
基于云模型的水闸泵站远程监测数据挖掘分析
2020-07-06 04:31李晓春
上海理工大学学报 2020年3期
李晓春, 张 生
(1. 上海市青浦区河道水闸管理所,上海 201799;2. 上海理工大学 光电信息与计算机工程学院,上海 200093)
水闸泵站远程监测系统主要用于对区域内河道水位、水质等参数以及水泵、水闸等设备的运行情况进行实时监测,记录数据并形成历史数据库,以确保水闸泵站的安全运行并准确预测可能发生的水灾[1]。当前对于水灾以及水闸泵站安全预测预警方面的研究大多采用单测点模型,例如文献[2]基于我国山洪灾害雨量预警的需求,介绍了采用分布式水文模型分析临界雨量的基本思路与方法。文献[3]以南京三汊河闸门失稳风险为例,采用故障树法对闸门失稳事故进行分析。文献[4]以某近海软基拦河闸变形监测资料为基础,建立基于变形监测数据的近海软基水闸水平位移监控指标拟定方法。文献[5]结合风险分析对水闸安全监测项目的设置和测点布置等进行了研究。以上采用单测点模型的研究虽然可以在一定程度上对水灾或水闸泵站的安全进行预测预警,但实际上导致水灾以及影响水闸泵站安全方面的因素往往不止一个,水闸内外水位高低、雨量大小等都是影响水闸泵站安全的重要因素,在多因素影响环境中只考虑单因素而得到的规律有一定的应用局限性。考虑多影响因素则需要更多的监测信息,水闸泵站远程监测系统实时获取的数据是对水闸泵站安全预警的重要依据,如何分析和使用这些数据是准确预警的关键。针对水闸泵站远程监测数据库中的大量数据,关联规则挖掘方法能够提取指标属性间的关联规则,是数据分析的有效方法。文献[6]提出了基于关联规则挖掘的电力生产安全事故事件关键诱因筛选分析方法。文献[7]提出改进的FP-Growth算法挖掘隧道交通事故关联规则。文献[8]使用时间序列规则挖掘算法建立交通拥堵传导规律模型,提高交通效率。文献[9]提出了一种基于关联规则分析的电力变压器故障马尔科夫预测模型,使用Apriori算法挖掘状态参量与状态之间的关联规则以及各状态之间的关联规则。以上研究算法均采用关联规则挖掘算法辅助决策,其中Apriori算法是关联规则挖掘的常用方法。
本文采用Apriori算法提取监测数据的关联规则,为水闸泵站的安全预警提供依据。采用Apriori算法提取规则的问题之一是多次扫描庞大的数据库而造成的时间成本较高,本文采用二进制的方式存储数据。基于加权二进制的Apriori算法既能节约存储空间,又能通过二进制的“与运算”得到频繁项集,降低时间成本。为解决数据挖掘过程中监测数据实时更新的问题,采用基于增量更新的Apriori算法提取潜在规则,即利用水闸站中的闸内外水位、雨量和流量数据,引入动态更新方法对原有规则进行更新,通过对比规则对可能发生的水灾作出及时、准确的预测。
在实际情况中,水闸泵站的监测数据往往具有连续属性,数据挖掘算法无法直接处理这些数据,需要将连续属性进行离散化处理。常见的连续数据离散化方法如等距离划分方法、布尔逻辑和粗糙集理论结合的离散化算法等主观性较强,且在本质上是对属性空间的硬划分。文献[10]将云理论引入数据挖掘领域,提出了一种基于云理论的属性空间软划分方法,并将其用于煤矿安全监测数据关联规则的挖掘。本文采用云模型对连续数据进行离散化处理,该方法不仅克服了划分区间过硬的问题,还考虑了划分过程的不确定性。
本文提出了云模型和改进Apriori算法相结合的水闸泵站远程监测数据挖掘分析方法。首先利用云模型将具有连续属性的监测数据进行离散化处理,得到相应的定性概念语言值;然后利用水闸泵站中的闸内外水位、雨量和流量数据,通过采用改进的Apriori算法挖掘水闸泵站安全规则;针对不断更新的动态数据库,引入动态更新方法对原有规则进行更新,从而为水闸泵站提供比较好的安全策略。
1 云理论相关知识
1.1 云模型及相关概念
云模型由李德毅院士首次提出,是一种用语言值描述某定性概念与其数值表示间不确定转换的模型[11]。
定义1[11]云和云滴:设U是一个普通集合。U={xi,i=1,2,···,n},称为论域。设 T 为与集合 U 相联系的定性语言值,xi对于T所表达的定性概念的隶属度为μ(xi)是一个具有稳定倾向的随机数,其取值为[0,1],则称xi在论域U上的分布为隶属云,简称云。其中,每一个确定值和它的隶属度组成的数据对(xi, μ(xi))称为一个云滴。
云模型的数字特征用期望值Ex、熵En和超熵He这3个数值来表征,记作向量C (Ex, En,He),称为云模型的特征向量,它构成了定性与定量的相互映射,把模糊性和随机性集成到了一起。
期望值Ex:即论域中定性概念的信息中心值。
熵En:即不确定性的度量,反映在论域中能够被该定性概念所接受的范围。熵越大,定性概念越模糊,随机性也越大。
超熵He:即En的熵,是熵的不确定性的度量,间接反映了云的“厚度”。超熵越大,云滴离散度越大,“厚度”也越大。
1.2 云发生器
云发生器(cloud generator,CG)即通过软件实现或固化硬件实现的云的生成算法。云可以根据不同条件和不同输入输出变量生成,于是存在不同的云发生器,本文运用逆向云发生器进行属性空间软划分,运用X条件云发生器进行数据语言值转换。
由定性概念值到定量数值的过程,即从数字特征到云滴的转换过程,称为正向云发生器;则逆向云发生器就是由定量表示到定性概念的过程,即从云滴转化到数字特征的过程,如图1所示。

图1 逆向云发生器示意图Fig.1 Schematic diagram of a backward cloud generator
在给定论域中特定数值x的条件下,云发生器称为X条件云发生器[12],如果给定云的3个数字特征(Ex,En,He)和论域上的特定值x,利用X条件云发生器则可以得到与特征向量个数相对应的n个隶属度数值,如图2所示。

图2 X条件发生器示意图Fig.2 Schematic diagram of a X condition generator

云模型和云发生器能够实现定量数据与定性数据之间的相互转换,通过定量到定性的转换过程能够将原始的监测数据离散化,从而将离散化后的数据用于后续的Apriori算法,达到挖掘关联规则的目的。
2 基于云模型的属性空间软划分
本文挖掘关联规则所使用的Apriori算法,其适用的数据类型为离散型数据,但水闸泵站的监测数据为连续型,因此需要对原始监测数据进行处理。通过分析水闸泵站的监测数据和指标,可以建立属性空间。本文采用基于云模型的属性空间软划分方法[12],通过对数据归纳分析,将数字特征值与定性语言值对应起来,即可从数据中产生概念,定量的数据就可以表达成定性的语言概念以实现连续监测数据的离散化。
2.1 监测数据属性空间软划分
设水闸泵站监测数据的关联规则由m个条件属性和1个决策属性组成,则空间矢量数据p={p1,p2, ···,pm,pm+1}就是一条包含(m+1)个属性的历史监测数据,n条监测数据记录可以表示为矢量域P={p1,p2, ···,pn}。
若 集 合{C1,C2,···,Cm,Cm+1}为P的 非 空 子 集 ,Ci={C1,C2,···,Cl}为任一属性的数字特征集合,其中任意一个数字特征可能对应z个该属性的基础数据,且,都有,为P的一个划分。
本文以生成3个云(l=3)为例,选取{好,中,差}3个语言值,对水闸泵站监测数据属性空间进行软划分,方法如下:
根据水闸泵站的历史检测数据,利用1.3中的逆向云发生器算法得到属性的数字特征C(Ex,En,He)。由于本文选取云的数量为3,设中间云的特征值为C2(Ex2,En2,He2),则两侧云的特征值为C1(Ex1,En1,He1),C3(Ex3,En3,He3),其计算公式如下:
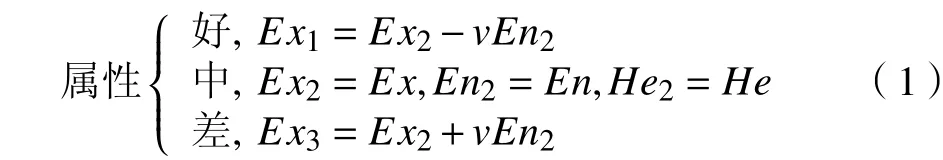
式中,v为根据实际情况选取的权值。
2.2 隶属度计算及语言值转换
对监测数据属性空间进行划分后,还需要将数据映射到对应的定性概念中。本文中任意一个属 性对 应 的 概 念集 为Ci={C1(Ex1,En1,He1),C2(Ex2,En2,He2),C3(Ex3,En3,He3)},与之对应的语言值集合为{好,中,差}。利用1.3中的X条件云发生器可以计算属性值x对概念集Ci中概念的隶属度值,记为μi={μ1,μ2,μ3}。比较隶属度大小,选取最大的隶属度对应的语言值作为属性值x的最终表现值。例如,若μ2>μ1>μ3,则x对应的概念为C2(Ex2,En2,He2),则语言表现值为“中”。
通过上述步骤,将水闸泵站监测数据属性空间进行软划分后,将历史监测数据变成了对应语言值,进而可以利用对应的语言值得到最终的关联规则。
3 考虑增量更新的关联规则挖掘方法
为了确保水闸泵站安全经济地运行,本文采用Apriori关联规则方法对水闸、水泵等设备的运行数据进行挖掘,即从运行数据中提取关联规则,从而对可能发生的水灾作出及时、准确的预测。水闸泵站监测数据库中数据量庞大,且采用Apriori算法提取关联规则需要多次扫描数据库,时间成本高。本文采用二进制的存储方式来存储数据,该方法能节省空间,且其采用矩阵乘积形式筛选频繁项集可以降低扫描数据集的次数,从而降低时间成本。考虑到数据是在动态更新的,采用传统Apriori算法需要对更新后的所有数据进行挖掘,耗时较多。为此本文采用基于增量更新的改进Apriori算法挖掘监测数据库中的潜在安全规则,从而为水闸泵站可能发生的危害做好预防措施。现将关联规则的相关定义进行介绍。
3.1 基于加权二进制的Apriori算法
关联规则挖掘作为数据挖掘中的重要方法,通过提取指标属性间的关联规则对数据进行分析。Apriori算法是关联规则挖掘的常用方法,主要通过筛选频繁项集和候选项集得到支持度和置信度,从而作为水闸安全规则的提取依据。P表示整个水闸泵的数据库,其中Tid={t1,t2,t3,···,tq}为监测记录的集合,ti(i=1,2,3,···,q)表示P中的每条行记录,且tiP。传统Apriori算法的主要概念如下。
定义1频繁项集
给定一个项集P,通过项集间的多次筛选获得候选项集Lk,若项集Lk的支持度大于或等于最小支持度,记作minsup,则称项集Lk为频繁项集,也称为频繁模式。
定义2Apriori-gen函数
通过Apriori-gen函数生成频繁k项集的操作过程包含两个步骤:连接和剪枝。将(k-1)个项集两两连接,得到候选项集Ck;对候选项集进行删减,除去一个不属于Lk-1的(k-1)个子集。
定义3强关联规则
设最小置信度为minconf,当频繁k项集的支持度 sup(P)≥minsup,置信度 conf(P)≥minconf,即频繁k项集为强关联规则。
当提取了关联规则后,会存在规则冗余或者冲突,需要进行处理。如果规则库中两个强关联规则r1和r2中的元素相互包含,若,则r2是一个冗余规则,需要删除。如果r1和r2中的元素包含性以及规则优先性相互矛盾,则规则r1和r2冲突,需要删除优先度低的规则。
针对Apriori算法执行过程中,需要多次扫描项目集、时间成本高且效率低的问题,本文提出采用加权二进制的关联规则挖掘方法。针对数据集的冗余性比较高,为降低频繁项集的效率,本文给出权重定义,即重复数据只显示一次,将重复次数与全部记录数的比值作为权重,记作w,如式(2)所示。

本文所提基于加权二进制的Apriori算法步骤如下:
步骤1对数据库P进行扫描,项目在数据库中的显示与否设置为“1”或者“0”,将重复出现的行记录只存储一次,重复次数的比值权重设置为w,并将行数与w的乘积结果存储到最后一列,得到候选集C1,依据原先设定的最小阈值,筛选出频繁项集L1。
步骤2将L1看做向量L1进行自乘,通过“与运算”连接,得出C2候选项集,扫描P得出L2,以此类推迭代。
步骤3扫描数据库k次后,且LkLk=Ck+1,即Ck+1为自乘的结果,当Ck+1=,停止数据库扫描。
步骤4获得最大频繁集Lk。
3.2 加权二进制Apriori算法的增量更新过程
Apriori算法虽然能够帮助解决规则提取的问题,但是,随着数据的不断增长,水闸泵站中的数据不断更新。采用Apriori算法挖掘更新后的数据耗时多、效率低,因此,本文采用Apriori算法的增量更新方式来获取频繁项集,无需对所有数据进行更新,可以降低时间成本,具体的方法描述如下。
本文水闸泵站的数据集设为P,新增数据集为p,则新数据集为(P+p)。采用Apriori算法可以获取原始数据的频繁项集L(P),针对更新后的数据集,本文采用改进的加权二进制Apriori算法,相关定义如下:
a. 对于原始数据集形成频繁项集为L(P),新增数据集的频繁项集为L(p),依据某项集d在P和p中为频繁项集,在(P+p)中也为频繁项集,找出在P和p中相同的频繁项集,放入(P+p)的频繁项集L(P+p)中。
b. 当项集d∈L(p)且dL(P)时,扫描数据集P得到支持度supportP,再在p中求出supportp,以及求出d在(P+p)中的supportP+p,如式(3)所示,若supportP+p≥minsup,则将d作为频繁项集L(P+p)中的一部分,反之不是频繁项集。
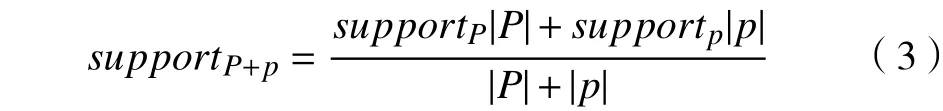
c. 当项集d∈L(P)且dL(p)时,扫描数据集p得到支持度supportP,再在P中求出supportp以及求出d在(P+p)中的supportP+p,如式(4)所示,若supportP+p≥minsup, 则 将d作 为 频 繁 项 集L(P+p)中的一部分,反之不是频繁项集。
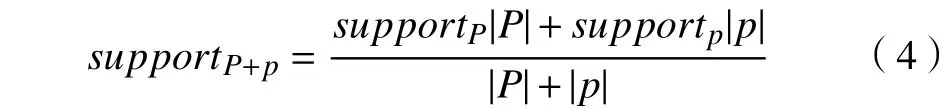
d. 若项集d在P中为非频繁项集,在p中也为非频繁项集,那项目集在(P+p)中也为非频繁项集。
基于以上相关概念,本文所提Aprioir算法的增量更新步骤如下。
输入水闸站监测原始数据集P,新增数据集p,最小阈值设定为minsup。
步骤1对于某项集d而言,d∈L(P),如果{d}=L(P+p),删除与L(p)相同的频繁项集,一直循环,直到得到既属于P也属于p的频繁项集d。
步骤2当d∈L(P),如果有事务集s∈p且ds,将d出现的次数累加为count。
步骤3当count≥minsup,将数据集d添加到频繁项集L(P+p)当中,重复步骤2,直到扫描结束,得到最终的频繁项集。
步骤4根据频繁项集提出数据的安全规则的指标,即支持度和置信度,来验证水闸站的安全性。
4 案例分析
某市地势低平,水力比较平缓,同时河道中有大量聚集沉淀的污染物,当大暴雨突然袭击时,由于城市里多余的水量很难及时排出而常常形成水涝。水涝危害市内居民安全且会造成大量财产损失,因此需要对当地水闸泵站的远程监测数据进行分析,从而对水灾进行准确的预测预警。在预测预警过程中,仅仅依靠系统监测到的闸内外水位、雨量、流量和水闸位数据并不能满足要求,还需要根据已有的数据对潜在的安全规则进行挖掘,以便对水灾进行准确的预测预警。结合某市水务局的水务监测数据和该市某水闸泵站的水闸位等记录数据,利用本文的方法对安全规则进行挖掘。其中水闸泵站监测的部分监测记录基础数据如表1所示。

表 1 水闸泵站监测基础数据Tab.1 Monitoring data of the sluice pumping station
利用基于云模型的属性空间软划分方法对表1中的监测数据集进行属性空间软划分。将监测的各项属性均看作一维语言变量,对于雨量和流量属性,定义小、中、大3个语言值;对于内外河水位及水闸位,定义低、中、高3个语言值。
以内河水位为例,对表1中数据调用逆向云算法,计算得到反映内河水位的数字特征为Ex=2.696,En=0.264,He=0.118,对应语言值为“中”。取权重v=1,则与语言值“高”对应的数字特征为Ex3=2.959,En3=0.377,He3=0.349,与“低”对应的数字特征为Ex1=2.433,En1=0.359,He1=0.330。
对表1中的初始数据进行软划分后,使用X条件云发生器计算隶属度并根据隶属度进行排序,得到如表2所示的数据。以内河数据中“3.02”为例,计算得到隶属于3个概念的隶属度分别为:0.19,0.03,0.95。可以得到结论:该值隶属于“内河水位高”这一概念的程度最大。将该结论记录到结果数据库中,该条记录在数据库中应为“内河水位=高”。

表 2 经过软划分的数据表Tab.2 Soft partitioned data
针对表2中的数据,采用改进的Apriori算法挖掘潜在关联规则。设置支持度为10%,置信度为50%,得出关联规则如表3所示。
从表3中规则可以得知,当内河水位高,雨量大且流量小,则得出外河水位低且水闸位低的支持度和置信度比较大,而外河水位低以及水闸位高的支持度和置信度较低。由此得出,当内外河水位差较大,雨量大且水流慢时,若水闸位较低,可以降低水灾的危险性。当内河水位低,雨量和流量中等时,得出外河水位高低以及水闸位高低的支持度和置信度较大,可以推出水闸位与内外河水位,雨量流量密切相关,此时雨量和流量大小直接影响水位、水闸位高度大小,与水库安全性有着直接关系。当内河水位较低,雨量和流量处于中等程度时,水闸位较低的置信度较高,水闸位高的置信度较低,说明水闸泵站的闸高度未拉开太大,才能预防水闸可能产生隐患的危险性。
5 结束语
本文针对水闸泵站监测预警的影响因素多、数据庞大的特点,提出了基于云模型的水闸泵站远程监测数据挖掘分析方法,特点如下:
a. 基于云模型的属性空间软划分方法处理水闸泵站监测数据,将数值数据转化为数据挖掘算法可用的定性概念语言值。
b. 利用二进制存储监测数据值,并通过“与运算”获取频繁项集。考虑到数据是不断更新的,采用基于增量更新的Apriori算法挖掘水闸泵站指标的规则,分析规则后的隐含意义,从而为水闸泵站可能的隐患给出预测和预警。
通过对某市水闸泵站的监测数据进行挖掘分析后得出关联规则,验证了所提方法的可行性和有效性。后续研究考虑将基于云模型的属性空间软划分方法与水闸泵站智能监测系统结合起来对实时监测数据进行转换,以呈现更直观具体的水闸泵站安全情况。
猜你喜欢
辽宁大学学报(自然科学版)(2022年1期)2022-04-26
建材发展导向(2021年18期)2021-11-05
建材发展导向(2021年18期)2021-11-05
青岛大学学报(自然科学版)(2020年3期)2020-09-30
建材发展导向(2019年23期)2019-11-28
建材发展导向(2019年10期)2019-08-24
计算机技术与发展(2019年7期)2019-07-23
科技与创新(2016年4期)2016-03-16
中国高新技术企业(2015年3期)2015-03-26
数据(2009年1期)2009-04-08
