
基于联合投影字典学习的辐射源调制识别
2020-08-14 01:48李东瑾杨瑞娟董睿杰
兵工学报 2020年7期
李东瑾, 杨瑞娟, 董睿杰
(空军预警学院, 湖北 武汉 430019)
0 引言
随着新型装备的不断革新,多功能一体化技术因其独特优势备受关注[1]。一体化技术的应用将有望解决单平台能力不足、多功能系统冗余和集约化程度不高等问题。高效的辐射源信号识别将为系统一体化功能间的柔性融合提供无源数据支持,是一体化系统智能化的关键环节。辐射源识别技术经历了漫长的发展历程,其本质在于提取信号的高稳定性特征,利用模式识别等方法实现高效分类,当前研究多聚焦于调制类型识别。早期,诸多学者致力于人工特征提取及分类识别方式研究。随后,特征提取方式不断增多,通过各类线性、非线性映射提取了诸如小波特征、熵特征、复杂度特征和模糊函数特征等高阶特征[2-5];分类器研究也由传统线性分类器转向机器学习领域的非线性分类方式,特征稳定性和整体识别性能均得以提升。综合来看,特征提取和分类器设计方式繁多,但人为干预因素较多,难以充分挖掘和利用内在特征。
近年来,稀疏表示与字典分类算法在压缩感知、图像识别、计算机视觉、图像降噪等领域取得了诸多成果[6-9]。对应算法主要分为两类:1)稀疏表示分类,聚焦于稀疏重构,采用重构误差完成分类识别,例如稀疏表示分类(SRC)等[9];2)字典学习分类。常通过引入各类判别项强化鉴别能力,文献[10]通过引入类别一致性约束提出了判别迭代奇异值分解(D-KSVD)字典学习方式;文献[11]引入Fisher判别准则,综合考虑类内与类间误差,提出了基于Fisher判别的字典学习方法(FDDL);文献[12]考虑编码鉴别性和标签连续性约束提出了标签一致性迭代奇异值分解(LC-KSVD)字典学习方式,文献[13]考虑高维核映射提出了核迭代奇异值分解(Kernel-KSVD)算法。字典学习能够提取样本数据的内在特征,得到较本质的原子特征表示,在辐射源识别领域已有部分学者开展相关研究并取得成效,所研究内容大致分为两类:1)基于解析字典学习的辐射源识别,即通过既定线性、非线性映射得到固定原子字典表示并用于实现分类识别[14],该方式需要进行人工设计,难以适应参数变化等情况;2)基于判别约束的字典学习识别方式。文献[15]利用Fisher判别字典进行Gabor原子特征学习,得到了较强表征能力的时频原子字典。综合来看,字典学习理论应用于辐射源识别领域仍有较大发展空间。现有字典学习方式对环境和各型信号的适应能力存在较大差异,尤其对于参数多变且具备较高相似度数据难以实现有效识别,因此需要判别字典具备更高的适应性和特征提取能力。
鉴于此,本文采用联合投影字典学习(JPDL)方式进行辐射源识别。为降低信号非平稳和噪声干扰影响,采用短时傅里叶变换(STFT)及其预处理后的浅层时频信号作为初始特征。联合投影字典侧重特征映射及选择能力,通过特征映射提升特征维度并增强特征辨识度,利用降维学习选择强特征并降低高维数据冗余,完成特征的核空间非线性升维投影与线性降维投影。分类识别过程利用联合投影字典进行稀疏编码,并通过重构误差完成分类识别。
1 基于JPDL的辐射源识别系统
实际应用辐射源信号面临复杂电磁环境、信号非平稳及各类不确定性,时域信号稳定性不高且分辨能力较差,因此不利于高效识别。时频域信号具备较好的能量聚焦性和局部频域维稀疏特性,其中STFT时频特征[16]复杂度较低,有助于提升分类时效性。此外,浅层时频特征为字典学习提供一个较好的初始字典集,便于其学到更本质的分类特征。
基于字典学习的辐射源识别系统如图1所示,其包含包括测试与训练两个阶段。训练阶段利用已知辐射源信号及对应类别标签离线进行降维学习和字典学习,获取降维投影矩阵和最佳字典表示;测试阶段通过无标签数据进行稀疏编码并完成有效性验证。整个流程可分为3个部分,即浅层时频特征提取、JPDL、分类识别,其中JPDL过程包括核空间映射、特征降维学习、稀疏编码和字典学习。稀疏编码阶段完成字典原子的最优线性表示。
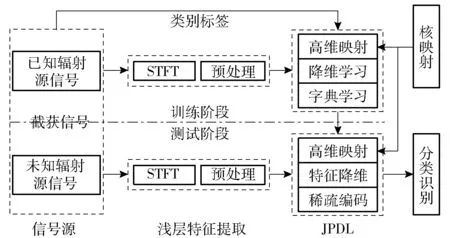
图1 基于JPDL的辐射源识别流程示意图Fig.1 Flow chart of emitter signal recognition based on joint projection dictionary learning
本文主要考虑10种调制方式,即单载频(SCFM)信号、线性调频(LFM)信号、非线性调频(NLFM)信号、二相编码(BPSK)信号、四相编码(QPSK)信号、Frank信号、二相频率编码(BFSK)信号、四相频率编码(QFSK)信号、LFM-BPSK复合调制信号和BFSK-BPSK复合调制信号。
1.1 浅层时频特征提取
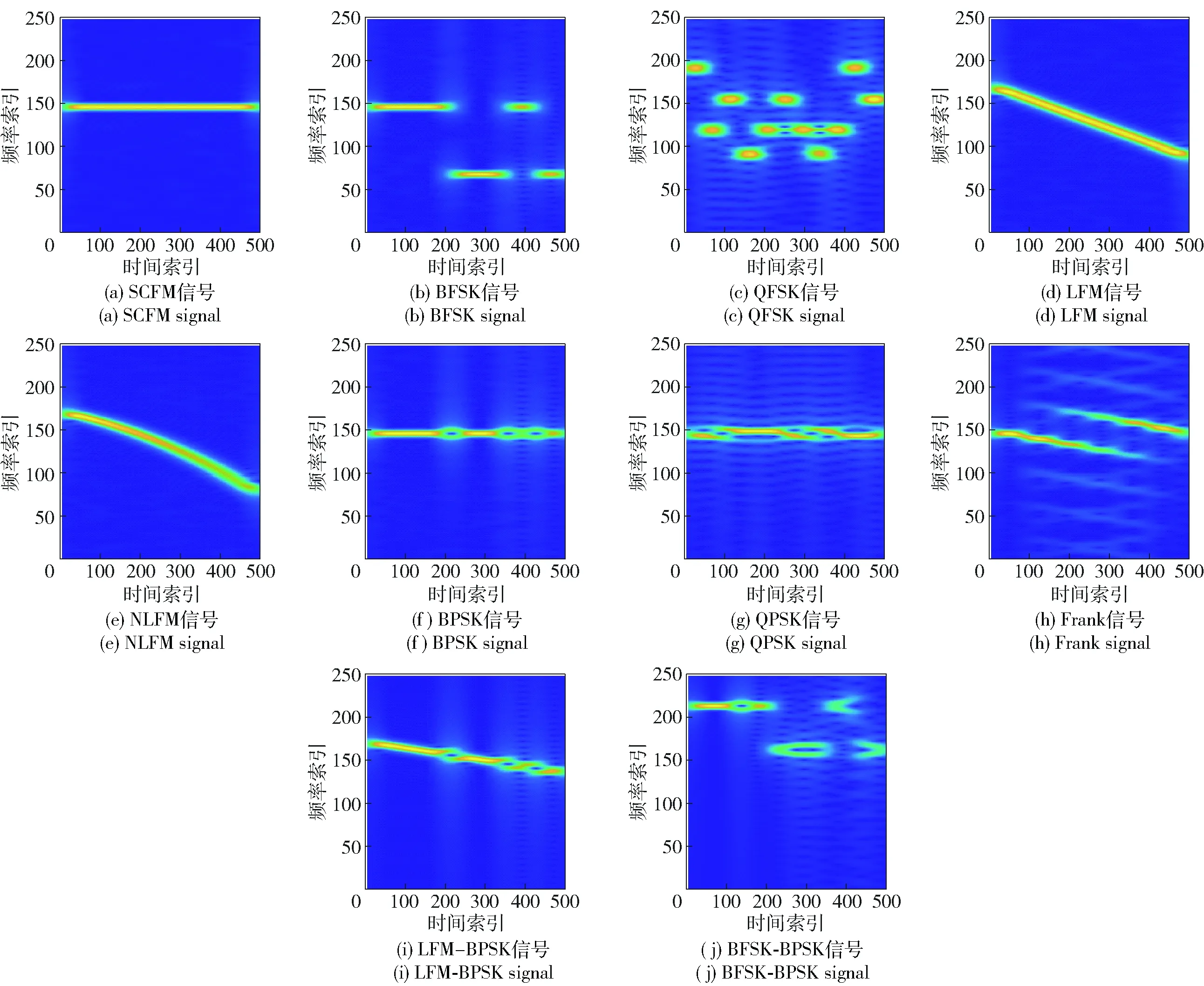
图2 辐射源信号时频图Fig.2 Time-frequency diagrams of emitter signal
图2所示为辐射源信号STFT时频图,图中时间索引值对应信号的不同时刻,且其单位间隔对应时间分辨率,频率索引的单位间隔对应一个频率分辨单元。时频变换将一维信号投影至二维时频域,具备更高的能量聚焦性和辨识度。此外,信号在时频空间中占比较小,具备较好的稀疏性质。时频信号直接作为特征输入存在维度过高、信息冗余和噪声干扰等问题,因此进行如下预处理:
2)构建滤波系数矩阵Fp×q,初始化为Fp×q=Qp×q.Fp×q=[f1,f2,…,fq]中列信号对应局部频域维特征,具备稀疏性,逐列进行归一化处理:
(1)
3)滤波系数优化。选取系数增强函数g(x)=x3,进行系数稀疏化表示:
(2)
式中:i∈[1,p];j∈[1,q];mean(·)为向量均值运算。
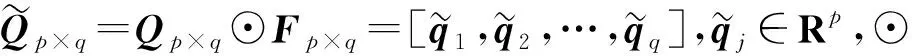
图3所示为-5 dB时SCFM与NLFM信号预处理前后时频图对比,预处理较好地抑制了噪声干扰,但特征维度仍然较大,进一步降维难以有效保留结构特征和细节特征,甚至引入了额外特征损失。因此字典分类模型同时考虑降维学习和字典学习。

图3 预处理前后时频图对比Fig.3 Comparison of time-frequency diagrams before and after pre-processing
1.2 JPDL理论

(3)
式中:y为测试样本,y∈Rm;I为单位矩阵;T0为稀疏度;α为稀疏系数,α∈RK. 目标函数为Frobenius范数形式的重构误差,约束条件包含稀疏度约束和投影正交约束。为保证凸优化性质,约束条件也常采用l1范数[19]和l2范数优化[9]形式。
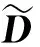
(4)
式中:K(·)为核函数φ(·)的核矩阵表示,K(X,X)=φ(X)Tφ(X)为核Gram矩阵,K(X,X)∈RN×N;S=[α1,α2,…,αN]为稀疏系数矩阵。利用训练样本进行字典学习时,可分解为L类独立问题进行联合求解,即
(5)
式中:Si为第i类稀疏编码。上述目标函数并非理想的联合凸函数,因此采用分步迭代方式[20],固定其中部分变量,更新剩余变量,交替进行优化求解。具体计算流程如下:
1)初始化处理,选择核主成分分析(KPCA)[13]方式得到伪随机变换矩阵A;字典系数矩阵B中每列随机一个元素置1,其余元素置0.
2)固定伪随机变换矩阵A与字典系数矩阵B,通过字典学习得到稀疏编码Si,采用正交匹配追踪(OMP)[21]方式完成逐类优化更新。
3)固定伪随机变换矩阵A与稀疏系数矩阵S,逐类更新字典系数Bi,对(5)式求导,可得

(6)
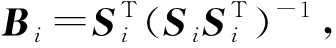
4)固定字典系数矩阵B和编码系数矩阵S,更新伪随机变换矩阵A,此时优化目标为

(7)
(7)式可等效为广义特征分解问题,求解得出矩阵A由(I-BS)(I-BS)TK(X,X)Ta=μa的前n个最小特征向量构成,μ和a分别对应特征值、特征向量。
5)计算相邻迭代误差,当相邻迭代误差达到设定阈值或满足最大迭代次数时终止,输出伪随机变换矩阵A与字典系数矩阵B;否则返回步骤2继续迭代。
1.3 基于字典学习的分类识别
联合投影字典通过核空间投影和降维投影学习获取到冗余特征原子,其中包含丰富的二次特征。联合投影方式能够有效学习原子特征,进而降低各类信号重构误差。进行分类测试时,采用子字典重构误差进行分类判定,分类识别目标函数为
(8)
式中:si和ei分别为样本y在第i类子字典上的编码系数和分类误差。因此样本y的识别结果为
(9)
如图1所示识别结构,具体训练阶段流程为:1)对时域信号进行STFT处理,得到二维浅层时频特征信号;2)对信号进行时频域降噪预处理,以增强特征辨识度;3)将二维时频数据进行向量表示;4)联合字典学习,利用各类训练样本数据对字典学习模型进行优化求解,得到伪随机变换矩阵A与字典系数矩阵B.
测试阶段流程为:1)STFT;2)预处理;3)向量化;4)特征降维及稀疏编码,利用已有字典模型完成高维映射、特征降维和稀疏编码;5)分类识别,利用(8)式计算重构误差,识别结果为(9)式所得最小重构误差类。
2 仿真实验
2.1 参数设置
为验证本文识别方法有效性,选取1.1节所述10类辐射源信号进行仿真实验。充分考虑信号多样性,选用随机数据集模拟参数多变的复杂情况。所有信号频段位于0~50 MHz范围且载频随机变化,对应参数设置如下:SCFM、BPSK和QPSK信号载频5~40 MHz;BPSK、BFSK和LFM-BPSK信号随机采用7位、11位、13 位Barker码;QFSK信号频率编码‘1,3,2,4,3,2,3,4,3,1,2’;QPSK信号相位编码‘4,1,3,2,1,4,1,3,2,3,4’;LFM信号载频5~25 MHz,带宽5~20 MHz;NLFM信号载频5~30 MHz,调制系数随机取值5~10 MHz;Frank信号载频10~30 MHz,相位调制阶数随机取值5~8;LFM-BPSK信号带宽5~20 MHz;BFSK-BPSK信号频率编码随机选取5位、7位Barker码,相位编码随机选取11位、13位Barker码。
测试环境如下:采样频率100 MHz,采样时长5 μs,STFT长度为512,为保留细节特征时频域降维参数p、q设为60. 在10~30 dB高信噪比(SNR)条件下随机生成训练样本,每类信号200个样本,数据集样本个数为1 600;在SNR为-10~10 dB(步长2 dB)条件下随机生成测试样本,每个SNR下单类信号样本为100,共计11 000个测试样本。计算机配置为CPU i5-M480,内存6.00 GB ,数学仿真软件MATLAB R2018b.

表1所示为降维参数对识别率影响,识别率随着降维参数的增大而增大,且随SNR增大平稳上升。当SNR为-8 dB时,保留100维数据进行特征表征仍能达到62.3%的识别率,可见降维学习使得低维数据具备较强特征表示能力;当SNR≥2 dB时识别率基本达到99%,维度对其影响减弱,综合考虑选择降维参数为300.

表1 不同降维参数对应识别率
基于稀疏表示的字典学习中,一般要求字典具备过完备性。图4所示为300维特征下识别率随字典原子数变化曲线,随着原子数目增多,字典完备性越好,识别率越高。当原子数为20~40时,识别率相对较低,原因在于数据集受载频等随机性影响较大,且部分数据类间差异性较小,少量字典原子难以形成完备表示。当原子数大于80时效果较稳定,此时字典原子对数据随机性和细微特征的全局表征能力较强。综合考虑选取字典原子数为150.

图4 不同字典原子数下识别性能Fig.4 Recognition rates for different atom numbers
图5所示为不同训练集下识别率比较,字典原子在小样本时与样本数一致,样本数大于150时字典原子选为150. 选择SNR为{-10 dB,-6 dB,-2 dB}进行测试,结果表明样本数据集越丰富识别效果越好。样本数为40的训练集整体平均识别率较低约为66.9%;当训练样本数为200时,数据所含随机样本较丰富,能够为字典学习提供有效样本支持。
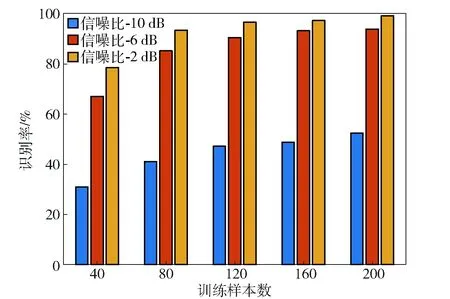
图5 不同训练样本集下识别性能Fig.5 Recognition rates with different training sample sets
文献[22]分析了小样本数据集识别问题,但其背景为固定参数辐射源信号、种类较少且类间辨识度高,无随机变化特征;文献[15]选用5类辐射源信号进行识别,识别数据集随机性和种类并不丰富,且类间差异较明显,0 dB时平均识别率约为90%. 本文所用数据集参数随机性较大,且部分数据类间相似度较高,加大了字典学习和原子表示难度,因此小样本数据集下形成的字典完备性不足。
2.2 预处理前后性能对比
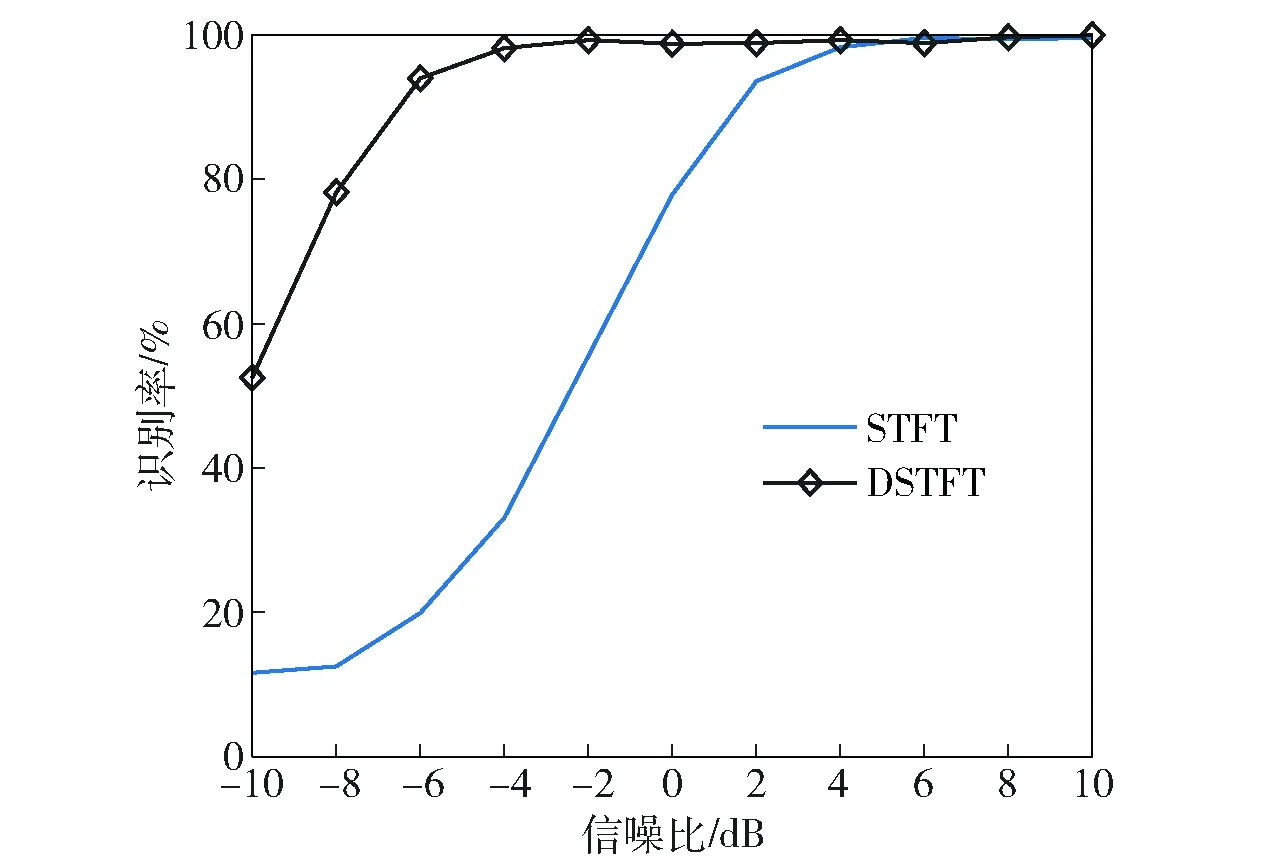
图6 不同特征识别性能对比Fig.6 Recognition performance with different features
为定量分析预处理增益,选择STFT处理后不降噪特征(记为STFT)与本文预处理后特征(记为DSTFT)在相同条件下进行训练和识别,测试结果如图6所示。预处理方式较好地抑制了噪声干扰,能够较好地保留信号时频结构,提高了低SNR环境适应能力,SNR为-10 dB时性能增益约40.9%.
2.3 综合识别性能对比
为验证识别方法有效性,选择FDDL[11,15]、LC-KSVD[12]和Kernel-KSVD[13]3类字典学习方式进行比较。为保证标准一致性,FDDL和LC-KSVD方式需在相同特征维度下进行学习,常规字典学习算法采用主成分分析(PCA)降维和随机投影降维,其中随机降维方式具备较大的随机性,此处采用PCA降维处理后数据作为FDDL、LC-KSVD和Kernel-KSVD的数据集。所有识别方式统一参数为:迭代次数10次,字典原子数150,特征维度300. FDDL方式中两项约束系数分别为0.

图7 不同识别方式性能对比Fig.7 Performance comparison of different methods
005、0.05,采用l
1
范数优化方式
[23]
;LC-KSVD方式中稀疏度为12,稀疏编码项约束系数为4,分类判别项约束系数为2;Kernel-KSVD方式核函数与JPDL方式一致。
测试结果如图7所示,预处理使得识别性能均保持在50%以上。JPDL方式识别率在SNR为-10~-4 dB条件下快速递增,在SNR为-4 dB时达到98.2%,随后性能逐渐趋于稳定;FDDL、LC-KSVD和Kernel-KSVD方式识别效果相对较稳定,在SNR为-10~-8 dB环境下优于JPDL方式,但在SNR为-6~10 dB环境下识别性能较稳定且不及JPDL方式。
不同字典学习方式下各类辐射源信号识别结果如图8所示。其中,FDDL和LC-KSVD方式识别效果相对稳定,但性能存在上限,对数据随机性特征提取能力和高相似度信号辨识能力均存在一定局限性。FDDL方式对SCFM、QFSK、QPSK和Frank信号识别效果较好,较易混淆信号主要为LFM和NLFM信号。LC-KSVD方式受数据随机性影响较大,所提取原子特征仅对QFSK、QPSK和Frank信号较有效,其余几类信号原子相似度较高,误分类概率较大。JPDL和Kernel-KSVD方式通过核映射一定程度改善了特征稳定性,较线性字典学习方式表现出一定优势。JPDL方式在LFM、NLFM和BPSK 3类信号的识别上优势更为明显,但低SNR环境下性能略弱于其余3类方式。
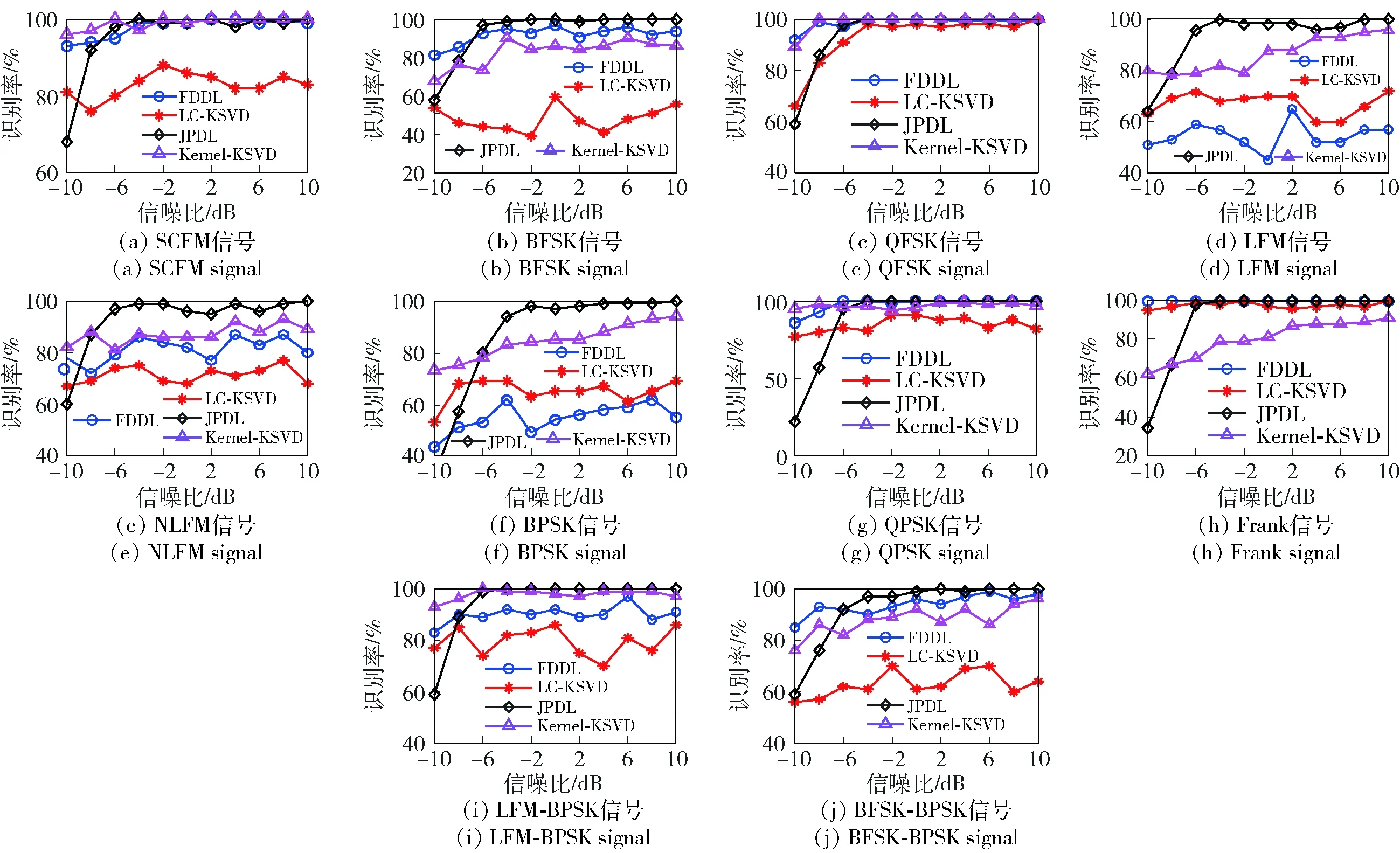
图8 不同识别方式下各类信号的识别结果Fig.8 Recognized results of various signals by different methods
综合对比分析得出:1)JPDL方式的核空间映射和降维学习所获取特征在低SNR条件下存在一定损失,随SNR提升特征稳定性增强;2)FDDL和LC-KSVD方式能够有效学习结构特征,对结构差异较大数据识别能力较强,结构特征经预处理后受噪声影响不大,因此整体识别效果较平稳;3)数据随机性和类别相似性加大了字典学习难度,识别曲线的波动主要由数据随机性引起,随机性起伏较大时,LC-KSVD和FDDL方式学习到的特征难以克服随机性影响,FDDL方式对应的类心并不稳定;4)核字典学习方式在本文背景下更为有效,其中Kernel-KSVD方式仅包含字典学习,难以对高维数据形成更稳定的低维表征。而JPDL联合学习方式能够同时进行降维学习与字典学习,具备更强的针对性,且对多类型、相似度较高信号的判别能力较强,SNR大于-6 dB时整体性能较优。此外,JPDL方式还可针对不同应用选择核空间样式和降维参数,能够有效避免高维数据样本计算引入的“维数灾难”。
表2所示为SNR -6 dB时JPDL方式识别的混淆矩阵,信号类型按图2顺序依次记为S1~S10. 其中:LFM与NLFM、LFM信号与LFM-BPSK信号相似度较高,存在2%~4%的混淆;SCFM、QPSK和BFSK-BPSK信号三者均与BPSK信号存在较大相似性,存在一定程度混淆;BFSK-BPSK和BFSK信号存在4%~7%的混淆;BPSK和BFSK-BPSK信号误判概率相对较大。整体来看,平均识别率达到94.4%,原子特征具备较高辨识度。
表3给出了4种识别方式的计算复杂度,测试时间为单个样本平均识别时间。其中:FDDL方式采用l1范数优化方式,训练时间和测试时间均最长;LC-KSVD方式时间最优,但识别能力不足;Kernel-KSVD方式的训练时效性介于JPDL方式和LC-KSVD方式之间,其测试时效性与JPDL方式相当。相比而言,JPDL方式能够有效兼顾计算复杂度与识别精度。
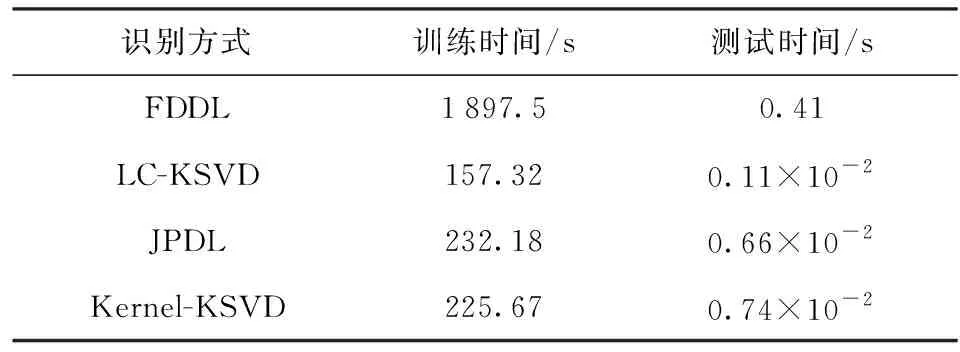
表3 计算复杂度比较
3 结论
本文提出了一种基于JPDL的辐射源识别方法,时频特征及预处理为字典学习提供初始字典集,JPDL考虑了高维核空间投影和降维投影,用于强化特征差异并降低数据冗余。仿真验证了该方法的有效性,得出以下主要结论:
1)降噪预处理有助于改善低信噪比环境下的识别率。
2)JPDL方式所提取字典原子具备较强表征能力,能够有效区分类间高相似度信号。
3)JPDL方式能够有效适应高维数据样本,通过降维学习形式降低计算开销。
4)在辐射源调制识别背景下,JPDL方式能够兼顾识别准确性和时效性,综合性能较FDDL、LC-KSVD、Kernel-KSVD方式更优。
猜你喜欢
舰船电子工程(2022年7期)2022-09-06
车主之友(2022年4期)2022-08-27
计算技术与自动化(2022年1期)2022-04-15
汽车实用技术(2022年4期)2022-03-07
兵器装备工程学报(2021年2期)2021-03-07
北京航空航天大学学报(2020年10期)2020-11-14
现代电子技术(2020年13期)2020-08-07
舰船电子对抗(2020年1期)2020-04-27
装备环境工程(2020年3期)2020-04-03
海峡姐妹(2019年12期)2020-01-14
