
基于XGBoost的固态白酒发酵产量预测∗
2020-07-13 12:48余天阳
计算机与数字工程 2020年5期
余天阳
(江南大学物联网工程学院 无锡 214122)
1 引言
白酒发酵过程中的酒醅温度影响酵母菌的生长繁殖,进而影响白酒的产量[1~2]。同时,入窖水分、入窖酸度和入窖淀粉浓度也会影响白酒的产量[3~5]。如何准确有效地预测白酒产量、保证白酒质量成为固态白酒发酵亟待解决的问题。常规优质固态白酒发酵温度曲线应符合“前缓、中挺、后缓落”的规律[6],是一系列复杂生化反应的宏观体现,其中蕴含重要的演化信息,故期望从中找出演化规律,利用已知的检测数据预测白酒产量,为下一轮的入窖工艺优化提供依据。
目前关于预测的方法主要有时间序列法、小波分析法、人工神经网络等。1989年Baldi P通过研究发现,在处理非线性数据上,神经网络的预测能力要优于传统模型[7]。但是L.Kaastra在1995年发现神经网络存在过拟合、难收敛和模型训练困难等问题[8],与此同时Vapink在神经网络的基础上首次提出了以结构风险最小化为原则的SVM(Support Vecor Machine,SVM)算法[9],该方法较好地解决小样本、非线性等实际问题,并且在很多领域已经开始得到应用,如两相流行识别[10]、故障诊断[11]、模式识别[12]等领域。但SVM的训练需要求解二次规划问题,影响计算速度。为此,Suykens等[13]提出了最小二乘支持向量机(Least Squares Support Vector Machine,LSSVM)方法。最小二乘支持向量机(LSSVM)是标准支持向量机的一种扩展,通过求解线性方程,有效简化计算过程,提高运算速度。但是,在LSSVM建模过程中模型的惩罚参数γ和核参数σ对模型的拟合精度和泛化能力有着较大影响。传统的取值方法是依据经验通过试凑法进行调试,没有统一的规则。粒子群(Particle Swarm Optimization,PSO)算法[14]是基于种群的并行全局搜索策略,概念简单、易于实现,且没有许多参数需要调整,具有更快的收敛速度,对处理高维数据具有一定的优势,常应用于支持向量机的参数优化。从已有的研究成果来看,基于机器学习方法进行预测已经越来越常见,但所采用的的方法多为常规方法,如SVM、神经网络、LSSVM等经典方法,Chen(2016)[15]提出了一种新的 XGBoost的机器学习算法,该方法是大规模并行boosted tree的工具,是目前最好的开源boosted tree工具包,比常见方法快数倍以上,已经逐渐应用于数据的分析预测中。
本文在XGBoost建模方法的基础上,通过分析样本间的马氏距离[16~17],剔除原始样本中相关性较小的样本点,并将该方法应用于固态白酒发酵的产量预测当中,测试结果表明该方法符合预测精度,能够应用于实际工程应用。
2 数据的采集与处理
2.1 数据采集
本文预测模型所需要的训练样本和测试样本来自于2018年2月江苏某酒厂生产区域内1168口窖池。该厂采用物联网无线测温技术对生产区域内全部窖池的糟醅温度进行实时在线监控。其中,物联网无线温度传感器统一安插位置为每口窖池中心点往下1.5m处(离窖底0.5m),采用PT100温度传感器每隔1h自动采集1次糟醅发酵温度,并发送到各自的无线路由器上,再由无线路由器将搜集到的温度数据传送到工控机中进行数据交换和数据处理。此次共采集样本522份,数据特征为522*1440。
2.2 相关性样本剔除算法
相关性样本剔除是将样本空间中相关性较小的样本采用一定的办法去除,再利用剩余样本进行建模。这种方法可以简化模型结构,提高在线计算的速度与精度。欧氏距离和马氏距离常被用来度量样本间的相似度。欧氏距离法表达的是数据在特征维度空间中的真实距离;马氏距离法表达了数据的协方差距离,即标准化数据与中心化数据之差,以此来考量样本间的相似程度。
2.3 相关性样本剔除实验
本文原始样本共有522个发酵数据,采用马氏距离法和欧氏距离法作为样本相似的判别依据。在保证模型精度的情况下,通过经验法选取ε1=0.01,剔除相关性较小的样本序号如表1所示。

表1 剔除样本对比
为了更好地评价相关性样本剔除算法的优劣,采用均方根误差RMSE指标对其进行检验:

其中l是测试样本的个数,yi为测试样本的原始值,ŷi为测试样本的预测值。如表2所示,剔除相关性较小的样本后,模型的精度明显增加,而采用马氏距离法精度最高。

表2 剔除算法比较
3 基于XGBoost预测方法
3.1 XGBoost基本原理
XGBoost[10]的 全 称 是 eXtreme Gradient Boost⁃ing,即极端梯度提升树,是梯度提升机器算法(Gra⁃dient Boosting Machine)的扩展。Boosting分类器属于集成学习模型,其基本思想是把成百上千个分类准确率较低的树模型组合成一个准确率较高的模型。该模型不断迭代,每次迭代生成一棵新的树,通过不断加入子树使模型不断逼近样本分布,过程如下:
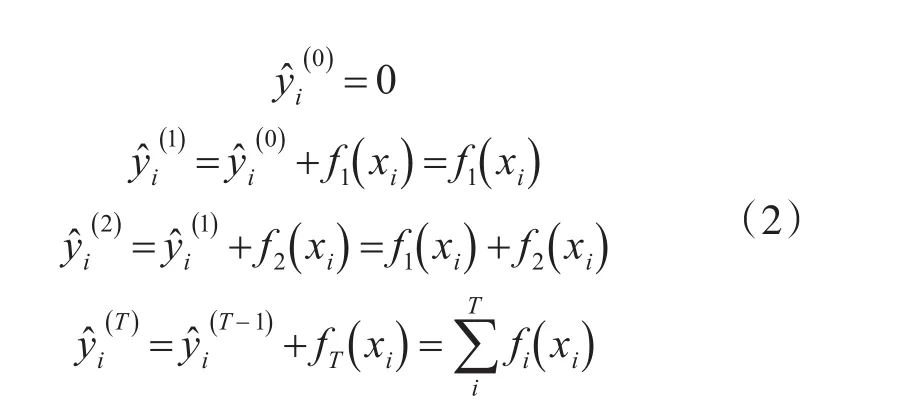

结合上述两式的最小残差值为(结构分数):
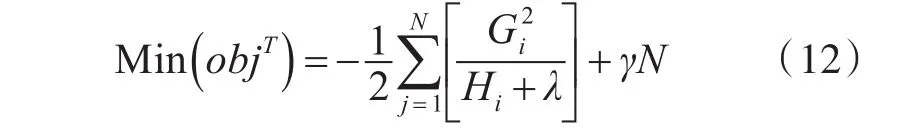
一次迭代要增加一棵树拟合样本集,暴力的方法就是枚举所有的树,然后选择结构分数最小的。
3.2 XGBoost模型参数
XGBoost模型有3种类型的参数:通用参数、辅助参数和任务参数。通用参数确定上升过程中上升模型类型,常用树或线性模型;辅助参数取决于所选的上升模型;任务参数定义学习任务和相应的学习目标。
XGBoost模型中,常用的参数说明如下:
1)booster:设置需要使用的上升模型。可选gbtree(树)或gblinear(线性函数),默认为gbtree。
2)nthread:XGBoost运行时的并行线程数,默认为当前系统可以获得的最大可用线程。
3)eta:收缩步长,即学习速率,取值范围是[0 , 1],默认为0.3。在更新叶子节点的时候,权重乘以eta,以避免在更新过程中出现过拟合的现象。
4)max_depth:每棵树的最大深度,取值范围为[1 , ∞] ,默认为6。树越深,越容易过拟合。
5)subsample:训练的实例样本占总体实例样本的比例,取值范围为[ ]0,1 ,默认为1,值为0.5时意味着XGBoost随机抽取一半的数据实例来生成树模型,这样能防止过拟合。
6)objective:默认为reg:linear。
seed:随机数种子,为确保数据的可重现性,默认为0。
3.3 K折交叉验证方法
论文采用K折交叉验证的方法。将原始数据分为K个子集,每个子集分别验证一次,剩余的K-1组子集作为训练数据,这样可以得到K组训练集和测试集,以最终的回归平均精度作为性能指标。在实际应用中K值一般大于等于2,需要建立K个模型来进行K折交叉验证的实验,并计算K次测试集的平均回归精度。
K折交叉验证的结果能较好的说明模型效果,有效的避免了过拟合和欠拟合问题。在XGboost中,通过使用xgb.cv函数来做交叉验证。
4 应用实例
固态白酒发酵是一系列复杂生化反应的过程。白酒发酵过程中酒醅温度变化是导致白酒产量变化的直接原因。此外,白酒产量还受到入窖酸度、入窖水分、入窖淀粉等因素的影响[16]。因此,建立能够反映这些因素的确定性固态白酒发酵产量预测模型比较困难。
目前我国的固态白酒发酵产量监控还是以经验为主,通过监控发酵过程中的酒醅温度曲线来大致推测窖池的发酵情况,从而针对性地做好下一轮入窖配料的调整工作。传统方法认为只要酒醅温度曲线保持“前缓、中挺、后缓落”的规律便意味着白酒发酵的正常。但是在这种模式下,酒醅温度的监控信息反馈具有滞后性,不能有效分析窖池内的发酵信息,从而直接影响下一轮的白酒发酵的产量。因此,根据完整的历史监测数据建立预测模型,对优化入窖配料方案、保障白酒发酵的高质高产具有重要意义。
4.1 样本集划分
有效地划分样本集可以提高模型的泛化能力,本文通过马氏距离进行异常样本剔除后共得到515组样本数据,再加上各自窖池发酵的入窖水分、入窖酸度、入窖淀粉和产量组成新的数据样本,数据特征为515*1444。按照校正集和验证集大约9:1的比例,将515个样本划分465个作为训练样本,50个作为测试样本,检验预测结果的真实性。
4.2 模型评估参数
采用预测均方根误差RMSEP和希尔不等系数TIC对模型性能进行评估。RMSE表示预测值与真实值之间的标准差,越小代表准确性越高;希尔不等系数是评价预测结果相对真实结果拟合误差的指标,值介于[0,1],越接近0,拟合误差越小。然而单一的RMSE并不能表明模型的实用价值,因此根据上述评价指标,对模型进行综合评价,其公式如下:

4.3 模型参数选取及预测结果对比
在预处理数据的基础上,采用XGBoost模型进行训练,具体参数如表3所示。

表3 单XGBoost模型参数
采用训练好的XGBoost模型对固态白酒发酵产量进行产量预测,具体结果如图1所示。为了更科学地评价预测方法的准确性,本文将XGBoost模型预测结果与BP、SVM、LSSVM、PSO-LSSVM模型预测结果进行比较。
PSO-LSSVM、LSSVM、SVM、BP预测的结果图分别如图2、图3、图4和图5所示。其中所有的测试数据与预测数据均已归一化处理。

图1 XGBoost模型白酒产量预测

图2 PSO-LSSVM模型白酒产量预测

图3 LSSVM模型白酒产量预测
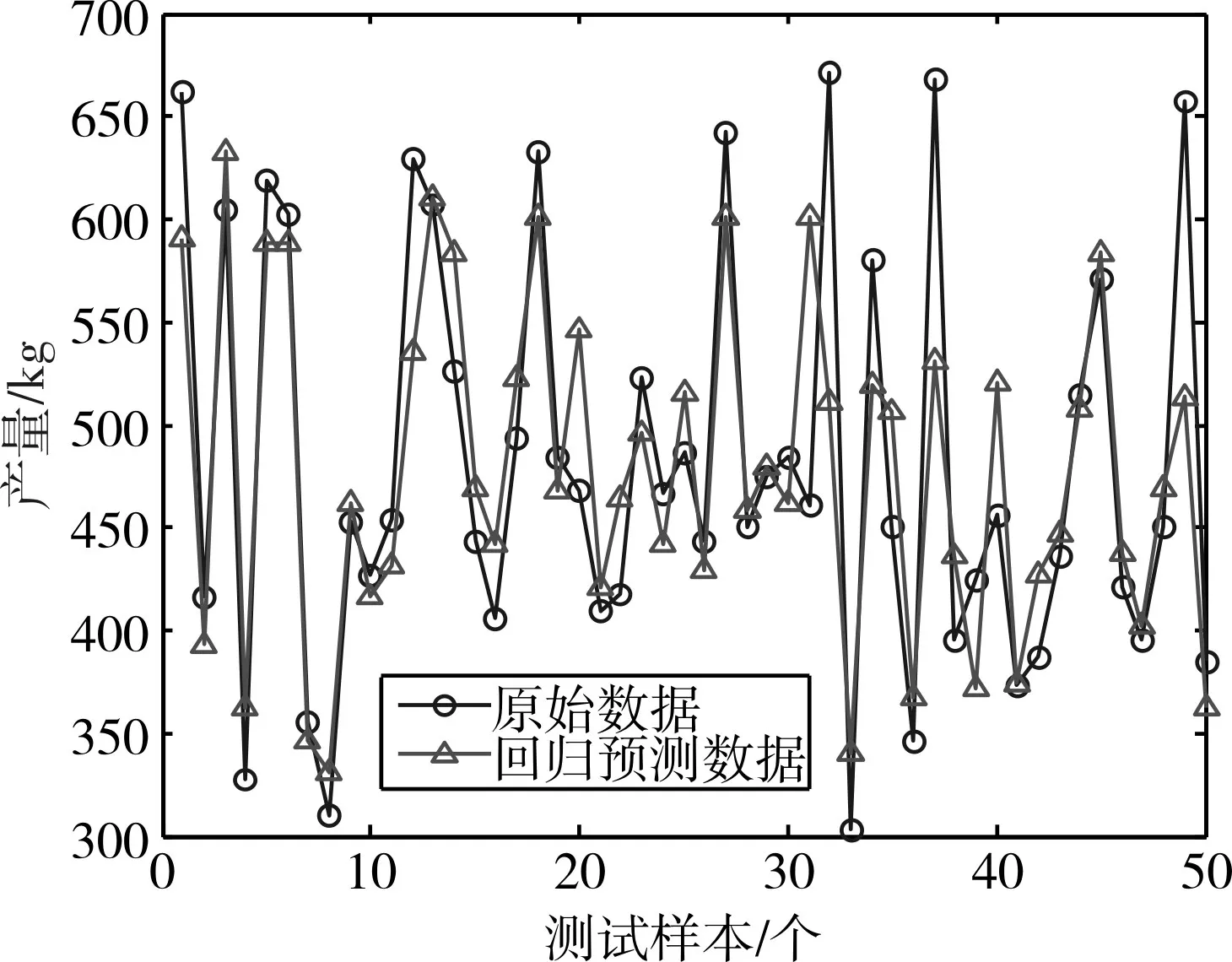
图4 SVM模型白酒产量预测

图5 BP模型白酒产量预测
为了更好地阅读各个算法的差别,本文使用均方根误差RMSE和希尔不等系数TIC两个参数对产量预测结果进行量化分析。两种评价指标从不同方面揭示了模型预测精度和拟合误差的程度。表4给出了五种算法在产量预测方面的对比。其中,XGBoost模型的均方根误差为41.2799,分别比PSO-LSSVM、LSSVM、SVM和BP低10.8%、18.3%、23%和27.3%。因此,XGBoost模型无论是在预测精度还是在拟合误差上都高于其他模型,表明XG⁃Boost模型预测的结果更加理想,在工程应用中更具优势。

表4 四种模型与预测结果对比
5 结语
本文将神经网络、支持向量机、最小二乘支持向量机、粒子群优化的最小二乘支持向量机以及XGBoost应用到固态白酒发酵的产量预测中,并且系统地比较了几种机器学习的有效性,并得出以下结论:
1)从数据本身来看,发酵过程中的酒醅温度时序数据、入窖淀粉、入窖酸度和入窖水分能够较好地反映固态白酒发酵的产量情况,利用其作为机器学习的输入特征可以较好地预测白酒产量,证明了机器学习在固态白酒发酵产量预测领域的有效性。
2)从预测结果和拟合误差来看,XGBoost模型的预测精度相对于其他模型而言,在拟合误差指数、均方根误差指数方面都有不同程度的提高,证明了XGBoost的预测能力的优越性。
3)从本文的实验结果来看,XGBoost方法在损失函数寻优过程中用到了一阶和二阶导数,并且加入了正则项来控制过拟合现象,提升了模型的预测精度。XGBoost预测能力要优于传统的机器学习算法,但由于该方法在白酒产量预测方面的研究较为匮乏,如何将XGBoost方法应用到实际生产过程中去将是本文后续的研究方向。
猜你喜欢
消费电子(2022年6期)2022-08-25
酿酒科技(2022年4期)2022-05-05
核安全(2022年2期)2022-05-05
中国饲料(2022年5期)2022-04-26
支点(2020年11期)2020-11-20
红领巾·探索(2020年8期)2020-10-26
特别文摘(2019年1期)2019-02-28
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
数学学习与研究(2017年3期)2017-03-09
