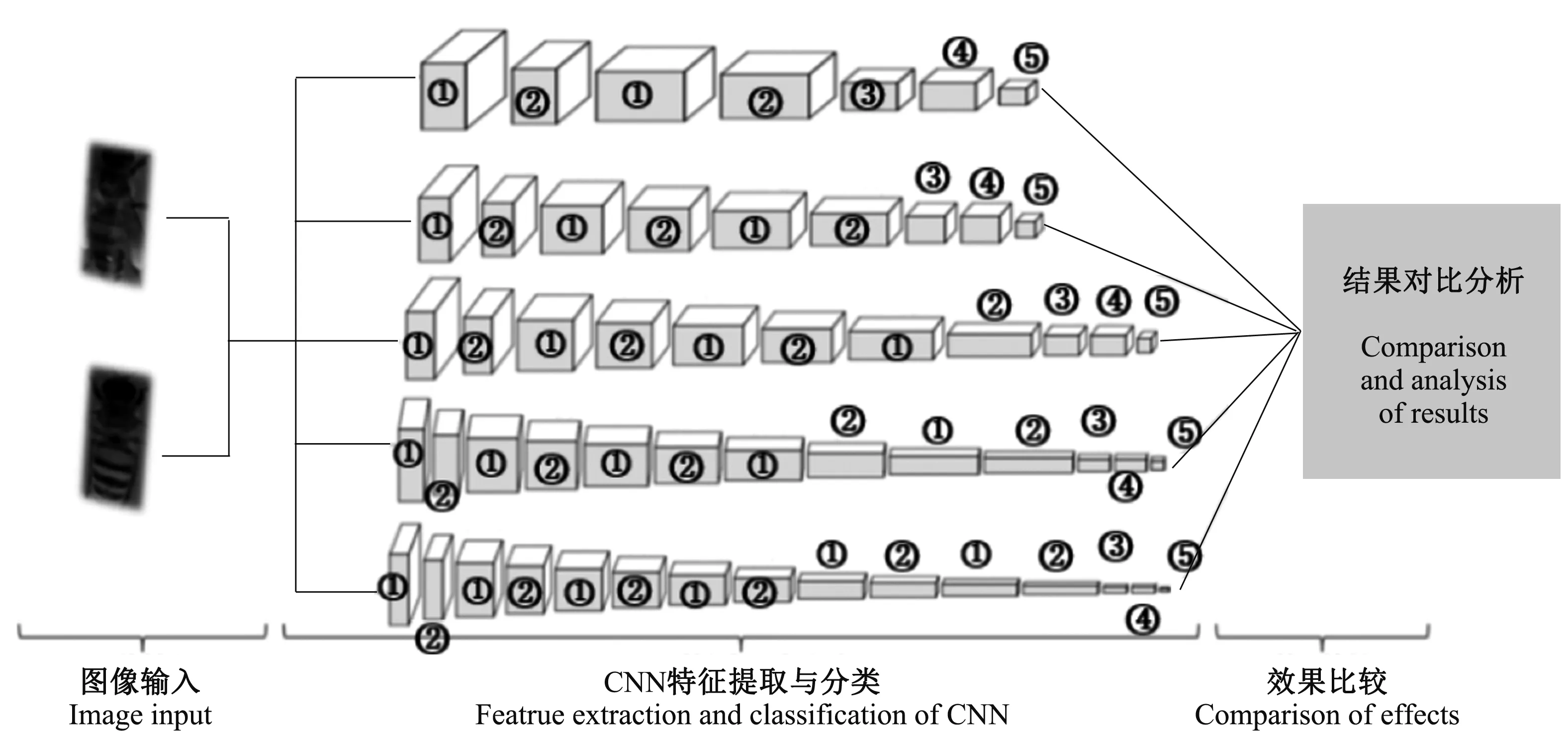
①:卷积层;②:池化层;③:全连接层;④:Dropout层;⑤:输出层①:Convolutional layer;②:Pooling layer;③:Fully connected layer;④:Dropout layer;⑤:Output layer图5 浅层CNN结构设计Fig.5 Shallow CNN structures design
1.4.2 深层CNN结构设计 为更好分析上述浅层CNN的模型效果,寻找最优网络结构,本研究使用2014年ImageNet挑战赛的冠军模型GoogLeNet进行比较。GoogLeNet共有4个子模型,本研究选用其经典版本GoogLeNet V1。为减小数据依赖性与提高训练效率,先在ImageNet上进行预训练,得到初始模型而后进行迁移学习。Inception是GoogLeNet的基础模块单元,其实现多尺度卷积提取多尺度局部特征,并经过优化训练得到最优参数配置。研究选择Inception的改进版本作为深度迁移学习的基本单元,其改进单元结构如图6。即通过1×1卷积、3×3卷积、5×5卷积和3×3最大池化构成单位模块,且3×3卷积和5×5卷积前添加1×1卷积,1×1卷积放在3×3最大池化之后以利于数据降维,从而降低庞大参数量带来的计算量大的弊端。

图6 Inception改进单元结构 Fig.6 Inception improved unit structure
GoogLeNet V1共有22层网络层数,输入层图片大小224像素×224像素×3通道。该网络共有9个Inception单元,包括Inception模块的所有卷积在内都用了ReLU修正线性单元激励函数,且使用Dropout层防止过拟合,最后采用平均池化层代替全连接层。整体结构如图7所示。
1.5 CNN训练
训练操作在Windows 10系统上完成,计算机配置为CPU Intel 酷睿 I7-6700 HQ、3.5GHz、内存4 GB,编程均在MATLAB R2018a中进行。针对上述衍生数据集,随机抽取2 576幅(1 326幅带花粉蜜蜂和1 250幅未带花粉蜜蜂)图像作为训练样本,其余280幅作为验证样本。同时,训练数据集中随机选取20%作为训练时的测试集。利用以上划分后数据集分别进行浅层、深层CNN的训练。
训练时需对模型进行调参,鉴于研究中对浅层CNN的5种架构进行对比研究,因此浅层CNN模型参数需保持一致。其中,初始学习速率是重要的参数,通常在优化的初始阶段采用较大的学习率使模型有更大的搜索范围,从而避免过早陷入局部极小值[19]。但较大学习速率易跨过极值点使得算法稳定性较差,因此初始设置学习速率为0.01,观察其损失函数的振荡态势,当达到稳定时缩小到原始的0.1倍(即设置gamma=0.1),重复以上步骤直至寻找到时长处于可接受范围内的最优准确率。其余参数按精度最优原则进行设置,最终使得5种浅层CNN与1种深层CNN均达到训练准确率处于稳定的状态为止。模型基本参数设置见表1。
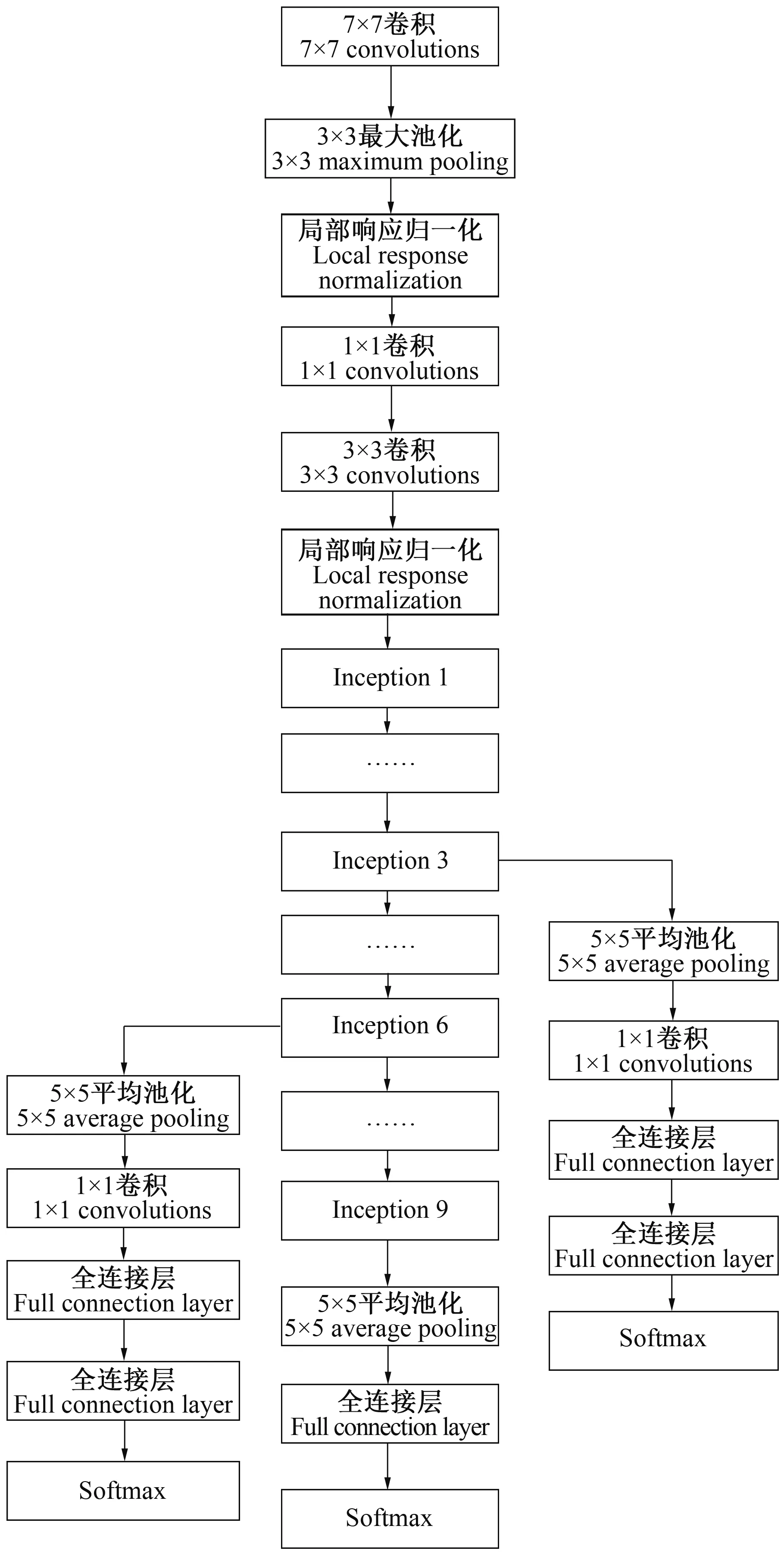
图7 GoogLeNet V1结构 Fig.7 GoogLeNet V1 structure
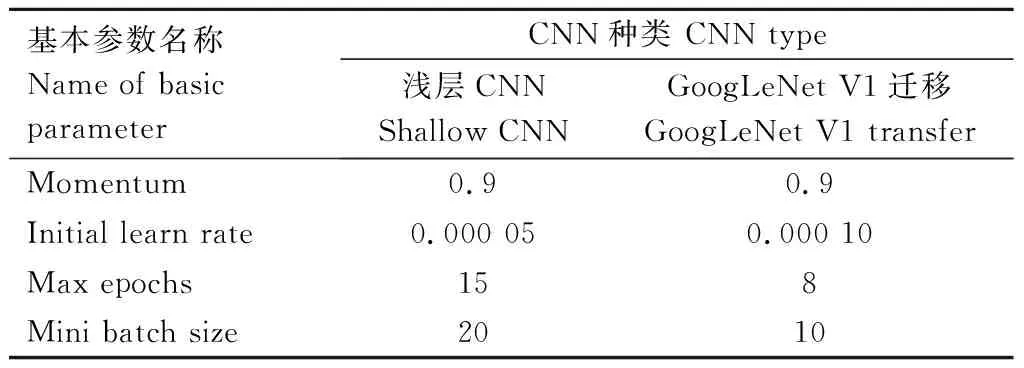
表1 基本参数设置Tab.1 Basic parameter settings
1.6 传统机器学习
为体现上述深度学习方法的优越性,本研究还利用传统机器学习方法与其对比。将预处理后的蜜蜂图片作为数据集,特征工程时考虑到该数据集中蜜蜂拍摄位于不同时间段,光照强度不同,为最大程度避免光照对数据处理带来的影响,选用提取图像的方向梯度直方图(Histogram of oriented gradient,HOG)作为分类器输入的特征向量。HOG特征描述子最早用于静态行人检测[20],其是基于对稠密网格中归一化的局部方向梯度直方图的计算。实际操作中,将图像分为小的元胞(cell),在每个元胞内累加计算出一维的梯度方向(或边缘方向)直方图。同时通过将元胞组成更大的块(blocks)并归一化块内的所有元胞以获得对光照和阴影的更好的鲁棒性。本研究修改图像分辨率为200像素×200像素,设置元胞大小为32 pixels×32 pixels,1个块内包含2个×2个元胞单元,最终每个样本提取得到900维特征向量。
本研究在分类器的选择上采用经典机器学习算法SVM、Bagging集成学习随机森林(Random forest,RF)[21]与K最近邻(K-nearest neighbor,K-NN)[22]。研究中导入特征向量进行训练并进行最优化调参。
2 结果与分析
2.1 CNN训练结果
5种浅层CNN与1种深层CNN训练迭代过程如图8。对于前5种CNN模型,在同一迭代次数(1 545次)下模型均趋于稳定。随着模型层数递增稳定性增加且训练准确率也有所上升。分析原因,神经网络越深,所提取的特征更加复杂,具有更好的非线性表达能力,因此网络鲁棒性提升[23]。但值得注意,随网络层数增加,模型达到稳定状态的迭代次数增多,这意味着完成模型训练需要更大的计算代价。图8f展示GoogLeNet V1迁移学习的训练过程,与浅层CNN不同的是,该训练过程具有更高的稳定性,且相比于其他深层网络,该网络达到稳定趋势的迭代过程也较短。从网络结构分析,首先GoogLeNet V1不同于VGG等深度网络,GoogLeNet做了更大胆的网络上的尝试,采用Inception单元模块而不是像VGG继承了LeNet以及AlexNet的一些框架,该模型虽然有22层,但却比AlexNet和VGG都小很多,性能优越。因此能在保证准确率的情况下最大程度地轻化网络,提升训练效率。其次,本研究在初始预训练的GoogLeNet V1网络上进行了迁移,进一步加快模型训练。但不可否认, GoogLeNet V1即便结构改进,参数量仅为AlexNet的1/12(500万),但其参数总量仍然巨大,这对计算设备提出了较高的要求。
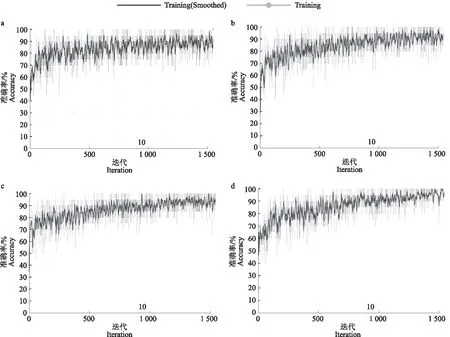
a:7层CNN模型;b:9层CNN模型;c:11层CNN模型;d:13层CNN模型;e:15层CNN模型;f:GoogLeNet迁移模型(22层)a:7-Layer CNN model;b:9-Layer CNN model;c:11-Layer CNN model;d:13-Layer CNN model;e:15-Layer CNN model; f:GoogLeNet transfer model(22 layers)图8 不同深度CNN训练迭代过程Fig.8 CNN training iterative processes at different depths
2.2 模型性能评估
本研究从蜜蜂觅食自动监测的实际需求出发,选取测试准确率、损失函数值以及训练时间对6种CNN模型进行效果评估(如表2)。对于浅层CNN,拥有4层卷积层(11-Layer)的模型测试准确率最高,达到0.903 6,其次是拥有2层卷积层(7-Layer)的深度网络,测试准确率为0.892 5。值得思考的是,5层(13-Layer)和6层(15-Layer)卷积层的深度网络测试准确率并不是一直增加,甚至出现下降,不如最初始的2层卷积层(7-Layer)模型。从损失函数值上看,在一定范围内,随着卷积层层数增加,模型损失值越小。但当模型总层数达到15层后,数值出现了反弹,拥有6层卷积层(15-Layer)的网络的损失函数值为0.070 6,高于拥有4层(11-Layer)和5层(13-Layer)卷积层的深度模型。训练时长随网络深度增加而增加,这便验证了深层网络需要更大的计算代价的结论。而对于本研究所采用的深层网络GoogLeNet V1迁移模型,发现其测试准确率最高(0.953 6),损失函数值也相当低,只有0.017 4,但训练时间为7 326.0 s,远高于以上浅层网络。

表2 CNN性能评估指标Tab.2 CNN performance evaluation indicators
2.3 网络深度影响机制与应用讨论
深度学习中,越深的模型意味着更好的非线性表达能力,可以学习更复杂的变换,从而拟合更加复杂的特征输入[24]。图9展示蜜蜂数据经CNN模型输入后各卷积层可视化。从边缘提取开始,随着卷积层数的增加,所学习到的特征也更加复杂。
网络加深能进行逐层的特征学习,理论上可获得更优的拟合效果。但本研究结果表明,并非网络越深,模型效果越好,在浅层CNN中,当网络层数超过11层时,测试准确率不仅没有上升,反而下降。分析其原因,一方面可能是加深深度带来的梯度不稳定问题不仅没有缓解,反而加重;另一方面是不断简单加深网络容易达到饱和,从而使模型性能无法提升,甚至开始下降。另外,加深网络还容易使得浅层网络的学习能力下降,限制深层的继续学习。但由于自身模型的优越性,研究中深层迁移网络GoogLeNet V1测试效果最佳。因此改进深层CNN结构,有利于解决梯度不稳定等弊端,使深层神经网络克服传统网络自身的瓶颈成为可能。

(1)—(6):第1~6层卷积层(1)—(6):1st to 6th convolutional layers图9 各卷积层可视化Fig.9 Visualization of each convolution
若将不同深度网络的各自特点运用到不同情况的农业研究中,既能符合生产需求,又能最大程度避免不必要的浪费。本研究的GoogLeNet V1迁移模型测试准确率最高(0.953 6),但训练时间长,设备要求高,可运用于农业上关于蜜蜂花粉研究中的小批量检测与分析。但对于大规模蜜蜂养殖产业来说,这无疑耗资巨大且效率低下。而本研究所设计的卷积层4层的浅层CNN因具有测试准确率较高(0.903 6)、计算成本较低(仅为GoogLeNet V1的1/7)的特点而更加符合生产实际。因此,综合考虑模型效果和训练成本,结合蜜蜂觅食监测任务的需求,选择合适网络更利于达到期望效果。
2.4 对比分析
为对比上述CNN结果,研究采用十折交叉验证法分别对HOG+SVM、HOG+RF和HOG+K-NN进行测试,结果如表3。发现传统机器学习算法的测试准确率与CNN有较大差距,其中表现最好的是HOG+SVM,准确率为0.847 2,其次是HOG+RF(0.797 2),准确率最低的是HOG+K-NN(0.777 8)。这是因为传统机器学习算法需人工提取特征,这样提取的特征具有单一性和浅显性[25],之后将提取特征映射至目标空间造成学习效果不如CNN。

表3 传统机器学习算法结果对比Tab.3 Comparisons of traditional machine learning algorithm results
3 结论与讨论
研究对蜜蜂觅食行为进行自动检测,利用计算机视觉技术对携带花粉蜜蜂与不带花粉蜜蜂进行识别。对比了5种不同深度下的浅层CNN以及深层网络GoogLeNet V1的迁移模型,结果发现,浅层CNN在测试准确率等方面不如深层CNN,其中11层的CNN模型具有最高测试准确率(0.903 6),而GoogLeNet V1的测试准确率达到0.953 6。但GoogLeNet V1迁移模型测试所消耗的训练时间远多于浅层CNN,需更高的设备计算要求。研究为不同实际需求下的蜜蜂觅食行为的监测提供建议:GoogLeNet V1深层网络适合用于小批量的科学研究,11层的CNN则更适用在大规模的蜜蜂养殖。其中,GoogLeNet V1深层网络作为目前深度学习主流神经网络,在许多方面都有应用[26-27],但目前未报道其应用于蜜蜂觅食行为的监测,因此本研究为今后蜜蜂养殖业中高精度的监测提供新的可能。另外,本研究提出的11层CNN,虽然测试准确率不如深层神经网络,但其训练成本低的优势有利于大规模的应用。
同时,本研究针对不同网络深度对模型效果的影响规律展开探讨,对比发现,在一定范围内,加深网络深度利于增加模型学习特征的复杂性,从而提升模型性能。但并非网络越深,效果一定越好,当网络层数达到饱和时,再简单重复叠加卷积层不仅无法提升网络性能,甚至可能出现下降。反观GoogLeNet V1模型,其虽然网络层数(22层)远高于对比模型,但该网络独特的Inception架构能减少模型的训练参数且有利于克服梯度下降,以此突破上述架构的局限性从而极大提高了CNN性能。因此,加深模型的同时改进网络结构是进一步提升CNN性能的正确思路,未来需着重研究。
另外,本研究还将CNN深度模型与传统机器学习算法进行对比,发现HOG+SVM、HOG+RF和HOG+K-NN等传统算法虽然在原理上相比CNN中的Softmax分类器更为成熟,但因其人工特征工程的局限性导致识别的效果不如CNN,这体现了深度学习运用于动物行为监测领域的优越性。但这也为探索更高精度的模型提供思路,即将深度神经网络与传统分类器相结合,比如CNN提取图像多维纹理特征后使用SVM等分类算法进行分类,结合后二者的优势有望进一步提升监测效果,今后应进一步加强研究。
猜你喜欢
哈哈画报(2022年8期)2022-11-23
水土保持学报(2022年5期)2022-10-10
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
建材发展导向(2021年24期)2021-02-12
健康体检与管理(2021年10期)2021-01-03
儿童故事画报·发现号趣味百科(2017年4期)2017-06-30
文理导航·科普童话(2016年6期)2016-09-12
吉林农业(2016年4期)2016-05-14
