
基于人眼感知的无参考色调映射图像质量评价
2020-07-14 02:51:12马华林张立燕
计算机应用与软件 2020年7期
马华林 张立燕
1(浙江工商职业技术学院 浙江 宁波 315012)2(宁波大学信息科学与工程学院 浙江 宁波 315012)
0 引 言
HDR图像相比低动态范围(Low Dynamic Range,LDR)图像能够表示更大的亮度范围,其亮度范围大约是10-4cd/m2~105cd/m2[1-2]。LDR图像能表示的动态范围不超过3个数量级,但人类视觉系统在真实场景中可以接受的动态范围可以达到6个数量级。因此,HDR图像对用户来说感受更真实更有吸引力。随着成像和计算机图形学技术的发展,HDR图像的获得越来越容易。然而,HDR显示设备比较昂贵[3],超出了普通消费者的承受范围。为了解决这个问题,产业界和学术界开发了许多色调映射算子[4],TMO能够把HDR图像转换成LDR图像,转换后的LDR图像被称为色调映射图像(Tone-mapped Image,TMI)。由于TMI相对HDR图像缩小了动态范围,不可避免地产生失真,例如亮度信息丢失、结构信息丢失、不自然的颜色等。针对一个HDR图像,不同的TMO产生的效果不一样。因此,TMI质量评价对于选择合适的TMO和改进TMO本身具有重要的研究意义。
TMI质量评价分为主观质量评价和客观质量评价,而早期的TMO性能评价主要采用主观质量评价。因为人眼是TMI的最终接受者,主观质量评分具有准确性高的特点。然而,主观质量评价[5]具有三方面的缺点:主观质量评价比较耗时费力,需要昂贵的HDR显示器和多个测试人员多次实验;主观质量不能嵌入到图像处理系统来改进TMO;主观评价由于人为的一些不确定因素导致评价的误差,例如对于主观评分相近的两个图像人眼也很难判断哪个图像更好一点。传统的客观质量评价方法假定参考图像和测试图像具有相同的动态范围,因此传统的客观质量评价方法不能直接评价TMI。
近年来,全参考TMI质量评价算法取得了丰硕的成果。Yeganeh等[5]是最先关注TMI质量评价的学者之一。他们首次建立了色调映射图像数据库(Tone-mapped Image Database,TMID),可以下载并用于评价TMI质量评价算法的性能。同时,他们提出了一种全参考TMI质量评价方法(Tone Mapped Image Quality Index,TMQI)。这个方法的基本思想是高质量的TMI不但要保护HDR图像的结构信息,还要保留图像的自然场景统计特性(Natural Scene Statistics,NSS)。Nafchi等[6]基于图像的局部相位信息提出了FSITM方法,该方法考虑了图像的颜色信息,但没有考虑图像的自然度。Kundu等[7]针对TMQI均匀池化的缺点,在TMQI基础上加入了视觉注意力模型,运用感知池化策略提升质量评价算法的性能。Xie等[8]使用字典学习技术在稀疏域提取局部结构相似度和全局自然度,合并这两个特征提出了一种全参考质量评价算法SMTI。鉴于色调映射图像失真类型多的特点,Hadizadeh等[9]从结构保真度、自然度、亮度、颜色等方面提取了八类特征来评价TMI质量。
无参考TMI质量评价相对全参考TMI质量评价具有更强的实用性。由于TMI失真通常不会出现模糊、块效应等类型的失真,传统的无参考质量评价算法不适合评价TMI。Gu等[10]结合信息量、结构、自然度三方面提出了BTMQI算法,该算法取得了很好的效果,但没有考虑TMI的颜色失真。Yue等[11]模拟人脑对颜色信息的处理过程来评价TMI质量,从简单细胞的响应中提取纹理信息特征,从复杂细胞的响应中提取结构和纹理信息。本文提出一种基于人眼感知的无参考色调映射图像质量评价方法,主要贡献如下:
(1) 首次采用聚类算法针对TMI高亮区、低暗区曝光异常的特点把色调映射图像分成暗区、中间区、亮区,根据物理亮度距离与聚类中心亮度值的特性,优化了使用K-means聚类对TMI分区的方法。相对不分区的色调映射图像质量评价方法显著提高算法性能。
(2) 在色调映射图像质量评价研究中首次使用非负矩阵分解方法,根据TMI灰度图像非负矩阵分解获得的系数特性,提出了一种新的图像显著性区域识别方法。
(3) 结合亮度和颜色两种信息来提取图像自然度,发现了亮度自然度和颜色自然度的互补性,相对单独使用颜色自然度或者亮度自然度显著提高了算法的SROCC指标。
1 评价方法设计
根据Weber定律,人眼能感受到的最小亮度变化应满足ΔS=KS,其中K为常量,当亮度值S相近时,对应的能被人眼感知的最小亮度变化范围ΔS也相近,按照祖母神经元理论人眼感受到亮度变化的原因是由一组感受S+ΔS亮度的神经细胞兴奋所致。因此,聚集亮度感知变化范围相似的细胞为同一个类别,分别分析每一类细胞感知到的图像质量。本文首先把TMI转换成灰度图像,然后使用K-means聚类算法把灰度图像按照亮度值进行聚类,每一类对应一个区域,在多个区域分别提取特征来评价图像质量。
根据TVI曲线人眼视觉系统具有5个亮度适应等级[12],因此分别把色调映射图像分成3个区域、4个区域、5个区域在TMID[5]图像数据库上进行实验。例如对于三个区域的划分,首先把色调映射图像用K-means聚类算法分成3个区域,分别提取每个区域的信息熵特征,然后用SVM聚合三个信息熵特征预测图像质量评分。选取Pearson线性相关系数(Pearson Linear Correlation Coefficient,PLCC)、Spearman秩相关系数(Spearman Rank-order Correlation Coefficient,SROCC)作为评价指标分别评价图像预测值与主观评分的准确性和一致性。
如表1所示,把色调映射图像划分成三个区域时,信息熵特征的性能指标是最好的,这三个区域分别是亮区、中间区、暗区。色调映射过程会缩小TMI的动态范围,导致TMI图像的高亮区和低暗区细节丢失,从而影响TMI的质量。如图1所示,亮区包含了曝光过度的区域(高亮区域),同理,对于曝光不足的图像,暗区包含低暗区,因此三个区域的划分体现了TMI图像的特性。
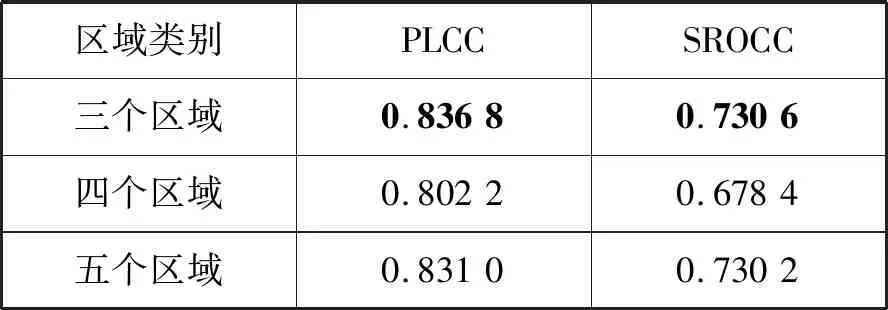
表1 不同区域划分方法信息熵特征的性能指标

(a) 灰度图 (b) 分成三个区域后图1 TMID数据库中的一幅图
K-means聚类时只考虑像素点到聚类中心的距离来确定像素点的类别,没有考虑人眼对亮度感知的非线性特性。设聚类中心亮度值为S1,感知亮度为P1,某个像素点像素亮度值为S2,感知亮度为P2。根据费希纳定理:
(1)
则亮度感知差P2-P1和S2与S1的关系为:
(2)
在K-means算法中S1和S2的物理亮度距离为:
D=(S2-S1)2=S12×(10P2-P1-1)2
(3)
对于相近的人眼感知差P2-P1,物理亮度距离与聚类中心的亮度值成正比,即人眼对暗区聚类时与聚类中心的距离要短一些,对中间区域聚类时与聚类中心的距离要长一些。因此,采用如下算法对色调映射图像的三个区域进行调整。
设L为图像像素亮度值,C1、C2、C3分别为暗区、中间区、亮区的聚类中心,则三个区域的分类如下:
(4)
如表2所示,采用式(4)对三个区域的分区进行调整后,信息熵特征的PLCC和SROCC都明显提升,说明分区的调整方法符合人眼的感知特性。
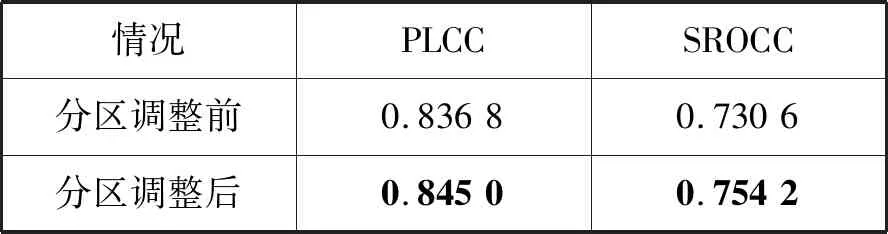
表2 区域调整前后信息熵特征的性能指标
TMI失真主要表现为信息细节的丢失、不自然的颜色、全局亮度和对比度的失真。因此,本文算法综合考虑了TMI的失真特点。如图2所示,本文主要提取了聚类感知特征、显著性区域特征、自然度特征。聚类感知特征在亮度域上提取,先把TMI转换成灰度图,根据亮度信息进行聚类,把图像分成亮区、暗区、中间区三个区域,在每个区域分别提取面积比率和信息熵两个特征。生理学和心理学的一些证据[13]表明人眼观察一幅图像时先看图像的整体,人脑会抑制图像中高频出现的特征,视觉注意力容易关注偏差比较大的区域,即显著性区域。假设图像中一个M×M区域具有亮区、暗区、中间区这三个区域中两个或两个以上区域的像素,这样的区域称为混合区域。混合区域中像素间的亮度值差异比较大,具有显著性区域的特点。本文通过对TMI的非负矩阵分解得到测试图像对应的系数,对系数进行分析识别出TMI的混合区域,在混合区域提出块比例、信息熵特征。由于TMO处理过程缩小了HDR图像的动态范围,影响了TMI的自然度,因此提取了亮度通道和颜色通道的自然统计特征。最后使用机器学习方法对所有特征进行回归,提出了无参考TMI质量评价方法。
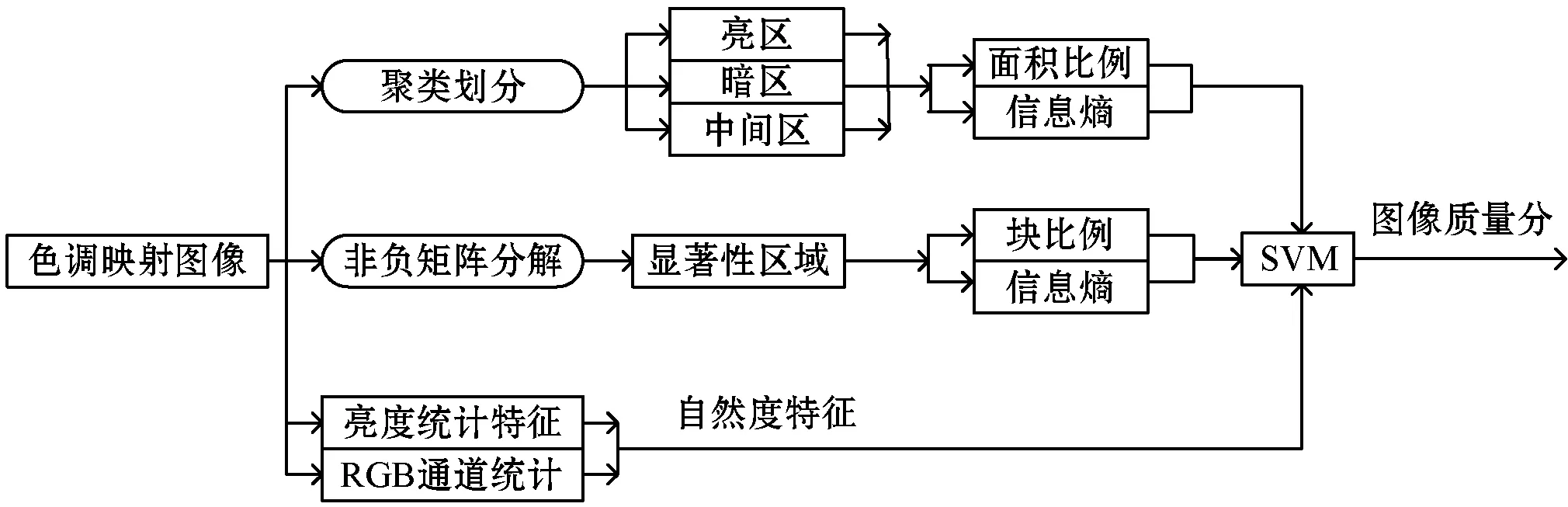
图2 无参考TMI质量评价框架
1.1 聚类感知特征
在视觉注意处理中,人类视觉系统对视觉细胞产生的刺激进行融合,通过不同的信息特征进行聚类,形成人类视觉系统的注意力分配图,因此聚类是人类视觉系统的固有功能。设m×n的灰度图像I,I(x,y)表示图像I中(x,y)像素点的亮度值,设暗区、中间区、亮区的像素亮度值集合分别为RL、RM、RH,则:
(5)
式中:C3、C1为亮区和暗区的聚类中心。信息熵是衡量信息量的有效方法,设p为概率密度,对RL、RM、RH,I分别求信息熵为:
(6)
EL、EM、EH分别表示暗区、中间区、亮区的信息熵。考虑到人眼观察图像时先整体后局部的特点,同时提取全局信息熵EG。
由于TMI图像容易出现过曝光或欠曝光的区域,这些区域的大小会影响图像的质量,因此提取了三个区域的面积比例作为特征。设N(·)函数表示计算图像或者图像块的像素个数,则每个区域的面积比例可以表示为:
(7)
RatioL、RatioH、RatioM分别表示暗区、亮区、中间区的面积比率。聚类感知特征向量Fcluster为:
Fcluster={EL,EM,EH,EG,RatioL,RatioM,RatioH}
1.2 显著性区域特征
当人眼看一幅图像时注意力会被吸引到图像中的一部分区域,这部分区域被称为显著性区域,是大部分人认为图像中重要的或者显著的部分。显著性区域的图像质量显然影响人眼对图像整体质量的评价。Goferman等[13]认为人眼观察一幅图像时先看图像的整体,人脑会抑制图像中高频出现的特征,视觉注意力容易关注偏差比较大的区域,即显著性区域。本文对TMI灰度图像的非负矩阵分解获得对应图像的系数,通过对系数的直方图的分析,提出了一种混合区域的识别方法,然后对混合区域提取信息熵,块比率等特征。
许多研究表明稀疏表示符合人脑对图像信号的认知,非负矩阵分解(NMF)与稀疏表示的字典学习类似。非负矩阵分解是把一个数据矩阵M分解为两个非负矩阵W和S的乘积,W为特征矩阵对应字典学习的原子矩阵,S为编码矩阵。数据矩阵M可以看作特征矩阵W中每一列和S中对应系数的线性组合,由于S的非负性,M是由W中的每一列按照S决定的权重系数累加而成,由于W中的每一列就是一个图像块,因此非负矩阵分解与部分组成整体的直观认知相符。


图3 从TMID数据库中选取的原始训练图像
对于训练样本库M,NMF的目标是寻找特征矩阵W=[W1,W2,…,Wr]∈Rm×r和S=[S1,S2,…,Sn]∈Rr×n来近似训练样本矩阵M:
M=WS
(8)
式中:r是大于零的整数,表示特征矩阵中列向量的个数。W和S的寻找过程可以转化为如下优化问题:
(9)
本文用Lin[14]的方法计算出了W和S,W就是通过训练库训练得到的特征矩阵。对于一个测试图像块转化而成的列向量Ti∈Rm×1,则得到Ti非负矩阵分解后的编码矩阵Fi∈Rr×1为:
Ti=WFi⟹Fi=(WTW)-1WTTi
(10)
式中:(WTW)-1WT是W的伪逆矩阵。对于测试图像T=[T1,T2,…,Tn]获得编码矩阵F=[F1,F2,…,Fn],n为一幅测试图像包含的图像块的个数。
TMI的混合性区域是区域中像素来自两种或两种以上聚类感知区域,例如一个图像块有三分之一的亮区像素和三分之二的中间区像素。把亮区、暗区、中间区、混合区图像块分别进行非负矩阵分解,对每个区域的编码矩阵进行直方图分析,如图4所示。
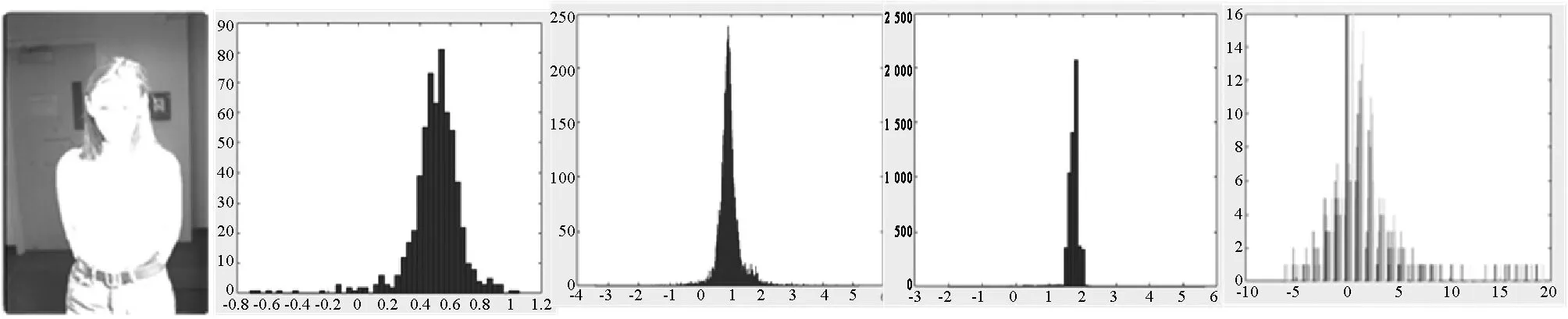
(a) 原图 (b) 暗区系数 (c) 中间区系数 (d) 亮区系数 (e) 混合区系数图4 亮区、暗区、中间区、混合区编码矩阵直方图
可以看出,图像暗区、中间区、亮区的编码矩阵的系数值比较小,混合区系数有较大值。因此可以通过分析编码矩阵的最大值来判断显著性区域,设阈值TH,定义显著性区域S如下:
S={Ti|max(Fi)>TH,Fi=(WTW)-1WTTi}
i=1,2,…,n
(11)
信息熵能有效衡量图像的信息量,根据式(6)对S的所有像素求信息熵获得显著性区域的信息量ES。显著性区域面积越大,对图像质量的影响越大,因此提取显著性区域的面积比例RatioS:
(12)
式中:N(·)函数表示计算图像或者图像块的像素个数;I表示图像。显著性特征FS为:
FS={ES,RatioS}
1.3 自然度特征
HDR图像经过色调映射后可能会出现曝光过度或者曝光不足的现象,造成TMI看起来不自然。然而,高质量的TMI不应当破坏其自然特性。TMI的自然度失真主要体现在图像过亮、过暗、不自然的颜色,因此本文考虑基于亮度和颜色提取自然度特征。
(1) 亮度自然度特征。本文采用了TMQI[5]的自然度统计模型,该模型使用3 000幅包括动物、夜景、建筑、草地等14个不同类别场景的自然图像。首先把每一幅图像转化成灰度图像,然后把灰度图像分割成11×11的图像块,分别求出每个图像块的均值与标准差,最后统计一幅图像中所有图像块的均值与标准差的均值,获得一幅图像的均值和标准差。图像的均值、标准差分别与高斯概率密度函数和Beta概率密度函数能够很好地拟合。两个概率密度函数计算如下:
(13)
(14)
式中:B(·)是Beta函数,模型的参数设置为μm=115.94,αm=27.99,αd=4.4,βd=10.1。TMQI的亮度和对比度的联合概率如下:
(15)
式中:K是随着Pm和Pd改变的标准化因子,K=max{Pm,Pd}使得统计自然度N标准化。
(2) 颜色自然度。本文采用Wang等[15]提出的基于颜色空间的自然度统计方法,该方法表明局部标准化颜色系数(local normalized color coefficients,LNCC)服从高斯分布,LNCC可以表示为:
(16)
式中:IC(i,j)是给定图像的C颜色通道某个像素的值,(i,j)是图像的空域坐标。
(17)
(18)
采用广义高斯函数(generalized Gaussian distribution,GGD)来拟合LNCC参数。GGD概率密度函数如下:
(19)
式中:Γ(·)是伽马函数。β为:
(20)
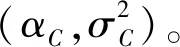
如表3所示,RGB颜色空间自然度特征获得了最好的性能,因此选择RGB颜色空间来提取颜色自然度特征FC:

表3 RGB、LAB、YCbCr颜色空间自然度特征性能指标
1.4 聚合策略
本文提取了聚类感知、显著性区域、自然度三类特征共16个,设V是TMI的特征向量,可以表示为:
V={FC,FS,N,FC}
(21)
特征提取之后需要一个回归模型来建立一个函数,这个函数能够映射特征向量到主观图像质量评价分。由于支持向量机(Support Vector Machine,SVM)在图像处理领域得到广泛的应用,因此把训练图像的特征向量和对应的MOS值输入支持向量机训练出一个预测模型f(·),把测试图像的特征向量输入预测模型获得图像的客观质量预测值Q。
2 实验结果与分析
2.1 实验数据库和性能指标
本文在TMID数据库上对提出的算法进行了相关性能指标验证。TMID数据库由加拿大滑铁卢大学开发,数据库中包括15幅不同场景的HDR图像,在每一幅HDR图像上使用8种TMO总共生成120幅TMI。主观实验邀请了20位测试人员,分别将每幅HDR图像对应的8幅TMI按主观质量的好坏进行排序,序号1~8作为分数,然后将每幅TMI的平均分作为主观质量分数。
根据视频质量专家组(video quality expert group,VQEG)的建议,PLCC和SROCC两个参数经常被用来检测各种图像质量评价方法的性能。SROCC用来评价客观质量评价算法和主观评价的一致性。PLCC用来评价客观质量评价算法和主观评价的准确性。在计算PLCC之前,为了消除主观质量评价引入的非线性因素,需对客观质量评价结果和主观质量评价结果进行非线性拟合,本文采用了五参数Logistic拟合方法。PLCC和SROCC值越大表示客观质量评价算法的性能越好。
2.2 训练集大小的影响
采用交叉验证的方法来评价本文提出的无参考色调映射质量评价方法。首先将TMID图像库中的TMI分为两个不重叠的图像子集。第一子集为训练图像,包含了数据库中120×n%的测试色调映射图像,并用这部分图像建立本文所需的预测模型。第二个子集为余下的120×(1-n%)色调映射图像并作为测试图像。为了消除性能偏差,本文随机重复1 000次之前的训练-测试过程,并将这1 000次测试所得到的性能指标的中值作为最终的性能指标。如表4所示,随着训练集尺寸的增大,预测模型的性能逐渐提高,但当训练集达到80%时,SROCC性能指标提升不再明显。
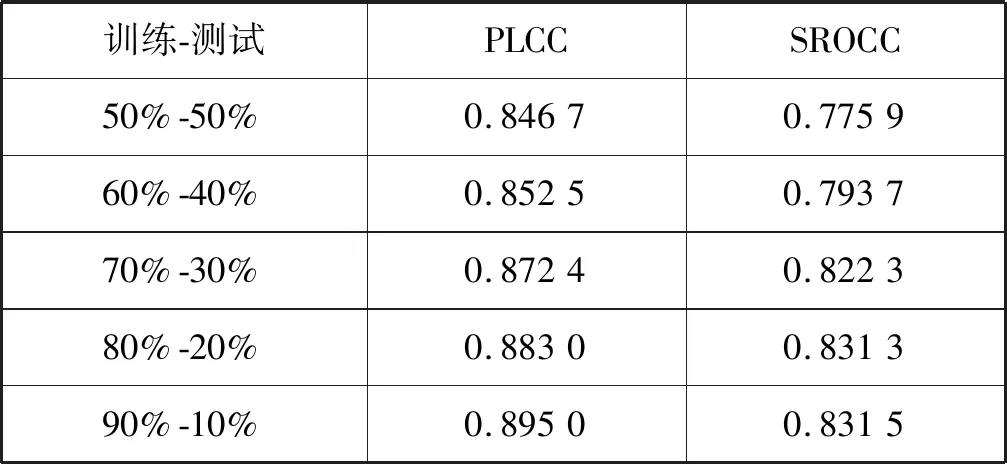
表4 不同大小训练集的性能指标
2.3 特征分析
本文算法提取了三类特征,具体包括聚类感知特征、自然度特征、显著性区域特征,如表5所示。聚类感知特征包括全局信息熵、三个区域的信息熵、三个区域的面积比率,全局信息熵可以看作是整个图像为一类的特殊情况。信息熵越大,说明图像的信息量越大,对图像分亮区、中间区、暗区提取的信息熵相对全局信息熵具有更好的性能指标,说明对图像聚类分区域感知图像质量的方法是有效的。三个区域信息熵特征和全局信息熵的组合显著提升了性能指标,说明三个区域信息熵特征可以弥补全局信息熵特征的不足。由于TMI图像容易出现过曝光或欠曝光的区域,这些区域的大小会影响图像的质量,三个区域的面积比例RatioΩ和EL、EM、EH、EG的组合提升了性能指标。自然度特征包括亮度通道特征N和RGB颜色通道特征FC,自然度显然与聚类感知特征具有很好的互补性,自然度和聚类感知特征结合后性能指标大大提高。显著性区域提取的混合区域特征ES和块比例RatioS结合使用比单独使用效果好很多,说明这两个特征具有互补作用。聚类感知特征、自然度、显著性特征联合使用后算法的性能指标进一步提高,说明显著性特征对TMI质量有一定的影响。
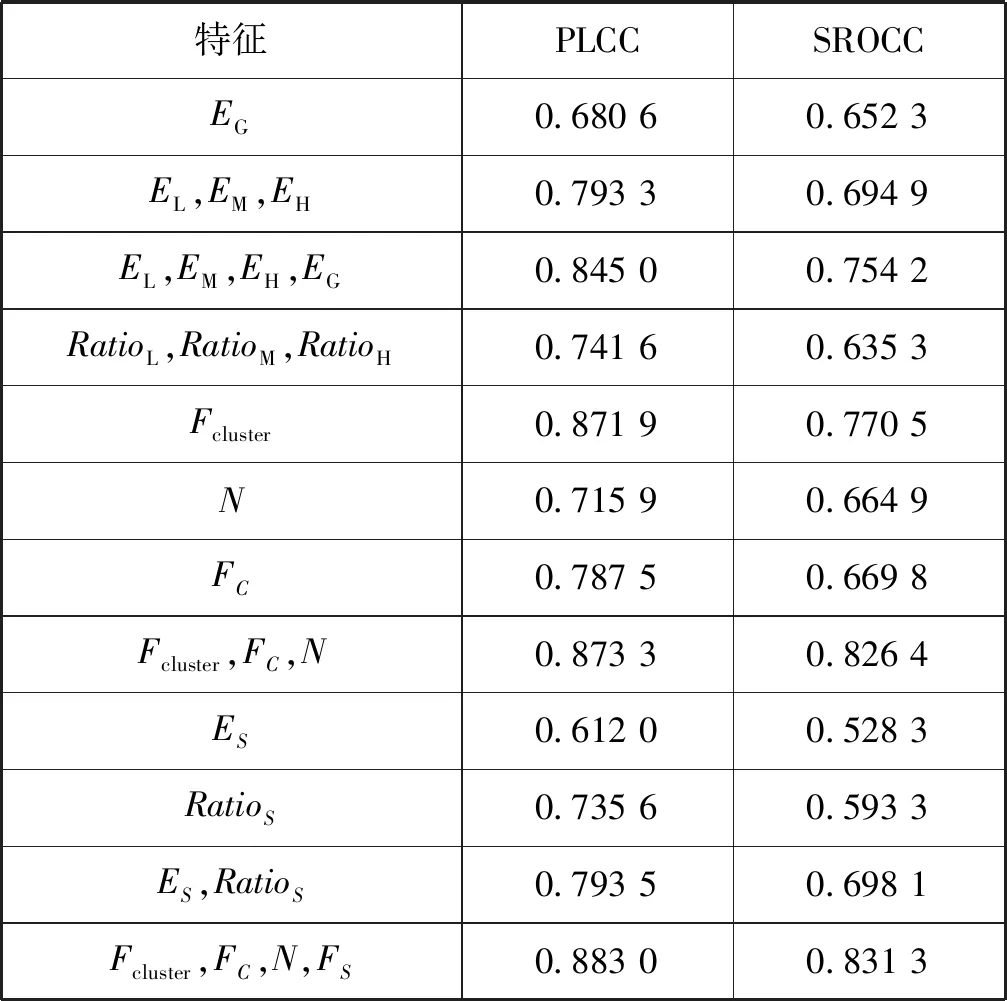
表5 本文算法中各特征的性能指标
2.4 算法比较
为了验证本文算法的准确性和有效性,在TMID数据库上与现有的代表性算法进行了比较,如表6所示。选择了有代表性的全参考和无参考图像质量评价方法作为对比。全参考图像质量评价方法包括TMQI[5]、FSITM[6]、NITI[16]。无参考图像质量评价方法包括BRISQUE[17]、BLIINDS-II[18]、Yue[11]、BTMQI[10]。TMQI、FSITM、NITI等专门为TMI设计的全参考图像质量评价方法要优于BRISQUE、BLIINDS-II等针对LDR图像的无参考图像质量评价方法,说明针对LDR的无参考图像质量评价方法不适合TMI的质量评价。BTMQI的性能超越了TMQI、FSITM等全参考方法,说明对TMI质量评价,无参考质量评价方法也能取得很好的效果。实验结果表明在TMID数据库上,对于PLCC和SROCC两个性能指标,本文算法优于现有代表性的算法。
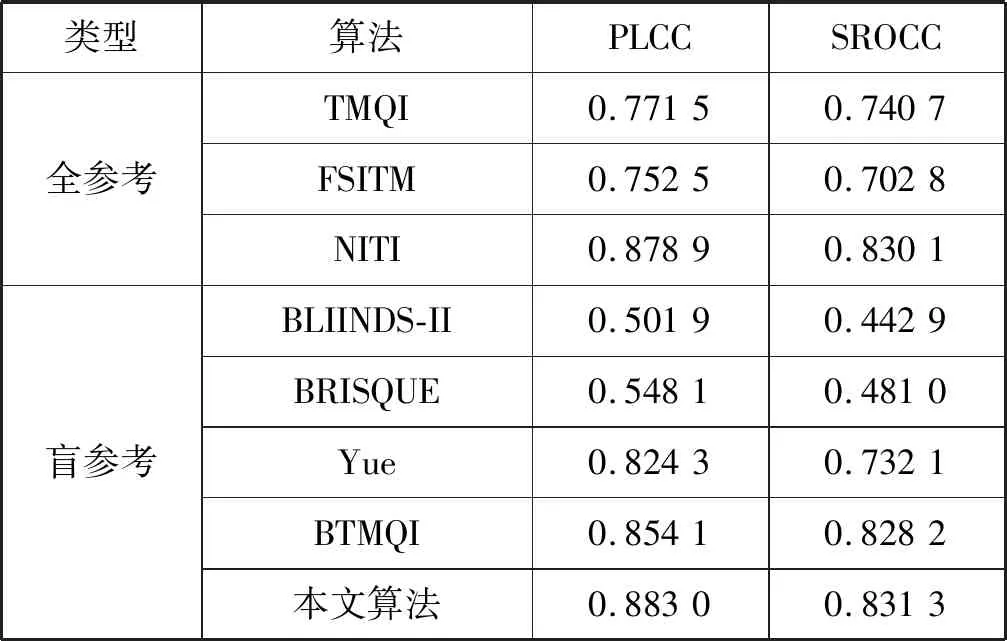
表6 本文算法与代表性算法的比较
3 结 语
本文受Weber定律启发,采用聚类感知TMI图像的质量。用K-means聚类算法把TMI分成暗区、中间区、亮区,提取三个区域的信息熵、面积比率和全局信息熵作为特征。通过分析图像编码矩阵的系数提取显著性区域,并在显著性区域提取信息熵、面积比率特征。在亮度和颜色通道提取了自然度特征。最后用SVM融合全部提取的特征获得TMI的质量分。实验表明,本文算法在TMID数据库上具有很好的性能。
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01 06:28:50
摄影之友(影像视觉)(2019年3期)2019-03-30 01:36:56
电子测试(2017年15期)2017-12-18 07:19:27
电子测试(2017年12期)2017-12-18 06:35:48
小天使·六年级语数英综合(2017年5期)2017-05-27 20:14:50
雷达学报(2017年6期)2017-03-26 07:52:58
现代工业经济和信息化(2016年19期)2016-05-17 05:38:10
公民与法治(2016年23期)2016-05-17 04:21:08
池州学院学报(2015年3期)2016-01-05 01:13:00
智能系统学报(2015年4期)2015-12-27 09:38:39
