
基于随机森林算法的农产品产量影响因素权重分析*
2020-07-13 10:11胡新祥李英兰孔祥盛马玉婷
甘肃科技 2020年9期
胡新祥,赵 霞,张 乾,李英兰,孔祥盛,马玉婷
(甘肃农业大学 信息科学技术学院,甘肃 兰州 730070)
1 概述
几千年来,中国劳动人民过着“靠天收”的生活。农民们根据长久以来的经验总结出了在农耕中各种方式方法。但是这种依靠经验的方法往往会因为一些特殊的因素而受到影响。一旦出现意外,对农户和社会带来的损失可能是不可估量的。进入了新时代,我们可以尝试使用现代技术来对这些影响农作物产量的因素进行科学的分析,让人们更加了解这些因素在农作物产量起到的作用,进而制定出科学的策略来应对一些不可控现象的发生。这既符合大环境趋势,也让理论研究真正的应用到实际社会生产生活之中。在信息时代,计算机技术能够为农产品产量的预测提供更多、更有效的预测方式。利用计算机技术的快速性,国内外的研究者将计算机技术运用到中国农业经济预测的过程中,通过建立相关农产品产量的预测系统,更精确的预测中国农产品产量的变化趋势。
近年来,深度学习等人工智能技术得到了迅速发展,在很多领域都取得了较好的应用效果。其中分类算法在数据挖掘方面应用最为广泛。
常用分类算法有:典型的朴素贝叶斯方法,针对大量数据训练速度较快,并支持增量式训练,对结果的解释便于理解,但在大数据集下才能获得较为准确的分类结果,且忽略了数据各属性值之间的关联性[1];K-最近邻分类算法比较简单,训练过程迅速,抗噪声能力强,新的数据能够直接参与训练集而不需要再次训练,但在样本不平衡时结果偏差较大,且每次分类都需要重新进行一次全局运算[2];决策树分类算法易于理解与解释,可进行可视化分析,运行速度较快,可扩展应用于大型数据库中,但容易出现过拟合问题,且易忽略数据属性间的关联性[3]。
随机森林算法在分类方面表现突出,其避免了决策树分类算法中容易出现的过拟合问题,并在运算量未显著提高的前提下,提高了分类准确率[4]。因此,设计旨在利用随机森林算法实现精准客观且省时省力的分析。
2 研究背景与目的
2.1 研究背景
年甘肃省主要农作物:玉米、高粱、马铃薯、棉花与油料的产量与10年间甘肃省各年年均太阳辐射量、年均气温与年均降水量之间的关系。
2.2 研究目的
以10年间甘肃省的各年度气象数据为条件,结合产量分析出各种气象因素对不同农作物产量的影响程度。采用python语言作为分析工具,采用随机森林算法对数据进行处理与分析。最后得出每一种农作物的产量受各种气候条件影响程度的大小,并用图表的形式直观展现,作为农业生产活动的参考指标。
3 数据的采集与处理
3.1 数据的收集
选取甘肃省2000年~2010年十年间的各类典型农产品产量与各年的年均降水量、年均气温与年均太阳辐射量,数据均来自国家统计局官网。对数据进行整理后在python程序中读取并制表,见表1。
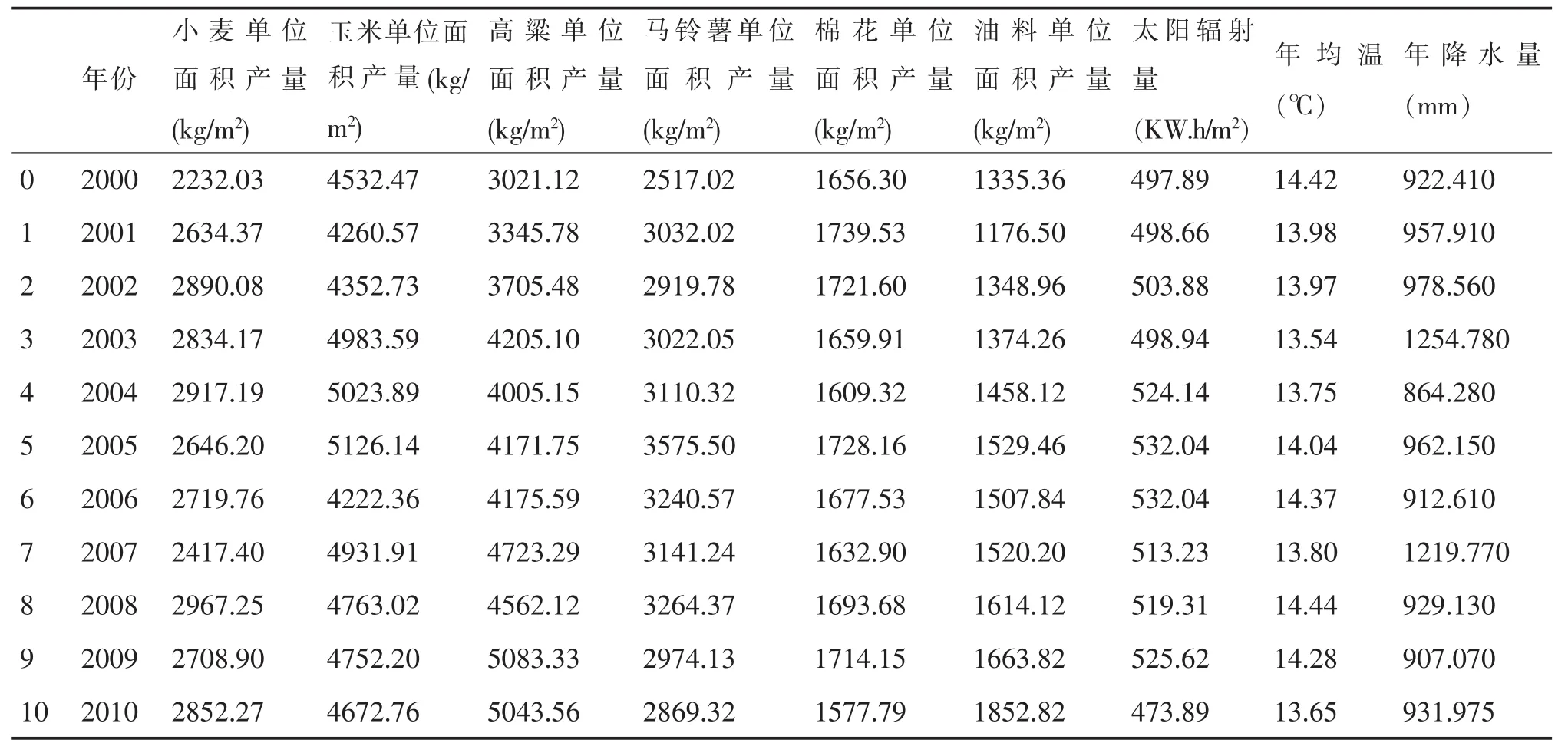
表1 2000年~2010年的数据
3.2 数据预处理
读取数据以后利用python对所得数据进行一些预处理动作,目的是为了观察数据是否存在缺失情况与离群数据。都缺失数据与离群数据要进行相应的处理。
首先将各年度的年均气温、降水量与太阳辐射量绘制在二维柱状图中进行观察。
观察10年间度甘肃省年均气温的直方图(图1),数据基本分布在12℃~14℃左右,无缺失数据与离群数据。

图1 2000年~2010年年均气温柱状图
观察10年间度甘肃省年均降水量的直方图(图2),数据基本分布在800~1000mm左右,2002年与2007年降水量有明显增多,无缺失数据。
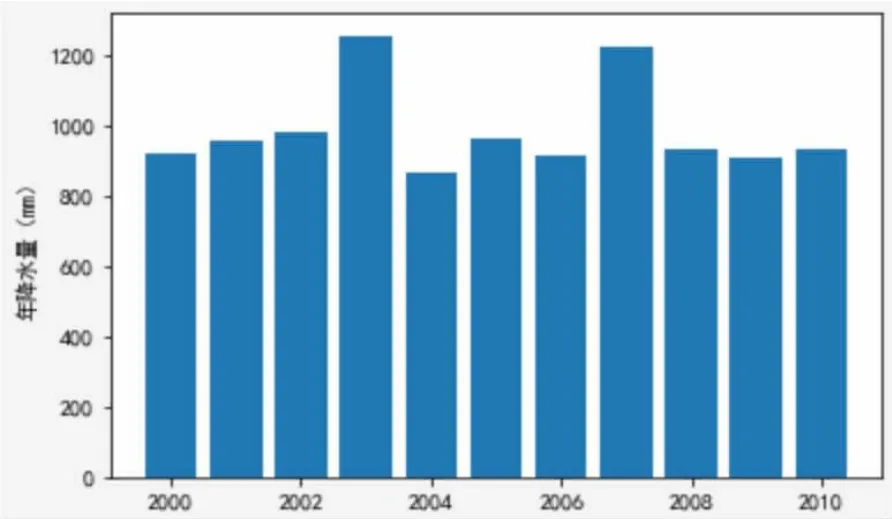
图2 2000年~2010年年均降水量柱状图
观察10年间度甘肃省年均太阳辐射量的直方图(图3),数据基本分布在 500KW.h/m2左右,无缺失数据与离群数据。
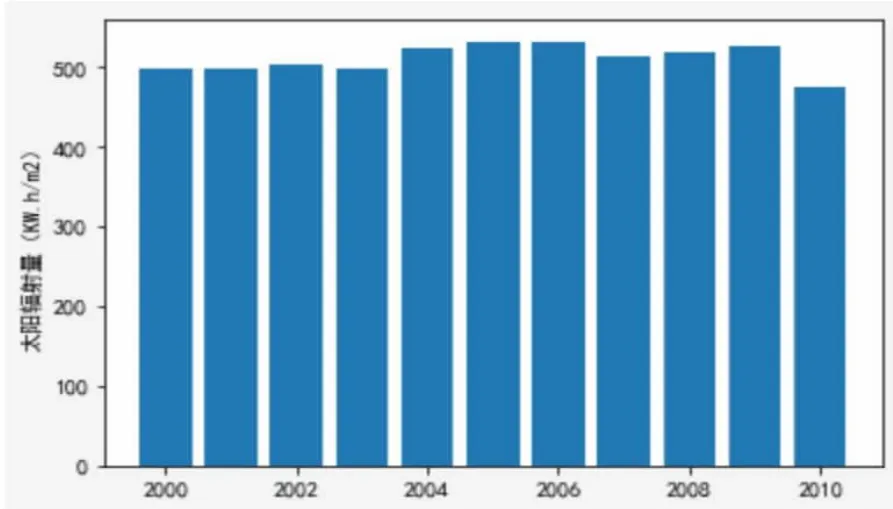
图3 2000年~2010年年均太阳辐射量柱状图
随后将10年间甘肃省各类主要农作物的年均产量利用箱型图直观的展现出来(图4),观察是否有缺失数据与离群数据。
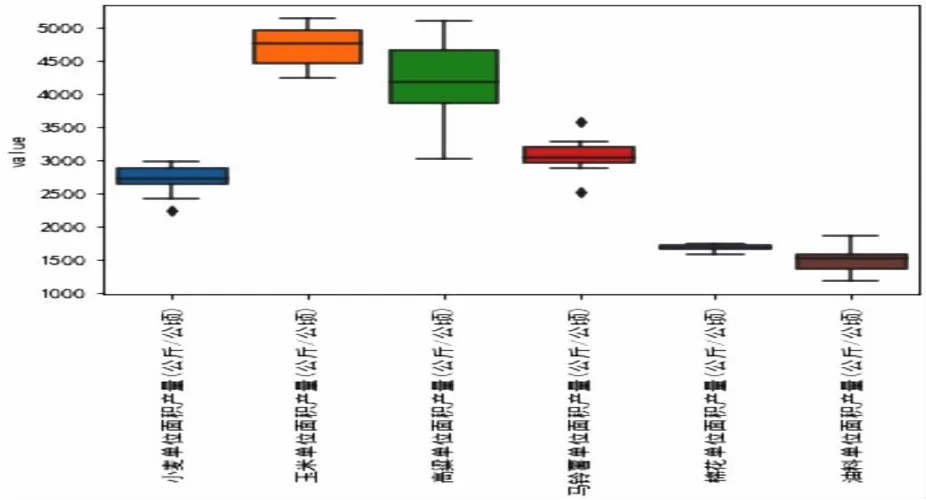
图4 2000年~2010年农作物产量箱型图
3.3 数据的分析
在对数据进行图表直观的分析以后,开始对收集到的数据进行进一步的分析,利用python中的pd.describe()函数对十年间农产品产量与环境量进行计算分析,其意义在于观察这一系列数据的范围。大小、波动趋势等等,便于判断后续对数据采取哪类模型更合适。计算结果见表2,count为计数值,mean为平均值,std为标准差,min为最小值,25%为下四分位,50%为中位数,75为上四分位数,max为最大值。

表2 pd.describe()函数对数据处理结果
从分析的结果来看,收集到的各项数据质量较好,都在各自的范围内波动,且无缺失情况。利用这些数据就可以进入到各种环境对产量影响程度的探索阶段。
4 查看相关性
在对收集到的数据进行预处理以后,进入数据相关性的分析工作中。在使用分类算法分析之前,利用python中numpy triu_indices函数制作数据矩阵,利用seaborn绘制数据热力图。这一动作的目的是初步查看各组数据之间的相关性,使用热力图可以更加直观的展现出来,如图5所示。
从得到的热力图中可以直观观察到各种农作物与各环境变量之间的相关程度。由图可初步得出:小麦的每公顷产量受太阳辐射量影响程度最大,年均温与年均降水量对其影响程度相当,但次于太阳辐射量的影响程度;玉米与高粱每公顷产量受太阳辐射量与年均降水量的影响程度较大,受年均温的影响程度较小;棉花每公顷产量受太阳辐射量与年均温的影响程度较大,受年均降水量的影响程度较小;三种环境对油料的产量影响程度相当。

图5 数据相关性热力图
初步查看到各环境与农作物之间的相关性后,选择一种合适的分类算法对数据进行更加深入的分析,得到各个环境变量对作物产量影响程度的具体权重。
5 随机森林
5.1 决策树
决策树作为随机森林的基分类器,是一种十分常用的分类方法。决策树分类思想实际上是一个数据挖掘过程,其通过产生一系列规则,然后基于这些规则进行数据分析[5]。决策树采用单一决策方式,因此具有以下缺点:一是包含复杂的分类规则,一般需要决策树事前剪枝或事后剪枝;二是收敛过程中容易出现局部最优解;三是因决策树过于复杂,容易出现过拟合问题。为了解决这些缺点,又引入随机森林的概念。
5.2 随机森林
随机森林中的决策树按照一定精度进行分类,最后所有决策树参与投票决定最终分类结果,这是随机森林的核心概念。
随机森林构建主要包括以下3个步骤:
1)为N棵决策树抽样产生N个训练集。每一棵决策树都对应一个训练集,主要采用Bagging抽样方法从原始数据集中产生N个训练子集。Bagging抽样方法是无权重的随机有放回抽样,在每次抽取样本时,原数据集大小不变,但在提取的样本集中会有一些重复,以避免随机森林决策树中出现局部最优解问题。
2)决策树构建。该算法为每个训练子集构造单独的决策树,最终形成N棵决策树以形成“森林”。节点分裂原则一般采用CART算法或C4.5算法,在随机森林算法中,并非所有属性都参与节点分裂指标计算,而是在所有属性中随机选择某几个属性,选中的属性个数称为随机特征变量。随机特征变量的引入是为了使每棵决策树相互独立,减少彼此之间的关联性,同时提升每棵决策树的分类准确性,从而提高整个森林的性能。
3)森林形成及算法执行。重复步骤(1)、(2),构建大量决策树,形成随机森林。算法最终输出由多数投票方法实现。将测试集样本输入随机构建的N棵决策子树进行分类,总结每棵决策树分类结果,并将具有最大投票数的分类结果作为算法最终输出结果。如图6所示。
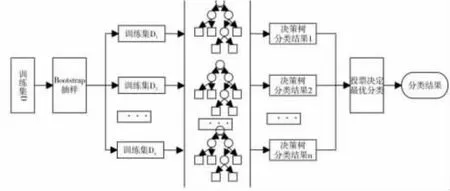
图6 随机森林算法原理图
5.3 使用随机森林
在程序中构造随机森林模型实现使用随机森林算法对已有数据进行分析,并对得出的果绘制农作物的影响程度的表格,见表3。

表3 各个因数影响农作物的程度情况表
6 实验分析
由随机森林算法得出的最后结果可以观察到,在此模型中,太阳辐射量、年均气温、年均降水量对小麦单位面积产量的影响程度分别为:0.425988 0.327842 0.246170;对玉米单位面积产量的影响程度分别为:0.383898 0.431007 0.185095;对高粱单位面积产量的影响程度分别为:0.558349 0.320426 0.121225;对马铃薯单位面积产量的影响程度分别为:0.701089 0.155311 0.143600;对棉花单位面积产量的影响程度分别为:0.338979 0.612493 0.048528;对油料单位面积产量的影响程度分别为:0.761373 0.195005 0.043622。
得出的结论与初步查看相关性时,从热力图中的到的大致相关性相吻合。说明结论准确可信。同时也验证了随机森林算法在对农产品产量影响因素权重分析中的应用的正确性与有效性。
7 结语
在此次实验中,通过收集到的甘肃省10年间环境变量与主要农作物产量的数据,在进行了数据的预处理与简单的查看相关性后,选择使用随机森林算法模型对一系列数据进行了科学、客观的分析。最后得到了太阳辐射量、年均温、年均降水量对甘肃省六种主要农作物影响程度的具体权重,得到的结果与现实相吻合,且用数据具体的说明的不同环境变量对不同作物的具体影响程度。这一结果在监督算法的保证下真实有效,可以作为农业生产活动的参考指标之一。
猜你喜欢
今日农业(2022年16期)2022-11-09
今日农业(2022年15期)2022-09-20
今日农业(2022年13期)2022-09-15
今日农业(2021年16期)2021-11-26
太阳能(2021年5期)2021-06-03
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
郑州大学学报(医学版)(2015年1期)2015-02-27
