
新型书目框架的发展历程及实施难点
2020-07-09 11:20邹美辰
图书馆学刊 2020年6期
邹美辰
(江苏第二师范学院图书馆,江苏 南京 211200)
1 新型书目框架的发展历程
新型书目框架是由传统书目框架发展而来的,具体是指突破传统书目框架的限制,构建书目数据之间的关联,使书目数据能够融入网络环境的更加开放和包容的书目框架。新型书目框架即美国国会图书馆于2011年5月首次提出的,为图书馆重新设计和完成的书目框架——BIBFRAME[1]。BI BFRAME不仅是当前图书馆书目格式的替代品,而且是现在和未来书目数据描述的基础。它能够使图书馆融入更广泛的信息社会,成为真正意义上的书目数据中心和互联场所。从卡片目录的出现到新型书目框架的提出,书目格式的发展可以划分为3个阶段。第一阶段图书馆采用的主要是卡片目录格式,并且开始出台一系列的国际性编目规则。第二阶段主要采用机器可读目录(Machine Readable Cataloguing,简称 MARC)格式,它为图书馆积累了大量的原始数据资源。之后随着关联数据的出现,图书馆又开始借助关联数据技术实现书目数据关联化,建立与其他资源的关联。第三阶段是新型书目框架BIBFRAME的提出,书目世界观开始发生根本性变革。MARC格式由于无法与语义网的基本标准兼容,开始受到根本性的质疑和挑战,逐渐成为制约书目数据向前发展的最大障碍。建立一个能够取代MARC格式的更加开放和包容的新型书目框架是时代发展的必然趋势。
1.1 卡片目录格式
书目数据最早采用的是1861年由美国哈佛大学图书馆首创的卡片目录格式。卡片目录格式一直在图书馆服务工作中发挥着巨大作用。随着卡片目录的出现,图书馆界开始出台一系列的国际性编目规则来指导卡片目录的编制。例如基于“巴黎原则”的《英美编目条例》第一版(Anglo-American Cataloguing Rules,简称 AACR1)和《国际标准书目著录》(International Standard Bibliography Description,简称ISBD),它们对于早期的编目工作有十分重要的指导作用。但随着时间的发展,卡片目录的不足开始逐渐暴露出来,所占空间大、文献信息量小以及检索速度慢。因此当计算机技术出现之后,图书馆界就开始着手研究能够用于计算机批量处理的新一代书目格式。
1.2 机器可读目录格式
经过大量的研发试验,美国国会图书馆于1966年1月推出了《标准机器可读目录格式的建议》,即MARC-1格式,并在此基础上于1967年提出MARC-2,即目前所有机器可读目录格式的母本。1969年初MARCⅡ格式磁带正式发布,成为图书馆界的革命性产品[2]。之后,由于各个国家语言和编目特点的不同,又研发了不同版本的MARC 格式,如USMARC、CANMARC、UKMARC、CNMARC等。MARC格式为书目数据在计算机内的记录和交换提供了通用的句法,图书馆的业务工作正式走向机器自动化时代。1972年,ISO 2709格式发布,它定义了一种通用的记录结构,包括记录头标区、地址目次区、数据字段区和记录分隔符,所有的MARC记录都可以通过ISO 2709格式进行交换,具体的记录结构如图1所示[3]。

图1 ISO 2709记录结构
随着MARC格式的正式发布,编目规则也进行了相应修订,并于1978年发布了修订后的《英美编目条例》第二版(Anglo-American Cataloguing Rules 2,简称AACR2)[4]。自从MARC格式出现后,图书馆的信息系统和书目记录处理就都基于MARC格式存在,编目规则AACR和书目格式MARC伴随着图书馆的编目工作走过了很多年,为图书馆积累了大量的原始数据资源。但随着网络环境的发展,MARC格式在结构和语义方面的不足日渐明显。MARC格式的局限性具体表现在以下几方面:首先MARC格式不具备可扩展性,例如无法对封面和评论等内容进行编码。其次MARC格式无法构建书目记录之间的关联,无法在网络环境当中得到充分利用。最后MARC格式由于ISO 2709格式的设计问题无法与其他数据格式,如XML格式等进行交换。MARC格式的局限性促使传统书目框架开始寻求转变。
1998年,国际图联(International Federation of Library Associations and Institutions,简称 IFLA)出版了一份名为《书目记录功能需求》(Functional Requirements for Bibliographic Records,简称 FRBR)的研究报告,其首次为扁平结构的书目数据建立了层次关系,并且采用了“实体—关系”模型对书目数据中各实体进行分析。FRBR将书目数据抽象为三组实体,分别为智力和艺术创作的成果(作品、内容表达、载体表现、单件)、智力和艺术内容的创作者(个人、团体)以及智力和艺术创造的主题(概念、物体、事件、地点),三组实体之间存在的关系如图2所示。FRBR对沿袭了一个多世纪的编目理论提出了挑战,打破了书目数据之间彼此独立没有关联的状况,使书目资源彼此关联起来,拉开了书目控制领域新阶段的序幕。之后,IFLA还于2009年和2011年分别出版了另外两个相关报告,分别为《规范数据功能需求》(Functional Requirements for Authority Data,简称 FRAD)和《主题规范数据功能需求》(Functional Requirements for Subject Authority Data,简称 FRSAD)。
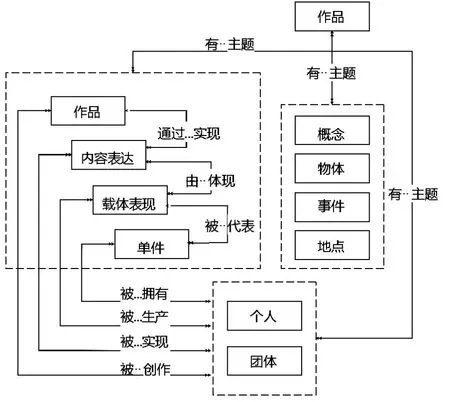
图2 FRBR三组实体之间的关系
随着数字时代的到来,基于传统组织方式的书目数据逐渐成为一个信息孤岛,图书馆中大量有价值的信息和知识被快速更新的互联网资源所湮没,没有发挥其应有的价值,图书馆界急需一种新的技术手段来解决上述问题。2006年7月,Tim Berners-Lee首次提出了关联数据的概念,即构建数据之间的关联,形成一个能被计算机理解的数据网络,从而将现存的信息孤岛整合成一个巨大的数据库[5]。这一概念的提出为书目数据的发展提供了新的契机,将书目数据发布为关联数据,实现书目数据关联化成为了各个图书馆打破资源壁垒的共识。书目数据关联化虽然没有从本质上改变图书馆采用MARC格式编目的现状,但仍然具有非常重要的指导作用。它为书目控制领域新阶段的发展指明了方向,推动了新型书目框架的建立。
1.3 新型书目框架
通过上述两个阶段的研究,为满足数字环境下资源描述与检索的新要求,英美编目条例修订联合指导委员会(Joint Steering Committee for Revision of AACR,简称JSC)开始试图制定最新的国际编目规则。资源描述与检索(Resource Description and Access,简称RDA)以统一的国际编目原则声明(Statement of International Cataloguing Principles,简称ICP)为纲领,以传统的AACR2为基础,以现代的FRBR和FRAD概念模型为框架,创造性地提供了一套更为综合、能覆盖所有内容和媒介类型资源的描述与检索的原则和说明[6]。RDA的编制始于1997年JSC举办的“AACR原则与未来发展国际会议”,会上提议将AACR2进一步国际化,扩展到更广泛的范围内使用。2009年,RDA编制完成。2010年6月,RDA工具套件(RDA Toolkit)正式发布,标志着RDA的正式诞生。同年11月,RDA活页印刷版出版。在此之后,RDA又进行了一系列的更新,并于2012年4月和2013年7月发布了第一次和第二次更新版[7]。

表1 RDA各部分主要内容
RDA借鉴了FRBR和FRAD中的实体,包括作品、内容表达、载体表现、单件、个人、团体、家族、概念、物体、事件和地点。RDA的内容分为导言、10个部分、附录、术语表和索引,其中10个部分的主要内容如表1所示。
编目规则从AACR到RDA的变化反映了书目世界观的根本性变革。RDA最突出的特点就是将书目数据划分为各种实体,然后对实体属性及实体间关系进行描述,非常符合语义网环境下的资源描述方法[8]。在RDA发布之后,很多机构都开始陆续开展了对RDA的测试工作,以便将理论研究推进到实践化进程当中。2008年5月到2010年12月,美国国会图书馆、美国国家农业图书馆和美国国家医学图书馆对RDA进行了联合测试[9]。2011年6月,RDA的测试报告正式发布。在这次测试当中,MARC格式的局限性开始暴露出来,其设计缺陷无法发挥RDA的最大效用,MARC格式开始受到根本性的质疑和挑战。
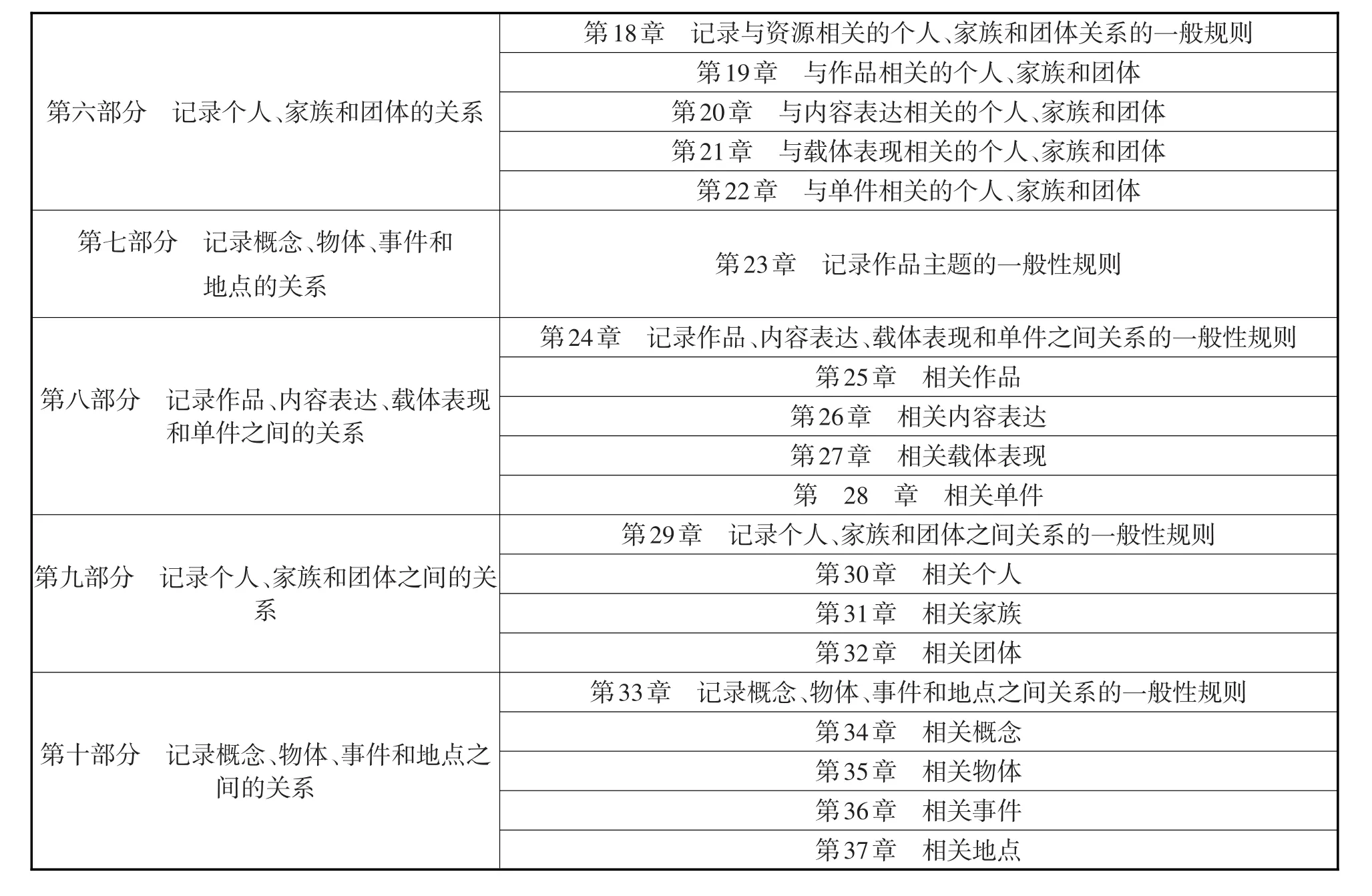
第六部分 记录个人、家族和团体的关系第1 8章 记录与资源相关的个人、家族和团体关系的一般规则第1 9章 与作品相关的个人、家族和团体第2 0章 与内容表达相关的个人、家族和团体第2 1章 与载体表现相关的个人、家族和团体第2 2章 与单件相关的个人、家族和团体第七部分 记录概念、物体、事件和地点的关系第2 3章 记录作品主题的一般性规则第八部分 记录作品、内容表达、载体表现和单件之间的关系第九部分 记录个人、家族和团体之间的关系第2 4章 记录作品、内容表达、载体表现和单件之间关系的一般性规则第2 5章 相关作品第2 6章 相关内容表达第2 7章 相关载体表现第 2 8 章 相关单件第2 9章 记录个人、家族和团体之间关系的一般性规则第3 0章 相关个人第3 1章 相关家族第3 2章 相关团体第3 3章 记录概念、物体、事件和地点之间关系的一般性规则第十部分 记录概念、物体、事件和地点之间的关系第3 4章 相关概念第3 5章 相关物体第3 6章 相关事件第3 7章 相关地点
为了彻底改变图书馆利用MARC格式编目的现状,美国国会图书馆于2011年5月发起了书目框架转换行动。2013年初,BIBFRAME的完整模型及具体元数据方案发布[10]。之后通过相关实验以及专家建议,美国国会图书馆开始对BIBFRAME进行修改,并于2016年4月发布了新型书目框架——BIBFRAME 2.0,其数据模型如图3所示[11]。
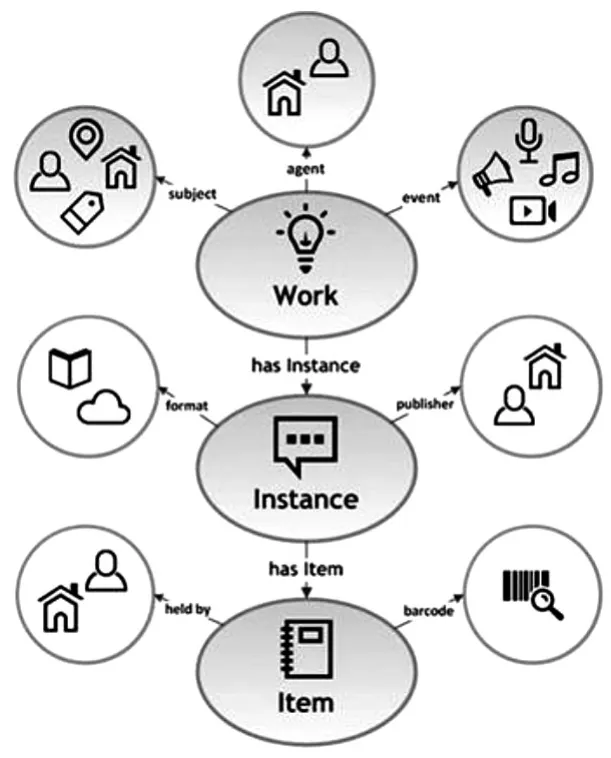
图3 BIBFRAME 2.0数据模型[11]
BIBFRAME采用了关联数据的思想,其目的就是使书目数据能够在图书馆内部和外部发挥最大的价值。它不仅仅是MARC格式的替代品,还为书目数据融入更广阔的互联网环境带来了巨大的潜力和可能性。模型包括3个核心类,分别为作品(Work)、实例(Instance)和单件(Item)。作品是一个抽象的实体,反映编目资源的概念本质,其属性包括责任者、语种和主题等。实例是作品的具体化表现,一个作品可能包含一个或多个实例,实例的属性包括出版者、出版地点、出版时间和出版类型等。单件则是实例的一个实际副本,其属性包括存放地点、排架号和条形码等。除此之外,该模型还定义了其他与核心类有关的关键概念,分别为代理(Agents)、主题(Subjects)和事件(Events)。代理是指通过作者、编辑、画家、摄影师、作曲人和插画师等角色与作品或实例产生关联的人、组织和权限等。主题是指与作品相关的概念,这些概念可以是主题、人物、地点、时间表达、事件、作品、实例、单件和代理等。事件则是指对作品内容中某些事件的记录。
BIBFRAME2.0总共包括186个大类,190个属性。其中,17个类有子类信息。BIBFRAME2.0将属性划分为17个类别,分别为通用属性(General Properties)、类别属性(Category Properties)、题名信息(Title Information)、作品标识信息(Work Identification Information)、作品描述信息(Work Description Information)、主题术语和分类信息(Subject Term and Classification Information)、实例描述声明(Instance Description Statements)、实例标识信息(Instance Identification Information)、实例描述信息(Instance description Information)、载体描述信息(Carrier Description information)、单件信息(Item Information)、类型信息(Type Information)、编目资源关系—通用(Cataloging Resource Relationships-General)、编目资源关系—特性(Cataloging Resource Relationships-Specific)、编目资源关系—详 细(Cataloging Resource Relationships- Detailed)、代理信息(Agent Information)和管理信息(Administration Information)[12-13]。
在BIBFRAME发布之后,国外的主要机构都在积极推动新型书目框架的应用和实施。在BIBFRAME 1.0版本推出后,美国国会图书馆、德国国家图书馆、大英图书馆、乔治·华盛顿大学图书馆、普林斯顿大学图书馆、联机计算机图书馆中心(Online Computer Library Center,简称 OCLC)和美国国立医学图书馆就利用其馆藏参与了BIBFRAME的测试[14]。此外,图书馆系统服务商VTLS还推出了支持新型书目框架的Open Skies平台[15]。科罗拉多大学也进行了相关实验研究,在Redis图书馆服务平台上实现了从MARC21记录到BIBFRAME实体的转换[16]。之后,在BI BFRAME 2.0版本中,伊利诺伊大学厄巴纳—香槟分校图书馆完成了从都柏林元数据到BIBFRAME 2.0的7829项转换,并通过与开放数据集进行关联增强了图书馆的数据发现[17]。匈牙利国家图书馆将其整个在线目录以BIBFRAME的格式发布到了语义网中,并建立了与 BNF、ISNI、LC NAF、VIAF 和Wikidata等外部数据集的链接[18]。
2 新型书目框架的实施难点
新型书目框架符合时代发展的趋势,能够满足图书馆适应网络环境的需求,将传统格式的书目数据转换到新型书目框架中,成为图书馆界面临的重大课题。目前,国内有很多机构和学者针对新型书目框架的理论和应用进行了相关研究。在当前环境下,新型书目框架的实施还面临着很多难点。
2.1 新型书目框架的理论和应用现状
目前国内已有很多关于新型书目框架理论和应用的相关研究,涉及新型书目框架实施的各个步骤。层次识别作为实施过程中的关键问题,已经引起了学者的关注。邹美辰对新型书目框架的层次识别进行了研究,涉及作品层、实例层和单件层[19]。胡小菁等对CNMARC书目记录作品层次转换方法进行了总结和实践[20]。但由于书目记录的质量参差不齐,层次识别不可避免地需要不同程度的人工干预,普适性需要进一步提高。元数据互操作作为实施过程中不可缺少的一环,也受到了广泛关注。国内有很多关于CNMARC与BIBFRAME相互映射及转换的相关研究。吴贝贝采用元数据映射方法,形成了CNMARC书目记录与BIBFRAME词表的映射表[21];周小萍通过元数据映射及转化方法,尝试了在CNMARC字段与BIBFRAME 2.0类及属性之间建立映射[22]。但目前还没有统一的映射方案和自动转换工具。对于数据的发布,夏翠娟和许磊对中文关联书目数据发布方案进行了研究,该研究只是对中文关联书目数据发布方案的初步探索,还存在很多不足[23]。最后是利用BIBFRAME提供服务的一些实践项目,包括上海市图书馆开发的基于BIBFRAME模型的家谱知识服务平台[24],夏立新等应用BIBFRAME构建的科技报告语义可视化服务平台[25]等。
2.2 新型书目框架的实施难点
新型书目框架的实施是一项十分复杂的工作,面临很多难点。基于国内新型书目框架的理论和应用现状,实施难点主要包括三部分:一是数据基础存在质量问题,例如著录字段缺失、著录字段错误、著录字段混用、著录形式不一致和规范文档缺失等;二是相关采编人员的素质和技能有待提升,需要转变传统观念;三是在新型书目框架的实施过程中,需要在层次识别、元数据互操作和转换工具开发等一系列问题上进行技术突破,目前还没有成熟的解决方案。新型书目框架的实施需要图书馆相关参与方共同合作,还有很长的路要走。
2.3 新型书目框架的实施建议
新型书目框架实施过程中面临的难点主要包括三部分,下面将分别针对这三部分提出相应建议。
2.3.1 重视书目数据的质量问题,对著录条例和编目规则进行重新修订
当前书目数据存在很多质量问题,这些质量问题给新型书目框架的实施带来了很大障碍,例如层次识别中无法实现字段的精确匹配。因此今后应该对书目数据的质量问题予以重视,对著录条例和编目规则进行重新修订,并建立相关规范文档,解决书目数据存在的著录字段缺失、著录字段错误、著录字段混用、著录形式不一致和规范文档缺失等问题。
2.3.2 通过相关培训和课题培养新型书目框架下的采编人员
BIBFRAME对于图书馆而言是新事物,BI BFRAME的实施需要培养大量采编人员。虽然目前很多业务都可以通过自动化系统完成,但人员仍然是图书馆各项业务和流程的关键因素。书目数据在应用BIBFRAME之后,编目方式发生了根本改变,对采编人员提出了较大挑战。因此,需要通过相关培训和课题帮助采编人员提升专业技能,转变传统观念,从关联的角度出发理解书目记录,在关注书目记录的存储、管理和维护的同时,对外部数据集进行分析和评估,拓展图书馆资源的利用范围。
2.3.3 对新型书目框架实施过程中的各个步骤展开全面研究
新型书目框架的实施可以大致分为6个步骤,具体流程如图4所示,包括层次识别、元数据互操作、开发编辑器及转换工具、数据发布、建立SPARQL端点以及利用新型书目框架提供服务。针对各个步骤的具体建议如图4所示。

图4 新型书目框架的实施流程
①按照BIBFRAME的层次结构设计符合书目数据特征的层次识别算法。BIBFRAME将书目数据按照层次结构划分,改变了传统MARC格式的扁平结构。这种方式可以更好地展示书目关系,加强书目数据之间的关联。为了实现书目数据的逐层聚集,可以按照BIBFRAME的层次结构设计符合书目数据特征的层次识别算法。在这个过程中,最重要的就是对各层次的具体内涵和书目关系进行分析,必要时还要在应用层次识别算法的同时进行一定的人工干预。
②利用元数据映射的方法实现两种元数据方案的互操作。MARC和BIBFRAME作为两种不同书目世界观指导下的书目框架,分别有各自的元数据方案。为了实现两种元数据方案的互操作,可以采用元数据映射的方法。在元数据映射的过程中,除了将MARC字段、子字段和指示符与BIBFRAME的核心类和属性进行对应转换外,还需要通过相关词表进行规范控制,同时解决语义相关问题。MARC与BIBFRAME的元数据映射是一项庞大而复杂的工作,需要循序渐进地推广。
③以开源软件为基础开发符合实际需求的BIBFRAME编辑器及转换工具。目前,国外已经发布了一系列有关BIBRAME的开源软件,例如美国国会图书馆网站上提供的配置文件编辑工具、记录检索工具、BIBFRAME编辑器以及MARC至BIBFRAME转换工具等[26]。MARC至BIBFRAME转换工具同时包含比较服务和转换服务两个功能,通过比较服务可以对比转换前和转换后的数据准确性和完整性,通过转换服务则能够实现书目记录从MARC格式至BIBFRAME格式的自动转换。为了实现数据格式转换,可以利用这些开源软件进行二次开发,在利用已有先进技术的同时减少开发成本,开发出符合实际需求的BIBFRAME编辑器及转换工具。
④通过学习前沿技术实现数据发布,并在此基础上开发新一代图书馆系统。BIBFRAME的技术门槛较高,完全应用语义万维网,涉及互联网和图书馆领域的多项前沿技术,传统图书馆系统很难满足其需求。因此图书馆的技术和开发人员需要认真学习有关数字图书馆协议、规范和查询语言等方面的技术,开发适合新型书目框架的新一代图书馆系统。目前很多系统开发商和平台提供商都在开发相应的服务平台,例如Intota、VTLS和Open Skies等。
⑤利用新型书目框架实现各类型和各机构的资源整合,转变传统资源组织观念,提供一体化服务。BIBFRAME的通用性和普适性较强,它试图建立一个独立于编目规则的可以容纳各类型和各机构资源的书目环境。因此,图书馆应该转变传统资源组织观念,实现“大资源”组织。利用BIBFRAME强大的包容能力实现各类型和各机构的资源整合,为用户提供一体化服务。图书馆整合的资源类型,除了传统的图书、期刊等资源,还应包括各种网络资源和多媒体资源。此外,图书馆还要努力实现与档案馆和博物馆等机构的资源整合。
3 结语
新型书目框架是在经历卡片目录格式和MARC格式等阶段后成形的。根据目前的理论和应用现状,笔者分析了实施过程中的难点,并提出了相应建议。新型书目框架的实施难点主要集中在数据质量、人员技能和技术突破等方面。新型书目框架消除了图书馆与外界的壁垒,使书目数据更加开放、更加共享,新型书目框架是时代发展的必然趋势。
猜你喜欢
都市人(2022年3期)2022-04-27
现代交际(2021年15期)2021-11-25
新世纪智能(数学备考)(2021年9期)2021-11-24
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
办公室业务(2015年23期)2015-11-26
科技传播(2015年13期)2015-09-16
科技视界(2012年11期)2012-08-15
全国新书目(2009年1期)2009-04-13
