
基于集成学习的电子商务平台新用户重复购买行为预测
2020-07-14 08:37胡晓丽张会兵董俊超吴冬强
现代电子技术 2020年11期
胡晓丽 张会兵 董俊超 吴冬强


摘 要: 对电子商务平台新用户重复购买行为进行预测有助于商户开展精准营销。现有单一方法在预测准确性方面还有待提升,文中提出一种基于集成学习的预测模型以进一步提升新用户重复购买行为的预测准确率。引入“分段下采样”以获得新用户重复购买和未重复购买的平衡样本;从用户、商户及用户与商户交互三方面构建新用户购买行为特征;依据集成学习思想Stacking融合RandomForest,XGBoost和LightGBM对新用户重复购买行为进行预测。实验结果表明,Stacking融合模型准确率和AUC值比单一模型平均提升了0.4%~2%,使用“分段下采样”样本平衡算法AUC值提升0.1%左右。
关键词: 重复购买行为预测; 集成学习; 分段下采样; 平衡样本获取; 购买行为特征构建; Stacking融合模型
中图分类号: TN99?34; TP391 文献标识码: A 文章编号: 1004?373X(2020)11?0115?05
Prediction of ensemble learning?based new users′ repurchase
behavior on e?commerce platform
HU Xiaoli1, ZHANG Huibing2, DONG Junchao2, WU Dongqiang3
(1. Department of Teaching Practice, Guilin University of Electronic Technology, Guilin 541004, China;
2. Guangxi Key Laboratory of Trusted Software, Guilin University of Electronic Technology, Guilin 541004, China;
3. Nanning Goblin Technology Co., Ltd., Nanning 530000, China)
Abstract: The prediction of new users′ repurchase behavior on E?commerce platform is helpful for merchants to perform precision marketing. The existing single method still needs to be improved in terms of prediction accuracy. A prediction model based on ensemble learning is proposed to further improve the prediction accuracy of repurchase behavior of new users. "Segmented sub?sampling" is introduced to obtain balanced samples of repurchase and non?repeated purchase of new users. The purchase behavior features of new users are constructed from three aspects, named users, merchants and interaction between users and merchants. Repeat purchase behavior of new users is predicted on the basis of the ensemble learning method Stacking integrated with RandomForest, XGBoost and LightGBM. The experimental results show that both the accuracy of Stacking fusion model and AUC (Area Under Curve) value increased by 0.4%~2% on average in comparison with that of the single model, and the AUC value is increased by about 0.1% when the "segmented sub?sampling" sample balancing algorithm is used.
Keywords: repurchase behavior prediction; ensemble learning; segmented sub?sampling; balanced sample acquisition; purchase behavior feature construction; Stacking fusion model
0 引 言
为了吸引更多新用户的关注和购买,电商平台会在“双十一”“618”等特定日期进行促销。然而,在促销期间获得的新用户多为一次性购买用户,不能为商户产生长期回报。因此,预测新用户重复购买行为是电子商务平台开展精准营销、获得长期客源的关键问题。利用新用户的浏览、收藏、放入购物车等海量行为数据来挖掘其购物习惯、偏好和意愿,是实现重复购买行为预测的有效途径。
文献[1]综合特征工程和模型训练,构建涵盖用户、商家、品牌、类别、商品及其交互等方面的新用户重复购买行为影响特征。分别使用Logistic回归、随机森林、XGBoost等五种模型进行训练预测,实验结果显示XGBoost表现最好。文献[2]针对预测新消费者的重复购买意向的问题,提出融合SMOTE算法和随机森林算法的预测模型,与均衡K近邻算法和决策树算法相比,该模型有更好的性能。文献[3]利用新用户的历史行为数据,提出了一种基于GBDT的两层模型融合算法(TMFBG)来预测重复购买用户,提高了预测精度和模型鲁棒性。文献[4]首先使用人工蜂群算法对新用户重复购买行为特征进行选择,然后依此构建新用户重复购买行为预测模型,实验结果表明,特征选择对模型预测结果的提升有一定作用。
上述研究大多采用单一模型进行预测,集成学习技术的发展使得可以通过个体模型和组合策略的优化选择以进一步提升预测效果。同时,在促销活动中新吸引用户发生重复购买行为的仅占6%左右,不平衡的樣本数据会影响预测效果。为此,本文使用“分段下采样”对原始样本进行平衡处理,然后,采用融合RandomForest,XGBoost和LightGBM的模型预测新用户重复购买行为[5]。
1 新用户重复购买预测模型
1.1 模型框架
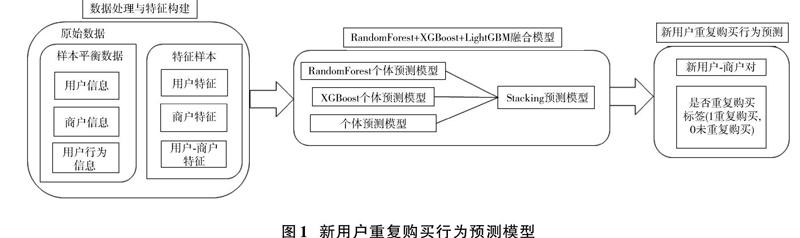
图1是融合用户属性、商户信息和用户与商户交互信息的预测新用户重复购买行为的集成学习模型。首先,完成用户历史行为数据清洗,并采用“分段下采样”方法进行样本平衡处理;然后,从用户属性、商户属性及用户?商户交互属性三个维度分别构建出用户特征、商户特征、用户?商户特征;输入构建好的特征到RandomForest,XGBoost和LightGBM个体模型中进行新用户购买行为预测训练;最后,通过Stacking方法对个体模型进行融合并将预测结果分类输出[6]。
1.2 新用户历史交互样本平衡与特征构建
1.2.1 新用户历史交互样本平衡
在促销结束后,只有极少部分新用户会重复购买,出现重复购买正样本与未重复购买负样本极度不平衡的问题。传统的“过采样”和“下采样”方法不能很好地解决该问题[7]。为此,设计了“分段下采样”方法:根据新用户购买行为时间敏感的特点,将重复购买用户和未重复购买用户原始样本以天为单位进行分段。针对新用户样本中的每个新用户根据欧氏距离找出其三个最近邻新用户,若该新用户是未重复购买用户,且其三个最近邻新用户中有两个以上是重复购买用户,则删除它;否则,当该样本是重复购买用户并且其三个最近邻中有两个以上是未重复购买用户,则去除最近邻中未重复购买的用户,其余保留原始新用户样本即可。
“分段下采样”样本平衡算法步骤如下:
输入:新用户原始历史数据([D]),数据记录天数([T]);
输出:新用户平衡历史数据([D*]);
算法流程:
1: D′ =D/T //对原始数据按照数据记录天数进行分段
2: for D(u)∈D′ do //遍历原始数据中的每个用户
3: D′(u) =RandomChoose(D(u)) //随机选择任意用户数据
4: if D′(u)为重复购买用户 then
5: if repeat?buy = sum(KNN (D′(u)))≥2 then
// [D′(u)]最近邻中未重复购买用户个数
6: delete (KNN (D′(u))≠repeat?buy)
//删除最近邻中的未购买用户
7: else
8: save(D′(u)) //保留新用户数据
9: else
10: if norepeat?buy = sum(KNN (D′(u)))≥2 then
11: delete (D′(u)) //删除新用户
12: else
13: save(D′(u)) //保留新用户数据
1.2.2 新用户历史交互特征构建
原始的新用户历史交互数据比较分散,可以直接使用的特征非常少,用于预测重复购买行为的效果不够理想。为此,运用统计分析方法构建出如表1所示的新用户重复购买行为预测特征。然后,将这些特征分别输入到RandomForest,XGBoost和LightGBM个体模型中进行特征选择和训练。
1.3 Stacking预测模型
基于表1特征,为了提高精确度和泛化能力,采用Stacking方法将RandomForest,XGBoost和LightGBM结合起来构建如图2所示的集成预测模型。第一层由3个个体模型组成,使用类似于5折交叉验证的策略来训练。然后,将个体模型预测结果输入第二层次级模型Logistic回归,用于训练新用户重复购买行为最终预测模型[8]。最后,组合输入个体模型测试样本的输出结果到训练完成的次级模型Logistic回归中,对新用户购买行为进行最终预测[9]。
1.3.1 个体预测模型
Stacking集成预测模型个体模型构建过程如下:
1) 选择RandomForest,XGBoost和LightGBM个体模型;
2) 按照8[∶]2比例划分新用户历史行为数据为训练集和测试集,并把训练集分为train1~train5不交叉的五份选择;
3) RandomForest个体模型使用train1~train4训练预测模型,train5预测新用户重复购买行为并保留结果;
4) 重复上述过程,直到把train1~train5都预测一遍,保存预测结果为[B1train=(b1,b2,b3,b4,b5)T];
5) 类似RandomForest个体模型,选择XGBoost和LightGBM个体模型进行5折交叉验证得到预测结果[B2train=(b1,b2,b3,b4,b5)T]和[B3train=(b1,b2,b3,b4,b5)T];
6) 在个体模型建立的过程中,每个模型分别对test数据集进行5次预测,并取均值得到對应预测结果[B1test=(b1)T],[B2test=(b2)T]和[B3test=(b3)T]。
1.3.2 Logistic回归次级预测模型
由于Logistic回归具有较强的泛化能力,可以降低Stacking的过拟合风险,因此Stacking预测模型次级模型选用Logistic回归模型进行建模,过程如下:
1) 根据三种个体预测模型训练集的输出[Btrain={B1train,B2train,B3train}],构建逻辑回归方程[y=wTBtrain+b],其中,[w]为权重值,[b]为偏回归系数,[y]表示新用户是否重复购买的因变量。
2) 因变量[y]取值为1,新用户重复购买的概率是[p=P(y=1Btrain)],否则,取0的概率为1-[p]。
3) 采用极大似然函数法求解模型中的回归系数,评估优化模型。
4) 输入个体预测模型测试集的预测值[Btest={B1test,B2test,B3test}],得到测试集的最终预测值,并对其评估。
算法详细过程如下所示:
算法:新用户重复购买行为Stacking预测模型
输入:用户属性数据([U])、商品属性数据([I])和用户历史行为数据([B]);
输出:用户?商户对([U?M]),是否重复购买(repeat?buy)(1表示重复购买,0表示未重复购买);
算法流程:
1: read date={[U],[M],[B]} //读取输入数据
2: create[vi={v1,v2,…,v40}] //构建新用户重复购买行为特征
3: [U*=choose(U)]
//根据“分段下采样”均衡算法进行数据样本均衡
4: cat=RandomForest (data([U*][×][xi]))
//构建RandomForest个体模型,并进行训练
5: Light=XGBoost Classifier(data([U*][×][xi]))
//构建XGBoost个体模型,并进行训练
6: xgb=LightGBM Classifier(data([U*][×][xi]))
//构建LightGBM个体模型,并进行训练
7: log=logistic (data(train_out(5[×]3)))
//构建Logistic回归次级模型进行模型融合训练
8: repeat?buy=log(data(test_out(1[×]3)))
//Logistic回归次级模型进行模型融合预测
2 实验与分析
2.1 数据集
选用天猫数据集进行测试,部分字段如表2所示。数据集提供了“双十一”前后6个月中约26万新用户的购物信息,其中正负样本比例约为1[∶]16。
2.2 评估指标
对于新用户重复购买行为预测问题,根据样例真实类别与文中模型预测类别组合划分为真正例(TP)、假正例(FP)、真负例(TN)、假负例(FN)四种类型。数字化混淆矩阵后可推导出表示分类正确的样本数与总样本数之比的准确率(Accuracy)和表示正例样本排在负例样本之前概率的AUC值(Area Under Curve),公式分别为:
[Accuracy=TP+TN(TP+FP)+(TN+FN)] (1)
[AUC=01TP dFP(TP+FN)(TN+FP)] (2)
2.3 实验结果与分析
2.3.1 融合模型验证
这里以预测6个月内新用户是否重复购买为例,比较分析融合模型与三种个体模型的性能差异。将每个模型在同一训练和测试数据集上分别运行10次,求得准确率和AUC值的平均值作为模型最终结果,如表3所示。
从表3中的实验结果可知,文中Stacking模型的准确率和AUC值在训练集和测试集中均高于三种个体模型,主要原因是Stacking模型中的第一层个体模型能够有效地学习原始杂乱无章的新用户历史购买行为数据中的特征,同时,选择的个体模型也符合Stacking模型对基分类器选择差异化大、准确性高的要求。就个体模型而言,LightGBM,XGBoost和RandomForest性能依次递减。这是因为,LightGBM通过使用垂直拆分替代水平拆分来获得极高的准确性,XGBoost对超参数进行优化,对影响新用户重复购买行为的特征进行了自动优化处理,提高了模型的准确率和鲁棒性。此外,比对训练集合测试集可以看出,模型在训练集和测试集上的准确率和AUC值相差不大,没有发生过拟合或者欠拟合问题。
为了更直观地验证Stacking模型的稳定性,将四种模型在10次训练集上的准确率画出如图3所示折线图,并分析波动趋势。
从图3中可看出,Stacking模型与三种个体模型相比在模型稳定性上有明显优势。RandomForest,XGBoost和LightGBM的Accuracy随实验次数波动较大。Stacking模型处于高Accuracy的区间内小幅度波动,模型整体上稳定性较好,这是因为集成学习通过融合多个个体模型的预测结果,在提高单个模型性能的同时,可以有效避免选择某个预测效果不好的个体模型的结果。
2.3.2 重复购买行为影响特征分析
比较三种个体模型的重复购买行为影响特征发现并无明显差异,说明表4展示的三种预测模型排名前10的影响特征对新用户的重复购买行为影响较大,对商户提高新用户重复购买率的策略制定具有重要意义。
表4中所列的特征中,从宏观角度来看,用户?商户特征对用户重复购买行为的影响力最大,商户特性和用户特征次之。从微观角度来看,用户?商户特征中某用户在某商户购买商品总次数,某用户在某商铺中购买某类商品的总数,某用户在某商铺中购买某个商品的总数三个特性体现了某个用户对商户的“偏爱”程度,实际情况是用户往往习惯在经常购买的商家去购买商品;某用户在商户中第一次和最后一次交互的时间差,某用户在商户中交互最频繁的月份,某用户在某商户中一个月交互次数三个特征度量了某用户在某商户的“停留”时长,根据经验可知,某用户在某商户“停留”的时间越长,越容易发生购买行为。此外,由表4中也可以看出,用户购买转换率、用户年龄和性别也是对用户重复购买影响较重要的几个特征,这与实际情况非常一致。
3 结 语
本文采用Stacking融合模型有效提高了新用户重复购买行为预测的准确率和稳定性,应用“分段下采样”样本均衡算法提升了模型预测的准确率和AUC值。分析了影响重复购买行为的重要特征,为商户增加新用户重复购买率、提高用户忠诚度和精准营销等方面相关策略的制定提供了参考。后续将深入挖掘新用户重复购买行为影响因素,在聚类分析基础上进行特征构建和模型训练,同时,借鉴交叉验证的思想以进一步提升AUC值。
注:本文通讯作者为张会兵。
参考文献
[1] LIU G, NGUYEN T T, ZHAO G, et al. Repeat buyer prediction for E?commerce [C]// Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. [S.l.]: ACM, 2016: 155?164.
[2] 张李义,李一然,文璇.新消费者重复购买意向预测研究[J].数据分析与知识发现,2018,2(11):10?18.
[3] XU D, YANG W, MA L. Repurchase prediction based on ensemble learning [C]// 2018 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI). Guangzhou, China: IEEE, 2018: 1317?1322.
[4] KUMAR A, KABRA G, MUSSADA E K, et al. Combined artificial bee colony algorithm and machine learning techniques for prediction of online consumer repurchase intention [J]. Neural computing and applications, 2019, 31(2): 877?890.
[5] DOROGUSH A V, ERSHOV V, GULIN A. CatBoost: gradient boosting with categorical features support [EB/OL]. [2018?10?24]. https://arxiv.org/abs/1810.11363.
[6] MA X, SHA J, WANG D, et al. Study on a prediction of P2P network loan default based on the machine learning LightGBM and XGboost algorithms according to different high dimensional data cleaning [J]. Electronic commerce research and applications, 2018, 31: 24?39.
[7] FERN?NDEZ A, GARCIA S, HERRERA F, et al. SMOTE for learning from imbalanced data: progress and challenges, marking the 15?year anniversary [J]. Journal of artificial intelligence research, 2018, 61: 863?905.
[8] RUAN Q, WU Q, WANG Y, et al. Effective learning model of user classification based on ensemble learning algorithms [J]. Computing, 2019, 101(6): 531?545.
[9] BOL?N?CANEDO V, ALONSO?BETANZOS A. Ensembles for feature selection: a review and future trends [J]. Information fusion, 2019, 52: 1?12.
[10] THAKKAR P, VARMA K, UKANI V, et al. Combining user?based and item?based collaborative filtering using machine learning [C]// Information and Communication Technology for Intelligent Systems. Singapore: Springer, 2019: 173?180.
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
劳动保护(2019年7期)2019-08-27
金融周刊(2018年13期)2018-12-26
四川党的建设(2018年21期)2018-12-05
中国交通信息化(2018年5期)2018-08-21
学习月刊(2015年22期)2015-07-09
中学科技(2015年1期)2015-04-28
技术经济(2014年12期)2014-02-28
