
一种基于协同过滤和混合相似性模型的推荐算法
2020-07-06 04:30丁家满沈书琳贾连印游进国李润鑫
上海理工大学学报 2020年3期
丁家满, 沈书琳, 贾连印, 游进国, 李润鑫
(1. 昆明理工大学 信息工程与自动化学院,昆明 650500;2. 云南省人工智能重点实验室,昆明 650500)
随着大数据时代的到来,信息与日俱增,使得信息消费者难以从大量数据中获取对自己有用的信息,而数据生产者也无法使自己的信息在众多信息中得到用户的关注,这就是信息过载问题[1]。推荐系统通过收集用户的爱好、行为习惯等信息并加以分析,帮助用户快速准确地找到自己想要的信息,被认为是缓解信息过载问题最有效的方法之一[2]。目前推荐系统所采用的推荐技术主要包括关联规则(association rules)[3]、基于内容的推荐(content-based recommendation)[4]、协同过滤(collaborative filtering, CF)、基于效用的推荐(utility-based recommendation)[5]和混合推荐(hybrid approach)[6-7]等。其中,协同过滤推荐算法是推荐系统中应用最广泛最成功的推荐技术之一[8],其目标是根据已知的信息计算未知的评级[9]。主要包括基于用户(user-based)的协同过滤算法[10]、基于项目(item-based)的协同过滤算法[11]、基于模型(model-based)的协同过滤算法[12-13],它们在针对不同目标时都取得了很好的推荐效果。
但协同过滤算法仍存在着许多问题,最主要的是数据稀疏问题和冷启动问题。现实生活中用户的评分数量较少,占总项目数的比例较低,导致提取的用户偏好特征较少,推荐结果不准确,这就是数据稀疏问题。为了解决协同过滤算法中的数据稀疏问题,文献[14]从用户偏好和全局角度提出了一种基于用户偏好聚类的有效协同过滤算法,以减少数据稀疏的影响。文献[15]提出了一种基于优化用户相似度的协同推荐算法。在传统的余弦相似算法中加入了一个平衡因子,用于计算不同用户之间的项目评价尺度差异。文献[16]提出一种混合用户相似性方法,该方法在特定领域取得了较好推荐结果,但仍然存在冷启动方面的问题。为了有效解决冷启动问题,文献[17]提出了将主题模型与矩阵分解(MF)相结合的LDA_MF模型,并融合改进的结合内容与行为的LDA_CF,Item_CF算法形成混合算法,提高长尾应用的推荐率。文献[18]提出了用户时间权重信息概念,结合项目属性信息解决完全新项目冷启动问题,但过于依赖共同评分项目,在数据稀疏环境下,效果不佳。文献[19]提出一种利用多群组智慧协同过滤算法,并结合用户偏好模型,对于解决用户冷启动问题取得了较好的效果,但对于多群组数据缺失或者稀疏情况,推荐效果有待提高。
以上文献分别在解决数据稀疏和冷启动问题方面取得不错的成果,但如何有效地同时解决这两个问题有待改进。为此,本文提出一种基于协同过滤和混合相似模型的推荐算法,利用PSS(proximity-significance-singularity)模型计算不同用户在不同项目间的相似度,并将不同项目间的评分关系作为权重调整用户相似度;接着,采用用户-项目-特性和用户-项目-标签的三分图形式描述用户、项目、特性、标签之间的关系,得到项目特性和项目标签的关系权重;同时,设定用户偏好因子和不对称因子作为权重调整不同用户间的评分偏好并提高模型的可靠性;最后,结合用户时间权重信息,构成基于协同过滤和混合相似模型的推荐算法。
1 问题定义
定义1 用户相似度
假设两个用户u,v分别评价两个项目i,j,评分等级分别为rui和rvj,项目评分权重为Sitem,则用户相似度定义如式(1)所示。
式中,函数S1(rui,rvj)代表仅基于用户不同项评级的相似度,利用文献[16]中调整后的PSS模型进行计算。函数S1(rui,rvj)具体公式如式(2)所示。

Proximity函数(见式(3))用于描述用户间的评分绝对差值对相似度的影响;Significance(见式(4))函数描述用户评分与评分域中值之间的关系;rmed表示评分域中值,如果用户评级距离评分域中值较远,则此评级更为重要;Singularity(见式(5))函数描述一个评级对的均值与这两个项目的全局评分均值的绝对差值对相似度的影响,μi,μj表示项目i,j的平均评分值。
S1函数采用的是不同用户在不同项目间的相似度计算,为了使不同项目具有可比性,本文使用Sitem函数表示项目间的评分关系,并将此作为权重因子来调整用户之间的相似度。为了使其能够充分利用项目i,j的所有评分来解决共同评分的问题,这里式(6)采用调整后的标准化欧式距离进行计算。
式中:rik,rjk表示某一用户对项目i和项目j的评分值;sk表示用户评分的标准差。这里考虑没有评分的项以用户评分均值代替。为了使项目间的相似权重更为准确,将标准欧式距离进行归一化处理,使其结果在(0,1]之间,得到项目评分权重函数Sitem如式(7)所示。
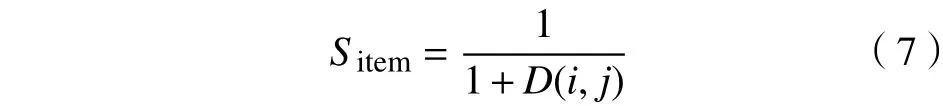
定义2项目特性信息
设fui表示用户u是否评价过项目i,fia表示项目i是否具有特性a,Ci表示项目i具有的特性个数,Ca表示共同拥有特性a的项目个数,则项目特性信息如式(8)所示。

项目特性信息描述用户、项目与特性之间的关系。如果用户u评价过项目i,则fui=1,反之fui=0;同样,如果项目i具有特性a,则fia=1,反之,fia=0。
定义3项目标签信息
设fui表示用户u是否评价过项目i,fti表示标签t是否标注过项目i,Ci表示项目i被标注的标签个数,Ct表示标签t标记过的项目个数,即拥有共同标签的项目个数,则项目标签信息如式(9)所示。

项目标签信息描述用户、项目与标签之间的关系。如果项目i具有标签t,则fti=1,反之,fti=0。
定义4不对称因子
设Iu为用户u的所有评分项目数量,Iv为用户v的所有评分项目数量,则不对称因子定义如式(10)所示。
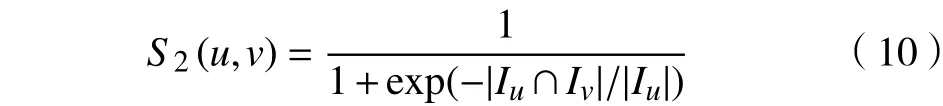
不对称因子S2通过描述两个用户的共同评分项目数量与目标用户评分项目数量的比例来强调用户间的不对称性。如果共同评分项目数量与用户u的所有评分项目数量的比例大于其与用户v的所有评分项目数量的比例,则表示共同评分项目对用户u的影响要大于用户v。
定义5偏好因子
设μu和μv表示用户u和用户v的评分均值,σu和σv表示用户u和用户v的评分标准差。偏好因子S3如式(11)所示。
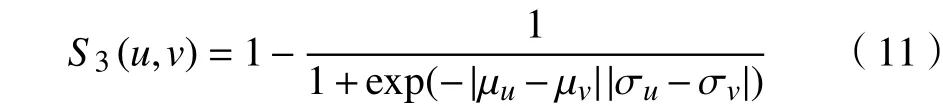
偏好因子S3通过描述用户之间评分均值和标准方差的绝对差值乘积来调整用户的偏好,减少偏好差异带来的影响。
定义6用户时间权重
在现实生活中,不同用户有不同的评级偏好。一些用户更喜欢追求新事物,这些用户为“积极用户”,其评论时间与项目发布时间间隔较短。相反,有些用户更喜欢别人给出过评分的项目,这类用户为“消极用户”,其评论时间与项目发布时间间隔较长。将用户评论时间与项目发布时间间隔作为用户时间权重信息,在推荐新项目时,优先推荐给积极用户。用户时间权重为用户评价项目总数与用户对项目的评价时间和项目发布时间的时间间隔总和的比值。设sum为用户u评价项目总数,timeui表示用户u对项目i的评价时间,datei表示项目i的发布时间,则用户u的时间权重如式(12)所示。
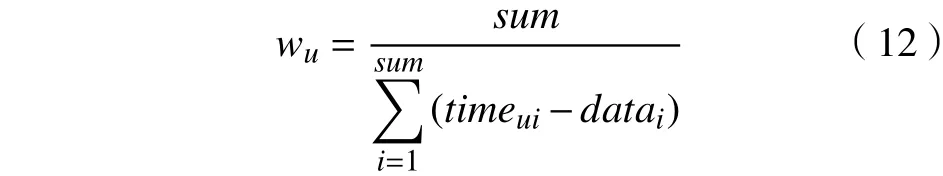
可以看出,(timeui-datei)越小,用户时间权重wu越大,说明该用户越喜爱新的事物,为积极用户;反之,说明该用户为消极用户。
算例1为了更好理解,以用户u1,u2,u3和项目i1,i2,i3,i4为例描述用户时间权重信息,具体信息如表1所示。
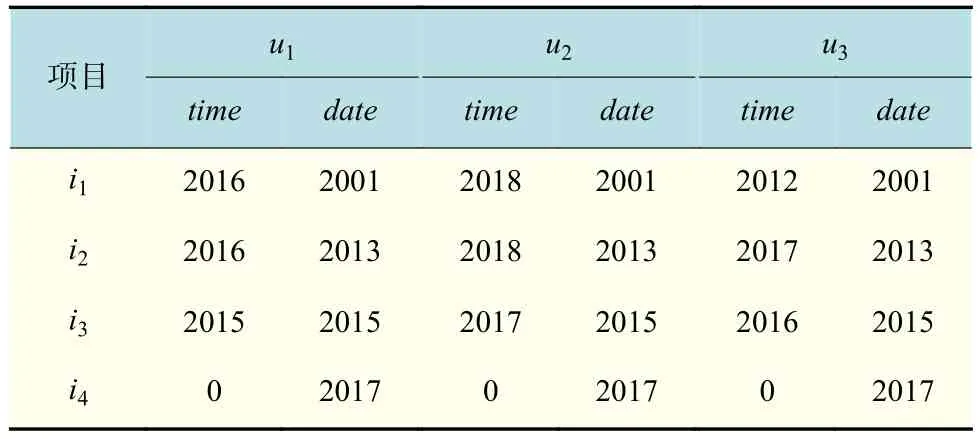
表 1 用户评价时间表Tab.1 User appraisal schedule
其中time代表用户评价时间,date代表项目发布时间,根据式(12)可以得到用户的时间权重信息如下:
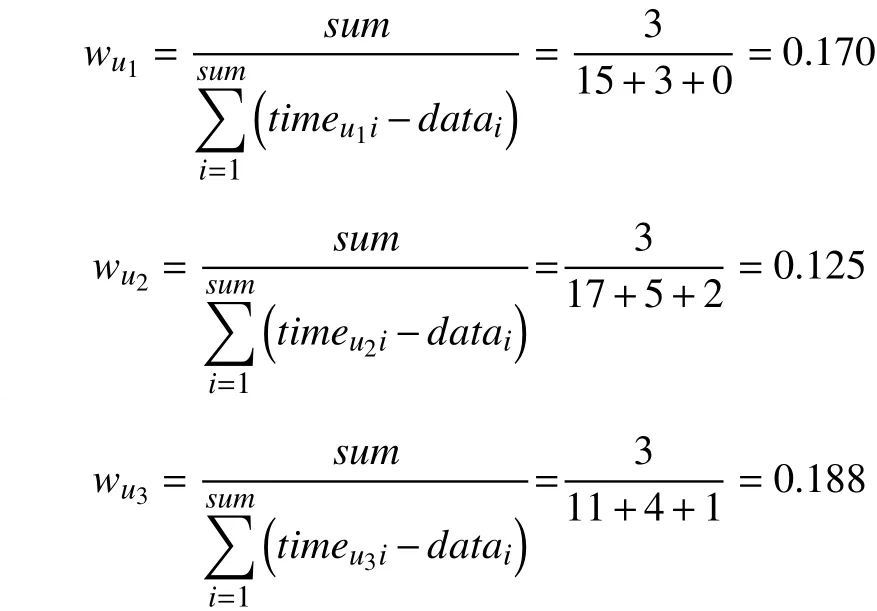
由例子可以看出,用户u3的时间权重最高,即用户u3较用户u1和u2更喜欢体验新事物,为积极用户,则优先将新项目推荐给u3。
定义7预测评分值
为了得到用户对未评级项的预测评分值,需要计算目标用户与其他用户的相似度,筛选出与目标用户相似度最高的前K个邻居用户组成邻近集,再根据预测评分公式进行计算。设preui表示用户u对未评级项目i的预测评分值,和分别表示用户u和用户v的平均评分值,rvi表示用户v对项目i的评分,K表示用户u的近邻集合,S(u,v)表示用户u和用户v的相似度,则预测评分值如式(13)所示。
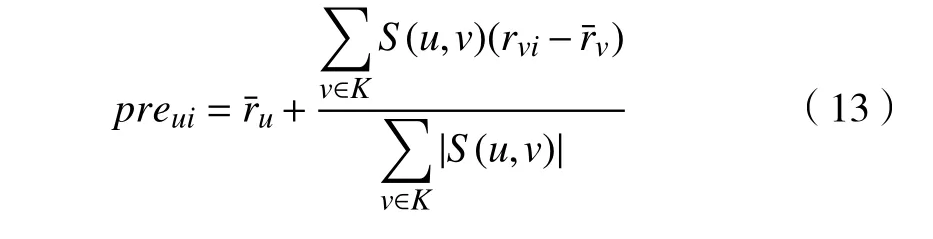
2 基于协同过滤和混合相似模型的推荐算法
传统的相似性度量多采用用户间的共同评分项进行线性计算[20],但实际情况中,数据稀疏问题使得共同评分项并不常见,变量之间通常也不存在线性关系,因此传统推荐算法的准确度也随之降低。而为了解决共同评分项问题,采用不同用户在不同项之间的评分来进行相似度计算。并且为了更好地适应非线性情况,考虑累积所有可能的评分,并将不同项之间的评分关系作为权重因子调整用户相似度。
在考虑用户评分的基础上,还要考虑项目本身的特性,特别是新项目本身没有用户行为,因此更需要结合项目特性来解决项目冷启动问题。同时,标签既能表达用户对项目的自我理解,也能体现出项目本身所具备的特征,因此结合标签信息进行推荐更能体现用户的兴趣和项目特点。
传统的相似性度量在计算用户相似度时通常将其看作对称模式[21],即两个用户间的相似影响相同。但在实际情况中,两个用户的评分数一般并不相同,相似影响也不相同。因此,设计一个不对称因子,用以强调用户间相互影响的不对称性。同时,考虑到用户都有各自的评分偏好,有些用户更喜欢评价高分,即使项目并不理想;也有些用户更倾向于评价低分,哪怕项目很好也不会给很高的评分。为了平衡用户偏好,使结果更为理想,设计偏好因子。
综上考虑,提出一种混合相似性模型如式(14)所示。
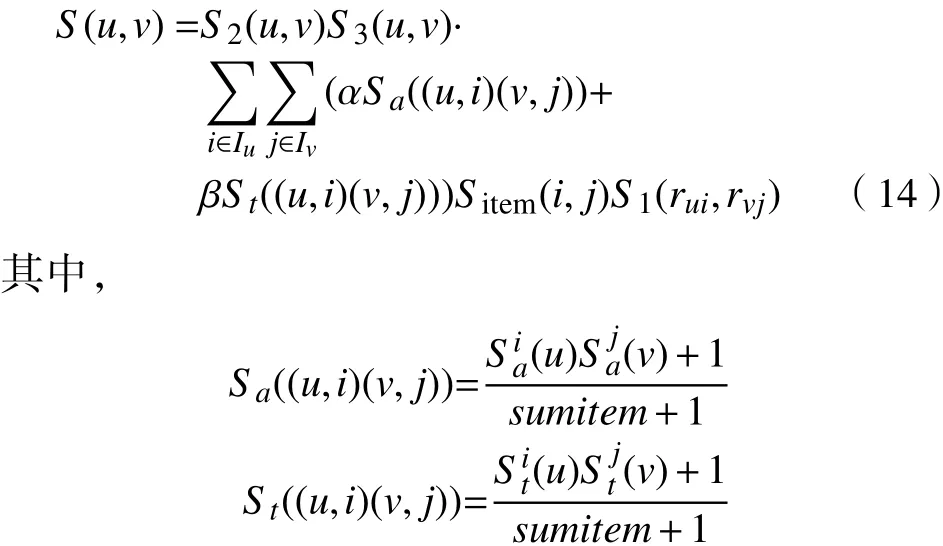
即利用PSS模型计算用户间的相似度S1,并使用项目间评分关系权重Sitem调整用户相似度;接着,描述用户、项目、特性、标签之间的关系,得到项目特性权重和项目标签权重;同时,设定用户不对称因子S2和偏好因子S3作为权重调整不同用户间的评分偏好并提高模型的可靠性,构成混合相似性模型。式中:,代表信息偏好权重,即用户对项目特性信息和标签信息的偏好比重,取值范围为(0,1),且+=1;sumitem为项目总数。
最后结合用户时间权重信息,使用预测评分公式(14)得到目标用户对未评级项目的预测评分值,结合用户时间权重信息式(12)组成式(15),实现推荐。
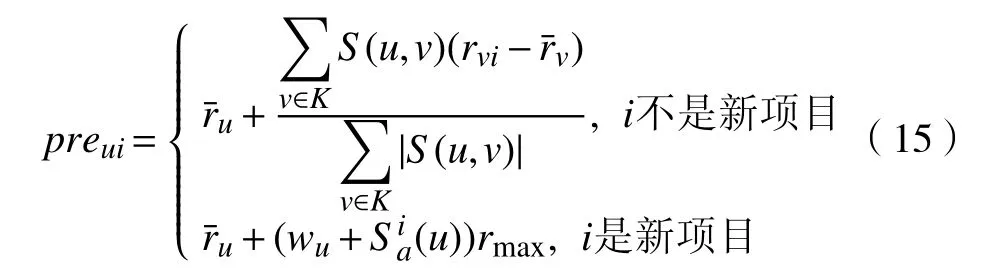
算例2为了更好地理解以上公式,下面根据用户-项目评分矩阵(表2),项目-特性矩阵(表3)以及项目-标签矩阵(表4)给出的例子进行分步说明。
表2评分为1,2,3,4,5共5个等级;表3表示如果项目具有某一属性,则设值为1,否则设值为0;表4同理。首先以用户u1为研究目标,根据表2给出的用户评分矩阵,结合式(1)计算用户u1分别与u2,u3的相似度。这里以u1,u3分别评价项目i1,i2为例,进行具体公式计算如下:
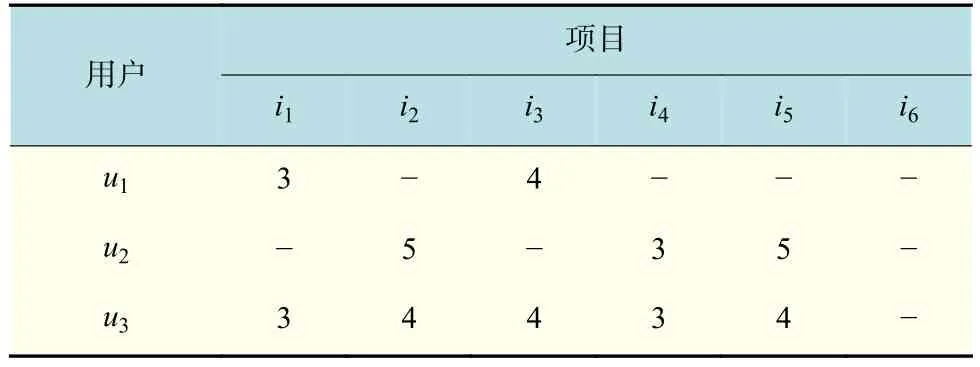
表 2 用户-项目评分矩阵Tab.2 User-item rate matrix

表 3 特性-项目矩阵Tab.3 Attribute-item matrix

表 4 标签-项目矩阵Tab.4 Tag-item matrix

为了更好地理解和计算项目特性权重信息和项目标签权重信息,以项目特性权重信息为例,将用户-项目矩阵、项目-特性矩阵转化为用户-项目-特性三分图形式,具体如图1所示。
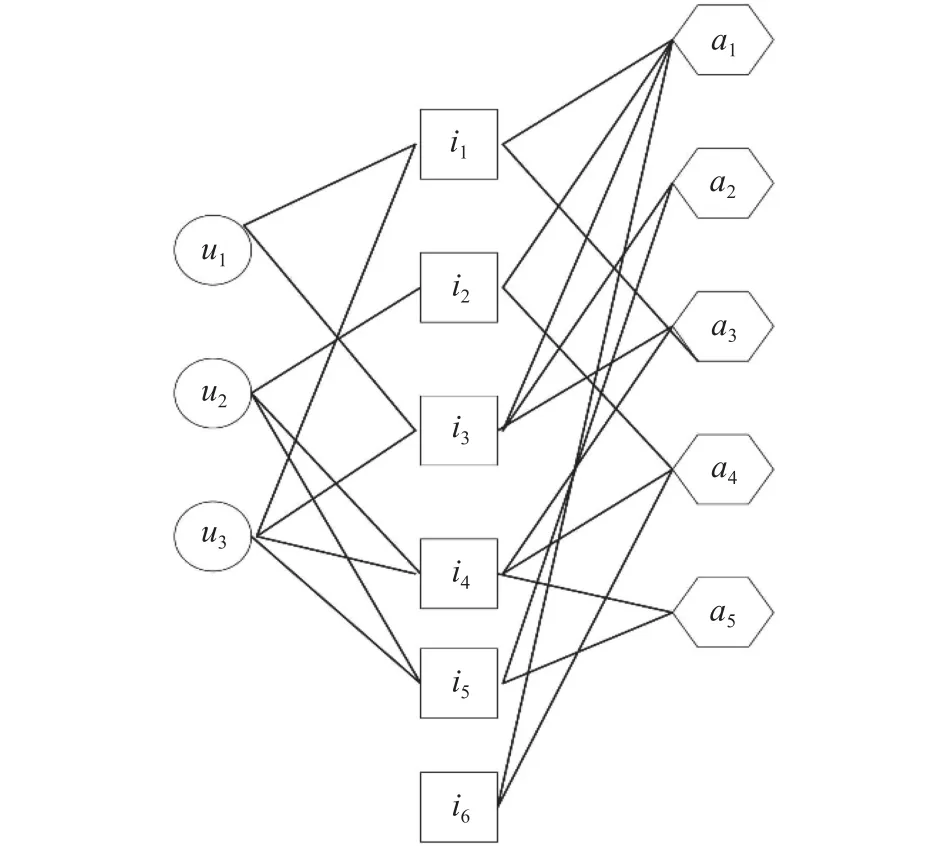
图1 用户-项目-特性信息Fig. 1 User-item-attribute information
图1 中:u代表用户;i代表项目;a代表特性。如果用户u评价项目i,则使用一条直线连接用户u和项目i;同理,如果项目i拥有特性a,则连接项目i和特性a。继续以用户u1为研究目标,根据图1可知,项目i1拥有特性a1和a3,而有3个项目共同拥有特性a1,同样有3个项目共同拥有a3,结合式(10)计算项目i1的项目特性权重为
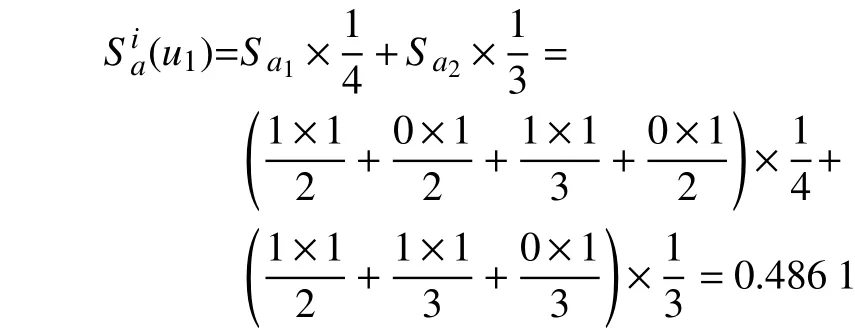
同理,使用式(9)计算项目i1的项目标签关系。然后,根据式(14)可以得到最终的用户间的相似性,如表5所示。
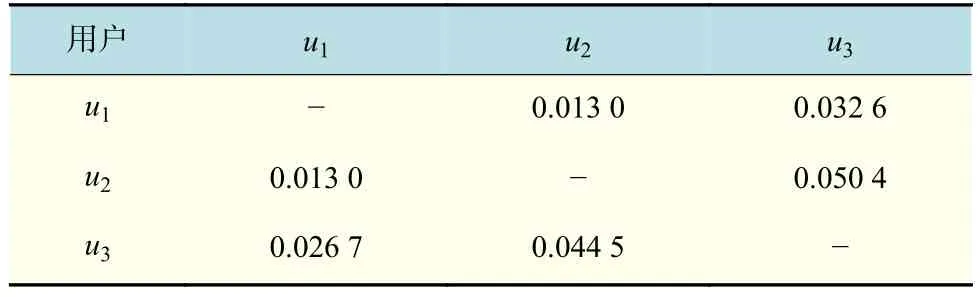
表 5 用户相似值Tab.5 Values of the user similarity
由表5可以看出,用户u1和u2没有共同评分项,但仍能根据其他信息得到相似度,说明本文方法并不依赖共同评分项,并且用户间的相似影响基本不同。最后,根据式(15)计算用户对未评级项目的评分,若该项目是新项目,则直接采用用户时间权重信息与新项目特性信息结合得到预测评分值。最后对用户的项目评级进行排序,完成Top-N推荐。
基于协同过滤和混合相似性模型的推荐算法描述如表6所示。

表 6 RCFHSM算法描述Tab.6 Description of RCFHSM algorithm
3 实验结果和分析
3.1 数据集预处理和度量标准
本实验采用的数据集是由美国Minnesota大学的Grouplens研究小组创建并维护的MovieLens数据集[22],在预处理后,将其划分为互不相交的训练集和测试集,训练集占80%,测试集占20%。
3.2 实验结果和分析
本文进行两类实验,首先采用MAE,F1-measure方法进行对照实验,验证算法的有效性;然后对数据进行再处理,采用新颖度指标进行对照实验,验证推荐算法对解决新项目冷启动问题的有效性。
实验1推荐算法的准确度。
将参数α和β取多种不同的值进行组合,分别进行准确度实验。由于推荐个数少时准确率较高,因此,首先在推荐个数为5的情况下,计算不同参数取值组和近邻集的K值影响,对K值进行选择,如图2所示。
由图2可以看出,在不同的参数组情况下取K=20时准确度最高,因此,限于篇幅,只列出K=20时一部分不同推荐个数的准确度对比,如表7所示。
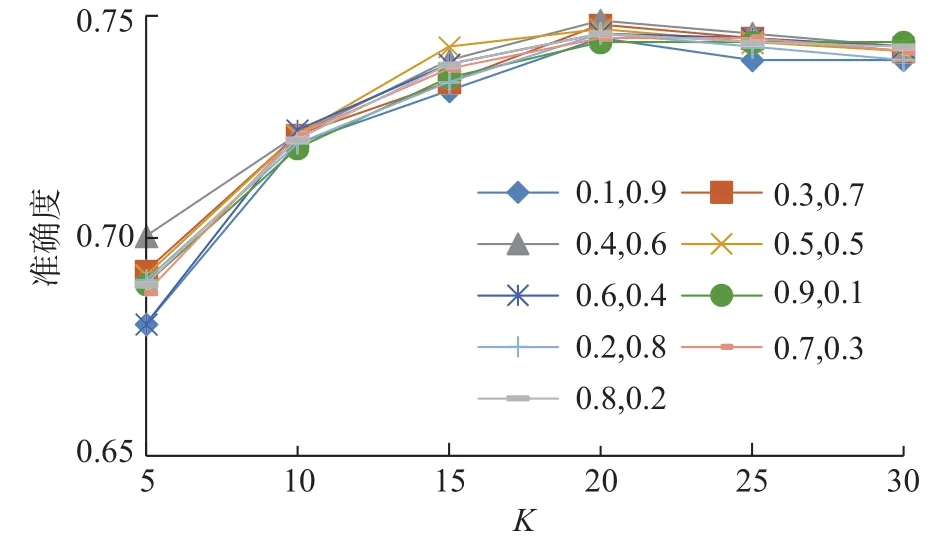
图2 不同K取值的准确度Fig. 2 Accuracy of different K values
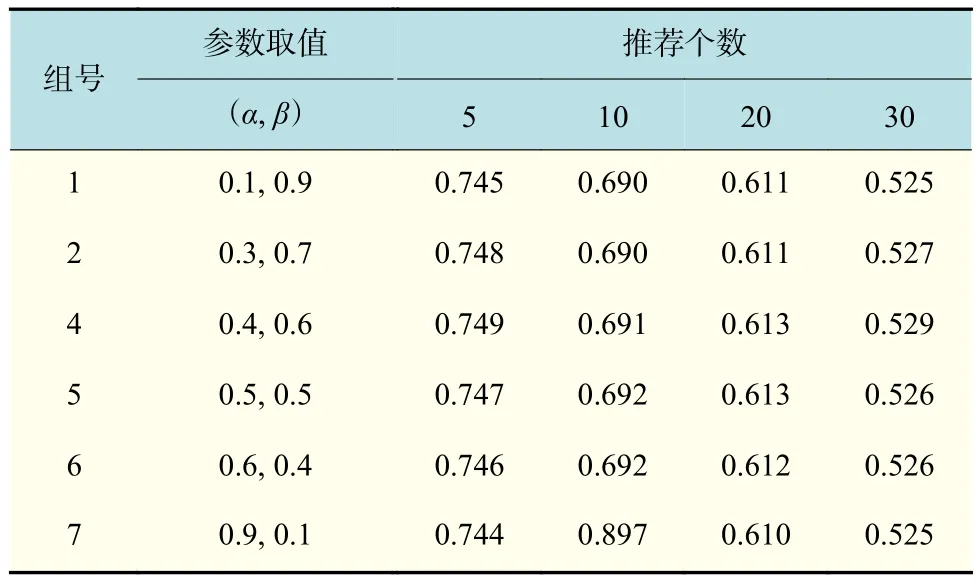
表 7 参数取值Tab.7 Parameter values
本文进行多组实验后发现,其实参数α,β对实验结果的影响并不大,说明算法本身对参数取值依赖性不大,但仍选取α=0.4,β=0.6,此时,算法在此数据集中准确率相对较好。将本文算法(简称 RCFHSM)与文献[16]中的基于用户推荐的UPCC算法、基于物品推荐的IPCC算法和混合用户相似模型(以下简称HUSM)算法进行MAE,F1-measure对比,结果如图3和图4所示。
观察两图可知,本文提出的基于协同过滤和混合相似模型的推荐算法在评估方法MAE,F1-measure上都优于其他推荐算法。这是因为相比其他算法,本文在累积所有评分项来解决共同评分项较少所导致的数据稀疏问题时,同时加入了特性权重信息和标签权重信息,提高了推荐的效果。
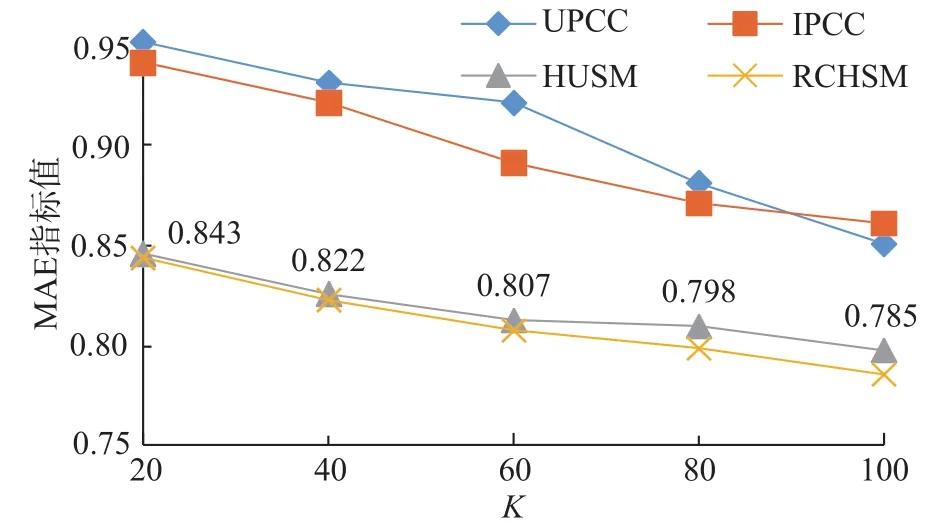
图3 MAE对比Fig. 3 MAE for different algorithms
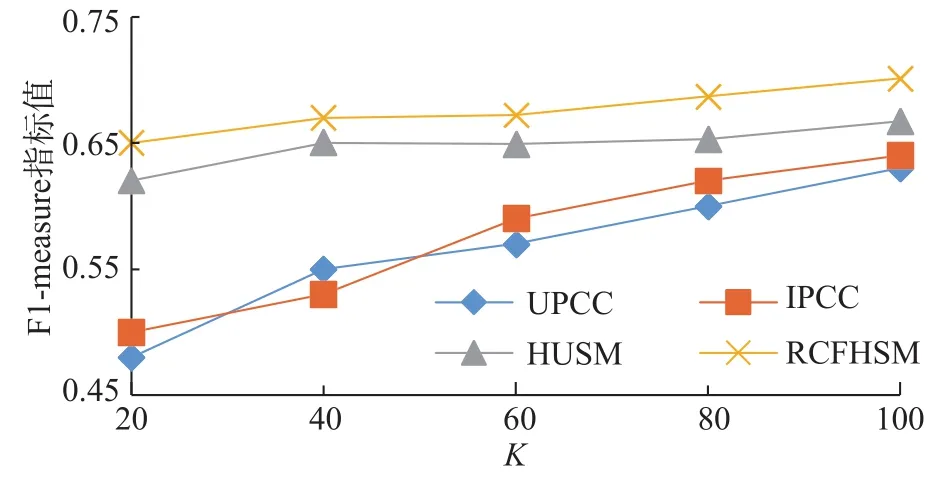
图4 F1-measure对比Fig. 4 F1-measure for different algorithms
实验2 解决新项目冷启动问题。
原数据集中不存在新项目,即用户未进行评级的项目,因此对原数据集进行再处理,在测试集中随机抽取300,500,1 000个项目依次作为新项目,训练集中对应的300,500,1 000个项目的评分信息及标签信息依次设为0。使用处理后的数据集对本文算法进行准确度和新颖度实验,因为前面的几个算法更多基于评分计算,在解决项目冷启动方面效果并不好,为此加入文献[18]的CUTATime推荐算法结果进行对比。
从表8和表9中可以看出,本文算法的新颖度优于CUTATime算法。这是因为在计算新颖度时加入了用户评分均值,从而提高了新项目的推荐比例,使新项目能够得到更多的推荐。

表 8 CUTATime算法准确度和新颖度Tab.8 Accuracy and novelty of CUTATime algorithm

表 9 RCFHSM算法准确度和新颖度Tab.9 Accuracy and novelty of RCFHSM algorithm
4 结 论
针对推荐算法一直以来的数据稀疏和冷启动问题,提出一种基于协同过滤和混合相似性模型的推荐算法。该算法通过计算用户在不同项目间的相似性来解决用户间共同评分项较少所带来的数据稀疏问题;并将项目特性权重和用户时间权重信息相结合用于解决新项目冷启动问题。在此基础上进行了对比实验,实验结果表明,本文提出的混合相似性模型合理可行,有较高的准确度和新颖度,并能有效地解决数据稀疏和冷启动问题。
猜你喜欢
重庆大学学报(2022年6期)2022-06-23
心理学报(2022年5期)2022-05-16
茶道(2022年3期)2022-04-27
汽车实用技术(2021年17期)2021-09-23
客联(2021年2期)2021-09-10
现代畜牧科技(2021年4期)2021-07-21
当代陕西(2020年17期)2020-10-28
流行色(2020年9期)2020-07-16
人大建设(2018年5期)2018-08-16
