
基于二次分解的改进时间序列超短期风速预测研究
2020-08-05 13:36南宏钢乔锦涛
华北电力大学学报(自然科学版) 2020年4期
赵 征, 南宏钢, 乔锦涛
(华北电力大学 控制与计算机工程学院,河北 保定 071003)
0 引 言
截止2019年年底,我国风电累计并网装机容量达到210.05 GW,占全部发电装机容量的10.4%[1],风电已经成为继火电、水电之后的第三大能源。风速作为影响风功率的第一大因素,然而风速具有的随机性、非平稳性给电力系统的安全稳定运行带来极大的冲击与挑战,因此准确预测风速对电网的正常运行至关重要[2]。
根据风速预测模型的不同,风速预测方法主要有物理学方法、统计学方法及组合方法[3]。
物理学方法需要丰富的气象数据与大量的机组技术参数[4],建模过程复杂。而统计学方法[5]利用风速历史数据,建立系统输入与输出之间的映射关系,从而对未来风速趋势做出预测,建模过程简单可行。统计学方法中时间序列分析法主要有:自回归滑动平均法[6]、自回归差分滑动平均法[7]、广义自回归条件异方差法[8]等。组合方法虽然在一定程度上能够提高模型的预测精度,但是加权系数的强壮性一直是这类方法的瓶颈[9]。
考虑到时间序列法采用风速历史数据,建模简单计算量少,其本身所具有的时序性和自相关性已经为建模及预测提供了足够的信息,适用于超短期及短期预测。ARIMA模型用于刻画时间序列的自相关性;GARCH模型用于刻画时间序列的波动性[9]。文献[10]建立了超短期风速预测的ARIMA-GARCH模型,并且对GARCH模型中的条件方差进行加权混合修正,以此来提高预测精度,但是考虑到风速的波动性较强,该模型并未对原始风速数据进行预处理。文献[11]建立了短期风速预测的CEEMDAN-QGA(quantum genetic algorithm, QGA)-BP(back propagation, BP)模型,但是并未考虑到原始风速序列经CEEMDAN分解后,高频分量仍存在较大的随机性,对其进行VMD分解可有效地降低随机性。二次分解[12]体现了对原始数据处理的“精细化”思想。
鉴于以上考虑,本文提出了一种基于CEEMDAN-VMD二次分解的ARIMA-GARCH超短期风速预测模型。首先对原始风速数据进行CEEMDAN分解,采用样本熵评估各分量的复杂性,对复杂性高的分量进行VMD分解。二次分解后的各分量作为ARIMA-GARCH预测模型的输入,将所有分量预测值线性叠加得到最终预测结果。
1 基本方法原理
1.1 自适应噪声完整集成经验模态分解
自适应噪声完整集成经验模态分解[13]在原始信号x[n]中添加满足标准正态分布的高斯白噪声ω[n],则第i次的信号可以表示为xi[n]=x[n]+ωi[n](i=1,…,I),其中,I为实验次数,CEEMDAN算法步骤如下:

(2)在r1[n]中添加白噪声,即分解r1[n]+ω1[n],(i=1,…,I),得到第2个模态分量IMF2及余量r2[n]。
(3)重复步骤(1)、(2)。当分解出的剩余分量不适合被分解时,停止分解。最终原始信号可表示为
(1)
式中:K为分解后本征模函数的数量。
1.2 变分模态分解
变分模态分解[14]的核心是变分问题的构造与求解。变分问题可表述为:经VMD分解后得到若干个模态的估计带宽最小,并且所有模态可以重构为原信号。
VMD算法步骤如下:
(1)计算调制信号梯度的平方L2范数,对各模态信号带宽进行估计,即
(2)
式中:{uk}表示各模式的集合;{ωk}表示各模式的中心频率;δ(t)表示冲激函数;f表示原始信号。
(2)加入二次惩罚因子α和拉格朗日算子λ(t)将原问题转换为非约束变分问题。即
(3)
式中:二次惩罚项提高了惩罚项有限权重的收敛性,拉格朗日乘子用于执行约束。

(4)
(5)
(6)
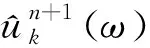
收敛准则:

(7)
2 CEEMDAN-VMD-ARIMA-GARCH预测模型
2.1 自回归差分滑动平均模型
自回归模型AR(p),是利用时间序列当前时刻值及其滞后p阶的历史信息建立多项式来刻画时间序列的特征,具体表达式如下:
ut=c+φ1ut-1+φ2ut-2+…+φput-p+εtt=1,2,…,T
(8)
式中:c为常数项;φ1,φ2,…,φp为多项式系数;εt为服从εt~N(0,σ2)的白噪声。
滑动平均模型MA(q),是利用时间序列当前时刻值及其滞后q阶的历史信息建立加权多项式来刻画时间序列的特征,具体表达式如下
ut=μ+θ1εt-1+θ2εt-2+…+θqεt-q+εtt=1,2,…,T
(9)
式中:μ为常数项;θ1,θ2,…,θq为多项式系数;εt为服从εt~N(0,σ2)的白噪声。
自回归滑动平均模型ARMA(p,q)是AR(p)模型与MA(q)模型的组合,具体表达式如下:
(10)
ARMA模型适用于解决平稳过程的时间序列,对于非平稳时间序列需要进行差分运算,该模型变为自回归差分滑动平均模型。
dYt=Wt
(11)
式中:Wt为非平稳时间序列Yt经过d阶差分后得到的平稳时间序列;d为d阶差分算子。
2.2 模型定阶
模型定阶用于确定平稳时间序列模型(ARMA)的阶数。本文采用贝叶斯信息准则[15](bayesian information criterion,BIC)确定模型阶数。BIC信息准则相较于AIC(akaike information criterion, AIC)信息准则具有更低的阶数。BIC信息准则为
(12)

2.3 参数估计
参数估计用于确定ARMA模型中的未知系数φ1,φ2,…,φp和θ1,θ2,…,θq。常用的参数估计方法有矩估计法、最大似然估计法及最小二乘估计法。矩估计法运算繁琐且无法得到全局最优解。最大似然估计法难以将似然函数转化为参数的显示函数。本文采用最小二乘估计法估计模型未知参数。
2.4 异方差性检验
若时间序列模型方差不是常数,其大小随时间变化且与过去的误差有关,表明该模型的残差具有异方差性。自回归条件异方差模型(autoregressive conditional heteroskedastictiy,ARCH)通过描述方差的变化规律,对原模型的残差序列进行优化。在此基础上波勒斯莱文进行改进,建立广义自回归条件异方差模型。标准的GARCH(1,1)模型为
(13)

ARCH LM检验[16]经常被用来检验模型残差中是否具有异方差特性,原假设为
H0:α1=α2=…=αq=0
(14)
LM检验统计量TR2为样本长度乘以回归检验R2,渐进服从χ2(p)分布,其中p为χ2分布的自由度。给定置信区间,当TR2>χ2(p)对应的临界值时,则拒绝原假设,证明存在异方差效应。
2.5 CEEMDAN-VMD-ARIMA-GARCH预测模型
针对风速时间序列的随机性、非平稳性,本文提出了CEEMDAN-VMD-ARIMA-GARCH预测模型。图1为预测模型流程图。模型预测步骤如下:
(1)原始风速序列经过CEEMDAN分解,获得含剩余分量在内的n个分量。
(2)采用样本熵[17]评估各分量的复杂性。针对复杂度相对较高分量进行二次分解-VMD分解。判断经二次分解后各分量的平稳性及模型的残差特性,分别建立对应的ARIMA-GARCH预测模型。
(3)对复杂度相对较低各分量分别判断平稳性及残差特性,建立ARIMA-GARCH预测模型。
(4)将所有分量的预测值叠加,得到最终风速预测值。

图1 CEEMDAN-VMD-ARIMA-GARCH预测模型流程图Fig.1 CEEMDAN-VMD-ARIMA-GARCH forecast model flow chart
3 算例实现
本文选用西北某风电场1月1日至3日连续3天的风速数据作为实验样本,采样时间间隔为5 min,共有864个数据点,预测未来3 h风速。
3.1 CEEMDAN分解风速序列
CEEMDAN能够较好地解决EMD(empirical mode decomposition, EMD)、EEMD(ensemble empirical mode decomposition, EEMD)中出现的模态混叠现象。CEEMDAN分解样本数据,原始风速分解结果如图2所示。
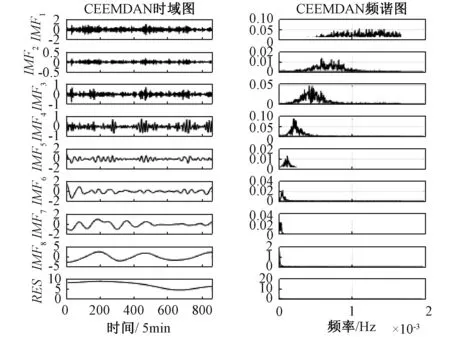
图2 CEEMDAN分解结果图Fig.2 CEEMDAN decomposition result chart
图2中,原始风速序列被分解为8个波动较小的IMF分量和1个剩余分量RES。结合时域图与频谱图,不同分量的主频率成分不同,对应时域的波动性不同。前3个分量的主频率成分不单一,说明它们仍然具有较高的复杂度。为了提高模型预测精度,本文采用样本熵评估分量的复杂性,具体结果如图3所示。
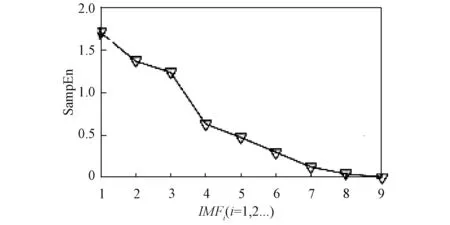
图3 各子分量样本熵值Fig.3 Entropy of each subcomponent sample
从图3各子分量样本熵值可以看出,前3个分量的样本熵值较高,熵值均高于1。从第4个分量开始熵值急剧减小,其中第4个分量熵值约为0.6,远小于第三个分量的熵值。综上所述,认为前三个分量是复杂度相对较高分量。
3.2 VMD二次分解
本文对IMF1、IMF2、IMF3三个样本熵值较高的分量进行VMD二次分解。
首先确定IMF1分量VMD分解的层数K。由于VMD分解层数需要人为确定,文献[19]提出了一种较为便捷的模态数K的选取方法,其基本思想是考虑VMD分解之后各模态的中心频率互不相同,如果出现相邻两个模态之间中心频率相近,则认为出现过分解。文献[19]中认为当前分解层数减1作为最佳分解层数。本文选用该方法来选取VMD的分解层数。此外,VMD分解的初始其他参数中,α取值1 000,τ取0。IMF1分量VMD分解不同K值下的中心频率如表1所示。
从表1可以看出,当K=4时,相邻两个模态分量中心频率的距离最小值为198×10^(-6)。与模态数K=2,K=3的中心频率距离值有明显的区别。可以认为此时属于模态“接近”情况。此外,考虑到的运算效率,VMD的分解层数也不应该过大。因此,我们认为模态数K=4时,VMD分解属于过分解。因此,模态数K选择3。K选择3时,IMF1分量的VMD分解图如图4所示。
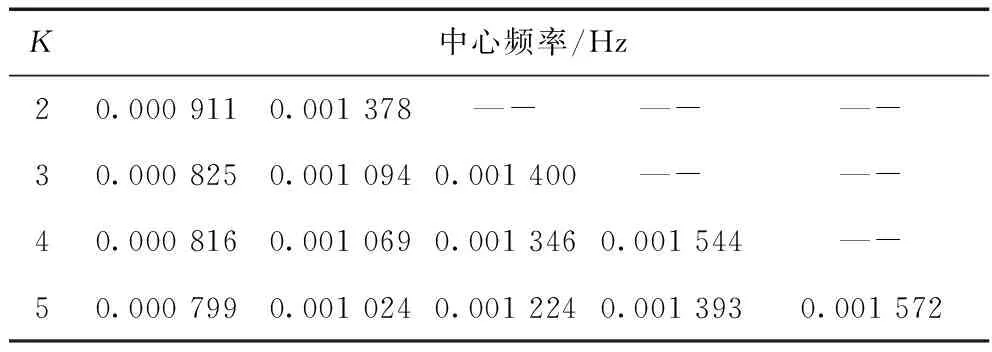
表1 IMF1分量VMD分解不同K值下的中心频率
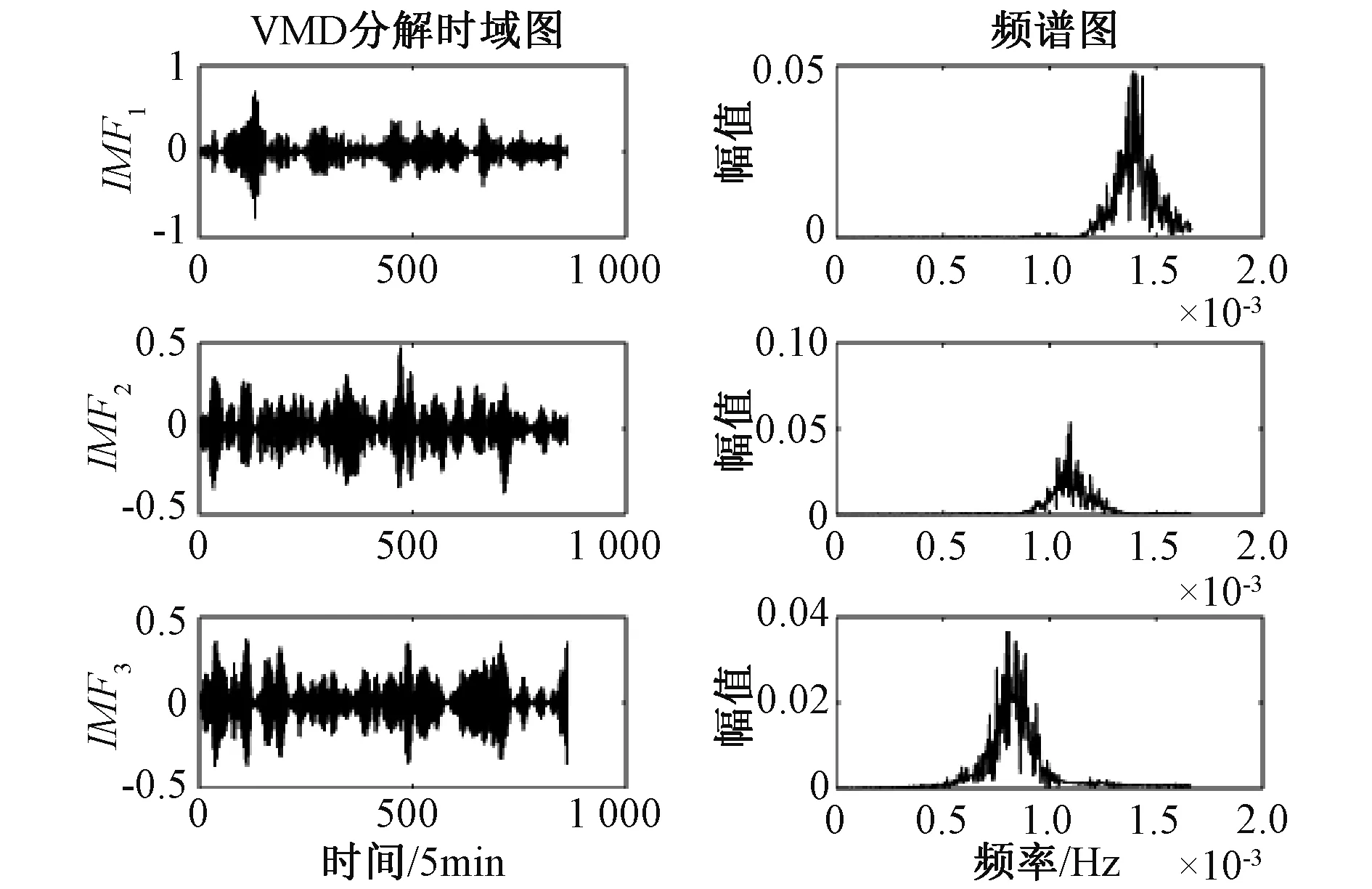
图4 IMF1模态数K为3时VMD分解图Fig.4 VMD decomposition diagram when IMF1 modal number K is 3
同理,对IMF2、IMF3分别进行VMD分解,经过分析不同分解层数K对应的中心频率,IMF2分量VMD分解层数K选择2较为合适,IMF3分量VMD分解层数K选择2较为合理。
至此,原始风速数据经过CEEMDAN-VMD二次分解后共有13个分量,其对应的样本熵值如图5所示。
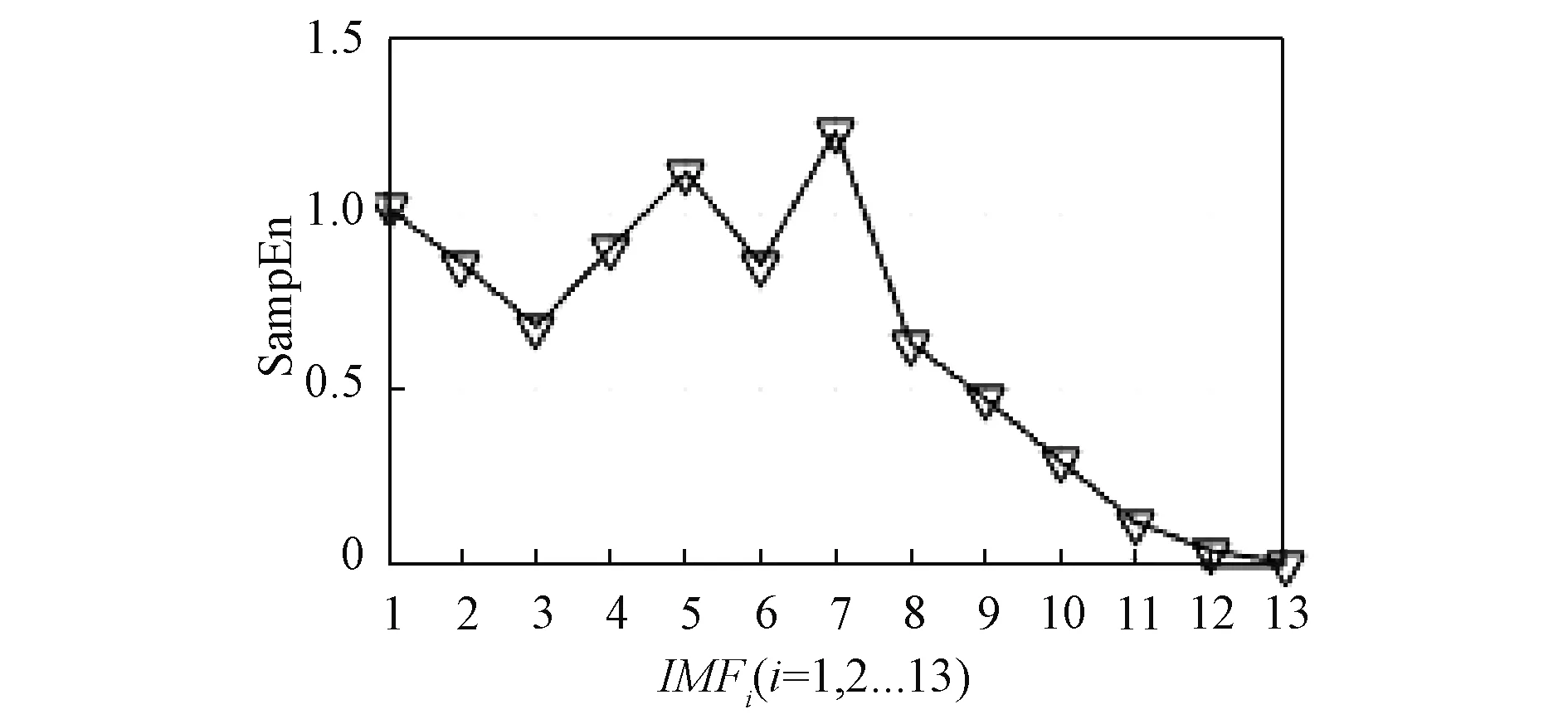
图5 CEEMDAN-VMD二次分解各分量样本熵值Fig.5 CEEMDAN-VMD quadratic decomposition of each component sample entropy
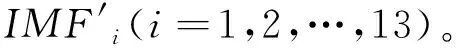
3.3 模型定阶
建立预测模型之前,每个时间序列需要进行平稳性检验。经ADF(augmented dickey-fuller test, ADF)检验,13个分量均为平稳时间序列,分别建立ARMA模型。


表2 根据BIC准则确定ARMA阶数表

表3 CEEMDAN-VMD二次分解各分量模型阶数表
3.4 异方差性检验

表4 ARCH LM检验表
表4中,统计量TR2服从卡方分布,对应的值为15.883 9,小于置信水平5%对应卡方分布的临界值,不拒绝原假设,表明序列具有异方差性。
考虑到高阶GARCH模型的参数估计过程较为复杂,因此对各分量ARMA模型拟合残差建立GARCH(1,1)模型进行修正。其余12个分量采用相同的方法进行ARCH LM检验。
3.5 误差评价指标
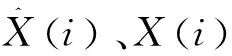
(15)
(16)
(17)
(18)
3.6 不同模型预测结果比较
本文模型CEEMDAN-VMD-ARIMA-GARCH处理原始风速时间序列,得到3 h风速预测值。为了对比验证所提方法的有效性,本文建立了对比模型一:CEEMDAN-ARIMA-GARCH预测模型;对比模型二:原始风速-ARIMA-GARCH模型。原始风速作为ARIMA-GARCH预测模型的输入,得到风速的预测结果。三种模型预测结果如图6所示。

图6 三种模型预测结果对比Fig.6 Comparison of prediction results of three models
图6中,采用三种不同的数据分解策略,构建相同预测模型得到不同的预测结果。观察图中曲线,采用原始风速序列直接建立预测模型,虽然预测值能够整体反映真实值的变化趋势,但其结果始终存在较大的滞后;采用数据分解时,CEEMDAN分解、CEEMDAN-VMD二次分解的预测曲线都能够有效地克服滞后,预测值始终能够及时地反映出真实值的变化。但当真实风速值发生较大的突变时,采用CEEMDAN单一数据分解方法所得预测结果与真实风速之间存在较大的偏差,在时刻点3、15处表现尤为明显。比较前两种方法,利用CEEMDAN-VMD二次分解所得预测结果既能克服预测存在的滞后现象,又能在风速存在大幅变化的时刻有较为良好的预测效果。表5列出了本文所提模型的误差指标。为了更直观地体现本文所提模型的有效性,在表5中用预测模型代替ARIMA-GARCH模型。

表5 模型预测误差
从表5可以看出,直接采用原始风速序列建立预测模型,其效果最差;CEEMDAN-ARIMA-GARCH模型预测效果次之;本文所提模型CEEMDAN-VMD-ARIMA-GARCH模型预测效果最好,能够有效地提高预测精度。
4 结 论
本文针对风速具有随机性、非平稳性的特点,提出了CEEMDAN-VMD-ARIMA-GARCH预测模型,有效地提高了风速时间序列预测的准确性。通过仿真对比实验,得到以下结论:
(1) CEEMDAN分解能够消除模态混叠现象,具有优良的分解效果;
(2) 以样本熵判断各分量的复杂程度,将复杂性较高的分量进行VMD二次分解,可以进一步降低信号的复杂性,与CEEMDAN分解和ARIMA-GARCH相结合的模型比较,平均绝对误差减少了7.1%;
(3) 本文考虑了对原始风速序列二次分解处理,引入GARCH模型用于修正时间序列模型残差序列的异方差性,但是并没有考虑GARCH模型的修正。因此,今后重点考虑对GARCH模型的修正进而提高预测精度。
猜你喜欢
科学技术创新(2022年15期)2022-05-18
中学生数理化(高中版.高考数学)(2021年3期)2021-06-09
科学与财富(2020年24期)2020-10-27
读者·校园版(2020年19期)2020-09-16
当代陕西(2019年19期)2019-11-23
智族GQ(2019年9期)2019-10-28
电子制作(2019年11期)2019-07-04
英美文学研究论丛(2018年1期)2018-08-16
初中生世界·九年级(2017年10期)2017-11-08
中学生数理化·八年级数学人教版(2016年5期)2016-08-23
