
基于Petri网可达图的业务对齐方法
2020-08-06 08:23:18田银花杜玉越
计算机集成制造系统 2020年6期
韩 咚,田银花,杜玉越,张 琴
(1.山东科技大学 矿业与安全工程学院,山东 青岛 266590;2.山东科技大学 智能装备学院,山东 泰安 271000;3.山东科技大学 计算机科学与工程学院,山东 青岛 266590)
0 引言
过程挖掘的理念是通过从事件日志中提取出有价值的信息,从而发现、监控和改进实际业务过程[1-5]。过程挖掘的研究对于实施新的业务过程以及分析、改进已实施的业务过程具有非常重要的意义,是近年来相关领域国内外研究的热点[6-8]。过程挖掘主要包括过程发现、合规性检查、过程增强等应用类型。其中,合规性检查将事件日志中的事件与过程模型中的活动进行对比,旨在找到观察行为和建模行为之间的共性和差异[9-13]。
在众多合规性检查方法中,对齐观察行为和建模行为成为衡量记录系统运行行为的事件日志和过程模型一致性的重要手段[14-16]。对齐方法的主旨在于发现过程模型与事件日志之间存在的偏差。通常情况下,包含偏差数最少的对齐被认为是最优对齐。有关最优对齐的查找方法是NP-hard问题,时间复杂度和空间复杂度均较高。在过程挖掘研究领域,对齐方法已得到广泛的研究与应用[17-21]。已有大量关于对齐方法及类似方法的文献呈现了此类方法的思想、动机以及解决的问题。
Cook等[22]提出一种比较迹与过程模型来量化相似度的方法。该方法虽然是基于状态空间的分析方法,但因其使用了启发规则简化搜索空间,从而产生了错误的对齐结果,以致于只能部分支持重复变迁和不可见变迁。
Adriansyah等[16]提出一种计算迹与过程模型之间最优对齐的方法。其主要算法思想为:①依据迹中活动之间的次序生成一个线性结构的日志模型;②计算新生成的日志模型与过程模型之间的乘积模型;③计算该乘积模型的可达图,即变迁系统图;④利用启发式搜索算法——A*算法,在变迁系统图中查找得到最优对齐。该方法生成的变迁系统空间较大,在该查找空间上虽然可以根据不同的代价函数查找到满足不同代价函数的对齐,但是也因此增加了查找最优对齐的工作量。
Lu等[23-24]提出基于偏序事件数据的合规性检查方法。首先,从已有日志中获得偏序迹。然后,提出一种方法可以使用偏序迹和偏序对齐实现合规性检查。虽然该方法对齐过程较为简单,但是在某些情况下只能得到最优对齐的近似解,无法求得所有可能的最优对齐结果。
Wang等[25]提出一种基于工作流分解的对齐观察行为和建模行为的方法。该方法虽然能够处理较大规模的业务过程模型和较长的迹,但只能处理能够划分成段的块状工作流网模型,具有一定的局限性。
浙江省列入 《全国山洪灾害防治县级非工程措施建设规划》的68个县(市、区)中,第一批 20 个县(市、区)和第二批38个县(市、区)正在建设过程中,一个覆盖全省的山洪灾害防治监测预警网络即将形成。但建设过程中发现在以下几方面需进一步完善:
Song等[26]提出一种过程模型与事件日志之间的高效率对齐方法。该方法借助启发式规则以及迹重演等技术,大大降低了查找空间的复杂程度,但其查找空间中依然存在无法到达最优对齐的冗余节点,且由于预处理计算的局限性使得该方法只能找到部分最优对齐。
Tian等[27]提出一种过程模型与事件日志之间的简约对齐方法——最优对齐树(Optimal Alignment Tree, OAT)方法。OAT方法能够生成一棵最优对齐树,通过对叶子节点的标记,可以很容易地查找到最优对齐。该方法虽然提高了在搜索空间中查找最优对齐的时间效率,但是在生成最优对齐树时,由于将所有信息都放在节点上、不对重复节点进行共享、不对无效节点进行修剪等原因,导致生成树过于庞大,甚至搜索空间状态爆炸。
通过分析总结上述各类对齐方法,找到目前对齐方法存在的主要问题:①查找空间过大,算法复杂性较高;②不能找到符合要求的、准确的最优对齐;③不能找到所有的最优对齐等。针对上述问题,本文提出一种基于Petri网可达图的对齐方法。该方法和Adriansyah等[16]提出的A*对齐方法的处理方式类似,使用了两Petri网的乘积方法。通过两Petri网的乘积,将迹与过程模型之间的拟合关系全部体现在了一个Petri网中,从而将迹与过程模型之间的对齐运算转换成求Petri网可达状态的运算。和A*对齐方法完全不同之处在于本文提出的方法每次不是只对一条迹进行处理,而是通过计算事件日志的花型模型,将事件日志中所有迹都体现在花型日志模型中。而花型日志模型与过程模型之间乘积模型的可达图中就包含了所有迹与过程模型之间的对齐。
1.2 治疗方法 对照组患者采用甲氨蝶呤小剂量分次肌注联合米非司酮进行治疗,甲氨蝶呤剂量:0.4 mg·kg-1·d-1,5 d为一个疗程,米非司酮剂量100 mg,2次/d,连续服用3 d,剂量600 mg。观察组给予患者一次性甲氨蝶呤肌注给药联合米非司酮(100 mg,2次/d)进行治疗,甲氨蝶呤一次性剂量50 mg/m2,在患者给药4~7 d,如实验室检查血β-hCG下降幅度小于15%或持续上升,于第7天再次肌注同剂量甲氨蝶呤。
本文提出的基于Petri网可达图的对齐方法是对A*对齐方法的一种扩展与改进。本文所提方法及A*对齐方法与上述其他方法相比存在两个优点:①二者都能够计算出精确的对齐结果,而非近似解;②二者都能够求得基于给定代价函数的所有最优对齐。而本文提出的方法与A*对齐方法相比,大大减少了计算乘积模型与可达图的次数,从而节省了存储空间和计算可达图所花费的时间。
1 基础知识
当前各企业组织的信息系统中记录了海量事件,并存储于各类日志中[28]。日志中记录的每一个事件,都描述了该事件在信息系统中留下的轨迹,称为迹。
定义1迹,事件日志。设A是一个活动集合。若存在一个活动序列σ∈A*,则称σ是一条迹。若存在一个迹的有限非空多重集L∈β(A*),则称L为一个事件日志。其中:A*表示集合A上所有有限序列的集合;β(A*)表示集合A*上所有多重集的集合。
Petri网是一种特殊结构的有向二分图,由两种互不相交的节点组成,分别称为变迁和库所[29-30]。从库所到变迁或从变迁到库所的有向连线称为弧,即流关系。Petri网的状态称作标识。
本文使用的Petri网均为标签Petri网。Petri网中标签的含义在于为每一个变迁分配一个相应的活动名称。变迁和实际业务中的活动之间一旦建立映射关系,则变迁与活动二者之间就彼此对应起来。
英国肉用家畜委员会下属有25%以上的猪场应用液体饲料饲喂。英国Wheyfeed有限公司每年向整个英国销售运输超过20万吨液体副产品。荷兰小麦淀粉、土豆皮、乳清粉和酵母浓缩蛋白质等高水分副产品年产量约575万吨,不宜远距离运输,主要用在猪饲料上。荷兰约60%的规模化猪场使用液体饲喂技术[2]。随着乙醇工业的发展,加拿大安大略省约有20%的生长育肥猪饲喂含玉米酒糟和浓缩浸出水溶物配制的液体饲料[3]。
定义2标签Petri网系统。设A是一个活动集合。定义集合A上的标签Petri网系统为元组N=(P,T;F,α,mi,mf),其中:P是库所集合;T是变迁集合,且P∪T≠∅,P∩T=∅;F⊆(P×T)∪(T×P)是库所和变迁之间的有向弧集合,称作流关系;α:TAτ定义了变迁到标签的一个映射函数,τ为不可见变迁,Aτ=A∪{τ};mi,mf分别标记网系统N的初始标识和结束标识。
本文采用库所集合上的多重集来对变迁的发生规则进行描述。任意可达状态m∈β(P)。Petri网N=(P,T;F,α,mi,mf)中的变迁引发规则如下:
(1)对于任意变迁t∈T,若·t∈m,则称t在标识m下是使能的,记作m[t>;
(2)若m[t>,则在标识m下,变迁可以引发。在标识m下,变迁t发生后得到一个新的标识m′,记作m[t>m′,且有:m′=mt·-·t。
签订后的合同原件由归口管理部门存档;相关签约依据原件由承办部门收集整理,交合同归口管理部门或按档案管理规定存档。
定义3可达图。设A是一个活动名称集合且N=(P,T;F,α,mi,mf)是一个Petri网。定义一个变迁系统TS=(S,A′,T′),其中状态集合S=R(mi),初始状态Sstart={mi},终结状态Send={mf},活动集合A′=A且变迁集合T′={(m,α(t),m′)∈S×A×S|t∈T(m[t>m′)}。TS通常被称为Petri网N的可达图。
将事件日志中的迹在Petri网模型上进行重演时,可能会出现二者不完全拟合的情况。不拟合的状态一般称为偏差,对齐能够对偏差进行标记[16,31]。
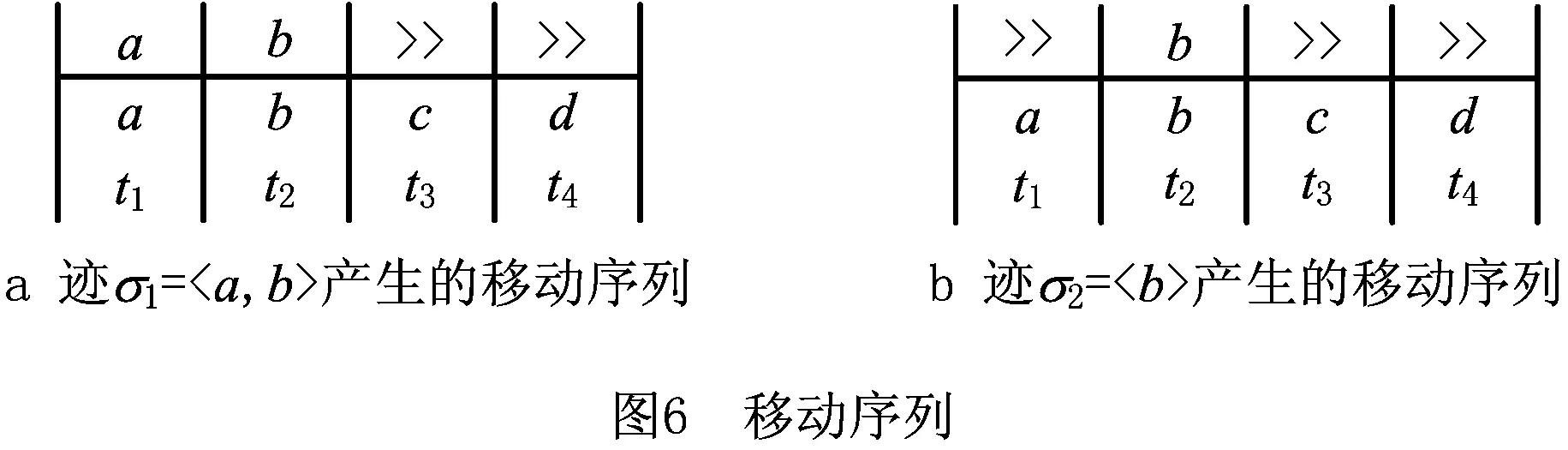
从可达图的初始状态到其他状态的任一条路径均能产生移动序列,每条路径的长度即为该路径构成移动序列的代价值。由此可见,从初始状态到结束状态之间的路径产生的移动序列,若其在第1列上的投影与给定迹一致,且在同条迹中路径最短,则产生该迹与模型之间的一个最优对齐。如图6a所示的移动序列,即为迹σ1=a,b与过程模型Np之间基于标准似然代价函数的一个最优对齐。同理,图6b所示的移动序列即为迹σ2=b与过程模型Np之间基于标准似然代价函数的一个最优对齐。
(1)π1(γ)↓A=σ,即移动序列的第1列元素在A上的投影(忽略≫)产生迹;
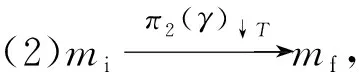
定义4中,≫代表无移动,A≫=A∪{≫}。
该项重组方案并未取得成功,近三个月后,泛海控股以推进重组的“有关条件尚不成熟”为由,终止了这次重组并复牌。
对于对齐中任意元组(a,t)∈γ,对(a,t)进行如下分类:
(1)若a∈A且t=≫,则称之为日志移动;
因此,乘积模型由日志模型、过程模型和同步变迁共同组成。同步变迁是由日志模型与过程模型中具有相同标签名称的变迁衍生而来的一类变迁。乘积模型的库所、初始标识和结束标识分别为日志模型和过程模型中库所、初始标识和结束标识的并集。
(3)若a∈A且t∈T,则称之为同步移动;
(4)否则,称作非法移动。
采用Γσ,N来标记迹σ与过程模型N之间所有对齐的集合。
由定义4可知,迹和过程模型之间的对齐是一个由移动组成的序列。移动为迹中的活动和模型中的行为建立起关联关系。其中:日志移动是指迹中观察到的活动不允许在模型上进行模拟;模型移动是指由模型运行产生的行为未在迹中观察到;同步移动是指迹中的活动与模型中的行为一一对应。日志移动和模型移动说明了迹与过程模型之间的不拟合,体现了对齐中的偏差。
第四,网上自助报账业务量剧增,加之校园网网络设施等关联问题,容易出现集中访问而导致系统瘫痪无法使用得问题。客观上也因为财务系统管理员人员少、任务重,不能及时解决系统出现的新情况、新问题,并及时反馈。
女人们一进家屋,屋子好像空了;房屋好像修造在天空,素白的阳光在窗上,却不带来一点意义。她们不需要男人回来,只需要好消息。消息来时,是五天过后,老赵三赤着他显露筋骨的脚奔向李二婶子去告诉:
给定一条迹与过程模型,可能会有多个不同的对齐结果。为了得到最合乎需求的对齐结果,应该为每一类移动赋予一个特定代价函数值c((a,t))。在给定代价函数的约束下,计算出的代价值最小的对齐就是最优对齐。给定代价函数c((a,t))的取值情况直接决定了迹σ与过程模型N之间的一个最优对齐集合。
本文代价函数采用标准似然代价函数lc((a,t))。该函数为各类移动分配代价值的情况如下:日志移动和模型移动的代价值均为1,而同步移动的代价值为0。
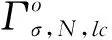
2 事件日志与过程模型的对齐可达图
业务对齐可以对事件日志中给定迹与过程模型之间出现的偏差进行准确定位。本章以给定的事件日志和过程模型为例进行阐述,以便更加形象、清晰地描述该方法的思想。
2.1 事件日志的花型模型
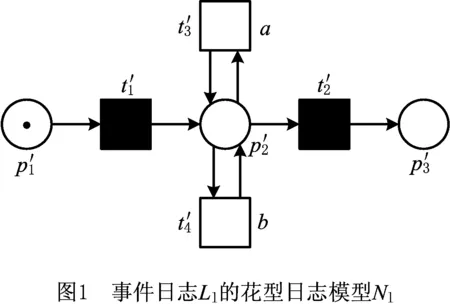
设A是一个活动集合,A={a,b,c}。给定事件日志Ll=[(σ1)3,(σ2)7],其中迹σ1=a,b,迹σ2=b。Ll是一个包含10个案例的简单事件日志,10个案例可以被表示为2个不同的迹。
遍历事件日志中所有的迹,提取出活动子集,将这些活动全部映射到变迁,构造花型日志模型。花型模型是一种极端的日志模型,该模型能够重演事件日志中所有的迹[28]。花型模型只是包含事件日志中的活动信息,并未体现活动间的关系。仅基于活动的发生,即可构造出花型模型。此类模型具有较好的简洁度和拟合度,但是精确度较低。
一般情况下,花型模型中包含初始库所、中间库所和结束库所3个库所。初始库所和中间库所之间关联一个开始变迁,中间库所和结束库所之间关联一个结束变迁,本文中开始变迁和结束变迁都使用不可见变迁来表示。然后,将活动子集中的每个活动各自映射到一个新的变迁,并添加该变迁到中间库所的弧以及中间库所到该变迁的弧。通过上述操作,可构造事件日志对应的花型模型。
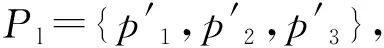
2.2 过程模型
在业务过程管理中,过程模型可以是通过发现算法得到的,也可以是手工建立的。此外,过程模型可以是描述性的,也可以是规范化的。
雪萤把枪换到左手,右手拿匕首指着范坚强,说:“把手机拿出来,放在桌上。”范坚强故意摸了老半天,还没有把手机摸出来。雪萤大声命令:“快点!”范坚强只好把手机放到桌上。雪萤隔着办公桌,把手机电池取下来,然后把手机还给了范坚强。
给定过程模型Np=(Pp,Tp;Fp,αp,mi,p,mf,p),如图2所示。其中:库所集合Pp={p1,p2,p3,p4,p5,p6},变迁集合Tp={t1,t2,t3,t4},流关系集合Fp={(p1,t1),(t1,p2),(p2,t2),(t2,p4),(p4,t4),(t1,p3),(p3,t3),(t3,p5),(p5,t4),(t4,p6)};模型中变迁与活动之间的对应关系为αp(t1)=a、αp(t2)=b、αp(t3)=c和αp(t4)=d;pi,p=p1,pf,p=p6,初始标识mi,p=[p1],结束标识mf,p=[p6]。该过程模型是一个标签Petri网,也是一个合理的工作流网。
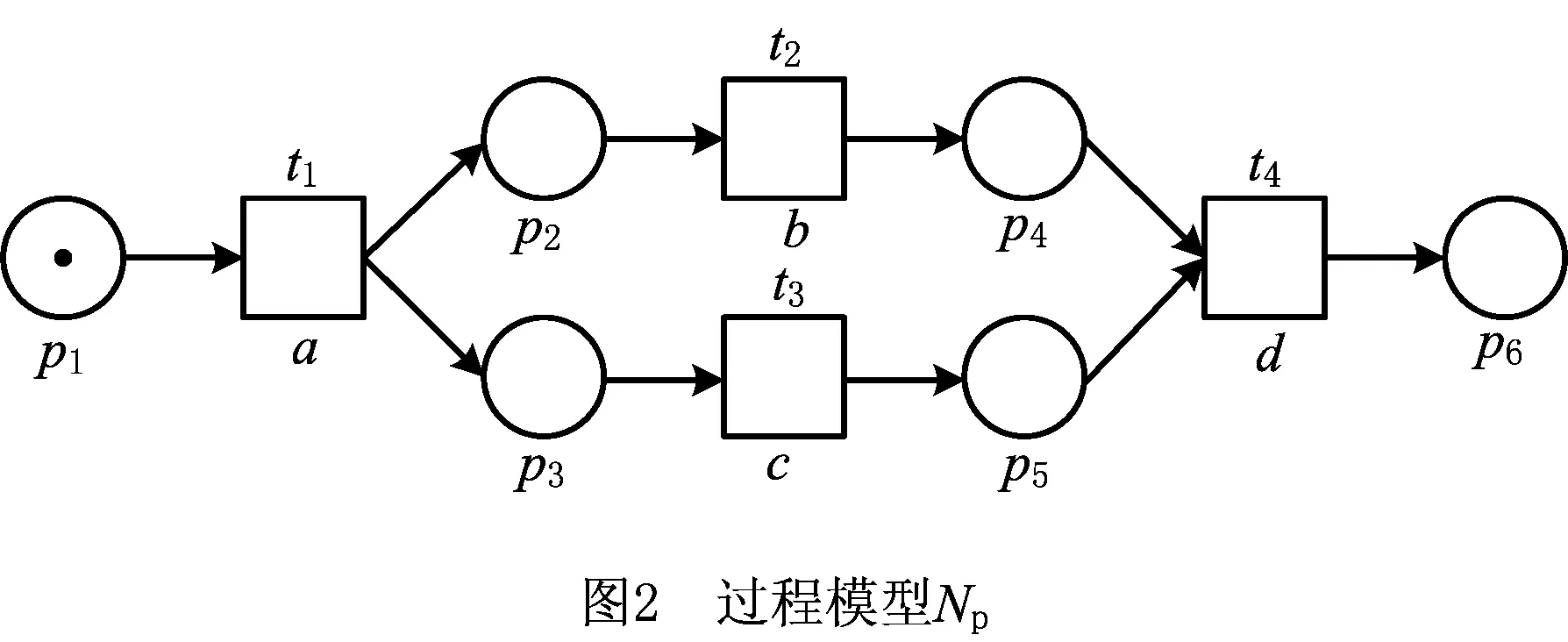
2.3 花型日志模型与过程模型的乘积模型
Adriansyah等[16]在实现A*对齐方法时,提出两Petri网乘积的概念。通过日志模型与过程模型之间的乘积运算,可以将日志中观察到的活动和模型中建模的活动之间的比对结果呈现在乘积模型的变迁上。本文将花型Petri网模型和过程Petri网模型分别作为两个原始的Petri网,计算二者的乘积,将事件日志活动子集中的活动与过程模型变迁上映射的活动之间的对齐情况体现出来。
品牌类型主要是指自创品牌、加盟品牌,或者两者的综合。比如有些图书馆的阅读推广服务可以加盟到一些成熟的品牌中,如上海的“阅读马拉松”,这样既可以吸收加盟品牌成熟的管理模式和经验,也可以直接参与到他们的活动中。另外,图书馆也可以创建自己的品牌,或者区域内图书馆联合创建统一的阅读推广品牌。因而,各图书馆可以根据自身的条件以及内外环境决定品牌的类型。
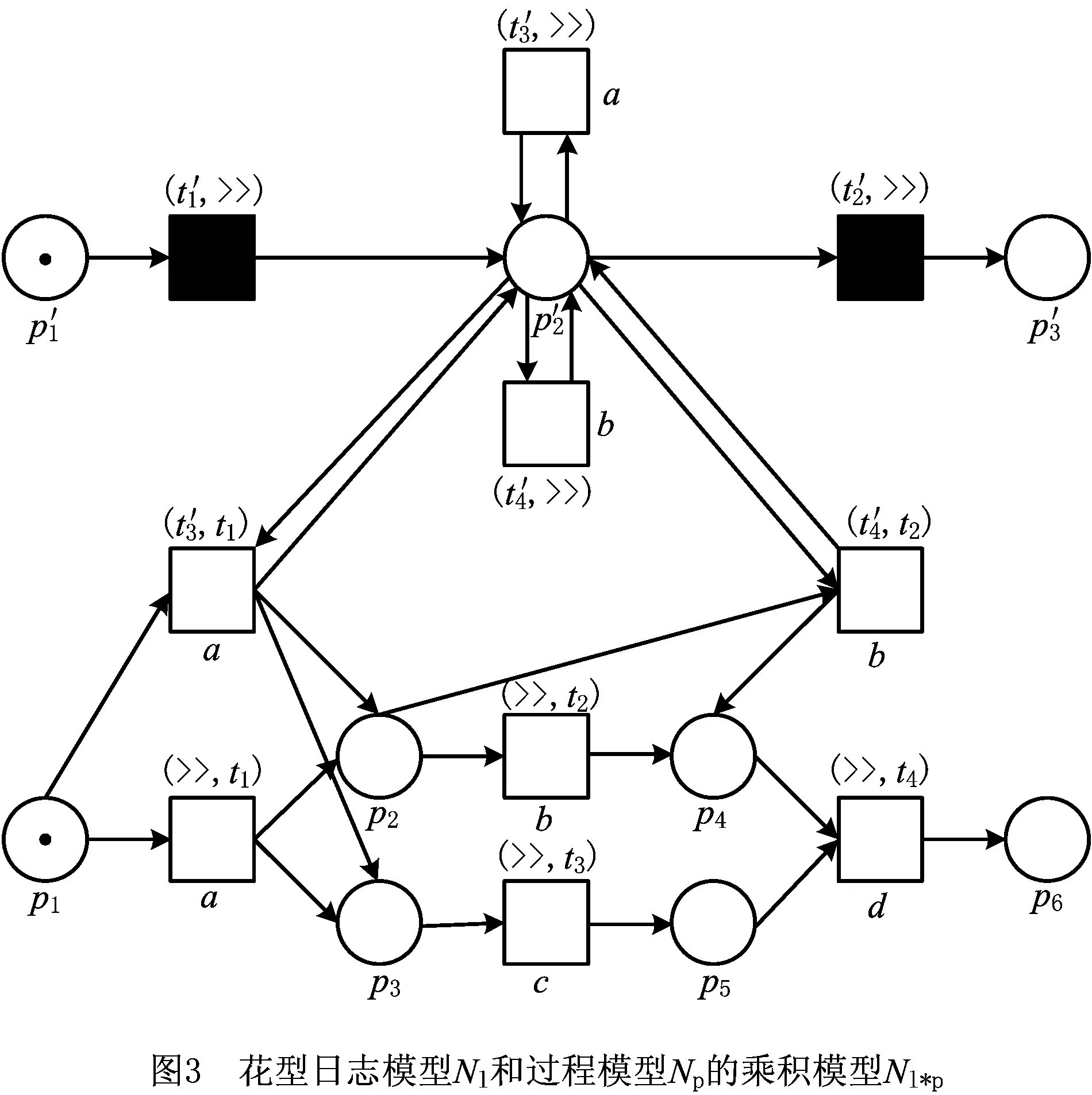
由两Petri网乘积的定义可知,乘积网中保留了原网中所有的库所、变迁和弧关系。且库所名和变迁上映射的标签保持不变,变迁名变为一个序偶。事件日志Petri网中变迁的名字,序偶中的第1个元素为原网中的变迁名,第2个元素为“≫”;过程模型Petri网中变迁的名字,序偶的第1个元素为“≫”,第2个元素为原网中的变迁名。若两个Petri网中具有相同标签的变迁(不可见变迁除外),则相应地生成一个新的变迁,该变迁继承两个Petri网中同标签变迁上的活动名以及它们与前后集之间的弧关系。
(2)若a=≫且t∈T,则称之为模型移动;
为了使花型日志模型的结构特点符合工作流网合理性的定义,花型日志模型中必须有开始库所和结束库所,用来表示业务流程的开始和结束。开始库所和结束库所的输出变迁为不可见变迁,在实际观察业务流程的工作中表示没有任何活动被观察到,以及观察工作的开始和结束。虽然这两个特殊变迁在乘积模型中,形如日志变迁,但是效果如同同步变迁,称为日志空变迁。该空变迁对应的移动是非法移动,形如(τ,≫),称为日志空移动。
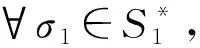
假设日志模型N1=(P1,T1;F1,α1,mi,1,mf,1),过程模型N2=(P2,T2;F2,α2,mi,2,mf,2),则乘积模型N3=N1⊗N2=(P3,T3;F3,α3,mi,3,mf,3)中的变迁类型及属性如表1所示。弧关系可以根据变迁的前后集建立。

表1 乘积Petri网中的变迁
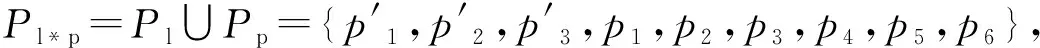
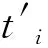
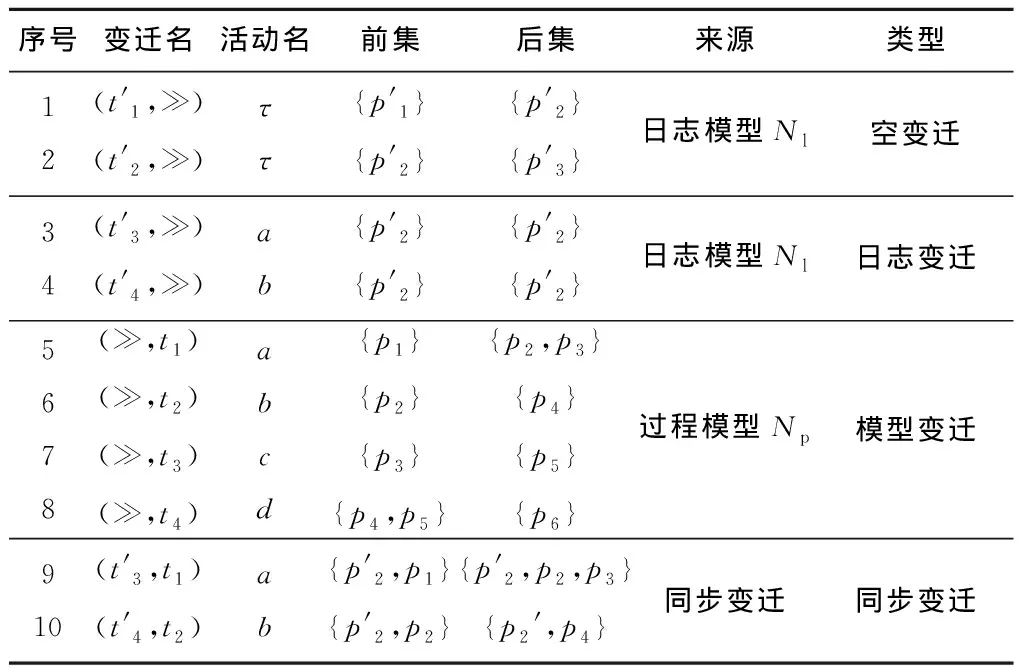
表2 乘积模型Nl*p中的变迁
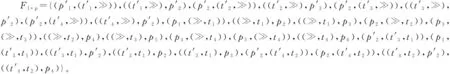
经过上述运算过程,计算得到花型日志模型Nl和过程模型Np之间的乘积模型Nl*p,如图3所示。显然,乘积模型也是一个Petri网。
2.4 乘积模型的可达图
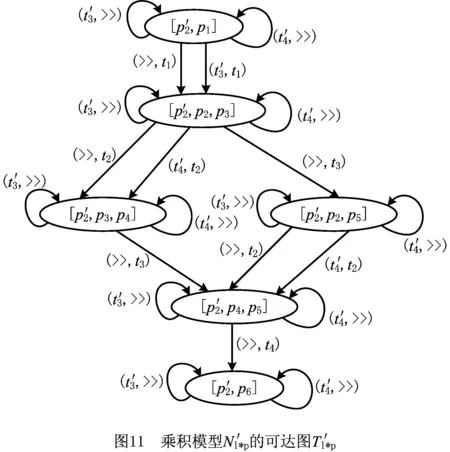
接下来,计算花型日志模型Nl与过程模型Np之间乘积模型Nl*p的可达图。从初始状态[p1′,p1]开始,依次引发Petri网中的使能变迁,记录所有可达状态及引发的变迁,得到乘积模型Nl*p的可达图Tl*p,如图4所示。Petri网的可达图是一个有向图,又称为变迁系统。可达图显式地描述了Petri网中变迁的引发过程及可达状态。图4中,节点代表Petri网的可达状态,由库所多重集表示;节点之间的边由状态之间的引发变迁进行标注;无起点箭头所指向的节点为初始状态;双圈节点代表乘积模型的结束状态。
给定事件日志与过程模型,日志中迹与模型之间的对齐就直接转变成在乘积模型中计算完整变迁引发序列的问题,而完整变迁引发序列就对应了乘
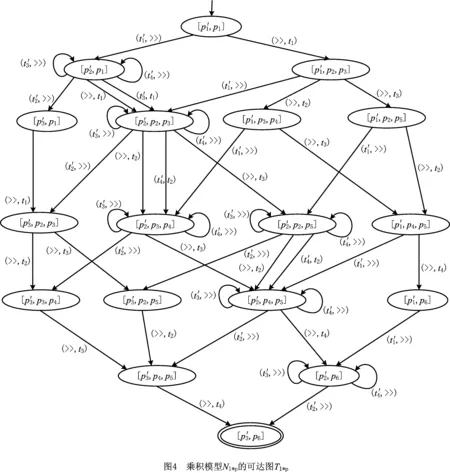
积模型可达图中一条从初始节点到结束节点的路径。因此,可以将计算事件日志与过程模型之间最优对齐的问题转化为计算Petri网中最小代价引发序列的问题。
由表1可知,乘积模型中变迁可分为日志变迁、模型变迁、同步变迁和空变迁4种类型,其中空变迁又包括日志空变迁和模型空变迁。4类变迁均可映射为不同类型的移动。根据标准似然代价函数为4类变迁赋予权值,其对应关系如表3所示。
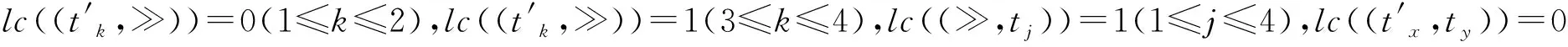

表3 变迁上权值的分配情况
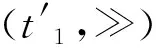
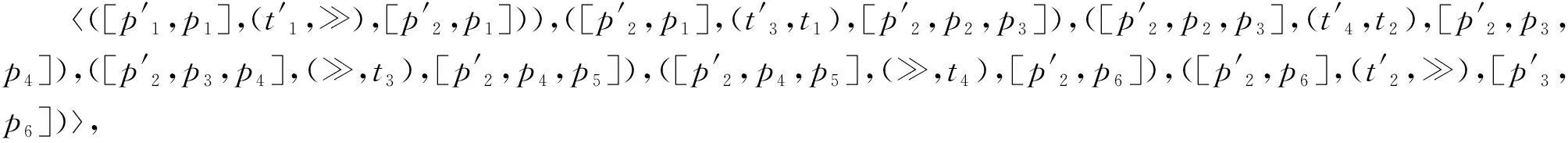
1.2.1 DNA提取 用含枸橼酸钠抗凝剂的真空采血管,分别采集患儿及其父母外周静脉血5ml,应用试剂盒 (采用美国OMIGA公司E.Z.N.A Blood DNA试剂盒)提取DNA,提取步骤参照试剂盒说明;取适量DNA用紫外分光光度进行定量和纯度检测,其余保存于-20℃备用。
定义4对齐。设A是一个活动集合。σ∈A*是A上的迹,N=(P,T;F,α,mi,mf)是Petri网。迹σ与网N之间的对齐γ∈(A≫×T≫)是一个移动序列,该序列满足下述条件:
由于问卷都是针对各外语院系整体课程状况展开,只有掌握和了解本单位的总体情况,才能填写好此问卷。因此,问卷由各高校外语院系的负责人,或者是文化课程的负责人填写。由于目前我国的英语专业分布在不同类型的高等院校中,受到各院校办学特点的影响,英语文化课程的设置也不尽相同。为了能够全面了解不同类型高校英语专业文化课程建设情况,本研究对5类高等院校进行了分层抽样:综合类院校、理工类院校、外语类院校、师范类院校和其他类院校共计40所,涵盖了985院校、211院校、全国重点和普通院校。
2.5 可达图的性质研究
事件日志中包含了所记录案例的多项信息。本文忽略每个案例的时间戳、资源等属性,只考虑活动。因此,迹都是若干活动组成的序列。假设S为一个集合,给定S上的序列σ,运算∂set(σ)的功能是将序列σ转换为相应的集合[24]。S*为S上所有有限序列的集合。
证毕。
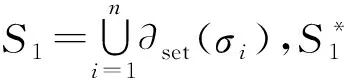
证明假设γ=(a1,t1),(a2,t2),…,(an,tn)(n≥1),其中ai∈S1∪{≫}(1≤i≤n),tj∈T2∪{≫}(1≤j≤n)。根据对齐的定义,γ一定满足以下两个公式:①π1(γ)↓S1=σ1;②根据花型日志模型的结构特点可知,活动标签和变迁是一一对应的(不可见变迁和除外)。即是一个双射函数,则存在逆函数根据上述γ满足的两个公式,存在使得且即根据乘积模型的定义,由此可见,γ′是乘积模型N3的一个完整变迁引发序列,对应可达图T3中从初始节点到结束节点的一条路径λ。将和从λ中删除,并将λ中剩余变迁全部映射到对应的移动,得到新的序列λ′=f(λ)=(a1,t1),(a2,t2),…,(an,tn)。可见,λ′=γ。
在过程模型中,不可见变迁一般用来为“改变过程状态却不能在信息系统中直接被观察到的行为”建模。当过程模型中存在不可见变迁时,本文将该类变迁在乘积模型中生成的新变迁称作模型空变迁。此类空变迁对应的移动在定义4中被称作模型移动,但为了表示其没有任何可观察行为发生的特性,本文将其称作模型空移动。日志空变迁和模型空变迁统称为空变迁,日志空移动和模型空移动统称为空移动。
小说家又说:“日本童话大师安房直子有一篇童话《狐狸的窗户》,讲述了一个小狐狸开了一家印染店的故事。如果小狐狸不狡猾,它能开成印染店吗?”女孩似乎听明白一些,点点头,而富翁却像听傻了一般,双眼直勾勾地盯着小说家。
根据花型模型的结构特点,花型日志模型不仅可以重演事件日志中观察到的所有迹,还可以重演事件日志活动子集上所有有限序列。根据花型模型的重演能力,可以得到花型日志模型与过程模型的乘积模型及其可达图的一些性质。
对表1 的数据进行分析归纳整理,企业领导人员网络培训面临的主要问题主要在以下五个方面:一是教育培训信息化建设(平台+管理)需加强,新信息技术、新媒体应用不充分;二是资源建设(课程资源)不足,资源共享难;三是网络教学方式方法创新不够;四是与干部员工职业发展需求的关联度有待提升;五是与建立兼容、开放、共享、规范的干部网络培训体系的目标还有差距。
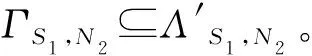
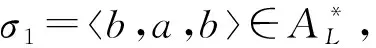
推论1给定∀σ1∈L1,假设γ∈Γσ1,N2,则使得γ=λ′。
推论2给定σ1∈L1和似然代价函数lc(),假设则使得γ=λ′。
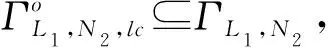
推论2说明,给定事件日志与过程模型之间基于似然代价函数的最优对齐可以在可达图中找到,为后面的最优对齐查找工作奠定了理论基础。
3 最优对齐查找算法
通过第2章的方法可以得到花型日志模型与过程模型之间乘积模型的可达图。在该可达图基础上,根据标准似然代价函数,借助查找初始节点到结束节点之间最短路径的思想,能够找到给定迹与过程模型之间的最优对齐。本章将提出两个算法,分别实现事件日志中全部迹与模型之间基于标准似然代价函数的一个最优对齐和所有最优对齐的计算。
由于可达图中大部分节点不只一个父节点,甚至有些节点存在自环,以致于在查找最优对齐的过程中,可能由不同分支到达同一状态节点。虽然二者对应的状态节点是同一个,但是代表的含义却完全不同。因为查找时所达的状态还和当前对齐及当前代价等信息有关,所以查找过程中对于每一步查找产生的信息,不仅要记录可达状态,还要记录前缀对齐、代价等。在此将存储这些信息的单位称为查找节点。为了将查找过程中产生的查找节点与可达图中的可达状态节点明确区分,后文将可达图中的可达状态节点称作可达状态,简称状态。而节点指的是查找过程中生成的查找节点。
3.1 一个最优对齐的查找算法
由推论2可知,事件日志中任意迹与模型之间基于给定代价函数的最优对齐均可在可达图中找到。根据2.4节的分析,可将最优对齐的计算问题转换为可达图中最短路径的查找问题。但是因为事件日志中不只一条迹,任取可达图中初始状态到结束状态之间的一条路径,其对应的未必是所求迹的对齐,更未必是最优对齐。如果只是单纯的求可达图中初始状态到结束状态之间的最短路径,得到的很有可能并非所求迹的最优对齐。为了能够计算某条确定迹的最优对齐,在遍历可达图中的路径时,不仅要尽量查找最短路径,还要保证变迁序列在第1列的投影转换成活动序列后是所给迹的前缀。下面给出算法1,实现事件日志中全部迹与过程模型之间的一个最优对齐的计算。
算法1计算事件日志L1中每条迹与过程模型N2之间基于标准似然代价函数lc()的一个最优对齐。
输入:事件日志L1,标准似然代价函数lc(),事件日志花型模型N1与过程模型N2之间乘积模型N3的可达图T3;
输出:事件日志L1中每条迹与过程模型N2之间的一个最优对齐。
步骤1对事件日志L1中所有迹σk(1≤k≤|L1|),依次执行步骤2~步骤12。
步骤2优先队列queue初始化为空。
步骤3生成一个查找节点,该节点具有3个属性,其初始值分别设置如下:状态为mi,3,前缀对齐设置为,代价值为0;并将该查找节点放入优先队列queue。
步骤4当优先队列queue不为空时,执行步骤5。
步骤5对优先队列queue中所有查找节点node进行如下检查:将该节点前缀对齐在第1列投影得到的序列长度存储于变量a,代价值存储于变量c,选取c-a值最小的节点node作为当前节点curnode,并将该节点从队列queue中删除。
步骤6对当前节点curnode的状态属性m在可达图中对应的所有出边(m,tk,mk)及其对应的可达状态m[tk>mk进行考察,转步骤7;若所有后继可达状态都已被检查,转步骤4。
步骤8若状态mk为mf,3,则转步骤9;否则转步骤10。
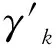
步骤12将该节点放入队列queue;转步骤6。
在算法1中,以c-a的最小值作为选择当前节点的基准。其中:c为节点的代价值,a为节点的前缀对齐在第1列投影所得序列的长度。该基准的选择有利于最优对齐查找算法的尽快结束。根据标准似然代价函数,c值表示对齐中偏差的个数,在查找最优对齐时,其值越小越好;a值表示当前已经观察到的迹中的活动个数,其值越大说明迹中已经比对过的活动越多,而剩余需比对的活动越少。因此,节点的c-a值最小,在一定程度上说明该节点的前缀对齐中出现的偏差少但完成的对齐工作多,该节点更容易尽早到达结束状态,并获得最优对齐。
当给定迹与过程模型之间的一个对齐查找结束时,a必然为固定值即给定迹的长度。因此,在查找给定迹的对齐时,如果查找过程中遇到多次满足到达结束状态且前缀对齐在第1列的投影为给定迹的情况,则第1次得到的c值肯定是最小的,即查找过程中找到的第1个符合结束条件的对齐就是要查找的最优对齐。
下面以本文第2章事件日志Ll中迹σ1=a,b和图4所示可达图Tl*p为例说明算法1执行一遍的查找过程。此例中以标准似然代价函数为偏差的衡量标准,即在对齐序列中,同步移动和空移动的代价均为0,模型移动和日志移动的代价均为1。该查找过程存储可达图中可达状态生成查找节点的顺序与连接关系,如图7所示,图中每个查找节点对应的详细信息如表4所示。
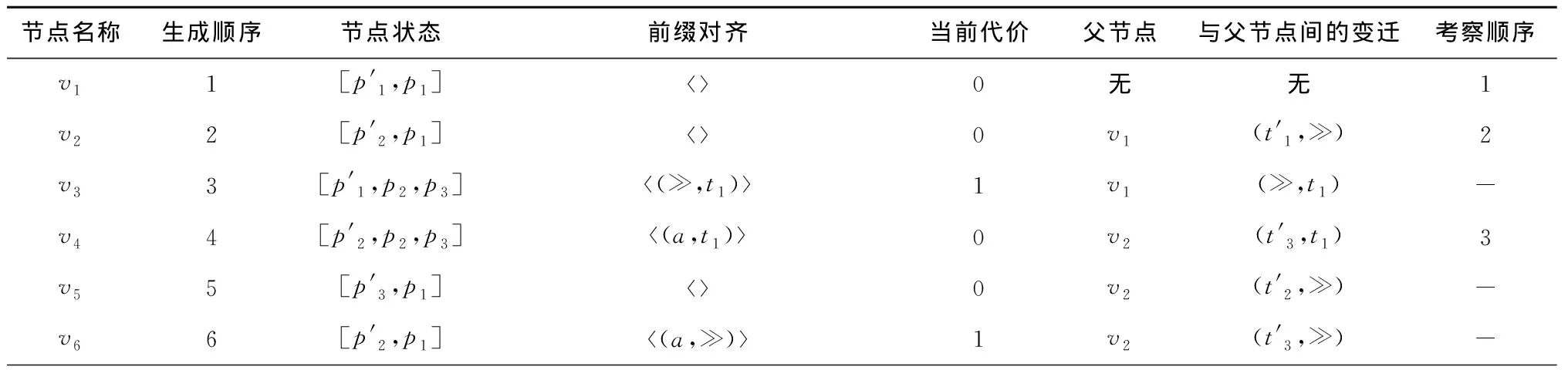
表4 迹σ1与过程模型Np之间一个最优对齐的查找节点属性
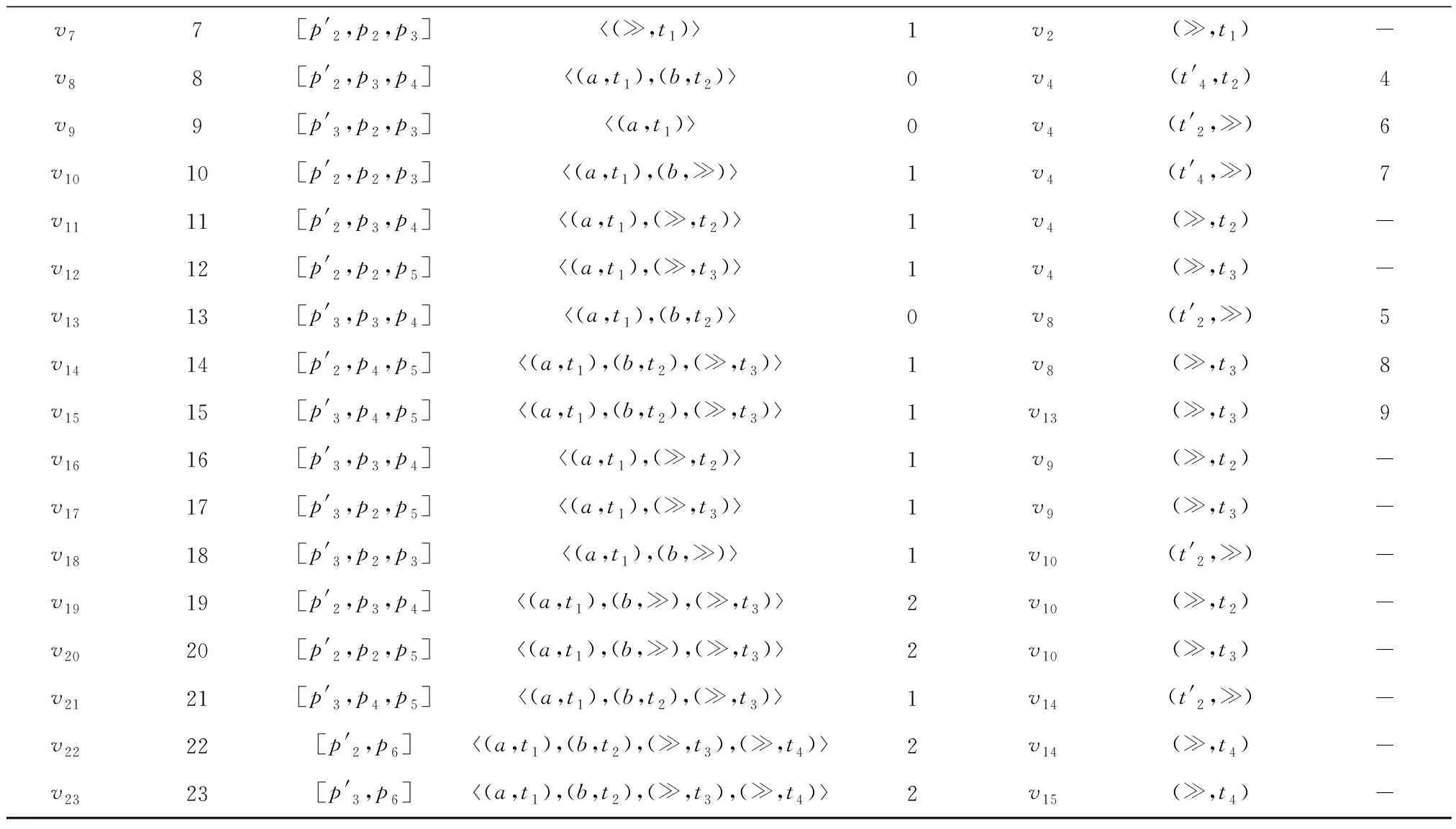
续表4
该查找过程具体执行步骤如下:
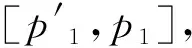
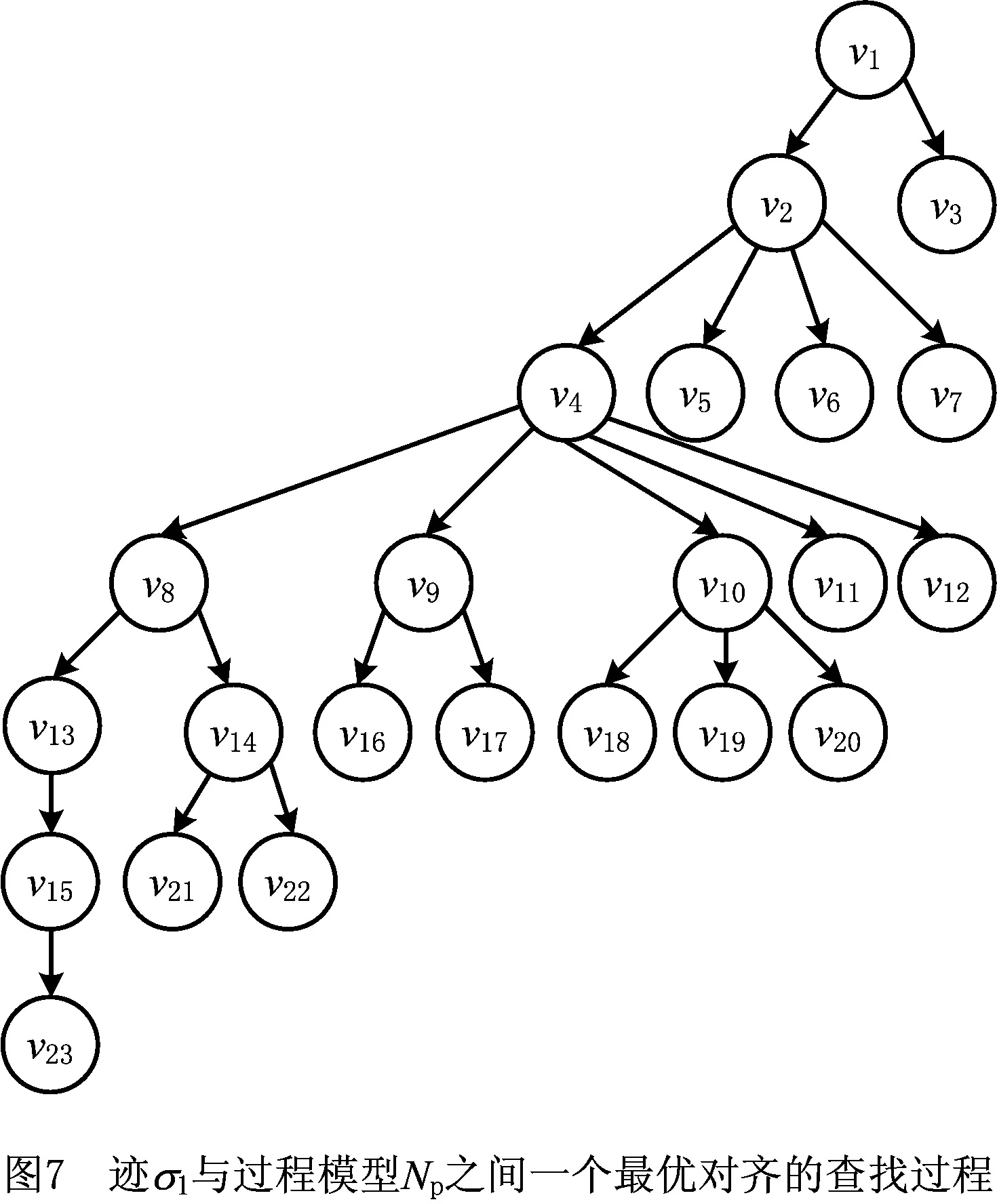
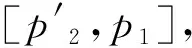
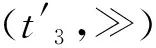
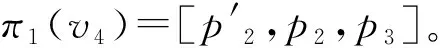
(5)从queue的节点v3、v5、v6、v7、v8、v9、v10、v11、v12中选取c-a值最小的v8作为当前节点,并将v8从queue中删除。在可达图中考察状态π1(v8)的出边及后继状态,生成新节点v13、v14,并放入队列queue。
(6)依此类推,依次从queue中选取节点v13、v9、v10、v14作为当前节点,并分别生成节点v15,v16、v17,v18、v19、v20,v21、v22,放入队列queue。
在算法1中,由于每个节点都存储了前缀对齐,最终找到状态为结束状态而前缀对齐在第1列的投影为迹本身时,其存储的前缀对齐即为要求的最优对齐。在查找过程中生成的查找节点凡是已经考察过的就可以舍弃,无需保存,从而大大节省了算法的存储空间。另外,算法1中将节点的代价值与前缀对齐在第1列投影的序列长度之差作为当前节点的选择标准,在一定程度上提高了找到最优对齐对应结束状态的效率。
3.2 所有最优对齐的查找算法
由于可达图中包含了事件日志中所有迹与过程模型之间的所有对齐,基于给定代价函数在可达图中进行最优对齐的查找时,若不加最优代价值的约束,将会得到所有对齐,而不只是最优对齐。因此,在第1次得到迹的最优对齐时,其代价值就是迹与模型之间基于给定代价函数的最优代价值,后面得到的代价值均小于等于该值。另外,对于代价小于或等于最优代价值的节点必须全部检查后,才能确定是否找到了所有的最优对齐。若一个节点对应的代价值大于最优代价值,则该节点永远都无法到达对应最优对齐的结束状态。下面给出算法2,计算事件日志中每条迹与过程模型之间基于标准似然代价函数的所有最优对齐。
算法2计算事件日志L1中每条迹与过程模型N2之间基于标准似然代价函数lc()的所有最优对齐。
输入:事件日志L1,标准似然代价函数lc(),事件日志花型模型N1与过程模型N2之间乘积模型N3的可达图T3;
输出:事件日志L1中每条迹与过程模型N2之间的所有最优对齐。
步骤1对事件日志L1中每条迹σk(1≤k≤|L1|)执行步骤2及以后操作;若所有迹均已考察完,则转步骤16。
步骤2优先队列queue初始化为空;设置最优代价值cost为+∞。
步骤3生成查找节点,该节点具有3个属性,其初始值分别设置如下:状态为mi,3,前缀对齐设置为,代价值为0;并将该查找节点放入优先队列queue。
步骤4当优先队列queue不为空时,转步骤5;否则,转步骤1,准备查找下一条迹的所有最优对齐。
步骤5对优先队列queue中所有查找节点node进行如下检查:将该节点前缀对齐在第1列投影得到的序列长度存储于变量a,代价值存储于变量c,选取c-a值最小的节点node设置为当前节点curnode,并将该节点从队列queue中删除。
步骤6对当前节点curnode的状态属性mk在可达图中的所有出边(mk,tk,j,mk,j)及其对应的可达状态mk[tk,j>mk,j进行考察,转步骤7;若所有后继可达状态均已被检查,则转步骤4。
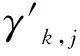
步骤9若状态mk,j为mf,3,则执行步骤10;否则,转步骤13。
步骤12找到当前迹σk的一个最优对齐γk,j,将其并入集合Γk;准备查找该迹下一个的最优对齐,转步骤4。
步骤15将该节点放入队列queue,转步骤6。
步骤16返回事件日志L1中每条迹σk的最优对齐集合Γk,算法结束。
该算法还可以进一步优化,如在生成新的后继节点时,若队列中存在与即将生成的新节点状态相同且前缀对齐相同的节点,则无需生成新节点。这样可以减少优先队列中后继待考察节点的个数,提高算法的执行效率。关于算法的简化问题,留待以后进行研究。
就本文给出的算法1和算法2而言,因为涉及到可达图中状态的遍历问题,而且有些状态不仅被访问一次,甚至还会被访问多次,所以算法时间复杂度较高。因此,本文中关于在可达图中查找一个最优对齐和所有最优对齐的算法依然是一个NP-hard问题。
采用算法2,可在可达图Tl*p中计算出迹σ1=a,b与过程模型Np之间基于标准似然代价函数lc()的全部最优对齐。该最优对齐结果如图8所示,查找过程所经过的路径与最优对齐之间的对应情况如表5所示。
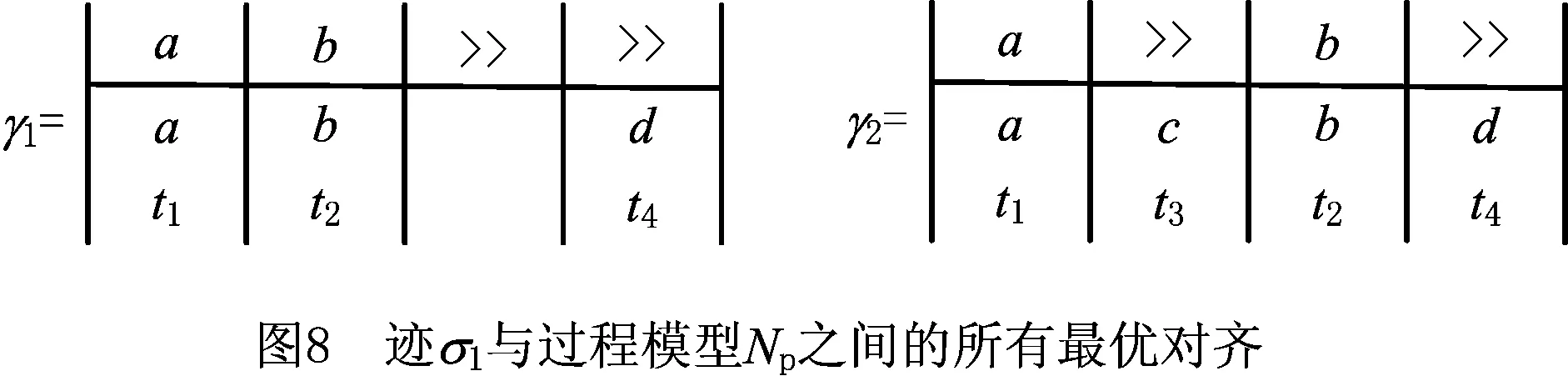
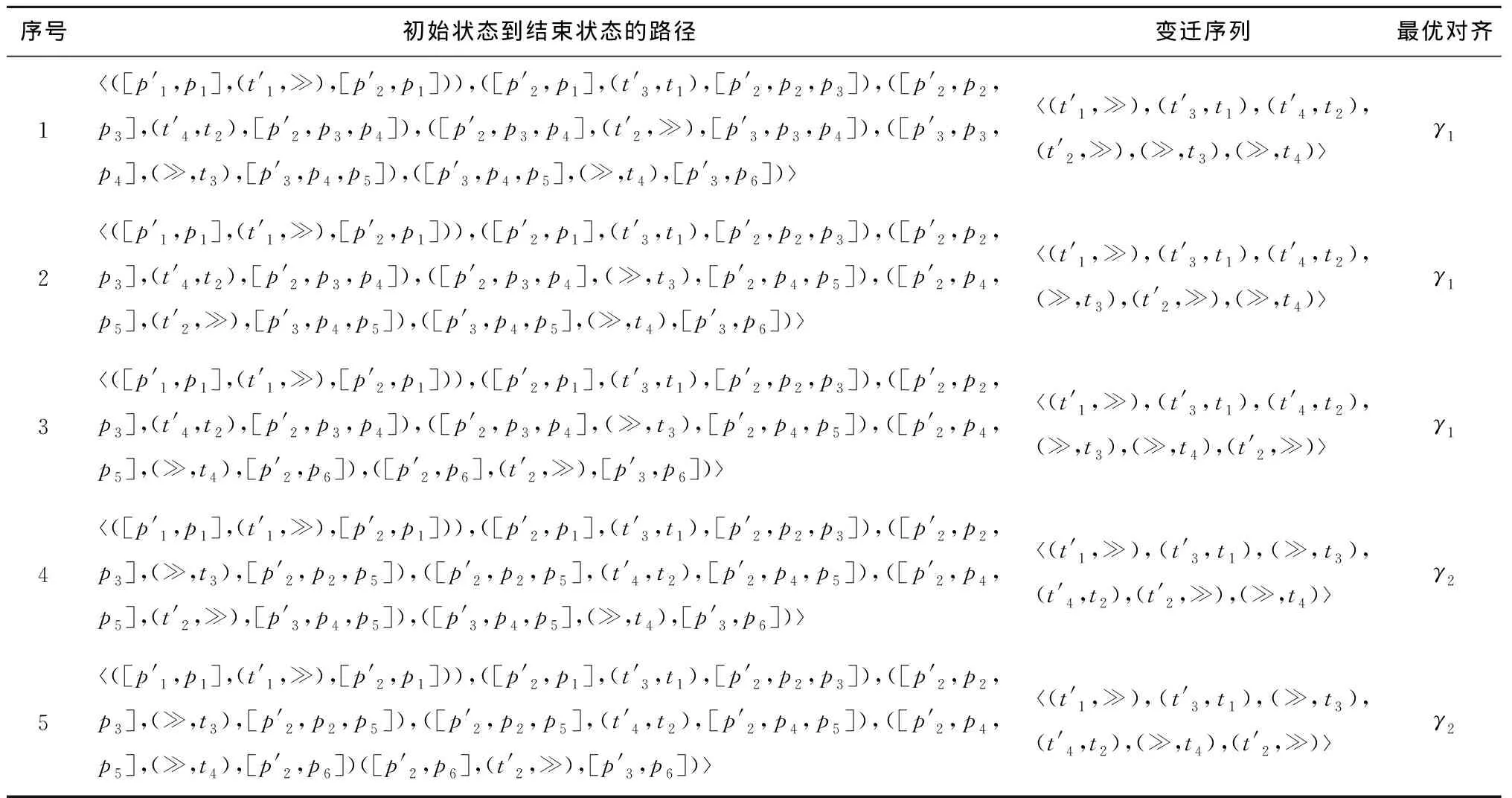
表5 可达图Tl*p中路径与最优对齐之间的对应关系
该例子验证了可达图中从初始状态到结束状态的路径包含了迹与过程模型之间基于给定代价函数的所有最优对齐。但是,由表5可以看出该方法存在下述问题:可达图Tl*p中初始状态到结束状态之间的多条路径对应着迹σ1与过程模型Np之间基于代价函数lc()的同一个最优对齐。同一最优对齐的多次重复出现,很大程度上降低了算法的执行效率。造成这个问题的主要原因是乘积模型中空变迁的存在。空变迁在路径中的位置不同,会形成不同的路径。但是当路径映射成移动序列时,空变迁对应着空移动,即没有任何移动,会导致不同路径映射到同一对齐。如表5所示,路径1和路径2都映射到最优对齐γ1,路径3、路径4和路径5都映射到最优对齐γ2。
当只查找一个最优对齐时,空变迁在对齐序列中的位置在合理范围内发生变化时不会影响对齐结果的性质就导致了算法1在执行时生成较多查找节点,从而降低了算法1的执行效率。同理,当查找所有最优对齐时,算法2的执行效率也会受到空变迁的影响而大幅度下降。为了解决该问题,简化最优对齐的查找过程,下面给出一个优化方案。
4 对齐方法的优化方案
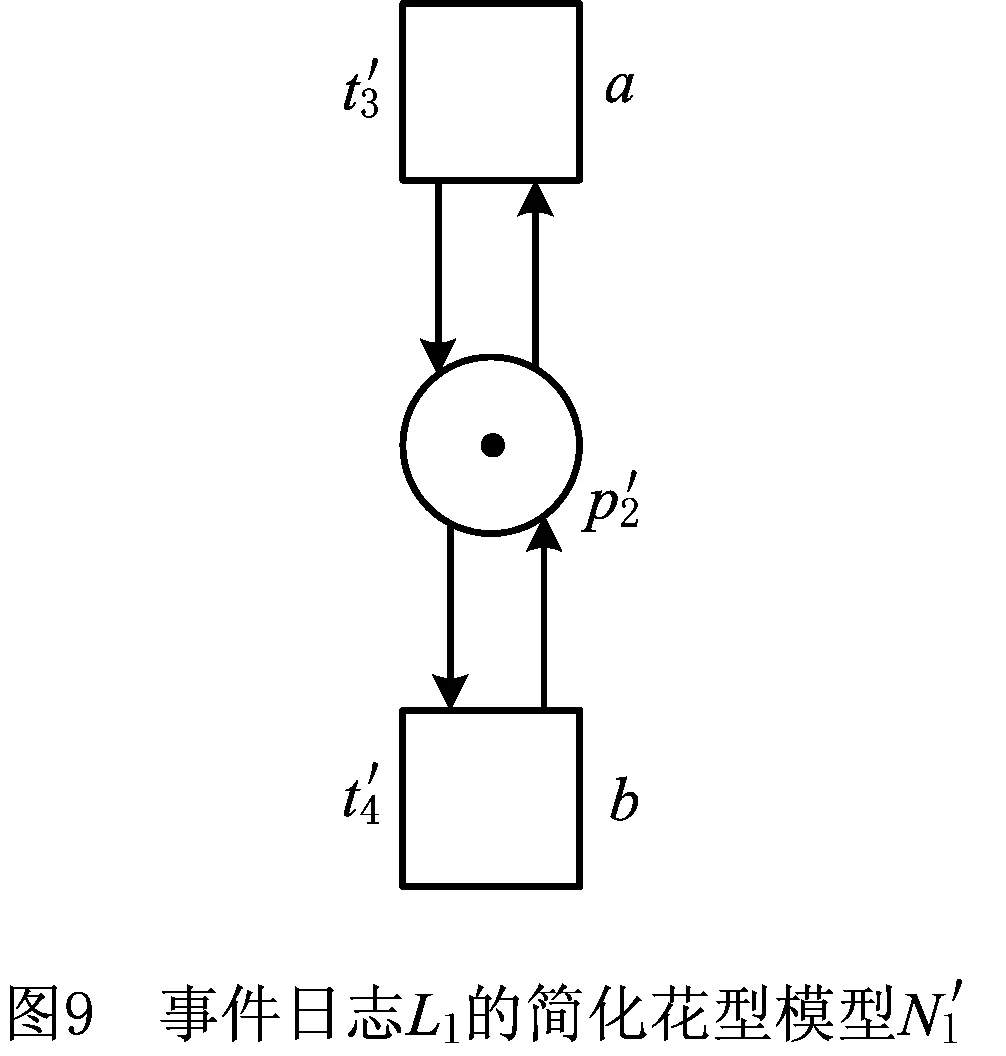
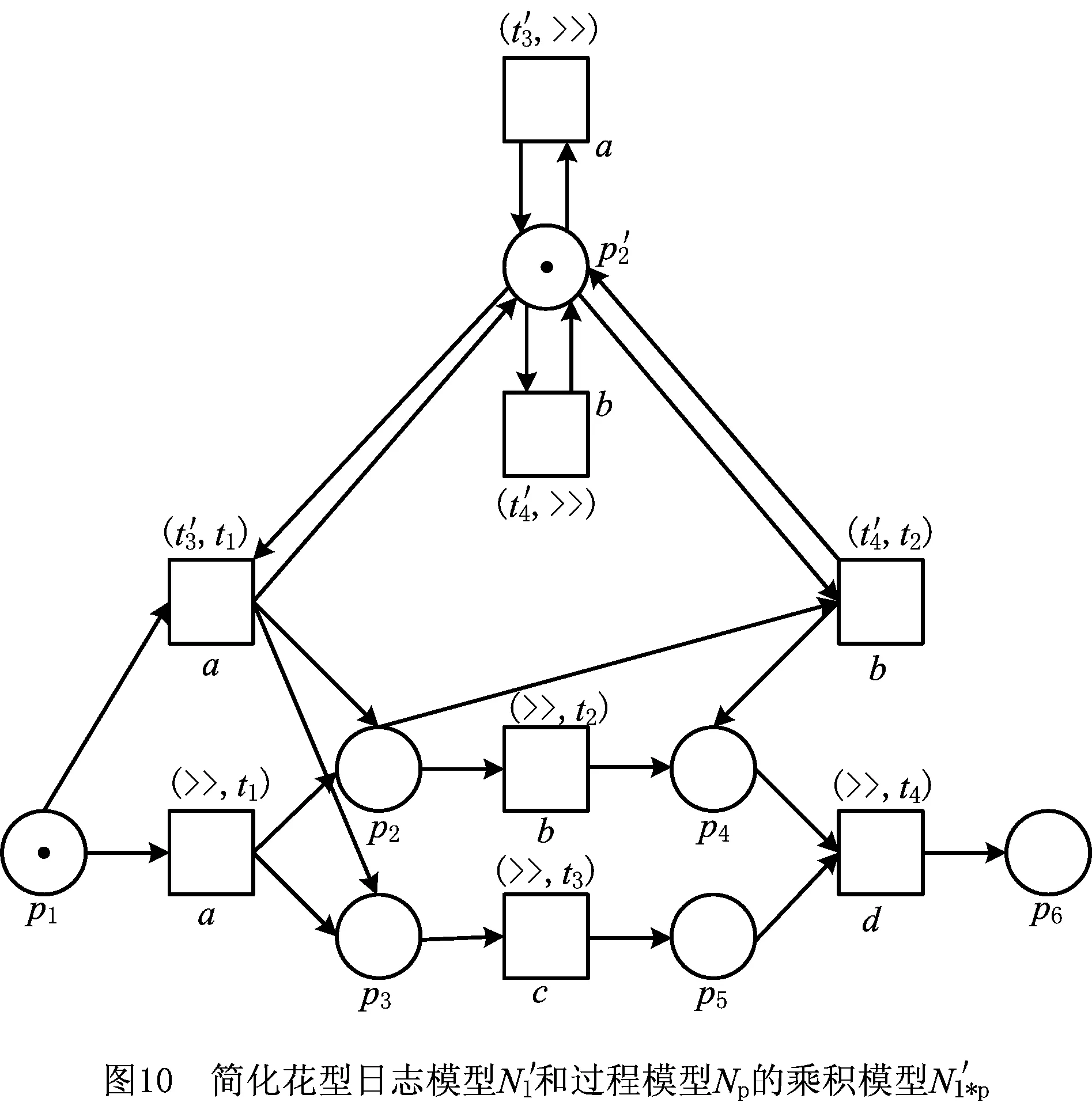
根据事件日志的活动子集构建日志模型时,为了使日志模型符合合理工作流网的定义,在构建花型日志模型时,添加了开始库所、结束库所、不可见变迁等元素。但这些元素的添加其实对于花型日志模型重演迹的能力并没有任何影响。为了简化生成乘积模型及其可达图的规模,在实际实现该方法时,采用简化花型日志模型。仍以本文2.1节中给出的事件日志Ll为例,其简化花型日志模型如图9所示。为了沿袭上述文中内容,简化模型中的变迁及库所标号保持和图1所示模型Nl一致。
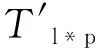
5 仿真实验
2.5节已经从理论角度说明了基于Petri网可达图的业务对齐方法的正确性。3.1节和3.2节分别给出实例分析,验证了该方法的有效性与合理性。本章将给出一些仿真实验结果,并与A*对齐方法的相关部分进行比较来评价该方法,说明该方法的优越性。
无论是A*对齐方法还是基于Petri网可达图的对齐方法均包含查找空间的生成和最优对齐的查找两个步骤。其中:查找空间的规模从一定程度上决定了最优对齐查找的复杂程度。本实验重点考察了查找空间即可达图的大小及生成时间,可间接说明最优对齐查找的复杂程度,代表整个对齐方法的性能。因此,仿真实验考察的重点在于:①日志模型与过程模型之间的乘积模型所包含的库所数和变迁数;②乘积模型的可达图中的状态数;③计算可达图所花费的时间。通过对上述内容进行研究,验证该方法的优越性。
在本仿真实验中,A*对齐方法和基于Petri网可达图的对齐方法的源程序均采用C++语言编写实现,在Microsoft Visual C++ 6.0环境下运行。
下面分析煤矿斜巷运输安全的实际运行情况[32],并利用Petri网对其进行建模。给出一个基于Petri网的煤矿斜巷运输监控系统的简单模型,如图12所示。该模型包含一个表示开始的库所p1,一个表示结束的库所p14,模型中任一库所或者变迁均在从p1到p14的一条路径上。且该模型满足安全性、恰当完成、可完成、无死变迁等性质。因此,该模型是一个合理的工作流网。
图12中库所和变迁所代表的实际含义分别如表6和表7所示。另外,图12中每个变迁都映射到一个标签活动,其对应情况如表7所示。
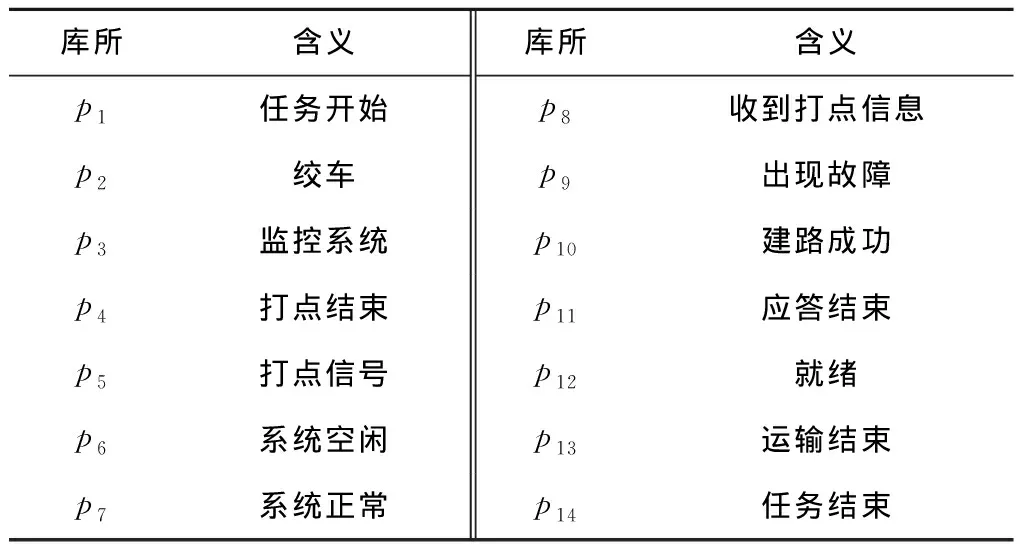
表6 模型Ns中库所及其含义
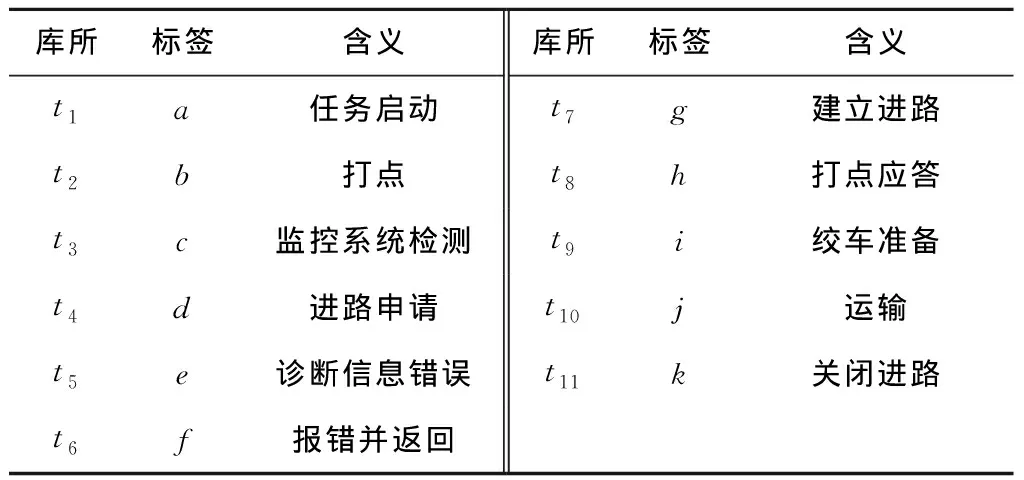
表7 模型Ns中变迁及其含义
由该过程模型随机生成一些活动序列组成事件日志,并与已知过程模型进行分析。由过程模型生成完全拟合且长度不同的迹,每条迹大约包含9~15个活动,并通过随机删除以及添加活动在迹中制造噪音。在添加活动时,未出现模型中变迁映射的活动名之外的其他活动名,即迹中每个活动均是集合A={a,b,c,d,e,f,g,h,i,j,k}中的元素。然后,基于标准似然代价函数计算全部迹与过程模型之间的一个最优对齐。统计乘积模型中库所个数、变迁个数、可达图中节点个数以及计算可达图花费的时间等,以比较A*对齐算法和基于Petri网可达图的对齐方法在计算事件日志中所有迹和过程模型之间对齐时的优劣。
本仿真实验共生成4个事件日志,每个事件日志包含5条不同的迹。4个事件日志中5条迹的平均长度分别为6、9、12、15。每次实验的结果数据都是相同实验做10次的平均性能。A*对齐方法和基于Petri网可达图的对齐方法的对比结果如表8~表10所示。其中,表8显示了两种对齐方法之间乘积模型的库所数和变迁数的比较结果,表9显示了两种方法可达图状态数的比较结果,表10显示了两种方法在乘积模型的基础上生成可达图所需时间的比较结果。表8和表9说明了两种方法占用存储空间的对比情况,表10说明了两种方法花费时间的对比情况。

表8 A*对齐方法与基于Petri网可达图的对齐方法之间乘积模型的比较
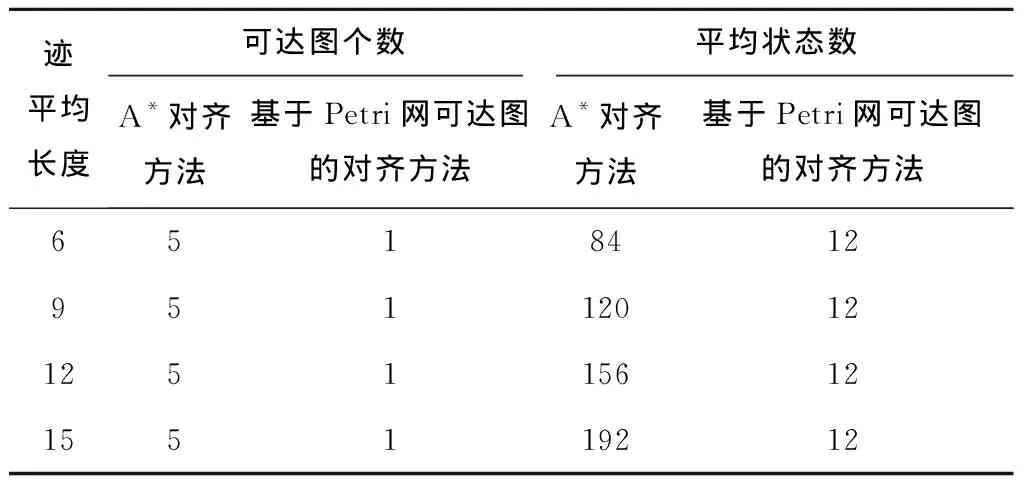
表9 A*对齐方法与基于Petri网可达图的对齐方法之间可达图的比较
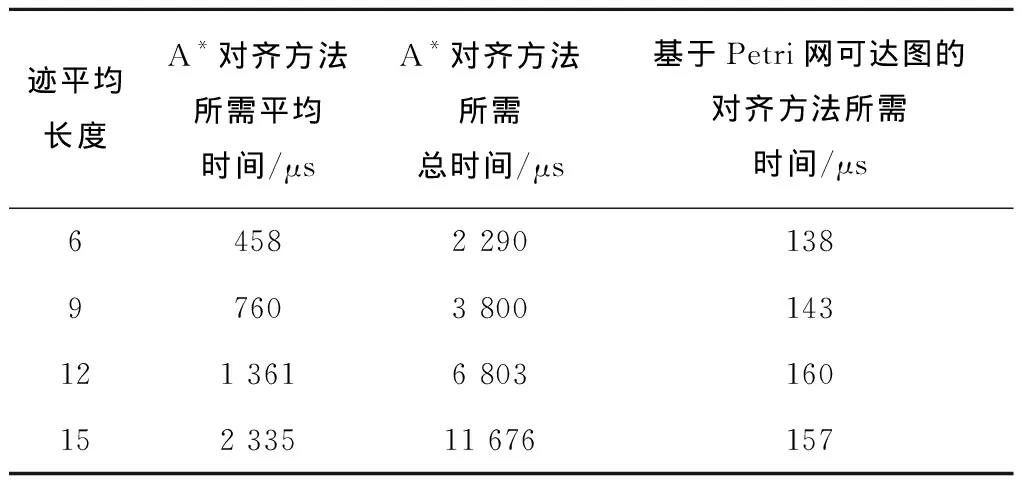
表10 A*对齐方法与基于Petri网可达图的对齐方法之间计算可达图所需时间的比较
由表8和表9可知,当一个事件日志中包含5条不同的迹时,若采用A*对齐方法计算事件日志中迹与过程模型之间的对齐,则需要建立5个乘积模型,对应5个可达图。而采用基于Petri网可达图的对齐方法只需建立1个乘积模型,相应的只有1个可达图。
另外,从表8和表9可以看出,当事件日志中迹的平均长度增长时,A*对齐方法中得到的乘积模型的库所数和变迁数,以及可达图的状态数均会呈线性增长。而基于Petri网可达图的对齐方法中得到的乘积模型的库所数和可达图的状态数均为常数,保持不变,且其值比A*对齐方法要小很多。基于Petri网可达图的对齐方法中得到的乘积模型的变迁数在迹较短时,其值比A*对齐方法的平均值要大。且随着迹的平均长度的增加,其值递增。但是,当迹的平均长度达到一定值时,基于Petri网可达图的对齐方法中得到的乘积模型的变迁数的值也会成为一个固定值,不再发生改变。如表8中,当迹的平均长度为12、15时,基于Petri网可达图的对齐方法中得到的乘积模型的变迁数固定为33。即使迹的平均长度继续增加,只要迹中活动均在集合A中,则该变迁数将继续保持为33。
由上述分析可知,当事件日志中有m条不同的迹时,基于Petri网可达图的对齐方法只需计算1个乘积模型和1个可达图,而A*对齐方法需要计算m个乘积模型和m个可达图。一般情况下,基于Petri网可达图的对齐方法得到的乘积模型比A*对齐方法得到的乘积模型的库所数和变迁数少得多,且基于Petri网可达图的对齐方法得到的可达图比A*对齐方法得到的可达图的状态数要少得多。表8和表9的比较结果说明基于Petri网可达图的对齐方法占用的存储空间比A*对齐方法要小得多。
表10第2列记录了A*对齐方法计算1个乘积模型的可达图时所花费的时间,第3列记录了A*对齐方法计算5个乘积模型的可达图时所花费的时间。因此,迹平均长度相同时,第3列的数值是第2列数值的5倍。无论事件日志中有多少条迹,基于Petri网可达图的对齐方法只需计算1个乘积模型和1个可达图,因此该方法只记录了一列数值。在实际运算时,需要比较的是基于Petri网可达图的对齐方法计算1个可达图所需时间和A*对齐方法计算5个可达图所需时间。即在迹平均长度相同时,通过比较第4列的时间和第3列的时间可知,基于Petri网可达图的对齐方法计算可达图所需的时间远远小于A*对齐方法。而通过比较第4列的时间和第2列的时间可以发现,A*对齐方法计算1个可达图的时间也要比本文所提方法所需时间大很多。表10的比较结果说明了基于Petri网可达图的对齐方法所花费的时间比A*对齐方法要小。因此,基于Petri网可达图的对齐方法的性能优于A*对齐方法。
6 结束语
随着企业组织中记录的事件日志越来越多,事件日志与过程模型之间的合规性检查在过程挖掘中发挥的作用越来越重要。目前,对齐作为合规性检查的一种重要手段,由于其能准确定位偏差,衡量观察行为和建模行为之间的拟合程度,在挖掘算法、精确度检查、模型修复等方面具有广泛的应用。现有对齐方法一般只能计算迹与过程模型之间的一个最优对齐,甚至只能得到次优对齐。而Adriansyah等提出的A*对齐方法虽然能够计算出迹与过程模型之间基于代价函数的所有最优对齐,但是该方法每次计算一条迹与过程模型之间的最优对齐时都需要复杂的预处理工作。该预处理工作包括生成迹对应的日志模型与过程模型之间的乘积模型及其可达图。若要使用A*对齐方法计算事件日志中所有迹与过程模型之间的对齐,则需多次调用预处理方法,生成多个日志模型与过程模型之间的乘积模型及其可达图。该过程需占用较多的存储空间与计算时间。
为了解决上述问题,本文提出了A*对齐方法的扩展方法——基于Petri网可达图的业务对齐方法。本方法不再以一条迹生成的顺序结构的事件网作为日志模型,而是以事件日志的活动子集构建的花型模型作为日志模型。然后,计算花型日志模型与过程模型之间的乘积模型以及该乘积模型的可达图。该可达图包含事件日志中所有迹与过程模型之间的对齐。无论事件日志中包含多少条迹,该方法的预处理工作只需计算1个乘积模型和1个可达图。最后,提出算法1和算法2在可达图中根据前缀对齐的查找结果,找到事件日志中全部迹与过程模型之间基于给定代价函数的一个最优对齐和所有最优对齐。
该方法有效地解决了A*对齐方法预处理时,效率低、内存占用多等问题,提高了计算最优对齐的效率。将事件日志中所有迹与过程模型之间的对齐情况都体现在了一个可达图中,简化了计算最优对齐时的查找空间。但该方法存在一定的问题,即若采用符合合理工作流网定义的花型日志模型,则会造成空间的浪费,并增大查找时间。针对上述问题,本文提出一种优化方案,可以有效降低算法的空间和时间复杂度,但该优化方案中所采用的简化花型日志模型不符合合理工作流网的定义。因此,在今后的工作中,将根据事件日志建立更合理的日志模型,进一步提高查找算法的执行效率。
猜你喜欢
小学生学习指导(中年级)(2021年3期)2021-04-06 09:12:08
电子器件(2021年1期)2021-03-23 09:24:02
小资CHIC!ELEGANCE(2019年32期)2019-11-22 07:56:49
数学年刊A辑(中文版)(2018年1期)2019-01-08 01:58:22
纺织学报(2016年8期)2016-07-12 13:28:41
数学学习与研究(2015年15期)2015-05-30 01:17:26
数学年刊A辑(中文版)(2014年2期)2014-10-30 01:40:54
华侨大学学报(自然科学版)(2014年4期)2014-10-11 06:23:42
浙江理工大学学报(自然科学版)(2014年1期)2014-05-25 00:35:47
吉林大学学报(工学版)(2014年1期)2014-04-12 00:32:08
