
大规模复杂场景下基于ResNet的回环检测技术研究
2020-07-13 12:56王红君郝金龙岳有军
计算机应用与软件 2020年7期
王红君 郝金龙 赵 辉,2 岳有军
1(天津市复杂系统控制理论及应用重点实验室 天津 300384)2(天津农学院 天津 300384)
0 引 言
近年来,同时定位与地图构建技术(Simultaneous Localization and Mapping,SLAM)在多个领域被推广应用,但仍有一些问题亟待解决。在大规模复杂场景下,SLAM系统面对复杂环境变化时精度和鲁棒性差是需要解决的主要问题,集中表现在关键帧提取困难、回环检测过程中回环位置难以确定、跟踪性能差等。其中,回环检测是移动机器人抑制累计误差的关键,通过对同一位置的重识别,SLAM系统可以对姿态和全局地图进行优化,提高系统的精度和稳定性。
在大规模复杂场景下,往往存在着摄像机视角大幅改变、地貌特征改变、大量移动物体、光照剧烈改变和天气季节改变等[1]环境条件的改变,限制了回环检测算法的使用。2013年Milford等提出的SeqSLAM是第一个大规模复杂场景下有一定效果的视觉定位系统。SeqSLAM通过当前图像序列来匹配已有最相近的图像序列,它关注的是图像序列的整体特征而不是单个图像的特征,其对季节变化拥有良好的应对能力。但SeqSLAM的准确性与图像序列的拍摄角度的一致性紧密相关[2],采用图像序列匹配也会使尾部图像序列无效[1],采用暴力匹配方式进行图像匹配使得计算成本随着场景规模激增。
2017年Siam等[3]提出的Fast-SeqSLAM是一种高效的SeqSLAM版本。Fast-SeqSLAM的核心是通过近似最近邻算法代替了SeqSLAM中暴力匹配的方式,从而在不降低精度的情况下降低了时间复杂度。
随着CNN的发展,AlexNet[4]、VGG[5]、GoogLeNet[6]和ResNet[7]等被用来进行图像特征的提取,解决了对象分类、场景识别和物体检测等识别问题。2017年国防科技大学的Bai等[8]提出了一种融合CNN与SeqSLAM的回环检测算法SeqCNNSLAM。该算法使用先前训练好的Places-CNN[9]的第3卷积层或第5池化层来进行图像特征的提取,再通过SeqSLAM来进行图像的序列。在Nordland和Gardens point等数据集上验证了SeqCNNSLAM不但有SeqSLAM应对环境季节变化的能力,还对视角变化具有鲁棒性。2018年徐建鹏等[10]提出基于Faster-RCNN神经网络回环检测的优化算法,该算法使用Faster-RCNN神经网络对图像序列进行检测,将获得的图像语义特征、像素位置及特征图等构建成二维语义特征向量图,根据二维语义特征向量图之间的相似度匹配得到初始回环,再经位姿验证获得最终回环结果。徐建鹏的基于Faster-RCNN神经网络回环检测的优化算法和SeqCNNSLAM的成功表明,将CNN与回环检测算法融合能够改善回环检测算法的精度和鲁棒性。
不同于SeqSLAM使用图像像素值当作图像特征,也不同于SeqCNNSLAM延续SeqSLAM使用图像序列进行匹配,本文采用ResNet对关键帧进行特征提取,使用词袋法进行单幅图片的特征匹配,采用弱监督的迁移训练方法来训练ResNet,提出一种基于深度残差网络和利用信息熵改进的局部聚合描述符向量的回环检测方法RIV-LCD。
1 相关理论
1.1 深度残差网络
深度残差网络(Deep Residual Network,ResNet)由He等[7]提出,解决了随着CNN网络层数加深,准确率下降的问题。ResNet在ILSVRC和COCO 2015上取得了五项第一,优于其他各种CNN模型在ImageNet数据集上的表现,TOP5误差仅为3.57%[7]。ResNet由若干个building block或bottleneck组成,其结构如图1所示。不同数量的building block或bottleneck组成了不同深度的ResNet。本文使用50层的ResNet来对图像进行特征提取。

图1 building block与bottleneck的结构图
1.2 局部聚合描述符向量
局部聚合描述符向量(VLAD)[12]通过计算图像特征描述子与其所属的聚类中心的差矢量来聚合图像特征。
如果给定N个D维的本地特征描述子{Xi}作为输入,K个聚类中心{Ck}作为VLAD的元素,VLAD的输出是一个D×K维的矩阵V。位置元素V(j,k)的计算公式如下:
(1)
式中:xi(j)和Ck(j)分别是第i个本地特征描述子和第k个聚类中心的第j维元素。
1.3 词袋法
词袋法(Bag-of-Words,BoW)[13]最早出现在自然语言处理和信息检索领域。该模型忽略文本的语法和语序等要素,将其仅仅看作是若干个词汇的集合。BoW使用一组无序的words来表达一段文字或一个文档。近年来,BoW模型也被广泛应用于图像检索。
2 ResNet的弱监督迁移训练
2.1 预训练
对于训练一个已知结构的卷积神经网络,最核心的问题是数据集的获取和损失函数的确定。由于回环检测数据集规模偏小,而ResNet的层数深权值参数多,大规模重复训练时,容易出现参数过拟合问题。采用关联数据集进行预训练十分重要,可以有效规避过拟合问题。在第一阶段,采用关联性强的场景识别大型数据集Places2[14]进行预训练;在Place2中,选取适合应用环境的图片对ResNet进行场景识别训练,使得ResNet可以获得提取特定环境图像特征的能力。对于第一阶段场景识别的训练,可以使用Softmax分类器和交叉熵损失函数。
(2)
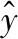
2.2 弱监督迁移训练
第二阶段弱监督迁移训练需要使用回环检测数据集,Nordlandsbanen数据集[15]比较适用。Nordlandsbanen数据集记录了特隆赫姆和博德之间729 km的铁路,在四个不同季节的同一条铁路线路一共拍摄了四次。如图2所示,图中依次是春夏秋冬四个季节在同一位置拍摄的图片。由于季节不同,四次拍摄拥有不同的光照(白天和夜晚)、地貌特征(植被雨雪覆盖等)和运动物体(乘客列车等)。可以有针对性地应用于训练CNN,使其在不同光照、气候和地表外貌条件下,获得对同一地点图像的共同特征提取能力。

图2 Nordlandsbanen 数据集
由于单输入网络不能直接输入两幅图片进行比较,无法进行图像匹配任务训练,所以第二阶段采用弱监督的迁移训练方式进行训练。其中,选取损失函数的关键是要体现出图片之间的差异,用来监督训练,这种关联变量因数据集的特征而定,可以是GPS坐标,也可以是图像在序列中的位置。在Nordlandsbanen数据集上,用于弱监督训练更合适的变量是图像在序列中的位置,因为该数据集四个视频流的每一帧都经过对齐,可以使用Triplet损失函数[16]进行弱监督迁移训练。Triplet损失函数如下:
(3)
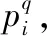
2.3 训练流程
两个阶段的训练流程如图3所示。

图3 训练流程示意图
3 信息熵加权VLAD
由于属于每一个聚类中心的本地特征描述子所包含的信息量不同,可以设置一个权重参数ak(xi)当作(xi(j)-Ck(j))的权值[17]来描述每一个类本地特征描述子间的关系:
(4)
可以用信息熵度量属于每一个聚类中心的本地特征描述子所包含的信息量。根据香农给出的信息熵定义公式[18],对于任意一个随机变量X,其信息熵定义如下(单位为比特(bit)):

(5)
仿照式(5),本地特征描述子的信息熵定义如下:
(6)
式中:c为本地特征描述子聚类中心个数;pk为第k类本地特征描述子在所有本地特征描述子中所占的比例,即第k类的先验概率。该信息熵反映了集合X中的本地特征描述子平衡分布的期望,也可以度量X中包含信息量的大小。
将特征矩阵V信息熵的值Entropy(X)赋给ak(xi),可以得到:
(7)
ResNet提取图像本地特征和信息熵加权VLAD,产生本地特征描述子的流程示意图如图4所示。
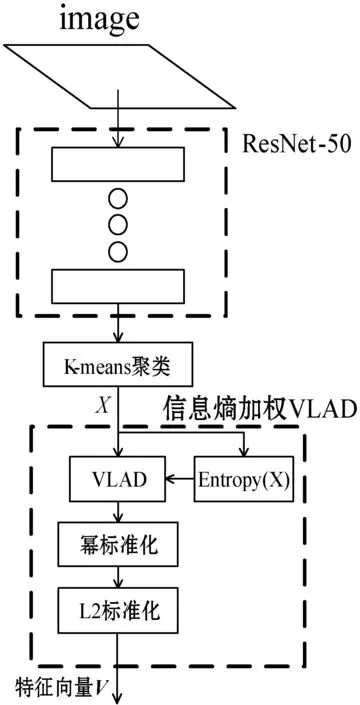
图4 ResNet与信息熵加权VLAD提取特征流程示意图
4.1 基于BoW的特征向量匹配
使用BoW时,要通过K-means聚类算法聚类出本地特征描述子的K聚类中心,得到一个字典。匹配时,先将离线数据库图片以及在线数据库图片的本地特征描述子投射到字典的空间中,得到图片本地特征描述子相对应的words分布;然后再以同样的方法,得到待匹配目标图片的本地特征描述子相对应的words分布;最后通过比较这些words分布的相似性,得到TOP1候选结果。所使用的BoW的算法流程如图5所示。
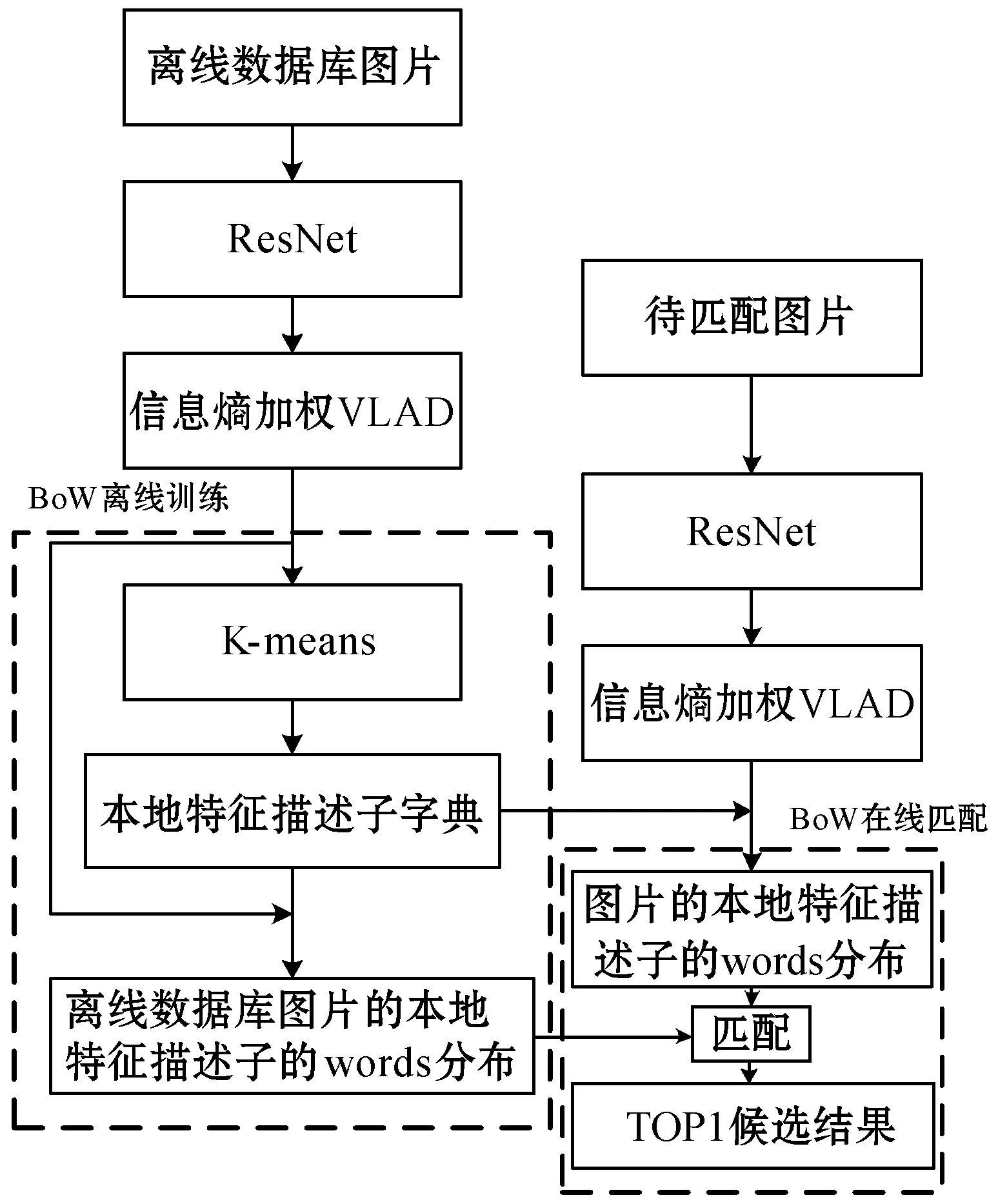
图5 BoW的离线训练与在线匹配流程示意图
5 实验与分析
5.1 实验平台与测试集
实验在一台图像处理服务器上进行,该服务器配备为64 GB运行内存、48个2.20 GHz的Intel Xeon CPU以及2张12 GB显存的GeForce GTX 1080Ti显卡。在该实验平台上搭建深度学习环境Anaconda3以及Tensorflow进行实验。在Nordlandsbanen数据集上等间距按顺序在每个季节图像序列中抽取出33 626幅图片,四个季节共134 504幅图片作为测试集。
5.2 可行性验证实验
在Nordlandsbanen数据集的测试集上进行测试,通过春天图片匹配夏天相同拍摄位置的图片,得到可行性验证准确率召回率曲线,如图6所示。其中:“ResNet+信息熵加权VLAD+BoW”为RIV-LCD算法得到的准确率召回率曲线;“ResNet+无权值VLAD+BoW”为使用没有权值原始的VLAD得到的准确率召回率曲线;“ResNet+BoW”为没有使用VLAD得到的准确率召回率曲线。

图6 可行性验证precision-recall曲线
可以看出,使用VLAD处理后的图像特征匹配时,可以明显提高召回图像的匹配准确率,经过信息熵加权VLAD处理后的图像特征匹配时,有更高的准确率。
在Nordlandsbanen数据集的测试集上进行测试,通过春天的图片匹配其他季节相同拍摄位置的图片,结果如图7所示。可以看出在光照、气候、地表外貌大幅变化时,RIV-LCD仍可以完成回环检测,证明该算法对环境条件剧烈变化具有良好的鲁棒性。而错误匹配主要存在于两种情况:地貌特征十分相似和隧道内弱光照的情况,分别如图8、图9所示。

图7 RIV-LCD准确匹配到的图像

图8 地貌相似时RIV-LCD匹配到的错误图像

图9 隧道内弱光照时RIV-LCD匹配到的错误图像
5.3 对比实验
在Nordlandsbanen数据集上进行测试,使用秋天的图像来匹配夏天的图像,测试结果如图10所示。“RIV-LCD”为RIV-LCD算法得到的准确率召回率曲线,同样“SeqSLAM”、“Fast-SeqSlam”和“CNN-SeqSlam”分别为SeqSLAM、Fast-SeqSlam和CNN-SeqSlam算法得到的准确率召回率曲线。

图10 在Nordlandsbanen数据集上得到的precision-recall曲线
对比图10中四种回环检测算法准确率召回率曲线可以看出,随着召回率的升高,RIV-LCD的准确率下降最缓慢,在获得最大召回率时准确率为84.8%。相比之下,SeqSLAM的准确率下降最快,在获得最大召回率时准确率为55.5%。同样Fast-SeqSlam和CNN-SeqSlam的准确率下降比RIV-LCD快,在获得最大召回率时准确率分别为69.0%和71.3%。这些都说明本文的RIV-LCD在大规模复杂场景下精确度和鲁棒性更高。
6 结 语
在大规模复杂场景下,为解决现有部分回环检测算法无法使用的问题,本文提出了一种新的回环检测算法RIV-LCD。实验表明:大规模复杂场景下RIV-LCD在面对光照、气候、地表外貌大幅变化时,仍然可以准确地进行回环检测;在同样的大规模复杂场景下,RIV-LCD比SeqSLAM、Fast-SeqSlam和CNN-SeqSlam拥有更高的准确率和鲁棒性。
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
中学生数理化·八年级物理人教版(2020年6期)2020-10-30
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
南北桥(2017年7期)2017-04-21
中国水运(2016年11期)2017-01-04
电脑知识与技术(2016年27期)2016-12-15
