
基于双池化与多尺度核特征加权CNN 的典型牧草识别
2020-07-07 06:10:30肖志云赵晓陈
农业机械学报 2020年5期
肖志云 赵晓陈
(1.内蒙古工业大学电力学院,呼和浩特010080;2.内蒙古工业大学内蒙古机电控制重点实验室,呼和浩特010051)
0 引言
内蒙古自治区是我国重要的草原畜牧业生产基地,全区草场面积达8 666.7 万hm2,占内蒙古土地面积的76.5%,约占全国天然草场面积的1/4[1]。深入研究牧草是合理利用草地资源、实现国家可持续发展的重要途径。实现牧草生长趋势的精准检测、研究牧草物种多样性等都需要对牧草进行准确分类。目前,牧草识别主要由人工完成,费时、费力,且精度较低。
随着机器视觉技术的发展,众多研究者以叶片的颜色、纹理、形状等视觉特征研究植物叶片识别方法[2-7]。首先使用特定的图像分割算法将叶片与背景分离,然后通过将提取到的叶片的颜色、纹理、边缘等多个特征相融合的方式研究植物叶片识别方法,利用多种聚类和分类算法建立识别模型,获得了较好的识别结果。上述方法是从图像分割与叶片特定特征的提取出发,对植物叶片进行分类识别,而当存在光照变化、背景复杂、叶片重叠等自然因素影响时,图像分割效果会受到影响,提取到的特征也会发生较大变化。因此,基于图像分割与提取特征的识别方法在自然环境下效果不理想。
自ALEX 等[8]提出AlexNet 卷积神经网络模型以来,卷积神经网络大量应用于图像分类研究中[9-13]。文献[14]在对稻飞虱与非稻飞虱进行图像分类研究时,首先使用迁移学习在ResNet-50 框架上训练,然后通过Mask R-CNN 对其进行分类识别,平均识别精度达92.3%;文献[15]在对花卉品种进行分类时,提出一种将卷积神经网络与随机森林相结合的方法,相比手工提取特征方法,有效提高了识别率。与手动提取特征的方法相比,基于深度卷积网络的图像识别方法无需图像分割,可自动提取特征,且提取的特征不受光照变化、背景复杂等环境的影响,适于自然背景下的图像识别。
上述基于卷积神经网络的识别方法虽然提高了识别精度,但采用的都是一种池化方式,且对特征没有按重要性进行区分,不能充分利用图像所包含的信息。本文针对自然背景下牧草图像难识别的问题,充分利用牧草图像信息,设计一种基于双池化与多尺度核特征加权的卷积神经网络结构,以有效提高网络的识别精度。
1 样本集获取
通过两种方式获取牧草图像:首先在自然场景下使用相机对牧草图像进行采集;其次通过网络爬虫爬取互联网上的图像对数据集进行补充。通过对上述方法获得的牧草图像进行筛选后,共保留紫花苜蓿、红三叶、鸡眼草、紫云英等10 类2 110 幅牧草图像,且每幅牧草图像的背景各不相同,牧草区域有大有小,光照强弱也有不同。图1为本文需识别的10 类牧草图像,表1 为数据集中各类牧草的数量。

图1 本文需识别的牧草种类Fig.1 Forage species images to be identified
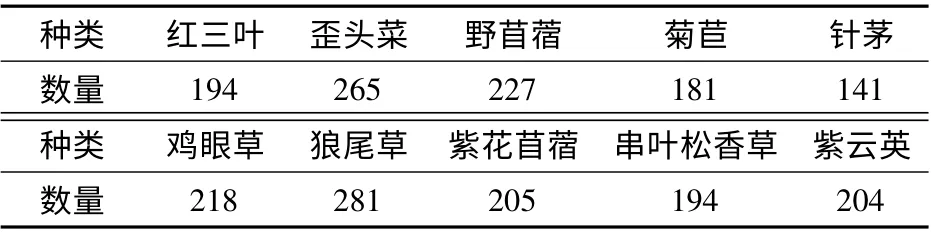
表1 样本集中各类样本数量Tab.1 Number of pastures in sample set
2 卷积神经网络基本框架及优化
2.1 卷积神经网络基本框架
本文网络是在VGG-Net[16]结构基础上改进而来,VGGNet-13 结构如图2 所示,图中,Conv 代表卷积核,Max Pooling 代表最大值池化,Avg Pooling 代表均值池化,FC 代表全连接层。网络采用了卷积层堆叠的结构且在每2 个卷积层后接1 个池化层,网络共包括10 个卷积层和5 个池化层,其中卷积核尺寸为3 ×3,池化层采用Max Pooling。
2.2 函数选取及网络优化
为提高网络对特征分布的拟合能力,卷积神经网络通常在卷积层和全连接层后引入非线性激活函数。常用的激活函数为ReLU 激活函数,其表达式为
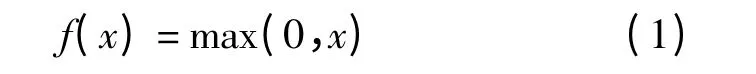
式中 x——输入特征值
f(x)——输出特征值
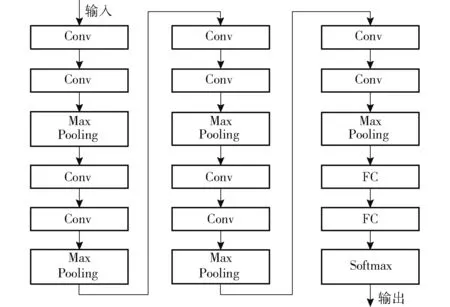
图2 VGGNet-13 结构Fig.2 Network layer parameter
由式(1)可知,当x <0 时ReLU 函数的输出为0,训练时会造成神经元失活,因此本文网络的非线性激活函数采用ELU[17]函数,其表达式为
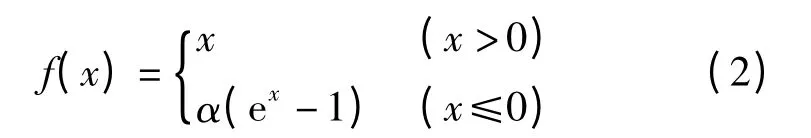
式中 α——伸缩因子
α 控制ELU 负值部分何时饱合,在本文中取值为1。
由式(2)可知,ELU 函数在x≤0 部分是一个指数函数,因此不会出现神经元失活问题。
在最后1 个池化层后引入了Global Average Pooling[18]层,可以大量减少网络参数,有效地防止过拟合,甚至在很多网络中都使用它来替代全连接层。为提高网络非线性同时保证识别精度,本文并没有取消全连接层而是将其参数设为512,之后是Softmax 层用于对牧草图像分类。
采用Adam 优化器最小化损失函数。由于数据集中的样本之间存在差异,必然存在网络容易学习的样本和难以学得的样本,因此采用Focal loss[19]代替交叉熵作为网络的损失函数。以二分类为例,交叉熵表达式为
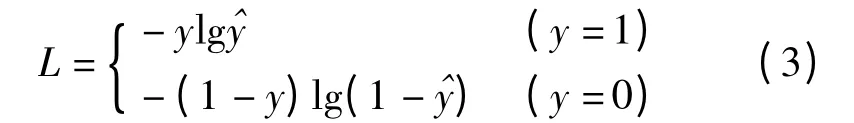
L——交叉熵损失函数值
Focal loss 的表达式为
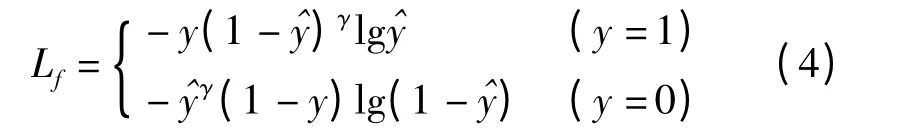
式中 Lf——Focal loss 值
γ——指数调控因子
由式(4)可知,Focal loss 在交叉熵的基础上引入了γ 因子,当γ >0 时^y 值越大的样本有更小的损失函数值,因此Focal loss 可以使网络在训练时更加关注于难以学得的样本,经实验测定,当γ =5 时效果最佳。
3 双池化与多尺度核特征加权结构
3.1 双池化特征加权结构
池化层是卷积神经网络的基本结构,池化可以在保留主要特征的同时降低特征维度,减少卷积神经网络的运算量,最常用的有Max Pooling 和Average Pooling。
Max Pooling 选取池化区域内最大值作为特征值,其表达式为
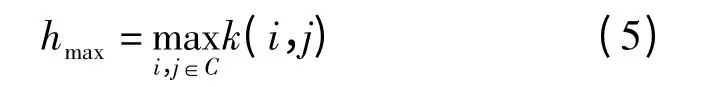
式中 C——池化窗口内(i,j)的取值集合
k(i,j)——池化窗口内位置为(i,j)的像素值
hmax——池化后的值
Average Pooling 选取池化区域内的平均值作为特征值,其表达式为
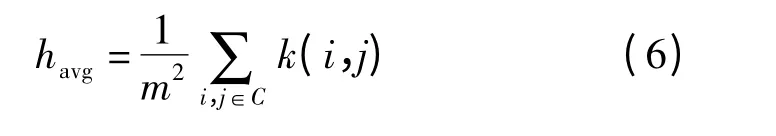
式中 havg——池化后的值
m——池化窗口尺寸
研究表明Max Pooling 能够更多地保留图像纹理等显著性信息[20],而Average Pooling 则更多地保留了图像的局部空间信息[21]。目前大多数卷积神经网络只选取一种池化方式,会造成更大的信息损失,为充分利用特征信息可以同时使用这两种池化方法。
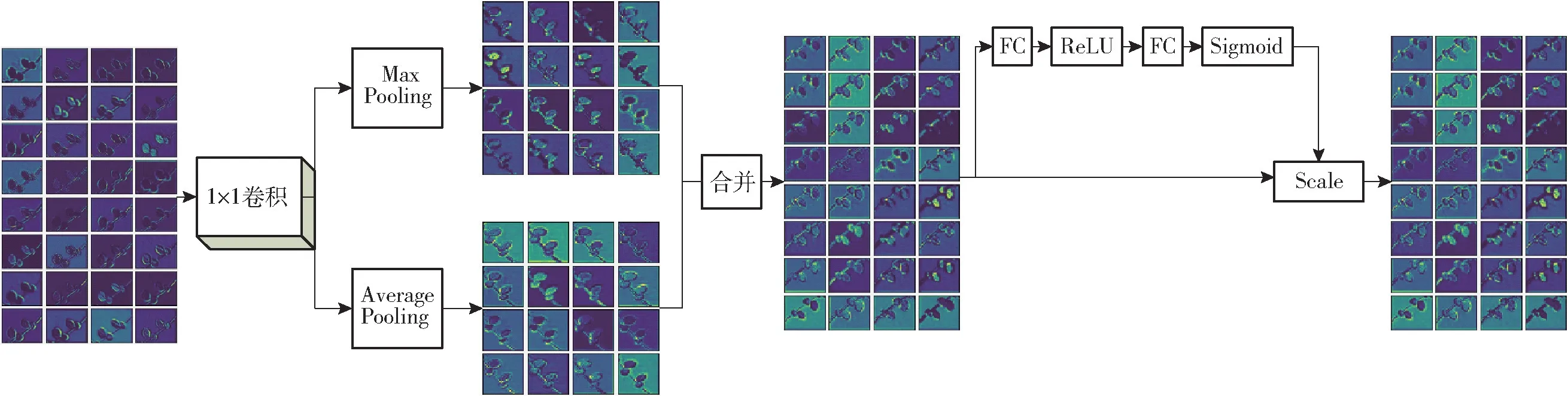
图3 双池化结构Fig.3 Double pool structure
结合SeNet(Squeeze-and-excitation networks)[22]提出了一种双池化卷积神经网络结构,其结构如图3所示。首先对上一个卷积层输出的特征图进行1 ×1卷积操作,将特征图的个数降为原来的1/2,然后对降维后的特征图分别进行最大池化和平均池化操作得到两组特征图,之后将这两组特征图进行拼接。
图4 为两种池化方式单独使用时测试集的识别率随训练次数的变化曲线,从图中可知,两种池化对识别结果的影响不同,因此将拼接后的特征图直接输入到下一个卷积层不合理。为解决这个问题,引入SeNet 中的特征重标定策略,即通过学习的方式自动获取每个特征的重要程度,然后依照这个重要程度对特征进行加权,从而提升有用的特征并抑制对当前任务作用较小的特征。
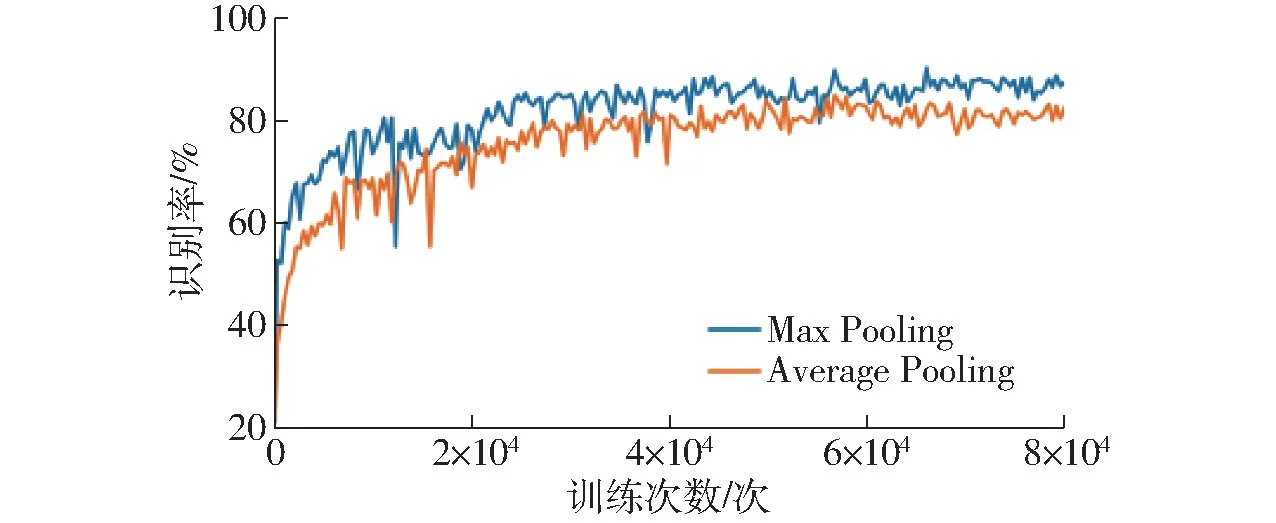
图4 两种池化方式识别率对比Fig.4 Accuracy rate graph of two different pooling methods
如图3 右半部分所示,首先对拼接后特征图进行Global Average Pooling 操作,将H ×H ×C 的特征图变换为1 ×1 ×C 的向量,其中H 为特征图的尺寸,C 为特征图的个数。然后将此向量先后输入到2 个全连接层,第2 个全连接层输出向量中的元素即为池化层拼接后对应特征图的权重,之后将该权重与原特征图相乘得到新的特征图,最后将新特征图输入到下一个卷积层。在此过程中引入全连接层的目的在于使网络能够在训练过程中通过学习不断地调整特征图的权重,直到其最大程度地满足于当前任务。
如图5 为训练过程中权重分布图,由图可知,在训练开始阶段权重分布变化幅度比较大,随着训练的进行权重分布逐渐趋于稳定,说明在本文双池化结构中引入特征重标定策略后其权重在网络训练过程中不断调整,直到其收敛于最优权重。
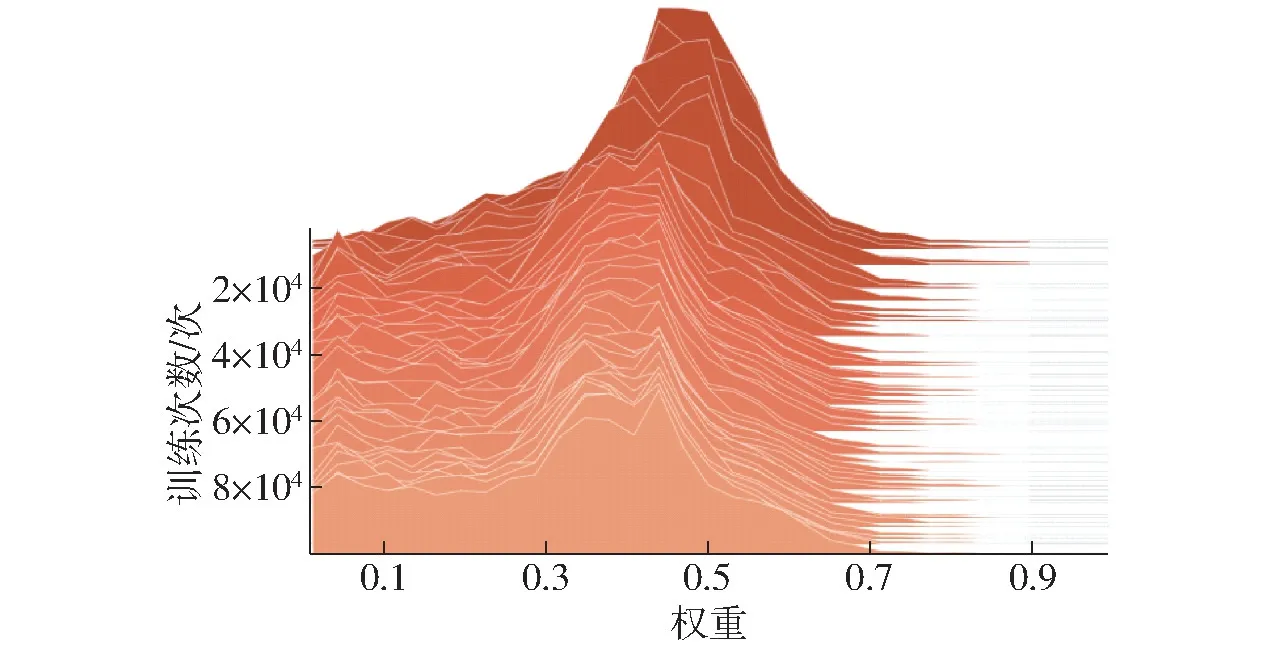
图5 网络训练过程中权重分布变化Fig.5 Weight distribution change diagram duringnetwork training
网络训练完成后,若最大池化层产生的特征图的最小权重大于平均池化计算出的特征图的最大权重,则说明相对最大池化,平均池化层产生的特征图对当前任务的贡献很小,这种情况下引入平均池化将失去意义。
表2 为网络训练完成输入1 幅图像后,提取的第1 个双池化结构中Max Pooling 和Average Pooling各特征图的权重,即各特征图对当前任务的重要程度,结合图4 可知,虽然在2 种池化单独使用时Max Pooling 的整体效果优于Average Pooling,但并不是Max Pooling 中所有特征图对当前任务的重要程度都高于Average Pooling,说明本文方法是可行的。
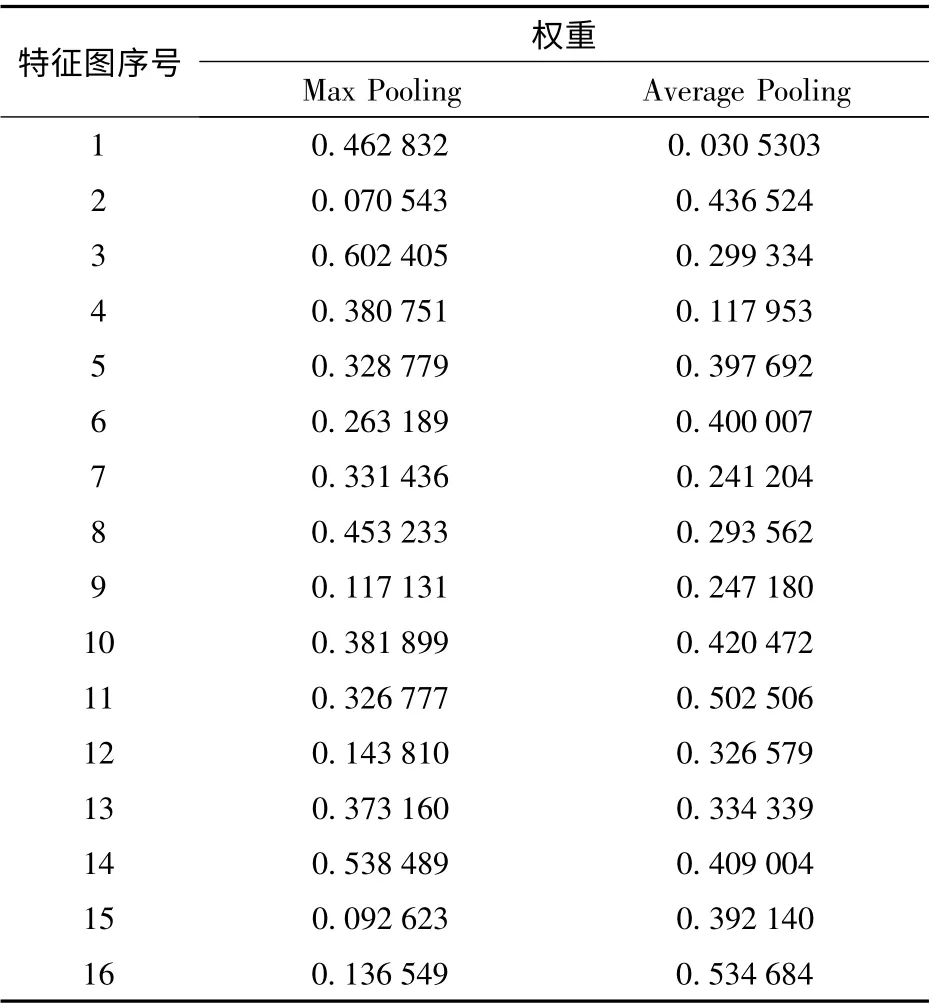
表2 两种池化方式所得各特征图权重Tab.2 Weight values of each feature map obtainedby two pooling methods
3.2 多尺度核特征加权结构
在卷积神经网络中,不同尺寸的卷积核对图像的感受野是不同的,小尺寸的卷积核与图像进行卷积操作得到的特征能更好地反映图像的局部特征,大尺寸的卷积核则能更好地反映图像的全局特征[23],为增强网络适应性,本文使用两种尺寸卷积核的组合来对牧草进行识别,但网络的运算量是随着卷积核尺寸的增大而增大的,卷积核太大则会造成海量的运算量。因此本文只对比了尺寸为3 ×3、5 ×5、7 ×7 的卷积核与3 ×3 卷积核组合后对网络识别率的影响,实验结果显示3 种组合的识别率分别为92.76%、94.10%、92.81%。
由以上结论可知,在3 ×3 卷积核中引入5 ×5 的卷积核后识别率提升了1. 34 个百分点,而在3 ×3 卷积核中引入7 ×7 的卷积核后网络识别率提升并不明显,因此本文使用3 ×3卷积核与5 ×5卷积核组成Conv block 结构对牧草图像进行识别。
为充分利用特征信息,引入了Densenet[24]中的特征复用思想,即网络任意两层之间都有直接的连接,每一层的输入都是前面所有层输出的并集,而该层所学习的特征图也会被直接传递给其后面所有层作为输入。其表达式为
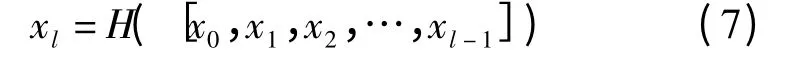
式中 xl——第l 层特征图
H(·)——ELU 激活函数
这样在提高特征利用率的同时减少了参数量[25];网络更容易训练,并且稠密连接的正则化作用在少量的训练集中能够有效降低过拟合[26];加速卷积神经网络反向传播时梯度的传递,在一定程度上缓解了随着网络的加深而产生的梯度消失问题和模型退化问题。上述Conv block 和复用特征组成的结构如图6 所示,具体操作如下。
Conv block 操作:首先将上一层得到的特征图输入到1 ×1 卷积层,目的是减少特征图的数量,以减少运算量;然后将降维后的特征图分别输入到3 ×3 卷积层和5 ×5 卷积层,同样为减少计算量将3 ×3 卷积核分解为1 ×3 卷积核和3 ×1 卷积核,5 ×5 卷积核分解为1 ×5 卷积核和5 ×1 卷积核。
特征复用操作:将经上一个Pooling block 层或输入层输出的特征图和与当前Conv block 之间所有Conv block 输出的特征图进行拼接,之后经过一组1 ×1 的卷积核进行降维。
经过上述操作后,共产生3 组特征图,之后的操作是将这3 组特征图进行拼接。同样,在此也引入特征重标定策略,对拼接后的特征图进行加权以增强有用特征,抑制无用特征。

图6 多尺度特征加权结构图Fig.6 Multi-scale feature weighted structure
图7 为网络训练完成后提取的各层输出的特征图,由于相邻2 层提取的特征图区别较小,因此每2个Conv block 模块提取1 次特征图。由图可以看出,网络Conv block2 模块输出的特征图包含了牧草图像空间、颜色等混合信息,但图像的背景部分仍然存在;Conv block4 和Conv block6 的特征图更多地包含了牧草图像的纹理和轮廓等不变性特征,而图像背景部分已经基本消除;Conv block8 层则更多保留了各类牧草之间有区分性的特征,而Conv block10 输出的特征图则代表了与类别相关的信息。以上分析表明,随着网络层数的加深,特征的抽象程度和稀疏程度也越来越高,且提取到的图像特征主要是牧草特征而非背景,因此本文网络能够有效提取牧草特征。
4 实验与结果分析
对紫花苜蓿、针茅、狼尾草、紫云英等10 种典型牧草进行识别研究,所选软件平台为Anaconda3 中的spyder,使用Python 语言和Tensorflow 深度学习框架进行图像预处理和卷积神经网络的搭建;硬件平台为计算机,处理器为IntelCore i5-8400,GPU 为GTX1060,6GB 显存。
4.1 数据集扩充与图像预处理

图7 网络各层提取的特征图Fig.7 Feature map extracted from each layer of network
首先将获得的样本尺寸调整到128 像素×128 像素,然后按4∶1的比例将初始数据集随机分为训练集和测试集。由于卷积神经网络参数较多,在训练过程中极易发生过拟合,因此在对网络训练之前需要对初始样本的训练集进行扩充。常用的数据扩充方法有平移、旋转、亮度变换、添加噪声等。数据扩充应结合具体研究目标的特点,不能随意扩充,例如形状是牧草主要表征之一,在数据扩充时不应改变牧草形状。另外扩充的图像与原图像之间应有一定差距,但同时要尽多地保留原始图像中牧草的相关特征。例如在对图像进行平移时,若平移的像素点太少,则平移后的图像与原图无异,在这种情况下反而会加重网络过拟合,若平移过多则会丢失较多的牧草信息。因此在对图像进行平移变换时,将平移的范围限制在10 ~30 像素,在旋转变换时只进行了90°、180°、270°的旋转,其他数据扩充方式也遵循以上思想。数据扩充分3 次进行:第1 次,通过旋转、平移、裁剪和填充将数据扩充为原训练集的7倍。第2 次,考虑到在自然条件下光照强度对识别结果影响较大,因此对上述扩充后的图像进行亮度变换扩充至原训练集的14 倍。第3 次,对原始训练集进行添加噪声和水平镜像变换。最终扩充后的训练集是原训练集的16 倍,且每次扩充后网络识别率均有提升。对样本集进行编号分类并制作标签,扩充后各类牧草数量及各类牧草的标签如表3 所示。

表3 扩充后的训练集中各类样本数量Tab.3 Number of samples in expanded training set
在使用卷积神经网络对图像进行处理之前首先对图像进行标准化操作,表达式为

式中 X——图像样本 μ——样本均值
σ——样本标准差
X*——标准化的样本
采用Adam 优化器对网络进行训练,批处理容量为60,采用指数衰减的学习率,基础学习率0.002 2,学习率衰减系数为0.99,L2正则化系数为0.000 7,模型迭代次数为100 000。
4.2 实验结果分析
图8 为使用VGG-13 对牧草数据集训练时的相关曲线,由图8a 可知,训练集识别率在训练10 000 次时已经达到100%,而测试集识别率仅为70%。由图8b 可知,训练集上的损失值在训练50 000 次后已经接近0,而测试集上的损失值在0.3附近,由此得知在直接将VGG-13 在牧草图像数据集上训练时会发生过拟合,为验证本文网络的有效性,本文对VGG-13 网络各层参数进行了调整,使其适应于牧草数据集。
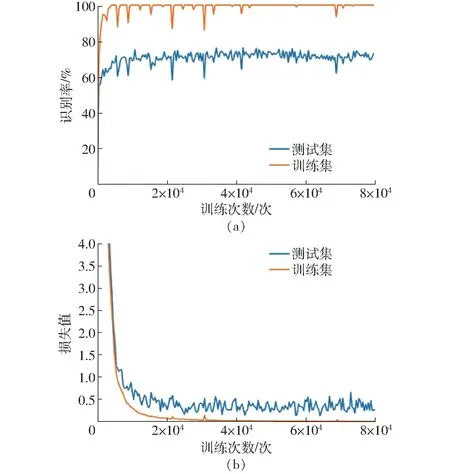
图8 VGG-13 在牧草图像数据集上相关曲线Fig.8 Correlation curves of VGG-13 on pasture image dataset
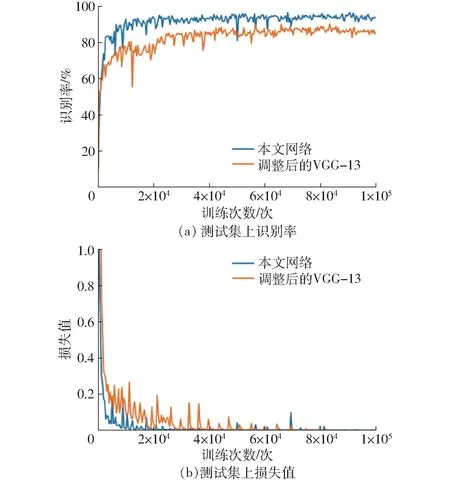
图9 本文网络与调整后的VGG-13 相关曲线Fig.9 Comparison of network and adjusted VGG-13 correlation curves
图9 为调整后的VGG-13 与本文网络在测试集上的识别率和在训练集上的损失值曲线对比图,结合图8a 知,调整后的VGG-13 相比调整前识别率有了明显提高,而相比调整后的VGG-13,本文网络的识别率更高。由图9b 可知,本文网络的损失值在迭代20 000 次时已经接近0,而调整后的VGG-13 在迭代近40 000 次才接近0,因此本文网络明显收敛更快。
为验证本文方法的有效性,将调整后的VGG-13、调整后的VGG-13 +双池化结构和本文网络在单类样本测试集上进行了对比,其识别率如表4 所示。由表4 可得知,调整后的VGG-13 结构只有5 类牧草识别率超过90%;VGG-13 +双池化结构有8 类牧草图像识别率超过90%,其中有3 类牧草地识别率超过了95%,紫云英的识别率达到100%;本文网络除鸡眼草外,识别率均超过了90%,其中有5 类牧草超过了95%,针茅的识别率达到100%。由以上分析可知,3 种网络中本文网络在对单类样本识别中表现最好,其次是调整后的VGG-13+双池化结构,调整后的VGG-13 网络表现最差。结果表明本文提出的牧草识别方法在单类样本上是有效的。
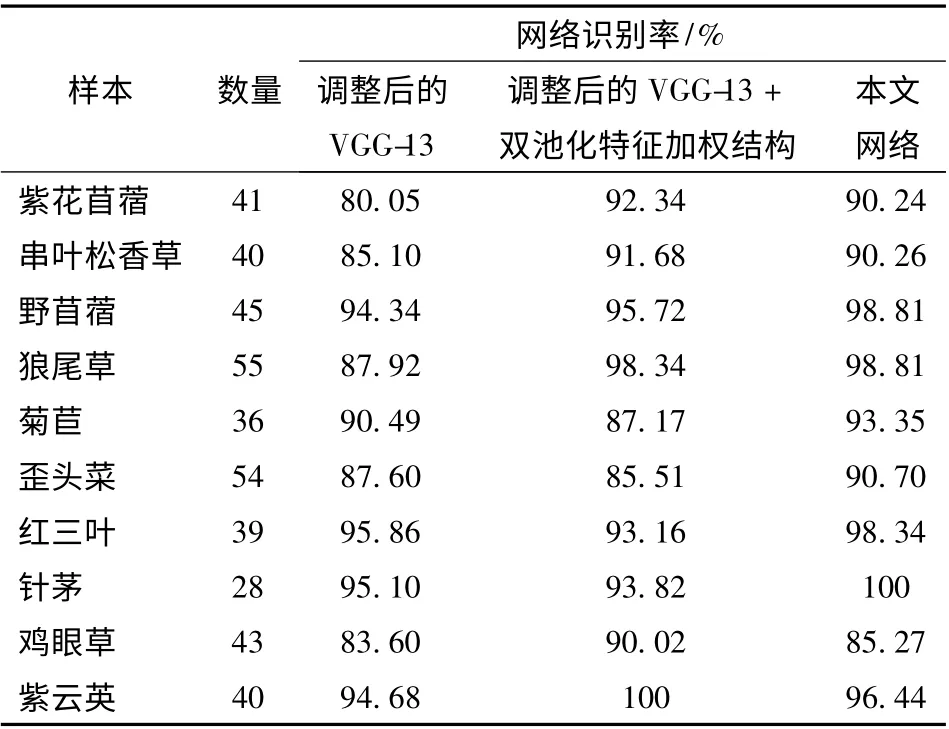
表4 各网络在训练集中各类样本上的识别率Tab.4 Recognition rates of various networks on various samples in training set
为进一步分析识别率差异的原因,本文提取了部分分类正确和分类错误的图像类激活热力图,分别如图10、11 所示。
由图10 可知,对于能够正确分类的样本,其对分类有贡献的区域主要集中在牧草所在区域,尤其是与各牧草有显著差异的部分,如红三叶图像中“V”形白色纹理部分,紫云英叶基部分,紫花苜蓿的叶尖部分。
由图11 可知,对于错分样本,可以分为3 种情况:第1 种情况是图像对分类起作用的区域是背景而不是牧草本身,如图11b、11e、11f、11g、11i,原因是在原图像中背景叶片的特征更为明显,网络在分类时误将背景叶片作为目标叶片,进而导致错分。第2 种情况是图像中牧草叶片个数过多,单个叶片区域过小,使网络无法提取有效特征,如图11a、11h。第3 种情况是图像对分类起作用的区域是牧草叶片部分,但却将类别错分,如图11c、11d,原因是原图像中牧草区域专有特征不明显,对分类起作用的区域与其他牧草相似,从而导致分类错误。由以上分析可知,歪头菜识别率较低主要由第1 和第2种情况造成,紫花苜蓿则由第1 种情况造成,而在鸡眼草被错分的样本中均存在这3 种情况。

图10 分类正确图像的类激活热力图Fig.10 Class activation thermal maps of correct image classification

图11 分类错误图像的类激活热力图Fig.11 Class activation thermal map of classification error image
表5 为各网络在单幅图像运行时间和在测试集上平均识别率对比。由表5 可知,VGG-13 网络的识别率最低且所用时间最长。本文网络比调整后的VGG-13 网络在训练集上的平均识别率高5.7 个百分点,但运行时间却只多了0.035 s,证明本文提出的方法是有效可行的。网络各层参数设置如
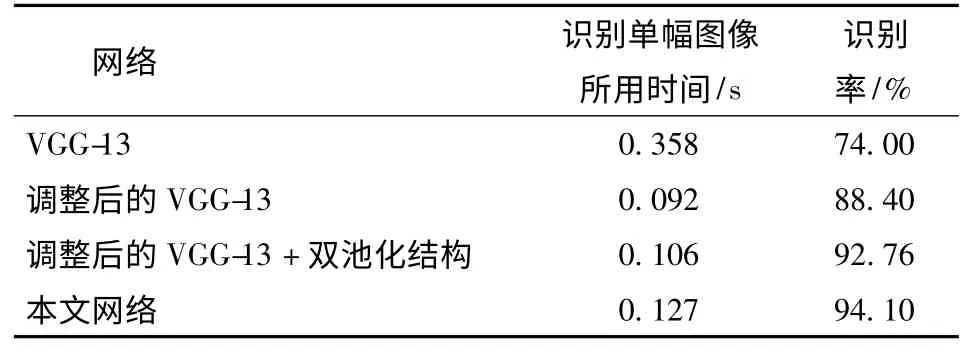
表5 各网络测试集平均识别率与运行时间对比Tab.5 Comparison of average recognition rate and running time of each network test set
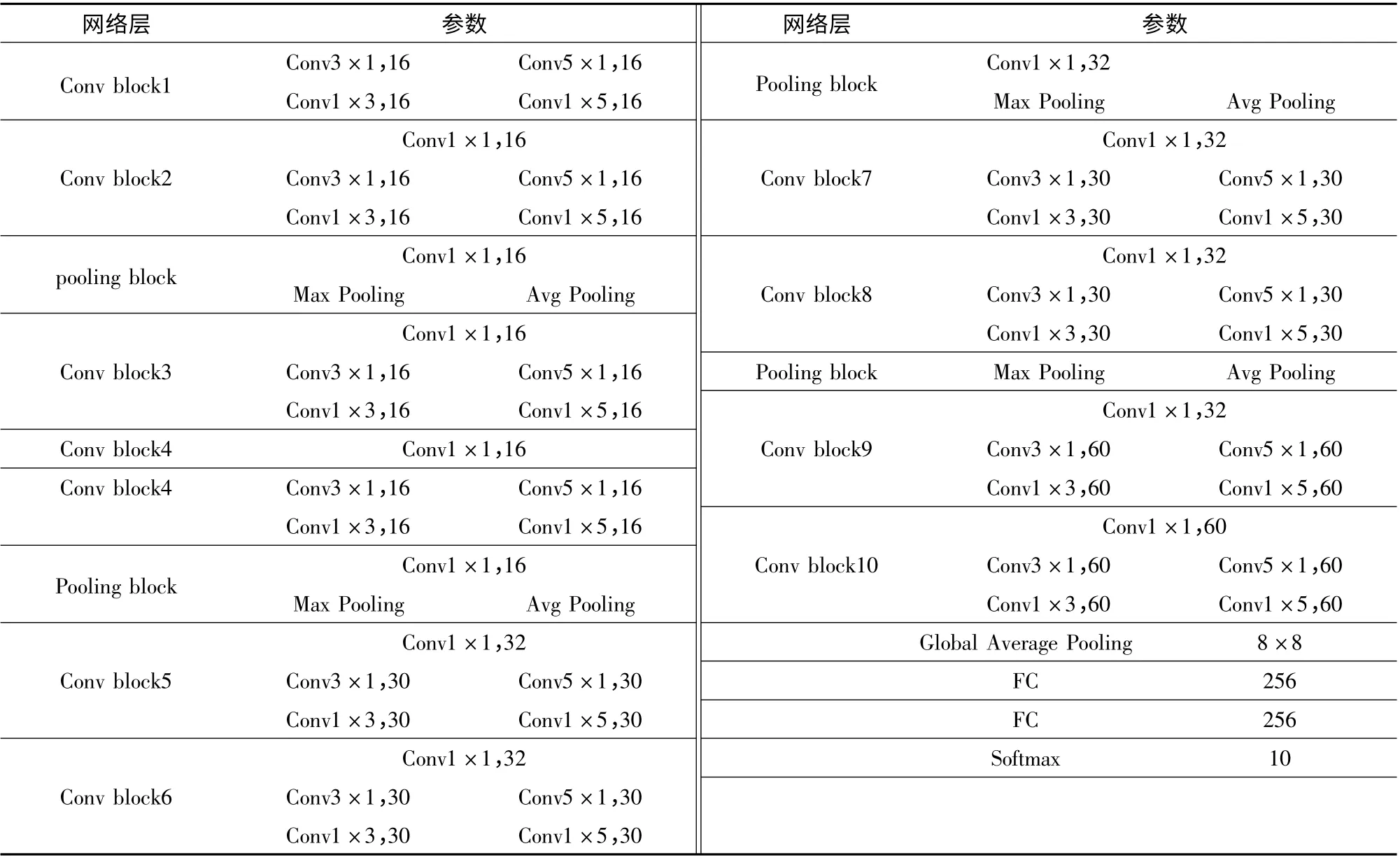
表6 网络各层参数设置Tab.6 Network layer parameters
5 结论
(1)提出的方法能够更充分地利用图像包含的信息,且在测试集上的平均识别率达到了94.1%,明显优于VGG-13 网络。
(2)提出的网络结构在训练时,网络的收敛速度是VGG-13 网络的2 倍以上,说明本文网络可以大幅提高网络收敛速度。
(3)对10 类牧草进行单独识别时,本文提出的方法识别率优于VGG-13 网络,且有9 类牧草识别率超过90%,其中有5 类牧草识别率在95%以上,证明本文所提出的方法能够对牧草图像进行准确识别。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27 05:35:46
科学技术与工程(2023年3期)2023-03-15 10:34:12
软件导刊(2022年3期)2022-03-25 04:45:04
今日农业(2021年10期)2021-07-28 06:28:00
计算机工程(2020年3期)2020-03-19 12:24:50
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
——黔南扁穗雀麦
贵州农业科学(2019年1期)2019-02-20 02:09:54
计算机技术与发展(2019年1期)2019-01-21 00:56:38
中国交通信息化(2018年3期)2018-06-13 03:27:58
中国交通信息化(2016年2期)2016-06-06 07:28:02
