
基于级联卷积网络的面部关键点定位算法*
2020-07-13 07:13:38孙铭堃梁令羽汪涵何为赵鲁阳
中国科学院大学学报 2020年4期
孙铭堃,梁令羽,汪涵,何为†,赵鲁阳
(1 中国科学院上海微系统与信息技术研究所 宽带无线移动通信研究室, 上海 201800;2 中国科学院大学, 北京 100049)(2019年1月3日收稿; 2019年3月22日收修改稿)
在计算机视觉领域,人脸作为生物识别的一项重要特征,较指纹、虹膜等其他特征来说,具有采集简单、非接触性且隐蔽等优点,在视频监控、安全验证、门禁系统等方面有着很广阔的应用前景。
人脸关键点定位是人脸识别的关键环节,其在限定环境下已达到商用程度,但在非限定环境[1]中,由于图像采集时的非可控性,如拍摄背景、角度、光照、人脸表情及拍摄成像质量等,使得非限定环境下人脸识别的难度大大提高。因此,非限定环境下的人脸关键点定位一直是国内外研究的热点。目前关键点定位方法大致可以分为以下几类:1)基于先验规则的方法[2];2)基于形状和外观模型的方法[3];3)基于统计能量函数的方法[4-5];4)基于级联回归的方法[6-8];5)基于分类器的方法[9];6)基于深度学习的方法[10-13]。随着计算资源的提升,通过卷积神经网络的非线性映射能力提取人脸形状特征的深度学习,在人脸识别上取得了远超其他方法的识别精度。
本文采用级联卷积网络[14]的思想,有别于常规的5点定位,实现了包括外部17关键点与内部51关键点在内的共68关键点定位。针对外部关键点,将两层卷积网络级联,分别完成外部关键点的粗细定位;针对内部关键点,结合可变形部件模型(deformable part model,DPM),引入五官部位的形变信息,在检测人脸的同时完成五官位置的定位,避免了传统算法中由于先检测人脸位置,后检测五官位置,而造成人脸位置检测结果直接影响五官定位精度的问题。此外,在模型训练过程中,引入多通道卷积,提取不同层级的特征信息,使图像中的低、中、高分辨率的像素得到充分利用,提高面部关键点的检测精度。
1 卷积神经网络
卷积神经网络[15](convolutional neural network,CNN)主要由卷积层和池化层构成,是一种专门用来处理具有类似网络结构数据的神经网络[16]。在卷积层中,通过并行地进行多个卷积运算来代替一般的矩阵乘法运算,进而产生一组线性激活响应,然后通过一个非线性激活函数对得到的线性激活响应进行映射,最终再使用池化函数(pooling function)对输出进行调整。
VGGNet构筑了16~19层深的卷积神经网络,是由牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司研究员一起研发的深度神经网络,迁移到其他图片数据上的泛化性也非常好。其中VGG-16网络由13个卷积层、5个池化层和3个全连接层构成,模型的参数量达到数亿级,而且在网络模型的训练阶段中,还需保存每一步的权值(weight)、偏重(bias)的偏导数以及所需部分的输出结果。考虑到硬件环境受限,故对原有VGG-16网络做轻量化处理:
1)卷积核数目:为了提取更详细的图像特征,将卷积核数量由512升为600,虽然增加了卷积层的网络参数,但其只占整体参数量的一小部分,从整体上看,仍缩短了网络训练所需时间。
2)激活函数:采用PReLU替代ReLU作为每一个层所使用的激活函数,解决神经元失活问题,并加快网络的收敛速度,减少网络训练周期。
3)全连接层:由于全连接层占据绝大部分的参数量,故去除前两层全连接层;同时采用平均池化的方法代替原第5层的最大池化,提取出更抽象、更具有辨识度的特征[17],在保留网络性能的同时进一步降低模型的参数个数。
Light-VGGNet的网络结构及参数设置如表1所示。
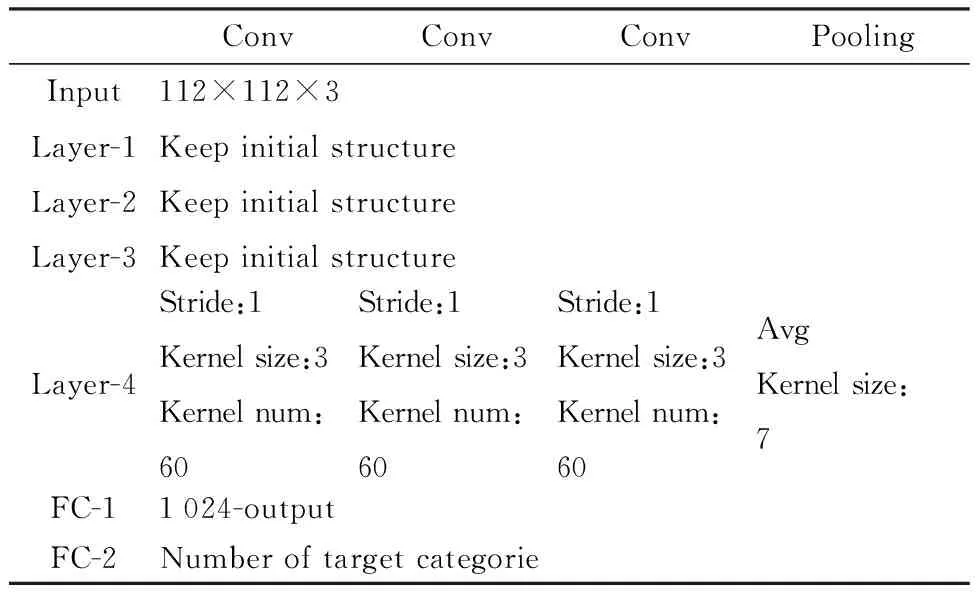
表1 Light-VGGNet网络结构及参数量Table 1 Structure of Light-VGGNet
CIFAR-10数据集是由50 000张训练图像和10 000张测试图像组成的小型自然图像数据集,共包括10类图像,每幅图像都是32×32的RGB图像。采用未经任何预处理和增强的原始图像,在CIFAR-10数据集上,采用VGGNet、Light-VGGNet进行模型训练。所得实验结果如图1。由训练结果可知,在CIFAR-10和CIFAR-100数据集上:1) Light-VGGNet的误差总是小于VGGNet函数;2)当二者迭代相同次数后,Light-VGGNet的准确率较高。
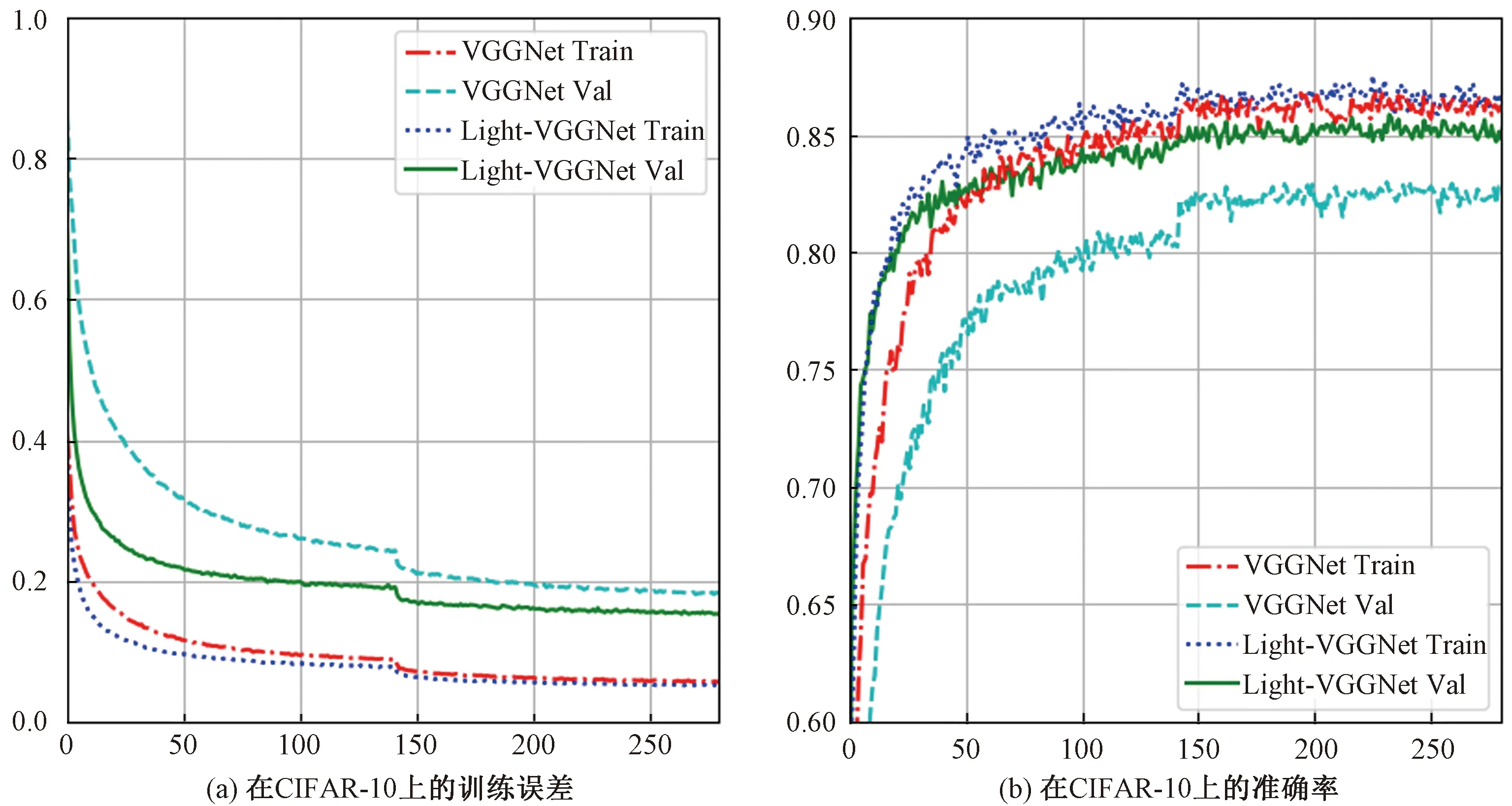
图1 VGG-16和Light-VGGNet的对比Fig.1 Comparison between VGG-16 and Light-VGGNet
2 人脸关键点定位算法
人脸关键点(landmark)即人脸上能够代表人脸差异的坐标点。通常由人脸外轮廓、左右眉毛轮廓、上下眼睑、双眼中心点、鼻尖、鼻梁及鼻头轮廓、内外嘴唇轮廓组成。根据这些关键点所处的相对位置可分为内、外关键点。其中外关键点分布于人脸边缘,可提取人脸大致的位置与角度信息;内关键点则主要由局部的五官关键点构成,这类关键点在人脸识别与跟踪中能够提供更可靠的局部信息。
常见的关键点定位大多为5点,仅能确定五官的大致位置,局部细节特征很少。而本文主要是对人脸实现68关键点定位,包括外轮廓的17个点,左右眉毛10个点,左右眼12个点,鼻梁及鼻头9个点,以及嘴巴内外轮廓20个点。此68关键点能够提供丰富的局部特征,实时跟踪人脸的局部变化,该检测的问题形式可表达为
y=hθ(x),
(1)
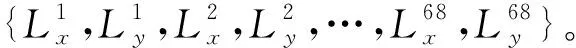
2.1 级联卷积网络
本文采用Zhou等[14]提出的关键点检测思想,并行采用两个级联卷积网络,由粗到精,由外向内地实现对人脸68个关键点的高精度定位。网络结构图如图2所示。

图2 级联卷积网络示意图Fig.2 Diagram of cascade convolutional neural network
2.2 可变形部件DPM模型
可变形部件模型(DPM)是一种基于部件的复杂物体检测方法,它是在HOG[18]特征检测的基础上引入弹性形变部件,如图3(a),来描述目标部件之间的相对变化,以加强对复杂目标的特征描述。
人脸检测中,DPM的训练过程如图3(b)所示:选用HOG特征对输入图像进行人脸信息提取,同时通过构建图像特征金字塔降低分辨率对滤波器响应的影响;之后再进行根滤波器与部件滤波器的训练,并将粗、细尺度滤波器进行组合,完成针对人脸轮廓、人眼、鼻头及人嘴的模型搭建;再采用合适的分类器对模型进行训练,从而得到一个针对人脸的星形结构模型。最后利用训练好的DPM模型在目标图像上逐块扫描,并根据DPM得分进行部件的判断与定位。
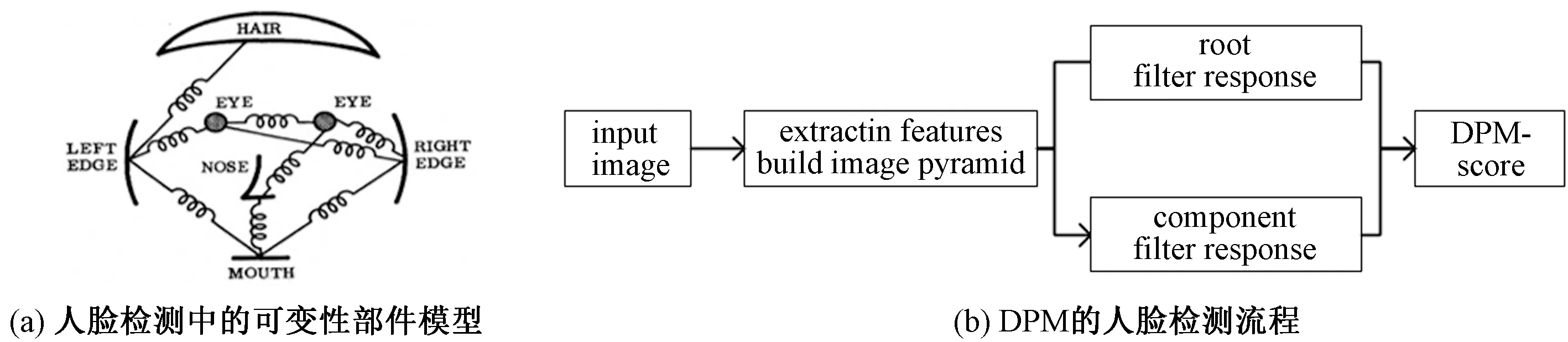
图3 DPM模型在人脸检测中的应用Fig.3 Application of DPM in face detection
虽然DPM能够有效地利用目标整体与各个部件的特征与位置信息,但依然存在以下问题:1)HOG特征的提取与图像金字塔的构筑过程计算量大,造成整个特征提取过程耗时很长;2)将模型应用于图像检测时,由于它是将训练完成的滤波器与图形的各个部分进行扫描匹配,工作量较大,进一步增加了目标检测耗时。
2.3 人脸检测层
卷积神经网络在图像特征提取过程中通过卷积操作避免了繁杂的图像预处理过程,且其权值共享性有效减少了训练过程的参数量。故在Light-VGGNet网络基础上,融合DPM模型,提出DPM-CNN网络结构,通过引入多通道卷积,提取不同尺度的人脸信息,以完成CNN特征金字塔的构造,增强网络对目标尺寸的抽象表达能力,解决DPM模型特征提取与检测过程耗时较长的问题。此层的网络结构如图4所示。

图4 人脸检测网络结构Fig.4 Network structure of face detection
此层将112×112的RGB图像转换为灰度图像作为输入,共包含4层卷积层。其中:1)第1卷积层由64个3×3的卷积核构成,跨度为2;2)第2卷积层由128个3×3的卷积核构成,跨度为1;3)第3卷积层由256个3×3的卷积核构成,跨度为1;4)第4卷积层由600个3×3的卷积核构成,跨度为1。各卷积层之后均为2×2,跨度为2的最大池化层。同时在第2、3卷积层之后引入多通道卷积,与第4池化层的结果进行拼接(contcat),并输入到全连接层,最后再经过SoftMax层进行激活响应,得到28维的输出层。
在人脸检测层中引入DPM人脸模型,在进行人脸检测时,采用式(2)所示函数作为误差函数,结合人脸五官位置坐标,对人脸检测层进行迭代训练,完成人脸与五官位置的同时检测。
Loss=LFaceRoi+λLPartRoi
(2)
λ用于均衡两个损失函数,默认设为1;i由人脸的左右眉毛、左右眼眼角、鼻子、嘴巴的左右嘴角共12个五官关键点构成。(x,y)为真实坐标点,(x′,y′)为实际坐标点,且对误差进行归一化处理,以消除人脸尺寸对训练结果的影响。
2.4 人脸外部关键点定位
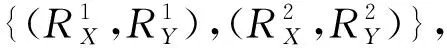

图5 外部关键点检测网络结构Fig.5 Network structure of external landmark detection
2.5 人脸内部关键点定位
对人脸内部关键点,采用两层级联网络进行定位。其网络结构如图6(a)所示:1)将第1层人脸检测层中定位到的人脸位置坐标以1.2倍的尺寸扩大,裁剪重塑为96×96的图像,采用人脸检测层中的DPM-CNN网络结构,结合五官位置信息,同时完成人脸内部轮廓边界框与五官位置的定位;2)第2层:固定第1层网络权值,并将第1层定位到的五官位置坐标以1.5倍扩大,抠取左右眉毛、左右眼、鼻子、嘴巴共6个局部图像,缩放为48×48的尺寸,记录图像间的空间变换参数,再采用相同的卷积网络分别对其进行关键点定位,每层的网络结构如图6(b)所示。
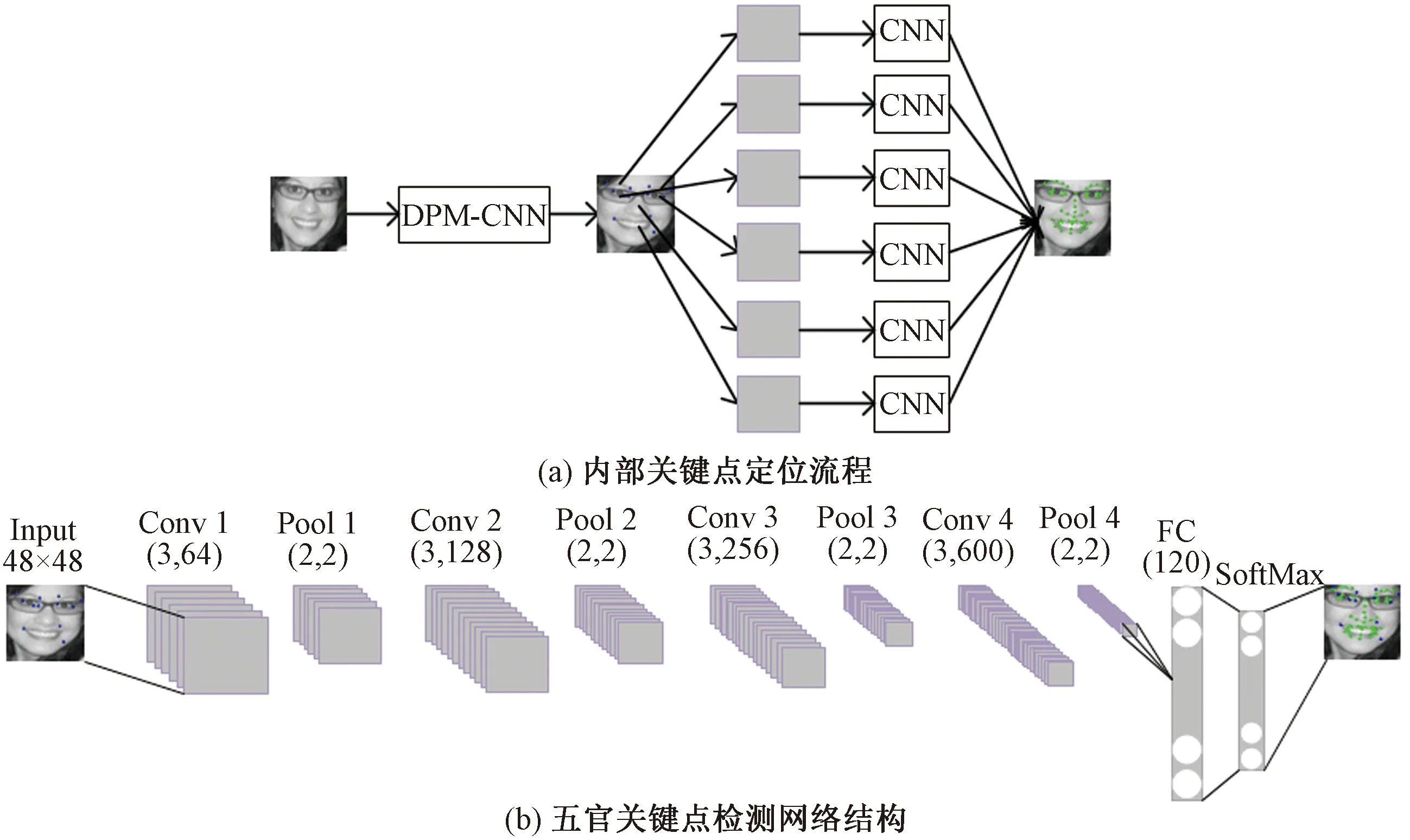
图6 五官关键点检测示意图Fig.6 Diagram of partial landmark detection
3 实验设计及结果分析
3.1 数据集扩充及模型训练
本文所有实验及模型是在ubuntu16.04系统上,采用TensorFlow 1.8.0开源框架,在两块内存为12 G的TITAN V上完成。所用数据集来自Helen、LFPW、实验室录制及网络爬取的人脸图像。并手动对采集的数据样本重新标记,经过筛选后,共获得13 000张不同背景、光照、姿势的人脸照片。此外,通过伸缩镜像、加噪等操作,对此数据集进行样本扩充,最终得到34 000张样本图像。在其中随机选取30 000张作为训练集,其余4 000张选做验证集。图7为部分样本图片及标定信息示意图,可看出此样本涵盖了不同肤色、人种、角度、表情、尺度和光线的场景图。为了更方便地使用卷积神经网络训练,将图片统一为112×112的大小。在每次训练时,对权重进行Xavier初始化,并在训练样本中随机选取300作为训练Batch,采用Adam(adaptive moment estimation)算法进行训练,并将学习率设置为0.000 1。

图7 样本数据集示意图Fig.7 Diagram of sample data set
为了更全面地分析本文算法的性能,本文采用LFW人脸库作为测试集,并采用归一化的平均误差[11](normalized mean error)来衡量算法的性能,如下式所示:
(3)
式中:(x,y)为关键点标记的真实位置坐标;(x′,y′)为预测的位置坐标;N为用作测试的图像数量;分母D为双眼距离,用以平衡因人脸尺寸带来的差异。同时,为了更加量化地评判实验结果,当相对误差Lossrelative_err值大于0.1时评判为预测失败,标为0;反之则预测成功。
3.2 实验结果分析
3.2.1 人脸检测层
采用式(3)评判实验结果,最终得到的人脸平均识别率如表2所示:在验证集上,人脸检测率至少能达到92.8%。经网络级联后,在内部轮廓检测上,准确率提升至96.9%。
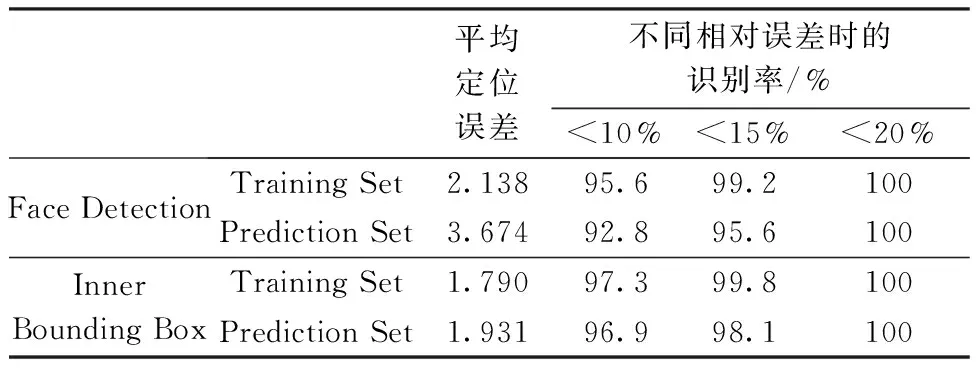
表2 人脸检测与人脸内轮廓平均识别率Table 2 Recognition of face detection and inner bounding box
此外,以FDDB数据库为测试集,将本文的DPM-CNN网络与传统的人脸检测模型Viloa-Jones[19]、DPM模型、RCNN[20]、Faster RCNN[21]、MSCNN[22]的检测准确度做对比。结果如表3所示。

表3 不同方法在FDDB上的检测时间、准确率和漏检率Table 3 Comparison of detection time, accuracy, and missed detection rate on FDDB among different methods
传统的Viloa-Jones采用积分图的方法进行特征提取,准确率明显低于其他方法。RCNN与Faster RCNN采用图像分割的方法选择候选窗口,虽然在一定程度上,减轻了选择窗口的工作量,但是依然会明显影响其检测速度。而MSCNN模型采用单一CNN结构,将多步骤融合到单一的卷积网络中,相较Faster RCNN大幅提升了检测速度,也提升了准确率。但其误检与漏检依然较低。而本文的DPM-CNN模型,在Light-VGG网络基础上,结合可变形部件,依靠部件的形变对误差函数进行约束,在人脸检测的同时完成对五官位置坐标的定位,并通过引入多通道卷积提取更多的图像特征,从而进一步提高了检测准确度和检测速度。
3.2.2 人脸关键点检测
以FDDB为测试集,将定位到的内外人脸框、五官关键点等与其他算法进行对比,来论证该算法的优越性。首先对内部人脸框进行定位,识别结果如表2所示。
本文算法与DCNN[23]、Shortcut DCNN[24]相比,左右眼、鼻子及嘴巴4个五官位置的平均定位误差都较低,具体结果如表4所示。本文网络结构在每个关键点位置的定位过程中融合了五官之间的形变约束,并通过多通道融合低高层网络特征,增强了网络的特征提取能力,最终使得该算法在各个关键点都有着较低的输出误差。

表4 五官位置平均定位误差Table 4 Average positioning errors of facial features
最终,本文算法在内外关键点、左右眉毛、左右眼、鼻子及嘴巴各部位关键点上的平均定位误差如表5所示,各个局部位置的平均定位误差都较低且相似。
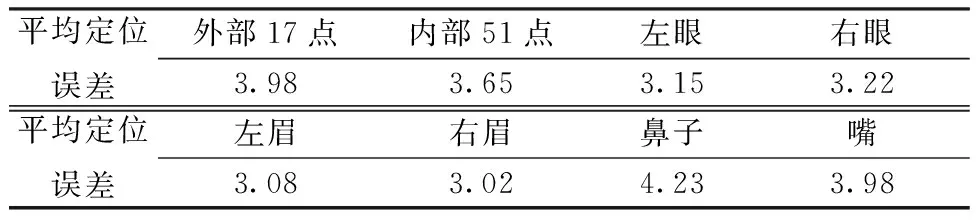
表5 人脸内外关键点平均定位误差Table 5 Average positioning errors of facial landmarks
图8为部分测试结果,从中可看出,对内外关键点的定位中:1)本文所采用的网络模型在非限定环境中不受年龄、肤色、姿势及表情变化的影响,能够很好地适应头部的偏转、仰俯及倾斜。2)当佩戴浅色透明眼镜时,可准确地标定出人眼关键点;当佩戴深色眼镜时,亦可在相应区域内大致标定出人眼关键点。3)当人脸处于部分遮挡或有复杂干扰物时,也可根据未遮挡部分准确估计出被遮挡部分的关键点位置。4)然而,当采集的图像分辨率较低且受光照极度不均时,此时由于丢失了大量的局部信息,使得标定结果存在一定程度的偏移。

图8 人脸关键点检测结果Fig.8 Examples of facial landmark detection
4 结论
本文提出一种基于级联卷积网络的面部关键点检测,在Light-VGGNet网络基础上,引入可变形部件,并通过多通道卷积提取不同层级网络的特征,构建CNN特征模型,完成DPM-CNN模型的搭建。通过人脸检测与五官位置的同时定位,降低人脸检测偏差对五官检测的影响。在进行面部关键点检测时,将两层不同的卷积网络级联,完成内外关键点的精准定位。经过一系列对比实验,本文中的网络模型,在精准度和检测速度上都较其他算法得到了提升。在非限定环境下,对年龄、肤色、表情、姿势以及模糊遮挡等情况都有着很好的适应性。但当光照不均且图像分辨率较低时,关键点定位仍存在一定程度的偏移。故在今后的工作中,需进一步优化网络结构,扩充训练数据集,提高模型适应性,且拟在本实验基础上,将该模型投入到相关的实际应用中。
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16 07:36:56
今日农业(2021年8期)2021-11-28 05:07:50
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
小星星·作文100分(2019年9期)2019-11-22 11:04:21
学生天地·小学低年级版(2019年3期)2019-04-10 23:59:08
学生天地(2019年9期)2019-04-04 11:56:08
动漫星空(2018年9期)2018-10-26 01:17:14
小雪花·小学生快乐作文(2016年2期)2016-05-30 05:36:38
发明与创新(2015年33期)2015-02-27 10:40:09
中国卫生(2014年2期)2014-11-12 13:00:16
