
基于近邻传输的粒度SVM算法*
2020-07-10 12:29程凤伟王文剑
计算机与生活 2020年7期
程凤伟,王文剑
1.太原学院 计算机工程系,太原030032
2.山西大学 计算机与信息技术学院,太原030006
3.山西大学 计算智能与中文信息处理教育部重点实验室,太原030006
1 引言
支持向量机(support vector machine,SVM)是Vapnik等人提出的一类通用有效的学习方法[1],在处理小规模二分类问题时表现出较好的性能,并在很多领域如手写数字识别[2]、人脸识别[3]、时间序列预测[4]得到成功应用。SVM 在处理小样本数据集时比较有效,但实际应用中往往要处理一些大规模数据集,由于算法需要利用整个Hessian矩阵,受计算机内存容量的限制,SVM在处理大规模数据集时效率低下。为了提高SVM的学习效率,许多学者提出了一些方法,其中,Tang等人于2004年提出了一种新的机器学习模型[5]——粒度支持向量机(granular support vector machine,GSVM)。其主要思想是首先构建粒度空间获得一系列信息粒,然后在每个信息粒上进行SVM学习,最后通过聚合信息粒上的信息获得最终的决策函数。粒度支持向量机学习算法用重要信息粒代替传统的数据点进行训练,可大大提高支持向量机的训练效率,同时获得满意的泛化能力[6-7]。目前典型的GSVM模型主要是SVM与关联规则[8-9]、聚类[10]、粗糙集[11]、决策树[12]、商空间以及神经网络[13-14]等相结合的模型,这些GSVM算法在解决实际问题时取得了不错的效果,尤其是对一些分布较为均匀的大规模数据集,大大提高了SVM的学习效率,但在处理一些分布不均匀的数据集时难以奏效。后来提出的动态粒度SVM 算法(dynamic granular support vector machine learning algorithm,DGSVM)[15]和层次粒度SVM 算法(hierarchical granular support vector machine algorithm,HGSVM)[16]采用多层次粒度划分的方法可在一定程度上缓解粒划过程带来的模型误差。
本文将近邻传输思想[17]、粒度计算理论和传统的SVM 分类方法进行有效的融合,提出一种基于近邻传输的粒度SVM算法——APG_SVM(affinity propagation based granular support vector machine)。APG_SVM 算法选取的粒中心不是求和平均得到的,而是所有数据点通过竞争得到的粒中心;APG_SVM算法经过初次训练后,找到那些重要的信息粒,用Kmeans聚类算法对它们进行继续粒划,提取粒中心加入到训练集;采用此粒划模型对样本集进行筛选,提取重要的分类信息加入到训练集进行训练,可以获得较好的泛化能力。
2 APG_SVM算法模型
GSVM在很大程度上可以提高传统SVM的分类效率,但是目前大多数GSVM 算法在划分粒的时候采用的K-means聚类算法,即划分粒的个数是由用户给定的初始粒划参数指定的,粒中代表点(粒中心)的选定也是通过求和计算平均值得到的,这样得到的粒中心作为粒中的代表点往往不能真正地去表达一个粒。本文采用一个新的算法:将所有的数据点看成潜在的粒中心,计算数据点之间的相似性,再通过迭代计算出数据点之间的亲和度与适用度,通过亲和度与适用度两个参数来确定数据点是否可以成为粒的代表点(粒中心)。
APG_SVM 算法考虑到不同粒度之间的分布差异对分类结果的影响,在经过初次SVM训练后,计算每个粒到分类边界的距离和粒的混合程度(即粒中正负样本的混合程度,混合程度越低的粒越纯,纯粒是只包含正类或负类样本的粒)。对于靠近分类边界和混合程度较高的粒,由于它们包含相对较多的分类信息,需要对这些粒进行细化,再次粒划分,得到更多的子粒,取子粒的粒中心代替父粒加入到训练集进行再次训练。
首先定义几个概念。给出一个训练集X={(xi,yi)},其中xi∈Rd,yi∈{+1,-1}。s(xi,xk)表示数据点xi与数据点xk之间的相似性,s(xi,xk)=-||xi-xk||2。除了相似性,每个数据点还有两个属性:数据点与其他潜在粒中心的亲和度r(xi,xk) 和适用度a(xi,xk) 。r(xi,xk)表示从数据点xi角度出发,与其他潜在粒中心相比,xk作为其代表点(粒中心)的合适程度;a(xi,xk)表示从候选粒中心xk角度出发,选择成为数据点xi的粒中心的合适程度,而不是作为其他点的粒中心。在第一次迭代中a(xi,xk)初始化为0。亲和度r(xi,xk)的计算方法如下:

在第一次迭代中,因为适用度为0,r(xi,xk)的值就等于数据点xi与xk的相似性减去数据点xi与其他候选粒中心的相似性的最大值。当k=i时,r(xk,xk)的值就等于s(xk,xk)减去数据点xi与其他候选粒中心的相似性的最大值,r(xk,xk)反映了数据点xk如果不作为一个粒中心而是从属于另外一个粒的不合适程度。若r(xk,xk)的值为正,则表示xk适合作为一个粒中心;若r(xk,xk)的值为负,则表示xk不适合作为粒中心,而应该从属于另外一个粒。在后面的迭代过程中,如果有一些数据点被分配给其他的粒,根据式(2),它们的适用度的值就会下降到负数,同样根据式(1),负的适用度又会降低一些点的相似性s(xi,xk)的有效值,这样就把相应的候选粒中心从竞争中删除。

从上述公式可以看出,如果其他点xi对于xk有正的亲和度,那么xk点作为粒中心的适用度就会增加,为了限制正的亲和度的影响,给出一个阈值,使它不超过0,如式(3):

用近邻传输思想求解粒中心的每一次迭代过程包括:(1)更新亲和度给出适用度;(2)更新适用度给出亲和度;(3)结合亲和度与适用度来监控算法并决定是否终止迭代过程。
上述更新规则简单且易于计算,信息(亲和度与适用度)只需要在已知相似性的点之间进行交换更新,在迭代过程的任意时刻都可以用适用度与亲和度来识别粒中心。当算法执行到指定的迭代次数后或者在数次迭代过程中信息保持稳定的状态时终止迭代过程。
根据以上迭代过程获取一组粒E=及其粒中心C=,粒ei的半径反映一个粒的大小,其定义如下:

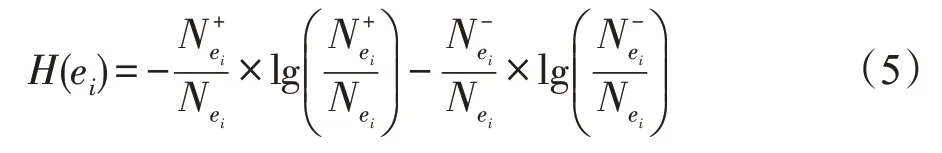
其中,H(ei)∈[0,1],H(ei)值越大,表示粒ei的混合度越高;H(ei)值越小,表示粒ei的混合度越低,粒越纯;当H(ei)=0时,表示粒ei是纯粒。
用T(ei)表示粒ei需要再次划分粒的个数,称之为粒划因子,一般靠近决策边界或者混合度较大的粒包含更多的分类信息,也最有可能成为支持向量;本文选择靠近决策边界或者混合度较大的粒进行再次划分,从而使样本空间中得到的信息粒数目更多。这样定义的优点是能够对相对重要的区域提取出更细更多的分类信息参与训练,而对相对不重要的区域中只抽取少量代表点加入训练集,因此提取有用信息并剔除冗余信息来构造训练集可以获得更优的超平面。T(ei)由粒的混合度和粒到超平面的距离共同决定,其定义如下:

其中,para是一个调和参数,用于确定一个粒是否需要再次划分的重要程度,Yi表示粒ei的中心到超平面的距离。
经过SVM 初次训练的粒,有些需要再次粒划,有些无需再次粒划。若一个粒满足Yi<1+ci或者H(ei)>δ,则这个粒需要再次粒划(其中δ是用户定义的一个置信度,是粒混合度的一个界值,可由统计实验得出),即距离分类超平面较近或混合度较高的粒需要再次划分。
综上所述,本文提出的APG_SVM算法的主要步骤总结如下:
步骤1根据给定的数据点的s(xk,xk)值,分别用式(1)和式(2)计算每个数据点的亲和度与适用度,然后结合式(3)进行迭代计算,直到亲和度与适用度保持一个相对稳定的状态,完成了数据集进行初始粒划分,得到一系列的初始粒及其粒中心。
步骤2取粒中心放到训练集中进行SVM 训练,得到一个分类超平面。
步骤3根据式(4)和式(5)计算出每个粒的半径及混合程度,根据粒半径、混合度及粒到超平面的距离找出需要再次划分的粒,根据式(6)计算出需要划分的粒的粒划因子,用K-means算法对它们进行再次粒划,得到一组子粒。
步骤4取子粒的粒中心代替原来的粒中心加入到训练数据进行再次训练,得到分类超平面:
f(x)=sgn(W*φ(x)+b)
步骤5算法结束。
相对于传统GSVM分类器,APG_SVM是采用近邻传输思想的竞争机制求解粒中代表点,这些代表点能够更加有效地去表达一个粒,用这些代表点代替一个粒加入到训练集进行训练,可大大提高SVM的分类效率。同时经过初次SVM 训练,采用粒到分类超平面的距离和混合度两个指标来判断粒的重要程度,细划重要的分类信息,使包含更多分类信息的样本加入到训练集,进而获得更好的泛化能力。
3 实验结果及相关分析
将本文提出的APG_SVM 算法与传统GSVM 算法、HGSVM 算法[16]和DGSVM 算法[15]进行比较。本文在6 个典型的UCI 数据集(见表1)上进行了测试。实验中采用高斯核函数,其中正则参数C取1 000,核参数d取1.0。调和参数para由网格搜索算法计算取为0.2,δ=0.55。

Table 1 Datasets used in experiment表1 实验采用的数据集
图1给出了APG_GSVM算法与其他3种算法在初始粒划参数取值为100时的正确率。
从图1 可以看出,APG_SVM 算法的正确率在几个数据集上都非常高,与GSVM 算法相比,APG_SVM 算法正确率相对稳定且算法效率较好;与HGSVM相比,在以上6个数据集上,APG_SVM算法的正确率都要高于HGSVM算法;与DGSVM算法相比,APG_SVM算法的正确率除了在Breast_cancer数据集上略低于DGSVM算法以外,在其他5个数据集上都高于DGSVM 算法。这是因为本文采取了近邻传输思想选取了更有代表性的粒中心,用这些粒中心进行SVM训练,取得了更好的分类效果。
为了测试APG_SVM 算法在训练过程中粒划分程度的高低,实验还对最终参加SVM 训练的样本的个数进行了统计。图2给出了APG_SVM算法与GSVM算法、HGSVM算法和DGSVM算法的统计结果。
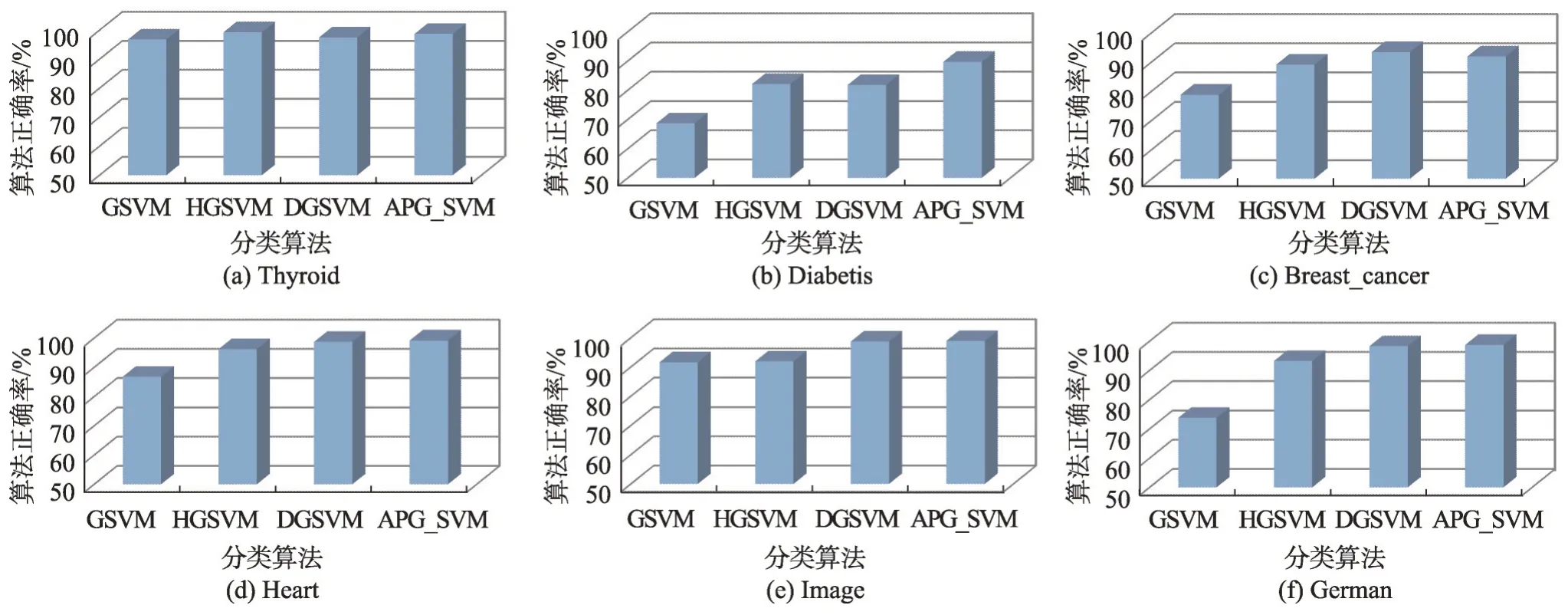
Fig.1 Comparison among APG_SVM and GSVM,HGSVM,DGSVM图1 APG_SVM算法与GSVM、HGSVM、DGSVM 算法比较
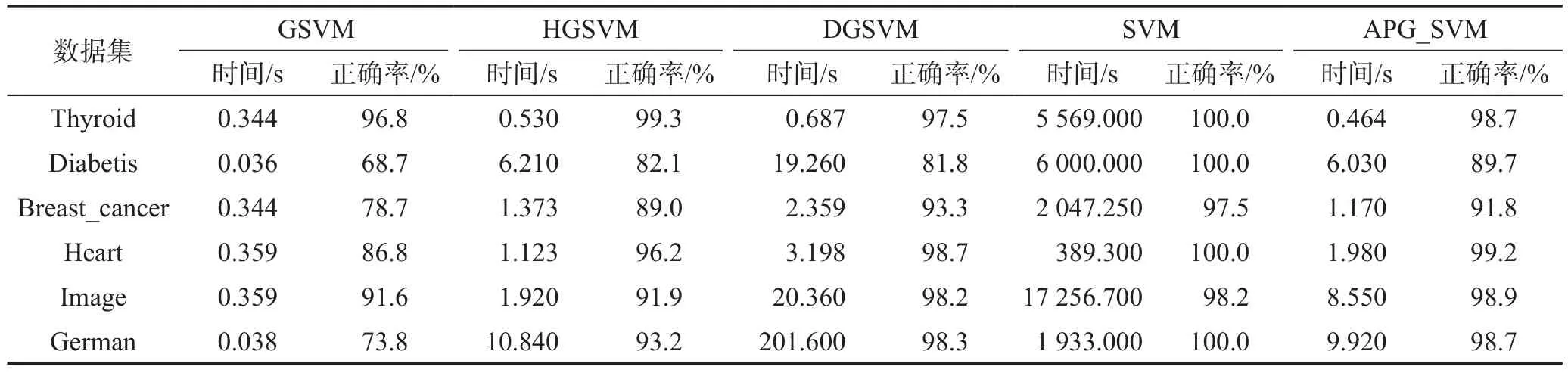
Table 2 Comparison of experimental results by several algorithms表2 几种方法测试结果的比较
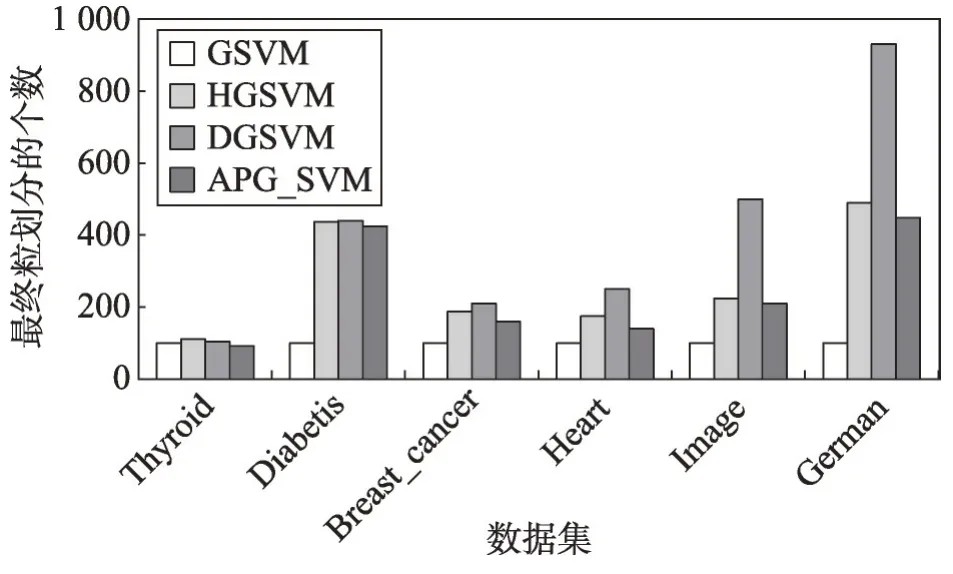
Fig.2 The number of samples in SVM training of several algorithms图2 几种算法中参与SVM训练的样本个数
从图2 可以看出,在几个数据集上,传统GSVM算法的训练样本为100,因为初始粒划参数的值设置为100,而GSVM 只进行一次粒划分;APG_SVM 算法与HGSVM、DGSVM 算法相比,参加SVM 训练的样本个数更少,因此训练集的规模也更小,特别是在数据集Thyroid、Heart、Image上最终参加训练集样本的个数占整个训练集的比例都在5%以下,在其他数据集上最高也不到15%。由于训练规模的减小,会在很大程度上减少训练时间,进而提高算法的效率。
表2 是APG_SVM 和HGSVM、DGSVM、传统GSVM 以及经典SVM 测试结果的比较,从实验结果中可以看出,在6个数据集上APG_SVM训练效率比经典SVM 算法有上千倍的提高。APG_SVM 与SVM 相比分类正确率虽有所下降,但仍有较高的分类准确率。与GSVM 相比,APG_SVM 具有更好的泛化性能。与DGSVM 相比,在6 个数据集上APG_SVM的分类效率都有所提高,在其中5个数据集上,APG_SVM算法表现出更好的分类性能。与HGSVM相比,在其中3个数据集上,分类效率虽有所下降,但APG_SVM算法表现出更好的泛化能力。
上述实验结果表明,APG_SVM算法采用近邻传输思想能有效提取支持向量信息,减少模型误差,获得了更好的分类性能。与SVM 相比,APG_SVM 算法提取出含有分类信息较多的代表点在数据集上进行训练,大大压缩了训练集,在正确率几乎没有太大变化的情况下,速度有了很大提高,而且在初次粒划分之后对重要分类信息进行细划,使得实验结果非常稳定。与上述几个算法相比,APG_SVM仍然保持非常高的分类水平。
4 结束语
本文提出了一种基于近邻传输的粒度支持向量机学习算法,通过竞争机制更有效地提取重要的分类信息进行SVM训练。同时,根据样本分布特点,细划重要分类信息,获得了很好的泛化性能和训练效率。本文对二分类问题进行了实验验证,在未来的工作中,考虑将算法扩展到多类分布不均匀数据的分类问题中。另外,可以将本文的方法应用于网页分类、疾病监测等大规模分布不均匀的实际问题中。
猜你喜欢
佳木斯大学学报(自然科学版)(2022年3期)2022-06-27
计算机研究与发展(2022年1期)2022-01-19
苏州科技大学学报(自然科学版)(2021年4期)2021-12-02
计算机应用(2020年12期)2020-12-31
小型微型计算机系统(2020年10期)2020-10-21
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
新作文·高中版(2017年6期)2017-07-06
少儿科学周刊·儿童版(2017年3期)2017-06-29
文苑(2015年9期)2015-09-10
