
基于级联与深度信念网络的恶意代码分层检测
2020-07-20 06:15:54段玉莹王凤英
计算机工程与设计 2020年7期
段玉莹,王凤英
(山东理工大学 计算机科学与技术学院,山东 淄博 255000)
0 引 言
恶意代码(malicious code)被定义为一系列故意创建,对计算机系统或者网络信息机密性、完整性、可用性产生威胁的软件程序。现阶段,恶意代码常针对新型漏洞进行设计,是敌手发动高级持续威胁(advanced persistent threat,APT)的主要技术手段[1-4]。
目前典型的恶意代码检测技术包括:基于静态分析[5,6]、动态分析[7,8]以及机器学习的方法[9,10]。静态分析的检测适于非混淆样本,但对未知及变种代码往往无计可施;动态分析的检测对混淆样本表现更为出色,但此方法需要触发恶意代码的执行,且路径单一。目前基于机器学习的检测大多为浅层的机器学习模型,通过大量恶意样本提取特征,训练样本以构建模型判断软件的恶意特性。这些浅层机器学习模型,在复杂函数及其分类等问题上表述能力受限,泛化能力也受到了制约,分类的精度和准确度并不理想[11]。深度学习是对机器学习更深层次的解释,可以对多层深度结构实现非线性映射[12]。因此,本文提出了采用级联与深度信念网络进行恶意代码的检测,通过级联由简到繁的检测方法,以及深度信念网络的无监督特性,提高检测效率的监测方案。与其它机器学习的检测结果相比较,本文中检验恶意代码的准确率得到显著提高。
1 相关研究
1.1 受限玻尔兹曼机(RBM)
RBM为一种仅含有两层节点的随机神经网络模型,各层之间处于一种全连接状态,每层内部各部分相互独立,其结构如图1所示。
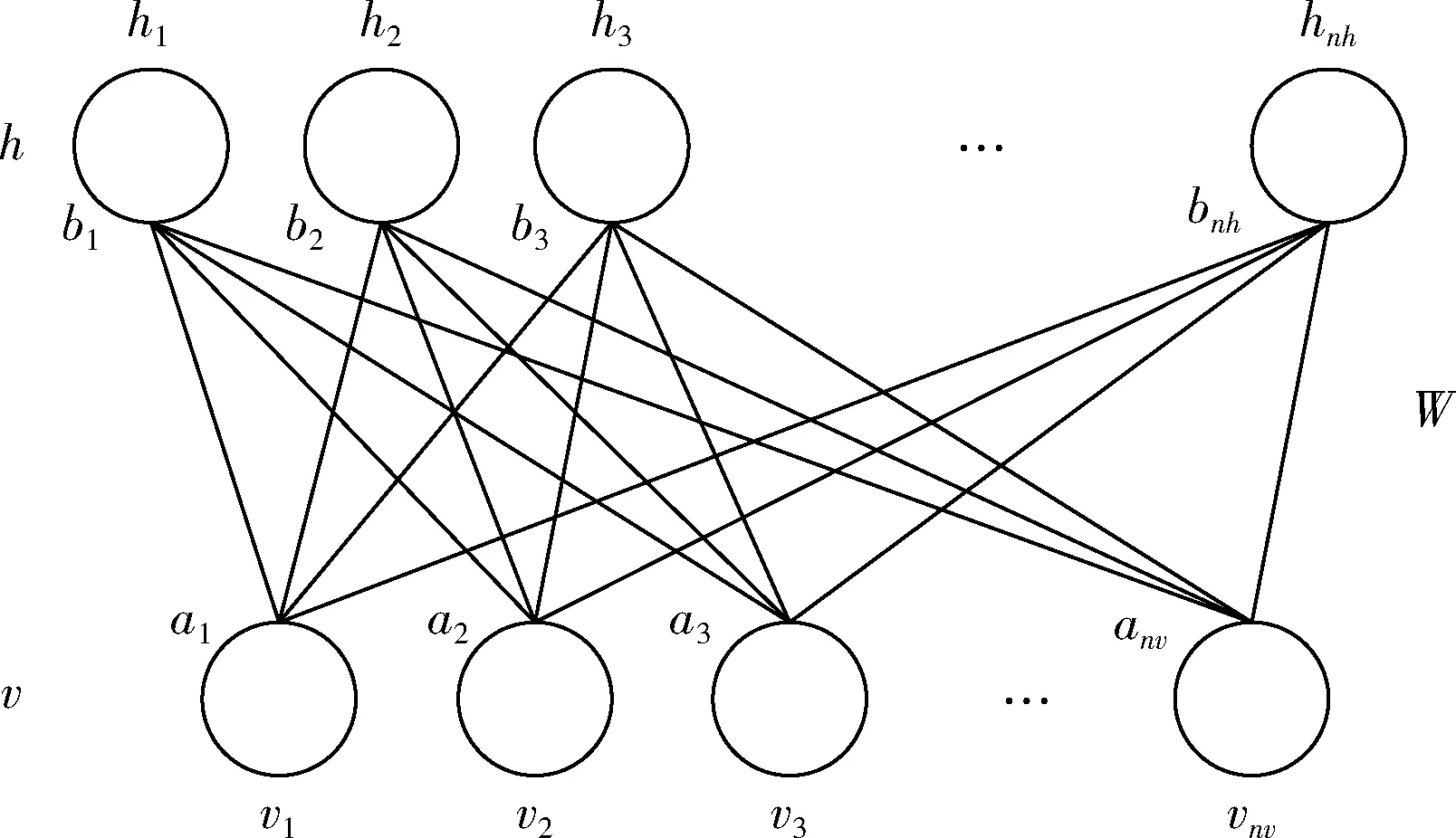
图1 受限玻尔兹曼机结构
图1中,h->Hidden Layers;v->Visible Layer;W->Weight。 RBM为一个基于能量的模型,其能量函数可以由式(1)所示
(1)
其中,θ={w,a,b} 为未知参数vi、hj分别表示第i个可见单元的值和第j个隐藏单元的值,ai、bj分别表示第i个可见单元和第j个隐藏单元的偏置,wij为神经元i和j之间的连接权值。为了方便讨论,假设所有可见单元和隐藏单元的取值均为0或1。根据式(1)的能量函数,可以得到 (v,h) 的联合概率分布为
(2)
(3)
其中, Z(θ) 为归一化因子,由于RBM同一层节点间无连接,故同一层中的节点互相独立,在已知v或h时,hj或vi的值为1的条件概率分别为
(4)
(5)
其中,sigm为激活函数,其函数表达式为
(6)
根据式(4)和式(5),在已知v的条件下,可以求出h的概率分布;反之,也能通过h的概率分布对v进行重构。
1.2 RBM训练方式
RBM训练过程即样本概率分布拟合过程。在1.1节已得到RBM联合概率分布,通过极大似然估计法获取样本概率分布最大化情况下的未知参数θ。
RBM训练方式包含对比散度法(contrastive divergence,CD)与并行回火法(parallel tempering,PT)。CD算法在进行目标分析的过程中通过Gibbs不断迭代得到优异的采样梯度作为近似似然函数的真实梯度值,虽然训练效果明显,但是存在严重的偏估计[11],同时当训练数据过度复杂时会导致Gibbs采样链陷入局部极小域。PT算法通过对高温以及低温链条进行并行分析,经过不断迭代,得到真实梯度近似值,对于复杂数据分析的效果明显高于CD算法。但是PT算法在进行数据分析过程中需要大量的数据交换操作,工作效率较CD算法较低。本文数据分析采用并行分布式系统,与PT算法特征互补,是目前训练RBM网络最理想的算法。
1.3 深度信念网络模型(DBN)
DBN是由多个RBM按照一定规律构成的深度学习模型,通过无监督贪婪算法对网络模型反复循环训练,采用训练数据对网络参数进行微调,有效避免随机初始化参数带来的局部最小问题,可完成原始数据的完美建模,其结构如图2所示。
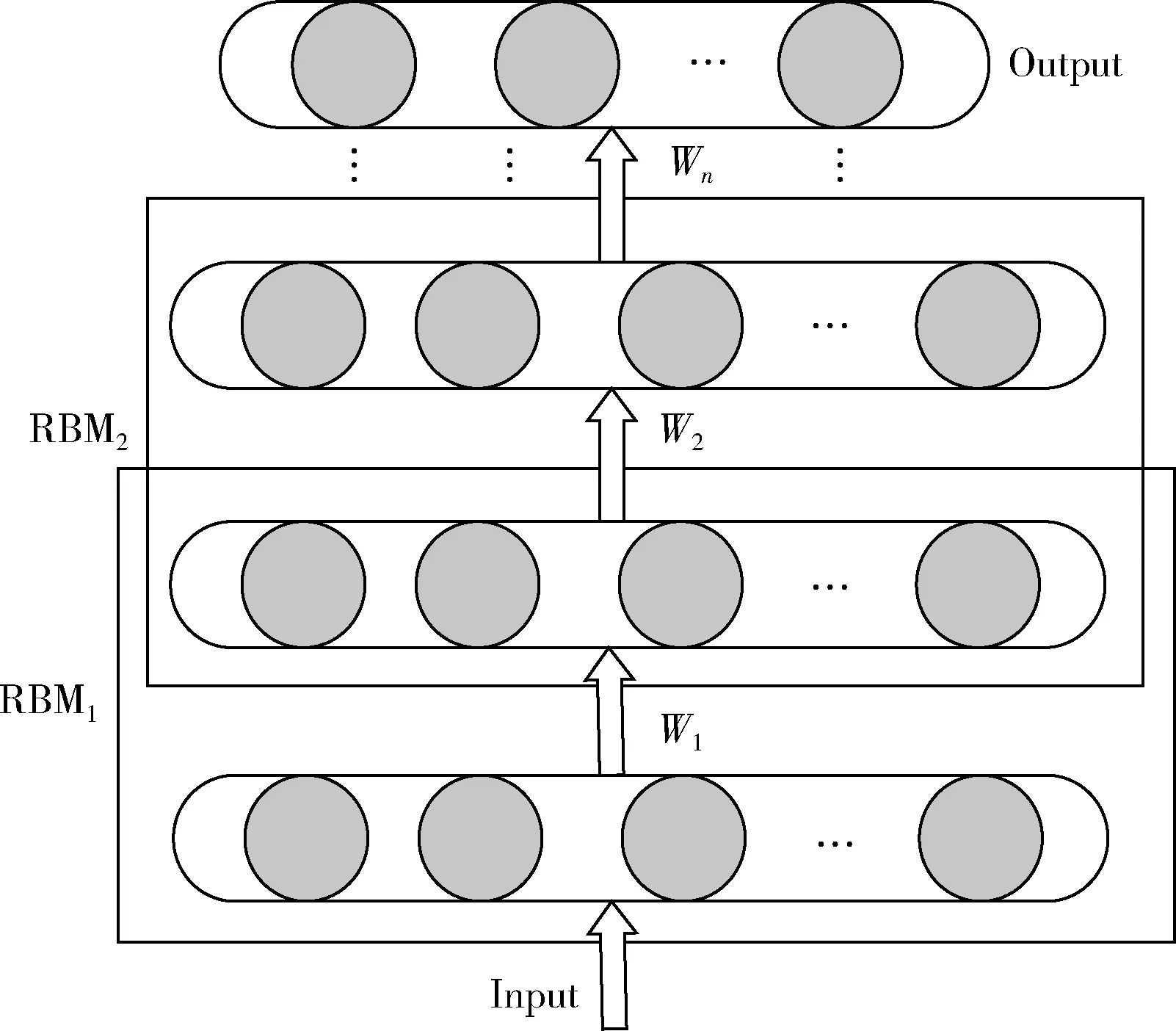
图2 深度信念网络模型
2 构建级联与深度信念网络分层检测框架
2.1 恶意代码的特征信息提取
获取有效的恶意代码样本集是实验进行基础,特别是深度学习背景下的恶意代码检测,只有确保训练样本的数量、类型足够大,才能确保检测结果的准确性。通常情况下,恶意代码的获取包含用户端采样、公开恶意代码网络数据库以及Nepenthes等恶意代码捕获工具3种有效的途径。
基于深度学习的恶意代码特征信息的提取所采用的分析方法有两种:一种是静态分析方法,另一种是动态分析方法。恶意代码静态特性提取采用信息逆向处理方式获取样本序列特征、字符串特征以及API调用特征等选取数据特征信息;恶意代码动态特征的提取采用沙箱技术完成样本信息检测,根据检测报告进行恶意代码行为特征的提取。
为提升恶意代码检测分类的准确性,将检测信息转化为二进制文件,并采用信号处理与稀疏表示相结合的方法从多个不同的角度进行线性表示,根据恶意代码纹理信息的相似性特征实现恶意代码的分类。对于本文中深度学习框架的设计采用Boosting算法与LBP级联稀疏表示算法相结合的方式,融合恶意代码多种不同类型的特性,实现恶意代码的静态分析以及动态深度学习,抽取出恶意代码的行为特征并实现特征融合,嵌入自动学习深入检测框架,提升系统检测的可扩展性。
2.2 恶意代码分析检测框架构建
恶意代码传播具有高复制性特征,通常情况下捕获到的恶意代码已留存在病毒仓库中,为提高检测效率,在检测模型设计过程中引入了层次化检测概念,依据从简到繁的检测原则,将Hash值匹配、LBP级联稀疏表示、反汇编特征匹配以及深度信念网络进行级联,层次化结构如图3所示。

图3 分层检测结构
恶意代码检测系统主要分为两部分:模块一是基于现有恶意代码库的数据信息下的恶意代码检测模块,包括Hash值匹配、LBP级联稀疏表示以及反汇编特征匹配;模块二是基于大数据背景下深度学习的恶意代码的深度分析检测,采用深度信念网络对模块一得到的数据结果进行深层次的筛选检测,确定信息中可能存在恶意代码的任务段。恶意代码检测流程如图4所示。

图4 恶意代码检测流程
恶意代码检测工作流程原理分析:
(1)HASH值匹配
基于HASH算法下的恶意代码检测所采用的方法包含MD5、SHA1以及CRC 32等,通过HASH算法任一文件均可以生成一个HASH值。根据恶意代码的传播特性,在进行恶意代码检测前首先判定HASH值是否已存放在恶意代码库,进行初步筛选,提高资源利用率以及恶意代码检测效率。
(2)LBP-级联稀疏表示
LBP(local binary pattern)是对图像局部区域纹理特征的描述。PRICo-LBP特征检测为图像LBP特征的优化操作,能够与平移、旋转等操作完美的融合。假定像素点A, 则以像素点A为圆心,r为半径,提取圆弧上m个邻点,判定其与A点之间的对应关系获取图像的局部特征。设A点的LBP特征为LBPn,r(A), 则有像素点A的旋转不变LBP特征LBPn,i与旋转不变的Uniform LBP特征LBPr,u[13], 定义如下
(7)
(8)
其中,方程式(7)中的ROR(LBPn,r(A),i) 代表将LBPn,r(A) 向右平移i个单位,如ROR(00001111,3)=11100001。 方程式(8)中的gc代表给定点A的像素值,gi代表定点A第i个邻点的像素值。
稀疏表示(sparse representation,SR)的本质是将信号分解到一系列子空间,是降维过程的一般化,同时也是正则项对噪声类型的约束,为多子空间模型。对于给定矩阵X可以由信号矩阵L与噪声矩阵E表示,即
X=L+E
(9)
在分解过程中由于并未给定特定的约束条件,为此对于矩阵X的分解可能存在多种不同的解。为便于计算,选取的信息L需要满足低秩约束,同时噪声E对于信号L影响最小,即满足稀疏约束。所以最终凸优化问题为
(10)
对于矩阵X假如存在分块矩阵W满足
X=XW
(11)
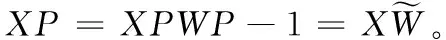
(12)
其中,参数C为自表示的系数矩阵。
对恶意代码进行层次化处理,选用Rotational Uniform LBP完成恶意代码的局部特征提取,通过稀疏表示获取恶意代码的全局特征。引入滑动窗口获取代码间的位置关系,随后采用式(8)提取图像块中每一像素点的Rotational Uniform LBP特征。随后,基于同家族恶意代码具有相似的纹理特征以及代码复用状况,按照式(7)实现恶意代码图像块的LBP特征直方图的稀疏表示。
(3)反汇编特征匹配
综合考虑恶意代码的特征以及实际情况,本课题研究所选用的文件头部特征包括字节名称、字节个数以及动态链接属性。由于同种类型的文本具有相似的特征信息,为此选用汉名距离进行数据计算。对于恶意代码分类,首先将文本信息向量化,结合反汇编技术获取文本信息的操作码(OpCode)以及系统函数序列(SysFunc)。所以,在n确定的情况下,可以获取不同的OPCode以及SysFunc的n-gram特征。
(4)深度信念网络
以模块一中获取得到的恶意代码的特征信息为基础完成恶意代码特征信息的融合处理,随后采用深度信念网络,训练每层的受限玻尔兹曼机,对DBN网络进行无监督反馈调节进行优化,通过最后一层BP神经网络微调整个网络模型,建立训练好的DBN模型,从而达到恶意代码自动检测的要求。
2.3 恶意代码实验检测方案
本实验采用的训练样本以及测试样本均取自Microsoft开源数据集,其中总计包含九大类恶意代码,包含一个.bytes文件与一个.asm文件,用于指导恶意代码特征信息提取以及分类预测。
首先,在获取的九大类恶意代码文件中分别随机抽取N个数据文件完成训练文本集的构建。随后,借助Excel删除训练文本中重复数据集,确保数据的单一性。最后,依据恶意代码纹理相似性原则以及DBN分类策略完成恶意代码特征信息的提取操作,并通过深度信念网络实现恶意代码的深度学习、自动判断。
3 检测平台的设计实现及结果分析
本实验总共选取了6组实验样本,其中所包含的样本个数分别为1200、1500、2000、2500、3000、3500,在每组样本数据中分别选取70%的样本作为训练样本,剩余的30%为检测样本。
高学习率与迭代更新速率为正相关,但是不利于局部/全局优点的提取;低学习率有助于发现局部最优点,但是不利于全局最优点的提取。为此,结合恶意代码特征以及系统设计的实际情况,采用高学习率提取恶意代码全局近似最优,随后采用较小的学习率提取恶意代码的局部最优,通过期望值计算模型全局最优解。根据实际情况,迭代次数选取300次,学习率为0.30,权重衰减参数为0.85。实验过程中纹理特征的选取对于实际实验结果的影响如图5所示。

图5 纹理特征对实验结果的影响
根据实验结果显示,检测文件在0至1500之间随着检测文件的维度不断上升,分类准确率呈现上升的趋势;随后文件检测概率呈现下降的趋势,为此本文实现所选取的纹理特征的维度为1500。指令频率特征的选取对于实际实验结果的影响如图6所示。

图6 频率特征对实验结果的影响
根据实验结果显示,频率特征值在0至600之间逐渐增加时,恶意代码检测准确率逐渐增大;随后恶意代码检测准确率逐渐降低,为此本文实验所选取的特征值为600。
综合考虑全局特征,本文实验所采用的DBN层数为两层、纹理特征的维度为1500、频率特征值为600,将检测文件分别输入系统进行深度学习,随后进行实验得到的最终的检测结果见表1。
通过对表1中检测准确率进行计算,最终恶意代码得到恶意代码检测准确率平均可达98.1%。随后,不断增加检测样本的数目,最佳情形下恶意代码检测准确率高达99.2%。

表1 检测准确率分析
为验证本文所设计的层次化恶意代码检测框架的可行性,选取了SVM、KNN、稀疏表示、PRICoLBP以及 PRICoLBP+ 稀疏表示、DBN+BP几种不同类型的恶意代码分类检测模型进行对比,其分类准确率见表2。
通过表2与不同检测模型的对比,采用不同类型的检测框架以及算法模型对于恶意代码检测结果将会产生巨大的影响,通过实验我们可以发现采用SVM模型检测恶意代码得到的检测准确率较低,本文所采用的基于级联与深度信念网络的分层检测(级联+DBN层次化检测)模型具有更高的准确率,最佳情况下可高达99.2%。

表2 不同检测模型对比结果/%
4 结束语
本文结合层次化检测以及深度学习思想,依据恶意代码的入侵特性,采取从简到繁的检测原则,通过级联操作进行恶意代码的初级判定。随后通过深度信念网络,融合检测文件纹理信息以及频率特征,构建自动学习机器模型,实现恶意代码的深层次检测。实验结果表明,基于级联操作与深度信念网络的恶意代码检测模型对于恶意代码检测准确率有积极影响,准确率平均可达到98.1%。最佳情况下恶意代码检测准确率高达99.2%,更优于目前市面上恶意代码检测模型框架。
猜你喜欢
黄河之声(2021年9期)2021-07-21 14:56:34
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
音乐天地(音乐创作版)(2020年2期)2020-04-18 06:44:04
民族音乐(2018年4期)2018-09-20 08:59:04
中国交通信息化(2018年5期)2018-08-21 03:37:40
电子制作(2016年15期)2017-01-15 13:39:09
系统工程与电子技术(2016年2期)2016-04-16 05:16:51
电测与仪表(2014年1期)2014-04-04 12:00:34
