
基于非对称空间金字塔池化的立体匹配网络
2020-07-17 07:35王金鹤苏翠丽孟凡云车志龙
计算机工程 2020年7期
王金鹤,苏翠丽,孟凡云,车志龙,谭 浩,张 楠
(青岛理工大学 信息与控制工程学院,山东 青岛 266000)
0 概述
三维场景信息重建是计算机视觉应用的关键,如车辆自动驾驶和医学内窥镜成像技术的应用,都是基于该技术对目标场景或物体的深度信息进行计算。深度信息计算目的是获取双目图像中像素点的视差值,而视差值取决于空间景物在左右视图中的对应关系,这种寻找左右图像平面之间对应点的过程称为立体匹配[1]。
传统立体匹配方法通常包含4个步骤,即匹配代价计算、匹配代价聚合、视差计算和视差细化。早期的立体匹配算法分为全局匹配、局部匹配以及两者结合的半全局匹配算法。但是这些方法均通过人工设计代价函数学习图像特征之间的线性关系,不仅计算代价昂贵,而且在遮挡、重复纹理、弱纹理等区域达不到理想的匹配效果。
深度学习技术的发展使计算机视觉研究得到重大突破。卷积神经网络(Convolutional Neural Network,CNN)能够进行复杂的非线性表示,具有强大的表征能力,近年来被广泛用于图像识别及立体匹配的应用。进而,基于卷积神经网络的立体匹配方法相继被提出。但现有方法多采用深而复杂的3D卷积网络架构进行端到端的视差图学习。尽管这些立体匹配方法在网络框架和训练方式上存在巨大差异,但是通常都采用Siamese网络作为立体图像对的特征提取器,由此可见Siamese网络结构在立体匹配中起到基础性作用。
目前有些研究避免使用复杂的端到端CNN框架,而是针对Siamese网络结构进行改进。受此启发,本文改进基础的Siamese特征提取网络,引入空间金字塔池化(Spatial Pyramid Pooling,SPP)思想优化池化方式,以充分利用图像信息。通过构建非对称空间金字塔池化(Asymmectric SPP,ASPP)模型,在特征提取阶段对图像块进行多尺度特征提取,以期获得更准确的视差估计结果,提高匹配精度。
1 相关研究
基于卷积神经网络的立体匹配方法主要包括基于CNN的匹配代价学习、基于CNN的视差回归和基于CNN的端到端视差图获取三类。
1)基于CNN的匹配代价学习方法主要以图像块之间的相似性作为匹配代价。文献[2]成功地将CNN应用到匹配代价计算中,通过深层Siamese网络来预测图像块之间的相似性得分,以此获取图像块的匹配代价。文献[3]在此基础上提出一种缩小型立体匹配网络,较好地解决了原模型处理过程中耗时多的问题。文献[4]研究了一系列用于图像块匹配的二分类网络,并且建立双通道网络架构进行视差估计。此后,文献[5]提出使用内积层计算图像块对应像素的相似性,该方法可实现一秒内计算准确结果,并且将匹配任务转化为多分类问题,类别是所有可能的视差。文献[6]结合残差网络[7](ResNet)提出一种高速网络来计算匹配代价,并且设计一个全局视差网络预测视差置信度得分,进一步优化了视差图。
2)基于CNN的视差回归方法把视差图获取作为立体匹配的核心任务,其质量的优劣对三维信息重建有直接影响,因此,目前存在较多侧重于视差图后处理方法的研究[8-9]。文献[10]提出经典的Displets网络,使用3D卷积并通过物体识别和语义分割处理图像对间的对应关系,大幅提高了匹配精度。文献[11]提出检测-替换-优化(Detect-Replace-Refine,DRR)结构进行视差估计,通过标签检测、错误标签替换、新标签优化来改善分类效果。文献[12]提出半全局匹配网络SGM-Net,通过训练网络学习预测SGM的惩罚项,以取代人工调整方法。
3)基于CNN的端到端视差图获取方法不对端到端网络进行复杂后处理,而是输入左右图像对网络直接学习输出视差图。文献[13]提出端到端DispNet网络结构结合光流估计进行立体匹配任务学习的方法,并且合成一个大型立体图像数据集SceneFlow用于网络训练。此后,文献[14]在DispNet的基础上提出了级联残差学习(CRL)网络。该网络分为DispFullNet和DispResNet两部分,前者输出初始视差图,后者通过计算多尺度残差优化初始视差图,最后将两部分网络的输出结合构成最终的视差图。文献[15]提出了效果较好的GC-Net结构,其利用3D卷积获得更多的上下文信息,实现了亚像素级别的视差估计。为获得图像更多的关键信息,有学者采用深度特征融合和多尺度提取图形信息的卷积神经网络[16-17]。文献[18]利用图像语义分割思想,同时结合全局环境信息提出了PSMNet结构,其主要由两个模块组成:金字塔池化和3D卷积神经网络。金字塔池化模块通过空间金字塔池化[19]和空洞卷积[20]聚合不同尺度和位置的环境信息构建匹配代价卷。3D卷积神经网络模块通过将多个堆叠的沙漏网络与中间监督相结合来调整匹配代价卷,同时提高对全局信息的利用率。
上述方法都是利用深而复杂的3D卷积网络架构进行端到端的视差图学习,通常都采用Siamese网络作为立体图像对的特征提取器。由此可见,立体匹配本质上依赖于使用Siamese网络来提取左右图像特征信息。文献[21]回避了复杂的端到端CNN框架,而是对基础的Siamese网络结构进行改进,其在文献[5]网络中引入普通池化和反卷积操作,利用池化操作扩大了网络的感受野,为后续匹配提供了更多的视觉线索,并使用反卷积操作恢复图像分辨率。
本文改进基础Siamese特征提取网络,通过引入空间金字塔池化(SPP)思想优化文献[5]方法原有的池化方式,构建非对称金字塔池化模型,在特征提取阶段对图像块进行多尺度特征提取,进而提高匹配精度。
2 非对称金字塔网络结构
如前所述,本文所提出的网络架构仍采用图像块作为输入,左右图像块的像素大小遵循先前工作,输出为图像块的相似性。本节首先介绍空间金字塔池化模型,在此基础上改进池化方式,提出非对称空间金字塔池化模型,最后详述整个网络架构及其他改进细节。
2.1 空间金字塔池化模型
空间金字塔池化[19](SPP)对前一卷积层输出的特征图进行不同尺寸池化操作,得到不同分辨率的特征信息,从而有效提高网络对特征的识别精度。文献[19]给出了详细的池化过程:首先使用3种不同刻度的窗口对特征图像进行划分,每一种刻度代表金字塔的一层,划分后的每一个图像块大小为window_size;然后对每一个图像块都采取最大池化操作,提取出更高级的图像特征信息。图像划分计算公式如下:
win_size=「a/n⎤
(1)
str_size=⎣a/n」
(2)
其中,win_size和str_size分别表示池化窗口和池化步幅的大小,a表示金字塔池化层输入的特征图尺寸为a×a,n表示金字塔池化层输出的特征图尺寸为n×n,「·⎤表示向上取整,⎣·」表示向下取整。
如图1所示,对左输入图像进行金字塔池化操作:若前一卷积层输出为13×13大小的特征图,池化之后的特征图尺寸为2×2,则win_size=「13/2⎤,str_size=⎣13/2」,结果分别为7、6,即采用窗口为7、步幅为6池化操作即可得到2×2尺寸的特征图。
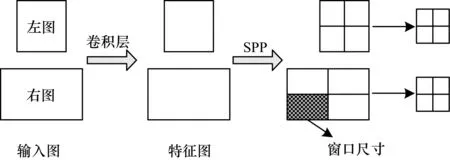
图1 原金字塔池化过程
如果对右输入图像采用相同刻度的池化操作,SPP模型也会将右图按照刻度划分,最终输出与左图相同尺寸的特征图像。但实际右输入图像块尺寸远大于左图像块,这表示右图像块包含更多的特征信息,若采用相同尺度的池化方式,将直接导致右原始图像丢失大部分特征信息,最终降低网络视差估计的精度,影响网络的匹配效果。
2.2 非对称空间金字塔池化模型
针对上述SPP模型存在的图像特征信息缺失问题,本文改变对右图像块的划分方式,重新定义金字塔池化公式,如式(3)~式(5)所示:
k=「|l-a|/n⎤
(3)

(4)

(5)其中,a、l表示金字塔池化层的输入特征图尺寸,n表示金字塔池化层输出的特征图尺寸,win_h和win_w表示池化窗口高度和宽度,str_h和str_w表示两个维度上池化步幅的大小。
改进后的金字塔池化过程如下:首先按照金字塔池化原理对右图多于左图的部分进行初步划分,得到初始划分图像块大小k;然后以整幅图像为池化层的输入,在图像高度的维度上仍采用原金字塔划分刻度,大小为n,但在图像宽度的维度上采用新的划分刻度(n+k)。改进后的池化过程如图2所示。
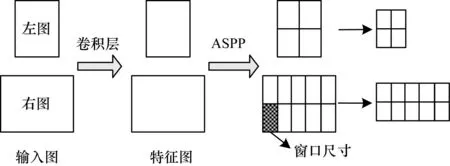
图2 改进的金字塔池化过程
改进后的池化模型对左右特征图像采用不同刻度的划分方式,针对右图实现了两个维度上不同尺寸的池化,右图被划分为更均匀的图像块,进行后续最大池化操作时能够得到更详细的特征信息。由于从整个池化结构上看,左右分支呈现非对称性,因此将本文改进后的池化操作称为非对称空间金字塔池化(ASPP)。
如图3所示,ASPP网络的左右分支分别以不同尺寸的图像块作为输入,左、右输入分别为10×10、10×(10+maxDisp)的图像块(maxDisp表示最大视差值)。输入图像经卷积层输出通道数为64的特征图像,图像尺寸不变。然后经过非对称金字塔池化,池化尺寸分别为4×4、2×2、1×1,对应生成3种不同尺度和精度的特征图像,通道数均为64。之后,通过上采样将3种特征图恢复为原始图像尺寸,最后采用级联操作将其连接得到通道数为192(64×3)的特征图像。本文将池化及后续上采样、级联步骤归一化称为非对称池化模块。此外,整个网络模型左右分支共享权值。

图3 非对称空间金字塔池化模型
2.3 改进的网络结构
为充分利用图像特征信息,本文在LuoNet网络基础上引入金字塔池化层,扩大目标像素位置的感受野,获取更多的图像信息,LuoNet网络结构如图4(a)所示。由于原有的金字塔池化操作会造成部分图像信息缺失问题,因此本文改进了网络结构,如图4(b)所示,使ASPP模型可以提取到更多的特征信息,达到更精确的匹配效果。

图4 改进前后网络结构对比
本文网络结构设计流程如下:
1)图像先经过4个卷积层(Conv)、批标准化和线性整流函数(ReLU)。
2)非对称池化模块(ASPP)对特征图像进行不同刻度的池化操作。
3)再次经过两层卷积操作(Conv)融合特征信息。
4)Inner Product层利用内积计算每个视差下左右特征的相似性得分。
5)Softmax函数计算每个视差的概率值,形成多分类网络模型。数字3和1分别代表卷积核的大小为3×3、1×1,64、128、192代表卷积核通道数。
此外说明,本文网络结构中所有卷积层和池化层中的步长均为1。
本文主要有两处结构上的改进:基于改进的金字塔池化模型提出非对称金字塔网络结构,网络通过多尺度提取图像特征信息改善了匹配效果;将网络深度由4层加深至7层,提升了网络匹配精度,并且额外的卷积层使用较的小卷积核,减少了特征维度,加快了网络收敛速度。
网络将不同尺寸的左右图像块作为输入,首先利用4层卷积神经网络层进行特征提取,每个卷积层对图像做卷积核为3×3、通道数均为64的空间卷积;然后经过空间批标准化和ReLU层;之后非对称池化模块将特征图像压缩到3个不同尺度中,得到多尺度特征图像;最后通过双线性插值将特征图像上采样至原始图像分辨率,并利用级联操作进行连接输出通道数为192的特征图。由于经过非对称金字塔池化后的特征图像含有不同精度的特征信息,因此本文叠加了两层额外的卷积层进行特征信息融合。为加快网络的收敛速度,额外的两个卷积层的卷积核尺寸分别设置为3×3和1×1,其通道数分别为128和64。为保留以负值编码的特征信息,同样删除了最后卷积层的ReLU线性激活函数。内积层以一种简单的方式计算特征之间的内积,并将其作为不同像素间的匹配代价。最后通过Softmax函数进行视差分类预测,类别是所有可能的视差值。本文网络结构中所有卷积层和池化层中的步长均为1。
3 实验与评估
在本文实验中,所有模型的训练、验证及预测均采用Tensorflow深度学习框架,操作系统为ubuntu18.04,网络训练及性能测试的GPU服务器为NVIDIA GeForce GTX 1060Ti。实验使用KITTI 2012[22]、KITTI 2015[23]数据集及Middlebury测试集上进行模型训练和视差评估。
3.1 实验过程
KITTI2012数据集包含194对带有视差真值的左右图像,随机选取160对图像作为模型训练集,剩余34对图像作为模型验证集。KITTI2015数据集包含200对左右图像,同样从中随机选取160对图像训练模型,剩余40对图像用于模型验证。每对图像大小为375像素×1 241像素。使用Middlebury测试集提供的Cones测试图像对、Teddy测试图像对和Tsukuba测试图像对来评估视差图,每对图像都含有视差真值,大小为375像素×450像素。在模型训练之前,对所有立体图像均进行预处理操作,分别通过减去平均值、除以像素强度标准差的方式将图像归一化为零均值和单位标准差的图像。
实验步骤与文献[5]中一致,首先从左右立体图像数据集中随机提取图像块,将提取出的右图像块以最大视差值进行拓展。如前所述,分别使用尺寸为4×4、2×2、1×1的池化操作。网络训练时图像块尺寸设置为10×10,最大视差值设置为128,验证时KITTI数据集上的图像块均随机截取275像素×640像素,Middlebury测试集的图像对大小仍为375像素×450像素。
网络所有参数使用He初始值[24]随机初始化,后续采用随机梯度下降(SGD)算法进行参数更新,网络损失函数采用softmax交叉熵损失函数,并采用AdamOptimizer算法[25]优化损失函数。本文以初始学习率1e-3进行网络训练,每迭代400次对学习率进行一次更新,逐步减小学习率直至模型训练稳定。本文设计批处理尺寸为128,网络总迭代次数为40k次,学习率由1e-3降至1e-4。
3.2 超参数分析
对算法性能产生影响的超参数分析实验,第1组是对2.1节中的k值进行影响分析,第2组是额外卷积层参数对比分析,参数为卷积核的尺寸。两组实验均使用KITTI2015数据集。
1)k值影响分析
本文通过引入k值对文献[19]金字塔池化方式进行改进,因此,对于k值的分析以文献[19]为基准算法进行直接对比。当网络池化刻度为{4,2,1}时,由式(1)、式(2)计算出经金字塔池化后的输出尺寸分别为{(4×4),(2×2),(1×1)};采用非对称金字塔池化,则由式(3)~式(5)进行相关计算,首先是对应参数k为{32,64,128},其对应输出的特征图尺寸分别为{(4×46),(2×28),(1×14)},无疑包含更多的图像信息。
本文实验采用图4(a)所示的网络结构(在最初的两个卷积层之后引入不同的池化结构),两组实验不同之处仅在于池化方式不同,验证数据均使用KITTI2012验证集。以网络匹配率为衡量标准,比较结果如表1所示。表中数据指标为视差值与基准视差差距分别大于2个、3个和5个像素的像素点比例,其中加粗数据表示最优数据。实验结果表明,在同等网络结构设置下,本文方法较对比方法在精度上均有提升,并且取得了最低误匹配率,这证明了改进网络的匹配效果优于其他模型。

表1 k值对匹配误差的影响
2)卷积层参数影响分析
在CNN中卷积核的尺寸对模型训练至关重要,较大的卷积核通常可以带来较大感受野,从而获取到更多的图像信息,但同时较大卷积核会导致昂贵的计算成本,降低模型计算性能。所以,使用更小的卷积核是当前保证模型精度的情况下,提升网络训练速度的一种方式。因此,实验对于图4(b)中额外的卷积层进行分析对比。实验分为3组,分别将卷积核尺寸设置为{1×1,1×1}、{3×3,3×3}、{3×3,1×1},通道数不变,均在在KITTI2012训练集上进行实验,实验结果包括网络错误率和网络损失函数值,如图5和图6所示。可以看出:卷积核{1×1,1×1}的卷积层因为含有最少的参数,其损失函数收敛速度最快,但错误率最高;{3×3,3×3}的卷积层在网络训练初期误匹配率较低,但随着训练时间的增加,其误匹配率降低缓慢,并且最终的损失函数值最高;卷积核为{3×3,1×1}的卷积层错误率最低,损失函数值收敛到最小,并且随着训练时间和迭代次数的增加,其错误率和损失函数值持续减小。因此,改进算法采用{3×3,1×1}的卷积核。

图5 不同卷积核尺寸下的误匹配率曲线

图6 不同卷积核尺寸下的损失函数曲线
3.3 实验结果评估
使用本文方法在KITTI2012和KITTI2015验证集上进行视差估计,并分别与文献[5,21]方法进行误差对比分析,阈值依次设置为2个、3个和5个像素,实验结果如表2和表3所示,其中加粗数据表示最优数据。可以看出,本文方法的错误率在各项指标上均小于对比方法,尤其是像素阈值为3、5时的网络匹配错误率分别从5.84%、4.80%降低至3.88%、2.94%。虽然相比原始方法LuoNet较为耗时,但比SPPNet在时间上提升了约50%。相比于数据集KITTI2012,其在数据集KITTI2015上错误率略高,但是仍低于两种对比方法。由此可以证明,本文方法在精度和速度上都具有一定优势。

表2 在KITTI2012数据集上的测试结果对比

表3 在KITTI2015数据集上的测试结果对比
本文方法与经典MC-CNN[2]匹配方法的比较如表4所示,以2个像素的像素点比例作为阈值,表中加粗数据表示最优数据,结果表明,本文方法较MC-CNN-acrt[2]误差降低了约14%,较MC-CNN-fast[2]方法降低了约11%,本文网络结构在KITTI2012和KITTI2015两个数据集上均实现了较低的错误率。

表4 4种方法的视差结果误差对比
在KITTI2012和KITTI2015数据集及Middlebury测试集上进行视差图预测,输出结果如图7~图9所示。图7和图8中列出2组视差效果对比图,图9列出3组对比结果。特别说明,在本文采用的文献[5]方法中,视差图未经过视差后处理,本文采取同样的处理方式,因此,输出视差图中含有一些噪音,但并不影响实验结果分析。
从图7~图9可以看出,本文提出的非对称金字塔池化网络获得的视差效果更平滑,尤其在Middlebury测试集中,所得视差图不仅含有较少的噪声,而且能够预测到图像物体及图像边缘的视差。例如图7中汽车边缘等细节区域、图9中Cones测试图像(左列)物体的边缘和Tsukuba测试图像(右列)台灯的边缘,本文方法输出的视差图效果均优于LuoNet。图8的匹配效果虽然在某些细节方面不够理想,目标物轮廓较为模糊,但是在没有进行任何后处理的情况下,完整保留了目标物的整体信息,即使视差图中有些区域含有较多的噪声,但本文方法仍能完整地保留不同场景的目标像素信息,并且取得更好的视差效果。

图8 KITTI2015数据集视差图

图9 Middlebury数据集视差图
4 结束语
针对卷积神经网络用于立体匹配时的耗时和信息损失问题,本文结合现有的卷积神经网络架构及池化结构,对金字塔池化方法进行改进,提出非对称金字塔池化模型,并且使用较小的卷积核增加网络深度。实验结果表明,与LuoNet网络结构相比,改进后的网络结构不仅能够加快网络训练收敛速度,而且能够进行多级特征信息提取,提升了网络匹配精度,改善了最终视差效果。但本文设计未使用视差后处理操作,网络处理对象仍是小尺寸图像块。下一步将研究如何平衡输入图像块尺寸与视差效果,并利用残差网络多级信息融合技术对视差图进行优化。
猜你喜欢
计算机应用(2022年9期)2022-09-25
软件导刊(2022年3期)2022-03-25
小型微型计算机系统(2022年1期)2022-01-21
集成技术(2020年6期)2020-11-30
计算机技术与发展(2019年1期)2019-01-21
天津大学学报(自然科学与工程技术版)(2018年6期)2018-05-30
智能计算机与应用(2018年2期)2018-05-23
现代计算机(2016年3期)2016-09-23
系统工程与电子技术(2016年7期)2016-08-21
系统工程与电子技术(2016年7期)2016-08-21
