
《科学数据管理办法》语词分析
2020-07-14 18:32温亮明李洋张丽丽
新世纪图书馆 2020年5期
温亮明 李洋 张丽丽


摘 要 文章分析了《科学数据管理办法》的文本语词,有助于把握国家对科学数据管理的政策导向。文章对《科学数据管理办法》的文本内容进行分词、词频合并、词性筛选、虚词剔除等预处理操作,基于文本预处理结果筛选得出频繁词和热词,构建“语词—条款”共现矩阵并可视化展示。研究发现:《科学数据管理办法》共有11个核心频繁词、9个重点频繁词、8个主要频繁词和若干个一般频繁词,各主题语词在文本中均有对应的核心条款,但主题语词和核心条款分布不均。
关键词 《科学数据管理办法》 自然语言处理 词频统计 关联分析
分类号 G322.0
DOI 10.16810/j.cnki.1672-514X.2020.05.015
Abstract Analysis of the text words of Measures for Managing Scientific Data can help to grasp the policy orientation of national scientific data management. Firstly, this paper performs some pre-processing operations such as word segmentation, word frequency merging, part of speech screening and vocabulary culling for the text content of Measures for Managing Scientific Data. Then, it screens out the frequent words of text and the hot words of each chapter based on pre-processing results. Finally, it constructs a “word-term” co-occurrence matrix and visualize it. Results show that Measures for Managing Scientific Data has 11 core frequent words, 9 key frequent words, 8 major frequent words and several general frequent words, but topic words and core terms are unevenly distribute in the text.
Keywords Measures for Managing Scientific Data. Natural language processing. Word frequency statistics. Correlation analysis.
0 引言
目前,科学数据已经成为支撑国家科技创新和经济社会发展的基础性和战略性资源[1],国际上一些组织和政府已经制定了明确的政策以推动科学数据的管理与开放共享[2]。我国也非常重视科学数据管理与共享工作,从2004年起先后在八个领域建成了国家科技资源共享服务平台[3],并相继出台了一系列领域科学数据管理政策。但与发达国家政策体系相比,我们在数据权益、共享规则等方面的管理政策仍有待健全和完善[4],主要表现为:现有政策侧重于个别行业领域数据的管理,而对其他学科领域数据涉及较少[5];现有政策制定主体几乎全为相关部委或领域数据中心,而无国家层面出台的法规政策,缺乏法律效力[6];缺乏国家宏观统一、明確的政策法规[7-8]。针对这些薄弱环节,我国于2016年12月将“加强和规范科学数据管理的办法”列入中央全面深化改革领导小组2017年工作重点[9];2017年3月,科学技术部会同有关部门启动了《科学数据管理办法》 (以下简称《办法》)编制工作;2018年1月,《办法》经中央全面深化改革领导小组审议通过;2018年3月17日,国务院办公厅正式印发《办法》[10]。《办法》出台后,引起了全社会强烈反响,多家主流媒体做了专题报道,科学技术部、中国科学院等部委召开专门会议宣传贯彻落实,部分省份出台了相应的实施细则,部分专家学者专门撰文论述、建言献策。鉴于此,有必要继续研究《办法》,从更多角度理解《办法》的精神内涵。
1 《办法》研究现状
1.1 意义阐述
《办法》是我国首次面向全领域科学数据出台的国家层面的科学数据管理办法,其实践指导意义重大。齐法制[11]、王卷乐[12]等认为,《办法》首次站在国家高度、面向多领域科学数据,具有划时代意义;郭华东[13]认为,伴随着《办法》的出台,我国迎来了发展科学大数据的重要历史机遇;柏永青[14]等认为,《办法》把我国科学数据管理和共享工作推向了新高度;张丽丽[5]、周玉琴[15]、赵小兰[16]等认为,《办法》为我国科学数据工作确定了行动纲领,突出了国家对科学数据管理和科技创新能力建设的重视。张保钢[17]、邵玉昆[18]认为,《办法》对提升我国科学数据管理水平、发挥国家财政投入在科技创新、经济社会发展、国家安全等方面的产出效益具有重要意义。庄媛[19]认为,《办法》 提出的举措补齐了我国科学数据管理存在的短板。王知凡[20]认为,《办法》出台打通了科技创新和经济社会发展之间的通道,有助于促进创新链和产业链的深度融合。刘敬仪[21]等认为,《办法》为政府决策、公共安全、国防建设和科学研究提供了有力支撑。邹自明[22]等认为,应该抓住《办法》出台的大好时机,着力提升科学数据开放共享理念,研究科学数据标准与共享规范。
1.2 内容解读
对政策文本具体内容的解读,为管理人员、研究人员、相关从业者深入领会《办法》精神提供了借鉴。赛迪智库[23]指出,《办法》的亮点是规定了科学数据强制汇交制度、明确了提高科学数据利用率的具体措施、规定了数据容灾备份制度。邢文明[24]等解读了《办法》中有关科学数据共享与利用的相关条款,认为《办法》明确了科学数据开放、共享与利用的三条原则。秦顺[25]等从管理体制、共享机制、安全措施三个方面对《办法》内容进行了解读。高瑜蔚[26]等比较分析了各地方政府、机构发布的11份《办法》实施细则,发现这些细则具有注重政策协同、突出平台应用、强调保密安全、重视考核评价等特点。白锐[27]等基于多源流模型,从问题源流、政策源流、政治源流三个角度分析了《办法》的政策议程。张洋[28]等从生命周期视角入手解读了《办法》汇交、处理、保存、共享四个方面的内容,并总结了《办法》的指导意义。王继娜[29]认为《办法》未能明确科学数据的所有权及非政府资金资助形成的科学数据的管理问题。储文静[30]等依据《办法》内容构建了基于科学数据全生命周期的高校科学数据管理规范流程。
但是,以上解读多是从性质角度探讨《办法》的意义和内容,尚未从量化角度分析细节问题。本文试图综合《办法》文本的语词之“量”和主题之“性”,从宏观微观相结合的角度进行解读和分析。
2 研究设计
2.1 研究框架
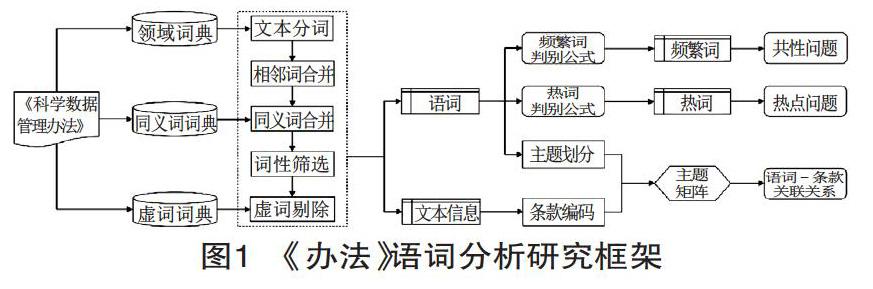
《办法》全文共分为六章、三十三条。由于第三十三条为具体施行时间,其学术意义较浅,因此本文的研究范围仅选择前三十二条文本内容进行分析,具体研究分为三个步骤。
文本预处理。利用自然语言处理技术对《办法》的语词进行领域词典构建、文本分词、相邻词合并、同义词词典构建、同义词合并、词性筛选、虚词词典构建、虚词剔除等操作,得到有实际意义的语词。
文本分析。基于文本预处理结果,选取了语词章节率、词频数、局部章节平均词频数和全部章节平均词频数作为基本指标,并构建频繁词来判别公式筛选《办法》 的频繁词,拓展词频逆文本频率法来抽取《办法》的热词,根据频繁词和热词的特定含义去探索《办法》所关注的共性问题和热点问题。
主题关联分析。基于文本预处理结果,将《办法》语词划分为若干主题,对《办法》文本结构进行了编码处理,基于主题分类结果和编码系列构建“语词-条款”共现矩阵,并进行可视化展示。
按照上述思路,设计了本文的研究框架,如图1所示。
图1中,虚词剔除及其之前的所有操作属于文本预处理阶段,频繁词判别、热词判别及其后续操作属于文本分析阶段,主题划分、条款编码及其后续操作属于主题关联分析阶段,文本分析和主题关联分析属于并列关系。
2.2 文本预处理
文本预处理包括文本分词、语词合并、词性筛选三个流程。
文本分词。首先,删除与研究无关的内容;然后,将有效内容依次导入语义分析系统ICTCLAS,得到初始分词结果。
语词合并。由于ICTCLAS系统以短词语作为分词标准,因此还需要在系统分类的基础上对初始分词结果进行人工干预合并,研读科学数据管理相关主题文献,结合学科领域专业术语,构建专业领域词典。借鉴关联规则分析思想,规定只有当两个语词连续出现的频次满足一定概率时才能进行语词合并,具体判定公式为:
其中,表示语词在文本中出现的频次,表示语词和在文本中连续出现的频次。
词性筛选。由于《办法》是政策文本材料,名词和动词更能代表原文本的重要语义信息,因此本研究选取了名词和动词作为主要研究对象,选取部分副词作为辅助性研究对象。
经上述操作,整个文本内容相当于由章节构成,章节相当于由有序的语词集构成。
2.3 文本分析
2.3.1 频繁词筛选
传统的频繁词筛选指标以语词的出现频次为准,但这种筛选方法的科学性值得考究[31]。参考相关研究成果[32],本文综合使用四个指标来抽取频繁词,即:包含某一语词的文本章节数A、某一语词在文本中出现的总词频数B、某一语词在所在章节的平均词频数C、某一语词在所有章节的平均词频数D。四个指标的计算方法如下:
上式中,表示文本总章节数,表示所有语词个数,表示语词在第章节对应的文本中出现的词频数。由于B值代表总词频数,一般数值较大,因此B可以看作规模因子;而A、C、D值則代表词频覆盖度,因此A、C、D可以看作影响力因子[33]。参考相关研究成果,本文对各指标赋予相应权值,构建了频繁词判别公式:
根据公式(6),F值高的语词即可判定为全文的高频繁词。
2.3.2 热词筛选
某些文献根据自我研究兴趣和社会背景来选取热词[34],但这种方法缺乏一定的数值依据。参考相关研究成果,本文使用并拓展了词频逆文本频率法[35](即词频数乘以逆向文本频率)来筛选各章节热词,具体计算公式为:
上式中,表示语词在第章节对应的文本中出现的词频数,表示语词所在章节的总词频数,表示文本总条款数,表示包含某一语词的文本条款数。
2.4 主题关联分析
2.4.1 主题“语词-条款”共现矩阵构建
借鉴共词分析法思想[36],本文认为当某一主题的语词在某章节经常出现时,该语词即与该章节存在关联关系[37]。基于上述思路并借鉴有关学者的研究方法[38],本文提出了一种凸显文档主题的表示方法——“语词-条款”共现矩阵(Words Terms Co-occurrence Matrix, WTCOM),共现条件为某语词在某条款中出现。
先将《办法》处理后的文本内容划分为若干主题,整个文本内容就相当于由主题构成。主题用“语词-条款”共现矩阵可以表示为:,其中表示文本中归为主题的语词相对于文本条款的共现程度,分别表示和的在文本中的相对次序。的具体计算方法为:
(8)
其中,表示主题相关语词和条款在文本中共现的频次,表示主题相关语词数量,表示文本总条款数。
2.4.2 主题“语词-条款”共现矩阵可视化
为了更加直观地了解不同语词与条款之间的关系强弱程度,借助社会网络分析工具Net Draw对各主题的“语词-条款”共现矩阵进行可视化处理,该软件的主要原理是根据小世界理论和中心度理论来挖掘不同节点之间的深层次关系,并以关联网络图形展示[39]。
3 结果分析
3.1 文本预处理结果
通过ICTCLAS系统分词,得到原始分词结果1533个。语词合并时,借鉴有关学者的经验[40],本文将的阈值设定为50%,即两个相邻的短语词共同出现的频次与它们分别出现的频次的最小值的比值大于或等于0.5时,两个短语词就可合并为新的长语词。初次合并后频次≥4次的13个组合词如表1所示。
将初次合并词添加到原文本中再次执行分词操作,直到不再出现新的组合词为止,共得到1340个语词。继续合并同义词,共得到1020个语词。合并结束后,按照现代汉语词性分类规则进行词性筛选,剔除掉介词、连词、助词等对本研究无实际意义的虚词,最终得到有实际意义的语词740个。
3.2 文本分析结果
3.2.1 频繁词筛选结果
根据频繁词筛选指标,分别计算并统计出各指标值和F值,各值排名前十的语词如表2所示。
根据各值包含的语词可以发现《办法》所重点关注的共性问题并确定各语词的核心程度。经过计算分析,将F值高于5且在四个指标中均出现的词看作《办法》的核心频繁词,核心词共有11个,包括科学数据、科学数据中心、开放共享等;将F值高于3且至少在三个指标中出现的词看作《办法》的重点频繁词,重点词共有9个,包括汇交、采集生产、国家秘密等;将F值高于2且至少在两个指标中出现的词看作《办法》的主要频繁词,主要词共有8个,包括使用、主要职责、法律法规等;将F值高于2且至少在一个指标中出现的词看作《办法》的一般频繁词,一般词共有2个,分别是政府预算资金和国家安全。
3.2.2 热词筛选结果
根据热词权重计算方法,得到各章节的热点语词,排名前十的热词结果如表3所示。
从热词分布情况可以看出各章节讨论的热点问题:第一章的讨论热点集中于《办法》的制定目的、科学数据的范畴;第二章的讨论热点集中于各级行政部门和法人单位的职责;第三章的讨论热点集中于科学数据的汇交与保存;第四章的讨论热点集中于科学数据的社会开放于共享利用;第五章讨论热点集中于科学数据安全管理;第六章讨论热点集中于对违规者的责任追究。
3.3 主题关联分析结果
3.3.1 主题划分结果
根据各章节名称,将六个章节的主题归纳为宗旨与原则、体制与职责、汇交与保存、共享与利用、保密与安全、考核与惩处六个方面。对有实际意义的740个语词逐一进行主题划归,其中568个有明确主题属性的语词被分别划归入六个主题中,其余172个主题属性模糊的语词则被剔除。568个语词在各主题中的分布情况为:宗旨与原则主题58个、体制与职责主题42个、汇交与保存主题30个、共享与利用主题52个、保密与安全主题50个、考核与惩处主题42个。各主题中排名前十的语词如表4所示。
3.3.2 主题“语词-条款”共现矩阵
主题划分结束后,统计各主题中语词在各条款的分布情况,其中宗旨与原则主题共有58个主题词,体制与职责主题共有42个主题词,汇交与保存主题共有30个主题词,共享与利用主题共有52个主题词,保密与安全主题共有50个主题词,考核与惩处主题共有42个主题词。根据公式(7),计算各主题的“语词-条款”共现系数并构建共现矩阵。为了表示方便,本研究参考相关成果的做法[38]对文本结构进行了编码处理,第一章的五个条款分别编号为Ⅰ1—Ⅰ5,第二章的五个条款分别编号为Ⅱ6—Ⅱ10,第三章的五个条款分别编号为Ⅲ11—Ⅲ18,第四章的六个条款分别编号为Ⅳ19—Ⅳ24,第五章的五个条款分别编号为Ⅴ25—Ⅴ29,第六章的三个条款分别编号为Ⅵ30—Ⅵ32。由于篇幅所限,仅选取“宗旨与原则”主题“语词-条款”共现矩阵的部分内容进行展示,如表5所示。
3.3.3 各主题“语词-条款”关联结果
将各主题的“语词-条款”共现矩阵导入Net Draw软件绘制的共现网络图谱如图2所示。其中,各个圆点代表主题语词,方形代表相关条款,圆点与方形之间有连线则表示它们存在关联关系,线条数量越多,表明该语词与条款之间的关联关系越强[40]。
(1) 宗旨与原则主题中共有162条关联关系,所有条款均包含于关联网络中,说明该主题贯穿整个《办法》,核心条款有Ⅰ1、Ⅰ2、Ⅱ7、Ⅱ8、Ⅱ9、Ⅱ10、Ⅳ19、Ⅳ24、Ⅴ26、Ⅴ27等,核心主题语词有科学数据、应当、国家、管理等。该主题中既包含带有引导语气的语词,如应当、加强、明确、做好、鼓励、支持等,又包含带有命令语气的语词,如不得、必须、确保等,这体现出《办法》的刚柔并济与灵活变通。对于重点领域的重要数据,必须采取强制措施,如条款Ⅳ25规定“涉及国家秘密、国家安全、社会公共利益等、商业秘密和个人隐私的科学数据,不得对外开放共享”。而其他类型的科学数据则采取“支持”或“鼓励”态度,如条款Ⅳ21“鼓励社会组织和企业开展市场化增值服务”,条款Ⅳ22“支持科研人员发表知识产权清晰、准确完整、共享价值高的科学数据”。
(2) 体制与职责主题中共有84条关联关系,条款Ⅰ1、Ⅰ2、Ⅲ15、Ⅴ25、Ⅴ29未包含在关联网络中,核心条款有Ⅱ7、Ⅱ8、Ⅱ9、Ⅱ10等,核心主题语词有法人单位、主管部门、负责、主要职责等。《办法》明确了我国科学数据实行国家统筹、各部门与各地区分工负责、法人单位及数据生产者组织贯彻落实的管理体制[41]。具体而言,由科学技术行政部门牵头负责全国科学数据的宏观管理与综合协调(条款Ⅱ7),国务院和各省级人民政府相关部门负责宣传贯彻落实国家科学数据管理政策(条款Ⅱ8),有关科研院所、高等院校和企业等具体负责贯彻落实各级科学数据管理政策,并建立健全本单位科学数据相关管理制度(条款Ⅱ9),科学数据中心承担国家、部门(地区)、领域等科学数据的整合汇交、开放共享、交流合作等重任(条款Ⅱ10)。此外,条款Ⅳ23还对使用者的义务做出了规定,“在论文发表、专利申请、专著出版等工作中注明所使用和参考引用的科学数据”。
(3)汇交与保存主题中共有50条关联关系,条款Ⅰ1、Ⅰ2、Ⅱ6、Ⅲ17、Ⅳ21、Ⅳ23、Ⅳ24、Ⅴ25、Ⅴ27、Ⅵ30、Ⅵ32未包含在关联网络中,核心条款有Ⅱ9、Ⅱ10、Ⅲ11、Ⅲ13等,核心主题语词有科学数据中心、汇交、采集生产等。条款Ⅱ9中要求各法人单位按照有关标准规范建立科学数据管理系统进行科学数据采集生产、加工整理和长期保存,条款Ⅲ11要求法人单位和科学数据生产者建立科学数據质量控制体系,条款Ⅲ13要求“各级科技计划管理部门应建立先汇交科学数据、再验收科技计划项目的机制”,这意味着用政府资金获得的科学数据必须上交[42]。为了防止国外科研成果发表平台对我国科学数据的“虹吸”而造成数据主权丢失[8],条款Ⅲ14要求论文作者在向国外期刊发表论文前必须将科学数据上交至单位统一管理。科学数据中心建设薄弱是我国科学数据管理的短板之一[7],因此“科学数据中心”在条款Ⅱ7、Ⅱ8、Ⅱ10、Ⅲ13、Ⅲ15、Ⅲ18、Ⅴ28、Ⅴ29等均有分布。未来,我国将形成国家科学数据中心—部门(地区)科学数据中心—领域科学数据中心三级体系。
(4) 共享与利用主题中共有73条关联关系,条款Ⅰ2、Ⅱ6、Ⅲ13、Ⅲ15、Ⅲ17、Ⅲ18、Ⅴ29、Ⅵ31、Ⅵ32未包含在关联网络中,核心条款有Ⅲ14、Ⅳ19、Ⅳ20、Ⅳ24、Ⅴ26等,核心主题语词有开放共享、服务、利用、开放目录、公布等。针对利用率过低问题,条款Ⅳ19指出科学数据开放共享应该遵循“开放为常态、不开放为例外”的原则,要求主管部门组织编制科学数据资源目录并接入国家数据共享交换平台。条款Ⅳ20列举了科学数据开放共享的形式,既可以在线下载,又可以离线共享,还可以提供定制服务。条款Ⅳ22表示,要“支持科研人员整理发表准确完整、共享价值高的科学数据”。条款Ⅳ24指出某些重要领域需要使用科学数据时,法人单位要“无偿提供”,确需收费时应按照“非营利”原则对外提供。科学数据资源价值的大小终需市场检验,数据资产化运作或许是提升数据价值的有效途径[43],条款Ⅳ21提出了开发利用的“市场化”原则,即法人单位可“对科学数据进行分析挖掘,形成有价值的科学数据产品”“鼓励社会组织和企业开展市场化增值服务”。
(5) 保密与安全主题中共有59条关联关系,条款Ⅰ2、Ⅱ6、Ⅱ7、Ⅲ11、Ⅲ12、Ⅲ13、Ⅲ17、Ⅲ18、Ⅳ19、Ⅳ21、Ⅳ22、Ⅳ23、Ⅵ30、Ⅵ31未包含在关联网络中,核心条款有Ⅳ20、Ⅴ25、Ⅴ26、Ⅴ27、Ⅴ28,核心主题语词有国家秘密、国家安全、安全等。条款Ⅳ20要求各法人单位明确科学数据的秘密级别、保密期限、开放条件、开放对象和审核程序等。条款Ⅳ25要求涉及国家秘密、国家安全、社会公共利益、商业秘密和个人隐私的科学数据不得对外开放共享。条款Ⅳ26要求主管部门和法人单位建立健全涉密科学数据管理与使用制度,严格管控数据的制作、审核、登记、传输、销毁等环节。条款Ⅳ27指出主管部门和法人单位应对对外公布的科学数据或开放目录进行安全保密审查。条款Ⅳ28提出建立健全防篡改、防泄露、防攻击、防病毒等网络安全保障体系。条款Ⅳ29要求科学数据中心建立应急管理和容灾备份机制,要对重要的科学数据进行异地备份。该主题解决了如何平衡数据开放性和安全性这一难题,也为后续开放数据政策制定提供了新思路——切勿一味强调开放共享,应该遵从“边开放边保护”原则[44]。
(6) 考核与惩处主题中共有47条关联关系,条款Ⅰ1、Ⅰ2、Ⅱ6、Ⅱ9、Ⅲ12、Ⅲ14、Ⅲ15、Ⅲ16、Ⅲ18、Ⅳ19、Ⅳ21、Ⅴ25、Ⅴ27未包含在关联网络中,核心条款有Ⅲ17、Ⅳ24、Ⅵ31等,核心主题语词有评价考核、激励机制、遵守、执行等。条款Ⅲ17指出要加强科学数据人才队伍建设,在岗位设置、绩效收入、职称评定等方面建立激励机制;条款Ⅳ24指出“对于因经营性活动需要使用科学数据的,当事人双方应当签订有偿服务合同,明确双方的权利和义务”。厘清数据的所有权、使用权、受益权等,有利于解决数字资产的确权问题[45],《办法》尊重知识产权,条款Ⅳ23要求“科学数据使用者应遵守知识产权相关规定”。条款Ⅵ31对伪造数据、侵犯知识产权、不按规定汇交数据等违规违法行为做出处理意见,要求主管部门可采取责令整改、通报批评、处分或行政处罚等处理形式对相关单位和责任人给予惩处。科学数据管理实行“权责相一致”原则[46]:一方面,鼓励数据生产者和拥有者开放共享科学数据并获得合法收益(条款Ⅳ21);另一方面,规定数据生产者和拥有者也要对数据的安全和质量负责,“对违反国家有关法律法规的单位和个人,依法追究相应责任”(条款Ⅵ31)。
4 结语
本文采用自然语言处理技术对《办法》进行了分词处理,以实词为研究对象,综合使用四种指标并构建判别公式,确定了文本的频繁词;拓展使用了词频逆文本频率法,筛选并得出了各章节热词;构建了“语词-条款”共现矩阵,可视化展现了具有相同性质和主题的语词与不同条款之间的关联关系。分析发现,《办法》的频繁词有科学数据、科学数据中心、开放共享、汇交、采集生产、国家秘密、使用、主要职责、法律法规、政府预算资金、国家安全等,这些频繁词较好地展示了《办法》的精神内涵:《办法》所指的“科学数据”主要针对“使用”“政府预算资金”“采集产生”的数据,《办法》的主要目的是促进科学数据“开放共享”与开发“利用”,拟建设各层级/领域“科学数据中心”,其“主要职责”是进行科学数据“汇交”与保存,《办法》强调保密与安全,对于泄露“国家秘密”和危害“国家安全”的行为,要严格按照国家相关“法律法规”进行惩处。此外,各主题相关语词在文本均有对应的核心条款和核心语词,但某些条款集中分布于某个主题而在其他主题分布较少,如条款Ⅰ2仅分布在宗旨与原则主题、条款Ⅱ7主要分布在体制与职责主题、条款Ⅲ17主要分布在考核与惩处主题和、条款Ⅳ19主要分布在共享与利用主题、条款Ⅴ25主要分布在保密与安全主题、条款Ⅵ31主要分布在考核与惩处主题。这种分布不均也能从各主题的相关语词数量与主题词关联关系数量的比例中体现出来,如宗旨与原则主题的58个相关语词之间共有162条关联关系(比例为1:2.79),而考核与惩处主题的42个相关语词之间仅共有47条关联关系(比例为1:1.12)。
文章的不足之处有:词频统计文本分析通常适用于大规模的语料文本,本文仅以《办法》文本语词为分析样本,研究对象具有一定的局限性;语词合并、词性筛选、主题划分等环节在尽量保持客观的基础上仍然存在少许主观因素,可能造成语义损失。未来研究可结合國内外其他相关政策性文本进行协同或对比分析,可借鉴相关研究成果构建更加合理的领域词典和主题词典等。此外,借助人工智能和机器学习相关技术对《办法》类语料库进行更深层次挖掘(如情感分析、政策导向预测等)也是值得尝试的方向之一。
参考文献:
何国金,王桂周,龙腾飞,等.对地观测大数据开放共享:挑战与思考[J].中国科学院院刊,2018,33(8):783-790.
张晓青,盛小平.国外科学数据开放共享政策述评[J].图书馆论坛,2018,38(8):147-154.
开掘好大数据资源“富矿”:聚焦我国首个国家层面的科学数据管理办法[EB/OL].[2019-07-10].http://www.gov.cn/zhengce/2018-04/08/content_5280638.htm.
科技部副部长出席科学数据管理座谈会[EB/OL].[2019-07-10].http://www.gov.cn/xinwen/2017-05/25/content_5196728.htm.
张丽丽,温亮明,石蕾,等.国内外科学数据管理与开放共享的最新进展[J].中国科学院院刊,2018,33(8):774-782.
司莉,邢文明.国外科学数据管理与共享政策调查及对我国的启示[J].情报资料工作,2013(1):61-66.
国家科技基础条件平台中心.国家科学数据资源发展报告(2016)[R].北京:科学数据文献出版社,2016.
国家科技基础条件平台中心.国家科学数据资源发展报告(2017)[R].北京:科学数据文献出版社,2018.
科技部举行《科学数据管理办法》新闻通气会[EB/OL].[2019-07-10].http://www.scio.gov.cn/xwfbh/gbwxwfbh/xwfbh/kjb/Document/1627104/1627104.htm.
国务院办公厅关于印发科学数据管理办法的通知[EB/OL].[2019-07-23].http://www.gov.cn/zhengce/content/2018-04/02/content_5279272.htm.
齐法制,陈刚,程耀东.建立权责明晰且能力健全的科学数据开放共享机制:以高能物理领域为例[J].中国科学基金,2019,33(3):229-236.
王卷乐,王明明,石蕾,等.科学数据管理态势及其对我国地球科学领域的启示[J].地球科学进展,2019,34(3):306-315.
郭华东.科学大数据:国家大数据战略的基石[J].中国科学院院刊,2018,33(8):768-773.
柏永青,杨雅萍,孙九林.国内外科学数据管理办法研究进展[J].农业大数据学报,2019,1(3):5-20,4.
周玉琴,邢文明.我国科研数据管理与共享政策体系研究[J].中华医学图书情报杂志,2018,27(8):1-7.
赵小兰,刘桂锋.香港高校科研数据管理服务调查分析[J].数字图书馆论坛,2018(6):37-44.
张保钢.国务院办公厅印发《科学数据管理办法》[J].北京测绘,2018,32(5):577.
邵玉昆.科技数据资源的开放共享机制研究[J].科技管理研究,2019,39(13):177-181.
庄媛.科学数据共享促科技腾飞[N].深圳特区报,2018-04-09(A02).
王知凡.数据价值的挖掘离不开市场[J].小康,2018(13):78.
刘敬仪,江洪.开放科学环境下国外高校图书馆科研数据管理服务启示[J].图书馆工作与研究,2018(10):18-24.
邹自明,胡晓彦,熊森林.空间科学大数据的机遇与挑战[J].中国科学院院刊,2018,33(8):877-883.
赛迪智库.《科学数据管理办法》的亮点与思考[J].中国工业和信息化,2018(9):12-14.
邢文明,洪程.开放为常态,不开放为例外:解读《科学数据管理办法》中的科学数据共享与利用[J].图书馆论坛,2019,39(1):117-124.
秦顺,邢文明.开放·共享·安全:我国科学数据共享进入新时代:对《科学数据管理办法》的解读[J].图书馆,2019(6):36-42.
高瑜蔚,石蕾,朱艳华,等.《科学数据管理办法》实施细则比较研究:以正式发布的11份细则为例[J].中国科技资源导刊,2019,51(3):1-10,17.
白锐,吕跃.基于修正多源流模型视角的政策议程分析:以《科学数据管理办法》为例[J].图书馆理论与实践,2019(10):50-55.
张洋,肖燕珠.生命周期视角下《科学数据管理办法》解读及其启示[J].图书馆学研究,2019(15):37-43,13.
王继娜.国外高校图书馆科学数据管理服务的调研与思考[J].情报理论与实践,2019,42(8)159-167.
储文静,李书宁.高校科学数据管理规范流程探究[J].情报理论与实践,2019,42(2):62-67.
GAMBHIR M, GUPTA V.Recentautomatic text summarization techniques:a survey[J].Artificial Intelligence Review,2017,47(1):1-66.
魏伟,郭崇慧,陈静锋.国务院政府工作报告(1954—2017)文本挖掘及社会变迁研究[J].情报学报,2018,37(4):406-421.
温亮明,王军,余波.基于论文产出视角的高校图书馆科研实力研究:以“985工程”高校为例[J].情报工程,2015,1(5):107-118.
李渝勤,孙丽华.面向互联网舆情的热词分析技术[J].中文信息学报,2011,25(1):48-53,59.
劉洪君.微博网络热点话题发现技术研究[D].北京:北京交通大学,2013.
CALLON M, LAW J, RIP A. Mapping the dynamics of science and technology: sociology of science in the real world[M].London:Palgrave Macmillan,1986:103-123.
余波,温亮明,李洋,等.基于关键词共现的图书情报领域MOOC研究热点解析[J].图书馆工作与研究,2017(4):69-77.
王丽培.《中华人民共和国公共图书馆法》词频统计与分析[J].图书馆工作与研究,2018(9):5-14.
朱庆华,李亮.社会网络分析法及其在情报学中的应用[J]. 情报理论与实践,2008(2):179-183,174.
王春华,李维,文庭孝.我国图书情报领域大数据研究热点分析[J].图书情报知识,2015(4):82-89.
吴妍.《科学数据管理办法》发布[J].福建轻纺,2018(5):2.
用国家资金获得的科学数据必须上交[J].计量与测试技术,2018,45(4):112.
吴超.从原材料到资产:数据资产化的挑战和思考[J].中国科学院院刊,2018,33(8):791-795.
马海群,蒲攀.国内外开放数据政策研究现状分析及我国研究动向研判[J].中国图书馆学报,2015,41(5):76-86.
赵国栋:深度解读《科学数据管理办法》[EB/OL].[2019-07-30].http://www.sohu.com/a/227351001_296848.
袁于飞.让科学数据开放共享成为常态[N].光明日报,2018-04-05(002).
猜你喜欢
江苏农业科学(2016年8期)2017-02-15
江苏农业科学(2016年8期)2017-02-15
计算机应用(2016年12期)2017-01-13
计算机应用(2016年12期)2017-01-13
软件导刊(2016年11期)2016-12-22
科技视界(2016年15期)2016-06-30
电脑知识与技术(2016年10期)2016-06-16
求知导刊(2016年10期)2016-05-01
电脑知识与技术(2016年5期)2016-04-14
电脑知识与技术(2016年4期)2016-04-11
