
英文语料库研究论著前言的多维体裁分析*
2020-07-02 10:36:04无锡科技职业学院宋仁福
语料库语言学 2020年1期
无锡科技职业学院 宋仁福
提要:本文基于英文语料库研究论著前言语篇,采用自下而上的语步分析法,利用“语篇瓦片叠压”(TextTiling)技术和多特征多维度分析法,考察语篇内部的语步结构、语篇功能及词汇语法表现。研究发现,英文语料库研究论著前言平均每篇包含7个左右语步,其中约36%的前言包含4—5个语步。后续的多维分析发现,多个语步体现出前言体裁的信息表达功能,主要用于陈述研究话题、写作背景等,还有少部分语步呈现出学术论证的特点,而在靠结尾部分多出现显性劝说型表述,旨在推销所介绍的书籍。其中,显性劝说虽然篇幅不大,但最具统计学上的显著性,可见它是前言语篇的特色功能。本实验表明,整合“语篇瓦片叠压”及多维分析的无监督体裁分析法,相对于通过经典的人工识别语步进行语言特征分析的做法,不但可行,而且更为客观高效,因此具有广泛的应用前景。
1.引言
Swales(1981)首创体裁分析(genre analysis),后在Swales(1990,2004)等文献中逐步完善并定型。国际上,体裁分析主要有三大流派:ESP学派、新修辞学派和澳大利亚学派(Hyon 1996)。ESP学派关注体裁分析理论对学术英语和职业交际英语教学方面的应用,其代表人物是John Swales、Vijay Bhatia、Ken Hyland等人;新修辞学派侧重研究体裁的社会语境,以帮助大学生和新入职者理解社会功能或行为,Carolyn Miller是其主要代表;澳大利亚学派重点研究中小学及成人学校语境所用体裁的相关教学研究,该派以Jim Martin为代表。
在国内,秦秀白(1997a,2000)较早介绍体裁分析理论。2001年我国体裁分析研究进入新的发展阶段(张萍 2005),涵盖了理论探讨以及学术、商务、新闻、演讲、法律等多个领域(王立非、韩放 2015)。体裁分析法可大体分为自上而下和自下而上两种。Biberet al(2007:12-13)认为,这两种方法的主要区别在于分析步骤的顺序。若事先已确定了语步分析框架,并依此对文本进行语言分析,这是自上而下法;相反,若无既定语步分析框架,只根据语篇的语言特征进行自动聚类,从而得到语步单位,属自下而上法。目前,体裁分析多基于Swales(1990,2004)和Bhatia(1993)的理论框架,把文本切分为若干语步,多以学术论文和商业信函等为研究对象,这是典型的自上而下方法。
2.研究背景
话语社团、体裁和语言学习任务是Swales体裁分析理论中的3个主要概念。话语社团概念包含六大要素(Swales 1990:24-27),Cutting(2000:1)将其概括为:一个由拥有共同目标、内部沟通机制、特定文体和专用词汇的成员而组成的群体。体裁由具有共同交际目的的一组交际事件组成(Swales 1990:58)。对此,秦秀白(1997b:7)进一步阐释:所谓交际事件就是按照特定目的和特定程式运用语言在社会生活中办事的实例;属于同一体裁的实例可在某些方面存有差异,由于它们具有相同的交际目的,故仍可被看作是具有相同体裁的语篇;体裁的理据对语篇的内容和形式起着制约作用,同一交际社团或同一领域的人都承认并力图遵守。
前言是学术著作中的有机组成部分,是明显不同于正文的体裁。一篇好的前言可以帮助读者快速知晓写作意图、图书主旨,并提供阅读建议等。前言、序言和引言之间有一定区别。前言通常由作者本人撰写,说明书籍的写作背景、写作缘由、读者对象、阅读建议等,末尾署撰写人姓名、日期,有时也写上撰写地点;序言往往由其他人而非作者自己写作,写作人多是该领域的知名学者或同行,阐明写作人对作者、书籍等的评介,并说明该书值得一读,结尾签署写作者姓名、日期、地点;引言一般由作者自己撰写,其目的和前言类似,不过,引言中往往会涉及书籍的内容,末尾一般不写作者姓名、日期、地点等(Bhatia 2004:68-69)。
国内对书籍前言进行体裁多维分析尚不多见,国际上此类研究的数量也只有个位数。目前,前言的体裁研究主要集中在大学教科书方面。Luzón(1999)从计算机工程和电信工程学科教材中随机选取了22篇前言,文章将前言分为8个语步,研究发现,教科书前言具有信息和推销双重目的,是一种高度互动的文体,帮助读者使用本书,并说明书的价值。Azar(2012)随机选取了1970—2005年出版的语言学和应用语言学书籍前言22篇,通过建立读者关系、建立自身定位、概述章节范围、致谢四个语步,发现前言的功能是作者在竞争激烈的学术背景下推销自己的书籍,有时还对书籍创作过程中提供帮助的人表示感谢。Abdollahzadeh &Salarvand(2013)收集了2000—2011年出版的管理、冶金和数学学科英语前言180篇,研究发现3个学科前言的交际目的、总体结构、读者预期、语步结构非常相似。同样,除了常见的信息目的外,前言还担负着推销目的。Asghar(2015)运用语步框架分析了15篇语言学领域相关英文前言,发现前言的修辞结构并非固定不变。上述研究都是在Swales、Bhatia等的语步分析框架下进行的。
本文将利用“语篇瓦片叠压”技术(Hearst 1993)和多特征多维度分析法(Biber 1988),对英文语料库研究论著前言进行自动聚类的自下而上式体裁多维分析。
3.研究方法
3.1 研究语料
本文语料取自书名包含corpus、corpora字样或丛书系列名称包含corpus的英文电子书260册,书籍内容都和语料库语言学相关,共提取有效前言61篇。所谓有效前言,指的是前言由书籍作者自己撰写,而不是丛书编辑前言、序言或引言等。61篇前言跨越1988—2015年,共27年时间。为方便起见,前言文件名统一采用编号pf01至pf61。每篇长度在175-2,700词不等,平均每篇946词。61篇合计57,690词。
3.2 “语篇瓦片叠压”文本分割技术
“语篇瓦片叠压”(以下称作TextTiling)文本分割技术及相关程序由美国加州大学伯克利分校信息学院Marti Hearst教授于20世纪90年代早期开发。该程序通过计算词语共现及分布,自动将文本切分为子话题,切分结果和人工切分达到了很好的一致性(Hearst 1993,1994,1997;Hearst & Plaunt 1993)。
Hearst(1997)假定,特定子话题的讨论需要使用一套特定词汇,当子话题改变时,使用的词汇很大一部分也会随之改变。TextTiling正是通过考察词语复现情况来发现子话题,其子话题又称“基于词汇的话语单位”(Vocabulary-Based Discourse Unit,简称VBDU)(Biberet al.2007:156)。
Hearst(1997)对TextTiling程序的具体算法作了比较系统的介绍,包括分词、相似值计算和边界识别三个环节。本文采用Boutsioukis(2015)用Python语言编写的自然语言处理工具包源代码,可从NLTK官方网站获得,主要参数均采用默认设置,即:伪句子长度为20(w=20),每10个伪句子组成一个文本块(k=10),相似度算法为文本块比较法,平滑宽度为2,边界划分临界值为HC,停用词为NLTK自带的英语停用词表。
TextTiling技术可以用于语步(Biberet al.2007:169)的自动切分。而传统以语步为分析框架的、自上而下的体裁研究,虽然取得了丰硕成果,但比较耗时费力,尤其是处理大量文本。作为计算机自动分析处理程序,TextTiling在这方面优势明显。有关TextTiling的详细介绍,可参见宋仁福(2016)。
3.3 多维分析标注软件
多维分析标注软件(Multidimensional Analysis Tagger,以下简称MAT)复用了Biber(1988)中进行英语语域变异的分析方法和流程。该软件内嵌“斯坦福词性赋码器”(Stanford POS Tagger)并进行了一定的优化,如增加了量词、代词等,在此基础上进行67种语言特征的标注与统计分析。经过对语言特征进行因子分析,Biber(1988:122)将所有体裁分为6个维度:维度1是交互性与信息性表达(involved versus informational production);维度2是叙述性与非叙述性关切(narrative versus non-narrative concerns);维度3是指称明晰性与情境依赖型指称(explicit versus situation-dependent reference);维度4是显性劝说型表述(overt expression of persuasion);维度5是信息抽象与具体程度(abstract versus non-abstract information);维度6是即席信息组织精细度(on-line information elaboration)。
运行MAT软件会生成所选语料库文本类型分析或体裁分析所需的统计数据,同时生成一份经语法标注过的语料库版本。MAT以图表形式标示输入文本或语料库的维度类型及最接近文本类型,其中,维度类型参照Biber(1988:102,103,122)书中的6个功能维度。最初的模型中有7个维度,但第7个维度数据较为稀疏,实际操作中往往舍去第7个维度(Biber 1989;江进林、许家金 2015)。文本类型参照《英语语体类型》(Biber 1989)一文中23类(书面语15类,口语8类)。最后,MAT软件还提供了文本维度特征的可视化工具。
4.结果与讨论
本研究先运用TextTiling工具对每篇前言进行子话题进行自动识别、切分,再通过Nini(2015)的多维标注分析软件MAT 1.3进行67种语言特征标注,从而进行语言特征、语篇体裁分析。
4.1 TextTiling结果分析
本语料共61个文本文件(pf32、pf59全文只有一段,字数不多,TextTiling处理报错,未计入统计分析范围),TextTiling处理后,每个文件自动生成子话题切分文件,现以pf01文件为例。pf01子话题信息标注在一组尖括号内,“
全部59篇(pf32、pf59除外)前言共划分为435个子话题,平均每篇7.37个,每篇实际子话题数2—25个不等,多为4—5个,占总数的35.59%。说明大部分前言阐述4—5个子话题,这和Azar(2012)4个语步的划分比较吻合。
每个子话题的字数各异,8—1,002个不等,平均为131.93字。65%左右的子话题字数集中在51—150字之间,字数在51—200字之间更是占全部子话题数的80%以上。
4.2 MAT结果分析
在语步切分、标注基础上,MAT对文本进行深入标注和分析(Nini 2015),并生成丰富的数据和图表,譬如,词性标注、语法分析、标准分(Z-Score)计算、67个语言特征值统计、功能维度统计与归类、文本类型,等等。本次分析设置的TTR值(类/形符比)是MAT默认的400。
4.2.1 文本分类
本文语料为英文语料库研究论著中的61篇前言,MAT将它们自动归为4类文本类型(见表1),即一般叙述型(general narrative exposition)、交互劝说型(involved persuasion)、学术型(learned exposition)和科学型(scientific exposition),其中,学术型和科学型占84.75%,但也有一定比例的变异。

表1 前言文本及文本分类
对学术型、科学型文本67个语言特征分值进行独立样本t检验,结果如表2所示,本例中的学术型、科学型文本并无显著差异(t=0.12,df=3347,p > 0.05),可视作同一类(科学学术型)分析讨论。

表2 科学型、学术型文本独立样本t检验
上述文本分类揭示了前言文本的三大特性,按显著性程度依次为:推销、信息传达和学术论述。信息传达是基础,学术论述是核心,推销是附产品。
前言大致都需要告诉读者该书的主旨、写作背景、写作目的、目录结构、读者对象、阅读建议或致谢等信息,以帮助读者决定是否阅读或购买此书,如例(1)至例(6)。
(1) (pf41)
(2) (pf10)
(3) (pf52)
(4) (pf52)
(5) (pf08)
(6) (pf61)
除信息传达外,学术性也是前言的一大特点。比如,前言中常谈论某领域的理论基础、研究现状、概念主题、代表人物等,这些都是学术性的表现,如例(7)至例(13)。
(7) (pf43)
(8) (pf02)
(9) (pf12)
(10) (pf41)
(11) (pf42)
(12) (pf52)
(13) (pf55)
前言文本的第三个特点是互动劝说性,通过人称代词we等方式模糊读者距离感,增强信任感,使读者认同作者及书籍所描述的价值,达到推销目的,这和前人(Luzón 1999;Azar 2012;Abdollahzadeh & Salarvand 2013)的研究较为吻合,如例(14)至例(16)。
(14)(pf08)
(15)(pf31)
(16)(pf52)
4.2.2 文本维度
Biber(1988)将文本按功能分成了6个维度:交互性/信息性表达、叙述性/非叙述性关切、指称明晰性/情境依赖型指称、显性劝说型表述、信息抽象/具体程度、即席信息组织精细度。每个维度分值有正有负,文本功能呈互补分布,分值绝对值越大则相应文本功能越明显。以维度1为例,维度1的功能是交互性与信息性表达,正分值反映交互性,负分值反映信息性。正分越大说明交互性越明显,负分值绝对值越大说明信息性功能越明显。
MAT处理后,每个文本都将得到6个维度的维度分值,图1为所有前言文本6个维度得分的最小值、最大值及均值,最小值和最大值之间的范围就是各文本在该功能维度的显著程度,均值则反映了所有文本的一般特性。图1显示,维度1、维度2和维度4均值都为负,维度3、维度5和维度6均值为正,按绝对值大小依次为:维度1、维度3、维度5、维度2、维度4和维度6,其中,维度1和维度3分值绝对值比较大,其他维度绝对值都比较小,说明信息性和指称明晰性是其显著特点。这是因为前言主要阐述了与书籍、作者等相关的信息,而且阐述清楚、明晰。
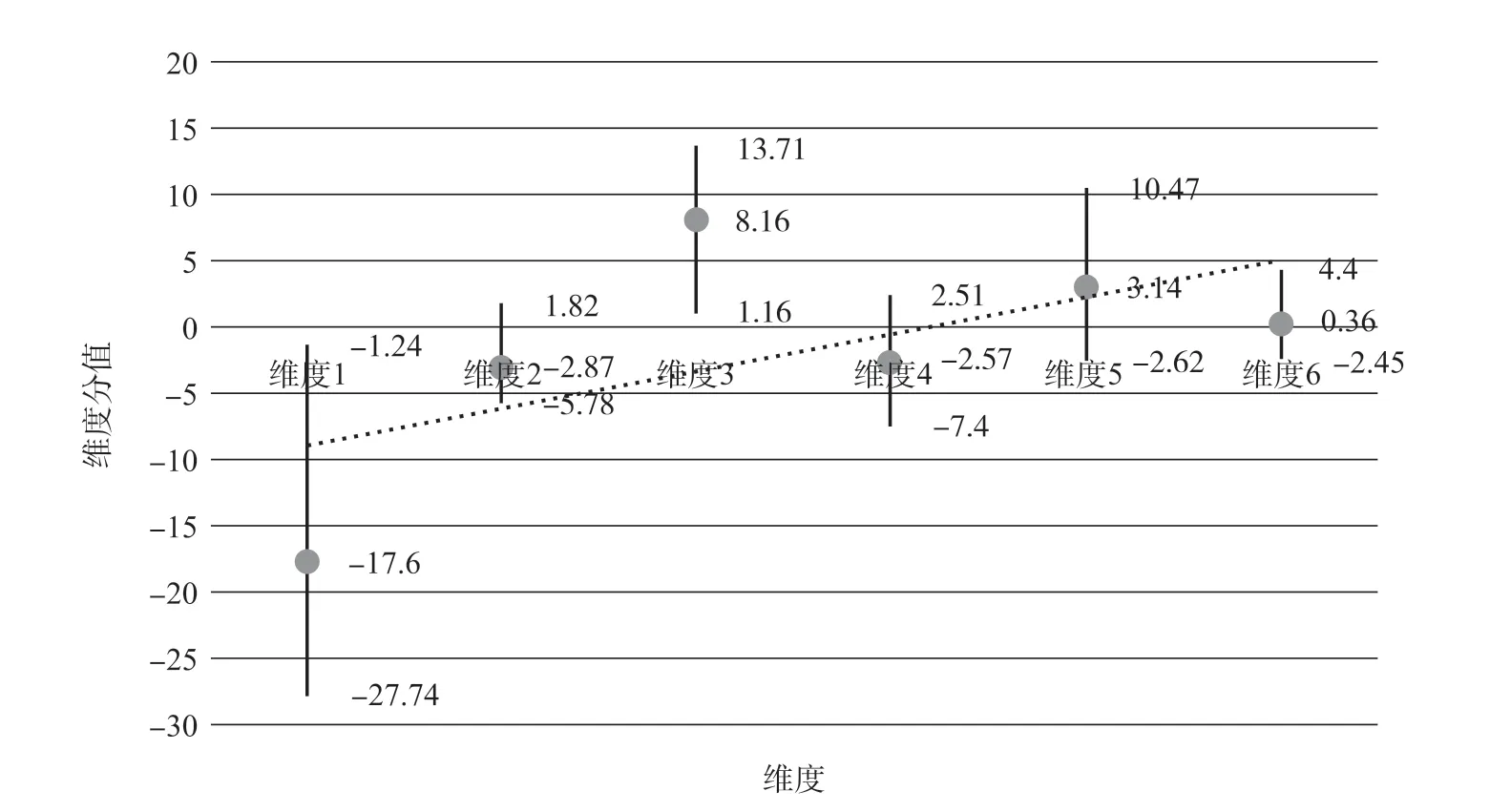
图1 前言文本各维度分值范围及均值
为进一步探究各语步的功能维度情况,文章将435个语步全部抽取并保存为435个独立文本文件。因为语步19—25各出现一次,未纳入统计,实际统计的语步为431个。为方便检索与回溯,文件名体现了原文件及其语步序号,如pf01_1,即pf01原文件中第一个语步。
图2为各语步在6个维度的均值柱形图,可以看出,各语步在维度1、维度2和维度4的分值全部为负数,维度3全部为正值,维度5的值除一个外全部为正,维度6半数以上的分值为负。这说明各语步在信息表达、非叙述性关切、显性劝说、指称明晰、信息抽象等功能方面比较突出。
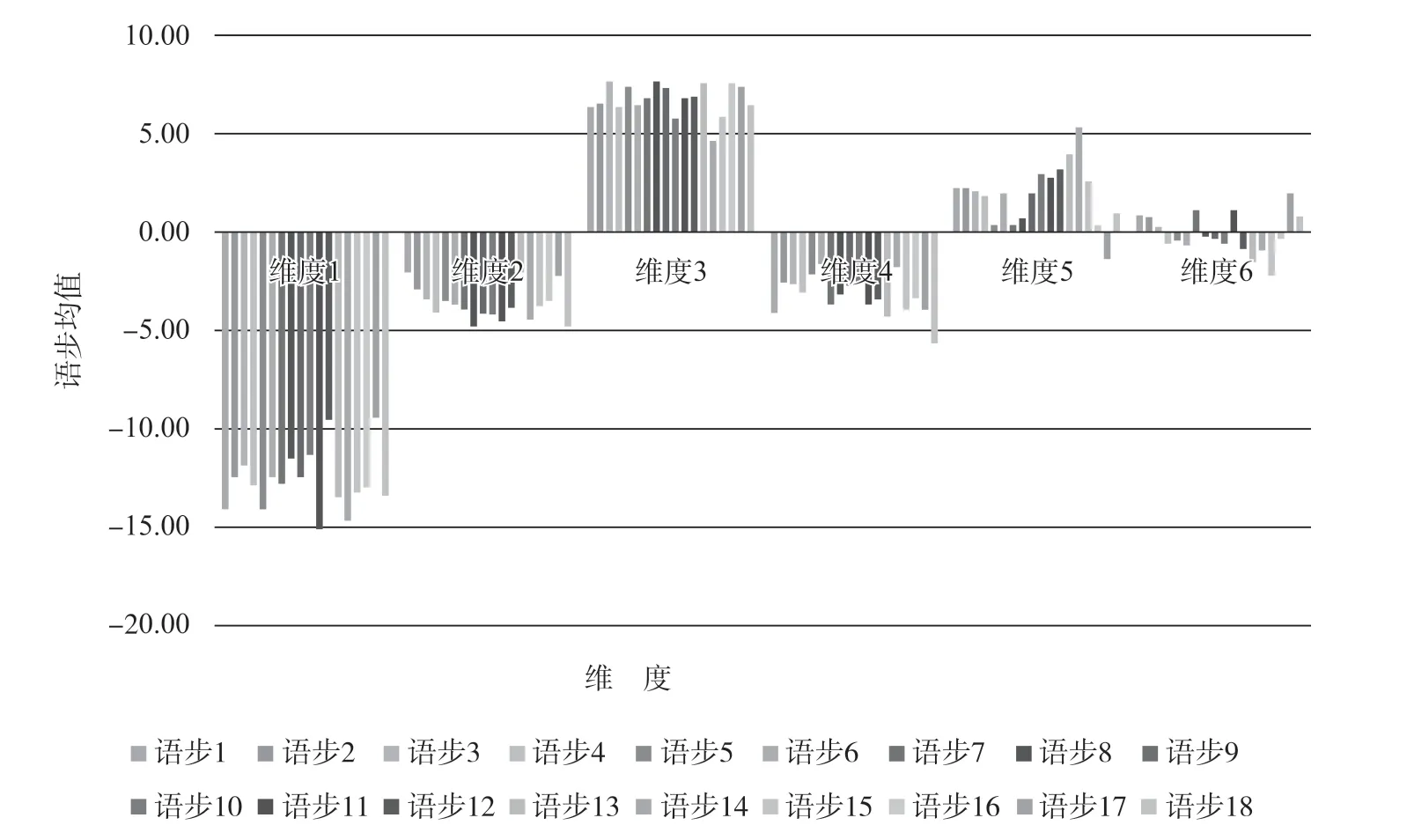
图2 各语步维度均值柱形图
与图2类似,表3呈现了各语步在6个维度的具体分值(按绝对值从高到低排列)。如表3所示,语步11、语步14、语步5和语步1表现出较强的信息性表达功能,语步18显性劝说功能较明显,语步14和语步13信息抽象功能较强。
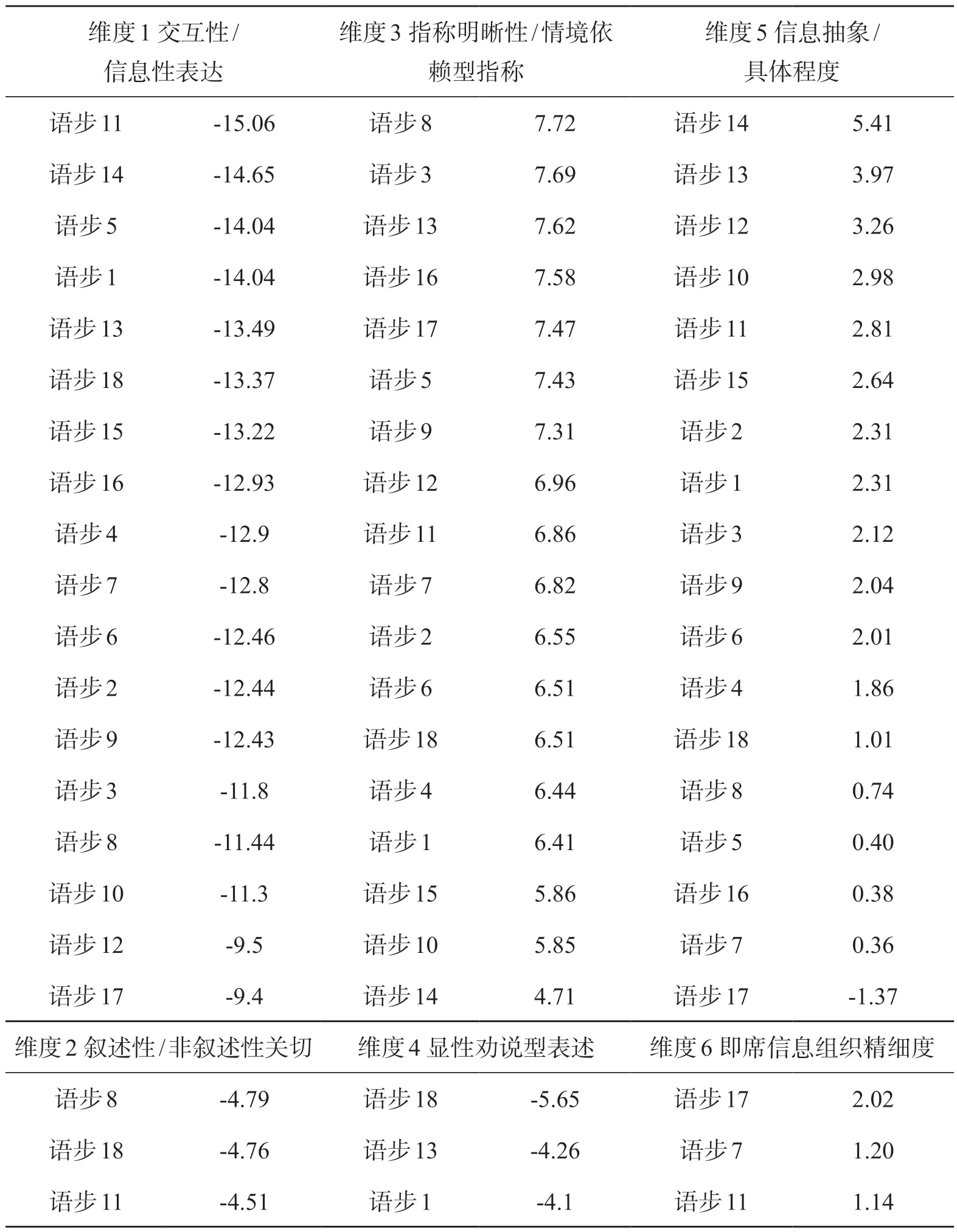
表3 各语步维度与均值统计表
(待续)
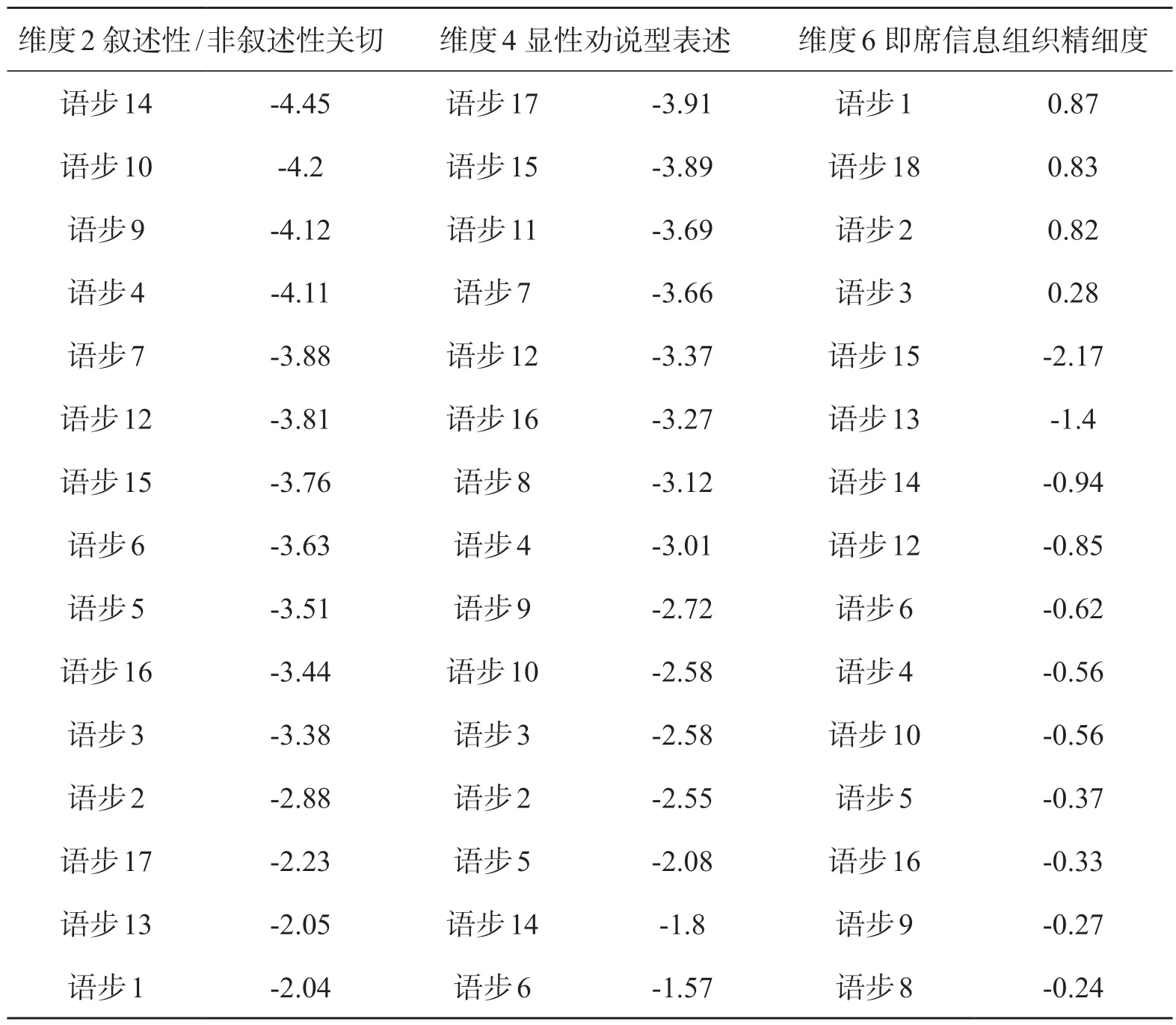
(续表)
信息性表达功能的主要语言特征是多用名词、介词、定语形容词、长词,词汇种类多(Biber 1998:193),其他特征还有多使用冠词、数词、专有名词等,这些特征可以在语步1、语步5、语步11和语步14中得到体现,如例(17)至例(18)。
(17) (pf38_1)
(18) (pf01_1)
语步14和语步13表现出较强的信息抽象功能,信息抽象功能的语言特点是多用连词、被动态、从句等(Biber 1998:151),如例(19)和例(20)。
(19) (pf02_14)
(20) (pf14_14)
5.结语
基于“语篇瓦片叠压”技术的分析显示,36%以上的英文语料库研究论著前言的语步数为4—5个,平均每篇7.37个。每个语步平均为132词,65%以上的语步词数在51—150之间。多特征多维度分析表明,前言具有3种体裁风格:学术论说、一般叙述、互动劝说,其中,学术论说为主体(占84%),叙述和劝说次之。因此,可以说前言兼具学术论说、背景叙述及书籍推销功能于一体。按几项功能的语篇分布来看,在多个语步(如第1、5、11、14语步)中体现出前言体裁的信息表达功能,主要用于陈述研究话题、写作背景等,也有部分语步(如第13、14语步)表现出学术论证性特点,而在结尾部分(如第18语步)多出现显性劝说型表述,旨在推销所介绍的书籍。
前言文本通过明晰的语言,向读者提供了与书籍内容、背景、目的等相关的基本信息和学术信息,有时也将致谢纳入其中,采用拉近与读者关系等策略,客观上也能实现推销功能。
由于本研究所采用的语料主题单一、样本较小,其结果难免有所局限。本文着重在于验证基于整合“语篇瓦片叠压”和多维分析技术的自下而上的语步分析方法。研究表明,“语篇瓦片叠压”技术可自动、高效地对语篇子话题(语步)进行切分,该技术与多特征多维度分析法相结合,能够有效揭示各语步的维度功能及语言特征。机器切分与分析省时省力、客观高效,值得在其他体裁分析研究中尝试。
猜你喜欢
教学考试(高考英语)(2024年1期)2024-04-26 03:09:38
开封文化艺术职业学院学报(2021年1期)2021-01-02 22:02:23
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
传媒评论(2019年3期)2019-06-18 10:59:04
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
厦门理工学院学报(2016年6期)2016-02-06 08:57:34
黑龙江工业学院学报(综合版)(2015年10期)2015-12-13 13:08:38
语言与翻译(2015年4期)2015-07-18 11:07:45
外语学刊(2011年3期)2011-01-22 03:42:17
