
基于大数据的社区用户行为分析系统的设计与实现
2020-08-10 08:20侯菡萏张帆
装备维修技术 2020年33期
关键词:行为分析
侯菡萏 张帆
摘 要:本文以大数据主流技术SparkCore和SparkSQL为主,搭配主流前端框架SpringMVC,系统前端方便社区管理者操作,提供高交互性、清晰易懂的可视化界面;后端优化分析算法,提高执行效率,增强代码鲁棒性和可扩展性,实现了社区用户消费行为分析预测、上网指数分析等功能,为管理者制定更合理高效的决策提供依据。
关键词:社区用户;行为分析;Spark技术
1 引言
随着中国国力的快速提高,人们对居住条件及其所在社区提供的服务都有了更高的要求。社区一般由第三方物业公司管理或社区用户自治,每一个社区都会有相应的社区管理者去决策。如果管理者能够提供合理决策,分配合适资源,居民的幸福感就会提升。由于不同环境、不同地区、不同时间下,两个社区往往存在着较大的差异,社区用户间的需求和生活习性也截然不同,社区的管理不能仅凭经验。根据中国民政部2020年2季度民政统计数据显示,现今全国共有51.7万个村委会,11.1万居委会,如此庞大数量下社区管理者与住户之间往往存在诸多矛盾,社区管理者认为住户感受过激、特例化;而社区住户认为管理者管理经验不足,不能合理分配资源,出现决策无效甚至失误。本文采用大数据技术解决以上矛盾,大数据技术提供了一种能够客观、实时反映某个时段内社区用户行为的方式,社区管理者依据大数据分析结果,实现多角度掌握社区用户行为,通过可视化界面及时察觉异常数据,从而提供有效决策。
2 大数据相关技术
2.1 Spark
Spark作为一款优秀的大数据开发技术,是一个专门为大规模数据而生的基于内存的实时计算引擎。其有四大特点,分别是速度快,相较于Hadoop,相同数据量Spark快100倍;易用性,提供了丰富的API借口,包含Python、Java、Scala等;通用性,提供一站式服务,包含核心SparkCore、使用SQL语句的SparkSQL、实时处理的SparkStreaming、机器学习的MLlib等;运行在任何地方,本身以.class形式存储,可以直接在JVM中运行。
2.2 SpringMVC
SpringMVC是一个较为优秀的Java Web开发框架,相较于以前的Web开发,其做了非常多的优化,将核心部分做了分工,分为M(Model),V(View),C(Controller),大大降低了耦合,同时增强了内聚,节约了开发人员的学习成本,提高开发效率,减少失误可能性。
2.3 Clickhouse
Clickhouse是一个列式数据库,建立该数据库的目的在于对数据进行快速的在线分析与处理。Clickhouse數据库的优点包括:紧凑数据格式、数据压缩、数据存储在磁盘、多核处理、支持分布式、支持部分SQL、数据实时更新等。
3 系统架构设计
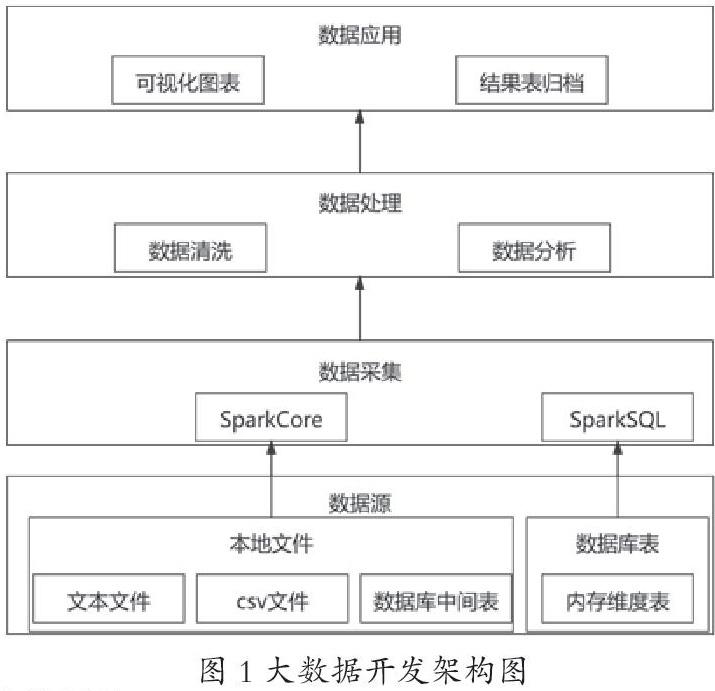
在大数据开发流程设计中需要先确认数据的输入和输出,分别是社区管理者提供的源数据文件和数据库结果表;其次确认输入的数据量总和,输出的数据量是结果表,数据量较小。由于分析结果既要生成结果表,还要展示到前端界面,需要一定的即时性和交互性,因此本系统选用Spark技术,由于Hive和MapReduce等技术适用于离线分析,一般用于在每天凌晨处理昨日的数据,而Spark则是基于内存实时处理,选用Clickhouse来存储更合适。同时Spark提供了一站式服务,有专门针对数据库的SparkSQL,设计大数据开发架构如图1所示。
4 系统功能设计
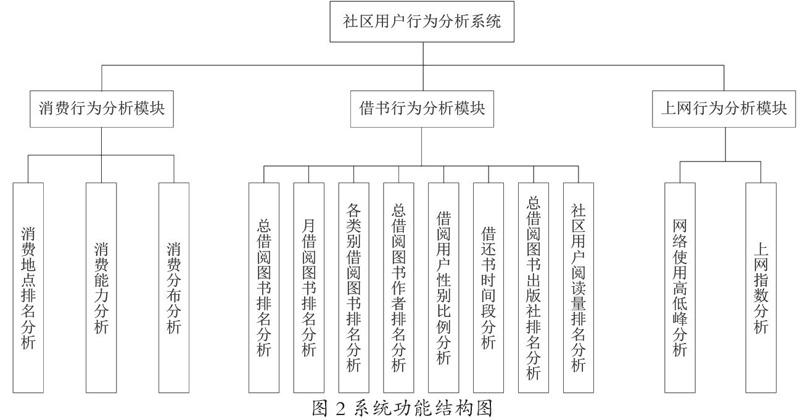
系统采用模块化思想,结合归纳法和演绎法进行设计。模块化思想要求每个子模块都具有一致的数据结构、一致的代码风格规范以及一致的操作流程,使用这种方式可以将一个复杂模块抽象为若干个逻辑清晰功能统一的子模块,从而提高代码复用性,增强代码的可扩展性,减少维护的成本并提高开发人员的开发效率。归纳法即在以往相似系统设计集的基础上,进行需求相关的二次设计,虽然能保证系统设计不会出现全局上的失误,但是往往也得不到有效的结构创新和改革。演绎法通过总结规律,根据普遍规律自下而上抽象出整个系统的逻辑。使用这种方法能够个性化定制系统,具有最合适最能满足需求的特点,但开发成本大幅度提高,也更容易出错,开发周期延长。因此开发过程中,最好的方式就是将两者结合,这两种方法的任何一个缺点都会严重影响本系统的质量,故需要中和两种手段并积极发挥优势的一面。依据以上方法,在社区用户行为分析系统中抽象设计出三大模块,各个模块下继续划分多个子模块,真正意义上实现了模块与模块间的低耦合,模块内部的高内聚。消费行为分析模块包括消费地点排名分析、消费能力分析和消费分布分析。借书行为分析模块包括总借阅图书排名分析、月借阅图书排名分析、各类别借阅图书排名分析、总借阅图书作者排名分析、借阅用户性别比例分析、借还书时间段分析、总借阅图书出版社排名分析和社区用户阅读量排名分析。上网行为分析模块包括网络使用高低峰分析和上网指数分析。系统结构如图2所示。
5 用户行为数据分析与实现
本质而言,Spark算法与Hadoop算法极为相似,但Spark算法能够更好地进行数据挖掘、机器学习技术方面的应用。在运算过程中,用户行为的数据信息统一存储在HDFS中,通过对数据的读取,可以获取频繁项集的全局支持度,最终将计算后的频繁项集保存在HDFS中。
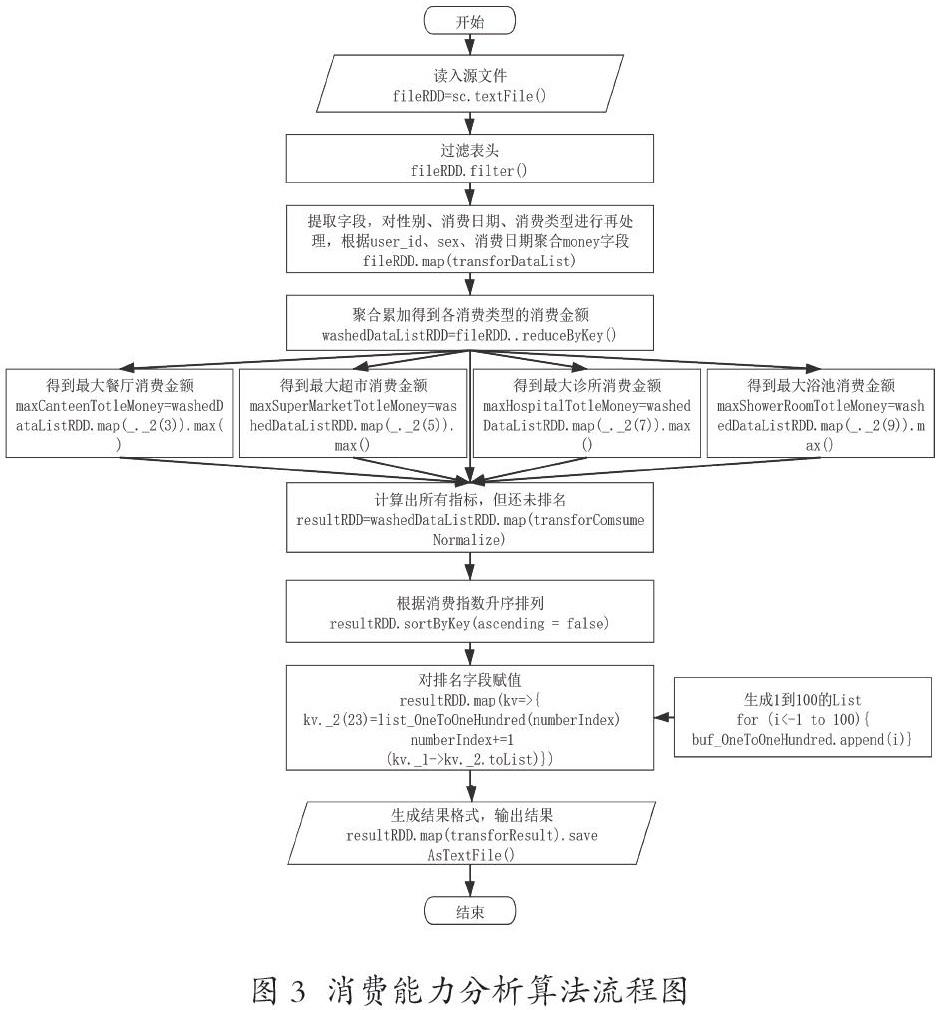
5.1 用户消费能力分析
该算法目的是分析社区用户每个人的消费能力,并进行赋分和排名。该算法实际业务作用为筛选重点消费人群,并在后续社区开发中重点培养和关注。该模块是用户粒度,因此需要平铺展开所有消费指标并计算比值,最后根据权重算法得出最终排名。算法流程图如图3所示。
5.2 借阅图书用户性别比例分析
该算法主要分析借阅群体在所有群体中的占比以及借阅群体中男女分布情况。该算法逻辑较为复杂,需要多个数据源分步计算多个指标,并需从不同维度上得到的临时结果再度整合才能完成,算法流程图如图4所示。
5.3 用户网络使用高低峰分析
网络使用高低峰算法主要分析在不同时间段社区用户每个人的上网情况,并且分析出每个人上网的高峰期和低谷期,是用户粒度的需求。算法流程图如图5所示。
6 用户行为数据应用
数据应用方面,包括对数据的展示、数据智能推荐、用户行为预测三部分。数据展示方面,是通过 Sprintboot提供的数据访问接口,对Mybatis进行持久化框架连接和应用。同时,Angular组件在系统中的应用,可以加快信息数据应用的响应速度,有利于系统数据信息处理质量的提升。最后,通过Echarts,将信息动态以直观的形式展示给用户。在数据智能推荐方面,基于内容过滤的推荐算法、双重聚类算法的融合,形成混合推荐技术。通过该技术的应用,可以对用户行为日志进行读取、分析,并在此基础上,对用户行为进行关于服务内容的智能推荐。用户行为预测方面,基于数据包的重组算法,可以根据用户行为的相关数据,实现网络数据信息的重组。
7 结语
本文阐述了构建用户行为分析系统的背景及意义,考虑到海量评价数据所带来的挑战,将数据存储、处理及用户行为模型构建与Spark技术相结合,设计了基于大数据平台的用户行为分析系统,系统主要包含用户消费能力分析模块、用户行为预测模块,每个模块有特定的功能,实现了用户行为信息的有效分析和深度应用,为社区管理者提供了进行有效决策的数据展示。
作者简介:
侯菡萏(1979.02—),女,汉,黑龙江省哈尔滨市,硕士,副教授,哈尔滨金融学院计算机系,研究方向:数据分析与数据挖掘。
课题:黑龙江省高等教育教学改革项目(SJGY20190265)《线上线下混合式“金课”的研究与实践——以“数据库原理及应用”课程为例》
猜你喜欢
东方教育(2016年6期)2017-01-16
现代电子技术(2016年23期)2017-01-12
电子技术与软件工程(2016年20期)2016-12-21
电脑知识与技术(2016年23期)2016-11-02
经营者(2016年12期)2016-10-21
考试周刊(2016年60期)2016-08-23
商(2016年6期)2016-04-20
现代经济信息(2016年1期)2016-01-25
物联网技术(2015年2期)2015-04-07
