
粒子群优化算法和支持向量机的上市公司信用风险预警
2020-07-14 08:37周树功李娟
现代电子技术 2020年11期
周树功 李娟

摘 要: 信用风险对一个上市公司来说十分关键,而信用风险受到多种因素的综合作用,变化十分复杂,当前信用风险预警方法无法反映其复杂的变化特点,使得信用风险预警错误率相当的高,信用风险预警结果不可靠。为了获得理想的信用风险预警效果,提出粒子群优化算法和支持向量机的上市公司信用风险预警方法。首先,分析上市公司信用风险预警原理,指出影响上市公司信用风险预警结果的重要因素;然后,将上市公司信用风险预警问题看作是一个多分类问题,通过支持向量机对上市公司信用风险变化特点进行深度分析和挖掘,建立上市公司信用风险预警分类器,并引入粒子群优化算法对上市公司信用风险预警分类器参数进行优化;最后,采用具体实例分析了上市公司信用风险预警效果。结果表明,文中方法的上市公司信用风险预警正确率超过90%,远远高于实际应用的85%,而且上市公司信用风险预警错误率要小于当前经典的上市公司信用风险预警方法,验证了所提方法的优越性。
关键词: 信用风险; 预警错误率; 上市公司; 多分类问题; 支持向量机; 预警正确率
中图分类号: TN915.08?34; TP334 文献标识码: A 文章编号: 1004?373X(2020)11?0072?04
Listed companies′ credit risk early warning based on particle swarm
optimization and support vector machine
ZHOU Shugong, LI Juan
(Department of Mathematics and Information Sciences, Tangshan Normal University, Tangshan 063000, China)
Abstract: Credit risk is very critical for a listed company. It is affected by a combination of factors and its changes are complex. However, the current credit risk early warning methods fail to reflect the characteristics of complex changes, which makes the error rate of credit risk early warning quite high and the result of credit risk early warning unreliable. In order to obtain an ideal credit risk early warning result, a listed companies′ credit risk early warning method based on particle swarm optimization (PSO) algorithm and support vector machine (SVM) is proposed. In the method, the principle of credit risk early warning of listed companies is analyzed, and the important factors that affect the results of credit risk early warning of listed companies are pointed out. And then, the credit risk early warning of listed companies is regarded as a difficulty in multi?classification. The SVM is used to deeply analyze and mine the change characteristics of listed companies′ credit risk to establish the credit risk early warning classifier of listed companies. Furthermore, the parameters of credit risk early warning classifier of listed companies are optimized by introducing PSO algorithm. Specific examples are employed to analyze the effect of credit risk early warning of listed companies. The results show that the accuracy of the credit risk early warning of listed companies, obtained with the proposed method, exceeds 90%, which is much higher than 85% existing in the practical application. The error rate of credit risk early warning of listed companies obtained with the proposed method is lower than that with the current classical credit risk early warning methods for listed companies, which verifies the superiority of the proposed method.
Keywords: credit risk; early warning error rate; listed company; multi?classification problem; SVM; early warning accuracy rate
0 引 言
随着我国经济迅速发展,企业向外型化、国际化方向发展,出现了许多上市公司。在经济全球化的背景下,信用问题是人们最为关注的问题之一,如果对上市公司信用风险把握不足,会出现许多债务危机,因此,对上市公司信用风险预警进行研究,做好信用风险防范措施具有重要的实际意义[1?3]。
对于上市公司信用风险预警问题,在国外,研究的起步比较早,研究历史比较长,上市公司发展比较成熟,具有大量的真实数据,而且人们对上市公司信用风险预警意识比较早,有许多成熟的上市公司信用风险预警方法[4?6]。在国内,上市公司信用风险预警研究时间短,还有许多技术不成熟。最初人们提出采用单变量建立上市公司信用风险预警方法,得到了较好的实际应用效果,但是由于考虑的指标比较少,局限性也十分明显[7?8]。有学者提出基于多元线性判别分析理论的上市公司信用风险预警方法,选择多个指标对上市公司信用风险进行估计,并根据估计制定相应的上市公司信用风险预警措施,但是由于多元线性判别分析理论假定上市公司信用风险是一种线性变化特点,而信用风险受到多种因素的综合作用,变化十分复杂,当前信用风险预警方法无法反映其复杂的变化特点,使得多元线性判别分析理论的信用风险预警错误率相当高,信用风险预警结果不可靠[9?11]。近年来随着非线性理论和机器学习算法的研究不断融合,出现以神经网络为代表的上市公司信用风险预警方法。选择多家上市公司的信用风险作为训练集,并与多元线性判别分析理论进行对比测试,神经网络的上市公司信用风险预警效果明显优于多元线性判别分析理论[12?14],然而神经网络同样存在不足,其需要大量的上市公司信用风险数据,属于大样本分类问题,使得上市公司信用风险预警成本高,同时,要收集大量上市公司信用风险预警的历史数据十分困难,因此,上市公司信用风险预警有待进一步研究[15]。
为了提高上市公司信用风险预警精度,本文提出了粒子群优化算法和支持向量机的上市公司信用风险预警方法,并与其他方法进行了上市公司信用风险预警仿真测试,验证了本文方法的优越性。
1 粒子群优化算法和支持向量机的上市公司信用风险预警方法
1.1 上市公司信用风险预警指标体系
指标体系直接影响到上市公司信用风险预警的效果,本文基于指标明确性、指标稳定性、指标敏感度要高、评价结果的全面性以及数据的可搜集性等原则,建立上市公司信用风险预警指标体系,共包含了10个信用风险预警指标,具体結果如表1所示。
1.2 支持向量机
支持向量机是一种专门针对小样本、非线性的模式识别算法,基于结构风险最小化理论,对一个二分类问题,通过寻找一个最优分界面将所有样本分开。设样本集合为[{(x1,y1),(x2,y2),…,(xi,yi)}],最优分界面线性方程为:
[ωTx+b=0] (1)
式中:[ω]表示法向量;[b]表示位移项。
如果最优分界面可以对样本进行正常分类,那么有:
[ωTxi+b≥1, yi=1ωTxi+b≤-1, yi=-1] (2)
最优分界面同时要保证两类样本之间的距离之和最大,即:
[maxω,b2ωs.t. yi(ωTxi+b)≥1] (3)
求其对偶问题:
[maxωi=1nαi-12i=1nj=1nαiαjyiyjxTixj] (4)
解出[αi]需满足KKT条件:
[αi≥0yif(xi)-1≥0αiyif(xi)-1=0] (5)
解出[α]之后,求出[ω]与[b]得到模型:
[f(x)=ωTx+b=i=1nαiyixTix+b] (6)
对于一些线性不可分的问题,可以存在错分的点,对每个样本点引入松弛变量[ξi],那么有:
[min12ω+Ci=1nξis.t. yi(ωTxi+b)≥1-ξi] (7)
式中[C]表示惩罚因子。
将样本通过非线性映射[?]引入到高维特征空间,最优分界函数为:
[f(x)=i=1nαiyi?(xi)?(x)+b] (8)
式(8)易出现维数灾难问题,为了解决该问题,引入核函数得到:
[f(x)=i=1nαiyiK(xi,x)+b] (9)
1.3 粒子群优化算法和支持向量机的上市公司信用风险预警方法
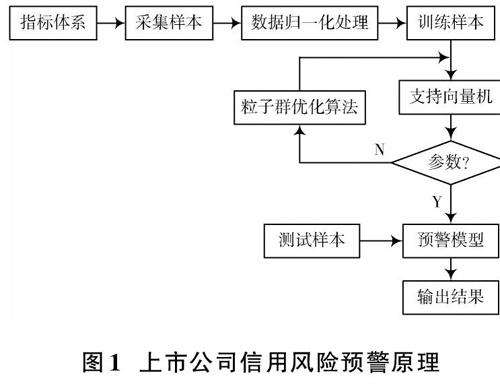
粒子群优化算法和支持向量机的上市公司信用风险预警方法的工作原理为:首先,建立如表1所示的上市公司信用风险预警指标体系,并接收相应的上市公司信用风险预警数据,标记相应的上市公司信用风险值;然后,将上市公司信用风险预警数据分为训练样本和测试样本集合,通过支持向量机对上市公司信用风险预警训练样本进行学习,并采用粒子群优化算法确定上市公司信用风险预警模型的参数;最后,通过测试样本检验上市公司信用风险预警效果,具体如图1所示。
2 上市公司信用风险预警实例分析
2.1 数据来源
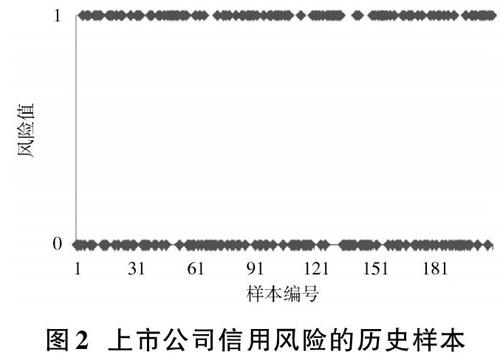
为了分析粒子群优化算法和支持向量机的上市公司信用风险预警效果,数据来源于业内公认的上市公司信用风险预警数据集。信用正常公司样本的值为“1”,信用异常公司样本的值为“0”,得到210个样本,训练样本集合和测试样本集合的样本数目之比约为3[∶]1。历史数据的上市公司信用风险值的变化曲线如图2所示。
由于上市公司信用风险预警指标量纲不同,使得指标值之间没有什么可比性,因此,对样本数据进行无量纲归一化处理,以提高上市公司信用风险预警效率,具体如下:
[x′i=xi-xminxmax-xmin] (10)
式中:[xi]表示上市公司信用风险预警指标的原始值;[x′i]表示上市公司信用风险预警指标无量纲归一化后的值;[xmax]和[xmin]分别表示上市公司信用风险预警指标的最大值和最小值。
2.2 支持向量机核函数的选择
当前支持向量机的核函数主要类型有:多项式核函数、径向基核函数和Sigmoid核函数。由于不同的核函数得到的上市公司信用风险预警结果不同,分别统计不同核函数的支持向量机的上市公司信用风险预警正确率,结果如表2所示。
从表2可以发现:相对于多项式核函数和Sigmoid核函数,径向基核函数的上市公司信用风险预警正确率更高,因此,本文选择径向基核函数的支持向量机构建上市公司信用风险预警模型,其定义如下:
[K(xi,x)=exp-x-y22σ2] (11)
式中[σ]表示核宽度参数。
2.3 支持向量机参数的确定
为了体现上市公司信用风险预警公平性,进行5次仿真实验,训练样本采用随机方式选择,剩余的样本作为测试样本集合,[C]的取值范围为[2-10,210],[σ]的取值范围为[2-10,210],每一次仿真实验的支持向量机参数如表3所示。
2.4 上市公司信用风险预警结果与分析
选择BP神经网络的上市公司信用风险预警方法以及随机确定支持向量机参数的上市公司信用风险预警方法进行对比实验,统计它们的上市公司信用风险预警正确率,结果如图3所示。从图3可以看出:
1) BP神经网络的上市公司信用风险预警效果最差,这是因为BP神经网络要求上市公司信用风险预警历史样本数量比较大,210个样本难以满足该“大样本”要求,导致上市公司信用风险预警正确率低。
2) 传统支持向量机的上市公司信用风险预警效果要优于BP神经网络,这是因为支持向量机的学习性能要优于BP神经网络,构建了更优的上市公司信用风险预警模型。
3) 本文方法的上市公司信用风险预警效果要优于传统支持向量机,是由于引入了粒子群优化算法解决了当前支持向量机参数优化的难题,提高了上市公司信用风险预警正确率,验证了本文方法用于上市公司信用风险预警建模的优越性。
3 结 语
上市公司信用风险是当前上市公司研究领域的一个热点,信用风险具有十分复杂的变化特点,为了解决上市公司信用风险预警正确率低的难题,采用支持向量机建立上市公司信用风险预警模型,并采用粒子群优化算法对上市公司信用风险预警模型参数进行优化。上市公司信用风险预警仿真结果表明,本文方法是一种正确率高的上市公司信用风险预警方法,具有十分广泛的应用前景。
参考文献
[1] 邹新颖,涂光华.基于信用风险及融资约束模型的财务预警指标构建[J].统计与决策,2015(14):45?48.
[2] 张希,朱利,刘路辉,等.基于多层网络的银行间市场信用拆借智能风险传染机制[J].计算机应用,2019,39(5):1507?1511.
[3] 霍源源,姚添译,李江.基于Probit模型的中国制造业企业信贷风险测度研究[J].预测,2019,38(4):76?82.
[4] 高雅轩,朱家明,牛希璨.基于KMV模型的我国上市民营企业信用风险实证分析[J].东莞理工学院学报,2019,26(3):87?93.
[5] 杨斌清,向燕,刘文福.基于遗传层次分析法的企业环境信用预警指标体系构建[J].江西理工大学学报,2017,38(6):33?38.
[6] 王妍.基于随机森林的信用评估特征选择[J].黑龙江科学,2019,10(14):159?161.
[7] 陈雪莲,潘美芹.基于Logistic回归模型的P2P借款人信用违约风险评估模型研究[J].上海管理科学,2019,41(3):7?10.
[8] 李兵,何华.基于KPCA?GaussianNB的电子商务信用风险分类[J].物流技术,2019,38(2):61?67.
[9] 王少英,兰晓然,刘丽英.基于非凸惩罚的SVM模型对科技型中小企业信用风险评估[J].数学的实践与认识,2019,49(3):307?312.
[10] 徐占東,程砚秋,迟国泰,等.一种与市场预期误差最小的信用风险评价模型及实证[J].数学的实践与认识,2019,49(3):94?107.
[11] 王晓洁,刘洪春.基于贝叶斯网的航运上市企业信用评价研究[J].价值工程,2018,37(35):101?105.
[12] 高更君,张盈.基于云模型的电商平台供应链金融风险评价[J].计算机应用与软件,2018,35(11):74?80.
[13] 王卓伦,王兴芬.网络零售物流企业信用评价指标体系与风险预警[J].福建电脑,2017,33(4):1?5.
[14] 邬建平,周希良.基于核主成分分析和BP神经网络的电子商务信用风险预警[J].物流技术,2016,35(4):97?102.
[15] 安英博,张宇敬,张建男.基于朴素贝叶斯的村镇银行信用风险预警研究[J].无线互联科技,2015(22):109?111.
猜你喜欢
辽宁经济(2017年6期)2017-07-12
电子技术与软件工程(2016年20期)2016-12-21
价值工程(2016年32期)2016-12-20
价值工程(2016年29期)2016-11-14
商(2016年27期)2016-10-17
商(2016年27期)2016-10-17
科学与财富(2016年28期)2016-10-14
当代经济(2016年26期)2016-06-15
新疆财经大学学报(2015年3期)2015-12-10
特区实践与理论(2014年5期)2014-07-24
