
EconDEAP经济学学术英语语料库的创建*
2020-07-02 10:36西南财经大学韩光菊
语料库语言学 2020年1期
西南财经大学 刘 霞 韩光菊
提要:国内外学术英语研究受到了越来越多的重视,学者们构建了多个学术英语语料库,但其中经济管理相关学科的语料并不多,而且目前并未有经过语步标注的大型语料库。DEAP是首个经过语步标注的大型学术英语语料库,包含了不同学科的子库,EconDEAP经济学学术英语语料库就是其中之一。本文介绍了EconDEAP语料库的语料来源、语料采集、文本清理等,尤其对语步结构的标注和校对进行了详细说明,最后探讨了该语料库对学术英语教学与研究的意义。
1.引言
随着国内外学术界对ESP写作教学与研究的重视日益增加,语料库ESP研究在过去10年间越来越多。3本语料库专刊以及4本ESP专刊在Web of Science数据库中共检索到2009—2018年发表的文章1,309篇,语料库ESP相关研究达到249篇,占了近20%,其中,绝大部分是语料库学术英语研究。
相较于其他的数据源,语料库对学术英语研究有着无可比拟的优势。首先,语料库提供了大量且真实的语言数据,以从数据中总结规律,完善或验证理论,从而达到更加科学的研究目的。其次,随着计算机技术的发展,语料库分析技术层出不穷,这些技术为研究者更加高效地分析语料库数据提供了便利。
构建语料库是语料库研究的基础。国内外构建了很多ESP专用英语语料库,其中大部分是学术英语语料库(见表1)。表1列举的学术英语语料库中,有10亿级的语料库,如Google scholar语料库和维基百科语料库,但相关人员没有对语料进行科学取样,更没有平衡各个学科和体裁。其余的语料库均属于百万级的,绝大部分包含了经济学或管理学学科的语料,但经管类的语料总词数不到百万,更重要的是,这些语料没有进行语步标注。

表1 现有学术英语语料库概况
John Swales 在1981年首次提出语步分析法(move analysis),至今,该方法仍是学术英语研究中影响最大、使用最多的研究方法,Swales(2004)仍是近10年语料库ESP研究被引用最多的文献。该方法认为学术论文一般由引言(Introduction)、方法(Methods)、结果(Results) 和讨论(Discussion)四大部分构成,因此被称为IMRD模型。语步分析的目的是“为了通过分析语篇结构,弄清楚语类是如何通过语步和小步被组织起来并实现交际目的”(Bhatia 1993:13)。了解并掌握语类的语篇组织结构,能极大提高作者写作时篇章的组织能力,增加读者在阅读时对语篇连贯的整体把握(Swales 1990:190)。只是,语步分析法过度依赖手工标注,很难进行大规模的语篇分析,即便是Swales(1981)的开创性研究也仅分析了48篇学术论文的引言部分,就得出了著名的CARS(Creating A Research Space)模型。如果能结合语料库与语步分析法,一方面,能够客观地发现语言特征在语篇内部的分布(梁茂成、刘霞 2014);另一方面,通过分析大量真实的经过科学抽样的语料,能够印证Swales(1990)关于语步由特有的语言特征实现的思想,为下一步研究语步和语言特征的关系奠定了基础。此外,由机器自动切分语步已经成为可能(刘霞2017),但在建模之前,仍然需要大规模人工标注过语步的语料作为学习语料。经过语步标注的DEAP语料库,能够为下一步实现多个学科语篇自动切分提供大量的学习语料。
2.语料库概况
EconDEAP共收录了74 种国际经济学期刊在2015—2018 年发表的研究论文631篇,其中研究论文525篇,综述以及观点性的论文101篇,书评5篇,总容量约为650 万词。
2.1 语料库创建的总流程
EconDEAP语料库的创建包括语料的搜集、语篇的人工标注,以及两次校对。其中,语料的搜集和语篇的标注由某财经大学的7位经济学方向的研究生完成。他们来自经济学方向6个不同的二级学科,包括金融学、财政学、税收学、保险学、经济统计学和产业经济学。然后由3位英语专业的研究生校对语篇格式,最后由研究者本人进行所有语料语篇结构标注方面的校对。
2.2 语料来源
语料库的代表性是语料库建设者需要关注的首要问题。语料库的代表性是指一个语料库在多大程度上能够代表一种语言或语言变体中各种不同的语言现象(Biber 1993)。本语料库的代表性主要体现在学科、体裁和时效性三个方面。
首先,国内外对经济学的学科分类目前仍存在较大争议(樊纲 2001)。本语料库的创建是为了服务于国内经济学学术英语的教学与科研,故我们选择了教育部2013年《学位授予和人才培养学科目录》中的学科分类,确定了经济学一级学科“理论经济学”(代码0201)下设的5个二级学科(政治经济学、经济史、EconDEAP经济学学术英语语料库的创建西方经济学、世界经济学、人口资源与环境经济学)和“应用经济学”(代码0202)下设的13个二级学科(国民经济学、区域经济学、财政学、金融学、产业经济学、国际贸易学、劳动经济学、经济统计学、数量经济学、国防经济学、保险学、金融工程、税收学),共计18个二级学科,作为经济学学术英语语料库涵盖的学科方向。但以国内的经济学学科分类为指导建库,就要面临如何确定每个学科对应的国际全文期刊的问题。我们根据美国科学情报研究所(Institute for Scientific Information,简称ISI)编制的Web of Science引文数据库中的期刊引文报告(Journal Citation Report,简称JCR),选择了经济学方向综合影响因子最高的前100本期刊,再参考国内某财经大学提供的经济学各个二级学科的期刊目录,并由参与数据搜集的经济学方向的研究生请教为他们授课的教授,共同确定了这18个经济学二级学科各自最权威的期刊3—5本(详见表2)。从表2可以看出,有些经济学的综合性权威期刊,如Quarterly Journal of Economics会出现在多个二级学科。在选择文章时,我们请同学们根据各自的研究背景,阅读标题和摘要,判断该论文的内容是否属于这个二级学科,以示区分。
其次,为了尽可能平衡语料的体裁,同时又体现经济学学科的实际特点,我们预先请每位同学搜集45篇论文,其中,研究论文25篇,观点性论文15篇,书评5篇,但同学们在搜集的过程中反馈大部分期刊没有书评,而观点性论文不容易区分,后期审校时发现不少观点性论文仍为研究论文,因此出现了表1中观点性论文较少,书评极少的现象,这也从一定程度上代表了经济学期刊论文发表的现状。最后,为了体现语料的时效性,我们只选取了2015—2018(主要为2016—2018年)出版的论文,见表2。
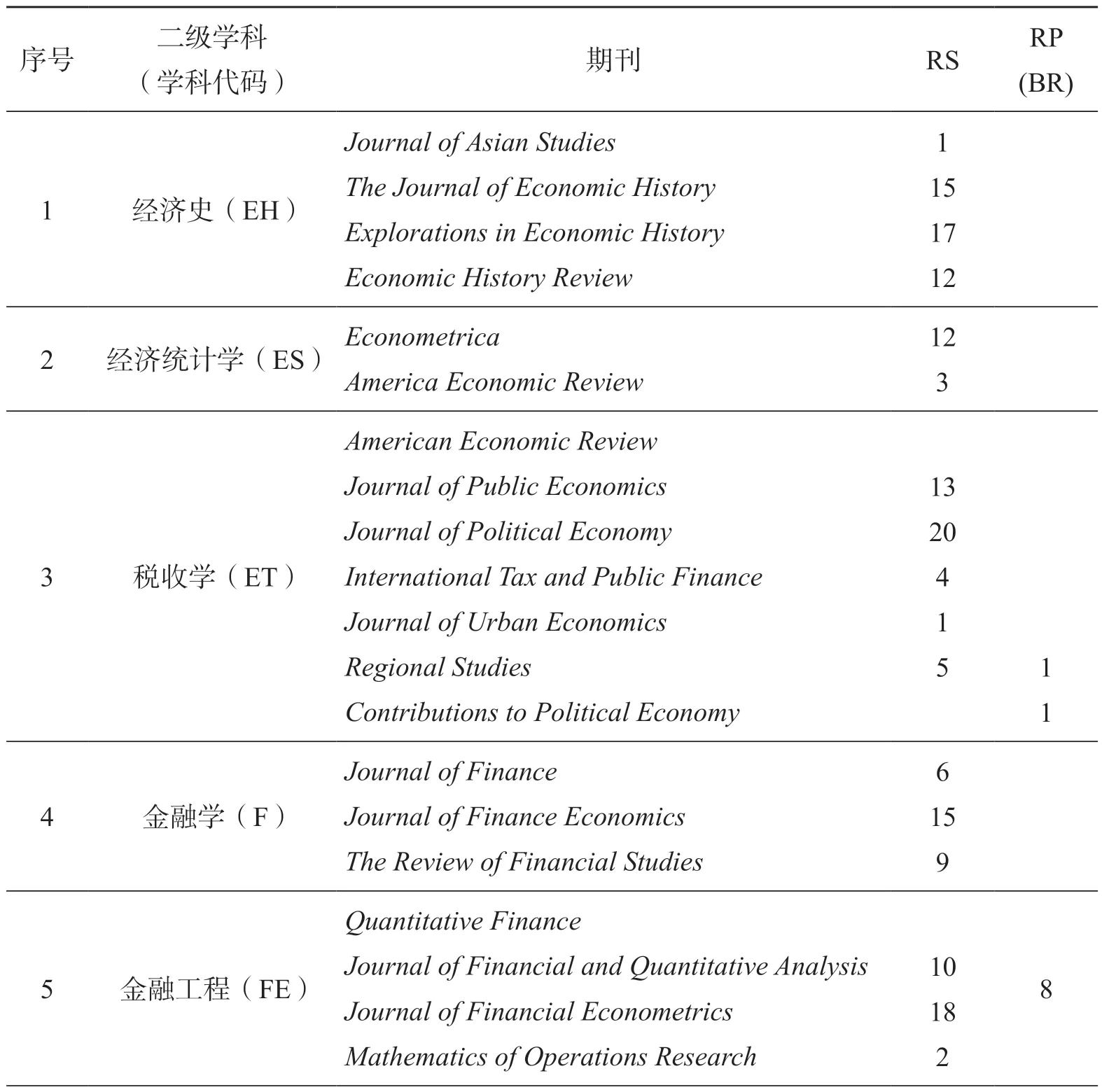
表2 经济学学术英语语料库来源期刊
(待续)
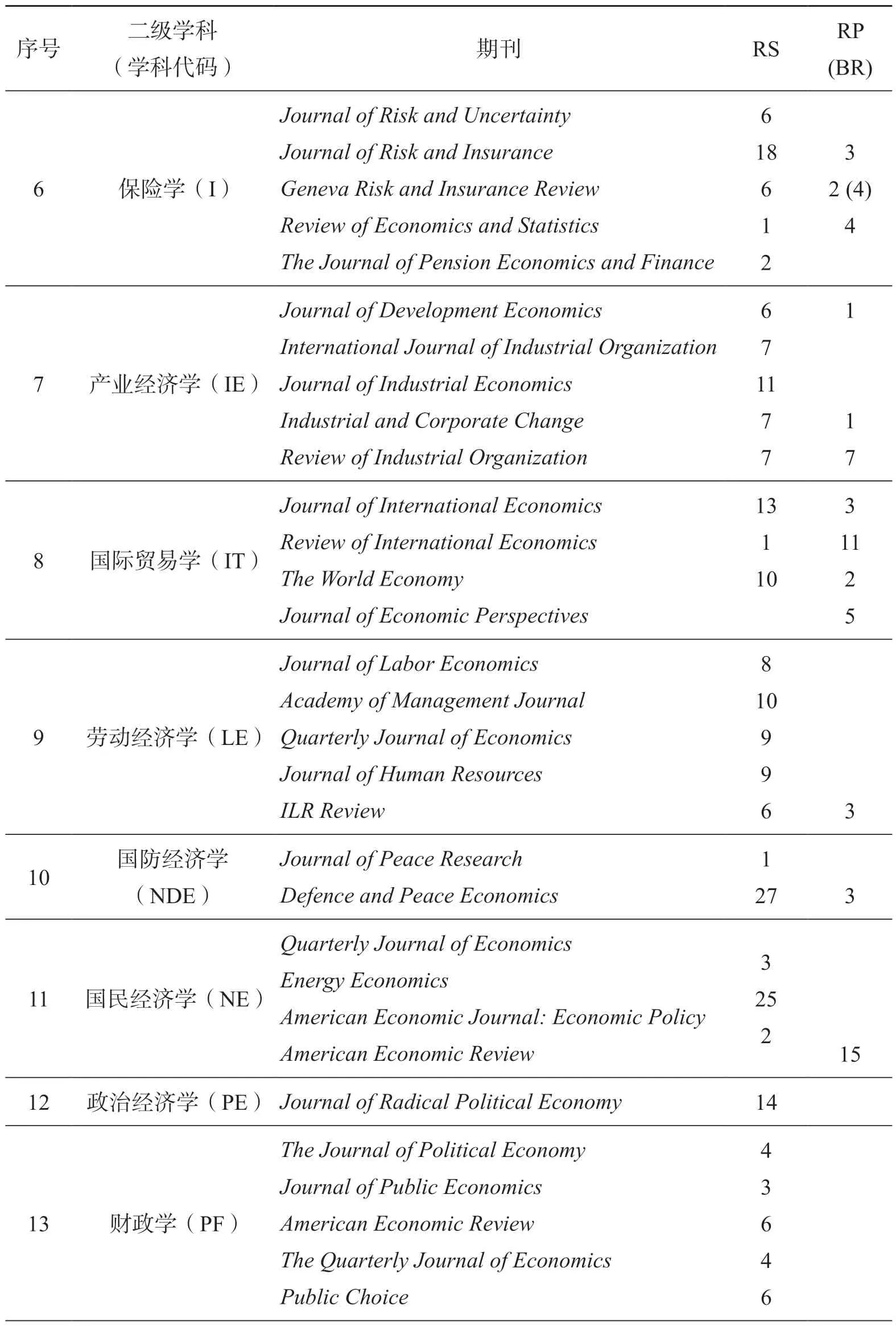
(续表)
(待续)

(续表)
2.3 语料的人工标注
目标期刊确定后,语料的收集相对容易,只需要按照目标期刊,从数据库检索并下载即可。但下载的PDF格式的论文,若批量转换为纯文本格式进行人工标注,在纯文本格式下阅读文本再标注就有极大的困难,且会影响标注结果。于是我们参考Swales(1990)提出的学术论文的宏观结构IMRD模型,结合经济学学术语篇的实际结构,预先确定了大部分语篇共有的原型结构,制作成WORD模板,并高亮显示开关闭符,方便同学们直接将原文每个部分的语言文字内容复制粘贴到对应的开关闭符中。该模板既包括了语篇的元信息,如journal、title、authors and affiliations、correspondence、appendix,也包含了经济学学术语篇原型结构的几个语步结构信息,如:abstract、keywords、introduction、methods、model、results、robustness、conclusion、references。这种复制粘贴的方式,虽然比下载后批量转换费时间,但是避免了因为没有语料标注经验而在纯文本中进行手工标注出现的错误,也避免了容易遗漏开始符或关闭符的问题。而且批量转换后的论文,仍然需要人工删除页眉、页脚、页码,以及图表。复制粘贴的时候,可以选择不复制这些需要删除的内容。此外,我们选择了复制网页版论文,而不是PDF,因为复制后者,其行尾会自动生成换行符。网页版的论文还会有一个文章目录,方便定位到文章的每一个部分。对于没有网页版的论文,则在Sci-Hub网页上打开全文进行复制,Sci-Hub网页上的论文复制时会失去原文应有的段尾换行符,将所有复制的内容合并为一段,于是我们选择了一段一段地复制,或者完整复制过来再分段的方式搜集语料。需要注意的是,我们预先确定的模板包含的语步结构码只是代表了大部分语篇共同具有的语步结构,即学术语篇的原型结构,但不能忽略经济学学术语篇结构的特异性,正如Devitt(2015)所言,语类能力是共同的,但实际语篇中的语类应用是特异性的,语类研究既要发现语篇中共同的原型结构,也不能忽略单个语篇的特异性。为了既体现每一个语篇的语步结构,又有一个方便归类的原型结构,我们采用了两级标注码。例如,如果原文语篇内部的标题是Methods and data,我们用
2.4 语料的校对
语料在搜集完成后,经历了两次人工校对。首先由3位英语专业的研究生对语料的格式进行校对,主要校对由于公式导致的换行或者句子不完整问题。有的同学在语料搜集时,原文中单独成行的公式,没有用#E替换,直接选择跳过该公式,导致句子不完整,且自动分段。于是我们统一使用正则表达式[w|:|)|,]s* 检索以上情况,再由人工逐篇判断该换行符是否属于原文,如不是,则删除换行符,并补充#E和句号或逗号,让句子保持完整,如将The specification takes the following form:修改为The specification takes the following form:#E.。句号或逗号根据上下文进行判断。
校对完语料格式之后,由研究者批量整理校对标注码。首先,使用PowerGrep批量检索所有语料中的开关闭符,判断开关闭符的数量是否一致,对于不一致的,到原文中进行修改。其次,在每个文本中,分别检索语步结构的标注码,对于明显不正确的进行修改。
3.基于EconDEAP 语料库的教学应用与语言研究
有了EconDEAP经济学学术英语语料库,研究者能够进行ESP领域的三个主要研究方面:(1)以Swales(2004)为中心的基于语步分析法的ESP体裁分析研 究;(2)以Simpson-Vlach & Ellis(2010)和Gardner & Davies(2013)为 代表,关注并优化学术英语跨学科的通用核心词表;(3)由Cortes(2004)、Biberet al.(2006)和Hyland(2008)引导的基于语料库的方法,探索学术英语语言的学科差异性研究,并与已经建成的医学(冯欣等 2017)、生命科学(彭工 2018)、语言学(布占廷等 2018)、军事学术英语语料库(马晓雷等 2018)进行对比研究。在教学方面,EconDEAP语料库的创建为经济学学术英语写作的教与学提供了丰富的语言材料,结合上述的研究结论,经济学学术英语写作的教授和学习,可以既关注经济学学术英语的通用核心词表,也可以对比各个二级学科特有的语言现象,利用语料库中的语步标注信息,关注这些通用的和特有的语言现象在语篇内部的变化。此外,有了大量经过语步标注的语料,为下一步构建模型,为实现语步的自动分析以及机器的自动标注奠定了基础。
4.结语
作为DEAP学术英语语料库的一个子库,EconDEAP经济学学术英语语料库严格按照预先制定的统一规范,在建库过程中,我们得到了多位专家教授的指导,同时与其他子库的建设者共同协商,以确保子库之间的可比性。经过期刊的选择、语料的搜集与清理、语步的人工标注,以及两次人工校对,我们最终构建了国内外首个经过语步标注的经济学学术英语语料库。该语料库与其他学科的语料库一起,将由中国外语与教育研究中心语料库语言学团队统一发布在语料云网站(www.corpuscloud.cn)及BFSU CQPweb平台(http://114.251.154.212/cqp/)),供语言研究者、语言教师、学生、科研人员免费使用。
猜你喜欢
通信技术(2021年12期)2022-01-25
天津外国语大学学报(2021年1期)2021-03-29
天津外国语大学学报(2020年1期)2020-03-25
语言与翻译(2015年4期)2015-07-18
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
外语教学理论与实践(2014年4期)2014-06-13
当代修辞学(2014年1期)2014-01-21
当代修辞学(2014年1期)2014-01-21
