
基于多层卷积模型的恶意URL特征自动提取
2020-07-20 06:15:54钱丽萍汪立东
计算机工程与设计 2020年7期
张 婷,钱丽萍,汪立东,张 慧
(1.北京建筑大学 电气与信息工程学院,北京 100044;2.国家计算机网络应急技术处理协调中心,北京 100029)
0 引 言
随着网络服务日益普及,不法分子利用网络进行攻击的行为日渐普遍。攻击者不断采用自动生成域名及网页隐匿等新的技术手段来增强恶意URL的隐蔽性,提高攻击命中率。其中,一种极为有效的手段就是采用恶意仿冒URL方式,该类URL在主机名、路径名、文件名或参数域中使用一些知名网站的域名,造成用户混淆,降低防备,诱导用户点击,从而完成攻击。由于仿冒特征对原始特征的扰动幅度较小,一定程度上影响了目前常用的基于字符串特征匹配、基于统计特性检测及基于特征学习等检测方法的检测性能。
恶意仿冒URL是恶意URL中的一种类型,与传统的恶意URL具有类似的检测方法。主要使用的方法包括黑名单、规则匹配和机器学习等。虽然上述方法能够在一定程度上实现对恶意仿冒URL的检测,但仍存在一定的局限性。
由于恶意仿冒URL在统计分布特性上类似于良性URL,往往被当前检测方法漏检。本文提出一种基于skip-gram编码器和卷积神经网络(convolutional neural network,CNN)相结合的恶意仿冒URL检测方法。该方法首先根据URL的结构特性,将其切分为协议、主机名、路径名、文件名及参数域5个部分,再利用skip-gram模型进行编码,最后使用连续卷积CNN模型对编码后的各部分分别进行特征提取,并结合机器学习方法实现对恶意仿冒URL的检测。
1 相关工作
当前主流的恶意URL的检测方法主要包括黑名单检测、规则匹配检测、基于机器学习检测[1]及基于深度学习的方法。
黑名单是一份包含已验证为恶意URL的网址列表。Kührer等[2]提出一种基于图表的方法用于识别黑名单中的漏洞,并对15个公共恶意软件黑名单和4个由杀毒软件供应商提供的黑名单进行有效性评估。虽然研究人员对黑名单列表进行扩展,但其识别能力仍依赖原有黑名单集,不仅容易引起漏判,且时间开销大。
传统机器学习方法被广泛应用于恶意URL检测领域。Vanhoenshoven等[3]运用决策树、随机森林、支持向量机(SVM)、多层神经网络(MLP)等方法完成对恶意URL数据集的检测。甘宏等[4]提出使用基于RBF核的SVM分类器对URL进行分类检测,并采用准确率、召回率、精准度和F-measure等评价指标对结果进行评估。由于机器学习算法的局限性,导致在特征提取和实验方面需要消耗大量的时间精力。
深度学习主要使用多层神经网络对字符串进行特征提取,找出字符串的隐性特征,便于URL的检测。Goldberg[5]从自然语言处理研究的角度介绍卷积神经网络,介绍自然语言的输入输出、特征提取、优化方式和常用函数(激励函数、损失函数、正则化、梯度下降、反向传播等)。陈旭等[6]论述以卷积神经网络为主体的深度学习算法的实现。潘思晨等[7]使用多层卷积神经网络对恶意URL进行检测。Le等[8]使用多层卷积神经网络对恶意URL在字符级和单词级分别进行检测。基于深度学习的检测,虽然能够较准确地检测字符级恶意URL。但其模型的网络层数较多,导致特征提取与检测过程的时间与空间复杂度较高。
攻击者常仿冒知名域名构造恶意URL,特别是结合使用域名生成算法(domain generation algorithms,DGA),如suppobox、cryptowall等,快速生成与Alexa Top 1M一元字符分布高度相似的恶意仿冒URL集,传统规则匹配或基于简单统计分布的机器学习检测方法难以区分[9,10]。
由于以上方法存在准确率较低、时间开销大、更新困难等不足,因此本文设计并实现了一种连续多个卷积层的CNN与多种机器学习算法相结合的检测模型,能够准确、高效地抽取恶意仿冒URL的判别特征,检测模型具有普适性,可以有效地提升恶意仿冒URL的识别能力。
2 特征提取模型结构
统一资源定位符(uniform resource locator,URL)是互联网上标识资源的唯一地址,格式为protocol://hostname[:port]/path/[?query](IETF request for comment 1738,RFC1738),其中“[]”表示可选内容。本文以超文本传输协议(hypertext transfer protocol,HTTP)的URL为主要研究对象,该类URL每个部分具有特殊的意义与构造规则,如图1 所示。因此,本文根据URL的结构特性将其划分为协议、主机名、路径名、文件名及参数域5个部分。由于本文主要研究基于HTTP协议的URL,故协议部分不作为研究对象。

图1 http协议形式
2.1 字符编码
深度学习网络模型无法直接处理字符串信息,因此如何在保留URL所包含信息的基础上对其进行转化是本文研究的重点之一。skip-gram[11]作为基于分布式思想编码的方法之一,具有强大的表征能力,能够将文本语料的最小语义单元映射为实数向量,并用不同语义单元的空间距离表示语义相似度;同时可以通过给定目标字符预测上下文信息,应用范围广且适用于较大量的数据集运算。且相较于CBOW模型,能够更加显式地表达字符间的关系,更加准确地提取字符特征,为后文URL的特征提取节省时间。因此本文设计skip-gram对URL进行稠密编码,完成URL信息转换。
skip-gram模型旨在将字符转换为占用空间更小的稠密向量。本文以URL为处理单位,选择其最细粒度——字符,作为最小语义单元,统计正、负数据集中的最小语义单元的频次,并按降序排列,结果如图2所示。横坐标为字符降序排列的序号,纵坐标为1-gram字符出现的频次。本文将频次较低字符包括中文字符(’翡’,’语’,’利’,’款’等)、非常用字符(’>’,’π’,’^’,’`’等)及乱码字符(’す’,’í’,’の’,’й’等)全部置为”UNK”,以减少模型训练的时间及空间复杂度,且不会对编码结果造成影响。故本文以频次为334次的第79个字符’!’作为切分点,舍去频次小于300次的字符。并将保留的79个字符与”UNK”组成skip-gram模型所需的字符表V。

图2 1-gram字符频次降序排列折线
在skip-gram模型中,w∈Rd是w∈V的向量表示,其中,d为字符向量的维数,w为字符表V中的字符。如图3所示,使用滑动窗口得到训练数据 (w,c), 不仅能获取相邻字符间的关系,也能获取具有一定距离字符间的关系。相较于普通二元数据对能更加准确表达字符的上下文关系。且本文设置大小为5的滑动窗口,即能保证充分获取字符间的关系,又能避免因距离过远而获取的错误关系。

图3 skip-gram模型扫描结果注:阴影代表当前“输入字符”,方框代表滑动窗口。
在目标字符w的上下文中观察到字符c的概率如式(1)所示,在目标字符w的上下文中未观察到字符c的概率如式(2)所示
(1)
(2)
其中,向量w与向量c分别为字符w与字符c的向量表示。
skip-gram模型使用噪声-对比估计(noise-contrastive estimation,NCE)预测目标字符,并利用负采样(negative sampling)技术,尽可能分配高概率给真实目标,低概率给其它噪声。将上文滑动窗口扫描得到的实验数据集D, 放入skip-gram字符编码器中,其隐藏层为无激活函数的线性神经元,输出层使用softmax激活函数。并设置相应负随机采用集D′进行训练,如式(3)所示。并通过式(4)计算出字符的稠密编码向量

(3)
w′=w·Wh
(4)
其中,向量w′是字符w的稠密编码向量,向量w是字符w的one-hot向量,Wh为skip-gram字符编码器训练结束后所得隐藏层权重矩阵。
综上所述,利用以上skip-gram字符编码器模型得到映射表S, 该映射表为字符到向量的一一映射。能充分表达字符含义与字符间的关系,降低后文CNN特征提取的复杂度,减少特征提取时间。
2.2 特征提取
近年来,CNN不仅在图像、语音识别方面取得成功,也在自然语音处理方面取得突破性的进展。Saxe等使用多核卷积对短字符串(恶意URL、文件路径、注册表等)进行特征提取并分类,其结果优于手动特征提取[12]。Vijayaraghavan等使用卷积神经网络在字符级和单词级上对多个短文本数据集进行分类检测,取得较好的结果[13]。故本文借鉴以上模型优点,使用连续多个卷积层的CNN模型(采用连续两、三、四个卷积层3种模型),分别针对URL的主机名、路径名、文件名及参数域部分进行训练,选取URL各部分的最优模型组合为最终模型,对整个URL进行特征提取。连续两个卷积层的CNN模型如图4所示,先采用连续两个卷积层进行连续特征提取,再使用平均池化对特征进行优化。由于池化作用会过滤部分相关特征,故本文采用多次连续卷积的方式,尽可能充分的提取URL的特征向量。
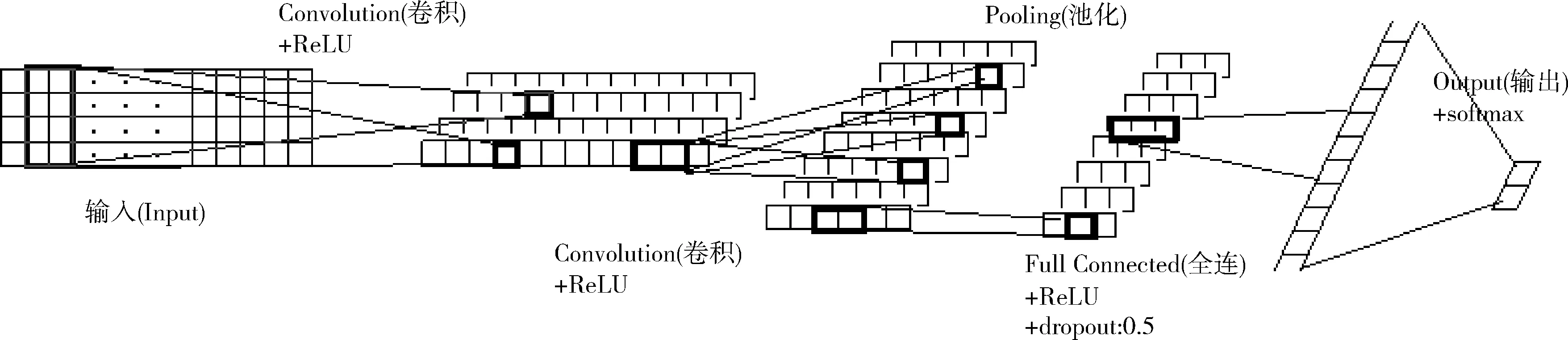
图4 连续两层卷积CNN模型结构
卷积层是连续多个卷积层模型的重要部分,主要作用是对数据进行特征提取。本文采用连续卷积即连续多次特征提取,相较于普通CNN模型,能够更充分提取字符间的特征关系。且首先选择较大尺寸的卷积核对URL整体特征进行有效提取,再选择较小尺寸的卷积核对URL局部特征进行详细提取。并采用”VALID”方式填充,相较于”SAME”方式能有效降低特征图的维度,降低运算的复杂度。池化层的主要作用是进行特征筛选,去除冗余或不相关特征,本文采用平均池化对特征进行筛选,相较于其它池化方式,平均池化能够筛选出URL的最优特征表达。
激活函数是神经网络的重要函数之一,利用它的去线性化功能,使神经网络实现非线性传播。其中ReLU函数仅使用一个阈值就能得到激活值,大大降低了神经网络的运算量,且ReLU函数适用于较小学习率参数。根据恶意仿冒URL本身特点、运算速度及较小学习率的设置,在卷积层和全连接层ReLU函数选择激活函数。
本文以连续两个卷积层模型为例,输入为数据向量X,Xi∈Rn, 长度为n的数据表示为X1∶n=X1X2…Xn, 两次卷积后得到特征向量C、C′, 如式(5)、式(6)所示。池化后得到特征向量P,如式(7)所示
Ci=f(W1·Xi*step1∶i*step1+c1-1+b1)
(5)
C′i=f(W2·Ci*step1∶i*step1+c2-1+b2)
(6)
Pi=Average{Ci*step2∶i*step2+c3-1}
(7)
其中,c1、c2为卷积核的尺寸,step1为卷积步长,W1∈R4*c1,W2∈R1*c2为卷积核的权重矩阵,b1∈R,b2∈R为卷积偏置项,c3为池化过滤器的尺寸,step2为池化步长。
综上所述,由2.1节得到的skip-gram字符编码器与2.2节得到的连续多个卷积层的CNN特征提取模型组成的网络模型如图5所示,且连续多个卷积层的CNN模型结构图如图4所示。故本文利用该网络模型对URL检测特征自动提取。

图5 本文模型结构
3 实验结果与分析
3.1 实验数据
Alexa与Phishtank网站全球公认的且被大量使用的良性与恶意URL数据集。本文从Alexa 网站爬取五万多条良性真实URL作为正样本集。并采用如下方法得到恶意仿冒URL样本集。
Jaccard系数(Jaccard similarity coefficient)[14]衡量两个集合之间相似性的重要方式,如式(8)所示为集合A,B的Jaccard系数。且恶意仿冒URL一般通过构造变换或字符变换模仿知名网站,故本文采用Jaccard系数来度量两个URL中特定部分之间的相似性
(8)
将Alexa Top 1M域名集的m条域名去除顶级域名作为集合U={U1,U2…Um}, 从Phishtank网站爬取的n条恶意URL,按第2章所述方法将其切分。本文数据均为基于HTTP协议的URL,故无需与集合U进行相似度对比。将主机名域,路径名域,文件名域,参数域作为集合H={H1,H2…Hn},P={P1,P2…Pn},F={F1,F2…Fn},Q={Q1,Q2…Qn} 分别与集合U进行Jaccard相似系数计算,若Ui与Hi,Pi,Fi,Qi中任意的Jaccard系数大于等于0.65,则第i条恶意URL为恶意仿冒URL,即负样本集,见表1。某些恶意仿冒URL的提取过程较费时,可能导致恶意仿冒URL集的提取过程耗费一定时间,但并不影响后续实验的检测。

表1 恶意仿冒URL样例
根据以上规则,本文选定实验所需正负样本集,并在其中分别随机选取30%的样本集作为测试集(正样本 16 950 条;负样本12 065条),剩下各70%的数据作为训练集(正样本39 550条;负样本28 151条)。
3.2 模型参数设置
为体现本研究意义,增强对比度,提升实验结果说服力。本文设计以下模型:
1.2 方法 采用自行设计的脊髓损伤神经源性膀胱功能障碍者排尿方式调查表和应用间歇导尿影响因素的调查表,内容包括脊髓损伤者的基本信息、排尿方式和应用间歇导尿的状况及影响因素等方面。调查者以问卷为基础,与被调查者交谈,充分讲解问卷中各项问题及填表要求,使患者完全理解后填写,并当场回收调查表。共发放76份,回收有效问卷76份,回收有效率100%。
模型1:运用本文URL数据集,调整已有模型结构,完成实验。本模型将本文skip-gram编码后的URL使用Saxe等提出的eXpose多核卷积模型进行特征提取,根据本文数据集,将卷积核的大小调整为4×20×8,4×30×8,4×40×8,4×50×8,dropout调整为0.6,最终得到128维的特征向量。
模型2:根据第2章提出的网络模型进行URL检测。先分别设计连续二层卷积层(模型2-a)、三层卷积层(模型2-b)、四层卷积层(模型2-c)的CNN模型对URL的主机名、路径名、文件名及参数域部分进行训练。如表2所示,模型2-a的卷积层参数为卷积c1、卷积c2;模型2-b的卷积层参数为卷积c1、卷积c2、卷积c3;模型2-c的卷积层参数为卷积c1、卷积c2、卷积c3、卷积c4。池化层过滤器使用大小为1×2,步长为2的平均池化。并选择各部分的最优模型组合为模型2的最终优选模型。根据数据集与CNN的特点,选用交叉熵计算误差代价,使用Adam优化器进行优化,设dropout为0.6,学习率为0.0001。
分别训练模型1与模型2,每次随机从训练集中选择100组数据训练,数据集共迭代60轮(即batch_size=100,epoch=60)。并基于测试集完成模型的特征提取,且对提取的特征进行评估与选择。

表2 URL各部分的3种模型卷积层参数
3.3 实验结果与分析
3.3.1 skip-gram编码结果与分析
为了能够更直观地对skip-gram编码结果进行分析,本文采用PCA技术对2.1节编码结果进行PCA降维处理,将高维字符向量降至二维向量,如图6所示。经本文skip-gram字符编码后,字符按语义相似性聚集,大、小写字母、数字分别聚簇。数据集中多次出现”http”,”taobao”,”com”,”Www”等字符串,即’h’、’t’、’p’,’a’、’b’、’o’、’t’,’c’、’o’、’m’,’W’、’w’字符之间具有频繁的上下文关系,在二维坐标中它们之间的空间距离较近。故skip-gram模型能够学习并扩大字符间的关系,使字符间的特征更显式表达,且与one-hot编码(80维/字符)相比,skip-Gram编码(4维/字符)数据所占内存空间更少,运算速度更快。故本文字符编码模型效果良好,能够将语义相似的字符聚类,为后文特征提取与分类提供良好的基础。

图6 各字符向量的PCA二维映射
3.3.2 模型优选结果与分析
模型2的优选过程中,分别使用模型2-a、模型2-b、模型2-c对URL的主机名、路径名、文件名及参数域部分的训练结果如图7~图10所示。表3为模型2各部分,全部使用模型2-a的全两层卷积模型、全部使用模型2-b的全三层卷积模型、全部使用模型2-c的全四层卷积模型及最终优选模型对恶意仿冒URL的分类结果对比表。

图7 主机名部分3种模型训练结果对比

图8 路径名部分3种模型训练结果对比
如图7可知,模型2-b与模型2-c的结果相似,且模型2-b的层数较少、复杂性较小,故主机名域选择模型2-b为较优模型。
如图8可知,模型2-c的趋势较其余两类模型平稳,且准确率高,故选择模型2-c为路径名域的较优模型。
如图9可知,模型2-c的结果均优于其余两类模型,故文件名域选择模型2-c为较优模型。

图9 文件名部分3种模型训练结果对比

图10 参数域部分3种模型训练结果对比

表3 不同组合模型分类结果对比
如图10可知,模型2-b的结果均优于其余两类模型,故参数域选择模型2-b为较优模型。
综上所述,模型2的最终优选模型的组合方式为:主机名域与参数域部分使用连续三层卷积层的模型2-b,路径名域与文件名域使用连续四层卷积层的模型2-c。
此外,根据对不同模型提取的特征空间评估,如表3可知,模型的正确率、召回率、F-M、ROC面积均随着卷积层数增加而增高,但其上升趋势均随着卷积层数增加而降低,故仅仅依靠增加卷积层数并不能达到最优结果。同时,与最终优选模型对比可知,最终优选模型较其它模型更优,故本文提出将URL切分为5部分分别进行特征提取的方法有效,且URL的各部分分别选择适合该部分数据特征的模型能够达到更优结果。
3.3.3 各模型结果对比分析
表4为eXpose模型[14]、模型1、模型2在FPR(假阳率)等于10-4、10-3、10-2时TPR(真阳率)的结果对比表。采用随机树、随机森林、贝叶斯、J48多种机器学习算法对模型1、模型2的结果进行十重交叉验证。并使用正确率、错误率、召回率、F-Measure、ROC面积评价指标对分类结果进行评估,结果见表5、表6。
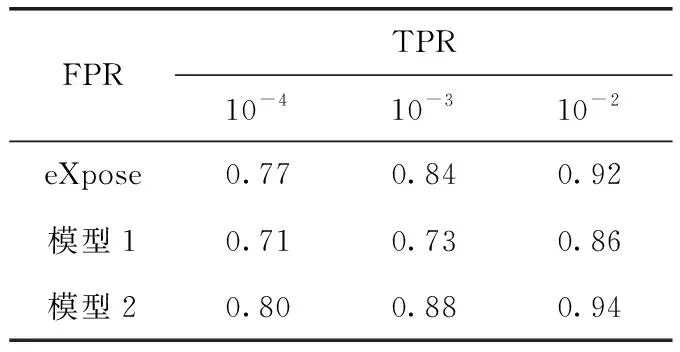
表4 各模型分类效果对比

表5 模型1的分类结果评估
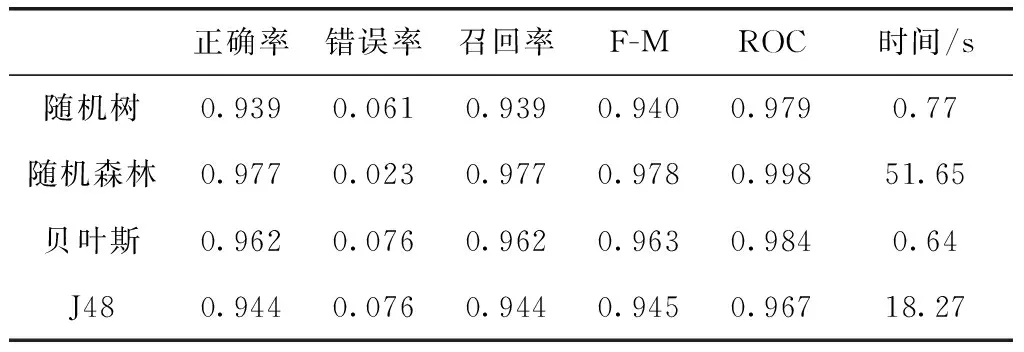
表6 模型2的分类结果评估
以表4中模型2的结果为例,在FPR等于10-4、10-3、10-2时,模型2的TPR的结果为80%、88%、94%,故TPR的结果随着FPR的增大而增大。由表4中FPR等于10-2时,eXpose、模型1、模型2的TPR的结果可知,模型2的分类结果优于其它模型,故使用模型2的特征提取方式对本文恶意仿冒URL数据集具有较良好效果。由模型1与eXpose的结果可知,eXpose的分类效果优于模型1,故本文对eXpose多核卷积模型的复现效果未达到最优,或eXpose多核卷积模型对恶意仿冒URL数据集未有最优效果。
由表5、表6可知,ROC曲线的评价结果较其它评价指标结果良好。并由表5、表6对比可知,模型2的分类效果均优于模型1,故模型2将URL切分为协议、主机名、路径名、文件名及参数域5个部分分别训练,更充分地提取了恶意仿冒URL的有效特征,提高了恶意仿冒URL的检测准确率,准确率最高达97.7%。
4 结束语
恶意URL识别是网络安全领域保证用户上网安全的重要检测手段之一。针对恶意URL中较难识别的类型——恶意仿冒URL,本文提出一种基于连续多个卷积层的CNN模型对恶意仿冒URL进行检测。实验结果表明,skip-gram字符编码器产生的稠密编码,能够充分体现字符上下文关系,降低后文特征提取的复杂度。利用URL的结构特性将其切分为5部分,每部分使用不同层数卷积模型进行预训练,再将各部分模型组合进行特征提取的方法有效。且选择三层卷积层模型处理主机名域与参数域、四层卷积层的模型处理路径名域与文件名域的最终优选模型的准确率最高。故本文提出的恶意仿冒URL检测方法能够有效提高网络安全人员对恶意仿冒URL的检测效率与准确率,在网络安全领域具有较好的应用前景。
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
电子制作(2019年11期)2019-07-04 00:34:38
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
电子制作(2018年19期)2018-11-14 02:37:08
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
自动化学报(2017年11期)2017-04-04 02:52:58
噪声与振动控制(2015年4期)2015-01-01 07:08:21
