
改进的基于BiLSTM的网络入侵检测方法
2020-07-20 06:15周航,凌捷
计算机工程与设计 2020年7期
周 航,凌 捷
(广东工业大学 计算机学院,广东 广州 510006)
0 引 言
网络入侵检测技术可分为两种类型:基于行为的入侵检测和基于特征的入侵检测。基于特征的入侵检测对于已知的入侵具有较高的准确率,但识别未知的入侵的能力较弱。基于行为的入侵检测对于任何偏离正常行为模型的行为都会将其识别为异常,缺点是容易将正常行为归类为攻击行为。
近年来,研究人员尝试将一些机器学习算法应用到入侵检测系统中。有研究将K近邻算法应用到入侵检测系统中[1]。有研究将支持向量机应用在入侵检测系统中,并采用了卡方检验法将与攻击行为无关的特征去除掉,较之前不删除特征的结果有提升[2]。多种机器学习算法也成功应用在入侵检测系统中,如朴素贝叶斯、决策树等[3]。上述研究都是基于传统的机器学习方法,虽然在样本识别能力上都有提升,但是表达复杂函数的能力有限,泛化能力较弱,因此不能较好地处理复杂分类问题。
本文使用NSL-KDD数据集训练模型并评估模型性能。利用BiLSTM对网络入侵数据进行高级抽象和非线性变换,并采用Batch Normalization机制使神经网络快速收敛,通过多次实验,选择了适当的隐藏层层数和迭代次数,最后获取分类结果。将设置的改进的基于BiLSTM的网络入侵检测方法与多种网络入侵检测方法进行对比,实验结果表明,改进的基于BiLSTM的网络入侵检测方法不仅提高了准确率,而且泛化能力也有提高。
1 相关工作
网络入侵检测的作用是发现未经授权的恶意行为,实质上是对数据进行分类的问题。传统的机器学习算法曾被认为是适合应用于入侵检测领域的算法,并在入侵检测中大量的应用。如使用随机森林的方法进行入侵检测[4],利用Adaboost融合多种传统机器学习方法进行入侵检测[5],虽然这些方法已经提高了准确率,但是这些方法都较依赖于特征选择,泛化能力较弱。
在深度学习发展的早期,深度学习算法因为较难训练所以较少被研究人员注意,早期被应用于入侵检测领域的神经网络有深度信念网络、限制玻尔兹曼机、自编码器,以及深度神经网络。采用深度信念网络在KDD Cup 99数据集上训练入侵检测模型[6,7],其效果要好于传统的机器学习算法,但容易过拟合。
近年有学者提出利用循环神经网络来进行网络入侵检测[8],其研究结果表明循环神经网络在网络入侵检测数据集中进行二分类和多分类的表现都优于传统机器学习算法,此外有文章对循环神经网络在入侵检测方面的应用做了进一步的探讨[9]。由于循环神经网络的变种结构LSTM在自然语言处理领域效果较好,有学者研究其在入侵检测领域的应用[10],认为一个优化的超参数能提升准确率和降低误报率。本文提出改进的基于BiLSTM的网络入侵检测方法,通过特征选择的方法更好地利用数据特征,实验结果表明准确率有提升且泛化能力较好。
2 改进的方法的原理
由于在入侵数据中的各个特征之间可能存在着依赖关系,本文利用BiLSTM神经网络处理数据特征之间的依赖关系,融合Batch Normalization机制使神经网络快速收敛,提出了改进的基于BiLSTM的网络入侵检测方法。
2.1 本文方法的模型
本文方法的模型由3个部分组成:数据预处理部分、训练部分、检测部分。在进行模型训练前,首先要进行特征提取。通过卡方检验法计算各个特征与结果的关联度,最终剔除了12个特征。由于实验中所使用的数据集中含有非数值化特征,而所提出的方法中输入的值必须为数值,所以需要将非数值化特征转换为数值化特征。
由于入侵检测数据集中各个特征的值分布不相同,有些差异过大,为了保证神经网络可以快速收敛,需要对所有特征进行标准化,使输入的各个特征分布相近。
训练模块的核心是使用BiLSTM神经网络从训练数据中提取特征,且利用ADAM优化算法不断迭代更新权重,从而使得网络最后生成的结果达到最佳。根据入侵检测数据集的特点,所设计模型的基本结构如图1所示,其中所使用的优化技术包括RELU激活函数,Bactch Normalization机制,ADAM优化算法。最终检测模块对测试数据进行检测并给出二分类和五分类的准确率,实验结果表明改进的基于BiLSTM的网络入侵检测方法效果较好。
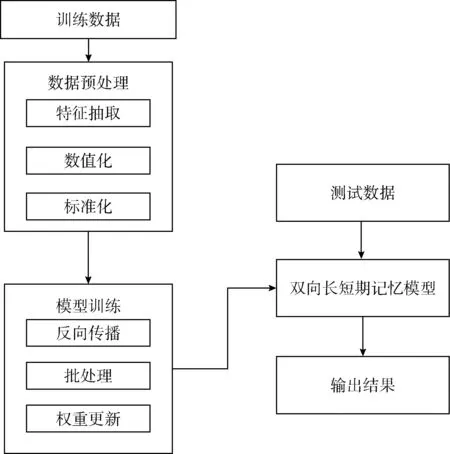
图1 模型工作流程
2.2 改进模型中使用的算法
2.2.1 BiLSTM
本文采用BiLSTM作为模型的核心,利用BiLSTM获取数据的表示向量并进行训练。BiLSTM是由前向LSTM以及后向LSTM组合而成的一个结构,能很好完成数据特征的抽取以及运算。LSTM全名为长短期记忆网络,其是循环神经网络上的一个特殊的结构,能够很好保存长数据特征的依赖关系,在自然语言处理领域被广泛使用。LSTM由3个门组成:遗忘门、输入门、输出门。遗忘门控制冗余信息的消除,输入门控制输入信息的保留,输出门接收遗忘门和输出门的信息经过筛选后传递给下一个LSTM单元。
LSTM单元的计算过程如下
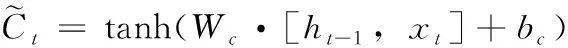
其中,ft代表的是遗忘门,Wf、Wi、Wc、Wo代表的是神经网络权重,bf、bi、bc、bo代表的是偏置值,ht代表t时刻的网络输出。而BiLSTM是LSTM的改进版,能很好解析双向数据信息,提供更加细粒度的计算,计算过程如下
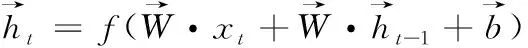
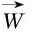
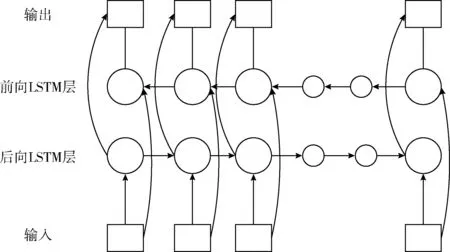
图2 BiLSTM结构
2.2.2 Batch Normalization
在利用BiLSTM对数据进行解析之后,在神经网络中数据分布可能发生了变化,本文为了解决训练深层神经网络时数据分布的不一致,引入Batch Normalization机制。Batch Normalization可以加快深层神经网络的训练,其在激活函数对前一层输入的数据进行非线性变换之后再进行归一化,可确保网络的可训练性,并且可以让神经网络持续保持输入数据分布的一致性,从而减少网络内部的节点分布发生较大的变换。使用Batch Normaliztion机制可以加快网络收敛的速度并且保持神经网络的表征能力。
Batch Normalization在每一层神经网络的计算过程如下
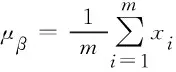
其中,B表示一个批次中有m个激活值,x′i表示归一化之后的值,yi表示经过BN变换之后的值。
3 实验与结果分析
本文设计了两个实验来评估本文入侵检测模型在二分类以及五分类上的表现。二分类分为正常和异常两种,五分类有Normal、R2L、Probe、R2L、U2R这5种。同时设置了MLP(多层感知机)、NB(朴素贝叶斯)、RF(随机森林)、SVM(支持向量机)、RNN(循环神经网络)、LSTM(长短期记忆)等算法作为对比。
实验使用Keras框架实现改进的基于BiLSTM网络入侵检测模型,使用的集成开发环境为Pycharm,实验数据集为NSL-KDD数据集,Keras框架可以更简单构建神经网络,该框架支持CPU和GPU两种环境。本文实验环境是Lenove启天M415,CPU为Intel core i5-7500@3.40GHz,RAM为8GB。
3.1 数据集
实验所用的数据集是在2009年公布的NSL-KDD数据集,NSL-KDD数据集是在KDD CUP 99基础上去掉了一些冗余的数据,使得分类器不会偏向更加频繁出现的记录并且能够获得更高的准确率。由于NSL-KDD数据集已经合理地设置了训练集和测试集,这使得不同研究工作中的评估结果可以相互比较。在入侵检测领域,NSL-KDD数据集被广泛的使用[11]。
NSL-KDD数据集包括3个主要文件:KDDTrain,KDDTest+,KDDTest-21。KDDTrain中共有125 973条数据,KDDTest+共有22 544条数据,KDDTest-21共有 11 850 条数据,数据集描述见表1。在3个文件中都包含了41个特征和一个标识符,其中1-10号特征为基本特征,11-22号特征为内容特征,23-41号特征为流量特征,在实验中将KDDTrain作为本次实验的训练集,将KDDTest+和KDDTest-21作为测试集。根据前面41个特征,可以在数据集中分为4种攻击类型:Dos、R2L、U2R、Probe,关于Dos、R2L、U2R、Probe的描述如下所使:
(1)Dos(拒绝服务攻击):该攻击会占用过多的计算资源或内存资源从而导致计算机无法处理合理的请求;
(2)R2L(远程攻击):攻击者无法直接访问受害计算机,通过尝试获得该计算机的用户身份来获取本地访问;
(3)U2R(本地攻击):攻击者使用本地普通用户访问系统,并利用某些漏洞获取对系统的更高访问权限;
(4)Probe(探测攻击):攻击者通过探测器收集目标系统潜在漏洞的信息用于进一步的攻击。
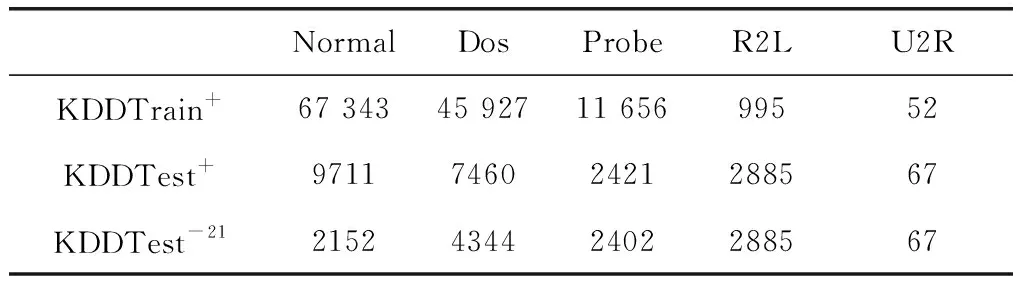
表1 数据集中各种类型的数量
3.2 数据预处理
3.2.1 数值化
由于NSL-KDD数据集中数据分布的不平衡以及特征类型不统一,这将使研究工作变得困难,所以需要对数据进行处理。在NSL-KDD数据集中存在38个数值型特征和4种非数值型特征,由于模型的输入必须为数值化的特征,所以需要将非数字特征转换为数字化特征,例如’service’,’protocol_type’,‘flag’等特征,在protocol_type中有3种不同的类型’tcp’,’udp’,’icmp’,这3种类型将会被转换为数字‘1’,‘2’,‘3’。而‘flag’特征有11种类型,‘service有30种类型都会被转换成相应的数字。在二分类中标识符有Normal和Anormal两种类型,将其转换为1,0,而在多分类中,标识符有5种类型分别是dos, normal,probe, r2l, u2l,则将其转换为数字0,1,2,3,4。
3.2.2 特征选择
特征选择是机器学习中的重要组成部分,使用特征选择是为了获得较高的准确率。对于特征选择,最常用的是过滤式方法和包裹式方法。在过滤式方法中,采用基于各种统计检验中的分数来选择特征,通过统计检验计算因变量和自变量的相关性来测量特征的相关性。包裹式方法则通过测量特征子集与因变量的关联性来查找特征的子集。因此,过滤方法可以在任何训练模型中使用,而在包裹式方法中,所选择的最佳特征子集最终用于特定的训练模型。实验选择使用过滤式的方法进行特征选择。在实验中需要删除一些不必要的特征,这些特征与攻击没有任何关联并且会降低入侵检测系统的性能。有研究使用了多种特征选择方法选择出与攻击类型相关的特征[12],攻击类型与特征之间的联系见表2。在实验中使用卡方检验的方式进行特征选择,经过观察得知7,8,11,14这4种特征几乎全为0对于实验毫无帮助,9,20,21与各类攻击类型基本无关联,通过卡方检验法计算15,17,19,32,40这5种特征在实验中没有帮助,故删掉这12种特征,最后保留29个特征作为输入。

表2 攻击类型与相关特征
3.2.3 标准化
在进行训练之前,通常要根据数据的分布决定是否要标准化,将数据统一线性映射到[0,1]的区间上。对数据进行标准化之后可以加快网络的收敛速度,还可以提升模型的精度。根据对KDDTrain训练集的分析,在特征’same_srv_rate’中存在最大值为1,最小值为0.01,两者之间差距较大,但是其中还有类似’protocol_type’的离散型特征,故需要将离散型特征提取出来之后进行标准化。标准化公式如下
(1)
3.3 评价指标
在入侵检测领域,有很多指标可以评估模型的性能,AC(准确率)是最重要的评价指标,因此在本文模型中准确率会作为评估指标之一。此外模型还设置了DR(召回率)和FPR(误报率)两种指标用于更好的评估模型的性能。
AC表示为在所有样本中模型能判断正确的比例,公式如下
(2)
DR是判断正样本数在正样本实际数上的比例,公式如下
(3)
FPR则是判断为正样本的负样本数在负样本实际数中的比例,公式如下
(4)
关于上述公式中TP表示预测是正样本,实际上也是正样本。FP表示预测是负样本,实际上是正样本。TN表示预测是负样本,实际上也是负样本。FN表示预测是正样本,实际上是负样本,表3为混淆矩阵表。显而易见,评估一个模型的性能则是看其是否具有高准确率,同时还有较低的误报率。

表3 混淆矩阵
3.4 二分类
在二分类实验中,将KDDTrain数据集的29维特征作为输入,因此本文模型中有29个输入节点,由于只是二分类,故只需要一个输出节点作为输出。为了训练出最好的模型,本文中设置的训练批次为500次,设计共有5层神经网络,其中有4层是BiLSTM层,最后一层作为输出层,前面4层结点为128个,其中每一层都采用了Batch Normalization机制使得每一个训练过程都保持同分布性。此外,实验中设置了SVM、RF、MLP、RNN等算法作为对比。
在所给的3个数据集中,改进的基于BiLSTM的网络入侵检测模型在KDDTrain训练集上的准确率为99.51%,在KDDTest+数据集的准确率为86.18%,在KDDTest-21数据集的准确率为76.96%,对比其它机器学习算法,该模型有较高的准确率和较好的泛化能力。RF,SVM等机器学习算法在该数据集中的准确度较低,并给出了基于RNN的入侵检测模型在NSL-KDD数据集上的准确率[8]。实验中给出了改进的基于BiLSTM的网络入侵检测模型在NSL-KDD数据集的测试结果,在图3中做一个全面的对比,表4 给出了该模型在KDDTest+测试集上的混淆矩阵,表5给出了该模型在KDDTest-21测试集上的混淆矩阵。最后可以观察到改进的基于BiLSTM的网络入侵检测模型所获得的准确率最高,同时计算出模型在KDDTest+数据集中的召回率为79.15%,误报率为9.17%。
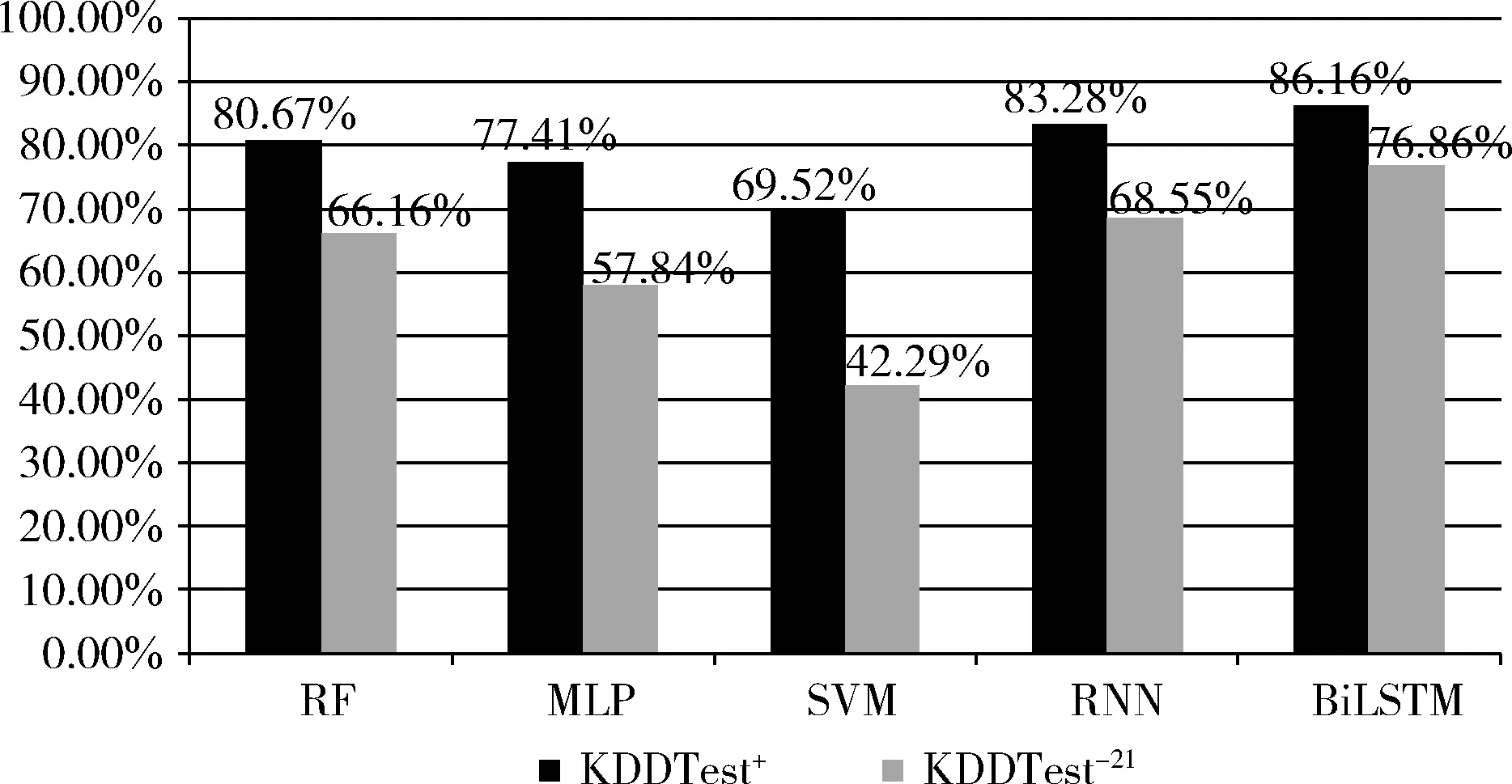
图3 各类算法在二分类中的准确率

表4 KDDTest+测试集的混淆矩阵

表5 KDDTest-21测试集的混淆矩阵
3.5 五分类
在五分类的实验中,将KDDTrain数据集的29维特征作为输入,与二分类不同的是,输出节点为5个代表5种类别,同样设置了5层神经网络,其中有4层是BiLSTM层,最后一层作为输出层,每层隐藏结点为128个。
为了更好评估改进的基于BiLSTM的网络入侵检测模型的性能,设置了MLP、RF,SVM,LSTM等算法作为比较。图4展示了该模型在KDDTest+和KDDTest-21测试集上进行五分类的结果,实验结果显示模型在 KDDTest+测试集上准确率为78.65%,在KDDTest-21测试集上准确率为60.11%,实验结果表明了该模型明显要优于MLP、RF、SVM、LSTM等算法。
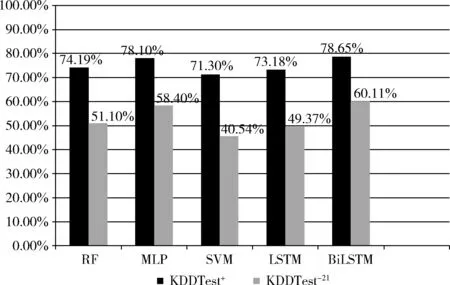
图4 各类算法在多分类中的准确率
为了更直观的观察模型的表现,在表6中展示了该模型在KDDTest+测试集上的混淆矩阵,表7展示了该模型在KDDTest-21测试集上的混淆矩阵。
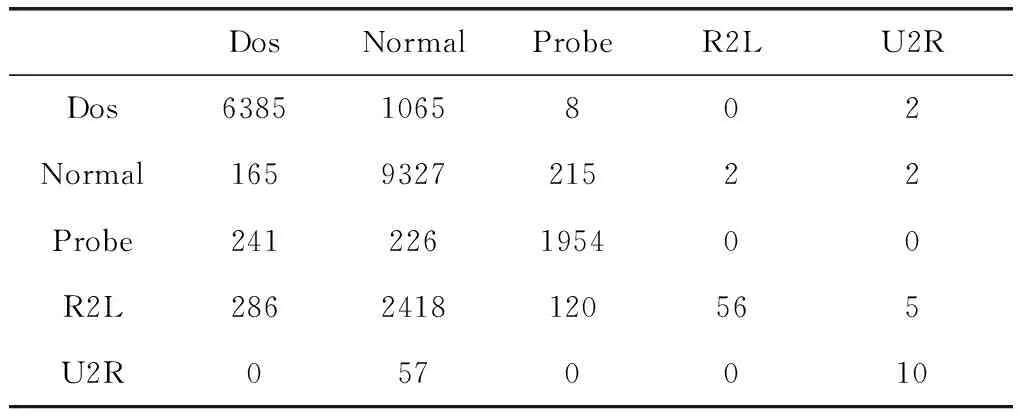
表6 KDDTest+测试集的混淆矩阵
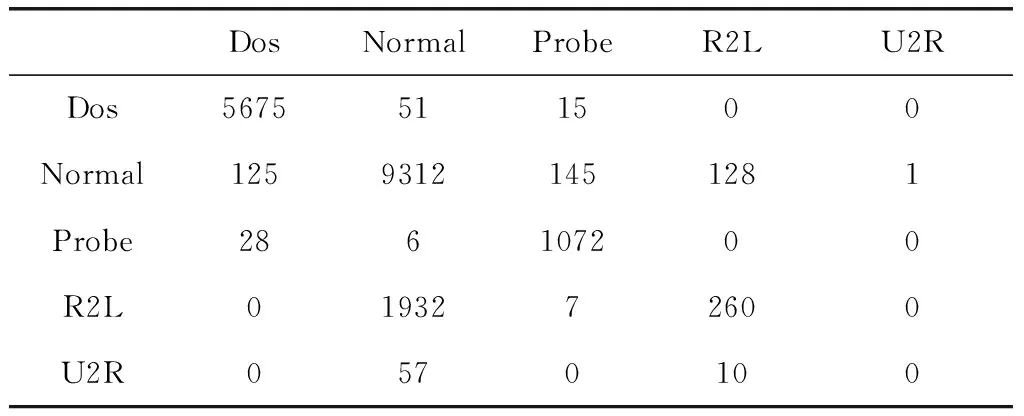
表7 KDDTest-21测试集的混淆矩阵
4 结束语
为了更好利用入侵检测数据之间存在的依赖性,提高入侵检测系统的准确率和泛化能力,本文提出一种改进的基于BiLSTM的网络入侵检测方法,利用BiLSTM获取数据的表示向量,在模型中加入Batch Normalization使神经网络快速收敛,最后在NSL-KDD数据集上进行了比较实验。实验结果表明,本文方法在二分类和五分类的准确率和泛化能力较其它的入侵检测方法都有提升,且计算时间耗费较少,从而在整体的性能表现上,本文方法要优于其它对比方法。在未来的工作中将进一步提升模型的性能,将对不平衡数据进行处理并加入注意力机制,以提高改进方法的召回率和准确率。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电子制作(2019年19期)2019-11-23
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
电子制作(2019年24期)2019-02-23
中国交通信息化(2018年5期)2018-08-21
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
