
基于运动韦伯和局部约束的稀疏表示暴力检测
2020-07-13 12:56:06李建新
计算机应用与软件 2020年7期
李建新 张 涛
1(东莞职业技术学院计算机工程系 广东 东莞 523808)2(江南大学物联网学院 江苏 无锡 214000)
0 引 言
近年来,越来越多的研究者们开始关注如何准确识别视频中的目标和事件[1-3]。暴力行为严重危害到了国家和人民的安全,故各大公共区域都安装了视频监控设备。计算机视觉技术的发展使人们意识到,可以通过计算机视觉来获取环境的一切信息[4],包括对视频监控中的暴力行为进行检测并及时发出警报。这样不仅可以节省大量的人力物力财力,而且可以解决传统视频监控的滞后问题。
早期,Nam等[5]认为人们在火灾现场杂乱的尖叫声和跑步声等具有明显的特征,可以根据这些特征来进行暴力检测,据此提出了一种基于声音特征的暴力检测算法。近年来,基于时空兴趣点的方法[6-7]被提出用来进行暴力行为检测。该算法从视频序列帧中提取出兴趣点,然后使用词袋模型(BoW)的框架进行暴力行为检测。
迄今为止,人们开展了很多基于视频的异常检测工作[8-11]。最近几年,一些研究人员开始尝试用基于深度神经网络的算法对暴力行为进行检测[26-28],但是深度神经网络在构建暴力特征时比较困难,因为大部分的深度学习算法模型都是针对图像构建的,忽略了视频的时序特性,无法很好地描述运动信息,暴力行为检测效率不高,而且操作步骤繁琐、特征提取的时间消耗高、不能高效执行。本文对暴力行为的检测主要集中在兴趣点的检测和特征表达上。Chen等[12]提出了一种用于人脸检测的韦伯局部描述子(Weber Local Descriptor , WLD),Wang等[13]证明了它具有光照不变性的特征。WLD陈述了这样一个物理现象:若外界信号的变化是原始信号的一定比率,这个刺激的信号就是值得注意的;如果小于这个比率,就将该刺激信号作为当前背景。WLD是用于检测图像中的兴趣点,而本文所研究的暴力检测要比人脸识别复杂得多,需要能够提供足够的运动信息的特征,因此,本文提出一种新的描述子——运动韦伯描述子(MoWLD)用于检测视频中的兴趣点。
现如今,基于稀疏分类的思想被研究者们应用于行为识别领域[14-16]。许多的研究者开始使用基于稀疏表达的分类机制用于人脸识别,但是如何学习稀疏的数据并且具有高判别性的词典仍然是一大难题。
1 算法设计
本文提出MoWLD 和稀疏分类相结合的方式对视频中的暴力行为进行检测,系统框架如图1所示。首先,从输入视频中用高斯滤波去除一些噪声。然后,再提取出MoWLD 特征。接着,提出改进的稀疏模型用于特定类字典的学习。在这个模型里面,表达约束项和系数调整项被用于字典的学习,使得学习的词典具备更强的判别能力。表达约束项可以确保带着同一类标签的训练样本特定类词典具备更好的重建能力。系数调整项反映了不同类标签的训练样本的特定类的子词典有较弱的重建能力,可以确保不同类的字典表达尽可能独立。因此两个增加的项可以使得模型具备更强的判别能力。最后,相应的分类机制被提出用来对视频中的暴力行为特征进行分类。
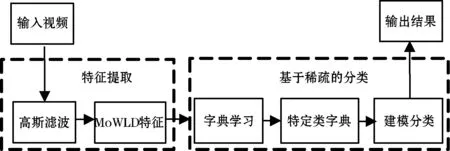
图1 提出的算法框架
1.1 运动韦伯特征提取
为了对暴力行为进行更好的识别,本文设计了一种有效的特征表达的方法,使它尽可能地包含更多的兴趣点信息。
1.1.1韦伯局部描述子(WLD)
Chen等[12]提出的韦伯局部描述子(WLD)主要包括差分幅值和差分方向两个变量。
差分幅值:
(1)
式中:反正切函数用于防止输出结果过大,可以抑制噪声的边缘效应;xc代表中间的像素,xi(i=0,1,…,p-1)代表邻域的像素;p是邻域的像素的个数;α用来调整当前像素与周围像素值的大小差别。
差分方向:
(2)
式中:x1-x5和x3-x7分别代表xc像素在垂直和水平方向上的两个邻域像素值的差。
文献[20]中,ξm和ξo分别被线性地量化为T个主要的差分幅值和方向。本文中,T为12。
WLD用当前像素和它的邻域的像素灰度差来衡量当前像素的变化程度,这种方式与人们获取世界信息的方式相符。Wang等[13]证明了差分幅值和差分方向具有光照不变性的特性。二维的WLD特征直方图的每一行对应主要的差分幅值ξm(xc),每一列对应主要的差分方向ξo(xc)[12,17]。
1.1.2改进的WLD
旋转不变性是两个关键点相似性度量的标准,因此对于图像的纹理特征是非常重要的。但是原始的WLD特征并不是旋转不变性的,因此本文提出改进的WLD直方图,通过聚合邻域的WLD直方图和使WLD直方图与它们的主方向对齐的方式重构WLD直方图。具体步骤如下:
1) 首先对输入图像用高斯滤波去除一些噪声,根据式(1)和式(2),计算处理后的图像中的每一个区域内的像素的差分幅值和差分方向。
2) 运用文献[17]中的非线性的量化方法,将差分方向量化为12个主方向,每一个方向覆盖30度,形成一个具有12个方向的差分方向直方图。
3) 将从局部邻域内计算得到的韦伯梯度的直方图累加到局部纹理特征中。
4) 邻域窗口内的韦伯梯度方向,根据当前点的韦伯幅值和它中心点的距离加权后,增加到当前直方图中。得到一个主方向后,其他邻域内的所有韦伯幅值都将被旋转到这个主方向上,从而达到旋转不变性的特性。
改进后的WLD直方图的构建如图2所示。输入图像中的某一邻域内的像素分为4×4块,每块包含3×3个像素。这样得到的WLD直方图有4×4×12=192维的向量。
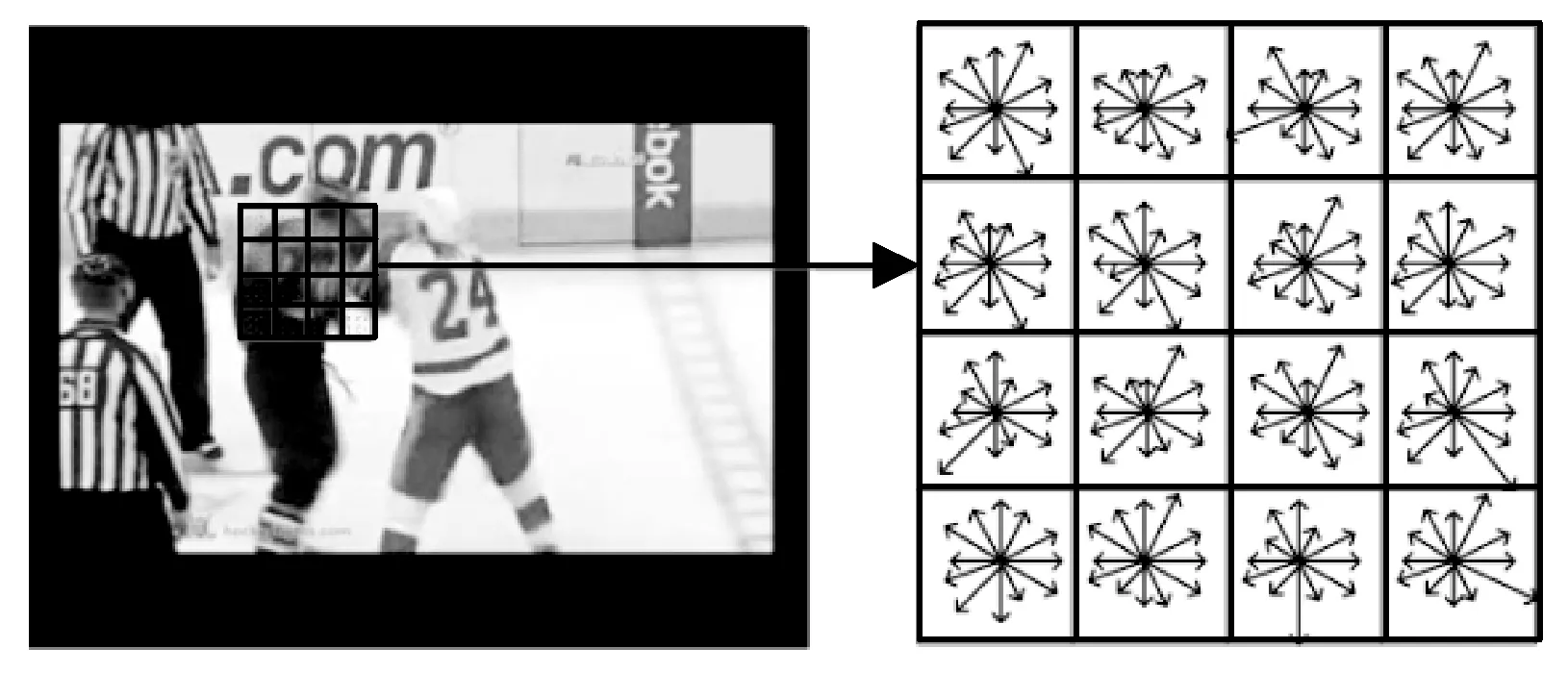
图2 改进的WLD直方图的构建过程
改进后的WLD只是对静态图像的处理,在暴力检测时,如果使用改进后的WLD特征进行特征描述,会产生很多与行为没有关系的兴趣点区域,对暴力检测结果产生很大的影响。因此本文提出了运动韦伯描述子(MoWLD),它由两部分构成:累加的WLD直方图,用来描述图像的表观空间;累加的光流直方图,用来刻画时间上的运动特征。此外,在同一位置的不同大小的子图像能够产生不同的特征向量,只有多尺度的图像采样方法可以解决这个问题,因此本文可以采用基于P个像素的正方形对称的邻域的集合计算得到的多尺度的WLD特征分析算法[12]。
1.1.3运动韦伯描述子(MoWLD)
本文提出的运动韦伯描述子(MoWLD)采用基于光流的方法对运动行为进行描述。基于光流的算法根据连续视频帧内的某一个图像区域在时间上的差异来确定运动区域。与基于视频立方体和时空卷的方法[8,18]不同,基于光流的方法能够明确地获取运动的幅值和方向,直接对行为特征进行描述。为了将运动特征增加到我们改进的WLD特征中去,采用同样的方法,将光流区域分割为4×4个网格,每个网格包含3×3个像素,使用同构建改进的WLD相同的方法,如此便得到了运动韦伯描述子(MoWLD)。
MoWLD将WLD和光流融合到一起来描述视频中不同帧之间的运动信息。同WLD特征一样,光流检测不同帧之间的运动幅值和方向特征,因此我们也要构建光流的直方图。构建光流直方图的过程与构建改进的WLD直方图过程类似。首先得到一个有4×4×12=192维的向量的光流直方图。为了增加时间上的上下文信息而达到更高的鲁棒性,再增加前三帧图像到当前描述子上,最终得到一个有4×4×192=3 072维数的特征向量的光流直方图。
这里我们直接将光流直方图融入到WLD直方图中形成MoWLD描述子,并不对光流方向进行调整。图3给出了MoWLD描述子的构建过程。提取连续四帧图像用于计算WLD和光流的直方图,具有足够运动量的候选兴趣点被认为是MoWLD的兴趣点,累加起来就是整个MoWLD特征。
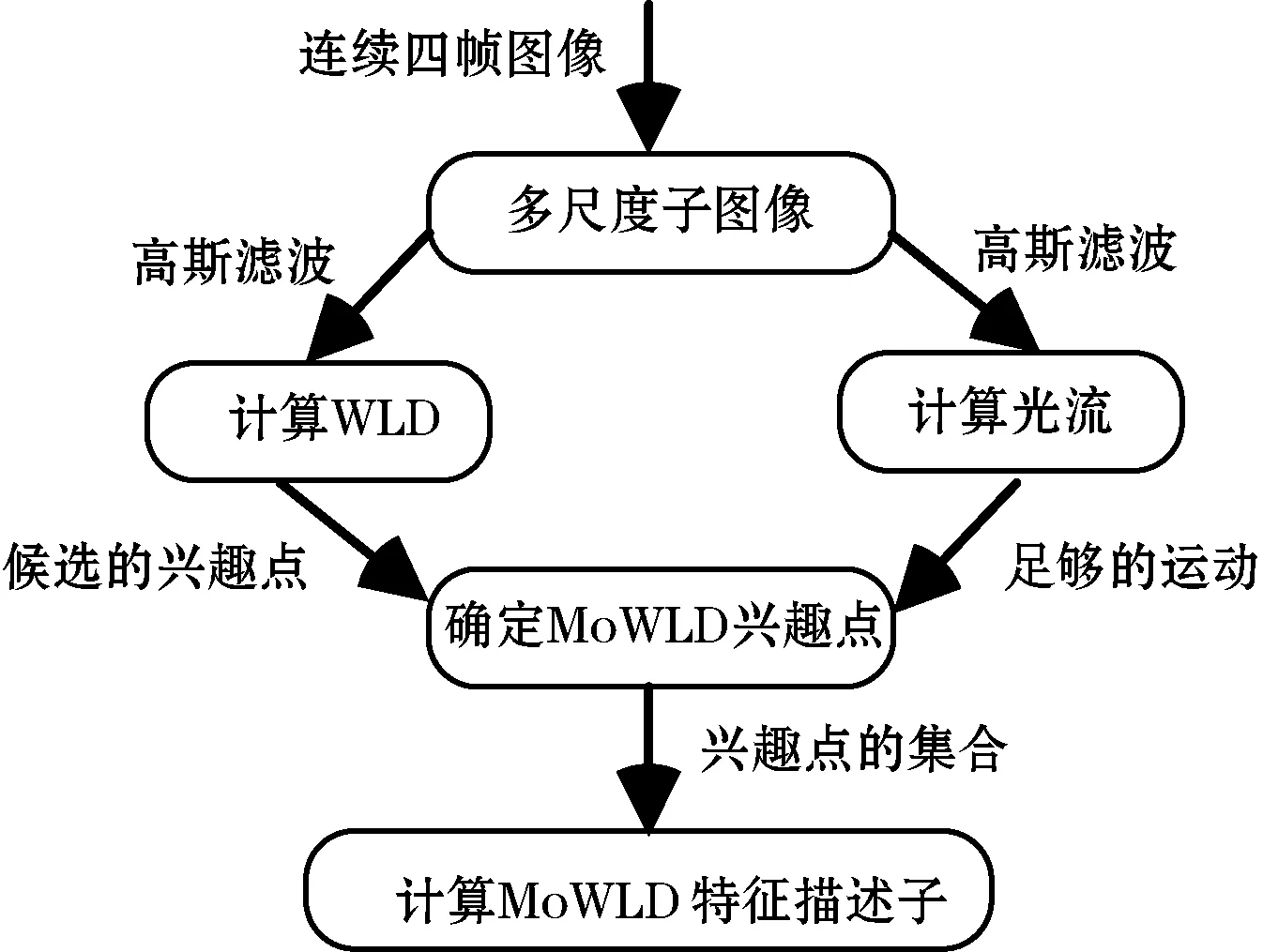
图3 MoWLD描述子的构建过程
1.1.4多尺度的MoWLD
本文采用多尺度的WLD特征分析的方法[12],多尺度的光流的计算就是根据WLD的尺度分别进行统计的。多尺度是定义在P个像素的正方形对称区域内,以(2R+1)为正方形的边的长度的尺度上。其中P代表邻域内的像素的个数,而R则确定了算子的空间分辨率。图4给出了3个尺度上的WLD算子。
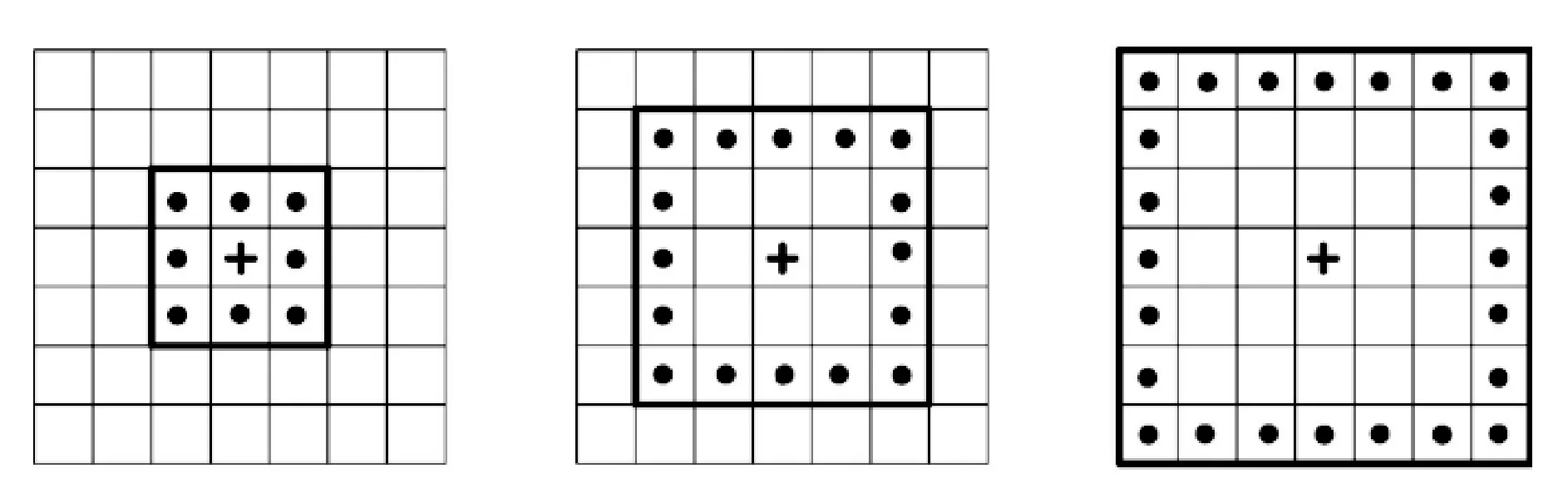
图4 多尺度WLD下的正方形对称区域图示
由于本文提出的MoWLD是基于WLD和光流,所以它的抗遮挡和变形的能力都比较强。而且,当一个兴趣点被检测到的时候,得到WLD的一个主方向,在这个邻域内的所有的梯度方向根据这个主方向做相应的旋转,从而使得MoWLD具有旋转不变性的特性。
为了减少冗余信息,提高检测的速度,我们采用基于核密度估计(KDE)[19]的特征降维方式,将MoWLD特征向量的维数降至550维。下面用降维后的MoWLD特征作为输入特征。
1.2 稀疏分类模型和字典学习
1.2.1SRC模型
给定K个物体的类,令D=[A1,A2,…,AK]代表由训练样本组成的字典,其中Ai是i类的训练样本的子集。令y代表测试的样本。传统的SRC分类算法如下:
1) 标准化每一个训练样本Ai,i=1,2,…,K。
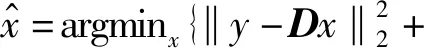
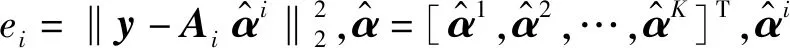
1.2.2提出的模型
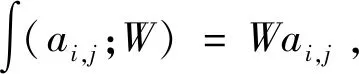
(3)
s.t. ‖dn‖2≤1,∀n
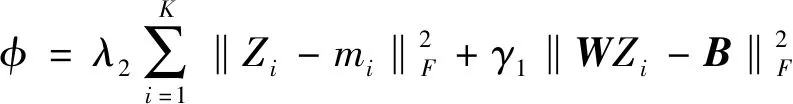
1.2.3特定类的字典学习
不同行为类型的MoWLD特征不同,因此本文采取特定类的字典学习方法。本文的稀疏分类模型融入了表达约束项和系数调整项,因而具有很好的分类效果。虽然式(3)是非凸的,但是当其他两个变量固定的时候,对求解式(3)中的D、W或Z变量就是凸的。因此我们可以将问题分割成三个子问题:当D和W固定时更新Z,当D和Z固定时更新W,当W和Z固定时更新D。如此便可以得到式(3)的解。
1) 当D和W固定时更新Z:此时,求解式(3)的问题就变为求解Z=[Z1,Z2,…,ZK]的问题。当计算得到Zi后,所有的Zj(j≠i)是固定的。式(3)可以降解为:
(4)
针对每一个Zi,方程可以进一步约束为:
(5)
计算得到Zi为:
Zi={DTD+(λ1+λ2)I+
γ1WTW}-1(DTai+λ2mi+γ1WTbi)
(6)
2) 当D和Z固定时更新W:原问题可以约束为:
(7)
式(7)可以变形为:
(8)
(9)
用最小二乘法求解得到如下结果:
(10)
3) 当W和Z固定时更新D:同更新Z的方法一样,当计算得到Di后,所有的Dj(j≠i)是固定的。式(3)可以降解为:
(11)
s.t.‖dn‖2=1,∀n
可以利用文献[21]中的拉格朗日对偶方法来求解式(1)。
至此,式(3)求解完毕。
1.2.4分类机制
学习过字典D后,我们需要对测试样本y进行处理,并进行分类。下面是我们提出的分类模型:
(12)

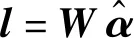
(13)
通过用一个简单的线性预测分类器去估计向量l的类,类别索引对应向量l中的最大的元素。
图5显示了本文提出的稀疏分类模型相比于原始的SRC模型的优势。在所用时间方面,SRC算法比较稳定。本文算法由于要计算同类之间的相似性矩阵,所用时间会随着样本数增加而增加,但是其成功地将所提出模型的算法的计算复杂度降低了。
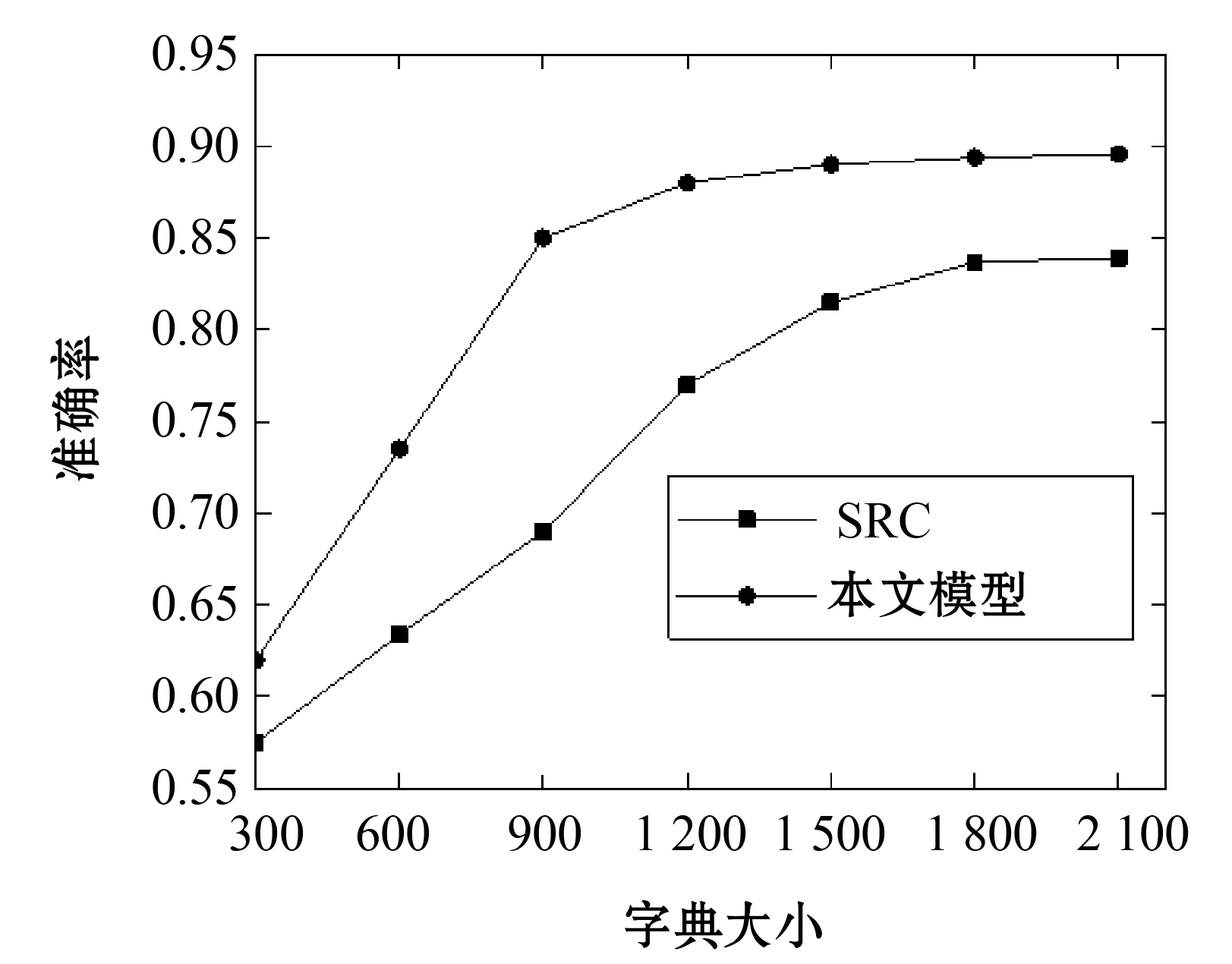
图5 不同字典大小下的表现性比较
2 实验结果与分析
为了验证本文提出的算法的有效性和优越性,我们在BEHAVE数据集[22]和Crowd Violence数据集[23]这两个数据集上对算法进行了测试,并且同当前比较流行的算法进行了比较。在上面提出的稀疏分类模型里,在字典学习阶段,我们设置λ1=0.005、λ2=3、γ1=1、γ2=0.1,在分类机制阶段,设置γ=0.01。在每一个数据集上使用5个交叉验证,以平均预测率(ACC)±标准差(SD)和ROC曲线的面积(AUC)两种方式显示结果。
2.1 在BEHAVE数据集上的测试结果
BEHAVE数据集涵盖各种场景下的超过200 000帧图像,包括走路,奔跑,追逐和打架等行为。我们将这些数据分为带有各种行为的片段,每个片段至少包含上百帧的图像。这里我们将每个片段标记为暴力或者非暴力,然后从中随机选取80个片段用来进行暴力行为检测,这80个片段分为20个暴力片段和60个非暴力片段。我们将本文的算法同当前比较流行的算法进行了比较,这些算法有HOG、HOF、HNF(HOG和HOF的结合)、ViF[23]、基于RVD的算法[24]、基于外貌和运动的深度神经网络(AMDN)[25]、MoSIFT算法[12]以及原始的SRC思想[20]。各种算法在BEHAVE数据集上的比较结果如表1所示。

表1 在BEHAVE数据集上的检测结果
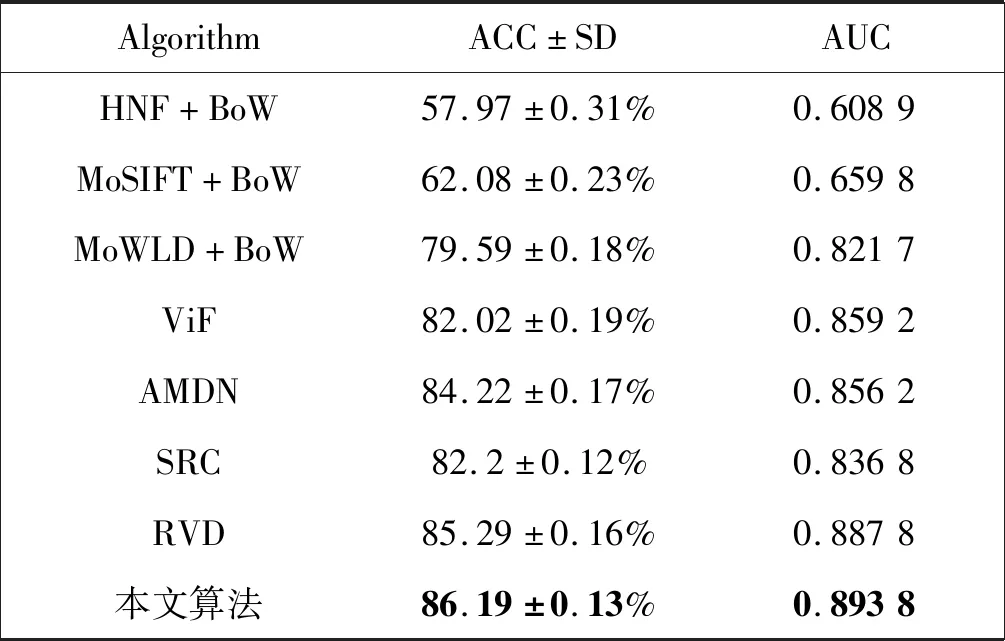
续表1
实验中字典被固定在1 800,由表中数据可以看出,本文提出的基于稀疏分类和运动韦伯特征相结合的算法战胜了其他所有的比较流行的算法。而且本文提出的MoWLD描述子相比于HOG、HOF和HNF具有更强的判别性。从表中数据也可以看出,基于RVD[24]方法的结果仅次于本文提出的算法,这是因为它在前期采用光流的高斯模型去除了大量的噪声,为后期的高准确率识别提供了保障。AMDN方法的表现性非常稳定,这是因为它采用深度神经网络自动地表达学习特征,但是这种方法因为使用了光流作为输入图像的特征,所以表现性并不是最好的。此外,BEHAVE数据集上包含了很多类似于打架的暴力行为,所以传统的SRC算法在这个数据集上的表现也不理想。
2.2 在Crowd Violence数据集上的测试结果
Crowd Violence数据集中的所有数据都来源于优酷,是专门为检测群体暴力行为而搜集的,所以它包含了很多的拥挤场景。Crowd Violence数据集的246个视频片段中,一半是暴力片段,一半是正常片段。我们将整个数据集分为5个集合来进行交叉验证。同样将本文提出的算法与当前比较流行的算法进行比较,各种算法在Crowd Violence数据集上的比较结果如表2所示。
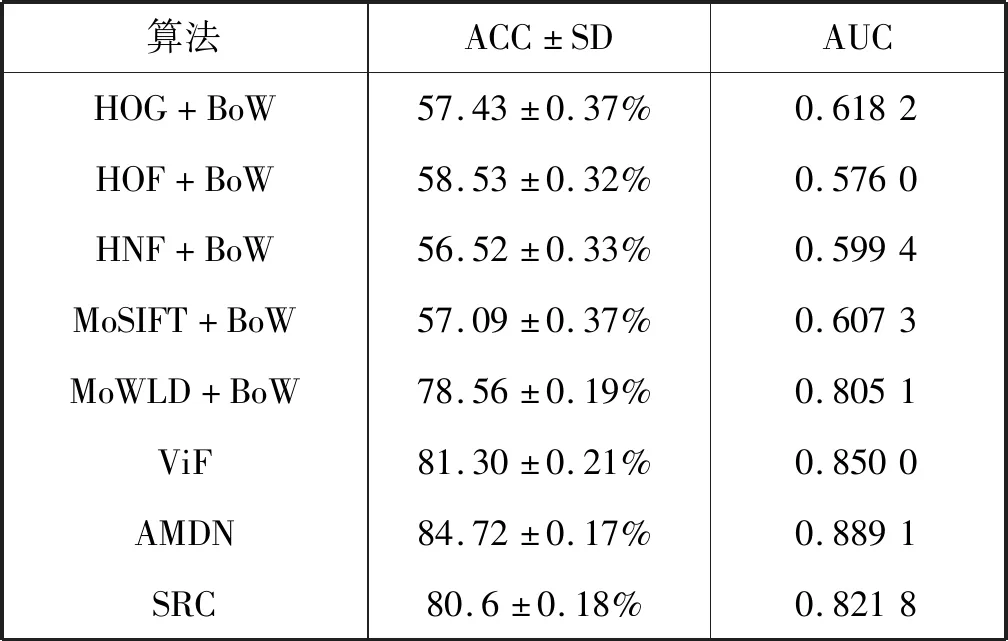
表2 在Crowd Violence数据集上的检测结果

续表2
实验中,仍然将字典大小固定在1 800。从表中的数据可以看出,RVD的表现性相比于之前下降了,这是因为Crowd Violence数据集中包含了很多的拥挤场景。AMDN在Crowd Violence数据集上的表现性非常稳定,但是由于光流噪声的引入,它的表现性并不是最好的。
原始的SRC模型比较简单,无法对场景中复杂的信息进行判别,所以这里SRC的表现性又下降了。最重要的是,从表中信息可以看出,本文提出的算法仍然是所有算法中表现性最好的。这是因为这种算法中的MoWLD描述子相比于HOG、HOF和HNF具有更强的判别性。而且,本文提出的稀疏分类模型中的表达约束项和系数调整项也使得本文的算法具有更强的判别性。同时也说明了本文提出的基于稀疏分类和运动韦伯特征相结合的算法即使在拥挤的场景下也具有很好的识别性。
3 结 语
针对视频监控场景中的暴力行为,本文提出了一种基于稀疏分类和运动韦伯特征相结合的暴力检测算法。本文提出的运动韦伯描述子(MoWLD)充分结合了SIFT特征计算梯度直方图方面的优势和LBP在计算有效性的特点,它既是对图像纹理特征的描述,也是对时间上的运动特征的刻画。改进的稀疏分类模型引入了表达约束项和稀疏调整项,表达约束项可以确保带着同一类标签的训练样本特定类词典具备更好的重建能力。系数调整项反映了不同类标签的训练样本的特定类的子词典有较弱的重建能力,可以确保不同类的字典表达尽可能的独立,因而使得算法具有更强的判别性。大量的实验结果证明本文提出的用于暴力检测的算法具有很强的判别性,提出的融合有监督的特定字典学习的稀疏模型在分类上也是非常有效的。同时本文提出的基于稀疏分类和运动韦伯特征相结合的算法即使在拥挤的场景下也具有很好的识别性。
猜你喜欢
导航定位学报(2022年5期)2022-10-13 08:35:28
青少年科技博览(中学版)(2022年6期)2022-08-31 09:04:02
阅读(低年级)(2021年5期)2021-08-23 02:03:02
小哥白尼(神奇星球)(2021年12期)2021-03-08 09:22:44
电光与控制(2018年10期)2018-10-13 08:19:00
戏剧之家(2016年6期)2016-04-16 13:01:01
妇女生活(2015年6期)2015-07-13 06:17:20
太空探索(2014年4期)2014-07-19 10:08:58
中国铁道科学(2014年6期)2014-06-21 06:35:32
海外英语(2013年5期)2013-08-27 09:39:15
