
结合残差密集块的卷积神经网络图像去噪方法
2020-07-20 06:16郭恒意贾振堂
计算机工程与设计 2020年7期
郭恒意,贾振堂
(上海电力大学 电子与信息工程学院,上海 200090)
0 引 言
图像在生成、存储和传输等过程中,会在一定程度上退化失真,质量下降,产生噪声[1-4]。图像去噪算法是图像处理领域中的经典问题之一,具有相当长的研究历史,并出现了很多经典的图像去噪算法,如空间域和变换域滤波方法,以及基于统计信息的去噪算法[5-11],而块匹配3D滤波方法(block-matching and 3D filtering,BM3D)[10]是其中先进的经典算法之一。通过对图像分块处理,并利用图像块之间的相似性进行重构,经过滤波变换得到去噪图像,有较好的信噪比和视觉效果。但随着噪声等级增高,图像块间的有用信息就会减少,这种利用图像块之间信息的去噪效果就会变差。随着计算机计算能力的提高和深度学习的快速发展,很多前人已经把深度神经网络用于解决图像去噪问题。在文献[12]中,提出一种多层感知器神经网络(multi layer perception,MLP)图像去噪方法,并将其作为回归问题,成对的含噪声和无噪声的图片用于估计网络参数。MLP训练网络应足够大,分割图像得到的区块应足够大,以及训练集也应足够大。该方法的一个不足之处为无法适应不同强度的噪声,若将不同水平的噪声图像作为输入进行训练则无法达到对特定噪声进行训练时的效果。文献[13]提出用较深层的CNN网络实现去噪,称为DnCNN。为了解决网络层数加深导致的梯度弥散效应,DnCNN并不对干净图像进行学习,而是学习图像中所包含的噪声。实验结果表明,结合使用BN层与残差学习可以提高模型的性能,DnCNN在不同噪声水平上训练,得到的结果要优于当前去噪方法的最优结果,如BM3D等。DnCNN网络深度为17层,对于视觉识别任务,网络的深度是至关重要的。网络越深,结果越好,但是计算复杂度也随之增大。如果计算能力受限,这种计算复杂度高的算法将不再适用。
基于以上问题,在文献[14]和文献[15]的启发下,本文结合残差密集块、批量规范化、线性修正单元和残差学习,提出了一种轻量级卷积神经网络去噪模型。
1 结合残差密集块网络去噪模型
图像去噪是通过对退化的含噪图像进行处理,估计得到原始图像的过程。如果给定的是一个加性高斯白噪声模型,含噪图像可以表示为
Y=X+Z
(1)
其中,Y是含噪图像,X为原始图像,Z为加性高斯白噪声。对于图像去噪,其任务是从含噪图像中抽离出潜在的干净图像。与噪声相比,潜在的干净图像包含更多信息。如果卷积神经网络直接预测潜在干净图像,网络的学习负担远远高于预测噪声的负担。
卷积神经网络是线性滤波和非线性变换操作的交替序列。输入层和输出层包含一个或多个图像。网络的中间层称为隐藏单元,每个隐藏单元的输出称为特征映射。卷积神经网络在做相关图像处理任务时比传统的神经网络有非常明显的优势,权值共享和局部连接极大地降低了网络模型计算量,减少了网络训练参数。本文在综合考虑充分提取特征和降低计算复杂度的基础上,设计了结合残差密集块的卷积神经网络。网络的第一层为卷积核(3*3)的卷积层加线性修正单元(rectified linear unit,ReLU);第二层为一个残差密集块(residual dense block,RDB);接着设计了6层卷积核(3*3)的卷积层,每个卷积操作后均添加批量规范化(batch normalization,BN)层和ReLU激活;再经过卷积核(3*3)的卷积和BN操作非线性映射输出噪声图像;最后通过与输入的跳过连接抽出潜在的干净图像。最终实验结果在部分测试数据上优于文献[12]和文献[13]的去噪效果。
1.1 残差密集块(RDB)结构
在卷积神经网络中的每一层都从之前卷积层的输出获得输入,并通过卷积,激活映射出更深层次的特征,不同深度的层所表达的特征都不一样,所以单一层表征并不能充分描述输入图像的特征信息和分布规律,而针对这样的问题,本文提出了一种结合RDB模块卷积神经网络,RDB模块结构如图1所示。

图1 RDB模块结构
后一层均与之前层相互连接,使这些纵向串接卷积层的特征均被充分利用[14]。RDB模块的输入输出采用跳过连接加速整体网络训练速度,卷积层的纵向延伸加深了网络深度,密集跳过连接在本质上拓宽了网络的宽度,融合后的特征图可充分表达原图像的特征信息,但是同时增加了算法模型整体计算量,所以本文提出的网络在卷积操作后全部采用ReLU作为激活函数。理论上,RDB模块串接可以更有效地进行特征提取,但考虑到网络整体计算复杂度的问题,本文只采用了一个RDB模块。后面我们也对在RDB模块中采用不同数量的卷积对去噪效果的影响分别进行了实验和数据分析。
1.2 激活函数的选择
当前,深度学习一个明确的目标是从原始数据中抽离出关键特征因子,然而原始数据中的特征通常都是关系复杂地密集缠绕在一起。如果能够去掉其中复杂的无关特征,提取关键性的稀疏特征,那么就降低了学习难度。ReLU激活函数可以通过去掉负值部分引入稀疏性,并且可以根据网络的梯度训练自动选择合理的激活值,即动态调节稀疏比率,保证目标函数拟合误差不断减小。ReLU激活函数表达式如下
f(X)=Max(X,0)
(2)
函数图像如图2所示。
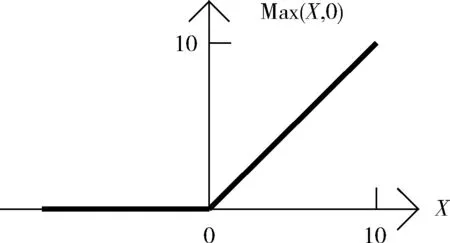
图2 ReLU函数图像
由函数图像可知,ReLU是一个简单的分段函数,当X小于零时,函数值为零,即不激活;当X大于零时,等价于斜率为1的正比例函数。ReLU可以有效地克服梯度消失问题,从而加快训练速度,表达形式简单,计算速度快。
1.3 批量规范化
深度神经网络的训练,往往需要多次调试参数的初始化。每一层输入数据的分布,随前层参数的变化而变化,层间输入分布的变化,导致训练变得复杂,而使用小学习率参数,导致训练较慢;此外,饱和非线性模型的函数在饱和区的导数趋于0,也使得模型不易训练。批量规范化(BN)方法的提出者,将上述问题归因于层间协变量偏移(internal covariate shift,ICS)问题。BN操作通过将总的训练样本数据分成小批次(Batch)数据,然后将数据规范化为近似标准正态分布,再通过学习得到的参数,对数据进行缩放和平移处理,恢复特征表达,缓解了梯度传递问题,以及饱和非线性激活问题;通过平滑优化解空间,起到了正则化作用,使模型对大步长学习率敏感度降低,更加易于训练。
所以本文在设计的网络结构时,于卷积层和ReLU激活层的中间添加了BN层。对于批量标准化,每个激活只添加两个参数,并且使用反向传播进行更新。BN与卷积的结合更有助于保留训练数据集中图像的先验信息,对非稀疏分布的卷积映射输出做归一化处理,从而使层层相连的输入输出流动更稳定。
1.4 跳过式连接的残差学习
残差学习框架提出的初衷是为了解决网络深度问题,即随着网络深度的增加,训练精度也开始下降。通过假设几个堆叠层的残差映射更容易被学习,基于这样的残差学习策略,极其深度的卷积神经网络就可以很容易地进行训练,并提高了图像分类和目标检测的准确性。
残差网络中的残差映射是向目标靠近的另一种学习策略,而且让网络学习信息量相对少的残差函数总会比直接学习信息量大的原始目标难度要低。如果残差函数趋近于零,那么网络输出相当于是对输入的恒等映射。即使网络加深,至少精度可以和之前保持一样,这样就解决了网络加深时的退化问题。
而结合到图像去噪,我们通过整体的跳过式连接来让网络学习信息量相对少的噪声的图像,再由含噪图像和网络输出的差值来抽离出潜在的干净图像。而且在浅层特征提取时我们通过密集的跳过式连接不是为了解决深度问题,而是以这种方式来不断引入之前层特征信息,再通过 ConCat 连接和特征融合,让网络自行学习所需图像信息,从而获得更丰富的图像特征,为之后的学习噪声分布奠定基础。而且残差学习和批量规范化结合使用可以实现快速稳定的训练,去噪效果也更好[13]。
1.5 网络模型整体结构
结合残差密集块的卷积神经网络整体结构模型如图3所示。
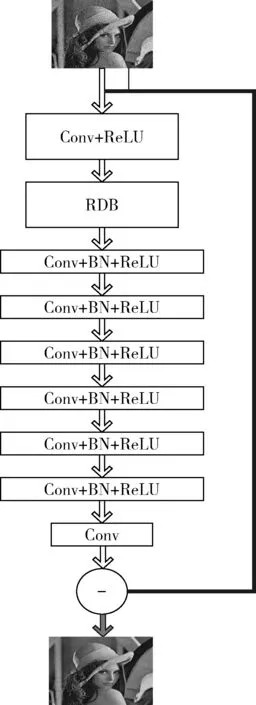
图3 网络整体结构
(1)第1层为Conv+ReLU,对输入的含噪图像进行初步特征提取。
(2)第2层为RDB层,RDB内部为4个Conv+ReLU,最后经过ConCat连接和Conv操作进行特征融合,同时增加了网络的深度和宽度,即密集提取输入图像的浅卷积层特征,然后拼接融合。
(3)第3层至第8层为Conv+BN+ReLU层,组成复杂的非线性结构学习图像中的噪声分布。
(4)第9层为Conv层,并与输入进行跳过式连接。
除了RDB模块中特征融合Conv采用(1*1)的卷积核,其余全部为(3*3)的卷积核,一至八层的卷积层中卷积核数量均为128,最后一层采用单个卷积核进行卷积映射输出图像噪声,与输入跳过连接抽出潜在干净图像作为整体的最后输出。
1.6 网络的优化算法
网络的优化算法是神经网络中除了网络模型的另一个核心,神经网络参数的优化直接决定了整个网络算法的质量。在网络整体参数上使用梯度下降法是一种实践中常用的反向传播算法,随着不断地迭代更新网络参数,神经网络模型在训练数据集上的损失不断减少,逐渐收敛到一个较小值,而此时网络中的参数就是所提出用于解决相关问题算法的最优解。但在解决一些非凸函数的问题时,梯度下降法并不能保证达到全局最优,存在损失收敛于某个局部最小值的情况,而且在整个训练数据集上计算并最小化损失函数是一个庞大的计算量。而单独在某个数据上计算优化损失函数虽然加快了训练,但是最后得到的网络参数将会更差,甚至可能达不到局部最优解。综合考虑以上问题,本文在训练网络时选择每次在一个Batch上计算优化损失函数,这样不仅可以避免收敛于局部最优解,也不会使计算负担过大。我们网络模型所要解决优化的损失函数如下
(3)
F(Xi;θ)=Xi-H(Xi;θ)
(4)
即期望图像Yi(标签)与网络估计输出图像F(Xi;θ) 的均方误差,其中θ为网络所要训练的参数权重和偏置的集合,Xi为输入的含噪图像,F(Xi;θ) 是网络估计的噪声,N为一个Batch的输入样本数量。网络的优化算法采用批量随机梯度下降法(stochastic gradient descent,SGD),参数θ的更新公式为
(5)
其中,ε为学习率,控制网络参数更新的速度,设置太小会使网络的训练效率变慢,而设置太大又会使网络参数更新时在最优解的两侧摆动,所以我们在训练时将其初始值设置为0.01,每10轮缩小为之前的1/10。
2 实验结果
本节详细介绍了所做实验和训练信息。
2.1 训练相关
实验采用400张180*180的灰度图像构造网络模型的数据集,为了便于训练,用40*40的剪裁框,滑动步长为10,将其中380张图像剪裁成了215 552个40*40的子图像块作为训练集,其余20张作为测试集。本文为了验证RDB模块是否能有效完成特定等级噪声图像去噪,对训练集图片分别添加了噪声等级为15,25,50的高斯白噪声,用于不同噪声等级网络的训练。
模型训练是在TensorFlow框架上完成的,计算机配置的CPU为InterCore第八代i7处理器,GPU为通过英伟达GTX1080,运行内存为16 GB。Batch大小设为128,每一轮训练1684个Batch的样本数据,共训练50轮。
2.2 不同数量Conv+ReLU层的RDB对去噪效果影响
为了考察不同RDB模块对网络去噪效果的影响,我们分别对含有2、3、4个Conv+ReLU层RDB模块的网络模型去噪性能进行了对比,分别对应于图4中的RDB1、RDB2、RDB3。实验结果如图4所示。
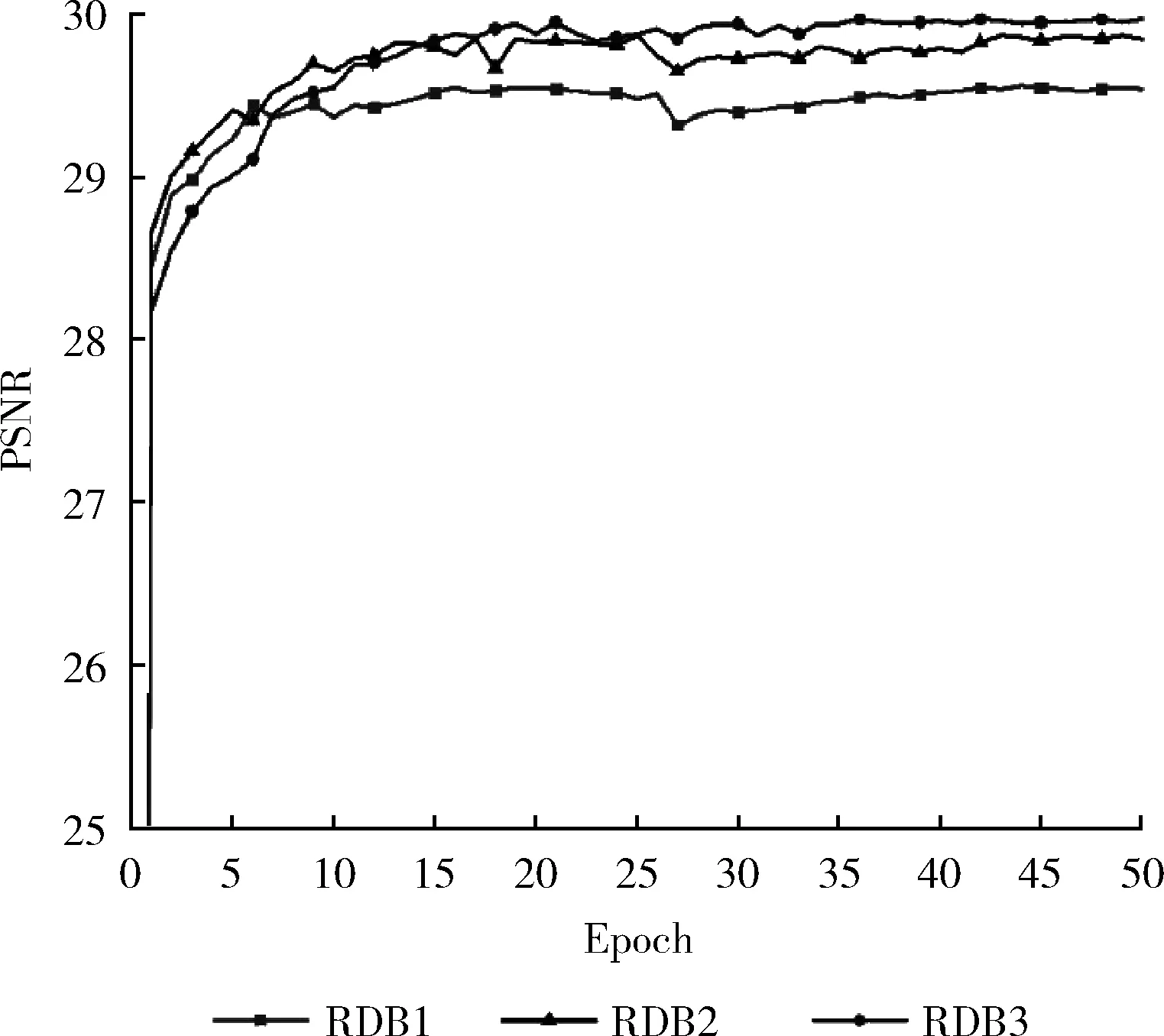
图4 RDB模块去噪效果
从结果可以看到,融合更多特征信息的RDB3取得了最好的平均峰值信噪比,这就验证了随着RDB模块中卷积层的增多,RDB的输出就会包含更多层的特征信息,对原始输入图像信息分布规律有更完整的表达,考虑计算复杂度问题,没有测试包含卷积层更多RDB模块。
2.3 与其它方法进行对比
为了更好的体现结合RDB模块卷积神经网络去噪效果,我们基于图像客观评价标准峰值信噪比(PSNR)对文献[10]、文献[12]、文献[13]和文献[16]与本文提出的方法进行了对比。表1~表3分别给出了几种方法在噪声等级为15、25、50的去噪PSNR(dB)的对比结果。部分数据来源于文献[13]和文献[15]。
从表1~表3可以看出,本文提出的去噪方法在噪声等级为15和25时均取得了最优的去噪效果。与文献[10]提出的最好的经典算法BMD3相比,在3种噪声等级下平均PSNR分别高出了1.05、0.78和0.43;而与文献[13]提出的在深度卷积神经网络图像去噪领域影响非常大的DnCNN方法相比较,在噪声等级为15和25时,本文提出的去噪方法平均PSNR分别高出了0.36和0.10,仅在噪声等级为50时,平均PSNR低了0.23。但与深度为17的DnCNN方法的计算复杂度相比,本文提出的方法消耗更少计算资源,同时在部分噪声等级去噪上达到了更好的去噪效果。噪声等级为15时的去噪效果如图5所示。图5中相同图片从左到右分别是原图,叠加噪声图和去噪图,由图5中的6组图像可得,本文提出的方法在去噪时很好地保留了图像的纹理细节,图像中的摄像师所站的草地以及身后的背景建筑,鹦鹉的嘴唇上凹痕,还有人物佩戴的首饰等都得到了清晰自然地保留。
3 结束语
从表格数据对比和去噪效果展示可以看出,本文中的残差密集块可以充分利用不同层次中图像特征信息,在图像去噪中有很好的表现,而且随着RDB模块中卷积块的增加,图像去噪的PSNR有明显提高。本文提出的结合残差密集块的卷积神经网络,通过密集提取不同层次图像特征,学习图像噪声,从含噪图像中抽出潜在的干净图像,减轻了计算负担,提高了平均峰值信噪比,很好地完成了图像去噪任务。与先进算法DnCNN相比,在噪声等级为15和25时分别高出了0.36和0.1。
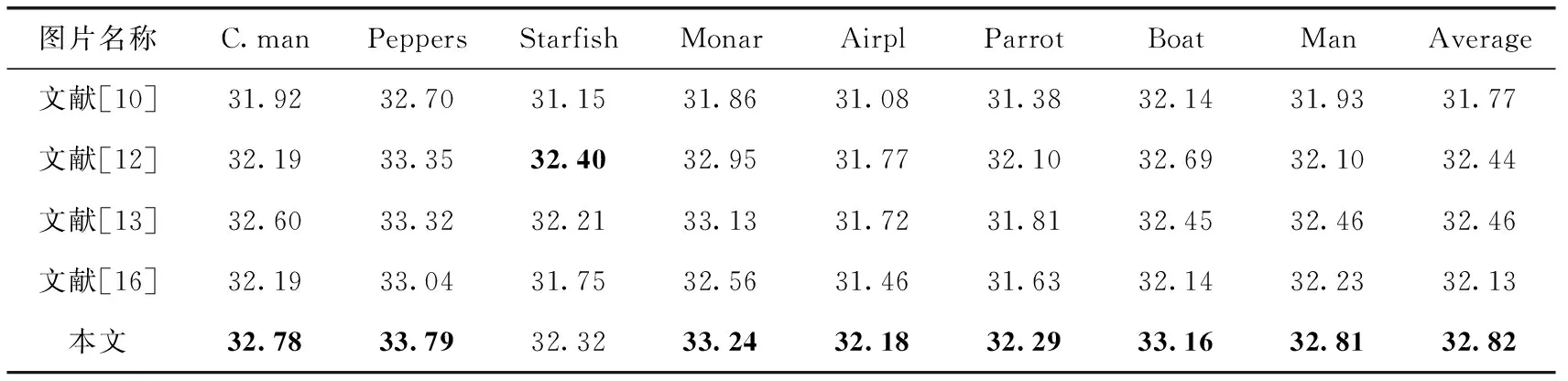
表1 噪声等级为15的各种去噪方法PSNR对比结果/dB
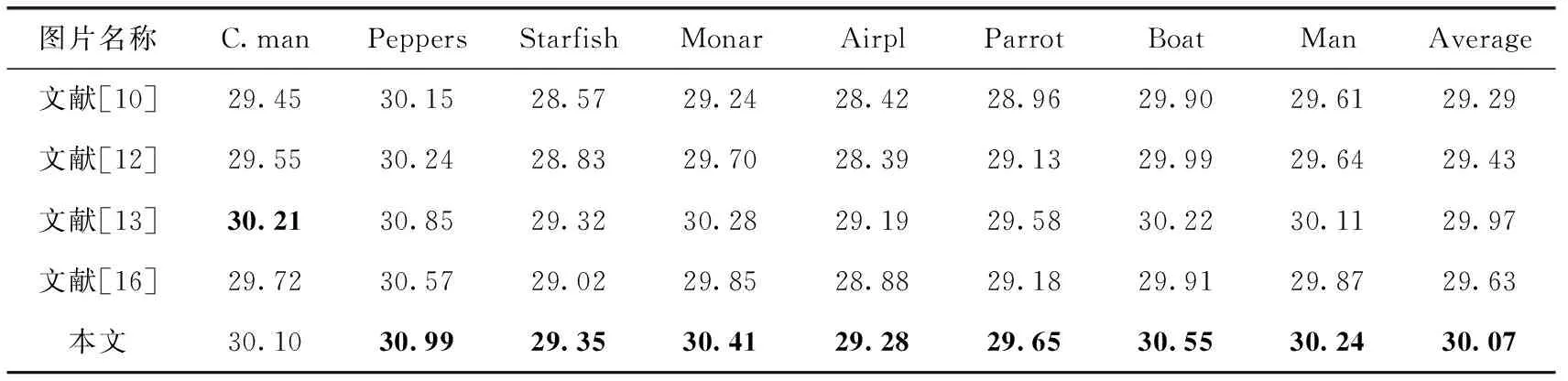
表2 噪声等级为25的各种去噪方法PSNR对比结果/dB
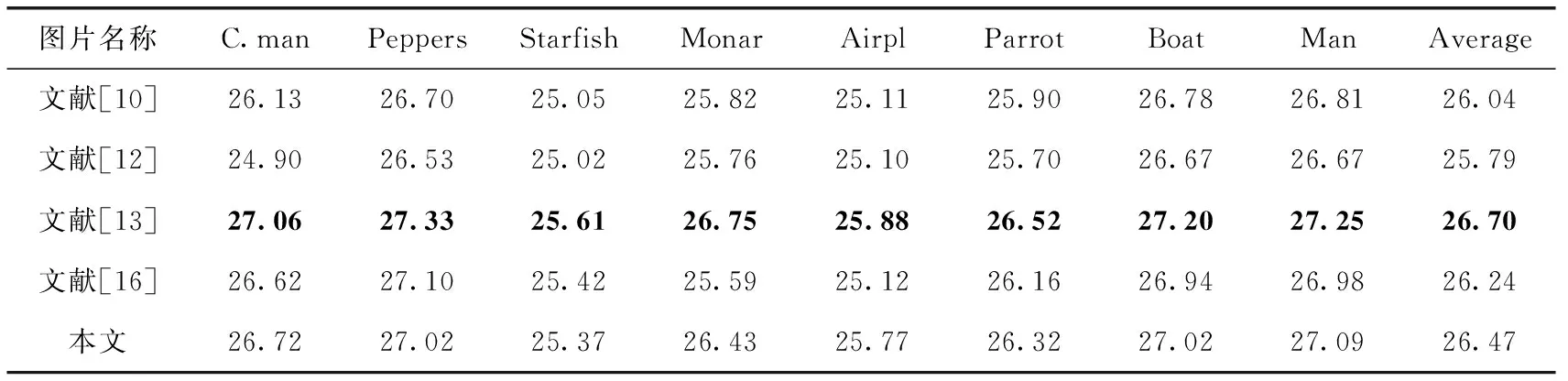
表3 噪声等级为50的各种去噪方法PSNR对比结果/dB

图5 噪声等级为15时的图像去噪效果
本文提出的简化模型结构,降低计算复杂度使得模型拟合高浓度噪声能力不佳,当然现在的去噪模型都存在随着噪声浓度增加去噪PSNR降低的问题,之后我们会结合这些问题继续研究,优化网络模型和学习方法。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2020年10期)2020-11-14
数学年刊A辑(中文版)(2020年3期)2020-10-27
电子制作(2019年13期)2020-01-14
自动化学报(2019年6期)2019-07-23
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
中学生数理化·八年级物理人教版(2017年9期)2017-12-20
中国惯性技术学报(2015年1期)2015-12-19
