
大数据时代档案信息资源共享平台数据挖掘模型的研究与实现
2020-07-23 07:08卞咸杰
档案管理 2020年4期
卞咸杰

摘 要:随着大数据时代技术的不断发展以及档案信息资源数据不断积累,如何利用档案信息资源大数据进一步提升档案服务能力,促进档案智能化管理能力提升,已经成为档案部门的当务之急。在描述数据挖掘相关概念的基础上,通过对数据挖掘技术在档案信息资源共享平台中应用的研究,从数据挖掘模型的确立、档案信息资源数据选择和档案信息资源数据源创建等方面,论述平台数据挖掘模型的建立,并在数据挖掘模型功能模块、数据挖掘模型处理流程、数据挖掘模型样本准备、预测模型创建和剖析模型集创建等方面进行实践,验证该模型的可行性,为实现档案信息数字化全面发展的目标提供了更为有效的科学方案。
关键词:大数据;档案信息资源;共享平台;数据挖掘;模型构建
Abstract:With the continuous development of technology in the era of big data and the continuous accumulation of archive information resource data, how to use archive information resource big data to further enhance archive service capabilities and promote the intelligent management of archives has become a top priority for archives departments. On the basis of describing the relevant concepts of data mining, through the research on the application of data mining technology in the archive information resource sharing platform, from the establishment of the data mining model, the selection of archive information resource data and the creation of archive information resource data sources, etc. The establishment of the data mining model, and practice in the data mining model function module, data mining model processing flow, data mining model sample preparation, prediction model creation and profiling model set creation, etc., to verify the feasibility of the model, in order to achieve archive information. The goal of comprehensive digital development provides a more effective scientific solution.
Keywords:Big data; Archive information resources; Sharing platform; Data mining; Model building
随着数据技术的进步,数据价值在互联网时代吸引了越来越多的关注。行业大数据的研究应运而生,过去不同部门掌握的传统数据往往呈现出烟囱式孤岛效应,相互之间有着巨大的关联价值却不能得到充分利用[1],档案信息资源方面尤为明显,档案行业的信息化建设快速发展,数字档案资源极大丰富,档案数据挖掘成为了學界和业界研究的新方向[2]。信息技术的发展与进步,对档案信息、数据进行深度的挖掘,使得档案信息管理的各个要素形成内在联系,充分实现档案信息资源的共享[3],用户对档案服务要求的不断提升,相关高层级的共享平台建设也逐渐完善,平台投入应用之后,档案信息资源数据也急剧增加。目前对档案信息资源数据的应用主要集中在现有数据的维护与检索方面,数据挖掘的过程不仅仅是表层对数据的数值分析,更是基于内容的深层语义知识发现[4]。如何将现有的档案信息数据利用效率最大化,数据挖掘的作用会显现出来,从数据流挖掘的角度来看,大数据档案信息资源数据挖掘处理是一个巨大的挑战[5],通过档案信息数据研究,并找出有价值的信息成为大数据平台建成后需要重点关注的方向。通过档案信息资源数据挖掘模型建立与实现,可以给档案信息资源共享平台提供数据挖掘方案作参考。
1 数据挖掘相关的概念
档案信息资源共享平台中的数据可以是结构化的,如关系型数据库中的数据,也可以是半结构化的,如文本、图形和图像数据,甚至是分布在网络中的非结构化数据[6]。数据挖掘是指从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、潜在有用的信息和知识的过程[7]。数据挖掘技术包括统计分析、序列模式发现、数据挖掘等[8],对于档案信息资源共享平台数据挖掘,包含预测任务和描述任务两大类任务[9]。首先需要根据现有的档案信息资源数据特点,建立数据分类,该分类作为预测目标数据的参考,分类任务完成后,需要通过回归方式,来预测连续的目标参考数据;其次需要将档案信息数据中联系的方式进行标准化描述,如趋势、轨迹等,数据挖掘任务的细化通常是探查性的工作,一般需要经过后继数据处理来验证和解释前期数据挖掘的结果。
1.1 数据分析
随着信息技术的发展,数学与计算机科学相结合产生了数据分析分支。对于档案信息资源数据分析是采用合适的统计分析方法对收集来的档案信息资源数据进行自动化分析,将采集到的数据加以汇总并得出统计报告信息,以求最大化地利用现有的档案信息大数据,发挥共享平台大数据的作用。档案信息资源数据分析是为了提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。传统的Excel自带的数据分析功能基本可以满足数据统计与数据分析的要求,该工具最终可以产生直方图、相关系数、协方差、各种概率分布、抽样与动态模拟、总体均值判断等内容。现代的数据分析一般借用数据库强大的数据分析功能,Microsoft SQL Server、Oracle等中大型数据库自带的数据分析工具,同时还可以根据需要配置数据报告。
1.2 数据挖掘
随着大数据技术及人工智能技术的成熟,对数据的利用需求日益增长,数据挖掘研究在此背景下成为热门的方向。从大量数据中挖掘出有用的信息,大数据的出现对传统的简单的数据挖掘算法提出挑战[10],档案信息资源的数据挖掘成为了当下热门的话题,所谓档案信息资源数据挖掘是指从档案信息共享平台大数据中发掘未知且不确定的并有潜在价值的信息的创造性决策支持过程,该过程依赖于数据库技术、人工智能技术、数理统计、模式识别、可视化技术等相关现代化科技[11]。在数据挖掘的过程中将由传统的半自动化向高度全自动化地分析档案信息资源数据,通过设定的策略进行推理,从中挖掘出潜在的有价值数据,帮助档案服务部门做出前瞻性决策。数据挖掘的对象不限源头数据类型,这对于多媒体化的档案信息资源特别有利,传统的档案信息资源一般采用结构化存储方式,因为其存在形式主要为文本格式。随着硬件设备配置的提升以及现代互联网技术的发展,档案信息资源的存在形式是多种形态并存,它可以是文本,图像、视频或结构化记录[12],如列表和表格,此类数据中也可以包含非结构化数据。
1.3 数据挖掘中常见的分析方法
决策树分析法。在档案信息资源数据归类与预测上有着极强的能力,该方法是以一连串的问题表示出来,经由不断询问问题,在该过程中不断优化流程,最终能引导出预定的数据信息。
神经网络分析法。该方法将一串待学习的档案信息资源数据提交给神经网络,使其归纳出有一定区分度的格式。若得到的是新的档案信息资源数据,神经网络即可以利用过去学习的成果并进行智能归纳后,推导出有价值的数据参考,自动学习推理的技能属于人工智能领域的一个分支,通过不断的数据学习,未来可以根据新提交的档案信息资源数据自动给出预测结果。
连接分析法。该方法是以数学领域中的图形理论为基础,由不同数据的关系发展出一个模式。该方法的核心是数据关系,由人与人、物与物或是人与物的关系可以发展出相当多的智能化应用,未来可以做出对档案服务能力提升更多的挖掘研究。
2 档案信息资源共享平台数据挖掘模型的建立
2.1 数据挖掘模型的确立
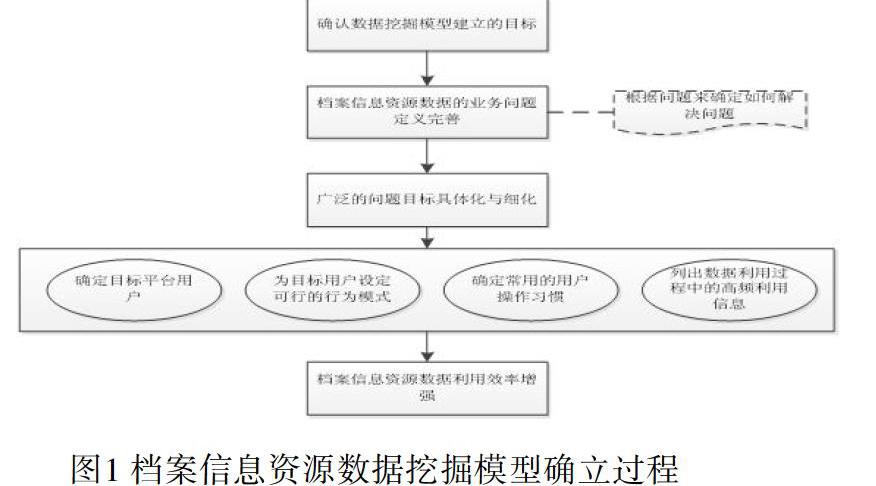
为了充分发挥档案信息资源共享平台的优势,要结合用户的实际需求建立完整的处理框架体系[13]。在实际做数据挖掘之前,首先需要确认数据挖掘模型建立的目标,在共享平台数据挖掘模型建立之前,将档案服务中涉及到档案信息资源数据的业务问题定义完善,然后根据问题来确定如何解决问题,将广泛的问题目标具体化与细化。在档案信息资源数据挖掘模型建立过程中,可以按照确定目标平台用户、为目标用户设定可行的行为模式、确定常用的用户操作习惯、列出数据利用过程中的高频利用信息、分析高频数据访问特点、为特定档案信息资源数据建立特殊访问通道,加强数据利用效率。具体确立流程如图1所示:
在此过程中通过中间模型来翻译输入数据变量与目标变量的关系,这一步非常重要,对数据挖掘对象和任务的理解程度需要正确且深入。如果这个问题没有被准确理解就无法把档案信息资源数据转化为挖掘任务。在实施数据挖掘任务之前,还需要明确如何使用档案信息资源数据挖掘结果以及确定交付结果的方式。
2.2 档案信息资源数据选择
档案信息资源数据存储点首先在共享平台所关联的大数据平台上,平台数据的大幅增加对平台自身来说是一项具有挑战性的任务[14],存储在仓库中的档案信息资源大数据在进入系统之前已经被清洗和核实过,共享平台会通过数据整合技术将不同的数据资源进行整合。数据在实际的整合过程中,会遇到相同的信息点名称但是表示不同的含义,这中间有一个数据迁移的过程,通过建立数据交互接口表,数据之间的信息互通将通过接口表信息完成信息翻译。数据选择与整理流程如图2所示:
在建模构建期间,需要准备足够的档案信息资源数据并注意数据库之间的平衡,这样对于数据研究更加便捷。特定数据在数据集合中的存在会产生更大的价值。数据挖掘的本质是使用过去的数据预测未来的趋势,针对档案信息资源的数据挖掘,历史上较新的信息对数据挖掘更加有价值,历史太过靠前的数据,由于其信息本身的附加属性信息较少,需要对这部分数据进行深加工,这样才能发挥更久历史的档案信息资源数据的价值。
2.3 档案信息资源数据源创建
在数据用于构建模型之前,数据探索方面需要得到足够的重视,不能等后继使用时才发现档案信息资源的数据质量问题,在具体的数据源创建过重中,可以遵循以下步骤执行:
检查档案信息资源数据分布情况,在数据库的初步探索阶段,可以借助可视化工具。现存的可视化工具如Excel对待挖掘的档案信息数据提供了强大的汇总分析支持。取得档案信息资源数据源中的数据文件后,需要对其中的内容进行剖析,剖析的过程中可能会产生不一致问题或定义问题的警告,需要对问题数据进行分析并解决警告,这样可以避免后继分析产生不必要的麻烦。
经过档案信息资源数据存储的值与描述进行比较与二次确认,并对档案信息资源大数据进行观察,将它们与现有文件中的变量描述进行比较,可以发现有问题的数据描述。确定档案信息资源存储的数据与所要描述的数据一致性是非常重要的,每条记录的字段定义信息要明确,这样才不会导致后继数据挖掘过程中的数据源头不一致错误。对存在问题的档案信息资源数据进行讨论研究,档案信息资源数据不同于普通业务系统的数据,其真实性与准确性要求非常高,如果存储系统中的数据看上去有存疑,需要记录下来。待问题数据积累到一定数量后进行沟通讨论,研究出问题源头,在今后的数据创建过程中避免问题的产生,这项工作需要耐心和细心,对档案信息数据挖掘的成果尤为重要[15]。
3 档案信息资源共享平台数据挖掘模型的实现
3.1 数据挖掘模型功能模块
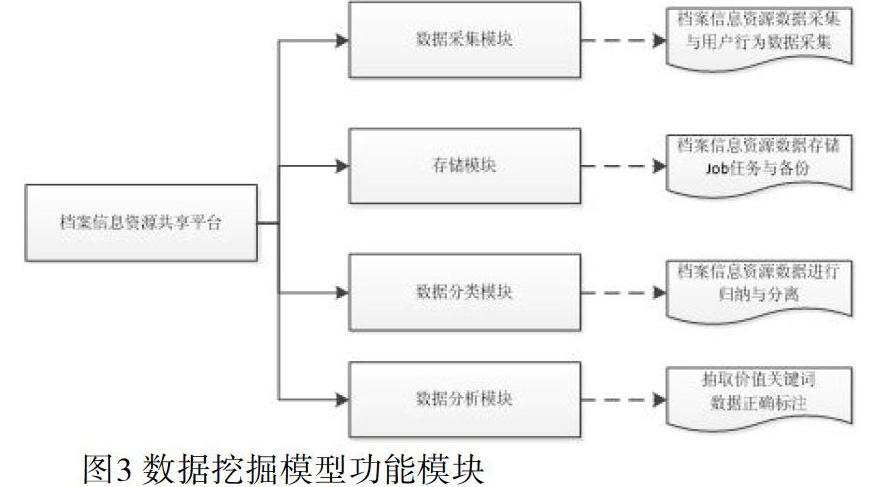
档案信息资源数据挖掘模型功能模块主要由档案信息资源数据采集模块、存储模块、数据分类模块、数据分析模块等组成。数据采集模块包含后台管理数据采集与用户行为数据采集,数据共享后会定期从公共接口进行数据交互,新产生的数据会收集到档案信息资源共享平台中。存储模块会定期将存储到平台的档案信息资源数据进行备份,并自动处理历史数据与当前操作数据分离,以提升数据挖掘模块的数据操作性能。数据分类模块通过利用档案信息资源共享平台获取的原始数据,采用智能策略对档案信息资源数据进行归纳与分离,该模块是待挖掘源头数据的最终达到预定目标的關键,良好的分类可以更好地发现有价值的结果。数据分析模块是对分好类的数据进行智能化提取价值关键词,该模块是档案信息资源数据挖掘的价值所在,该模块通过减少对非关键数据的分析来提升数据挖掘效率。具体的功能模块如图3所示:
3.2 数据挖掘模型处理流程
档案信息资源数据挖掘模型处理流程包括数据准备、数据预处理、数据挖掘、评价等几个过程[16],数据准备阶段是按用户需求从档案信息资源共享平台上获取基础信息。数据预处理阶段是将第一阶段收集的大量不完善、模糊和冗余的数据进行预处理并转换成准确有效的数据,在此流程中与数据挖掘相关的数据和属性才可以被使用,该流程中使用了数据挖掘算法,为数据挖掘奠定了基础。数据挖掘阶段可分为三个部分,即确定挖掘及其知识类型、确定算法,根据算法进行数据的实际挖掘。评价阶段主要时间预测结果验证,不合格结果可按以上三步重新挖掘,直到预测结果符合要求,同时应删除挖掘结果中的多余知识。档案信息资源共享平台数据挖掘模型的详细处理流程如图4所示:
3.3 数据挖掘模型样本准备
不同于以往的标准统计分析,需要将超出正常范围的数据舍弃以便于数据统计,在档案信息数据挖掘的过程中,以往的非正常范围数据可能正是数据挖掘的关键,在数据挖掘的样本准备过程中,需要重视这部分数据并对其进行研究。知识发现算法需通过档案信息资源原始数据来进行学习,如果没有足够数量的档案信息资源大数据模型的例子,数据挖掘模型是无法得出期望的预测模型。在这种情况下,利用边缘样本来丰富样本模型集,提高特定预测结果的成功率。档案信息资源数据挖掘模型的建立需要一个较长的时序,基于较短时间建立的模型存在风险,最终得到的数据学习知识不能真实反映数据趋势信息。在实际的时序应用中需要结合模型集中的多个时序信息以消除因时间推进带来的趋势分析影响。
3.4 预测模型创建
档案信息资源数据挖掘模型用来预测时,需要明确模型集所占用的时间长度,同时需要将具体的时间段明确下来,预测模型就是要利用过去设定的模型,用来解释最近的输出。预测模型部署到正式环境后,能够通过自我学习,运用不断更新的数据预测未来。数据预测模型创建是动态的,通过模型预测的短期信息是不能作为未来预测模型的基础数据输入,如果在远期数据预测中需要用到近期的预测信息,可行的方案是在模型集合中跳过近期预测数据输入。
3.5 剖析模型集创建
档案信息资源数据模型集与预测模型较为相似,不同点在于剖析模型集目标的时间帧与输入的时间帧是重叠的。该差别对建模工作有非常大的影响,因为输入可能使目标模式出现偏差,严格选择剖析模型的输入才能避免该问题的产生。当目标变量的时间帧与输入变量的时间帧一致时,该模型即是一个剖析模型。剖析模型输入变量可能会引入无固定的挖掘模式,而这些模式可能会混淆数据挖掘技术。
*2017年国家社科基金年度项目《大数据时代智慧档案信息服务平台构建与创新研究》(项目批准号:17BTQ074)阶段性成果之一。
参考文献:
[1]罗俊,于水,杨维,孔华锋.实时大数据挖掘系统的设计与实现[J].计算机应用与软件,2020(3):57-60+122.
[2]谭美琴,郑川.档案数据挖掘文献统计分析[J].资源信息与工程,2019(4):166-168.
[3]倪一君.大数据技术与档案数据挖掘分析[J].办公室业务,2019(5):21+24.
[4]王萍,牟冬梅,石琳琚,沅红.领域知识融合驱动下的数据挖掘模型构建与优化[J].情报理论与实践,2018(9):114-117+153.
[5]Sonia Jaramillo Valbuena,Sergio Augusto Cardona,Alejandro Fernández.Minería de datos sobre streams de redes sociales,una herramienta al servicio de la Bibliotecología[J].Información,cultura y Sociedad,2015,33:63-74.
[6]杨尊琦.大数据导论[M].北京:机械工业出版社,2018.
[7]王竞秋.数字·数据·知识:档案资源开发利用形式的拓展与整合[D].南昌:南昌大学,2019.
[8]Rehab Duwairi,Ammari Hadeel.An enhanced CBAR algorithm for improving recommendation systems accuracy[J].Simulation Modelling Practice and Theory,2016,60:54-68.
[9]栾立娟,卢健,刘佳.数据挖掘技术在档案管理系统中的应用[J].计算机光盘软件与应用,2015(1):35-36.
[10]谢光.基于Map Reduce 的云数据挖掘模型的设计与实现[J].网络安全技术与应用,2017(6):62-63+71.
[11]郑斐,郭彦宏,郝俊勤,刘娜.数据挖掘技术如何在图书馆建设中体现价值[J].图书情报工作,2013(S13):263-264+212.
[12]Hanane Ezzikouri,Mohamed Fakir,Cherki Daoui,Mohamed Erritali.Extracting knowledge from web data[J].Journal of Information Technology Research,2014,7(4):27-41.
[13]刘斌.档案信息管理系统中的计算机数据挖掘技术探讨[J].信息与电脑(理论版) ,2018(3):138-139+142.
[14]Hemant Kumar Singh,Brijendra Singh.A classification algorithm to improve the design of websites[J].Journal of Software Engineering and Applications,2012,5:492-499.
[15]王萍,牟冬梅,石琳,琚沅红.领域知识融合驱动下的数据挖掘模型构建与优化[J].情报理论与实践,2018(9):114-117+153.
[16]Cuiyuan Yu,Jie Shan.The application of web data mining technology in e-commerce[J].Advanced Materials Research.2014,1044:1503-1506.
(作者單位:盐城师范学院 来稿日期:2020-04-20)
猜你喜欢
环球时报(2016-12-26)2016-12-26
现代情报(2016年11期)2016-12-21
中学教学参考·理科版(2016年9期)2016-12-15
艺术科技(2016年10期)2016-12-14
亚太教育(2016年31期)2016-12-12
中文信息(2016年10期)2016-12-12
考试周刊(2016年89期)2016-12-01
科教导刊(2016年9期)2016-04-21
