
基于卷积神经网络的单目深度估计
2020-07-06 13:35王欣盛张桂玲
计算机工程与应用 2020年13期
王欣盛 ,张桂玲
1.天津工业大学 计算机科学与技术学院,天津 300387
2.天津市自主智能技术与系统重点实验室,天津 300387
1 引言
深度估计是计算机视觉中的一个重要课题。随着人工智能技术的不断发展,越来越多的智能产品逐渐问世。计算机科学、模式识别和智能控制技术的逐步发展和融合,能够对周围环境进行感知的技术和自主运动的技术也越发成熟。这些技术都离不开对图像深度的估计,所以对图像的深度估计在所有的自主导航技术中都有着宝贵的研究价值。
深度估计在无人驾驶汽车、机器人等领域中有着广泛的应用。深度估计在三维重建的课题中起着至关重要的作用,可以对现有的识别任务进行改善,如3D 建模、机器人运动[1-2]等。在出现深度学习技术之前,若完成场景中的物体距离估计需要通过多个摄像头和激光雷达等设备,设备昂贵且笨重。随着深度学习技术的不断更新,出现了越来越多的算法通过深度神经网络来完成图像深度的估计,最新的研究已经可以通过单目相机来完成深度估计,如Moukari 等人[3]在单目深度估计的方向中提供了有效的方法。但是如果将单目深度估计作为监督回归问题来解决,需要大量地面深度和场景中各个物体的具体距离,不仅步骤复杂,而且设备相当昂贵,导致没有足够密集标注深度信息的数据集。本文提出了一种无监督的端到端网络进行深度估计,计算左右视图差来对图像进行像素级的密集预测[4],结合Deeplab[5]语义分割模型设计了一个全新的深度估计模型,通过对KITTI街道数据集进行训练,可以对任意一张街道图像进行深度估计。优点是预测深度只需一个摄像头,不需要其他工具即可进行密集估计,相比传统方法方便快捷,在无人驾驶汽车以及机器人中有着更大的应用空间。训练过程不需要任何深度数据,对左右图像进行拟合,利用计算左右视差的损失函数即可完成深度估计。模型中使用空洞卷积[6]增加增大感受野,从而减少图像的下采样程度,减少原始图像中的信息损失,这也是在深度估计方向的研究中首次使用空洞卷积增加准确率。其中难点有:(1)无监督估计深度需要构建合理的网络模型,选取合适的参数,否则容易出现梯度消失或模型不收敛等情况。(2)通过左右视图视差估计需要严谨的损失函数来计算误差。(3)最后输出的深度图尽可能清晰。
本文做出如下贡献:
(1)提出一种新颖的深度估计网络架构,采用类似于DispNet[7]来进行特征金字塔的提取,并与DeepLab相结合,执行端到端的无监督单目深度估计,根据左右图像的差异来计算深度。
(2)采用编码-解码器结构,在编码器(表1)中添加语义分割层,采用多个空洞卷积并行来增大卷积核的感受野,从而减少了图像缩小的程度,使生成的图像更为清晰,可以显示更远地方的物体。
2 深度估计研究现状
虽然深度估计在计算机视觉中有着很长的研究时间,但是始终难以跨越检测硬件昂贵、笨重,计算效果与效率的很难平衡。完成视觉导航任务的传统方法通常是使用SLAM,原理是通过在梯度变化明显的图像区域中采样像素来进行直接稀疏视觉测距,但是难以摆脱测量过程复杂,在复杂环境无法测量,难以进行密集测量等缺点。随着深度学习技术的不断成熟,不断有更加高效的卷积神经网络提出,利用深度学习进行深度估计的研究也越来越受到重视。文献[8]提出了对光流预测的FlowNet框架,对深度估计的研究起到了重要作用,并得到显著的效果。最新研究也有将SLAM 与深度学习进行结合,如通过深度学习改进传统SLAM 中的漂移问题[9],通过深度学习将SLAM 的稀疏预测转化为稠密预测[10]等等。

表1 编码器结构详情
本文介绍的方法通过左右视图差进行深度估计,不需要传统SLAM 算法所需的设备。采用无监督的训练方式,不需要大量密集标注的数据集,便可以对图像进行像素级的密集预测,同时避免了在传统的单目深度估计中,与相机共同运动的物体则显示为无限远的情况。有一些现有方法也解决了同样的问题,但有一些缺点。例如,图像的形成模型不是完全可微分的,使得训练欠优[11],或者不能生成输出最大分辨率的图像[12]。
2.1 监督单目深度估计
Kuznietsov等人[13]提出的带有稀疏标注的数据集进行半监督训练,在有标注的地方进行监督训练,无标注的地方采用左右图像对比的方法生成连续密集深度图。Eigen等人[14]的采用两个网络叠加,第一个网络对图像进行粗尺度的全局预测,第二个网络负责对局部进行细化,采用大量带有标注深度信息的数据集进行训练。并通过CRF 正则化[1]对性能进行提升。Ummenhofer 等人[15]提出了Demon模型,采用Flownet模型,通过一串连续的图像中估计估计物体的运动,将深度估计作为一个运动恢复的问题。Liu等人[16]创造性地提出了一种深度卷积神经场模型,用来探究深层卷积神经网络(CNN)和连续随机条件场(CRF)相结合的性能,在多个数据集上得到优秀的效果。由于现有数据集的深度信息标签是稀疏的,无法对场景深度进行密集预测,所以无监督深度估计的优势体现在这一方面。
2.2 无监督单目深度估计
现在的无监督单目深度估计大多根据场景之间的视图差,如左右视图差和视频的前后差异来进行训练。Garg 等人[17]提出将左侧图像传入DeepCNN,再与右视图形成视图差重构出拟合图像。Godard 等人[4]提出了一种无监督的框架,用于从单目的视频中进行深度估计,可以通过没有标注的图像序列和运动的视频来进行训 练 。Poggi 等提出的 PyDNet 对 Godard 等人[4]的 框 架进行了简化,极大地减少了参数量,使其可以在树莓派等低功率的设备中运行。Casser等人[18]在最新的研究中表明,将目标检测结合到深度估计的计算中也可以得到出色的结果。
2.3 对图像进行语义分割
在之前的研究中,证实了全连接神经网络是可以有效进行语义分割,不过需要多次池化,才能使卷积核获得更大的感受野,然后在通过上采样恢复到原来尺寸,这样在反复的池化操作中丢失掉了很多信息。Chen等人[19]提出将DeepCNN 和全连接的条件随机场进行结合,同时通过空洞卷积增大感受野,从而解决语义分割中过多下采样和空间感知差等缺点。空洞卷积[15]的概念在随后的文章中提出,rate=5 的空洞卷积结构如图1 所示,在原先3×3 的卷积核中间添加4 个值为0 的空洞,在计算复杂度上与步长为1的3×3卷积核一样,却能达到11×11 卷积核的感受野。所以空洞卷积的作用是在不增加计算量的情况下增加感受野。同时并且提出ASPP,将多个尺度的空洞卷积串行连接,进一步提升了空洞卷积的使用效率。随后改进了多尺度空洞卷积的联级方式[5],比较了串行连接和并行连接两种方式的不同,进行改进之后获得的更好的结果。在串联模式中,连续使用多个扩展卷积,随着采样率变大,有效滤波器权重的数 量变小,当扩展的卷积核感受野过大,与图像的分辨率相当时,就不会捕获整个图像上下文,反而退化为1×1 的滤波器,只有中间的滤波器权重是有效的,所以连续使用扩展卷积对语义分割是有害的。为了克服这个问题,改进了ASPP模型,将提取到的特征分别通过一个1×1卷积和3个空洞卷积,将扩张率分别为6、12、18 的3×3 卷积核并联,再将这些卷积层的提取到的特征汇集在最后一个特征图上。

图1 空洞卷积图例
3 单目深度估计网络模型
本章介绍该模型如何通过一张图像来进行深度预测。网络模型分为编码和解码两部分,采用特征金字塔来提取特征。特征金字塔不同于图像金字塔,图像金字塔分别对缩小到不同尺寸的图像进行特征提取,特征金字塔在特征收缩阶段先对已提取到的特征图继续进行跨步提取,如图2所示,在底层的特征拥有高的分辨率,但是提取的信息少,高层的特征分辨率较低,但是提取到了更多的信息。高层特征在预测的同时结合低层的特征图,生成高清晰度的高阶特征图。编解码器将输入的原始图像信息转变成深度图像信息。编码器阶段利用残差网络对输入的图像提取大量特征,并且在不同的阶段对特征进行大量提取,解码器阶段对提取到的特征进行计算并进行像素级预测,得到深度图像。

图2 特征金字塔图例
3.1 编码器阶段的特征提取
在网络的编码阶段,使用深度残差网络Resnet50[21]进行特征提取。在深度残差网络中,与传统的神经网络不同,跳过一些层,将前面提取到的信息直接传到后面的层中,从而解决随着网络层数不断加深,网络性能反而退化的问题。将某些层的结果H(x)直接近似于残差函数F(x)=H(x)-x,而不是通过多层的卷积层计算得到H(x),虽然这两种计算方式都能够使结果直接地等于期望函数,但是学习到的内容有所不同,使网络模型在更深的层次中也能进行学习。
整个网络分为5个部分,conv2_x、conv3_x、conv4_x、为3个残差块,每个残差块内部具体结构如图3所示,采用跳跃连接,其中conv2_x、conv3_x的步长为2。不同于Resnet,在这个模型中,为了保留更多的信息,只把分辨率降到原始图像的1/16。通过ASPP可以极大地增加卷积核的感受野,使得网络模型可以免去过度下采样的步骤。下采样过程可以有效减少模型的参数量,如果完全舍弃下采样会出现模型参数量过大无法训练,模型容易过拟合等问题,但本文算法是根据左右视差进行深度的计算,由于左右视图的差别比较小,过度下采样会造成计算的不准确从而影响模型的精准度,所以在权衡模型参数量与计算精度后决定下采样的压缩系数为16。
网络模型中第5 部分为ASPP,是由多个扩展卷积并行连接组成的,可以对图像进行整体感知。连接如图4所示,在文献[13]中说明,空洞卷积的感受野计算方式如下:对于一个大小为3×3,步长为s,无空洞的卷积核来说,它在第n层网络中的感受野计算为:

图3 编码器结构图例

图4 残差网络图例

Rn-1表示上一层的感受野。某一层中,一个大小为k,扩张率为d的空洞卷积感受野为:
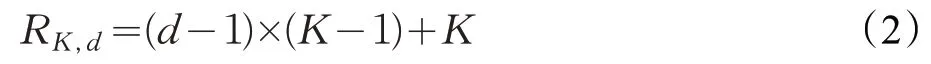
网络中ASPP 输出的结果先通过一个大小为3×3,扩张率为2 的卷积核,再通过一个1×1 和3 个扩张率分别为6、12、18 的卷积核。所以扩张率分别为6、12、18 的3×3卷积核感受野分别为18、30和42。
3.2 解码器结构
解码器根据提取到的特征图生成深度图。解码器通过叠加卷积层和池化层来提取图像特征,在空间上缩小特征映射。在文献[8]提出了一种优化池化层带来的图像粗糙的方法,将“上卷积”用于特征映射,同时接收来自网络“收缩”部分的特征进行结合来执行图像细化。“上卷积”层包括上采样和卷积,上采样层使用最近邻插值法使特征图分辨率翻倍。
解码器的结构详情如表2所示。编码其阶段由“上卷积”(upconv)、卷积层(iconv)和视差层(disp)交替组成,上采样层(Udisp)对获得的视差层(disp)使用最近邻插值使分辨率扩大一倍,从而能够和下一层进行卷积。结构流程为:首先将编码器输出作为输入,经过“上卷积”扩大分辨率。再将“上卷积”的输出,来自编码器阶段的特征图和来自上一个视差层的上采样,结合在一起进行卷积(iconv),生成视差(disp)。最后通过上采样层(Udisp)对视差层(disp)进行上采样。

表2 解码器结构详情
3.3 训练损失
这个模型计算深度的方法是通过左右图像一致性对图像进行深度估计。在DispNet的基础上增加了视差层(disp)的计算,使此网络在较高的层面上,通过推断左图像与正确图像匹配的差异来估计深度。此方法的关键部分是,可以通过从左侧采样生成右边的图像,将产生的图像与右图像(目标)对比,同时从生成的右图像产生左图形,再进行对比。使用双线性采样器生成具有反向映射的预测图像,因为这种方法可以产生完全可微分的图像,解决深度不连续处的“纹理复制”的误差,并且通过强制它们彼此一致来获得更好的深度。训练时给定左侧图像,训练目标是可以预测每个像素的场景深度f。在训练时,将左视图作为输入,右视图会在训练中用到。对于在同一时刻捕获的左右图像Il和Ir,首先尝试找到密集的对应部分dr,从左视图重构右视图,我们定义从左视图重构的图像为Ir′,同时从右视图重构左视图,定义从右视图重构的图像为Il′。d表示图像的视图差,b表示左右视图相机的距离,f表示相机的焦距,可以得到深度d'=bf/d。
由于该算法的原理是根据左右视差进行深度估计,所以模型可以在没有真实深度的情况下进行非监督训练。在解码阶段,每个阶段下都会通过损失模块对当前损失进行计算,定义损失为L,总损失L由三部分组成:

Lam表示重建的图像与对应的输入图像的相似度,Ldp表示视差图的平滑度,Llr表示预测的左右视差的一致性。
由于在训练网络中需要使用视差对输入的左右视角图进行采样,再通过双线性采样来生成图像,使用结合L1 正则化和单一尺度下的SSIM来组成我们的损失函数Lam:

SSIM(I,J)用于计算I与J两个图像的相似度,根据文献[22]提出的方案,用SSIM图像相似度函数与L1 正则项相结合作为训练中的损失函数,将文献[22]中使用的高斯滤波器用3×3的卷积核代替,将α设为0.85 时获得较好的实验效果和收敛速度。
Ldp的作用是使得视差变得平滑。通过L1 正则化来使得视差尽可能的平滑,在深度不连续的地方出现图像渐变。
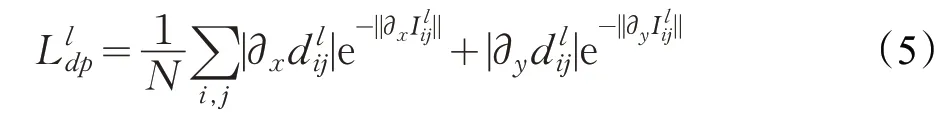
根据文献[23]中得到的结论,由于图像的不连续处常常在图形梯度变化剧烈的地方,D用于计算相邻两个像素间的像素差,使用e|i|进行像素级优化,使图像边缘变得平滑。

Llr是构建左右视图一致性的损失,在只输入左视图的前提下,同时对左右视图的视图差进行预测。为了生成更准确的视差图,再一次根据生成的右侧视图生成左侧视图,计算误差。表示由原始右视图生成的左视图,表示由生成的右视图再生成的左视图,计算两者之间的差异,同样引进L1 正则化对损失函数进行约束。
4 实验细节
4.1 数据集介绍
实验使用了KITTI[24]数据集和Cityscapes[25]数据集。该数据集通过在2个灰度摄像机,2个彩色摄像机,1个Velodyne 3D激光雷达,4个高分辨率摄像机,以及1个先进的GPS导航系统,对街道进行取景,并对车辆、行人等进行标注,是目前最大的自动驾驶数据集。KITTI数据集中有37 830张训练图片,包括28个场景,分辨率为1 242×375。对KITTI 官方训练集提供的697 张图像进行评估。实验中用到的另一个数据集是Cityscapes,其中包括22 972 张训练图片,这个数据集的分辨率为2 048×1 024。实验中进行了数据增强,以50%的几率对图像进行水平翻转,同时交换两个图像,使它们处于相对正确的位置。还增加了色彩增强,有50%的几率,对图像重新进行γ采样,随机伽马、亮度和色彩偏移。
4.2 实验具体介绍
本文实验基于tensorflow 框架实现,在ubuntu18.04系统下运行,硬件环境为GTX1080Ti。模型中包括2 449万个参数,通过47 小时的训练得到结果。在输出多尺寸的视差图时,使用非线性Sigmoid作为激活函数,输出图像的色彩范围约束在0到dmax之间,其中dmax设定为图像色彩的0.3 倍。学习率为0.000 1,训练进程到60%和80%的时候学习率减半。对于网络中的非线性,使用指数线性函数(eLU)而不是常用的整流线性函数(ReLU),因为发现使用ReLU激活函数在训练中会过早地将中间尺度的预测差异固定为单个值,从而使后续改进变得困难。在用最近邻使用Adam优化器,其中参数设置为β1=0.9,β2=0.999,ϵ=10-8。在每个残差块前面均增加批标准化(BatchNorm)[26],为了使来自不同层的特征图可以有效的合并在一起,参数decay为0.99,在实验中发现,添加BatchNorm 能够明显增加训练时的收敛速度和减少梯度消失的现象。整个训练过程共经过50 次迭代,训练时间47 小时。在训练过程中计算损失时,将4 个尺度下的损失一起进行优化。由于损失函数主要用来计算通过左右视图生成深度图的准确性,同时增加平滑项增加深度图的质量,所以损失函数的各项权重αam=1,αlr=1,αdp=0.1。实验分为两个:一种为直接通过KITTI 数据集进行训练;另一种为先在Cityscapes 上做预训练,再通过KITTI 数据集完成训练。
5 实验结果
本文实验从各个场景下的街道中取样,将KITTI官方提供的697个未训练的视差图像用于评估实验结果,这个数据集中包括29 个不同的场景。在表3 中列出了该实验结果与相同条件下其他的实验数据之间的对比,其中Abs Rel、Sq Rel、RMSE、RMSE log 这 4 个指标的数值越小越好,δ<1.25,δ<1.252,δ<1.253这3 个指标为越大越好。性能均优于现有的算法。标题后面的“k”表示使用KITTI 数据集训练,“cs+k”表示使用KITTI和Cityscapes两个数据集训练。从实验效果图中抽取了几张有代表性的图像,在图5中展示了本文实验的效果图与Godard等人的实验效果图对比,可以看出,使用空洞卷积提取特征,除了可以正确估计深度外,可以将原图不同的物体清晰的表现出来,可以增强模型对图像整体的感知,一些原本与背景融合的物体重新展现出来。但是如果使用扩张率过大的卷积核,反而会使图像变模糊,不能拟合出正确的图像。在第一个例子中,例如原图中与背景融合的电线杆在我们的效果图中完整的展现出来,并没有出现断裂,第二个例子地上的柱子和地面完全分割开来,第三个例子体现出人物和树木等事物的轮廓更为清晰。通过对比可以看出,如果图像中出现与远处事物颜色相近的物体,在Godard 的算法表现欠佳,而在本实验中可以准确表达。图6选取了一些具体的事物的差别。Cityscapes数据集中测试的效果图如图7所示。
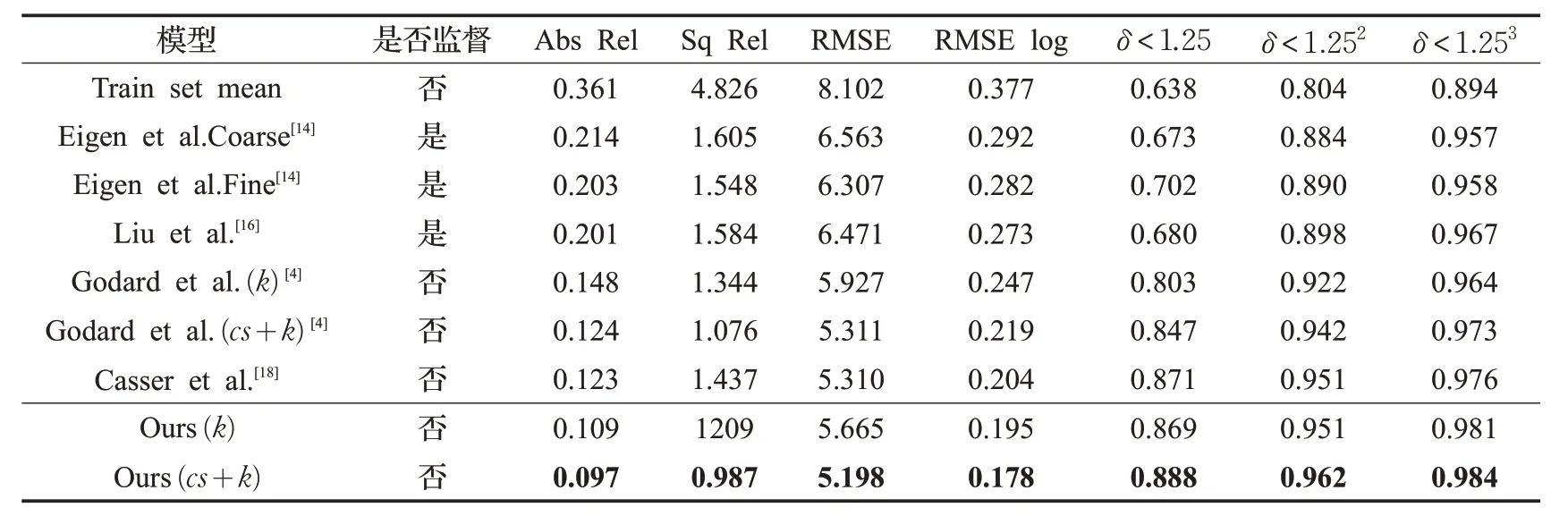
表3 实验数据对比
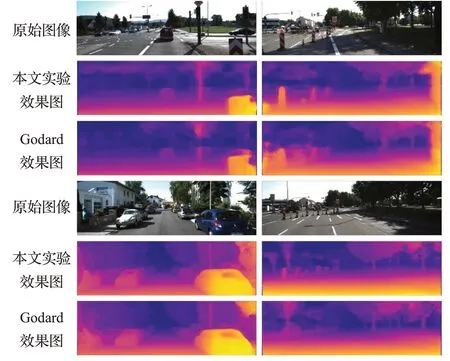
图5 深度图整体效果对比

图6 深度图具体细节效果对比

图7 Cityscapes数据集效果图
6 结束语
本文提出了一种基于特征金字塔结合语义分割的深度估计模型,在特征提取阶段采取深度残差网络提取特征,并结合空洞卷积对图形进行语义分割,通过大型街道数据集KITTI 和Cityscapes 的训练,使该模型可以对街道图像进行有效的深度估计,证实了在网络中添加语义分割层可以有效地提高生成图像的质量,保证图像中物体的完整性,使生成图像更加接近于原图像。在无人驾驶等方向有着重要的作用。通过左右视图生成的视图差计算深度。相比原先的算法[3],本文算法得到更好的实验数据,可以将街道场景中阴影部分的物体处理得更好,对远处物体也有更好的处理。今后的工作将从以下方面做进一步研究:
(1)从连续图像或者视频中检测深度,通过预测物体运动变化来估计深度。
(2)本文使用的是ResNet50 的网络,尝试使用更深的网络使结果更加精确。
猜你喜欢
小型微型计算机系统(2022年1期)2022-01-21
上海金属(2021年2期)2021-04-07
学生天地(2020年18期)2020-08-25
天津大学学报(自然科学与工程技术版)(2018年6期)2018-05-30
中学生数理化·中考版(2017年6期)2017-11-09
非公有制企业党建(2017年10期)2017-11-03
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
故事作文·高年级(2017年2期)2017-03-01
现代计算机(2016年3期)2016-09-23
